Я продолжаю цикл статей по разработке метода безытеративного обучения нейронных сетей. В этой статье будем обучать однослойный персептрон с сигмоидальной активационной ф-ей. Но этот метод можно применить для любых нелинейных биективных активационных ф-й с насыщением и первые производные которых симметричны относительно оси OY.
В прошлой статье мы рассмотрели метод обучения основанный на решении СЛАУ, решать ее мы не будем т.к. это слишком трудоемкий процесс. Сейчас нас интересует из этого метода только вектор «B», в этом векторе отражено насколько важен тот или иной признак для классификации.
И тут из-за того, что имеется активационная ф-я с насыщением можно выразить веса как:
Первое, что необходимо сделать — это заменить на . Т.к. в задачи классификации «y» может быть либо 1(принадлежит), либо 0(не принадлежит). То t должно быть либо 1, либо -1. Отсюда . Теперь
Теперь выразим коэффициент «K» как дробь, где в числителе функция, обратная ф-и активации от 0.99(от единицы взять нельзя т.к. будет +бесконечность), а в знаменателе сумма значений модулей всех элементов входящих в выборку(вероятно, можно использовать квадратный корень из энергии). И умножается все это на -1.
Итоговая формула получается:
Для сигмоиды, которая имеет вид , обратная ф-я — , при
*Небольшая проверка
Пусть есть две пары . Рассчитаем веса по формуле приведенной выше:
Теперь «прогоним» наши вектора через получившийся нейрон, напомню формулу отклика нейрона:
Первый вектор дал результат 0.997, второй — , что очень похоже на правду.
*Тестирование
Для тестирования была взята обучающая выборка 2 сигнала без шума, 1 и 2 Гц, 200 отсчетов. Одному герцу соответствует отклик НС {0,1}, двум {1,0}.
Во время тестирования распознавался сигнал + гауссов шум. ОСШ = 0.33
Ниже представлено распознавание:
1Гц, самый хороший результат

2 Гц, самый хороший результат
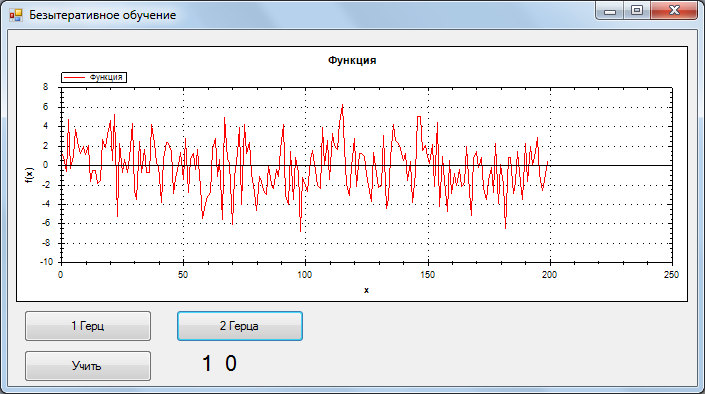
1 Гц, самый плохой результат
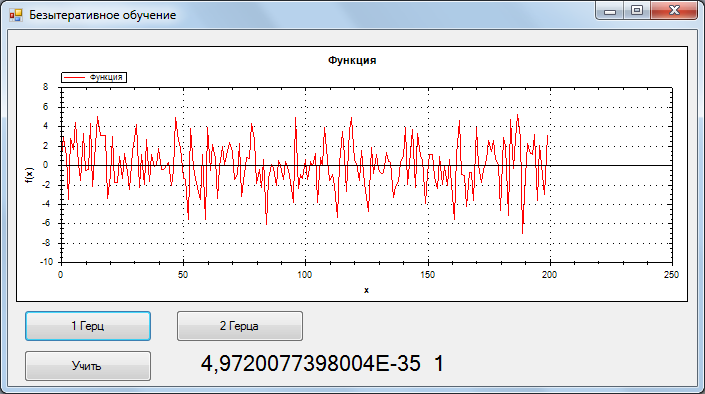
Учитывая, то что точность очень высокая(тестировал и на других сигналах). Я предполагаю, что данный метод сводит функцию ошибки в глобальный минимум.
Код обучения:
В дальнейших статьях планирую рассмотреть, обучение многослойных сетей, генерацию сетей с оптимальной архитектурой и обучение сверточных сетей.
В прошлой статье мы рассмотрели метод обучения основанный на решении СЛАУ, решать ее мы не будем т.к. это слишком трудоемкий процесс. Сейчас нас интересует из этого метода только вектор «B», в этом векторе отражено насколько важен тот или иной признак для классификации.
И тут из-за того, что имеется активационная ф-я с насыщением можно выразить веса как:
Первое, что необходимо сделать — это заменить на . Т.к. в задачи классификации «y» может быть либо 1(принадлежит), либо 0(не принадлежит). То t должно быть либо 1, либо -1. Отсюда . Теперь
Теперь выразим коэффициент «K» как дробь, где в числителе функция, обратная ф-и активации от 0.99(от единицы взять нельзя т.к. будет +бесконечность), а в знаменателе сумма значений модулей всех элементов входящих в выборку(вероятно, можно использовать квадратный корень из энергии). И умножается все это на -1.
Итоговая формула получается:
Для сигмоиды, которая имеет вид , обратная ф-я — , при
*Небольшая проверка
Пусть есть две пары . Рассчитаем веса по формуле приведенной выше:
Теперь «прогоним» наши вектора через получившийся нейрон, напомню формулу отклика нейрона:
Первый вектор дал результат 0.997, второй — , что очень похоже на правду.
*Тестирование
Для тестирования была взята обучающая выборка 2 сигнала без шума, 1 и 2 Гц, 200 отсчетов. Одному герцу соответствует отклик НС {0,1}, двум {1,0}.
Во время тестирования распознавался сигнал + гауссов шум. ОСШ = 0.33
Ниже представлено распознавание:
1Гц, самый хороший результат
2 Гц, самый хороший результат
1 Гц, самый плохой результат
Учитывая, то что точность очень высокая(тестировал и на других сигналах). Я предполагаю, что данный метод сводит функцию ошибки в глобальный минимум.
Код обучения:
public void Train(Vector[] inp, Vector[] outp)
{
OutNew = new Vector[outp.Length];
In = new Vector[outp.Length];
Array.Copy(outp, OutNew, outp.Length);
Array.Copy(inp, In, inp.Length);
for (int i = 0; i < OutNew.Length; i++)
{
OutNew[i] = 2*OutNew[i]-1;
}
K = 4.6*inp[0].N*inp.Length;
double summ = 0;
for (int i = 0; i < inp.Length; i++)
{
summ += Functions.Summ(MathFunc.abs(In[i]));
}
K /= summ;
Parallel.For(0, _neurons.Length, LoopTrain);
}
void LoopTrain(int i)
{
for (int k = 0; k < In[0].N; k++) {
for (int j = 0; j < OutNew.Length; j++)
{
_neurons[i].B.Vecktor[k] += OutNew[j].Vecktor[i]*In[j].Vecktor[k];
}
}
_neurons[i].W = K*_neurons[i].B;
}В дальнейших статьях планирую рассмотреть, обучение многослойных сетей, генерацию сетей с оптимальной архитектурой и обучение сверточных сетей.
Поделиться с друзьями
Firstprime
На данном этапе мой уровень развития не позволяет задать умный вопрос по этой теме. Но очень интересно знать сколько зарабатывает программист разбирающийся в теме статьи?
Zachar_5
Ну мне хватает))
Цифры назвать не могу.
Вообще хочу открыть свое дело на своих разработках, но это не реально сложно, вряд ли получится, но надо по пробовать. Вот мой основной проект, если интересно. Возможно и о нем напишу. Как закончу с НС.
GoldenStar
Впечатляет! Хороший уровень… просто завидую в хорошем смысле этого слова )
Хочу поработать в области оптического распознавания образов, но пока что не хватает времени, так как надо освоить железячную часть.
alexeykuzmin0
Пожалуйста, объясните, почему веса нейронов — это константа, умноженная на b?
Zachar_5
K — это нормировочный коэффициент. А b_k показывает насколько важен k-й признак для классификации.
alexeykuzmin0
Тогда почему для b_k используется именно такая функция, а не что-нибудь другое, показывающее важность признака, скажем, корреляция какая-нибудь? Это было проверено на практике и работает лучше, чем другие решения?
И, кстати, а почему берется именно f(0.99), а не f(0.98) или f(0.995)?
Zachar_5
Да было проведено несколько тестов, вообще-то до сих пор тестирую. Вариант с корреляцией был проверен, вот ссылка на него https://vk.com/ai_2016?w=wall-64012508_204.
Я изменил на f(0.999). Вообще этот коэффициент пока подбирается экспериментально. По логике он должен стремиться к +inf. Но на практике, я получил хорошие результаты когда подставил вместо f(x) 25.
alexeykuzmin0
Здорово, что эти значения были взяты именно из практики. А вы сравниваете полученные результаты с другими методами обучения той же самой модели, скажем, градиентным спуском? Было бы очень интересно посмотреть, насколько отличается качество и скорость на разных реальных задачах.
А насчет коэффициента, повышающего веса — интуитивно кажется, что чем он больше, тем выше будет качество модели, и тем проще переобучиться. Не зря же во всяких L1,2 и иже с ними штрафуют слишком большие коэффициенты.
AC130
Для линейно сепарабельного случая конкретно такая пропорциональность весов вполне может иметь место. А более сложные случаи однослойный персептрон и не должен охватывать.
Zachar_5
Ниже есть видео, там двухслойная сеть, но пока в том выражении по генерации архитектуры слишком много параметров, которые неоднозначно подбираются. Поэтому про этот метод я писать не готов, тестирую с разными параметрами. Собираю статистику. Потом планирую обобщить на любое кол-во слоев.
Zachar_5
Я имею право так делать, т.к. стоит задача классификации, а не регрессии. И имеется ф-я с насыщением, которая "сгладит" все неточности.
alexeykuzmin0
И все же непонятно, почему вы имеете право так делать. Здесь ведь нет итераций, значит, мы хотим получить точный ответ сразу, разве не так?
Zachar_5
Точный ответ для задачи классификации это 1 или 0, 1 если принадлежит выбранному классу, 0 в обратном случае. И эта формула дает такой ответ. Было проверено 4 различных формулы, у каждой есть свои плюсы и минусы, но в качестве основной была выбрана, та что используется в статье.
Вчера записал видео теста(пред. обработка БПФ):
alexeykuzmin0
Есть ли какие-то основания полагать, что та же самая формула будет оптимальна и при решении любой другой задачи классификации?
Zachar_5
Ну что тут сказать, тестирую! На MNIST`е буду сегодня завтра гонять.
Zachar_5
На MNIST плохой результат, 63%. Сейчас дорабатываю метод обучения скрытого слоя.