Так как базы данных Яндекс.Денег вынуждены хранить массу второстепенной и временной информации, однажды такое решение перестало быть оптимальным. Поэтому в инфраструктуре появился распределенный Data Grid с функциями in-memory базы данных на базе Hazelcast.
В обмен на стабильно высокую производительность и отказоустойчивость мы получили любопытный опыт внедрения, который не во всем повторяет документацию. Под катом вы найдете рассказ о решении проблем Hazelcast при работе под высокой нагрузкой, борьбе со Split Brain, а также впечатления от работы с распределенным хранилищем данных в большой инфраструктуре.
Зачем понадобилась In-Memory база
В Яндекс.Деньгах Hazelcast используется как in-memory база данных и, во вторую очередь, как распределенный кэш для Java-инфраструктуры. При проведении каждого платежа нужно где-то держать массу информации, которая после совершения транзакции уже не нужна, и она должна быть легко доступна. Мы называем такие данные контекстом сессии пользователя и относим к ним источник и способ перевода денег, признак перевода с карты, способ подтверждения перевода и т.п.
Помимо более долгого отклика, неудобно было поддерживать скрипт и хранить лишние данные в бэкапах. Множество разнообразных контекстов платежей, других временных данных, необходимость поддерживать автоматическую очистку, рост нагрузки на БД – все это побудило нас пересмотреть подход к хранению временных данных.
Необходимо было отдельное масштабируемое хранилище с высокой скоростью доступа. Толчком к изменением и поиску более изящного и быстрого хранилища временных данных послужила ранее случившаяся частичная замена на PostgreSQL.
Из ключевых требований к искомому решению были:
Отказоустойчивость как на уровне одного дата-центра (ДЦ), так и между двумя имеющимися.
Минимальный перерасход памяти на хранение данных (memory overhead). В первую очередь решение будет использоваться как хранилище данных, поэтому важно учесть потребление памяти самим хранилищем. В нашем случае получилось распределить некоторые локальные кеши приложений по памяти кластера, что дало выигрыш в десятки раз.
- Стоимость масштабирования. Так как платежный сервис постоянно наращивает мышцы (не всегда линейно), новая БД должна уметь делать это максимально дешево как на продакшене, так и в тестовых или локальных окружениях.
Если разбить три описанных выше критерия детальнее, то вот что должно было уметь искомое ПО:
Высокая скорость чтения/записи по сравнению с обычной БД и небольшой overhead по памяти для хранения данных.
Отказоустойчивость при ошибках на отдельных узлах.
Репликация как внутри дата-центров, так и между ними.
Высокий uptime в работе и возможность конфигурации на лету.
Возможность выставления фиксированного срока жизни объектов – TTL.
Распределенное хранение (шардинг) и балансировка нагрузки на узлы кластера со стороны клиента.
Поддержка мониторинга состояния кластера и возможность тестирования на локальном компьютере.
Простота настройки и поддержания инфраструктуры, гибкость.
- Автоматическое расширение кластера, возможность ограничить объём кэша отдельного типа объектов.
Кроме всего этого, было бы здорово получить в довесок распределенный механизм блокировок, интеграцию с приложениями, кэш на стороне клиента, поддержку протокола Memcache, а также клиенты для JVM, Java, REST, Node.js.
Большей части этих требований удовлетворяют следующие продукты:
Redis – не позволяет указывать max-idle-seconds для записей кэша, выполнять сложную репликацию и ограничивать объём памяти по отдельному типу объектов.
Ehcache big memory – обладает хорошими характеристиками, но предоставляет только платную лицензию.
Gridgain – тоже хорош, но репликация между ДЦ и внутри ДЦ есть только в платной версии.
Infinispan – вроде бы всем хорош, но достаточно сложен в настройке и не содержит коммерческой поддержки. Что еще печальнее, в сети нет информации о поведении в продакшене, а это увеличивает наши риски.
- Hazelcast удовлетворяет всем требованиям и активно используется в продакшене. Более того, именно на эту систему мигрируют с Redis. Из минусов только платный management studio для мониторинга, который уравновешивает API для реализации своей системы мониторинга.
Теперь расскажу подробнее о том, как все настроили и какие выводы сделали, потому что сложности с Hazelcast были связаны как раз с «граблями» конфигурации.
Кластер о 25 нодах
Так как для инфраструктуры Яндекс.Денег необходима локальная и геоизбыточность, мы включили в кластер Hazelcast ноды в двух дата-центрах, как изображено на рисунке ниже.

На схеме изображен кластер Hazelcast, распределенный между двумя удаленными ДЦ.
Всего он состоит из 25 нод, разбитых на две группы. Hazelcast хранит данные в кластере в партициях, распределяя эти партиции между нодами. Объединение партиций в группы позволяет Hazelcast осуществлять бэкапирование партиций между группами. Мы объединили в группы ноды кластера каждого ДЦ и получили простое и прозрачное резервное копирование данных между ДЦ.
Пример конфигурации:
<?xml version="1.0" encoding="UTF-8"?>
<hazelcast xsi:schemaLocation="http://www.hazelcast.com/schema/config hazelcast-config-3.5.xsd"
xmlns="http://www.hazelcast.com/schema/config"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<!-- Настройки сети между нодами кластера -->
<network>
<port auto-increment="false">5701</port>
<join>
<multicast enabled="false"/>
<!-- Включение в кластер нод из двух ДЦ -->
<tcp-ip enabled="true">
<!-- ДЦ 1 -->
<member>192.168.0.0-255</member>
<!-- ДЦ 2 -->
<member>192.168.1.0-255</member>
</tcp-ip>
</join>
</network>
<!-- Настройки групп партиций для взаимного бэкапа -->
<partition-group enabled="true" group-type="CUSTOM">
<member-group>
<!-- сервера ДЦ 1 образуют первую группу партиций -->
<interface>192.168.0.*</interface>
</member-group>
<member-group>
<!-- сервера ДЦ 2 образуют вторую группу партиций -->
<interface>192.168.1.*</interface>
</member-group>
</partition-group>
<properties>
<property name="hazelcast.logging.type">slf4j</property>
<!-- Логирование основных параметров состояние нод -->
<property name="hazelcast.health.monitoring.level">NOISY</property>
<!-- Предоставление всех метрик по JMX -->
<property name="hazelcast.jmx">true</property>
<!-- Отключение хука на SEGTERM по умолчанию -->
<property name="hazelcast.shutdownhook.enabled">false</property>
</properties>
</hazelcast>Блок network отвечает за настройку адресов серверов, которые будут образовывать кластер (в нашей инфраструктуре это отдельные диапазоны под два ДЦ). Partition-group содержит настройки групп партиций, между которыми осуществляется резервное копирование данных. Здесь тоже привязка к двум ДЦ для дублирования данных в обоих.
Что, если перегрузить Hazelcast в 80 раз
После настройки системы и некоторого наблюдения за ней я могу отметить высокую скорость чтения-записи, которая не меняется даже при повышенных нагрузках (данные хранятся в памяти). Но, как и любая другая распределенная система, Hazelcast чувствительна к пропускной способности и отклику сети. Hazelcast – это Java-приложение, а значит, требует тонкой настройки сборщика мусора (Garbage Collector), согласно профилю нагрузки.
Для тонкой настройки обычно обращаешься к документации, но тут с ней явная нехватка. Поэтому мы активно изучали исходный код и так доводили до ума конфигурацию. В целом решение оказалось надежным и справляющимся со своими задачами – это подтвердили и нагрузочные тесты, 80-кратная нагрузка которых никак не отразилась в метриках Hazelcast.
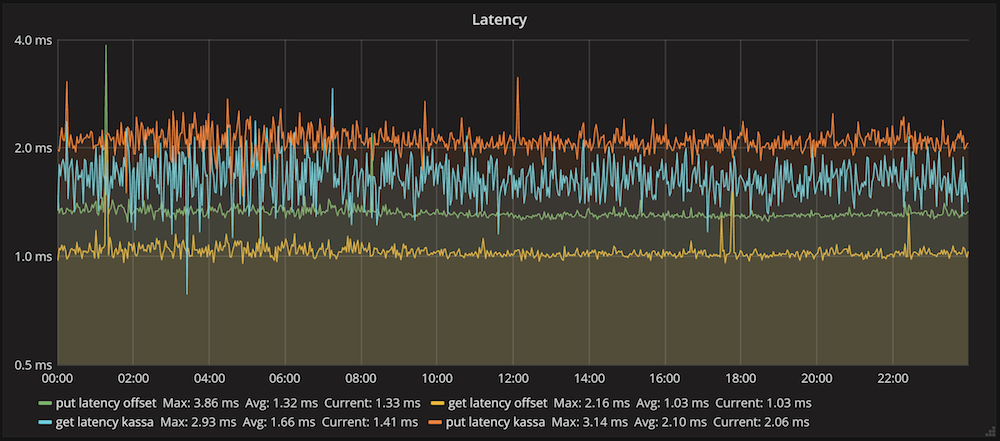
На графике представлено среднее время выполнения операций вставки и получения данных в Hazelcast для одного из клиентов. Среднее время вставки данных составило 2.1 мс, а чтения – 1.6 мс. Эти цифры отражают общую производительность системы: отправка запроса, его выполнение в кластере, сетевое взаимодействие и десериализация ответа.
Но при общем положительном фоне есть несколько областей, на которые стоит обратить особое внимание. Например, мы столкнулись со следующими проблемами при использовании Hazelcast:
Развал кластера и Split Brain, чреватый простоями и нарушением SLA.
Ложные срабатывания политик эвикта данных, которые приводят к потере данных.
Загрузка данных без учета настроек IMap приводит к засорению хранилища.
- Долго выполняются команды в момент изменения структуры кластера. При штатной перезагрузке команды вставки и получения данных тормозят нод кластера.
А раз документации к продукту немного, то подробнее остановлюсь на решениях.
Развал кластера и Split Brain
Ошибки в работе сети происходят постоянно, и Hazelcast их обрабатывает для исключения потери и неконсистентности данных. В нашем случае каждая нода Hazelcast запускается как часть приложения, которое выполняет необходимые настройки и осуществляет мониторинг. Это позволяет интегрировать Hazelcast в инфраструктуру, дает больше гибкости и обеспечивает единые методы поставки, мониторинга, логирования и управления инфраструктурой Яндекс.Денег.
Приложение запускается Spring Boot, который реализует свой classLoader. А между тем самописный classLoader Spring Boot имеет один очень нехороший баг. В случае нештатной ситуации кластер отправляет своим нодам идентификатор исключения для обработки ситуации. Ноды получают сообщения с ошибками и пытаются десериализовать классы исключений. Загрузчик класса Spring Boot не успевает загружать классы при высокой нагрузке и выдает ошибку NoClassDefFoundError.
В конечном итоге кластер может развалиться, преобразовавшись в несколько более мелких самостоятельных «кластеров». У нас такое как раз и произошло под нагрузкой, а в логах были лишь NoClassDefFoundError классов самого Hazelcast. В качестве лечения перед запуском приложения пришлось принудительно распаковывать классы всех библиотек следующей командой:
(springBoot
{requiresUnpack = ['com.hazelcast:hazelcast', 'com.hazelcast:hazelcast-client']}
)Чтобы такого не происходило в будущем, просто отключили в spring boot его сборщик пакетов:
apply plugin: 'spring-boot'
bootRepackage {
enabled = false
}Тогда при запуске приложения необходимо явно выгружать все содержимое .jar при старте:
-Dsun.misc.URLClassPath.disableJarChecking=true \$JAVA_OPTS -cp \$jarfile:$libDirectory/*:. $mainClassNameИспользование стандартного Class Loader исключило ошибки загрузки классов при работе приложения, но потребовало написания кода по сборке пакета для установки.
Ложные срабатывания политик эвикта данных
В нашей инфраструктуре Hazelcast используется преимущественно как хранилище данных, для этого идеально подходит IMap – распределенная Map<Key, Value>. Чтобы уберечь себя от нехватки памяти и исключения OutOfMemory, каждый из предварительно настроенных на стороне Hazelcast экземпляров IMap имеет верхнее ограничение по памяти, а также политики ротации устаревших записей.

Garbage Collector за работой.
Чтобы корректно удалять ненужную информацию, мы используем связку из параметров TTL и MaxIDLE () для ограничения времени жизни данных в этих коллекциях, а также ограничение размера хранимых данных на каждой ноде.
Политик ограничения коллекции по размеру (MaxSizePolicy) несколько:
PER_NODE: Максимальное число записей для каждой JVM.
PER_PARTITION: Максимальное число записей для одной партиции.
USED_HEAP_SIZE: Максимальный размер памяти, который могут занять записи конкретной коллекции – сумма вычисленных размеров каждой записи.
USED_HEAP_PERCENTAGE: То же самое что USED_HEAP_SIZE, только в процентах.
FREE_HEAP_SIZE: Минимальный размер оставшейся выделенной JVM памяти, на основе данных самой JVM.
- FREE_HEAP_PERCENTAGE: то же самое что и FREE_HEAP_SIZE, только в процентах).
Изначально использовали FREE_HEAP_PERCENTAGE, но в итоге переключились на USED_HEAP_PERCENTAGE. Дело в том, что эти похожие по назначению политики работают совершенно по-разному:
FREE_HEAP_PERCENTAGE – начинает очищать данные в коллекциях при Runtime.getRuntime().freeMemory() менее установленного лимита. Допустим, я хочу начать паниковать и удалять данные если осталось менее 10% доступной приложению памяти. Тогда получится постоянное срабатывание этой политики под нагрузкой. И это нормально, потому что так работает Java-машина при выделении и освобождении памяти.
- USED_HEAP_PERCENTAGE – работает совершенно по-другому (и это можно понять, только внимательно изучив исходный код Hazelcast, хорошо, что он есть в свободном доступе), эта политика срабатывает на каждую коллекцию в отдельности, а фактором является рассчитанная стоимость хранимых данных, которая примерно равна реальному значению. Так как это не показания JVM, а рассчитанные данные – график изменения EntryCost не выглядит как кардиограмма, а датчик не срабатывает ошибочно и процесс удаления данных не запускается.
Что касается FREE_HEAP_PERCENTAGE, мы пробовали настраивать GC так, чтобы порог доступной памяти никогда не достигался, но в лучшем случае ничего не менялось. Либо возникали проблемы с OldGen и Stop-the-World.
Использовав USED_HEAP_PERCENTAGE, удалось полностью избавиться от проблем с преждевременным эвиктом данных из коллекций. Одной из особенностей работы эвикта является механизм отбора элементов на удаление (EvictionPolicy: LRU, RANDOM и т.д.). Нам нужен LRU (Last Recently Used), но, с его точки зрения, только что загруженные данные и ни разу не запрошенные данные имеют одинаковый вес, что нужно учитывать.
Загрузка данных без учета настроек IMap
Программный запуск Hazelcast предоставляет свободу в методах его конфигурирования – например, можно сначала запустить ноду кластера, а затем применить настройки хранения. Так делать не стоит, ведь после запуска нода уже включается в механизм шардирования, репликации и бэкапирования данных Hazelcast. Под нагрузкой в эти доли секунды мы можем получить некоторое количество записей в коллекциях, которые имеют настройки эвиктов по умолчанию, т.е. бесконечный TTL в нашем случае. Записи тут же реплицируются и бекапируются на другие ноды.
Пока проблема проявилась, прошло достаточно времени, и в кластере скопился приличный объем балласта. К этим записям не применяются настройки, и они сами никогда не будут удалены, т.к. в Hazelcast свойства каждой записи запекаются в момент сохранения. А найти и удалить все такие записи не совсем тривиальная задача. Вывод: сначала конфигурируем инстанс, затем запускаем.
Долго выполняются команды в момент изменения структуры кластера
Hazelcast адекватно реагирует на выключение одной ноды или даже половины всего кластера, ведь данные реплицируются между всеми участниками. Но штатное поведение для Hazelcast не так хорошо для его клиентов. У клиента есть замечательная настройка smartRouting, которая позволяет ему самостоятельно переключится на другую ноду при потере соединения по умолчанию.
Она работает, но недостаточно быстро и все запросы на добавление или получение данных приходят на другие ноды кластера с предварительной установкой соединения. Задержки на установку соединения и операции с данными под нагрузкой не укладываются в таймауты клиентов (мы ограничили время операций 400 мс), и проводимые ими операции прерываются. Поэтому важно научить клиентскую часть обрабатывать такие ошибки и пытаться повторить операцию.
В свою очередь, проводить операции без выставленного таймаута тоже не лучшая идея, ведь по умолчанию он составляет 60 секунд – хватит ли у клиента терпения? Всех этих проблем можно избежать при штатной перезагрузке ноды Hazelcast – достаточно на клиенте не использовать smartRouting, а перед остановкой ноды остановить все её клиенты.
Мониторинг кластера
У Hazelcast есть собственное средство мониторинга – Management Center, доступный в лицензии Enterprise. Но все метрики доступны по JMX и их можно собирать, например, с помощью Zabbix. Так в нашей сети и мониторится занимаемая приложением память и, при необходимости, любая другая доступная метрика.
Тем не менее Zabbix беден в части возможностей по составлению запросов, построению и оформлению графиков, поэтому в большей степени он годится как источник данных для Grafana. Для мониторинга размеров коллекций, hit rate, latency их значения пересылаются в Graphite из компонента, управляющего запуском ноды Hazelcast.
Временные данные требуют автоматической очистки, и за ней тоже нужно приглядывать. Поэтому в логи попадает каждое добавление, удаление или эвикт данных из коллекций. Оперативные логи доступны в Kibana – Адель об этом недавно рассказал – и отлично подходят для расследования инцидентов или отслеживания эффективности кэшей. Такое логирование можно реализовать с помощью MapListener, что полностью покрывает потребности нашей команды в мониторинге кластера.
Перезапуск нод кластера
Для того чтобы сделать процесс перезапуска всех нод кластера максимально безболезненным для системы, мы применяем следующий подход:
Каждое изменение настроек Hazelcast – настройку новых или существующих коллекций, мониторинг, выделение памяти приложению – выполняется в рамках процесса релиза кластера как компонента нашей системы.
Для автоматизации процесса перезапуска всех нод с новыми настройками написан скрипт, который на основе данных мониторинга ноды принимает решение о возможности ее перезапуска с новой версией. У Hazelcast есть PartitionService с информацией о состоянии партиций кластера, включая информацию о бэкапах всех данных, isLocalMemberSafe(). Этот флаг скрипт интерпретирует как признак возможности безопасного перезапуска ноды – все ее данные могут быть восстановлены из бэкапов других нод.
- Сам по себе флаг isLocalMemberSafe() не гарантирует, что в следующую миллисекунду все не развалится. Поэтому мы запускаем Hazelcast со следующим параметром:
<property name="hazelcast.shutdownhook.enabled">false</property>
Это позволяет отключить Terminate (жесткое отключение) ноды при получении сигнала SEGTERM. Скрипт посылает SEGTERM ноде, контекст приложения закрывается с вызовом Graceful Shutdown.
Такой способ гарантирует штатный вывод ноды из кластера, ожидающего полной синхронизации данных перед выключением ноды. Процесс релиза кластера у нас занимает около часа в полуавтоматическом режиме, причем ввод ноды в кластер происходит в среднем за 5 секунд.
Потеря половины нод кластера
Интересный график я заметил одним добрым утром. Служба эксплуатации проводила учения по отключению одного ДЦ, и в какой-то момент кластер Hazelcast остался без половины своих нод. Все данные были успешно восстановлены из бэкапов группы партиций, а уменьшение количества нод в кластере позитивно сказалось на скорости работы.

При полном выключении одного ДЦ Hazelcast репартиционировал данные на оставшиеся ноды, а скорость работы возросла почти в 2 раза.
Возникает вопрос: почему бы нам не оставить в 2 раза меньше нод? Здесь как раз пространство для исследований – будем подбирать конфигурацию, которая обеспечит максимальную скорость без вреда для отказоустойчивости.
Стоило ли оно того
Распределенная in-memory база позволила организовать удобное и «красивое» хранение массы временной информации. Кроме того, архитектура получилась не только производительной, но и неплохо масштабируемой. Но я бы поостерегся советовать подобные распределенные системы всем подряд, так как они довольно сложны в поддержке, преимущества которой можно ощутить только на действительно большом потоке данных.
Кроме того, по результатам проекта мы научились не доверять решениям только на основе их популярности (привет Spring Boot), а также тщательно испытывать новый продукт перед внедрением. Но даже после всех описанных в статье настроек придется что-то докручивать и менять: например, мне еще предстоит познать «радость» обновления с Hazelcast 3.5.5 до свежей версии 3.8. Соль в том, что версии обратно несовместимы и потому острые ощущения гарантированы. Но об этом я расскажу как-нибудь в другой раз.
Комментарии (16)

doom369
06.07.2017 11:31В свое время отказался от Hazelcast так как:
1. При старте хацелькаст отжирал около 50 МБ хипа; А мы ранимся на low-end VM, где всего есть 250мб;
2. Внутри, на то время, был сложный и не очень хороший код со слипами в местах записи (если мне не изменяет память)…
3. Довольно большая джарка, сейчас уже 5мб, смотреть пункт 1.

enflout
07.07.2017 10:23Антон, спасибо за статью. Читали всей командой.
1) А вы подкладываете в Hazelcast свои jar-ы (domain-классы) для сериализации/десериализации/выборке по индексу? Удается ли в случае изменений в таких классах обновляться без остановки кластера?
У нас сейчас не получается подложить jar на каждую ноду по очереди (hazelcast начинает сыпать исключениями). Мы пробовали вместо jar-ов в classpath работать через Portable, но очень много однообразного кода readPortable/writePortable/portableFactory, вернулись на Java-сериализацию. Когда нужно переподложить jar-ы — останавливаем кластер. В 3.8 заявлено «User Code Deployment: Load your new classes to Hazelcast IMDG members dynamically without restarting all of them». Но интересно, как при таких высоких SLA как у Яндекс-денег, вы на 3.5 справляетесь с обновлениями этих jar-ов без остановки кластера? Или обходитесь стандартными Java-классами?
2) Как вы настроили параметры
hazelcast.client.max.no.heartbeat.seconds,
hazelcast.heartbeat.interval.seconds,
hazelcast.client.invocation.timeout.seconds
и другие таймауты
?
По дефолту они выставлены в довольно большие значения и при потере ноды hazelcast уходит в себя. В статье видел упоминания про 400 мс ограничение на клиенте. Получается, кластер у вас тормозит, когда нода выпадает, но со стороны клиента вы как-то в итоге повторяете ту же самую операцию?
3) Можете рассказать подробнее про потерю нод, датацентра? Как быстро кластер выкидывает ноду и продолжает работать? Как вы тестировали? (про потерю датацентра видел, но интересует с точки зрения простоев и SLA).
4) Сколько памяти вы даете каждой ноде? Где-то видел рекомендацию про не более 4Гб.
antonkislitsyn
07.07.2017 10:38А вы подкладываете в Hazelcast свои jar-ы (domain-классы) для сериализации/десериализации/выборке по индексу? Удается ли в случае изменений в таких классах обновляться без остановки кластера?
Так как мы запускаем каждую ноду программно как часть java-приложения, то храним доменные объекты прямо в коде этого компонента. Однако, это не широко распространенный кейс из-за описанных вами сложностей. Фактически мы не меняем доменные объекты.
Основной объем информации хранится в виде IMap<String, String>, в качестве ключа — уникальный идентификатор, значение — POJO сериализованный в JSON. Сериализацией/десериализацией управляет клиент, обратная совместимость реализуется очень просто. В результате никаких простоев
antonkislitsyn
07.07.2017 13:04Можете рассказать подробнее про потерю нод, датацентра? Как быстро кластер выкидывает ноду и продолжает работать? Как вы тестировали? (про потерю датацентра видел, но интересует с точки зрения простоев и SLA).
Весь процесс выключения ноды занимает ~500мс, из них ~30 мс штатный вывод из кластера. Бывают исключения, когда весь процесс затягивается до 5 секунд, что связано с Gracefull Shutdown.
Выкидывание по причине потери связи с одной из нод бывает крайне редко, обычно укладывается в таймауты.
Время за которое кластер восстанавливает нормальную работу хорошо видно в Kibana — это период времени когда был всплекс ошибок чтения/записи в Hazelcast. При нештатном выкидывании ноды из кластера в логах наблюдаются единичные ошибки в течении максимум 1 секунды
antonkislitsyn
07.07.2017 13:40Сколько памяти вы даете каждой ноде? Где-то видел рекомендацию про не более 4Гб.
512*25 серверов=12.5Gb. Нам хватает с кратным запасом. Кластер расположен на серверах рядом с другими сервисами. Если вам нужна другая конфигурация, то нужно просто провести нагрузочное тестирование, подтюнить GC.
Вот тест с 2Тб — https://www.youtube.com/watch?v=DozGQMHRoZI
antonkislitsyn
07.07.2017 11:42Как вы настроили параметры
hazelcast.client.max.no.heartbeat.seconds,
hazelcast.heartbeat.interval.seconds,
hazelcast.client.invocation.timeout.seconds
и другие таймауты
?
По дефолту они выставлены в довольно большие значения и при потере ноды hazelcast уходит в себя. В статье видел упоминания про 400 мс ограничение на клиенте. Получается, кластер у вас тормозит, когда нода выпадает, но со стороны клиента вы как-то в итоге повторяете ту же самую операцию?
Значения таймаутов клиента установлены по умолчанию. Таймаутом управляет конкретный бизнес процесс. Например, задача запускается из асинхронной очереди и пытается получить данные из Hazelcast с помощью IMap::getAsync(key).get(operationTimeout.getMillis(), TimeUnit.MILLISECONDS)), где operationTimeout — параметр конфигурации клиентского приложения, согласно требованиям к нему. Если Hazelcast ушел в себя, компонент ушел в себя, сеть мигнула или пожар, то ничего страшного — через operationTimeout задача прервется и через некоторое время запустится вновь.
В случае синхронных операций, которым требуется сделать вызов Hazelcast, прерывание операции так же обрабатывает клиент запустивший эту операцию. Например, пришел http запрос и мы пытаемся получить из Hazelcast кэш данных, не дождавшись данных за operationTimeout отдаем клиенту ошибку, который может сделать повторный вызов для исключения единичных сбоев.
dsukhoroslov
11.07.2017 17:15>>Служба эксплуатации проводила учения по отключению одного ДЦ, и в какой-то момент кластер Hazelcast остался без половины своих нод. Все данные были успешно восстановлены из бэкапов группы партиций, а уменьшение количества нод в кластере позитивно сказалось на скорости работы.
Поскольку SmartRouting у Вас отключен, запросы с клиента идут не прямо на ноду, содержащую данные, а на случайную ноду кластера. Могут попасть и в другой ДЦ, затем запрос будет перенаправлен в «правильный» ДЦ. Запросы между ДЦ, обычно, гораздо медленнее запросов внутри одного ДЦ. Поэтому, когда один ДЦ отключился, все стало ~ в два раза быстрее.
И еще интересно: у Вас после восстановления данных из бэкапов новые бэкапы создались внутри одного ДЦ? Мне кажется, их не должно б быть. Тогда и скорость put'ов еще возрастет…antonkislitsyn
11.07.2017 17:32Поскольку SmartRouting у Вас отключен, запросы с клиента идут не прямо на ноду, содержащую данные, а на случайную ноду кластера. Могут попасть и в другой ДЦ, затем запрос будет перенаправлен в «правильный» ДЦ. Запросы между ДЦ, обычно, гораздо медленнее запросов внутри одного ДЦ. Поэтому, когда один ДЦ отключился, все стало ~ в два раза быстрее
При отключенном smartRouting клиент подключается не к рандомной ноде кластера, а к той, что прописана в настройках подключения. Далее получение данных отдано на откуп Hazelcast. Клиента одного ДЦ подключаются к нодам того же ДЦ.
В обоих схемах не избежать походов за данными в другой ДЦ. Да, на графике виден эффект от исключения похода в другой ДЦ
antonkislitsyn
11.07.2017 17:33И еще интересно: у Вас после восстановления данных из бэкапов новые бэкапы создались внутри одного ДЦ? Мне кажется, их не должно б быть. Тогда и скорость put'ов еще возрастет…
Да, бэкапы создаются в рамках оставшейся части нод одной группы партиций. У нас это четко видно на графиках мониторинга количества элементов в коллекциях и количества забэкапленных элементов коллекций — после отключения одного ДЦ их количество не изменяется
gAmUssA
Спасибо за отличную статью.
Т.к. работаю в Hazelcast, возьмусь прокомментировать пару моментов.
Буду комментировать по ходу чтения статьи.
Обычно, из-за высокой latency между датацентрами, мы не рекомендуем размазывать кластер Hazelcast на множестно датацентром. есть WAN Replication, но как и у многих конкурентов она входит в платный пакет.
Так же, хочу отметить, что в более новых версиях появился механизм quorum, который позволяет настроить CP vs AP поведение для конкретных структур данных.
По поводу
NoClassDefFoundError. У Hazelcast много чего разного лежит вMETA-INF/services.Не все
uberjarупаковщики правильно приносят это все.В общем случае, хотелось бы поглядеть на полный stacktrace, но я тут вижу вы как-то это полечили.
Начиная с 3.7, eviction был очень сильно переработан. Об алгоритме можно почитать тут и тут.
Пусть вас не смущает JCache в последнем линке. с 3.7 JCache и IMap используют унифицированный механизм.
Так же в 3.7, появились Custom Eviction Policies — секция Custom Eviction Policy, так что можно реализовать что-то свое если LRU или LFU не подходят (там есть пример).
так делать нельзя. не то, чтобы я запрещаю, просто в этом случае ваш конфиг не применится, а будут использованы defaults.
ваш вывод очень правильный.
В любом случае, все ноды кластера должны иметь одинаковый конфиг.
Есть крутилки и для этого.
Вот тут можно почитать, что можно (и нужно крутить, для обработки внештатных ситуаций).
Тут все правильно сказал.
Management Center, кстати, умеет отдавать агрегированную статистику через JMX.
Можно заставить, MC собирать статистику по Hazelcast кластеру и отдавать ее в Zabbix или Prometheus.
Я бы не рекомендовал. Лучше поглядите на Diagnostics — фича, highly inspired by Metrics framework.
вот только вчера выкатили 3.9-EA (early access) с новой фичей про добавление конфигураций динамически.
Можно пробовать!
Вот тут сейчас обидно было ©
Начиная с 3.6, клиенты и ноды начали общаться по стандартному протоколу Hazelcat Open Client Protocol, что позволяет обновлять минорные версии нод и клиентов в разное время.
В 3.8 EE (Enterprise Edition) появилась возможность обновлять минорные версии нод «на горячую», т.е. обновлять 3.8 -> 3.9, 3.9->3.10 и тд.
Исходя из всего выше описанного, обновление на 3.8 очень рекомендовано.
В любом случае, буду рад ответить на любые вопросы, если такие появятся.
antonkislitsyn
Наш опыт показывает что latency просаживается не существенно. Не нашел в документации информацию по WAN Replication — поддерживается ли репликация между двумя разными версиями Hazelcast?
antonkislitsyn
Проблема с ложным срабатыванием FREE_HEAP_PERCENTAGE воспроизводится на 3.8. Проблема описана в статье — политика срабатывает при достижении размера занимаемой памяти всем приложением. На графике «Garbage Collector за работой» показано как происходит выделение и освобождение памяти — видно, что график много раз за день пересекает границу в 75% от доступной памяти. Это приводит к срабатыванию FREE_HEAP_PERCENTAGE=25%, хотя данных в коллекциях не так много. Я бы не назвал это ошибкой в Hazelcast, скорее — особенностью реализации. А вот за реализацией нужно идти в исходный код, в документации про реализацию ничего не сказано
antonkislitsyn
Спасибо за рекомендацию. Однако, мы логируем с помощью MapListener не статистику, а события по изменениям данных в коллекциях. Например, добавления с конкретным значением key, эвикты, удаления.
Статистику по каждой коллекции мы мониторим на основе данных IMap::LocalMapStats, отправляя их напрямую в Graphite. Таким образом получаем графики с latency, которые присутствуют в статье
antonkislitsyn
Позволяет добавлять только новые конфигурации на горячую. Основной кейс у нас — изменение текущих конфигураций. Программное добавление конфигураций подразумевает реализацию динамического изменения конфигов в компоненте, запускающем Hazelcast ноду. Это усложняет разработку, тестирование и поддержку компонента. Гораздо прозрачней для эксплуатации безопасно выключить ноду и запустить с новыми конфигами
antonkislitsyn
Соглашусь что документация хорошая, актуальная и позволяет получить информацию и рекомендации по продукту. Но лучшая документация — исходный код. Он у вас хорош, действительно. Прочитал код и сразу все понятно как работает
antonkislitsyn
В первую очередь собираемся обновляться до 3.8 как раз для этого. Можете порекомендовать варианты миграции с предыдущих версий? Мы сейчас в процессе изобретения велосипеда для миграции без простоя (: