Выходим на финишную прямую. Чуть больше двух месяцев назад я делилась с вами вводной статьёй о том, для чего нужно машинное обучение в страховой компании и как проверялась реалистичность самой идеи. После чего мы поговорили о тестировании алгоритмов. Сегодня будет последняя статья из серии, в которой вы узнаете об улучшении модели через оптимизацию алгоритмов и их взаимодействие.

1. Реалистичность идеи.
2. Исследуем алгоритмы.
3. Улучшение модели через оптимизацию алгоритмов.
Не всегда минимальная ошибка на тренировочной выборке соответствует максимальной точности на тестовой, так как излишне сложная модель может потерять способность к обобщению.
Ошибка в машинном обучении состоит из трёх частей: Bias, Variance и Noise. С шумом (Noise), как правило, сделать ничего нельзя: он отражает влияние на результат факторов, не учитываемых в модели.
С Bias и Variance ситуация иная. Первое отображает ошибку, связанную с плохо выработанными зависимостями, уменьшается с ростом сложности и при больших значениях говорит о том, что модель недостаточно обучена. Второе отображает чувствительность модели к колебаниям в значениях входных данных, увеличивается с ростом сложности и свидетельствует о переобучении. Отсюда возникает такое понятие как bias/variance tradeoff.
Лучше всего его проиллюстрирует следующее изображение:
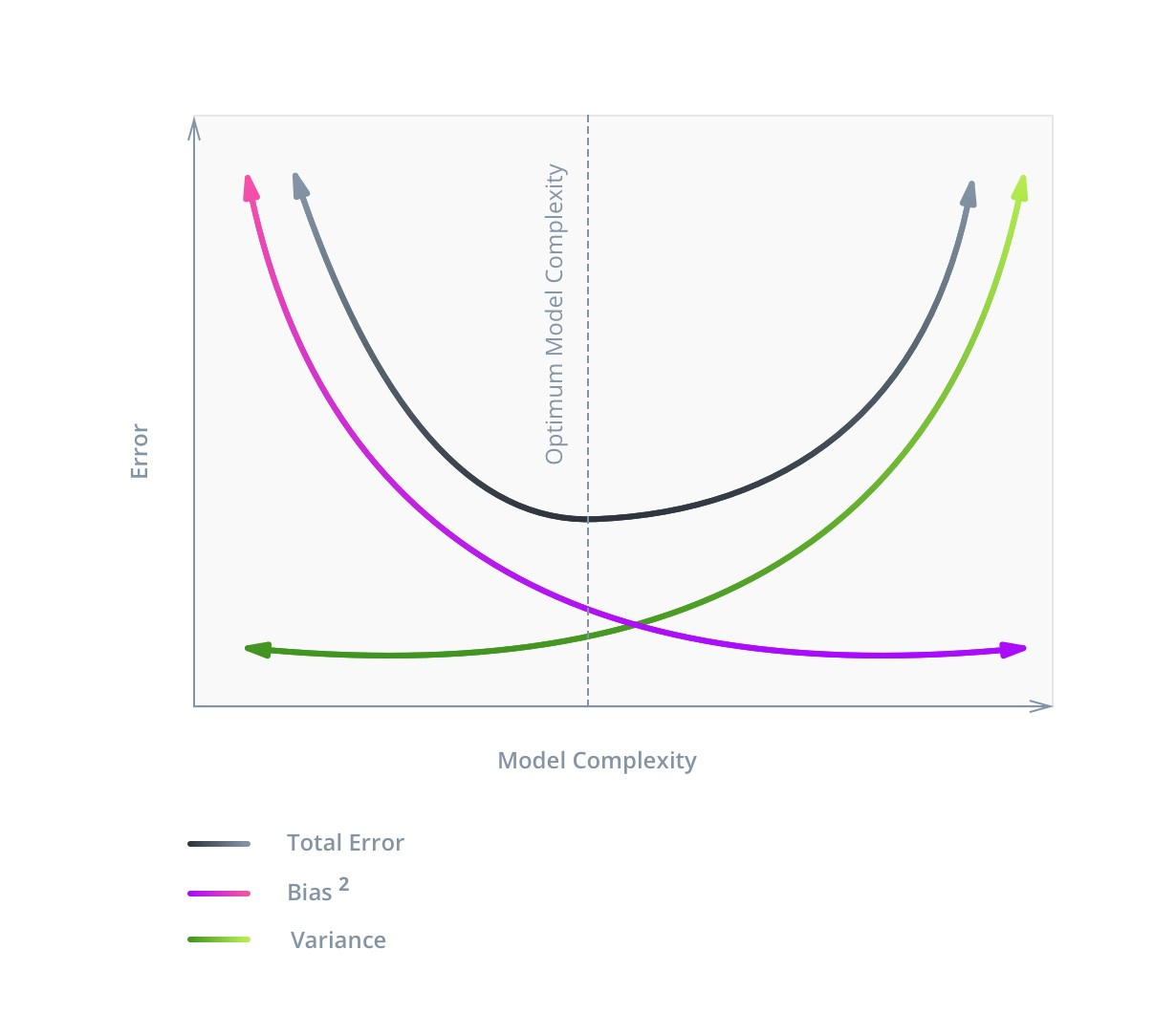
На графике видно, что оптимальная сложность модели соответствует функции C = min(V + B2), и это значение не будет соответствовать минимальному значению Bias.
Сложность модели состоит из двух частей. Первая часть общая для всех – это количество используемых признаков (или размерность входных данных). В нашем примере их немного, поэтому фильтрация вряд ли увеличит точность модели, однако сам принцип мы продемонстрируем. К тому же, всегда есть вероятность, что некоторые столбцы могут быть лишними, и их удаление не ухудшит модель. Поскольку при одинаковой точности следует выбирать более простое решение, полезным будет даже такое изменение.
В Azure ML есть несколько модулей фильтрации признаков для отсеивания наименее полезных. Мы рассмотрим Filter Based Feature Selection.
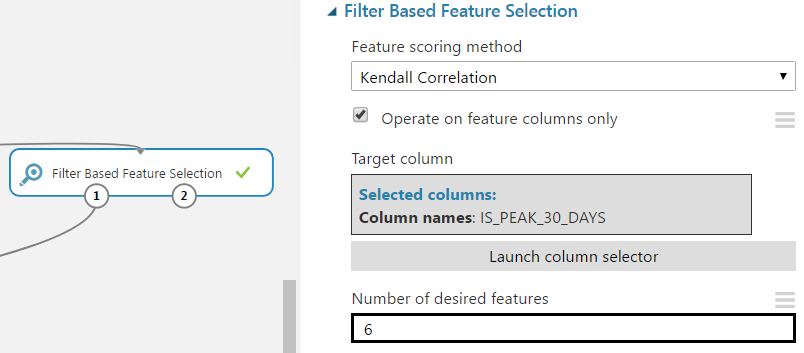
В этот модуль входят семь методов фильтрации: Pearson correlation, mutual information, Kendall correlation, Spearman correlation, chi-squared, Fisher score, count based. Возьмем Kendall correlation, поскольку данные не имеют нормального распределения и не имеют четко определенной линейной зависимости. Параметр количества желаемых признаков выставим так, чтобы в результате был убран один столбец.
Посмотрим на результаты присваивания коэффициентов схожести целевого и входных столбцов.

Столбец ageLessThan19 имеет низкий уровень корреляции с целевым, им можно пренебречь. Проверим это, обучив модель Random forest с теми же настройками, которые были использованы в примере в предыдущей статье.
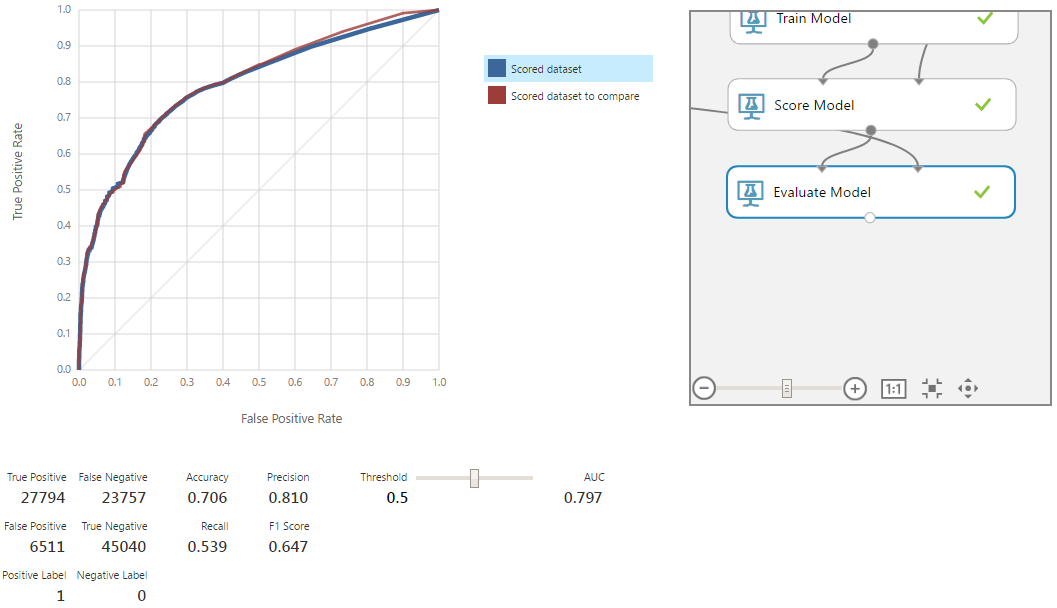
Кривая красного цвета соответствует старой модели. Удаление столбца привело к небольшому ухудшению модели, но в пределах статистической погрешности. Следовательно, удалённый столбец действительно не имел никакого значимого влияния на модель и был не нужен.
Вторая часть сложности модели зависит от выбранного алгоритма. В нашем случае это Random forest, для которого сложность, в первую очередь, определяется максимальной глубиной строящихся деревьев. Другие параметры тоже имеют значение, но в меньшей степени.
Рассмотрим модули Azure ML, которые помогут с этими задачами. Для начала, возьмём Tune Model Hyperparameters.
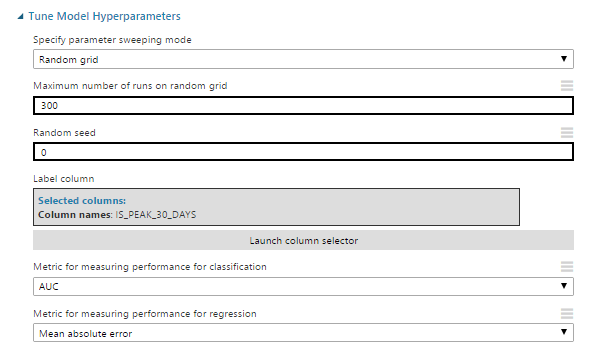
Рассмотрим его настройки:
Остальные параметры в нашем случае не имеют значения или не требуют отдельного описания.
Для корректной работы модуля в инициализации алгоритма следует изменить один из параметров, описание которого мы опустили в предыдущей статье в связи с его особым назначением. Речь идет о create trainer mode. В нем необходимо выбрать parameter range. В этом режиме можно выбрать несколько вариантов значений для численных параметров алгоритма. Также для каждого из численных параметров можно выставить режим parameter range. В нём можно выбрать диапазон, в котором будут выбираться потенциальные значения. Именно этот режим нам и нужен – Tune Model Hyperparameters использует эти диапазоны для поиска оптимальных значений. В нашем примере для экономии времени выставим диапазон только для глубины деревьев решений.

Другой модуль, который может пригодиться – Partition and Sample. В режиме assign to folds он разбивает данные на указанное количество частей. При подаче таких входных данных на модуль настройки параметров он начинает работать в режиме кросс-валидации. Остальные настройки позволяют задать количество частей, на которые будут разбиты данные, и особенности разбиения (например, ровное распределение значений по одному из столбцов).

При минимальных усилиях это позволило немного улучшить наш результат при оценке по AUC. При должных настройках и более тщательном поиске оптимальных параметров улучшение результата будет более существенным.

Теперь рассмотрим ещё один инструмент настройки обработки вывода модели. Поскольку в нашем случае рассматривается ситуация бинарной классификации, принадлежность к одному из классов определяется через граничное значение. Проверить его работу можно во вкладке модуля Evaluate. На выходе классификатора мы получаем не строгое значение класса, а уверенность в наличии «положительного» класса, которая может принимать значения от 0 до 1. Иными словами, по умолчанию, если классификатор выдает значение от 0.5, то в нашем случае предсказание о наличии пика будет положительным.
Не всегда 0.5 является оптимальной границей. В случае равноценности классов неплохим критерием может служить F1, хотя на практике это встречается редко. Предположим, что FN стоит в 2 раза дороже чем FP. Рассмотрим разные границы и оценим общую стоимость для них.
На графике ниже синим цветом обозначена общая стоимость ошибок FP, оранжевым цветом – FN, а зелёным – их сумма. Как видно, минимум общей стоимости приходится на threshold = 0.31 со значением равным ?40.4к. Для сравнения, при границе, равной 0.5, цена больше на 15к.
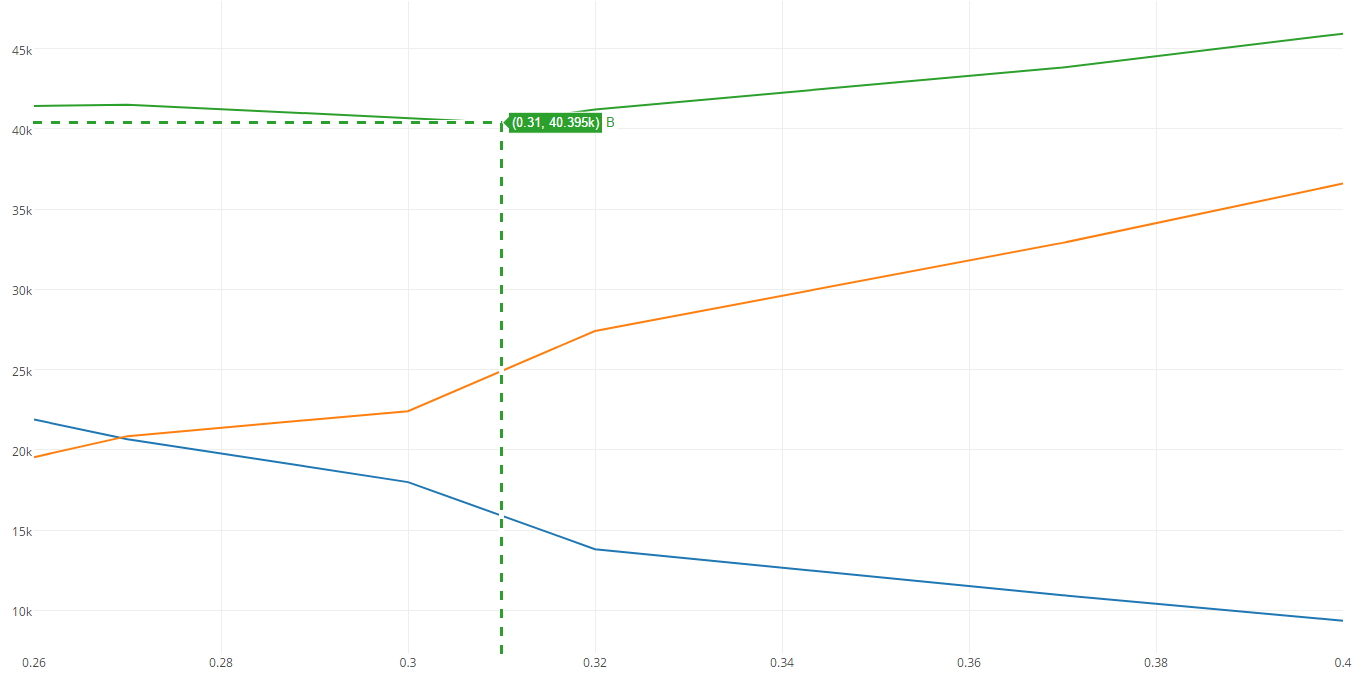
Для наглядности посчитаем минимум стоимости для модели без убранного ранее столбца.

На иллюстрации видно что, стоимость больше. Разница невелика, но даже такого примера достаточно, чтобы показать, что большее количество признаков далеко не всегда даёт лучшую модель.
Выбросы могут иметь критическое влияние на результаты обучения модели. Если используемый метод не является робастным, они могут крайне негативно воздействовать на результат.
В качестве примера можно рассмотреть следующий случай.
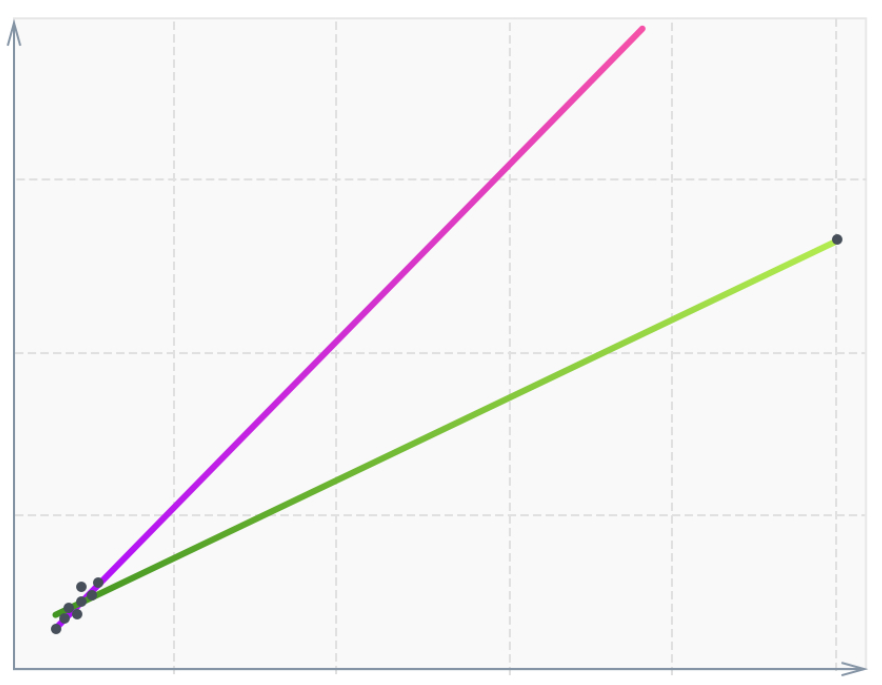
Хотя большая часть данных сосредоточена на диагонали, одна-единственная точка, находясь достаточно далеко от остальных, меняет наклон функции (зелёная). Подобные точки называются high-leverage points. Часто они связаны с ошибками измерения или записи данных. Это только один из видов стат-выбросов и их влияния на модель. В нашем случае выбранная модель робастна, поэтому такого влияния на неё не будет. Но убрать аномальные данные в любом случае стоит.
Чтобы найти эти точки, можно использовать модуль Clip Values. Он обрабатывает данные, которые выходят за обозначенные пределы, и может либо подставить в них другое значение, либо пометить их как отсутствующие. Для чистоты эксперимента проведём данную операцию только для тренировочных записей.

Через модуль очистки недостающих значений можно убрать строки с отсутствующими данными, получив фильтрованный от аномалий массив.
Проверим точность на новом наборе данных.
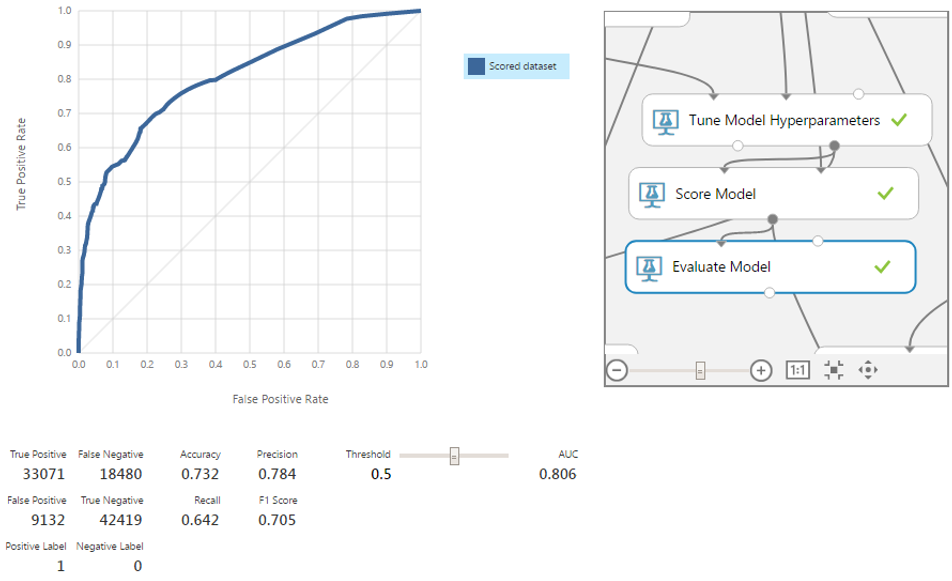
Модель стала немного лучше по всем 4-м пунктам. Стоит напомнить, что рассматриваемый нами алгоритм робастный. В определённых ситуациях удаление статистических выбросов даст ещё больший прирост в точности.
Комитет объединяет несколько моделей в одну для получения лучших результатов, чем может предоставить каждая из них в отдельности. Да, используемый нами алгоритм сам по себе является комитетом, поскольку заключается в построении множества различных деревьев решений и объединении их результатов в один. Однако не обязательно на этом останавливаться.
Рассмотрим один из простейших и, в то же время, популярных и эффективных способов объединения – stacked generalization. Его суть в использовании выходов разных алгоритмов как признаков для модели более высокого (с точки зрения иерархии) уровня. Как и любой другой комитет, он не гарантирует улучшения результата. Однако полученные через него модели, как правило, проявляют себя как более точные. Для нашего примера возьмём ряд алгоритмов для бинарной классификации, представленных в Azure ML Studio: Averaged Perceptron, Bayes Point Machine, Boosted Decision Tree, Random Forest, Decision Jungle и Logistic Regression. На данном этапе уже не будем вдаваться в их подробности – проверим работу комитета.
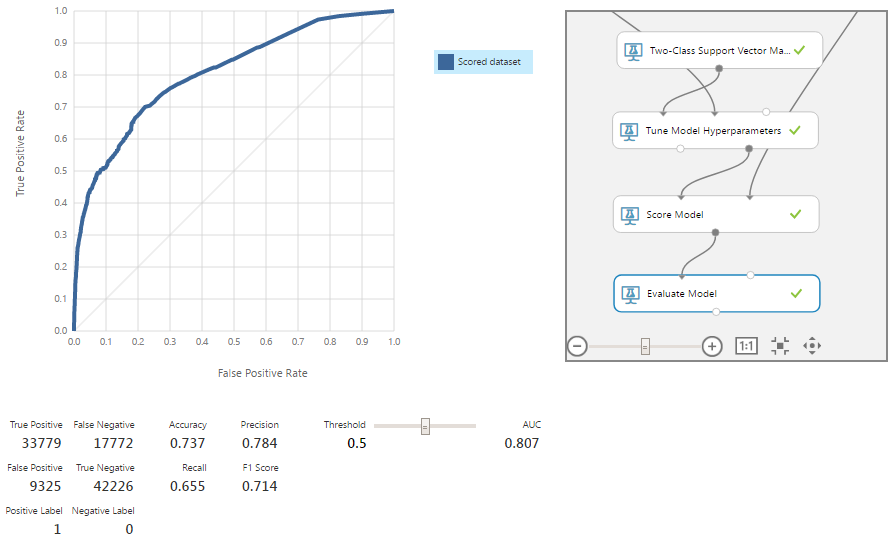
В результате получаем ещё одно небольшое улучшение модели по всем метрикам. Теперь вспомним, что классы в нашей модели не равноценны, и мы приняли, что FN в 2 раза дороже FP. Чтобы найти оптимальную точку, проверим разные значения threshold.

Минимум суммы стоимости ошибок находится на границе, равной 0.29, и достигает 40.2. Это всего на 0.2 меньше показателя, полученного до удаления аномалий и расчётов через комитет. Конечно, многое зависит от того, какой будет реальный денежный эквивалент этой разницы. Но чаще при таком незначительном улучшении имеет смысл воспользоваться принципом бритвы Оккама и выбрать чуть менее точную, но более простую по архитектуре модель, которую мы имели после настройки параметров модулем Tune Model Hyperparameters с минимальной стоимостью ошибок, равной 40.4.
В заключительной части цикла статей о машинном обучении мы рассмотрели:
В этой серии статей мы представили упрощённую версию системы предсказания затрат, которая была реализована в рамках комплексного решения для страховой компании. На демонстрационной модели мы описали большую часть шагов, необходимых для решения подобного рода задач: построение прототипа, анализ и обработку данных, выбор и настройку алгоритмов и другие задачи.
Также мы рассмотрели один из важнейших аспектов – выбор сложности модели. Финальная полученная структура давала наилучшие результаты в рамках метрик точности, f1-score и других. Однако при оценке потерь от ложноположительных и ложноотрицательных результатов она давала весьма незначительный профит. В связи с этим, не такая сложная модель, описанная в начале этой статьи, выглядит более привлекательно.
Это далеко не все возможности машинного обучения в подобных задачах, но мы сознательно упростили демонстрационную модель для большей наглядности и, отчасти, по причине NDA. Не вошедшие в статью особенности модели специфичны для бизнеса клиента и мало применимы к другим проектам, поскольку большинство решений на основе машинного обучения требуют индивидуального подхода. Полный вариант системы используется в реальном проекте нашего заказчика, и мы продолжаем улучшать его.
Команда WaveAccess создаёт технически сложное, высоконагруженное и отказоустойчивое программное обеспечение для компаний из разных стран. Комментарий Александра Азарова, руководителя направления machine learning в WaveAccess:
Цикл статей «Машинное обучение для страховой компании»
1. Реалистичность идеи.
2. Исследуем алгоритмы.
3. Улучшение модели через оптимизацию алгоритмов.
Настройка сложности модели и границы определения классов
Не всегда минимальная ошибка на тренировочной выборке соответствует максимальной точности на тестовой, так как излишне сложная модель может потерять способность к обобщению.
Ошибка в машинном обучении состоит из трёх частей: Bias, Variance и Noise. С шумом (Noise), как правило, сделать ничего нельзя: он отражает влияние на результат факторов, не учитываемых в модели.
С Bias и Variance ситуация иная. Первое отображает ошибку, связанную с плохо выработанными зависимостями, уменьшается с ростом сложности и при больших значениях говорит о том, что модель недостаточно обучена. Второе отображает чувствительность модели к колебаниям в значениях входных данных, увеличивается с ростом сложности и свидетельствует о переобучении. Отсюда возникает такое понятие как bias/variance tradeoff.
Лучше всего его проиллюстрирует следующее изображение:
На графике видно, что оптимальная сложность модели соответствует функции C = min(V + B2), и это значение не будет соответствовать минимальному значению Bias.
Сложность модели состоит из двух частей. Первая часть общая для всех – это количество используемых признаков (или размерность входных данных). В нашем примере их немного, поэтому фильтрация вряд ли увеличит точность модели, однако сам принцип мы продемонстрируем. К тому же, всегда есть вероятность, что некоторые столбцы могут быть лишними, и их удаление не ухудшит модель. Поскольку при одинаковой точности следует выбирать более простое решение, полезным будет даже такое изменение.
В Azure ML есть несколько модулей фильтрации признаков для отсеивания наименее полезных. Мы рассмотрим Filter Based Feature Selection.
В этот модуль входят семь методов фильтрации: Pearson correlation, mutual information, Kendall correlation, Spearman correlation, chi-squared, Fisher score, count based. Возьмем Kendall correlation, поскольку данные не имеют нормального распределения и не имеют четко определенной линейной зависимости. Параметр количества желаемых признаков выставим так, чтобы в результате был убран один столбец.
Посмотрим на результаты присваивания коэффициентов схожести целевого и входных столбцов.
Столбец ageLessThan19 имеет низкий уровень корреляции с целевым, им можно пренебречь. Проверим это, обучив модель Random forest с теми же настройками, которые были использованы в примере в предыдущей статье.
Кривая красного цвета соответствует старой модели. Удаление столбца привело к небольшому ухудшению модели, но в пределах статистической погрешности. Следовательно, удалённый столбец действительно не имел никакого значимого влияния на модель и был не нужен.
Вторая часть сложности модели зависит от выбранного алгоритма. В нашем случае это Random forest, для которого сложность, в первую очередь, определяется максимальной глубиной строящихся деревьев. Другие параметры тоже имеют значение, но в меньшей степени.
Рассмотрим модули Azure ML, которые помогут с этими задачами. Для начала, возьмём Tune Model Hyperparameters.
Рассмотрим его настройки:
- Specify parameter-sweeping mode – выставляем режим поиска (в данном случае, random grid). Поиск производится в пределах значений, заданных на этапе инициализации алгоритма.
- Maximum number of runs on random grid – количество тестируемых вариантов комбинаций параметров для обучения модели.
- Metric for measuring performance for classification – выбор из метрики как целевого значения для оптимизации задач классификации.
Остальные параметры в нашем случае не имеют значения или не требуют отдельного описания.
Для корректной работы модуля в инициализации алгоритма следует изменить один из параметров, описание которого мы опустили в предыдущей статье в связи с его особым назначением. Речь идет о create trainer mode. В нем необходимо выбрать parameter range. В этом режиме можно выбрать несколько вариантов значений для численных параметров алгоритма. Также для каждого из численных параметров можно выставить режим parameter range. В нём можно выбрать диапазон, в котором будут выбираться потенциальные значения. Именно этот режим нам и нужен – Tune Model Hyperparameters использует эти диапазоны для поиска оптимальных значений. В нашем примере для экономии времени выставим диапазон только для глубины деревьев решений.
Другой модуль, который может пригодиться – Partition and Sample. В режиме assign to folds он разбивает данные на указанное количество частей. При подаче таких входных данных на модуль настройки параметров он начинает работать в режиме кросс-валидации. Остальные настройки позволяют задать количество частей, на которые будут разбиты данные, и особенности разбиения (например, ровное распределение значений по одному из столбцов).
При минимальных усилиях это позволило немного улучшить наш результат при оценке по AUC. При должных настройках и более тщательном поиске оптимальных параметров улучшение результата будет более существенным.
Теперь рассмотрим ещё один инструмент настройки обработки вывода модели. Поскольку в нашем случае рассматривается ситуация бинарной классификации, принадлежность к одному из классов определяется через граничное значение. Проверить его работу можно во вкладке модуля Evaluate. На выходе классификатора мы получаем не строгое значение класса, а уверенность в наличии «положительного» класса, которая может принимать значения от 0 до 1. Иными словами, по умолчанию, если классификатор выдает значение от 0.5, то в нашем случае предсказание о наличии пика будет положительным.
Не всегда 0.5 является оптимальной границей. В случае равноценности классов неплохим критерием может служить F1, хотя на практике это встречается редко. Предположим, что FN стоит в 2 раза дороже чем FP. Рассмотрим разные границы и оценим общую стоимость для них.
На графике ниже синим цветом обозначена общая стоимость ошибок FP, оранжевым цветом – FN, а зелёным – их сумма. Как видно, минимум общей стоимости приходится на threshold = 0.31 со значением равным ?40.4к. Для сравнения, при границе, равной 0.5, цена больше на 15к.
Для наглядности посчитаем минимум стоимости для модели без убранного ранее столбца.
На иллюстрации видно что, стоимость больше. Разница невелика, но даже такого примера достаточно, чтобы показать, что большее количество признаков далеко не всегда даёт лучшую модель.
Поиск статистических выбросов
Выбросы могут иметь критическое влияние на результаты обучения модели. Если используемый метод не является робастным, они могут крайне негативно воздействовать на результат.
В качестве примера можно рассмотреть следующий случай.
Хотя большая часть данных сосредоточена на диагонали, одна-единственная точка, находясь достаточно далеко от остальных, меняет наклон функции (зелёная). Подобные точки называются high-leverage points. Часто они связаны с ошибками измерения или записи данных. Это только один из видов стат-выбросов и их влияния на модель. В нашем случае выбранная модель робастна, поэтому такого влияния на неё не будет. Но убрать аномальные данные в любом случае стоит.
Чтобы найти эти точки, можно использовать модуль Clip Values. Он обрабатывает данные, которые выходят за обозначенные пределы, и может либо подставить в них другое значение, либо пометить их как отсутствующие. Для чистоты эксперимента проведём данную операцию только для тренировочных записей.
Через модуль очистки недостающих значений можно убрать строки с отсутствующими данными, получив фильтрованный от аномалий массив.
Проверим точность на новом наборе данных.
Модель стала немного лучше по всем 4-м пунктам. Стоит напомнить, что рассматриваемый нами алгоритм робастный. В определённых ситуациях удаление статистических выбросов даст ещё больший прирост в точности.
Использование комитета (ансамбля) классификаторов
Комитет объединяет несколько моделей в одну для получения лучших результатов, чем может предоставить каждая из них в отдельности. Да, используемый нами алгоритм сам по себе является комитетом, поскольку заключается в построении множества различных деревьев решений и объединении их результатов в один. Однако не обязательно на этом останавливаться.
Рассмотрим один из простейших и, в то же время, популярных и эффективных способов объединения – stacked generalization. Его суть в использовании выходов разных алгоритмов как признаков для модели более высокого (с точки зрения иерархии) уровня. Как и любой другой комитет, он не гарантирует улучшения результата. Однако полученные через него модели, как правило, проявляют себя как более точные. Для нашего примера возьмём ряд алгоритмов для бинарной классификации, представленных в Azure ML Studio: Averaged Perceptron, Bayes Point Machine, Boosted Decision Tree, Random Forest, Decision Jungle и Logistic Regression. На данном этапе уже не будем вдаваться в их подробности – проверим работу комитета.
В результате получаем ещё одно небольшое улучшение модели по всем метрикам. Теперь вспомним, что классы в нашей модели не равноценны, и мы приняли, что FN в 2 раза дороже FP. Чтобы найти оптимальную точку, проверим разные значения threshold.
Минимум суммы стоимости ошибок находится на границе, равной 0.29, и достигает 40.2. Это всего на 0.2 меньше показателя, полученного до удаления аномалий и расчётов через комитет. Конечно, многое зависит от того, какой будет реальный денежный эквивалент этой разницы. Но чаще при таком незначительном улучшении имеет смысл воспользоваться принципом бритвы Оккама и выбрать чуть менее точную, но более простую по архитектуре модель, которую мы имели после настройки параметров модулем Tune Model Hyperparameters с минимальной стоимостью ошибок, равной 40.4.
Итоги
В заключительной части цикла статей о машинном обучении мы рассмотрели:
- Настройку сложности модели и выбор оптимального значения threshold.
- Поиск и удаление статистических выбросов из тренировочных данных.
- Построение комитета из нескольких алгоритмов.
- Выбор конечной структуры модели.
В этой серии статей мы представили упрощённую версию системы предсказания затрат, которая была реализована в рамках комплексного решения для страховой компании. На демонстрационной модели мы описали большую часть шагов, необходимых для решения подобного рода задач: построение прототипа, анализ и обработку данных, выбор и настройку алгоритмов и другие задачи.
Также мы рассмотрели один из важнейших аспектов – выбор сложности модели. Финальная полученная структура давала наилучшие результаты в рамках метрик точности, f1-score и других. Однако при оценке потерь от ложноположительных и ложноотрицательных результатов она давала весьма незначительный профит. В связи с этим, не такая сложная модель, описанная в начале этой статьи, выглядит более привлекательно.
Это далеко не все возможности машинного обучения в подобных задачах, но мы сознательно упростили демонстрационную модель для большей наглядности и, отчасти, по причине NDA. Не вошедшие в статью особенности модели специфичны для бизнеса клиента и мало применимы к другим проектам, поскольку большинство решений на основе машинного обучения требуют индивидуального подхода. Полный вариант системы используется в реальном проекте нашего заказчика, и мы продолжаем улучшать его.
Об авторах
Команда WaveAccess создаёт технически сложное, высоконагруженное и отказоустойчивое программное обеспечение для компаний из разных стран. Комментарий Александра Азарова, руководителя направления machine learning в WaveAccess:
Машинное обучение позволяет автоматизировать области, где на текущий момент доминируют экспертные мнения. Это дает возможность снизить влияние человеческого фактора и повысить масштабируемость бизнеса.
Поделиться с друзьями
Dmitry_5
Страхование должно понять, что основные риски внутри. Недобросовестные сотрудники, руководство, гадящее бизнесу и клиенты-мошенники. Никакие матмодели и бигдаты не помогут.
Alexazspb
Вопросы связанные с преднамеренным мошенничеством конечно же важны, но для них существуют отдельные решения. Эта система в первую очередь нацелена на снижение влияния человеческого фактора при оценке рисков. В некоторых случаях она позволяет предсказать возможные проблемы со здоровьем у клиентов и направить их на раннюю диагностику, что выгодно обеим сторонам.