 Предположим, что я дал вам относительно длинную строку, а вы хотите удалить из неё все пробелы. В ASCII мы можем определить пробелы как знак пробела (‘ ’) и знаки окончания строки (‘\r’ и ‘\n’). Меня больше всего интересуют вопросы алгоритма и производительности, так что мы можем упростить задачу и удалить все байты со значениями меньшими либо равными 32.
Предположим, что я дал вам относительно длинную строку, а вы хотите удалить из неё все пробелы. В ASCII мы можем определить пробелы как знак пробела (‘ ’) и знаки окончания строки (‘\r’ и ‘\n’). Меня больше всего интересуют вопросы алгоритма и производительности, так что мы можем упростить задачу и удалить все байты со значениями меньшими либо равными 32.В предыдущией статье, где я задавал вопрос об удалении пробелов на скорость, лучшим ответом было использование векторизации с помощью 128-битных регистров (SSE4). Оно оказалось в 5-10 раз быстрее подхода в лоб.
Очень удобно, что во всех процессорах имеются 128-битные векторные регистры, также как в процессорах x64. Неужели процессоры ARM могут работать настолько же быстро, как процессоры x64?
Давайте сначала рассмотрим быструю скалярную реализацию:
size_t i = 0, pos = 0;
while (i < howmany) {
char c = bytes[i++];
bytes[pos] = c;
pos += (c > 32 ? 1 : 0);
}Она удаляет все символы со значениями меньшими либо равными 32 и записывает данные обратно. Работает очень быстро.
Можно ли добиться ещё большей скорости с векторными инструкциями?
На процессорах x64 лучшей стратегией будет захватить 16 байт данных, быстро сравнить на предмет пустых символов, затем извлечь значение маски (или bitset), созданное из 16 бит, один бит на символ, где каждый бит соответствует значению, найден пустой символ или нет. Такой битсет быстро вычисляется на процессоре x64, поскольку там есть специальная инструкция (
movemask). На процессорах ARM такой инструкции нет. Можно эмулировать movemask с помощью нескольких инструкций.Итак, мы не можем обработать данные на ARM так, как на процессорах x86. Что можно предпринять?
Как это делает SS4, мы можем быстро проверить, что значения байтов меньше или равны 32, и так определить пустые символы:
static inline uint8x16_t is_white(uint8x16_t data) {
const uint8x16_t wchar = vdupq_n_u8(' ');
uint8x16_t isw = vcleq_u8(data, wchar);
return isw;
}Теперь мы можем быстро проверить любой из 16 символов, является он пустым, используя всего две инструкции:
static inline uint64_t is_not_zero(uint8x16_t v) {
uint64x2_t v64 = vreinterpretq_u64_u8(v);
uint32x2_t v32 = vqmovn_u64(v64);
uint64x1_t result = vreinterpret_u64_u32(v32);
return result[0];
}Это наталкивает на мысль о полезной стратегии. Вместо сравнения символов по одному, можно сравнить все 16 символов сразу. Если ни один из них не является пустым, то просто копируем 16 символов обратно на вход и идём дальше. В противном случае скатываемся к медленному скалярному подходу, но с дополнительным преимуществом, что здесь не нужно повторять сравнение:
uint8x16_t vecbytes = vld1q_u8((uint8_t *)bytes + i);
uint8x16_t w = is_white(vecbytes);
uint64_t haswhite = is_not_zero(w);
w0 = vaddq_u8(justone, w);
if(!haswhite) {
vst1q_u8((uint8_t *)bytes + pos,vecbytes);
pos += 16;
i += 16;
} else {
for (int k = 0; k < 16; k++) {
bytes[pos] = bytes[i++];
pos += w[k];
}
}Преимущества такого подхода проявятся сильнее всего, если вы ожидаете много потоков по 16 байт без пустых символов. В принципе, такое справедливо для многих приложений.
Я написал бенчмарк, в котором попытался оценить, сколько займёт удаление пробелов, по одной штуке за раз, на основе входных данных с небольшим количеством пустых символов, разбросанных случайным образом. Исходный код доступен, но для запуска вам нужен процессор ARM. Я запускал его на 64-битном ARM-процессоре (сделанном из ядер A57). У Джона Регера есть ещё несколько бенчмарков на такой же машине. Мне кажется, такие же ядра работают в Nintendo Switch.
| скаляр | 1,40 нс |
| NEON | 1,04 нс |
Технические спецификации небогатые. Однако процессор работает на частоте 1,7 ГГц, в чём каждый может убедиться, если запустит
perf stat. Вот сколько циклов нам символ нам нужно:| скаляр | ARM | Недавний x64 |
|---|---|---|
| скаляр | 2,4 цикла | 1,2 цикла |
| векторизованные (NEON и SS4) | 1,8 цикла | 0,25 цикла |
Если сравнить, то на процессоре x64 скалярная версия использует что-то вроде 1,2 цикла на символ, а ARM уступает примерно вдвое по циклам на символ. Это вполне ожидалось, потому что вряд ли ядра A57 могут конкурировать с x64 по производительности циклов. Однако при использовании SS4 на машине x64 я сумел добиться производительности всего 0,25 цикла на символ, что более чем в пять раз быстрее, чем на ARM NEON.
Такое большое отличие объясняется разницей в алгоритмах. На процессорах x64 мы используем сочетание
movemask/pshufb и алгоритм без ветвлением с очень малым количеством инструкций. Версия для ARM NEON гораздо слабее.На процессорах ARM есть много приятных вещей. Код ассемблера гораздо более элегантный, чем аналогичный код для процессоров x86/x64. Даже инструкции ARM NEON кажутся чище, чем инструкции SSE/AVX. Однако для многих задач полное отсутствие инструкции
movemask может ограничить вас в работе.Но, возможно, я недооцениваю ARM NEON… можете выполнить задачу эффективнее, чем удалось мне?
Примечание. Статья была отредактирована: как заметил один из комментаторов, на 64-битных процессорах ARM есть возможность перестановки 16 бит одной инструкцией.
Комментарии (53)

tronix286
09.07.2017 20:12-13И в целом, эта статья — полностью освещает текущее положение дел. Мы на iP166 крутили 3D бублики с закраской по Фонгу, и ваще divx спокойно декодировали в реалтайме, а сейчас не могут из строки пробелы убрать. Ой все ©
lorc
09.07.2017 20:22+24Вы это серьезно, что ли?
Это же чисто исследовательская задача. Игры разума. Погружения в пучины ассемблера ради максимального быстродействия. Именно такие как этот автор и делали DivX.



notorca
10.07.2017 00:36В итоге получилось, что на arm64 movemask заменяется vand + vaddv, а pshufb — vtbl1. Но маску в набор индексов приходится преобразовывать через таблицу, и загрузка значения из таблицы судя по всему наиболее медленная часть этого алгоритма.

Rayslava
10.07.2017 08:47+4Угу. Оптимизировали, векторизовали, отчитались об успехе. И тут приходит мультибайтовая локаль :(

VEG
10.07.2017 09:31+4Если это UTF-8, то указанный алгоритм сработает корректно. В UTF-8 у каждого кодпоинта, растянутого на несколько байтов, все байты имеют старший бит, установленный в единицу. То есть каждый такой байт будет больше 127. Соответственно, любые операции именно с ASCII-символами (коды которых меньше 128) не могут испортить многобайтовые символы.
Rayslava
10.07.2017 11:28Я, собственно, не к тому, что удаление пробелов работать не будет — с ним-то всё хорошо, а с фиксированным размером и всё остальное тоже будет неплохо, после небольших правок, как тут справедливо заметили.
Это я к тому, что при оптимизации работы со строками частенько забывают про обработку мультибайтов, надо хотя бы проверку этой самой локали и fallback-метод предусматривать на всякий случай.notorca
10.07.2017 11:32Так эта статья не про то, как сделать библиотечную функцию для удаления пробелов из строки, а про подходы к оптимизации.
notorca
10.07.2017 09:53Если мультибайтовая фиксированного размера, то все отлично, только маску для сравнения поменять.
GarryC
10.07.2017 10:59-4Прежде, чем привлекать сложные инструкции, можно было оптимизировать на простом С, убрав лишние записи и перейдя к указателям, что само по себе даст прирост раза в полтора. Ну и вместо тернарного оператора использовать нормальное сравнение (код на высоком уровне оптимизации не изменится, по зато KISS выполняется), получится что-то вроде
size_t i=0; char *i = bytes, *pos = bytes; while (i < howmany) { register char c = i++; if (c>' ') { *pos++ = c;}; }; Вот это - оптимизированная программа, и с ней надо сравнивать векторный вариант, а не с тем ужасом, что приведен в начале поста.notorca
10.07.2017 11:17+3Предполагаю имелся в виду вот такой вариант:
?char *i = bytes, *pos = bytes; const char *end = bytes + howmany; while (i < end) { register char c = *i++; if (c>' ') { *pos++ = c;}; }; return pos - bytes;
Он медленнее того, что в начале статьи почти в 2 раза.GarryC
10.07.2017 13:38-1Вот с этого момента поподробнее, пожалуйста.
Почему то Gobbolt.org утверждает (и я ему склонен верить), что этот вариант порождает код меньшего времени исполнения, поскольку:
1) отсутствует превращение индекса в указатель, который занимает 2 команды
2) отсутствует постоянная запись, которая есть в первоначальном варианте
3) проверка занимает ровно столько же времени, сколько тернарный оператор (но она понятнее)
Все это верно для оптимизации -O2.
Каким же образом этот вариант оказывается медленнее?notorca
10.07.2017 13:51Поскольку в статье речь идет об arm64 то и скорость я сравнивал на arm64.
Вот результаты:
despace(buffer, N): 0.79 ns per operation
despace2(buffer, N): 1.40 ns per operation
1) Превращение индекса в указатель занимает 0 инструкции (ldrsb w10, [x9], #0x1)
2) Безусловная запись быстрее чем условная, т.к. нет лишнего условного перехода.
3) Проверка генерирует дополнительный условный переход. в то время как тернарный оператор дает одну безусловную инструкцию cinc x0, x0, gt.
В итоге во втором варианте больше ветвлений, которые портят конвейер.
Вот картинки из дизассемблера

MacIn
10.07.2017 18:03Вот это, кстати, было бы здорово пояснить в статье.
Я при чтении тоже споткнулся о первый пример. При решении в лоб первым на ум приходит анализ символа и запись его только в случае необходимости (в рамках более привычной x86 это должно быть более быстрым).
GarryC
10.07.2017 18:07Я смотрел привычный ARM, для ARM64 действительно получается по-другому:
1) индексирование не стоит времени,
2) если вынести запись всегда, то с конвейером лучше — это надо делать.
3) операция сравнения получается точно такой же со скипом инкремента.
Так что почти Ваш вариант
будет оптимален по быстродействию, особенно, если пробелов немного.char *i = bytes, *pos = bytes; const char *end = bytes + howmany; while (i < end) { register char c = *i++; pos=c; if (c>' ') { pos++; }; }; return pos - bytes;
Единственное исправление, на котором я настаиваю, это последний оператор — ну не нужен тут тернарный оператор, а я его вообще избегаю по рекомендации MISRA.
P.S. Хотя я, вообще то, удивлен, что один переход может ТАК замедлить работу, пусть и в ARM64notorca
10.07.2017 19:09На обычном ARM индексирование тоже не стоит времени. LDR (register offset). Последний вариант чуть быстрее, но все еще хуже способа из статьи.
despace(buffer, N): 0.79 ns per operation
despace3(buffer, N): 1.19 ns per operation
if вместо тернарного оператора генерирует код через csel + move вместо csinc, что делает цикл на одну инструкцию больше (7 vs 6). Вообще заменять работу с массивами и индексами на указатели — только мешать компилятору оптимизировать.GarryC
11.07.2017 12:05Ну не знаю, почему у Вас так получается — я на Godbolt.org вижу совершенно одинаковый код для тернарного оператора и для условия (это gcc компилятор).
И для перевода в индекс для arm генерятся две команды — сложение с базой и собственно доступ. а для arm64 адресация со смещением — одна команда.
Кстати, опять таки на gcc генерится (и для arm и для arm64) еще отдельная команда инкремента указателя, а в Вашем дизассембелер ее нет — почему так?notorca
11.07.2017 13:37Вот для arm с gcc. 9я строчка, strb ip, [r0, r3], одна команда адресации со смещением.
Вот arm64, 11я строчка csinc для примера из статьи и 49я csel и 45я mov для if.GarryC
13.07.2017 11:16В общем, фигня какая то творится.
Я нашел вариант, который генерит оптимальный код из программы
получаетсяregister char c = *i++; if (c>' ') { *pos++=c; };
, что является наибыстрейшим кодом вот ссылка (так что я все таки был прав, ура).ldrb r2, [r3], #1 @ zero_extendqisi2 cmp r2, #32 strhib r2, [ip], #1
Но почему то такой код порождает только для версии ARM gcc 4.6.4.
Для версии ARM gcc 5.4.1 получается
, что несколько медленнее, а для ARM64 вообще генерится команда перехода — я не понимаю происходящего.ldrb r2, [r3], #1 @ zero_extendqisi2 cmp r2, #32 strhib r2, [ip] addhi ip, ip, #1notorca
13.07.2017 13:11Мне кажется что на Cortex A15 не будет разницы по скорости выполнения межу strhib r2, [ip], #1 и strhib r2, [ip]; addhi ip, ip, #1. А на Cortex A7 скорее всего будет, это я чуть позже проверю.
В ARM64 больше нету условного выполнения каждой инструкции, есть b, и csel.
notorca
14.07.2017 01:20+1Финальная расстановка точек. Тест на Cortex A7. Результаты по скорости:
despace(buffer, N) : 4.21 ns per operation despace_ptr(buffer, N) : 5.25 ns per operation neon_despace(buffer, N) : 3.33 ns per operation neon_despace_branchless(buffer, N) : 3.69 ns per operation
Где dspace это:
size_t i = 0, pos = 0; while (i < howmany) { const char c = bytes[i++]; bytes[pos] = c; pos += (c > 32 ? 1 : 0); } return pos;
dspace_ptr:
char *i = bytes, *pos = bytes; const char *end = bytes + howmany; while (i < end) { register char c = *i++; if (c>' ') { *pos++ = c;} } return pos - bytes;
Как видно из результатов код с меньшим количеством инструкций выполняется медленнее. Подробное объяснение потянет на отдельную статью, но если кратко, то важно не только количество инструкций, но и зависимости между ними, и это то, что компилятор умеет выстраивать достаточно не плохо, если ему не мешать. Например на Cortex A7 пара ldr/str для одного и того же регистра выполняется столько же, сколько простой ldr.
Также
addhi r0, r0, #0x1 subs r1, r1, #0x1
выполнятся за 1 такт потому что поддерживается dual issue для инструкций читающих по одному регистру.
Вот так, примерно, будет выглядеть выполнение кода по тактам:
1 ldrb r2, [r3]!, #0x1
2 strb r2, [ip, r0]
3 cmp r2, #0x20
4 addhi r0, r0, #0x1
4 subs r1, r1, #0x1
5 bne loc_10554
1 ldrb r1, [r3]!, #0x1
3 cmp r1, #0x21
4 strbhs r1, [ip]!, #0x1
5 cmp r3, r2
6 blo loc_10584
Дизассемблер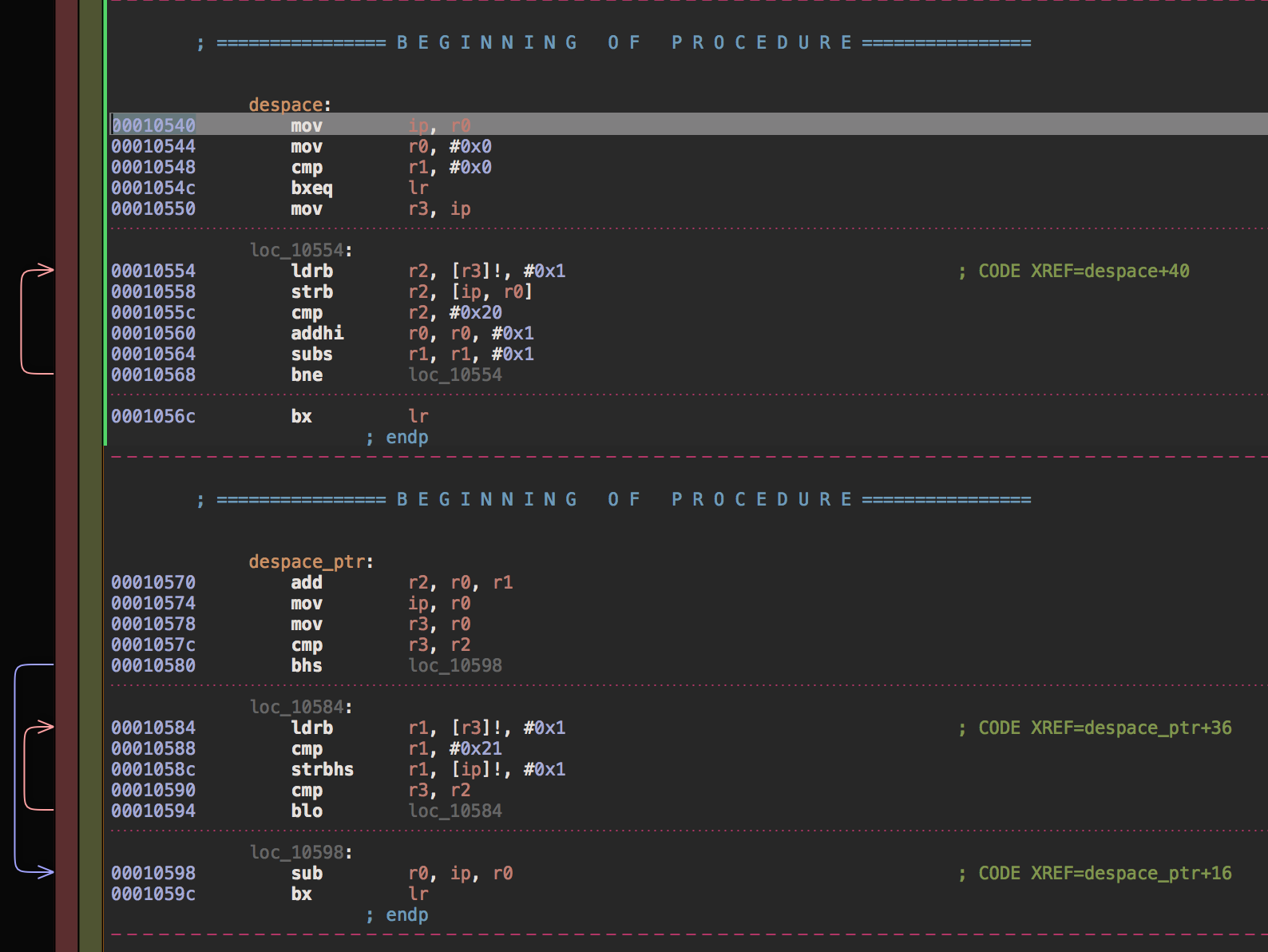
GarryC
17.07.2017 16:24Все равно как то странно — кода явно меньше а время получается больше — непонятно, может быть, дело в том, что в первом варианте цикл по счетчику, а во втором — по указателю, попробуйте такой вариант, если будет время. Но тогда почему сравнение во втором варианте не делается одновременно с записью, как в первом варианте — я остаюсь в недоумении.
Оптимизация в помощью векторов будет очень чувствительна к проценту пробелов и даст прирост только тогда, когда пробелов не более, чем сколько-то (интересно, сколько именно).notorca
18.07.2017 02:40В первом варианте запись и сравнение не зависят друг от друга, а зависят только от ldrb. При этом strb из того же регистра, в который идет ldrb может начаться на такт раньше, чем другие инструкции, зависящие от этого регистра.
Во втором случае запись зависит от сравнения, и не может начинаться раньше, чем выполнилось сравнение, которое в свою очередь дожидается результата ldrb. Вот и вся разница, счетчик либо указатель тут не причем.
Оптимизированный вариант neon_despace_branchless не зависит от процента пробелов.
notorca
10.07.2017 19:28Вариант из статьи на x86_64 тоже будет оптимальнее на многих компиляторах. Только для варианта из статьи clang 4.0 дополнительно развернул цикл
graphican
10.07.2017 15:02Неплохой конкурс получился бы: сделать на big.LITTLE с многопоточностью на Неоне вот такой простой алгоритм, который становится очень сложным в многопоточной среде.
tronix286
Имхо, никто не сталкивается с такой проблемой. Удалить из строки пробелы даже на древнем ARM610 на 233MHz или сколько он там, — это просто. На нынешних 2ГГц — да хоть на интерпритаторе бейсика написаном на питоне, генерящем ява скрипт обернутым похапе — ну не может оно тормозить. Не говоря уже про нативный простой код. Я не представляю, как можно его (код) написать, чтоб удаление из строки пробелов стоило хоть скольконибудь серьезного внимания. Если у кого-то такое получилось, то он просто б-г говнокода 80 левела. Зачет.
daggert
Тут не будем оптимизировать, там не будем… и вот уже ваш го*код тормозит даже на последнем 100500 ядерном зионе. Если есть возможность сократить такты при выполнении кода — их НУЖНО сокращать.
tronix286
Да об одном и том же говорим — пишите на Си, не будет никаких тормозов. Простая истина.
notorca
В статье 2мя способами на C написано с разницей в скорости в 2 раза. Комментарии к оригинальной статье тоже полезные.
0xd34df00d
Само по себе использование сей не гарантирует производительности, мягко скажем.
shude
На Си можно тоже написать, чтобы были тормоза. В некоторых системах которые работают с форматированием текста и обрабатывают большие данные, правильный выбор алгоритма может сократить количество железа, а это деньги.
PsyHaSTe
Оптимизации не даются бесплатно. В таком коде например намного проще совершить ошибку, выбрав неправильную маску или опечатавшись, тогда как в дуболомном
byte[] result = source.Where(b => b >= 32).ToArray()ошибиться просто негде. Есть такой парень, Кнут, мне кажется он что-то про подобные вещи писал...tyamgin
Например, >= с > перепутать?
PsyHaSTe
Пример еще лучше получился. Даже в таком варианте можно ошибку допустить.
POPSuL
Так в вашем «дуболомном» примере тоже можно ошибиться с
>=и>, не?daggert
Для этого существует код ревью, статические анализаторы и баг-тестинг. Хоть это и сложно и удорожает процесс — оно того стоит, ибо микрооптимизации дают о себе знать в итоговом продукте очень заметно.
PsyHaSTe
Большинство программ тормозят не потому, что SIMD не заюзали, а из-за большой буковки О. Если оптимизация бесплатная (ie компилятора), то я только за, а если ручная, то нужно взвесить за и против. В моей практике обычно больше "против". Ниже уже посчитали, что это позволяет обрабатывать 12ГБ/С символов. Медленный вариант в 4 раза медленнее. Если мы берем стандартный 32битный процесс (щас много где распространено, у нас на одном проекте например библиотеки типа OCR были все 32-битные, и приходилось поэтому писать продукт тоже под 32) с флагом на 3ГБ, то "медленный скаляр" переварит всю строку за секунду, а быстрый SIMD — за 0.25 секунды. Только пользователю все равно 3ГБ строку из базы/с диска поднимать чуть ли не минуту.
Я понимаю, что пример в статье это просто абстрактное "смотри как я умею". Но ваш вариант писать все в таком стиле меня настораживает. Я представляю продукт, где все написано в таком духе. Вместо однострочника за 5 секунд пишется и отлаживается SIMD-версия. У меня бы это заняло пару часов, просто чтобы без багов написать, покрыть тестами (однострочник в тестах не нуждается как правило) и т.п. Нужно найти элемент в множестве — снова вместо 5 минут тратим пару часов. Пофиг, что функция вызывается один раз на старте приложения, чтобы подгрузить плагины — скорость! Быстродействие! Все любят быстрые программы, но что-то никто не любит потом их дорабатывать и искать баги.
daggert
Конечно надо оптимизировать с умом, но вот у меня оптимизация приложения идет уже пятый год и за это время программа стала потреблять 256 мегабайт оперативки, вместо 1 гига и это лично мне критично.
0xd34df00d
Нет, конечно, не надо писать абсолютно всё в таком стиле. Профайлеры не зря существуют.
Кроме того, большая буковка O — это асимптотика. Во-первых, асимптотика сама по себе говорит о стремлении к бесконечности, во-вторых, она зачастую не учитывает некоторые особенности (современного) железа.
Вот и получается потом, что человек, хорошо знающий теорию, берёт и использует list, ведь ему надо будет вставлять в середину, а что вектор на современном железе практически всегда быстрее — так это и неважно.
Ну и да, в противовес вашему примеру, у меня, например, есть проект, который жрёт гигабайт сто, и который по этому массиву данных должен проходить примерно logn раз. Можно делать выводы.
Kaiser
Нет. Немного искусственный пример: вырезание пробелов занимает 5ms, затем стэммер работает 500ms. Если «заоптимизировать» вырезание пробелов до 0ms, то экономия будет не очень заметной: с 505ms до 500ms. А еще можно вспомнить эмпирическое правило, что чем больше ускорение кода, тем больше времени тратится на это ускорение. Тогда как ускорение стэммера даже всего на 10% даст эффект значительно выше. За этим нужно профилировать код, а потом уже что-то оптимизировать.
Кроме того, можно заметить, что вырезание пробелов O(n) задача, тогда как затыки в реальных задачах чаще возникают в другом классе задач. То есть, замечание справедливо.
Другое дело, что это PoC, показывающий как что-то можно ускорить SIMD инструкциями. И этот пример может быть полезен в совершенно других задачах.
lorc
Ну видно же что это исследование возможностей современных числодробилок. Или вы всерьез полагаете что кому то нужно удалять пробелы в восьмибитной кодировке, да на такой скорости?
Автор смог заставить x86_64 тратить четверть такта на символ. При частоте 3ГГц процессор смог бы обрабатывать 12гигабайт текста в секунду. Повторите это на бейсике…
Antervis
осталось только 12 гигов/сек прочитать и записать
Alexeyslav
Разве это проблема? в RAM-диск и делов-то…
Stecenko
Не такта, а цикла. Тактов, вероятно, будет больше.
notorca
Ну, во первых, это красиво.
PsyHaSTe
Красиво, что это можно сделать. Некрасивый код, который в итоге получается. В идеале я бы хотел написать как в примере выше
byte[] result = source.Where(b => b >= 32).ToArray(), а компилятор к такому виду привел (пусть даже с хинтами). А некоторые считают, что оптимизирующие компиляторы вообще трата времени. Аргументация была как раз что-то типа "все равно 95% кода выполняются очень редко, а компилятор оптимизирует все равномерно. Давайте пусть будет пользователь сам свои 5% горячего кода оптимзиировать, а на остальное забьем. Да, будет медленее, зато смотрите. какой компактный и быстрый компилятор!". Для кого-то вот это понятие красоты верно. Хотя например на мой взгляд аргументация бредовая.notorca
Компилятор достаточно неплохо векторизует код, особенно с хинтами. Но тут как раз такой случай, что нужно чуть больше ему помочь.
daocrawler
Существуют вполне прикладные задачи, в которых требуется обработать терабайты текста еще и распределенно в кластере. Именно в такие моменты и садятся за оптимизацию обработки пробелов, вдумчиво выбирают разделитель данных и т.д.