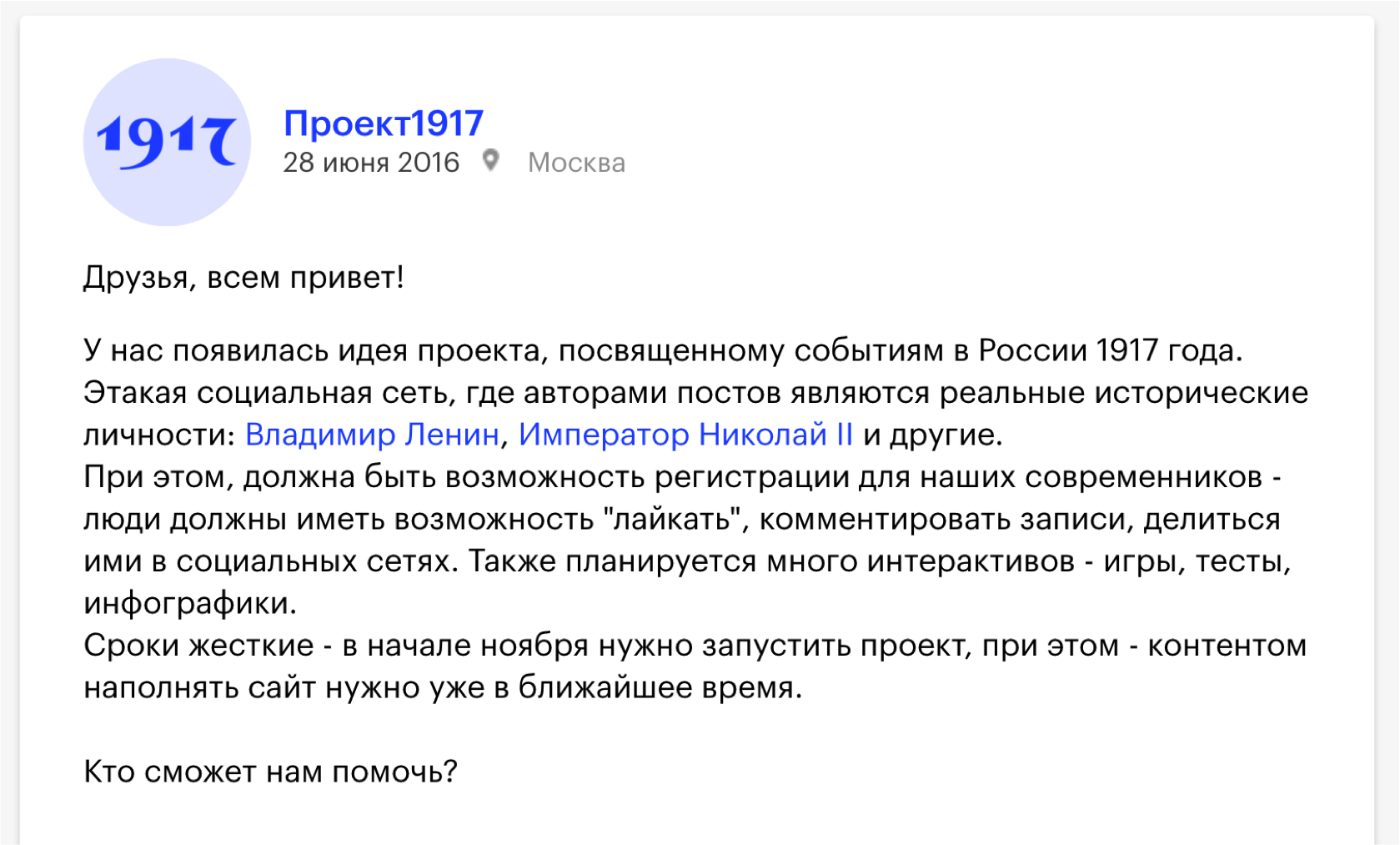
Создатели проекта говорят, что это лучшая социальная сеть в истории — потому что все ее пользователи давно умерли. Это сайт в формате социальной сети, где пользователями являются реальные исторические личности, которые пишут о событиях, происходивших ровно сто лет назад. Все материалы основаны на реальных исторических документах, письмах, публицистических материалах, используются данные из фотоархивов, из видеоархивов. Читатели нашего времени могут комментировать эти записи, лайкать, делиться ими в социальных сетях.

Изучив задачу, мы поняли, что она вполне реализуема, и можно успеть ее сделать в обозначенный срок. Несмотря на то, что наш основной профиль — администрирование и поддержка высоконагруженных проектов, мы начинали с веб-разработки, и до сих пор иногда занимаемся разработкой (кто, как не мы, лучше знает, как должна быть устроена инфраструктура сайта, рассчитанного на большой трафик).
Ключевой момент: у нас была несдвигаемая дата дедлайна — с точностью до минуты. Это 15:00 14 ноября — в это время в СМИ уйдут пресс-релизы, Яндекс опубликует проект у себя, на Красной площади человек с мегафоном сделает официальный анонс проекта. Вероятность сдвинуть дедлайн хотя бы на час была равна нулю.
На этапе согласования работ с клиентом мы определили четкий график реализации проекта. Понятно, что материалов очень много, и сайт наполнить контентом нужно не за час до релиза, а гораздо раньше. В начале августа мы решили выкатить в продакшн админку и начать верстать. В сентябре — доработать админку и начать привязывать данные, в октябре реализовать взаимодействие с пользователями нашего времени (сделать авторизацию, реализовать шеры, лайки, комментарии). 7 ноября (хорошая дата) было решено провести нагрузочное тестирование. 14 ноября — запуск проекта, спустя неделю после запуска мы реализовываем пуш-уведомления, чтобы возвращать пользователя на сайт. В декабре сайт должен был быть переведен на английский язык.
Формируем команду и начинаем работу
3 июля мы подписали договор, план работ и сделали первый коммит в репозитории.

В сложном проекте с жестким дедлайном очень важно, чтобы команда не стала выглядеть, как эта: Вася, который работает, и над ним десять менеджеров
Первый принцип — no rocket science (никаких ракетных технологий), хотя сроки и сжаты. Мы строим не ракету, которая должна прилететь на Марс и спасти человека, у которого закончилась картошка. Мы всего лишь делаем социальную сеть.

Если в процессе решения какой-то задачи в каком-то из рабочих чатов появлялся такой стикер, это значило: «Ребята, что-то у вас идет не так, нужно разбить задачу на более мелкие подзадачи, решать по отдельности и не усложнять себе жизнь».
В команде у нас были менеджер проекта, три программиста, два админа, два тестера, и в определенный момент было принято решение команду разделить на две географических зоны: часть ребят уехала из Иркутска работать в Москву, чтобы обеспечить длинный рабочий день (у нас главный офис в Иркутске, и разработка сначала велась там).
Какой был выбран стэк? Каждый день появляются новые технологии, и во всем этом очень легко заблудиться, включить что-то ненужное, просто потому, что это модно. Так делать не надо — не забывайте старую русскую поговорку: «Чем круче джип, тем дольше идти за трактором». И в программировании эта поговорка применима.
Как мы решили построить стэк? В качестве веб-сервера мы поставили Nginx с PHP-FPM, для базы был выбран MySQL 5.7, в качестве фреймворка для бэкенда мы выбрали Laravel — это наш рабочий фреймворк. Фреймворком для фронтенда был выбран Angular 1.5.
Один из главных принципов, почему Angular 1.5 — мы используем только то, что хорошо знаем, или сможем быстро найти ответ, если что-то не знаем. Первая более-менее стабильная версия второго Ангуляра вышла спустя две недели после того, как мы начали разработку, и нам было уже не до того, чтобы все переписывать. До этого с версиями 1.5, 1.4 мы работали достаточно много, знали все подводные камни, поэтому решили делать на том, чем мы умеем пользоваться.
Для работы с графикой мы взяли Imagemagic, для работы с видеоматериалами и с гифками мы взяли FFmpeg, обязательно используем Memcached, для сбора и работы со статикой мы используем Gulp с собственными, нами написанными тасками.
Делаем админку и верстаем
Через месяц мы уже выдали админку. Как построили админскую часть, как сайт наполняется контентом? За основу мы в бэкенде положили пакет L5-repository — это пакет для Laravel, который позволяет буквально тремя командами реализовывать нам RESTful API, делать нам все модели, создавать из коробки миграции со сложными отношениями, одним рутом генерировать нам полностью контроллер для работы с данными. Фронтенд админки был выполнен как одностраничное веб-приложение: активно используется сервис ngResource, чтобы взаимодействовать с API. На стороне фронтендa мы попытались реализовать самописный JS-cache, чтобы из админки данные постоянно не запрашивались с сервера, если мы что-то один раз загрузили, и с этим работаем на клиенте. Вся админка построена на Angular-компонентах.
Очень важно было обсудить с клиентом, как они хотят построить работу редакции. Идеальный вариант админки — когда над каким-нибудь разделом работает одновременно пять человек: кто-то обновил название, кто-то — текст. Клиент запланировал последовательную работу: будут ответственный за текст поста и ответственный за порядок постов. Мы сделали так, что компоненты не пересекаются между собой, и обновляют только те данные, с которыми они работают. В среднем на разработку компонента мы тратили где-то час, и какой-то принципиально новый раздел в админке выкатывали за день.
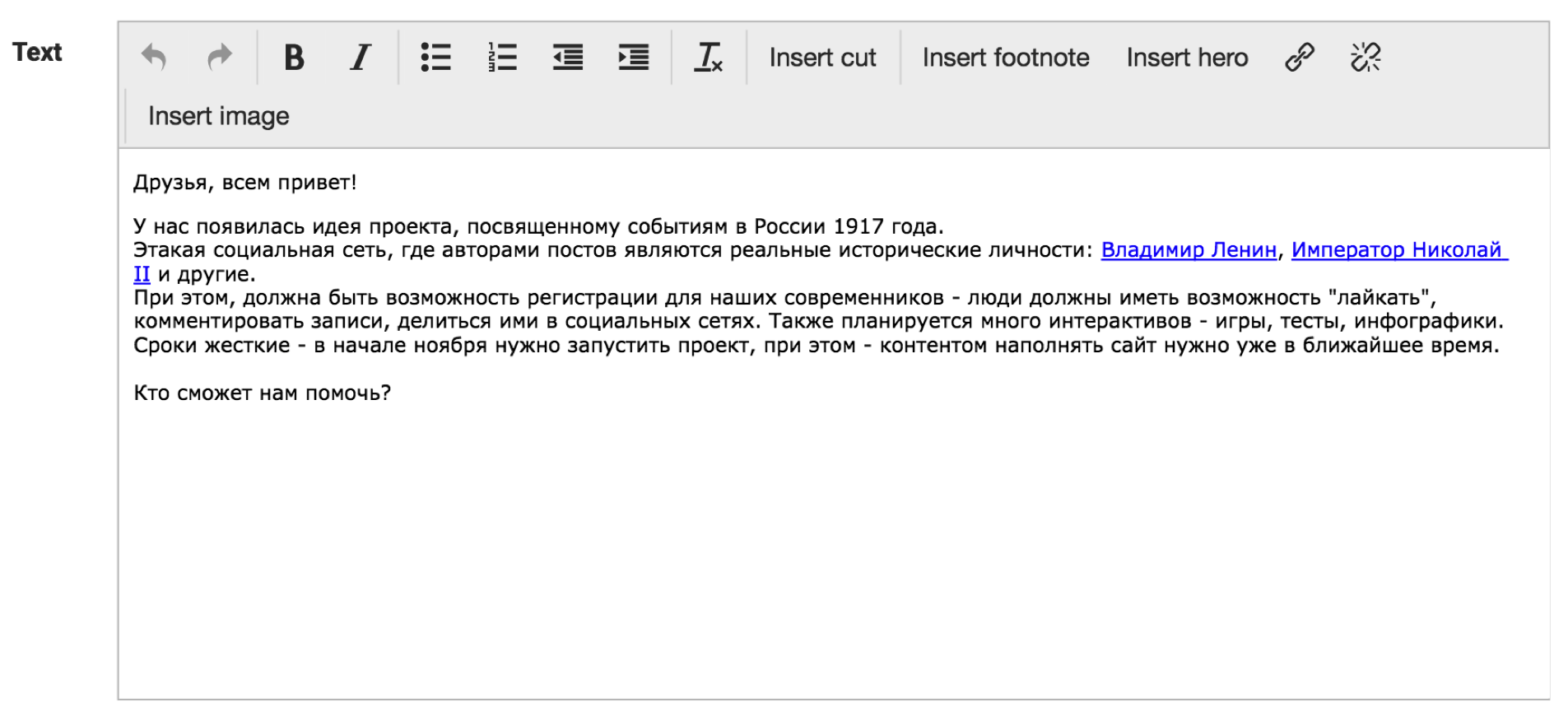
Самый простой наш компонент — текстовый редактор. Понятно, что это обычный TinyMCE, но немного доработанный. Видно, что у нас есть кнопки «вставить ссылку», «вставить героя» и сразу в тексте видно, что в текст будет вставлена, например, ссылка на Владимира Ленина, где будет потом красивый попап с его фотографией, и так далее.

Вот так вот выглядела редакция, которая в первый раз увидела нашу админку — они очень радовались, им было очень удобно и настолько просто, что можно научить ей пользоваться даже собаку:

Дорабатываем админку и привязываем данные
Итак, админку мы сделали, подбираемся к публичной части проекта — к фронтенду. Так получилось, что макеты нам дали чуть позже, каждый день на ходу менялись задачи. Это был первый тревожный звоночек: мы можем не успеть. Решили сразу верстать и адаптироваться на живые данные.
Как мы решили реализовать фронтенд? Для поисков, фильтрации, сортировок мы так же используем пакет, который используем в админке, — L5-репозиторий, то есть работаем со всеми данными как с репозиторием. Какие-то блоки на сайте с точки зрения PHP-кода мы выделяем в отдельные сервисы, они подключаются как объекты-одиночки, и нужно выстроить их так, что если понадобится вытащить из сайта один компонент и вставить его куда-то в другое место, все должно работать.

Например, есть у нас такой базовый компонент — календарь. Сразу же от этого компонента у нас выходит компонент «шапка». Это красивая картинка с популярными постами, с возможностью поделиться:

Дальше у нас идет лента постов, которая «общается» с календарем и смотрит, «какой день надо нарисовать».
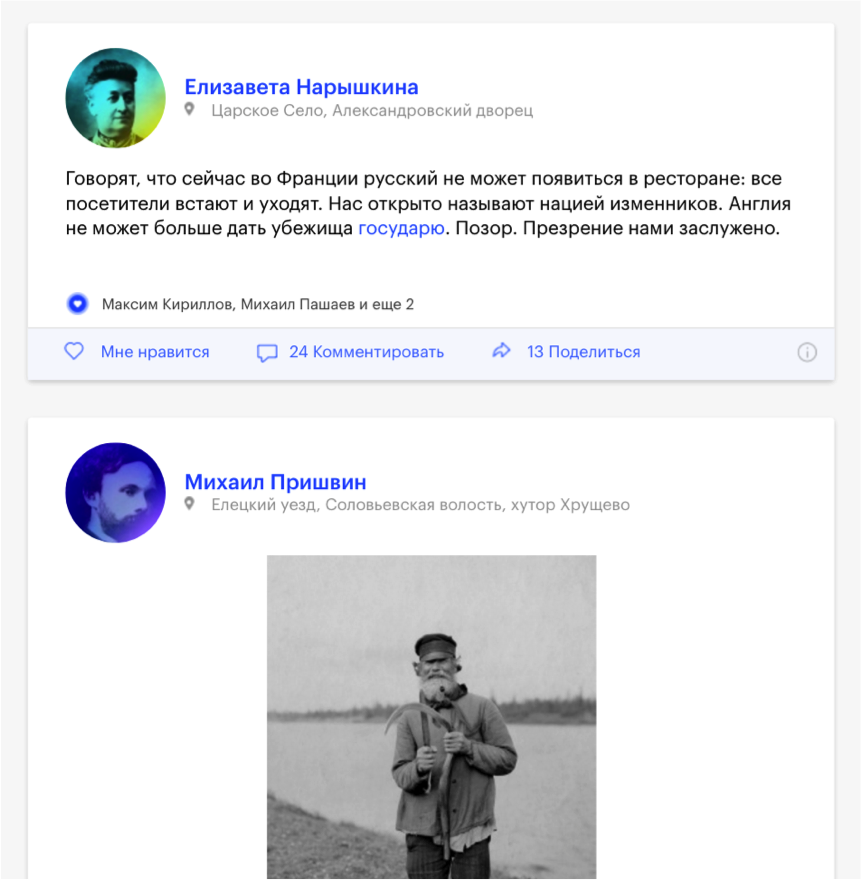
От ленты зависят блоки рекомендаций и блок подписки. От календаря зависят такие блоки, как погода, валюты, дни рождения. Почти как в настоящем Фэйсбуке можно посмотреть всю картину дня сразу.
На бэкенд, то есть на сервер, можно было предсказать нагрузку — в ТЗ обозначили определенное количество RPS, а вот то, с каких устройств будут просматривать сайт, мы предсказать не можем. Поэтому было решено публичную часть фронтенда делать максимально просто.
Во-первых, вся статика у нас сразу запрашивается из кэша, для динамической уникальной пользовательской информации мы используем API, которое не кэшируется. Вся динамическая загрузка работает через HTML. Сервер генерирует статичную ленту, например, прокрутили — пришла новая страница в HTML, то есть, данные не в JSON. Если вдруг все равно нам надо как-то работать на странице с JavaScript, мы либо оптимизируем, либо минимизируем использование AngularJS, и активно используем библиотеку Bindonce, которая позволяет реализовывать одноразовые связывания. Все изображения оптимизируются средствами Nginx, с помощью модуля http_image_filter, и в случае каких-то пиковых нагрузок мы раздачу статики переводим на CDN.
Делаем лайки, шеры, комментарии
Их реализовали за неделю. Во-первых, что такое, например, лайк или комментарий? По сути, с точки зрения базы данных, это обычная таблица, которая реализует связь many-to-many: есть, например, post id, есть user id. Мы решили подойти по-другому, и работать с этим отношением не как с отношением, то есть, например, что у нас пост имеет комментарии, мы выделили комментарии в отдельную сущность, которая имеет hasOne пост, hasOne автор. При этом, в Гугле по запросу «как написать лайки» предлагают использовать такую связь, например, как morph-by-many. Когда таблица хранит не два айдишника объектов, которые она связывает, а like-type, like-id. Например, хотите вы делать лайки для постов, для видео — вам предлагают сделать like-type, like-id. Мы решили, что это лишнее — у нас будет только одна таблица лайков.
Дальше. Активно использовали методы-мутаторы, чтобы, например, на странице одной строчкой получить число шеров, например, это у нас вк-шер, ок-шер, фб-шер. На фронтенде используется Localstorage, который в случае, например, неподдерживаемости браузером может опуститься до уровня кук. Там мы, например, храним информацию о том, что пользователь лайкнул пост, то есть, чтобы каждый раз мы не делали запросы в базу, не получали список постов. Мы сохраняем один раз все в Localstorage, страница срендерилась, сердечко закрасилось, лишний запрос в базу мы не делаем.
Мы не кэшируем API для работы с пользователем — он должен в реальном времени получать, например, актуальные комментарии. Нельзя сказать пользователю: Извини, у нас пять минут кэша, через пять минут твой комментарий появится». И если вдруг нам понадобится какое-то, например, динамическое общение с сервером, мы спокойно можем использовать события с каналами из Laravel, которые работают уже с Node.js.
Теперь о шеринге. Многие спрашивают, почему мы не используем какое-то готовое решение для этого. Дело в том, что помимо контента у нас очень много спецпроектов, где человек может пройти тест, загрузить фотографию, ему сгенерируется открыточка, он ее шерит в социальную сеть. При этом, если другой человек увидел в ленте у своего друга эту картинку, он на нее нажимает и должен попасть на страницу теста. То есть, на уровне Ngnix мы ботов отправляем на заглушки, а не редиректим ботов туда, куда нам надо.
Также в нашей системе шеринга мы реализовали свой механизм подсчета. Для всех подобного рода систем очень важно выводить акуальную информацию (число репостов), а также хранить их в базе для подсчета определенных статистик, рейтингов и прочее. Очень часто программисты, сталкивающеся с шерингом первый раз, реализуют подсчет следующим образом: по заданиям в cron бэкенд делает запросы к апи социальных сетей, получает свежие данные, сохраняет. У этого подхода есть два серьезных недостатка — во-первых, информация в текущий момент времени может быть не актуальна (например, крон раз в 10 минут обновляет данные о 1000 постов), во-вторых за частые обращения к апи социальных сетей с одного IP-адреса вас могут забанить.
Мы пошли другим путем. В момент, когда пользователь шерит пост в свою социальную сеть, мы паралельно с попапом шеринга делаем запрос к api социальной сети из js-кода (соответственно — с ip-адреса клиента), получаем актуальное число репостов, прибавляем к этому числу 1 (пользователь же еще не пошерил) и сохраняем в базу данных. Соответственно, мы постоянно поддерживаем базу количества шерингов в актуальном состоянии, и даже возникает такой эффект, что, например, ты пошерил, а число увеличилось на 10, значит, кто-то с тобой вместе сейчас шерит, ты такой: «О, круто, все в реальном времени работает, как мне это нравится!».
Разрабатываем пуш-уведомления и запускаем
Приближалось 14 ноября, ничего не предвещало беды, мы спокойно прошли нагрузочное тестирование, полностью подготовили сайт к релизу, как в 9 вечера по Москве появилось такое сообщение. Ребята передумали и решили сдвинуть разработку пушей на сейчас. Пик трафика ожидался как раз в день запуска, и базу подписчиков нужно было собрать уже в этот день. Когда люди разрабатывают пуш-уведомления, они не обращают внимания на главную проблему: цена ошибки при разработке — это новый домен и потерянная база подписчиков. Например, вы долго-долго колдовали и наконец-то добились того, что у вас в браузере появилась вот эта вот плашка «я подтверждаю отправку мне уведомлений». Если код у вас выглядел в этот момент вот так (больше человек эту плашечку никогда в своей жизни не увидит, пока в настройках не сбросит пермишены на пуши):

Вы не сохранили токен, а просто его законсолили
Как мы решили реализовывать пуши. За основу был взят сервис Google Fairbase. Так как времени оставалось мало, мы обязательно смотрим документацию и делаем все по ней. В случае, если человек не был авторизован на сайте, решили делать очень просто. Мы генерируем какую-то уникальную cookie этому человеку, и в базу сохраняем токен с ней. Потом человек авторизовался на сайте, мы посмотрели, что у него есть cookie, в базе есть токен с ней, перепривязываем токен на конкретного пользователя, и потом уже ему рассылаем какие-то персональные уведомления.
В качестве рассыльщика решили использовать пакет Laravel-FCM. Тот, кто работал с FCM или Firebase, знает, что, для того, чтобы отправить сообщение, нужно все поделить на пачки по тысяче токенов, сделать отдельно запросы. Laravel-FCM это берет на себя. При этом он очень просто позволяет нам генерировать payload в пуши, делать какую-то персональную картинку для человека, персональный заголовок, персональный текст, персональную ссылку и так далее.
Мы успели. Выкатили пуши за час до релиза. На следующий вечер про проект написали The Village, Медуза, CNN, BBC, в «Третьяковской галерее» устроили банкет для СМИ, на который нас пригласили. И такая небольшая ирония: до декабря 2016 года главный офис нашей компании официально располагался посреди леса. Представьте, как круто — вы сделали проект, о котором написали в CNN, а сделали вы его в лесу.
Делаем локализацию
Итак, мы запустили проект, он работает, баги поправили, на дворе декабрь, нам надо делать локализацию. Локализовали проект за два дня.
Хранить в базе данных информацию о двух языковых версиях мы решили так. Для каждой сущности, которая может быть переведена на другой язык (пост, герой, группа, видео, геолокация) мы добавили поля: lang, которое хранит язык — 0русский/1английский) и поле mirror_id, куда сохраняется id записи «дублера» при копировании.
При таком копировании, например, если у объекта есть какие-то отношения (автор у поста, геолокация), все его дочерние сущности тоже скопируются, причем если сущность уже копировалась (mirror_id не пусто), то у копируемой записи перепривяжутся отношения на эту сущность, если нет, то сначала скопируется она и потом перепривяжется.
Например, в русской версии есть два поста, написанных Николаем II, при копировании первого поста скопируется и пост, и автор, при копировании второго — только второй пост, а автором назначится уже скопированный ранее Николай II.
Что дальше?
Как вообще проект живет сейчас. Основную функциональность мы уже разработали, практически ничего не меняется, делаем спецпроекты (игры, тесты), и до сих пор у всех возникает желание все переписать. Энергию направляем в мирные цели — если был какой-то спецпроект, и что-то сделали не идеально, мы это не переписываем, а реализуем уже в новом спецпроекте.
Например, из спецпроектов мы сделали:
- игру «Не пусти Ленина в Россию» — это известная логическая игра про кошку, только надо было ловить Ленина;
- «Тиндер1917» — сервис знакомств с героями революции;
- тест «Кто ты в 1917 году?» — самый топовый, люди заходили толпами, сгенерировано порядка полутора миллионов результатов.
Выводы
- Сложное сделать простым легко, усложнить что-то и сделать простую вещь сложной еще легче.
- Помните историю, революция не всегда приводит к хорошим результатам.
- Учитесь на своих ошибках. Пока вы сами не положите сервер, не поймете, из-за чего он лег. Пока вы сами не допустите какую-то сложную ошибку, не поймете, почему что-то сломалось. Потерянный домен в пушах — это не самое страшное, что может случиться.
- Не гонитесь за модой. Следите за своим стэком, не создавайте там больших огородов. Если вам нужно решить какую-то новую задачу, посмотрите, есть ли у вас уже инструмент, который для нее подходит, не надо находить новый модный фреймворк, документация к которому есть только на китайском языке, вы такой: «О, это модно, давайте попробуем». Так делать не надо.
- И цифра аптайма 99,99 – это не предел. Всегда можно это улучшить.

Комментарии (9)

Versetti
13.07.2017 22:20"Создатели говорят, что это лучшая социальная сеть в истории — потому что все её пользователи давно умерли".
У них SMM-щики в принципе классные :)

LoadRunner
14.07.2017 09:47Читал статью и всё думал — какого фига проект уже готов, если речь про ноябрь и 17 год?
Только потом дошло, что проект открылся в 2016 году. Но почему?
eapotapov
14.07.2017 10:47+1потому что создатели хотели показать, что происходило в России до революции и привело в итоге к ней.
LoadRunner
14.07.2017 11:09Так и я о том же — почему не на столетие запланировали? Логичнее в 2017 году такой проект открывать.

4umak
14.07.2017 14:05+1Суть в том, что действия там происходят «в прямом эфире», таксказать. Только с лагом в сто лет.
В ноябре 1917го был только зафиксирован итог огромного количества событий, которые сложились в победу большевиков.
События же, приведшие к этому итогу, начались отнюдь не 6 ноября, а много раньше. Именно поэтому и проект стартовал раньше, чтобы показать нашим современникам, какие именно люди и действия привели к полученному результату.
asmln
14.07.2017 10:47Хороший проект. Прочитал про тест «Кто ты в 1917 году?», прошёл. И в конце разочарование. Facebook или вконтакт. Нет ни того ни другого. Но всё равно спасибо :)
Vjatcheslav3345
А против архивирования проекта нет возражений у его собственников и авторов?
eapotapov
в конце проекта сделаем «консервацию» :)