
Всем привет! Меня зовут Александр, я руковожу отделом Data Team в Badoo. Сегодня я расскажу вам о том, как мы выбирали оптимальный алгоритм для вычисления квантилей в нашей распределённой системе обработки событий.
Ранее мы рассказывали о том, как устроена наша система обработки событий UDS (Unified Data Stream). Вкратце – у нас есть поток гетерогенных событий, на котором нужно в скользящем окне проводить агрегацию данных в различных разрезах. Каждый тип события характеризуется своим набором агрегатных функций и измерений.
В ходе развития системы нам потребовалось внедрить поддержку агрегатной функции для квантилей. Более подробно о том, что такое перцентили и почему они лучше представляют поведение метрики, чем min/avg/max, вы можете узнать из нашего поста про использование Pinba в Badoo. Вероятно, мы могли бы взять ту же имплементацию, что используется в Pinba, но стоит принять во внимание следующие особенности UDS:
- Вычисления «размазаны» по Hadoop-кластеру.
- Дизайн системы подразумевает группировку по произвольному набору атрибутов. Это означает, что количество метрик вида «перцентиль» исчисляется миллионами.
- Поскольку вычисления производятся с использованием Map/Reduce, то все промежуточные вычисления агрегатных функций должны обладать свойством аддитивности (мы должны иметь возможность «сливать» их с разных нод, производящих вычисления независимо).
- Pinba и UDS имеют различные языки имплементации – C и Java соответственно.
Критерии оценки
Исходя из этих архитектурных особенностей, мы выдвинули ряд параметров, по которым будем оценивать алгоритмы расчёта квантилей:
Точность вычисления
Мы решили, что нас устроит точность вычислений вплоть до 1,5%.
Время выполнения
Нам важно минимизировать период времени от возникновения события до визуализации его квантилей на графиках. Этот фактор складывается из трёх других:
- время «математики» (стадия Map) – накладные расходы на инициализацию структур данных и добавление данных в них;
- время сериализации – для того чтобы произвести слияние двух структур данных, они должны быть сериализованы и переданы по сети.
- время слияния (стадия Reduce) – накладные расходы на слияние двух структур данных, вычисленных независимо.
Объём памяти
В нашей системе обрабатываются миллионы метрик, и нам важно следить за разумным использованием вычислительных ресурсов. Под памятью мы подразумеваем следующее:
- RAM – объём, занимаемый структурами данных для квантилей.
- Shuffle – так как расчёт производится с использованием Map/Reduce, то неизбежен обмен промежуточными результатами между нодами. Для того, чтобы это было возможно, структура данных должна быть сериализована и записана на диск/в сеть.
Также мы выдвигаем следующие условия:
Типы данных
Алгоритм должен поддерживать вычисления для неотрицательных величин, представленных типом double.
Язык программирования
Должна присутствовать имплементация на Java без использования JNI.
Участники исследования

Naive
Чтобы иметь некий референс для сравнения, мы написали реализацию «в лоб», которая хранит все входящие значения в double[]. При необходимости вычисления квантиля массив сортируется, вычисляется ячейка, соответствующая квантилю, и берётся её значение. Слияние двух промежуточных результатов происходит путём конкатенации двух массивов.
Twitter Algebird
Это решение было найдено нами в ходе рассмотрения алгоритмов, заточенных под Spark (используется в основе UDS). Библиотека Twitter Algebird предназначена для расширения алгебраических операций, доступных в языке Scala. Она содержит ряд широко используемых функций ApproximateDistinct, CountMinSketch и, помимо всего прочего, реализацию перцентилей на основании алгоритма Q-Digest. Математическое обоснование алгоритма вы можете найти здесь. Вкратце структура представляет собой бинарное дерево, в котором каждый узел хранит некоторые дополнительные атрибуты.
Ted Dunning T-Digest
Библиотека представляет собой улучшение вышеупомянутого алгоритма Q-Digest с заявленным меньшим потреблением памяти, улучшенной производительностью и более высокой точностью.
Airlift Quantile Digest
На этот продукт мы наткнулись при реверс-инжиниринге распределённого SQL-движка Facebook Presto. Было несколько удивительно увидеть реализацию квантилей в REST-фреймворке, но высокая скорость работы и архитектура Presto (схожая с Map/Reduce) подтолкнули нас к тому, чтобы протестировать это решение. В качестве математического аппарата используется опять же Q-Digest.
High Dynamic Range (HDR) Histogram
Это решение являлось идейным вдохновителем реализации перцентилей в Pinba. Его отличительной особенностью является то, что при инициализации структуры необходимо знать верхний диапазон данных. Весь диапазон значений разбивается на N-ное количество ячеек, и при добавлении мы инкрементируем значение в какой-то из них.
Методика проведения теста

Качественная оценка
Каждое из рассматриваемых программных решений было обёрнуто некоторой прослойкой (моделью) (чтобы адаптировать его под фреймворк для тестирования). Перед проведением performance-тестов для каждой модели были написаны unit-тесты для проверки её достоверности. Эти тесты проверяют, что модель (её нижележащее программное решение) может выдавать квантили с заданной точностью (проверялись точности 1% и 0,5%).
Performance-тесты
Для каждой из моделей были написаны тесты с использованием JMH. Они были разделены на категории, про каждую из которых я расскажу подробно. Не буду «засорять» пост сырыми выводом от JMH – лучше сразу буду визуализировать в виде графиков.
Raw-тест
В этом тесте мы измеряем производительность структур данных на вставку, то есть производятся замеры времени, требуемого на инициализацию структуры и на заполнение её данными. Также мы рассмотрим, как изменяется это время в зависимости от точности и количества элементов. Измерения производились для последовательностей монотонно возрастающих чисел в диапазонах 10, 100, 1000, 10000, 100000, 1000000 при погрешности вычисления 0,5% и 1%. Вставка производилась пачкой (если структура поддерживает) или поэлементно.
В результате мы получили следующую картину (шкала ординат логарифмическая, меньшие значения – лучше):
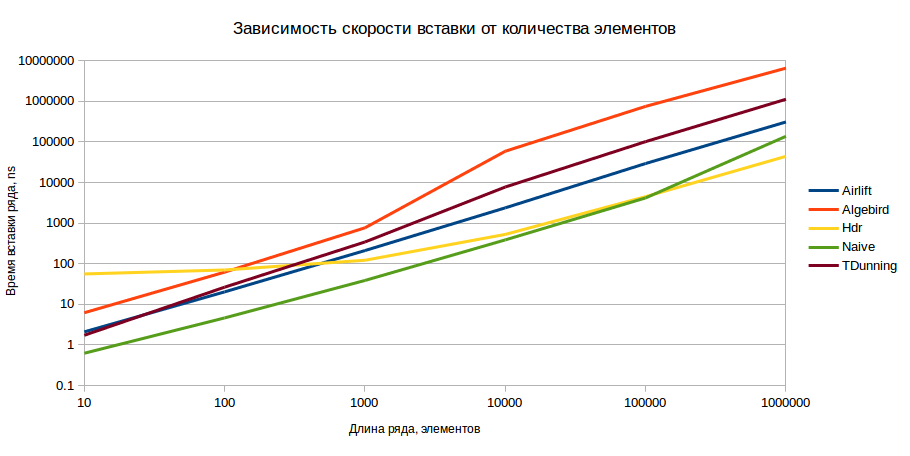
Результаты приведены для точности 1%, но для точности 0,5% картина принципиально не меняется. Невооружённым глазом видно, что с точки зрения вставки HDR является оптимальным вариантом при условии наличия более чем 1000 элементов в модели.
Volume test
В этом тесте мы производим замеры объёма, занимаемого моделями в памяти и в сериализованном виде. Модель заполняется последовательностями данных, затем производится оценка её размера. Ожидается, что лучшей окажется модель с меньшим объёмом занимаемой памяти. Замер производится с использованием SizeEstimator из Spark.

Как видно, при незначительном количестве элементов HDR проигрывает прочим имплементациям, однако имеет лучшую скорость роста в дальнейшем.
Оценка сериализованного размера производилась путём сериализации модели через Kryo, являющийся де-факто стандартом в области сериализации. Для каждой модели был написан свой сериализатор, который преобразует её максимально быстрым и компактным образом.

Абсолютным чемпионом вновь является HDR.
Map/Reduce-тест
Этот тест наиболее полно отражает поведение системы в боевой ситуации. Методика теста следующая:
- Предсоздаётся десять моделей, содержащих n-ное количество значений.
- Производится их слияние (эмуляция map-side combine).
- Полученное значение сериализуется и десериализуется десять раз (эмуляция передачи по сети с разных воркеров).
- Десериализованные модели сливаются (эмуляция финальной reduce-стадии).
Результаты теста (меньшие значения – лучше):
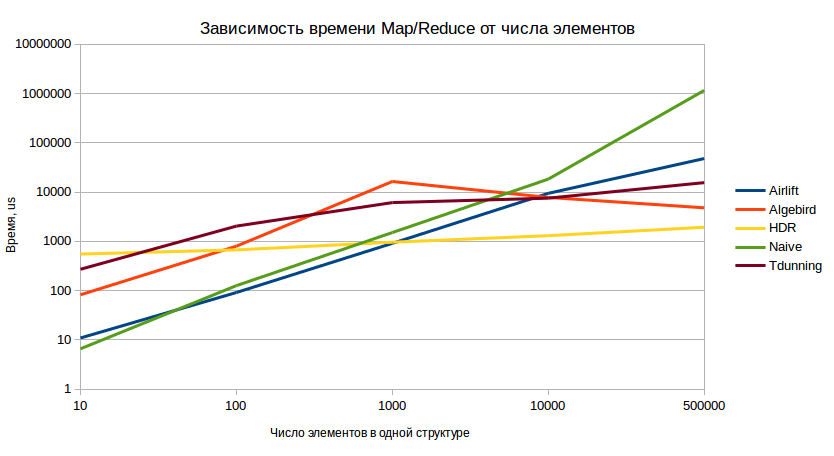
И в данном тесте мы снова отчётливо видим уверенное доминирование HDR в долгосрочной перспективе.
Анализ результатов
Проанализировав результаты, мы пришли к выводу, что HDR является оптимальной имплементацией на большом количестве элементов, в то время как на моделях с небольшим количеством данных есть более выгодные реализации. Специфика агрегации по многим измерениям такова, что одно физическое событие влияет на несколько ключей агрегации. Представим себе, что одно событие EPayment должно быть сгруппировано по стране и полу пользователя. В этом случае мы получаем четыре ключа агрегации:

Очевидно, что при обработке потока событий ключи с меньшим числом измерений будут иметь большее число значений для перцентилей. Статистика использования нашей системы даёт нам следующую картину:

Эта статистика позволила нам принять решение о необходимости посмотреть на поведение метрик с большим количеством измерений. В результате мы выяснили, что 90 перцентиль числа событий на одну метрику (то есть нашу тестовую модель) находится в пределах 2000. Как мы видели ранее, при подобном количестве элементов есть модели, которые ведут себя лучше, чем HDR. Так у нас появилась новая модель – Combined, которая объединяет в себе лучшее от двух миров:
- Если модель содержит менее n элементов, используются алгоритмы Naive модели
- При превышении порога n инициализируется модель HDR.
Смотрим результаты этого нового участника!



Как видно из приведённых графиков, Combined-модель действительно ведёт себя лучше HDR на малой выборке и сравнивается с ней при увеличении числа элементов.
Если вас интересуют код исследования и примеры API рассмотренных алгоритмов, вы можете найти всё это на GitHub. И если вы знаете реализацию, которую мы могли бы добавить к сравнению, напишите о ней в комментариях!
zuborg
HDR выглядит явным фаворитом уже из описания — плоская (недревовидная) структура данных, вычисление всех нужных перцентилей (например, 25, 50, 95, 99, да вообще любых, а не только один 95) одновременно, регулируемый баланс точность/память, практически мгновенная агрегация (сложить списки поэлементно)…
Быстрая синхронизация для SMP систем (нет необходимости использовать отдельный мьютекс, можно применять CAS на сам счетчик, или вообще атомарный инкремент, если такой поддерживается процессором).
Даже логарифм значения не обязательно вычислять, если работать с бинарным представлением float-а — в старших битах мантиссы фактически записан индекс нужной ячейки (относительно группы ячеек, покрывающей диапазон [1… 2) ), правда, тогда вычислять сам перцентиль будет сложнее, т.к. проиндексированные таким образом ячейки будут сгруппированы в логарифмической шкале неравномерно.
И самостоятельно реализуется весьма легко, при необходимости, алгоритм абсолютно прямой.
alexkrash
Ваши замечания вполне справедливы, однако я не был бы столь категоричен насчёт этого:
zuborg
1. Ну, вам бесполезны, но в целом для многотредовых програм собирать статсы по перцентилю сильно проще для HDR, чем заниматься обходом деревьев и блокировать их изменения. Например, полезно глянуть перцентили по сетевым задержкам, но там такие скорости…
2. Конкретно в этой имплементации пошли по легкому пути, но никто не мешает сделать автоподстройку, как верхнего, так и нижнего диапазона. Часть крайних данных может потеряться, да, но для приближенных вычислений это допустимо.