Содержание
- Часть 1: Введение
- Часть 2: Manifold learning и скрытые (latent) переменные
- Часть 3: Вариационные автоэнкодеры (VAE)
- Часть 4: Conditional VAE
- Часть 5: GAN (Generative Adversarial Networks) и tensorflow
- Часть 6: VAE + GAN
В прошлой части мы уже обсуждали, что такое скрытые переменные, взглянули на их распределение, а также поняли, что из распределения скрытых переменных в обычных автоэнкодерах сложно генерировать новые объекты. Для того чтобы можно было генерировать новые объекты, пространство скрытых переменных (latent variables) должно быть предсказуемым.
Вариационные автоэнкодеры (Variational Autoencoders) — это автоэнкодеры, которые учатся отображать объекты в заданное скрытое пространство и, соответственно, сэмплить из него. Поэтому вариационные автоэнкодеры относят также к семейству генеративных моделей.

Иллюстрация из [2]
Имея какое-то одно распределение
 , можно получить произвольное другое
, можно получить произвольное другое  , например, пусть — обычное нормальное распределение,
, например, пусть — обычное нормальное распределение,  — тоже случайное распределение, но выглядит совсем по-другому
— тоже случайное распределение, но выглядит совсем по-другомуimport numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
Z = np.random.randn(150, 2)
X = Z/(np.sqrt(np.sum(Z*Z, axis=1))[:, None]) + Z/10
fig, axs = plt.subplots(1, 2, sharex=False, figsize=(16,8))
ax = axs[0]
ax.scatter(Z[:,0], Z[:,1])
ax.grid(True)
ax.set_xlim(-5, 5)
ax.set_ylim(-5, 5)
ax = axs[1]
ax.scatter(X[:,0], X[:,1])
ax.grid(True)
ax.set_xlim(-2, 2)
ax.set_ylim(-2, 2)
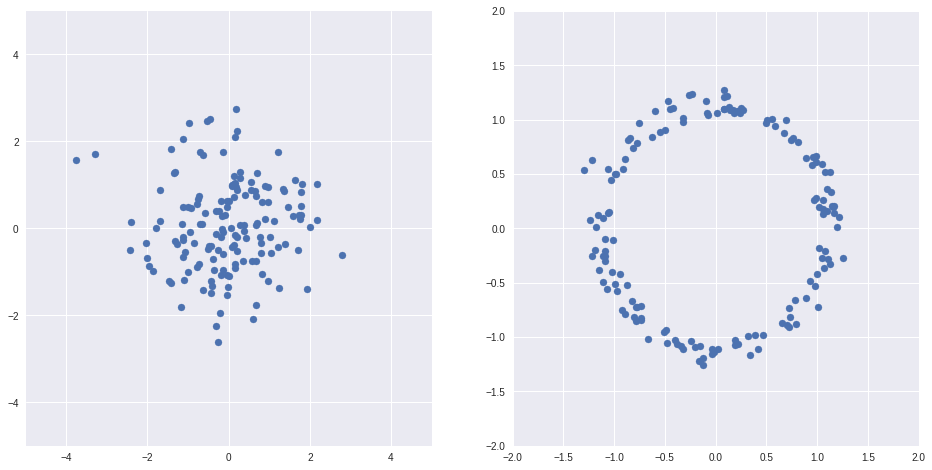
Пример выше из [1]
Таким образом, если подобрать правильные функции, то можно отобразить пространства скрытых переменных обычных автоэнкодеров в какие-то хорошие пространства, например, такие, где распределение нормально. А потом обратно.
С другой стороны, специально учиться отображать одни скрытые пространства в другие вовсе не обязательно. Если есть какие-то полезные скрытые пространства, то правильный автоэнкодер научится им по пути сам, но отображать, в конечном итоге, будет в нужное нам пространство.
Ниже непростая, но необходимая теория лежащая в основе VAE. Постарался выжать из [1, Tutorial on Variational Autoencoders, Carl Doersch, 2016] все самое принципиальное, остановившись подробнее на тех местах, которые показались сложными мне самому.
Пусть
— скрытые переменные, а  — данные. На примере нарисованных цифр рассмотрим естественный генеративный процесс, который сгенерировал нашу выборку:
— данные. На примере нарисованных цифр рассмотрим естественный генеративный процесс, который сгенерировал нашу выборку:
 вероятностное распределение изображений цифр на картинках, т.е. вероятность конкретного изображения цифры в принципе быть нарисованным (если картинка не похожа на цифру, то эта вероятность крайне мала, и наоборот),
вероятностное распределение изображений цифр на картинках, т.е. вероятность конкретного изображения цифры в принципе быть нарисованным (если картинка не похожа на цифру, то эта вероятность крайне мала, и наоборот),
 — вероятностное распределение скрытых факторов, например, распределение толщины штриха,
— вероятностное распределение скрытых факторов, например, распределение толщины штриха,
 — распределение вероятности картинок при заданных скрытых факторах, одни и те же факторы могут привести к разным картинкам (один и тот же человек в одних и тех же условиях не рисует абсолютно одинаковые цифры).
— распределение вероятности картинок при заданных скрытых факторах, одни и те же факторы могут привести к разным картинкам (один и тот же человек в одних и тех же условиях не рисует абсолютно одинаковые цифры).
Представим
как сумму некоторой генерирующей функции  и некоторого сложного шума
и некоторого сложного шума 

Мы хотим построить некоторый искусственный генеративный процесс, который будет создавать объекты, близкие в некоторой метрике к тренировочным
.
и снова

 — некоторое семейство функций, которое представляет наша модель, а
— некоторое семейство функций, которое представляет наша модель, а  — ее параметры. Выбирая метрику, мы выбираем то, какого вида нам представляется шум . Если метрика
— ее параметры. Выбирая метрику, мы выбираем то, какого вида нам представляется шум . Если метрика  , то мы считаем шум нормальным и тогда:
, то мы считаем шум нормальным и тогда:
По принципу максимального правдоподобия нам остается оптимизировать параметры
, для того чтобы максимизировать , т.е. вероятность появления объектов из выборки.Проблема в том, что оптимизировать интеграл (1) напрямую мы не можем: пространство может быть высокоразмерное, объектов много, да и метрика плохая. С другой стороны, если задуматься, то к каждому конкретному
может привести лишь очень небольшое подмножество , для остальных же будет очень близок к нулю.И при оптимизации достаточно сэмплить только из хороших
.Для того чтобы знать, из каких
нам надо сэмплить, введем новое распределение  , которое в зависимости от будет показывать распределение
, которое в зависимости от будет показывать распределение  , которое могло привести к этому .
, которое могло привести к этому .Запишем сперва расстояние Кульбака-Лейблера (несимметричная мера «похожести» двух распределений, подробнее [3] ) между
и реальным  :
:![KL[Q(Z|X)||P(Z|X)] = \mathbb{E}_{Z \sim Q}[\log Q(Z|X) - \log P(Z|X)]](https://habrastorage.org/getpro/habr/post_images/43c/531/ddb/43c531ddb17a769031acfe1d57bdb491.svg)
Применяем формулу Байеса:
![KL[Q(Z|X)||P(Z|X)] = \mathbb{E}_{Z \sim Q}[\log Q(Z|X) - \log P(X|Z) - \log P(Z)] + \log P(X)](https://habrastorage.org/getpro/habr/post_images/930/3dd/de4/9303ddde467987ba7289e4695ba03b28.svg)
Выделяем еще одно расстояние Кульбака-Лейблера:
![KL[Q(Z|X)||P(Z|X)] = KL[Q(Z|X)||\log P(Z)] - \mathbb{E}_{Z \sim Q}[\log P(X|Z)] + \log P(X)](https://habrastorage.org/getpro/habr/post_images/e40/62f/4ff/e4062f4ffaef2a6b6dafdcb7712ce0ad.svg)
В итоге получаем тождество:
![\log P(X) - KL[Q(Z|X)||P(Z|X)] = \mathbb{E}_{Z \sim Q}[\log P(X|Z)] - KL[Q(Z|X)||P(Z)]](https://habrastorage.org/getpro/habr/post_images/6a9/4f3/a68/6a94f3a6831a88bf300ed100387ac0e6.svg)
Это тождество — краеугольный камень вариационных автоэнкодеров, оно верно для любых
и  .
.Пусть
и зависят от параметров:  и
и  , а — нормальное
, а — нормальное  , тогда получаем:
, тогда получаем:![\log P(X;\theta_2) - KL[Q(Z|X;\theta_1)||P(Z|X;\theta_2)] = \mathbb{E}_{Z \sim Q}[\log P(X|Z;\theta_2)] - KL[Q(Z|X;\theta_1)||N(0,I)]](https://habrastorage.org/getpro/habr/post_images/bfc/222/82b/bfc22282b6adda3042f7b997aef20cc3.svg)
Взглянем повнимательнее на то, что у нас получилось:
- во-первых, , подозрительно похожи на энкодер и декодер (точнее декодер это
 в выражении
в выражении  ),
),
- слева в тождестве — значение, которое мы хотим максимизировать для элементов нашей тренировочной выборки + некоторая ошибка
 , которая, будем надеяться, при достаточной емкости
, которая, будем надеяться, при достаточной емкости  уйдет в 0,
уйдет в 0,
- справа значение, которое мы можем оптимизировать градиентным спуском, где первый член имеет смысл качества предсказания декодером по значениям , а второй член, это расстояние К-Л между распределением , которое предсказывает энкодер для конкретного , и распределением для всех сразу.
Для того, чтобы иметь возможность оптимизировать правую часть градиентным спуском, осталось разобраться с двумя вещами:
1. Точнее определим что такое
Обычно
выбирается нормальным распределением:
То есть энкодер для каждого
предсказывает 2 значения: среднее  и вариацию
и вариацию  нормального распределения, из которого уже сэмплируются значения. Работает это все примерно вот так:
нормального распределения, из которого уже сэмплируются значения. Работает это все примерно вот так: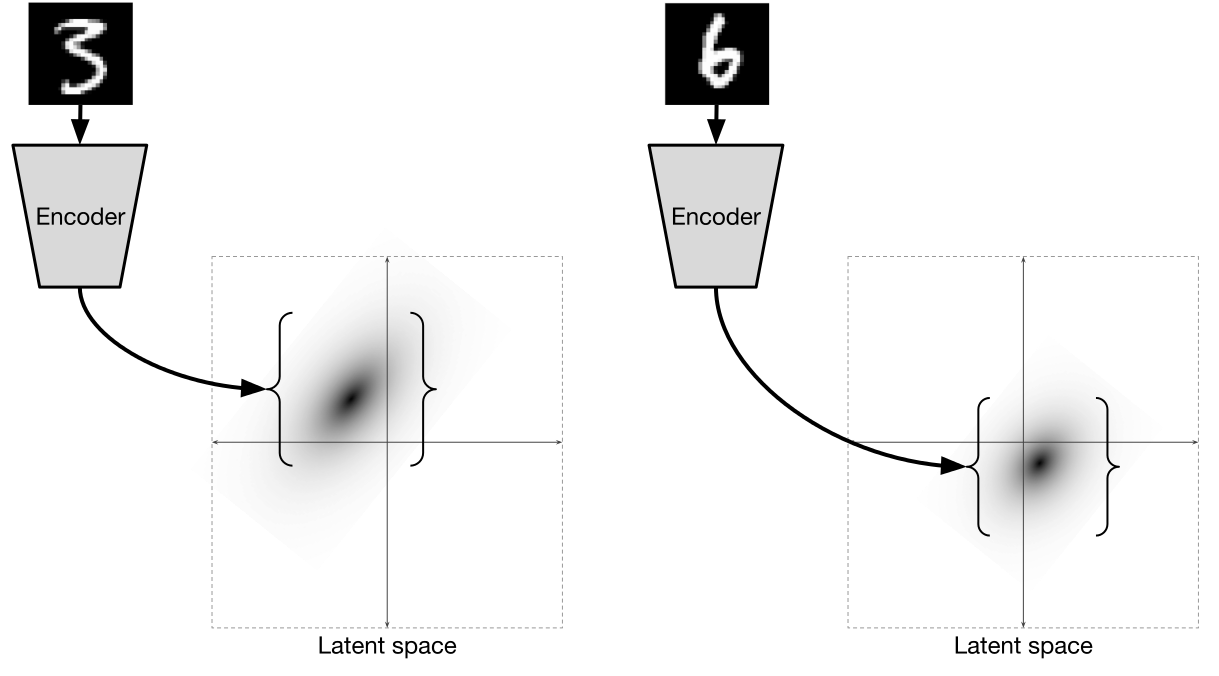
Иллюстрация из [2]
При том, что для каждой отдельной точки данных
энкодер предсказывает некоторое нормальное распределение
для маргинального распределения
:  , что получается из формулы, и это потрясающе.
, что получается из формулы, и это потрясающе.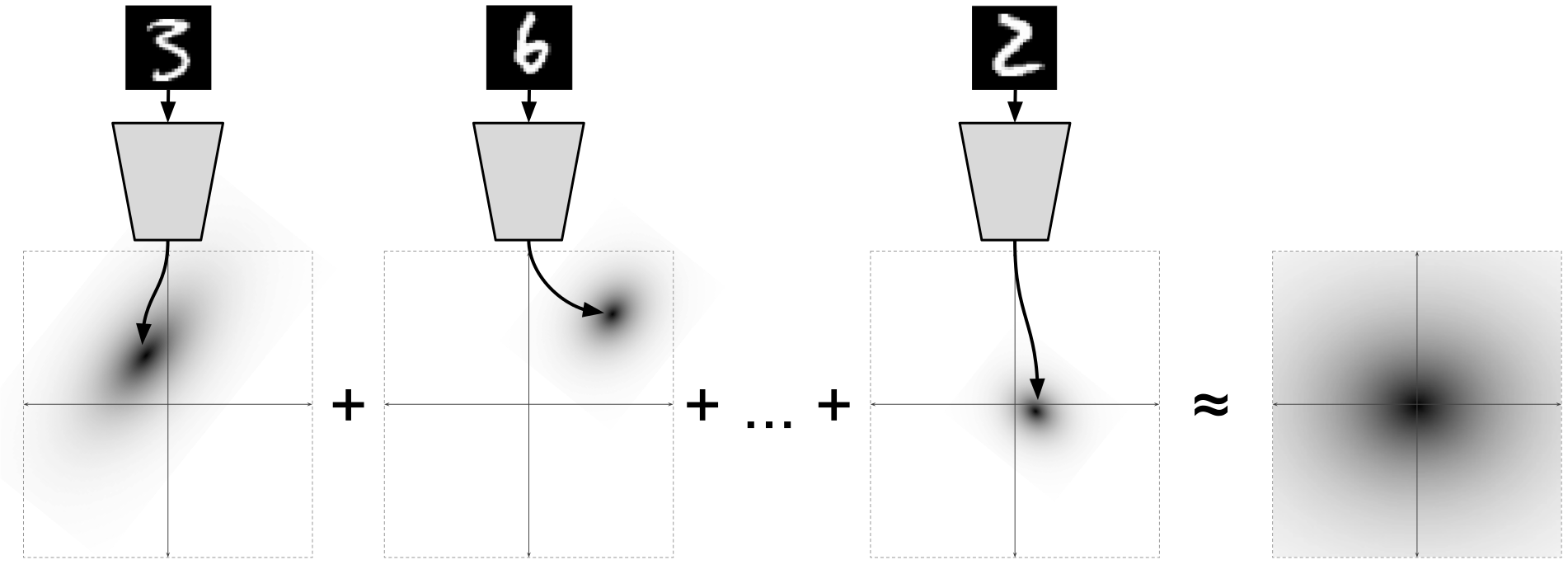
Иллюстрация из [2]
При этом
![KL[Q(Z|X;\theta_1)||N(0,I)]](https://habrastorage.org/getpro/habr/post_images/403/70d/4e3/40370d4e34e3a0bf6f0335e84ae19e6f.svg) принимает вид:
принимает вид:![KL[Q(Z|X;\theta_1)||N(0,I)] = \frac{1}{2}\left(tr(\Sigma(X)) + \mu(X)^T\mu(X) - k - \log \det \Sigma(X) \right)](https://habrastorage.org/getpro/habr/post_images/b27/b66/67c/b27b6667cc1b2dd794a0d8cd220a540a.svg)
2. Разберемся с тем, как распространять ошибки через ![\mathbb{E}_{Z \sim Q}[\log P(X|Z;\theta_2)]](https://habrastorage.org/getpro/habr/post_images/b30/2f5/5e4/b302f55e4a85ec37343537c4ed1119aa.svg)
Дело в том, что здесь мы берем случайные значения
 и передаем их в декодер.
и передаем их в декодер.Ясно, что распространять ошибки через случайные значения напрямую нельзя, поэтому используется так называемый трюк с репараметризацией (reparametrization trick).
Схема получается вот такая:
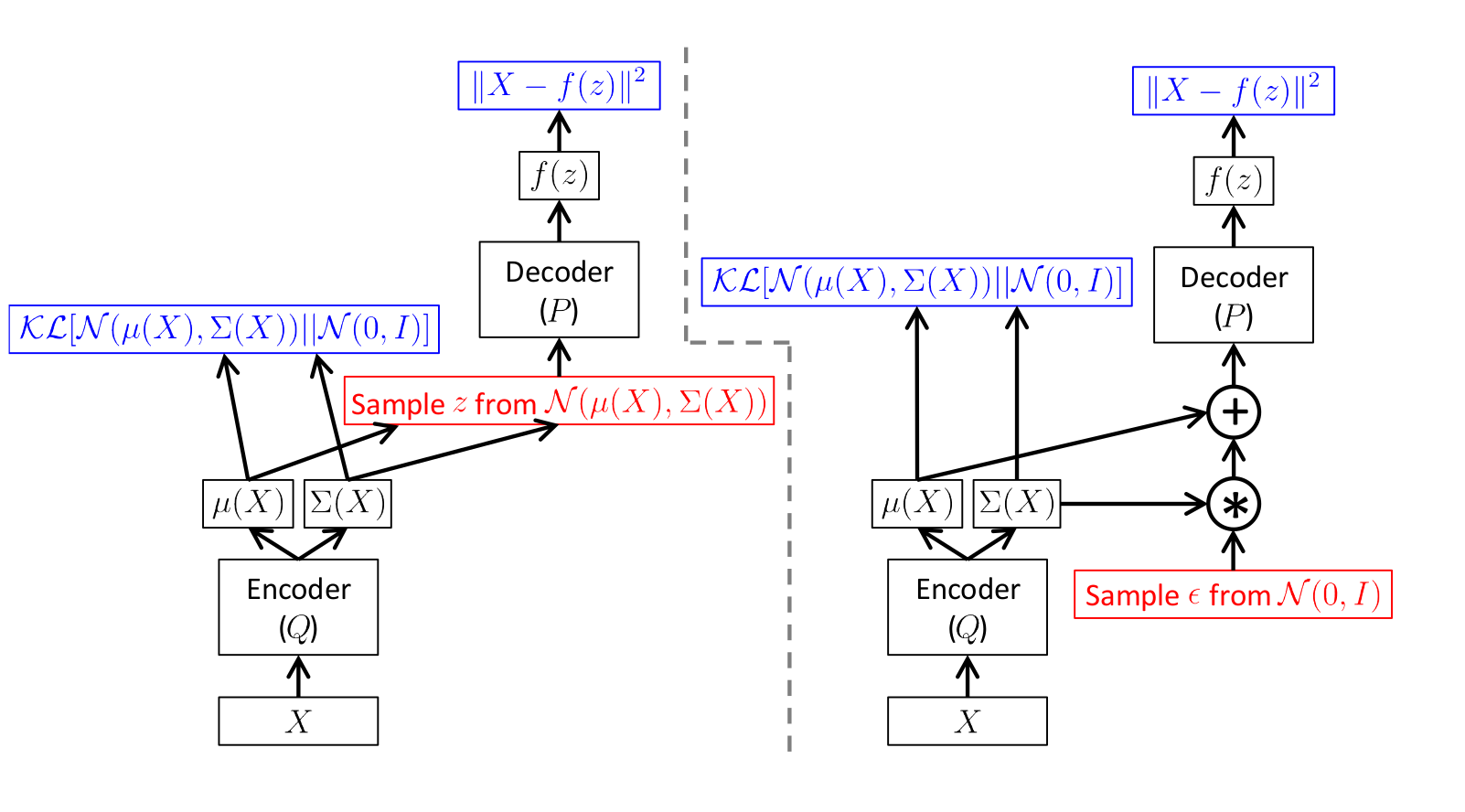
Иллюстрация из [1]
Здесь на левой картинке схема без трюка, а на правой с трюком.
Красным цветом показано семплирование, а синим вычисление ошибки.
То есть по сути просто берем предсказанное энкодером стандартное отклонение
умножаем на случайное число из и добавляем предсказанное среднее .Прямое распространение на обеих схемах абсолютно одинаковое, однако на правой схеме работает обратное распространение ошибки.
После того как мы обучили такой вариационный автоэнкодер, декодер становится полноправной генеративной моделью. По сути и энкодер-то нужен в основном для того, чтобы обучить декодер отдельно быть генеративной моделью.
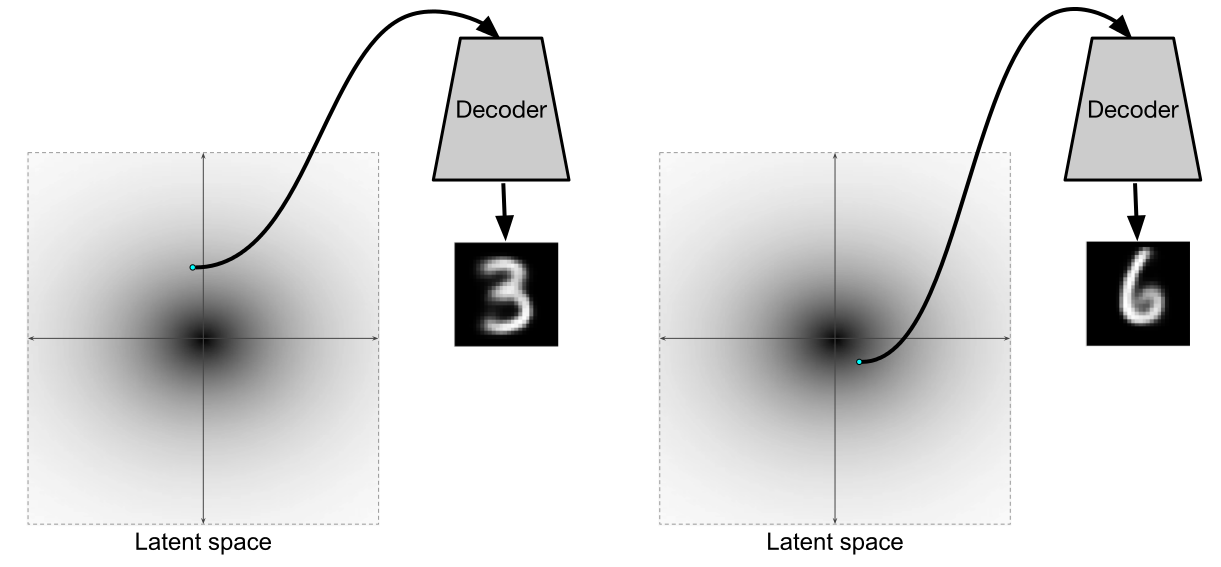
Иллюстрация из [2]

Иллюстрация из [1]
Но то, что энкодер и декодер вместо образуют еще и полноценный автоэнкодер — очень приятный плюс.
VAE в Keras
Теперь, когда мы разобрались в том, что такое вариационные автоэнкодеры, напишем такой на Keras.
Импортируем необходимые библиотеки и датасет:
import sys
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
from keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test .astype('float32') / 255.
x_train = np.reshape(x_train, (len(x_train), 28, 28, 1))
x_test = np.reshape(x_test, (len(x_test), 28, 28, 1))
Зададим основные параметры. Скрытое пространство возьмем размерности 2, чтобы позже генерировать из него и визуализировать результат.
Замечание: размерность 2 крайне мала, поэтому следует ожидать, что цифры получатся очень размытыми.
batch_size = 500
latent_dim = 2
dropout_rate = 0.3
start_lr = 0.0001
Напишем модели вариационного автоэнкодера.
Для того чтобы обучение происходило быстрее и более качественно, добавим слои dropout и batch normalization.
А в декодере используем в качестве активации leaky ReLU, которую добавляем отдельным слоем после dense слоев без активации.
Функция sampling реализует сэмплирование значений
из с использованием трюка репараметризации.vae_loss это правая часть из уравнения:
![\log P(X;\theta_2) - KL[Q(Z|X;\theta_1)||P(Z|X;\theta_2)] = \mathbb{E}_{Z \sim Q}[\log P(X|Z;\theta_2)] - \left(\frac{1}{2}\left(tr(\Sigma(X)) + \mu(X)^T\mu(X) - k - \log \det \Sigma(X) \right)\right)](https://habrastorage.org/getpro/habr/post_images/674/f96/9d7/674f969d746b488c8d9488cf5e1720aa.svg)
from keras.layers import Input, Dense
from keras.layers import BatchNormalization, Dropout, Flatten, Reshape, Lambda
from keras.models import Model
from keras.objectives import binary_crossentropy
from keras.layers.advanced_activations import LeakyReLU
from keras import backend as K
def create_vae():
models = {}
# Добавим Dropout и BatchNormalization
def apply_bn_and_dropout(x):
return Dropout(dropout_rate)(BatchNormalization()(x))
# Энкодер
input_img = Input(batch_shape=(batch_size, 28, 28, 1))
x = Flatten()(input_img)
x = Dense(256, activation='relu')(x)
x = apply_bn_and_dropout(x)
x = Dense(128, activation='relu')(x)
x = apply_bn_and_dropout(x)
# Предсказываем параметры распределений
# Вместо того, чтобы предсказывать стандартное отклонение, предсказываем логарифм вариации
z_mean = Dense(latent_dim)(x)
z_log_var = Dense(latent_dim)(x)
# Сэмплирование из Q с трюком репараметризации
def sampling(args):
z_mean, z_log_var = args
epsilon = K.random_normal(shape=(batch_size, latent_dim), mean=0., stddev=1.0)
return z_mean + K.exp(z_log_var / 2) * epsilon
l = Lambda(sampling, output_shape=(latent_dim,))([z_mean, z_log_var])
models["encoder"] = Model(input_img, l, 'Encoder')
models["z_meaner"] = Model(input_img, z_mean, 'Enc_z_mean')
models["z_lvarer"] = Model(input_img, z_log_var, 'Enc_z_log_var')
# Декодер
z = Input(shape=(latent_dim, ))
x = Dense(128)(z)
x = LeakyReLU()(x)
x = apply_bn_and_dropout(x)
x = Dense(256)(x)
x = LeakyReLU()(x)
x = apply_bn_and_dropout(x)
x = Dense(28*28, activation='sigmoid')(x)
decoded = Reshape((28, 28, 1))(x)
models["decoder"] = Model(z, decoded, name='Decoder')
models["vae"] = Model(input_img, models["decoder"](models["encoder"](input_img)), name="VAE")
def vae_loss(x, decoded):
x = K.reshape(x, shape=(batch_size, 28*28))
decoded = K.reshape(decoded, shape=(batch_size, 28*28))
xent_loss = 28*28*binary_crossentropy(x, decoded)
kl_loss = -0.5 * K.sum(1 + z_log_var - K.square(z_mean) - K.exp(z_log_var), axis=-1)
return (xent_loss + kl_loss)/2/28/28
return models, vae_loss
models, vae_loss = create_vae()
vae = models["vae"]
Замечание: мы использовали Lambda-слой с функцией, сэмплирующей из
из нижележащего фреймворка, которая явно требует размер батча. Во всех моделях, в которых присутствует этот слой, мы теперь вынуждены передавать именно такой размер батча (то есть в encoder и vae).Функцией оптимизации возьмем Adam или RMSprop, обе показывают хорошие результаты.
from keras.optimizers import Adam, RMSprop
vae.compile(optimizer=Adam(start_lr), loss=vae_loss)
Код рисования рядов цифр и цифр из многообразия
digit_size = 28
def plot_digits(*args, invert_colors=False):
args = [x.squeeze() for x in args]
n = min([x.shape[0] for x in args])
figure = np.zeros((digit_size * len(args), digit_size * n))
for i in range(n):
for j in range(len(args)):
figure[j * digit_size: (j + 1) * digit_size,
i * digit_size: (i + 1) * digit_size] = args[j][i].squeeze()
if invert_colors:
figure = 1-figure
plt.figure(figsize=(2*n, 2*len(args)))
plt.imshow(figure, cmap='Greys_r')
plt.grid(False)
ax = plt.gca()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
n = 15 # Картинка с 15x15 цифр
digit_size = 28
from scipy.stats import norm
# Так как сэмплируем из N(0, I), то сетку узлов, в которых генерируем цифры берем из обратной функции распределения
grid_x = norm.ppf(np.linspace(0.05, 0.95, n))
grid_y = norm.ppf(np.linspace(0.05, 0.95, n))
def draw_manifold(generator, show=True):
# Рисование цифр из многообразия
figure = np.zeros((digit_size * n, digit_size * n))
for i, yi in enumerate(grid_x):
for j, xi in enumerate(grid_y):
z_sample = np.zeros((1, latent_dim))
z_sample[:, :2] = np.array([[xi, yi]])
x_decoded = generator.predict(z_sample)
digit = x_decoded[0].squeeze()
figure[i * digit_size: (i + 1) * digit_size,
j * digit_size: (j + 1) * digit_size] = digit
if show:
# Визуализация
plt.figure(figsize=(15, 15))
plt.imshow(figure, cmap='Greys_r')
plt.grid(None)
ax = plt.gca()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
return figure
Часто в процессе обучения модели требуется выполнять какие-то действия: изменять learning_rate, сохранять промежуточные результаты, сохранять модель, рисовать картинки и т.д.
Для этого в keras есть коллбэки, которые передаются в метод fit перед началом обучения. Например, чтобы влиять на learning rate в процессе обучения, есть такие коллбэки, как LearningRateScheduler, ReduceLROnPlateau, чтобы сохранять модель — ModelCheckpoint.
Отдельный коллбэк нужен для того, чтобы следить за процессом обучения в TensorBoard. Он автоматически будет добавлять в файл логов все метрики и лоссы, которые считаются между эпохами.
Для случая, когда требуется выполнение произвольных функций в процессе обучения, существует LambdaCallback. Он запускает выполнение произвольных функций в заданные моменты обучения, например, между эпохами или батчами.
Будем следить за процессом обучения, изучая, как генерируются цифры из
.from IPython.display import clear_output
from keras.callbacks import LambdaCallback, ReduceLROnPlateau, TensorBoard
# Массивы, в которые будем сохранять результаты, для последующей визуализации
figs = []
latent_distrs = []
epochs = []
# Эпохи, в которые будем сохранять
save_epochs = set(list((np.arange(0, 59)**1.701).astype(np.int)) + list(range(10)))
# Отслеживать будем на вот этих цифрах
imgs = x_test[:batch_size]
n_compare = 10
# Модели
generator = models["decoder"]
encoder_mean = models["z_meaner"]
# Функция, которую будем запускать после каждой эпохи
def on_epoch_end(epoch, logs):
if epoch in save_epochs:
clear_output() # Не захламляем output
# Сравнение реальных и декодированных цифр
decoded = vae.predict(imgs, batch_size=batch_size)
plot_digits(imgs[:n_compare], decoded[:n_compare])
# Рисование многообразия
figure = draw_manifold(generator, show=True)
# Сохранение многообразия и распределения z для создания анимации после
epochs.append(epoch)
figs.append(figure)
latent_distrs.append(encoder_mean.predict(x_test, batch_size))
# Коллбэки
pltfig = LambdaCallback(on_epoch_end=on_epoch_end)
# lr_red = ReduceLROnPlateau(factor=0.1, patience=25)
tb = TensorBoard(log_dir='./logs')
# Запуск обучения
vae.fit(x_train, x_train, shuffle=True, epochs=1000,
batch_size=batch_size,
validation_data=(x_test, x_test),
callbacks=[pltfig, tb],
verbose=1)
Теперь, если установлен TensorBoard, можно следить за процессом обучения.
Вот как этот энкодер восстанавливает изображения:

А вот результат сэмплирования из


Вот так выглядит процесс обучения генерации цифр:

Распределение кодов в скрытом пространстве:

Не идеально нормальное, но довольно близко (особенно, учитывая, что размерность скрытого пространства всего 2).
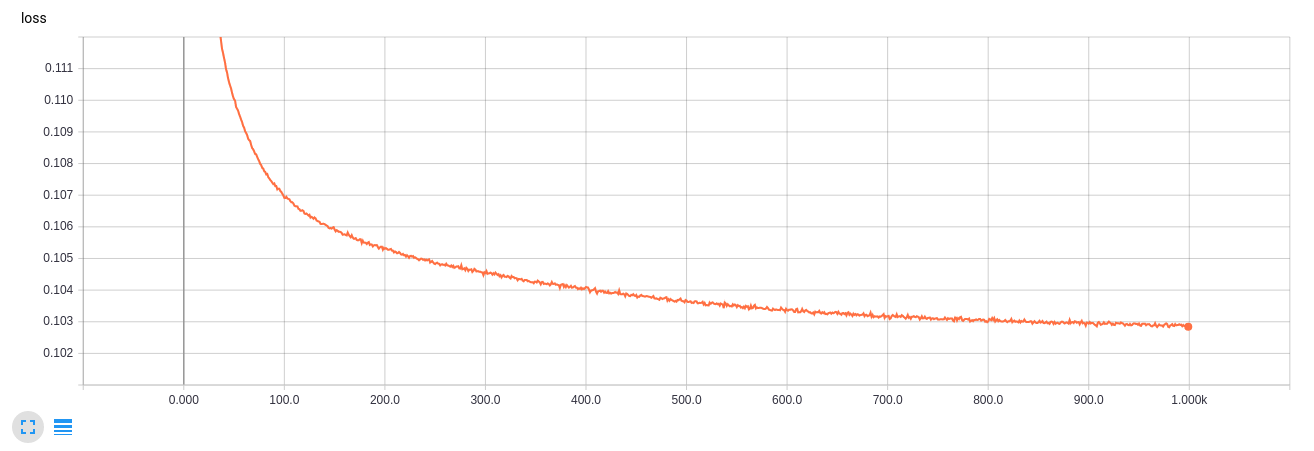
Кривая обучения в TensorBoard
from matplotlib.animation import FuncAnimation
from matplotlib import cm
import matplotlib
def make_2d_figs_gif(figs, epochs, fname, fig):
norm = matplotlib.colors.Normalize(vmin=0, vmax=1, clip=False)
im = plt.imshow(np.zeros((28,28)), cmap='Greys_r', norm=norm)
plt.grid(None)
plt.title("Epoch: " + str(epochs[0]))
def update(i):
im.set_array(figs[i])
im.axes.set_title("Epoch: " + str(epochs[i]))
im.axes.get_xaxis().set_visible(False)
im.axes.get_yaxis().set_visible(False)
return im
anim = FuncAnimation(fig, update, frames=range(len(figs)), interval=100)
anim.save(fname, dpi=80, writer='imagemagick')
def make_2d_scatter_gif(zs, epochs, c, fname, fig):
im = plt.scatter(zs[0][:, 0], zs[0][:, 1], c=c, cmap=cm.coolwarm)
plt.colorbar()
plt.title("Epoch: " + str(epochs[0]))
def update(i):
fig.clear()
im = plt.scatter(zs[i][:, 0], zs[i][:, 1], c=c, cmap=cm.coolwarm)
im.axes.set_title("Epoch: " + str(epochs[i]))
im.axes.set_xlim(-5, 5)
im.axes.set_ylim(-5, 5)
return im
anim = FuncAnimation(fig, update, frames=range(len(zs)), interval=150)
anim.save(fname, dpi=80, writer='imagemagick')
make_2d_figs_gif(figs, epochs, "./figs3/manifold.gif", plt.figure(figsize=(10,10)))
make_2d_scatter_gif(latent_distrs, epochs, y_test, "./figs3/z_distr.gif", plt.figure(figsize=(10,10)))
Видно, что размерности 2 для такой задачи очень мало, цифры очень размытые, а так же в промежутках между хорошими много рваных цифр.
В следующей части посмотрим, как генерировать цифры нужного лейбла, избавиться от рваных, а также как переносить стиль с одной цифры на другую.
Полезные ссылки и литература
Теоретическая часть основана на статье:
[1] Tutorial on Variational Autoencoders, Carl Doersch, 2016, https://arxiv.org/abs/1606.05908
и фактически является ее кратким изложением
Многие картинки взяты из блога Isaac Dykeman:
[2] Isaac Dykeman, http://ijdykeman.github.io/ml/2016/12/21/cvae.html
Подробнее прочитать про расстояние Кульбака-Лейблера на русском можно здесь:
[3] http://www.machinelearning.ru/wiki/images/d/d0/BMMO11_6.pdf
Код частично основан на статье Francois Chollet:
[4] https://blog.keras.io/building-autoencoders-in-keras.html
Другие интересные ссылки:
http://blog.fastforwardlabs.com/2016/08/12/introducing-variational-autoencoders-in-prose-and.html
http://kvfrans.com/variational-autoencoders-explained/
Комментарии (15)

barmaley_exe
25.06.2017 11:44+1Ясно, что распространять ошибки через случайные значения напрямую нельзя
На самом деле можно (формула 6), но лучше от этого не становится.

ex4sperans
26.06.2017 12:22+2Статья хорошая, правда, не особо понравилось, что KL-divergence вводится абсолютно на ровном месте (как в большинстве туториалов по VAE, впрочем), вместо того чтобы естественно появиться при переходе от взятия матожидания по p(z) к q(z | x).

AlexSerbul
28.06.2017 21:35+1Попиарил серию постов у себя в ФБ: https://www.facebook.com/permalink.php?story_fbid=648700375327080&id=100005613702541
kfmn
29.06.2017 17:36А правильно ли я понимаю, что у вас декодер является полностью детерминированным? Т.е по одному z он всегда дает один и тот же x? Если да, то это не полностью VAE, а что-то среднее между ним и обычным автоэнкодером.
В VAE должно учиться распределение p(x|z) и генерация x должна производиться по выбранному z в соответствии с ним.
Или я что-то упустил?barmaley_exe
29.06.2017 23:38Декодер здесь детерминирован в смысле детерминированной генерации параметров распределения p(x|z), на графиках, соответственно, не сами семплы, а распределение, из которого они приходят.
Правда, обучающая выборка не бинаризована (ну это происходит как-то неявно) и используется в сочетании с лог-лоссом, что не очень хорошо.
kfmn
30.06.2017 10:38на графиках, соответственно, не сами семплы, а распределение, из которого они приходят
Я имел в виду, что само распределение в коде никак не фигурирует.
Выход модели — тензор decoded, который просто является выходом последнего dense-слоя.
В посте фигурирует формула P(X|Z) = f(Z) + \epsilon, вроде бы понятно, что decoded это f(Z), но \epsilon осталось за кадром. И на графиках, соответственно, значения f(Z).
При этом в vae_loss должно, согласно теории, использоваться матожидание log P(X|Z) по сэмплам из Q(Z|X), которое должно вычисляться каким-нибудь методом Монте-Карло, а по факту используется бинарная кросс-энтропия между decoded и X, как в обычном автоэнкодере.
P.S. Это был ответ barmaley_exe, не туда ткнул…barmaley_exe
30.06.2017 20:41А какого фигурирования распределения в коде Вы хотите? Распределение на случайную величину, принимающую два значения, задаётся одним числом от 0 до 1 – вероятностью первого исхода. VAE предполагает условную независимость наблюдений X при условии кода Z, поэтому для задания распределения p(X|Z) достаточно задать по одному числу на каждый пиксель в X.
в vae_loss должно, согласно теории, использоваться матожидание log P(X|Z) по сэмплам из Q(Z|X), которое должно вычисляться каким-нибудь методом Монте-Карло, а по факту используется бинарная кросс-энтропия
Бинарная кросс-энтропия и есть логарифм распределения Бернулли, и мат. ожидание по Z действительно берётся с помощью Монте Карло оценки.
kfmn
03.07.2017 10:49Может я и в самом деле чего-то не понимаю, но ведь элементы X не принимают только 2 значения — 0 и 1, у них 256 возможных значений, градаций серого… поэтому о каком распределении Бернулли идет речь, мне неясно.
В формуле для нижней границы лог-правдоподобия (которая оптимизируется) входы энкодера вообще никак не фигурируют. Даже в качестве «таргетов» декодера. Там просто логарифм плотности… Да, для Бернулли это и есть кросс-энтропия (если под p(X|Z) понимается p(X=1|Z)), но это возвращает нас к первому вопросу.
мат. ожидание по Z действительно берётся с помощью Монте Карло оценки
— покажите мне пожалуйста это место в коде, я его в упор не вижу.barmaley_exe
03.07.2017 12:59Может я и в самом деле чего-то не понимаю, но ведь элементы X не принимают только 2 значения — 0 и 1, у них 256 возможных значений, градаций серого… поэтому о каком распределении Бернулли идет речь, мне неясно
Всё так, но кроссэнтропия выводится из логарифма плотности Бернулли, т.е. p(X|Z) – набор бернуллиевских распределений, поэтому для корректности следовало бы бинаризовать входы, поэтому подставлять в лог-плотность небинарные величины не совсем корректно.
В формуле для нижней границы лог-правдоподобия (которая оптимизируется) входы энкодера вообще никак не фигурируют. Даже в качестве «таргетов» декодера
Декодер принимает на вход семплы Z из распределения, параметры которого генерируются энкодером.
покажите мне пожалуйста это место в коде, я его в упор не вижу.
В vae_loss считается выражение под мат. ожиданием с использованием decoded, полученному по семплу из кода, что даёт Монте Карло оценку (с помощью выборки размера 1) всего мат. ожидания.
kfmn
03.07.2017 13:11p(X|Z) – набор бернуллиевских распределений
— вот никак не могу этого осознать. p(X|Z) — это число, оно ОДНО ЕДИНСТВЕННОЕ для всех пикселей X, потому что X — это один многомерный вектор, единый объект… По Вашему выходит, что оно дает одинаковую вероятность быть равным 1 для каждого пикселя картинки, а это очень странно.
Мне значительно ближе трактовка, которую изначально дал автор, что p(X|Z) = f(Z) + \epsilon, или даже просто так: X = f(Z) + \epsilon (математически это более корректно), т.е., если \epsilon, к примеру, центрированный нормальный шум с малой дисперсией, то все сэмплы из распределения p(X|Z) будут нормально распределены вокруг f(Z). Но эта трактовка идет вразрез с вычислением loss'а, об этом я и написал в самом первом комментарии.
Хотелось бы увидеть коммент от автора, который бы нас рассудил…barmaley_exe
03.07.2017 13:51вот никак не могу этого осознать. p(X|Z) — это число, оно ОДНО ЕДИНСТВЕННОЕ для всех пикселей X, потому что X — это один многомерный вектор, единый объект…
Да, и предположения модели таковы, что это число является произведением других чисел, по одному на каждый пиксель: p(X|Z) = ?? p(x? | Z). Каждое множимое должно быть бернуллиевским распределением, иначе бинарная кроссэнтропия не получится.
По Вашему выходит, что оно дает одинаковую вероятность быть равным 1 для каждого пикселя картинки, а это очень странно.
Нет, я такого не говорил. У каждого бернуллиевского распределения свой параметр, генерируемый нейросетью из семпла Z.
X = f(Z) + \epsilon
К сожалению, не всегда существует такое представление. Для бернуллиевских случайных величин, например, такой репараметризации не существует.
ffriend
+1 и буду ждать статью про VAE + GAN. Единственное, что не понял, это:
А как эти понятия вообще связаны в данном случае?
barmaley_exe
Обычный метод наименьших квадратов есть частный случай метода максимума правдоподобия для нормального распределения (соответственно, минимизация абсолютного отклонения (L1 ошибка) эквивалента ММП для распределения Лапласа).
Ну а здесь примерно так же, только мы берём мат. ожидание от правдоподобия p(X|Z) по скрытым переменным Z (надо же нам их откуда-то взять).