
В предыдущей статье я рассказывала, как в нашей компании проходит первая стадия тестирования проекта — анализ. Сегодня расскажу о следующем этапе — проектирования и документирования тестов.
Этот этап опционален. На некоторых проектах нет задокументированных требований, и тогда зачастую поддержка тестовой документации является единственным разумным способом хранения и передачи знаний о продукте. Иногда тестовую документацию требует заказчик, иногда мы пишем ее для себя. Иногда, если у нас есть хорошо написанные требования, мы отказываемся от документирования тестов в пользу экономии ресурсов.
Вид тестовой документации также зависит от ситуации на проекте и ожиданий заказчика.
Чек-листы vs Тест-кейсы
Чек-лист отличается от тест-кейса степенью подробности. В чек-листе вы не встретите подробных шагов кейса, для использования чек-листа при тестировании очень много информации нужно держать в голове в момент прогона тестов и знать логику работы приложения на отлично.
В нашей компании всегда использовались чек-листы, поскольку на написание тест-кейсов уходит неоправданно много времени, и они тяжеловесны — на прочтение кейса и его осознание тоже уходит время. Кроме того, не стоит забывать про эффект пестицида — баги кода имеют свойство приспосабливаться к тестам. При использовании чек-листа сохраняется некоторая свобода действий, а тест-кейсы этой свободы полностью лишают, увеличивая упомянутый выше эффект. Однако, при прогоне чек-листа в седьмой раз за последние сутки перед релизом часть функциональности, заложенной под одним пунктом чек-листа, теряется по причине человеческого фактора.
Было принято решение расширять чек-листы и делать их подробнее. Так тестировщик, в беспамятстве прогоняющий фичу перед релизом, не забудет проверить ошибки сети в ответ на каждый запрос, не потеряет проверку какой-нибудь «неважной» кнопки или какого-нибудь одного статуса из двенадцати. Так мы пришли к написанию подробной юзер-стори, полностью покрывающей фичу приложения, но по факту являющей собой один громадный тест-кейс.
Плюсы такого подхода:
- чек-лист подразумевает непрерывное выполнение его тестировщиком. Соответственно, все кейсы расположены в порядке, удобном для прогона, и времени на переход к следующему кейсу не тратится
- чек-лист покрывает большое количество пользовательских сценариев
- чек-лист содержит как позитивные, так и негативные кейсы. Проверяет восстановление после ошибок и прерываний, что в случае мобильных приложений очень важно
- чек-лист подразумевает длинные сессии, что повышает вероятность обнаружения утечек памяти и навигационных проблем
- информация о требованиях поступает тестировщику последовательно, что дает лучшее понимание логики работы приложения
Минусы такого подхода:
- чек-лист подразумевает декомпозицию по экранам приложения и сильно завязан на дизайн. Соответственно, все изменения в дизайне подразумевают изменения в чек-листе
- с учетом, что кейсы такого чек-листа должны быть связаны в единую стори, а кейсов в одном чек-листе может быть до двух сотен, поддерживать его сложно
- эффект пестицида значительно повышается
- чек-лист не может заменить требования для разработчиков — разрабатывать по таким требованиям неудобно
- чек-лист довольно долго писать и из-за его громоздкости его не всегда удобно использовать — по факту он пригождается только в финале перед релизом
Долгое время мы жили так. Вели свои чек-листы в системе тест-менеджмента Sitechko. Но компания менялась, менялись бизнес-процессы, и вопрос о переходе на другую TMS висел в воздухе. Он стал толчком для пересмотра процесса ведения тестовой документации.
Таблицы vs Деревья
Однажды я выпила поливитаминов, и меня осенило, что вместо того, чтобы хранить тесты в табличных форматах, куда удобнее использовать деревья, а точнее, вложенные списки. Ведь при написании той самой большой юзер-стори мы так часто сталкиваемся с проблемой, что не знаем, где расположить альтернативные действия. Например, когда у нас несколько кнопок на алерте. Чтобы проверить каждую из них, нам приходится прописывать вызов этого алерта несколько раз. Вместо этого мы могли бы подвесить проверку каждой из кнопок к вызову алерта.
В целом идея была в том, чтобы прописывать те же самые пользовательские сценарии в виде дерева, в котором переход — это действие, а узел — это состояние, в котором оказывается приложение после этого действия. По факту диаграмма состояний-переходов, только объектами выступают экраны приложения. Каждая ветвь такого дерева — тест-кейс.
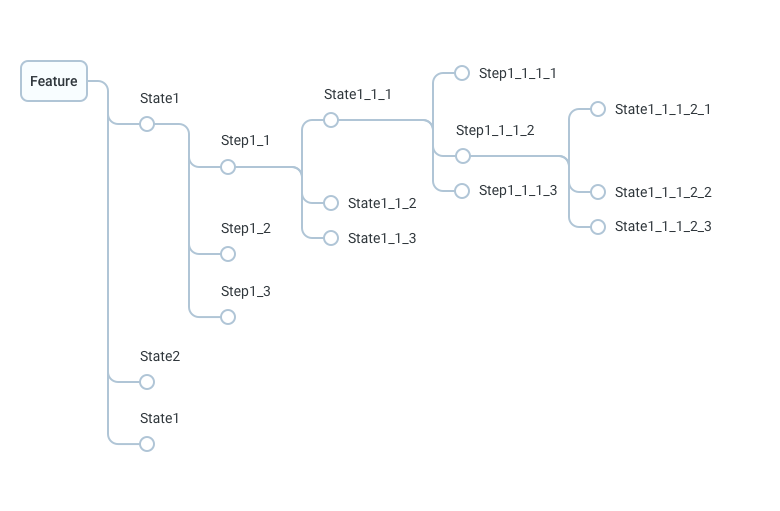
Когда стали пробовать, столкнулись с проблемами. Оказалось, что привычная нам декомпозиция по экранам приложения не работает: опираться на дизайн при проектировании тестов неудобно. Ветки дерева росли далеко в глубину, и это было неудобно визуально. В погоне за сценарием мы воротили циклы. А еще стало понятно, что отказаться от таблиц нельзя.
Решение крылось в смене подхода к декомпозиции, большей осознанности и отказе от «решений по умолчанию». Древовидная структура тестовой документации действительно удобна, поскольку дает большую свободу при проектировании. Вид декомпозиции определяет, что именно станет узлами нашего дерева. А это в свою очередь определяется особенностями продукта и приоритетами заказчика.
В целом, плюсы использования древовидной структуры:
- структура такой документации в итоге очень гибкая и позволяет вести как чек-листы, так и тест-кейсы в зависимости от нужд проекта
- дерево представляется в виде вложенных списков: у узлов дерева есть некоторый порядок, что сохраняет возможность последовательной и структурированной передачи информации о требованиях тестировщику в случае отсутствия на проекте задокументированного ТЗ
- такая структура позволяет спроектировать тестовую документацию, которую можно передать разработчикам вместо ТЗ
- временные затраты на написание чек-листов и тест-кейсов снижаются, поскольку структура позволяет избежать копипасты
Минусы подхода:
- такая структура тестовой документации требует тщательного проектирования и предварительной аналитики — при плохом проектировании все упомянутые выше плюсы теряются
Итоговые паттерны
Экраны приложения
Источником знаний является навсхема. Первый уровень дерева составляет список кейсов навсхемы, который обычно соответствует разделам приложения. Далее к ним подвешивается список экранов каждого раздела, к каждому экрану — список его состояний. В каждом узле дерева, начиная с третьего уровня, может содержаться чек-лист в табличном формате, описывающий каждый элемент дизайна и способы взаимодействия с ним. Если элементы дизайна сложные и имеют много состояний или на экране есть повторяющиеся элементы, можно декомпозировать еще глубже. Таким образом, одна ветвь дерева описывает жизненный цикл одного экрана.
Ниже в качестве примера приведена общая схема рассуждений при декомпозиции раздела заказов агрегатора авиабилетов.


К листьям этого дерева крепим короткие чек-листы. Так к каждому листу «навбар» линкуем чек-лист на элементы навбара для текущего экрана:

А к каждому листу «секция запланированные поездки» линкуем чек-лист на проверку части списка с активными заказами:

Критерии для выбора такого паттерна следующие:
- UI является приоритетным для заказчика
- минимум бизнес-логики на клиенте
- для приложения характерны кастомные элементы дизайна и анимации, сложные жесты
- на проекте нет других задокументированных требований кроме навсхемы
Объекты/действия
При таком подходе ориентируемся не на навсхему, а на документацию АПИ и клиентскую бизнес-логику. Негативные и позитивные кейсы разбиваем по разным веткам. Желательно, чтобы элементы одного уровня дерева отвечали на один вопрос, но можно оставить это ограничение только для одного уровня иерархии.
Такая схема крайне удобна в тех случаях, когда у нас есть активное влияние пользователей друг на друга, что порождает сложные сценарные цепочки. Примером может служить чат. Относительно предыдущего подхода такую документацию легче поддерживать, поскольку изменения в логике случаются реже, чем в дизайне.
Ниже приведен пример общей схемы рассуждений при декомпозиции по принципу объект/действие.
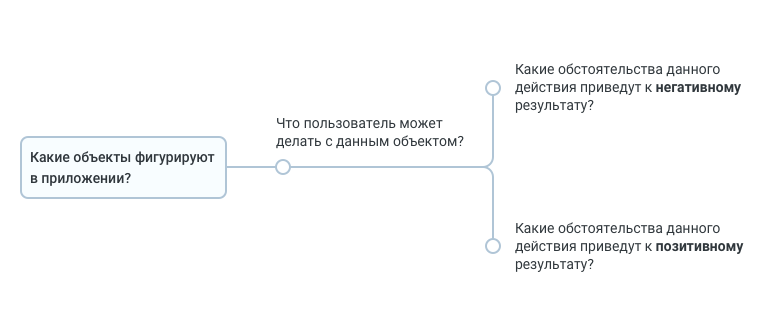

В такой схеме дополнительным бонусом является возможность использовать ее как карту для исследовательского тестирования и для смоук-теста. Степень подробности тестирования можно регулировать, отсекая при прогоне уровни дерева, поскольку каждый следующий уровень уточняет предыдущий. При углублении в ветвь дерева — углубляешься в функциональность.
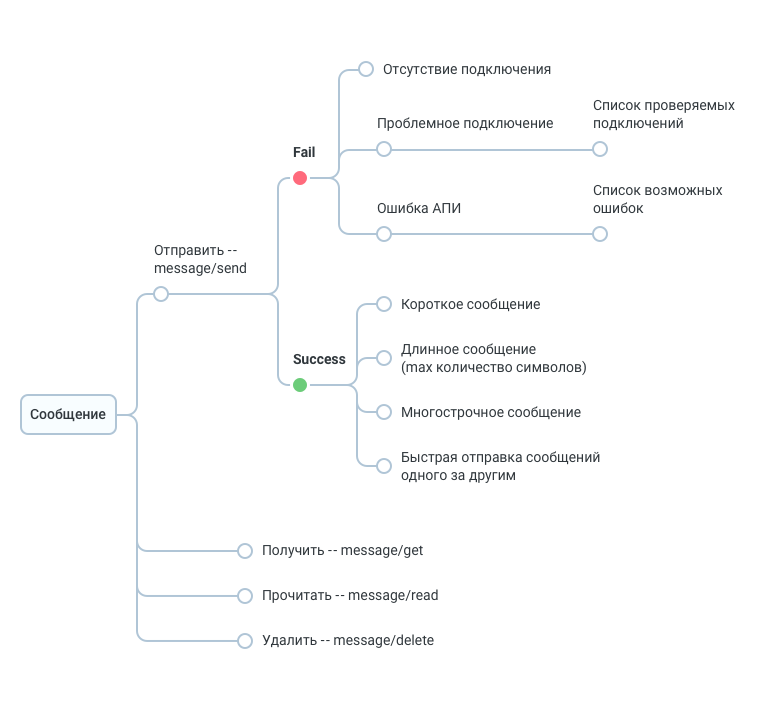
Например, для уже упомянутого чата схема документации будет выглядеть примерно так:
Критерии выбора такого паттерна:
- цель — протестировать функциональность
- сложная бизнес-логика
- частые правки дизайна
- стратегия тестирования на проекте подразумевает сочетание скриптового и исследовательского тестирования
На базе Use cases
Бывают ситуации, в которых нерентабельно декомпозировать функциональность и проектировать тесты по двум описанным ранее схемам. Например, если мы хотим покрыть тестами длительную работу с приложением – как в случае с лентой соцсети или прослушиванием музыки в бекграунде. Или когда фича завязана на сценарии с малым количеством альтернатив – например, оформление подписки на контент. В таком случае пользуемся третьим паттерном, основанном на пользовательских сценариях.
Сначала декомпозируем функциональность по use-кейсам. Определяемся с тем, какие действующие лица могут участвовать в процессе работы с приложением и какие цели они могут перед собой ставить. За это будут отвечать первые два уровня нашего дерева. Далее пытаемся найти все возможные входные условия, которые могут повлиять на отработку сценария по достижению текущей цели, и структурируем их в дереве. Их так же удобнее всего делить на позитивные и негативные. Далее к каждому листу подвешиваем сценарный чек-лист на проверку функциональности, отвечающей за достижение цели.
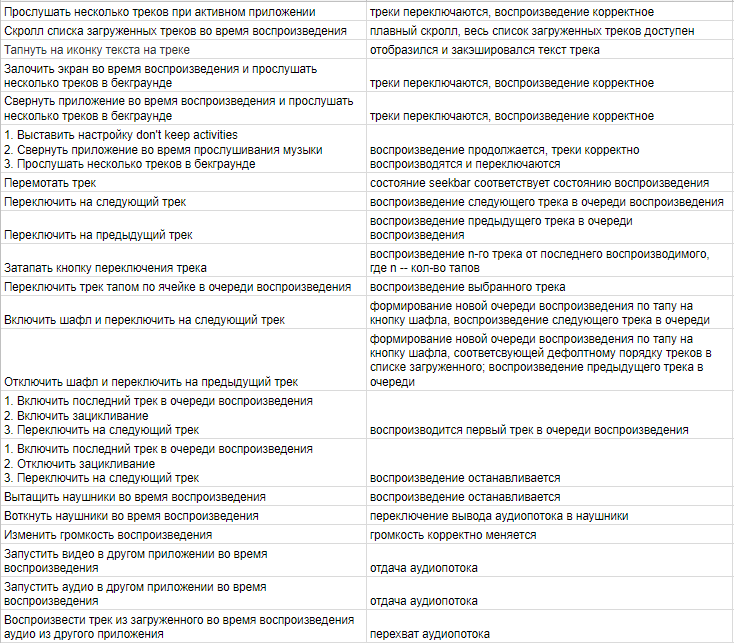
В качестве примера ниже приведена схема для музыкального плеера с функцией загрузки треков для прослушивания офлайн:


Здесь ко всем листьям позитивного сценария подвешиваем чек-лист, который нужно будет прогонять в условиях разных подключений к сети:
Бывает так, что при продумывании возможных use-кейсов цели пользователей получаются очень глобальными. Например, в уже упомянутом агрегаторе авиабилетов цель «купить билет» может поставить в тупик обилием возможных вариантов предусловий и количеством шагов, которые необходимо пройти для достижения цели. Кроме того, в таком приложении очень многое зависит от поведения сторонних систем, что накладывает некоторые ограничения на определение всех предусловий и однозначно выполняемого сценария. Предложения поступают от разных авиакомпаний и могут измениться в любую минуту. В каждый момент времени невозможно гарантировать, что покупка билета пройдет успешно, поскольку этот билет может оказаться куплен, пока мы заполняли данные для брони.
Решение первой проблемы заключается в более детальной декомпозиции. То есть большую цель «купить билет» можно разбить на маленькие цели, соответствующие шагам оформления — «ознакомиться с предложениями», «заполнить данные пассажиров», «оплатить заказ». И далее находить набор возможных предусловий, действий пользователя и результатов для этих маленьких целей.
Решение второй проблемы менее очевидно. Это в целом ограничение use-кейса — в случае, если поведение системы не определяется действиями пользователя однозначно, возникают проблемы с покрытием и проектированием use-кейсов. Для себя решили, что в таких ситуациях мы стараемся прописать все возможные варианты поведения систем, неподвластных пользователю, как предусловия, и тем самым снижаем неопределенность результата выполнения сценария. Либо используем другую схему проектирования тестовой документации.
Критерии выбора такого паттерна:
- для заказчика приоритетом является корректная работа определенных пользовательских сценариев
- приложение содержит экраны, на которых пользователь проведет много времени, потребляя контент
- приложение содержит фичи, заключающиеся в отработке линейного сценария
- стратегия тестирования на проекте подразумевает скриптовое тестирование
- простая бизнес-логика, легко покрываемая use-кейсами
Описанные выше паттерны можно и нужно комбинировать. В большом приложении с высокими требованиями к качеству обязательно встретятся как фичи, которые оптимально разбить по объекту/действию, так и фичи, требующие сценарного описания по use-кейсам. И точно так же в таком приложении могут обнаружиться экраны, для которых необходимо прописать все состояния элементов и всевозможные пользовательские взаимодействия с ними. Поэтому необязательно выбирать одну единую схему документации для всего приложения в целом, лучше всегда смотреть по обстоятельствами.
Отталкиваемся от цели
Мы сменили инструмент и выработали новые подходы к ведению тестовой документации, но от старых подходов не отказывались. Выбор стратегии зависит от потребностей на проекте и приоритетов заказчика. Если логика приложения простая и проект длится недолго, то обычно достаточно стандартных чек-листов на функциональность с минимальной подробностью. Если проект большой, сложный и без требований, то на часть фич стоит написать полноценную «древовидную» документацию. Если на проекте есть хорошо задокументированные требования, то иногда можно не тратить время на написание тестов по функциональности, зато можно уделить больше внимания нефункциональному тестированию (производительности, безопасности) и систематизировать его – опять же, если есть соответствующая договоренность с заказчиком. Или задокументировать только «рискованные» тесты. Юзер-стори все равно пишем почти всегда, но уже не такие подробные — как приемку для заказчика или как смоук-тест, а проведенная до этого работа по декомпозиции помогает нам быстро проектировать сценарий и правильно расставлять приоритеты.
Наличие тестовой документации на проекте позволяет зафиксировать информацию о требованиях, заранее продумать и структурировать тесты, снизить порог вхождения в проект нового тестировщика, снизить риски пропуска ошибок из-за человеческого фактора. Однако, написание и поддержка тестовой документации требуют ресурсов, которые не всегда возможно или не всегда оправданно тратить.
Комментарии (9)

ekiyasheva
06.08.2017 14:04+1есть ряд вопросов:
— само собой интересен инструмент. Что за инструмент, возможен ли совместный доступ, как помечаются приоритеты кейсов, можно ли фильтровать кейсы по типам, например, для прогона регрессии или части сценариев?
— как Вы тестируете, только черным ящиком или серым тоже. Если и серым, то где фиксируете описание и связи компонент, относящиеся ко все фиче, а не отдельным use case
— используете ли систему управления тестами. Если да, то какую — интересно, как Вы помечаете прогоны тестов в древовидной структуре.
— и наконец, какой у Вас жизненный цикл разработки продуктов, в которых используется древовидная документация. Сколько времени длится релиз, какую часть из него занимает тестирование
все это необходимо для понимания, насколько Ваша практика применима
EgorHMG
08.08.2017 18:36Практика более чем применима. В своё время только столкнулся с тем, что на масштабных проектах быстрей всё это делать в табличном виде. Для деревьев использовал mindmeister, в котором есть групповой доступ. Помечать прогоны там не очень удобно ибо цикла после пятого просто начинает копиться свалка. В общем, будет специальный софт — будут и деревья.

kika361 Автор
13.08.2017 12:08Большое спасибо за Ваш комментарий! Приятно знать, что такой подход используется кем-то еще.
Могли бы Вы подробнее рассказать о ситуациях, в которых таблицы оказались быстрее и удобнее — и почему?
Заранее спасибо.EgorHMG
14.08.2017 11:08+1Оба варианта использовали в web разработке. Для +- небольших или типовых проектов дерево подходит очень хорошо. Вести тестирование и разработку ветками удобно за счет того, что по большому счету дерево делается один раз, а потом вносятся небольшие правки для нового проекта. Количество проходов получается не очень большое, т.к кол-во правок минимально за счет типовости решений. В случае с порталами и крупными сервисами нужно переделывать всё с нуля. Процесс получается трудоемким, контроль версии вести сложно. Без специального софта, которого собственно нет, делать это нецелесообразно. Основная проблема именно в фиксации проходов по версиям и записи новых багов. В этих случаях обычная таблица онлайн + репорты по прогонам работают куда лучше. В экселе также делается древовидная структура, но с учетом необходимого места под фиксацию багов. Документ заливается в гугл докс, который позволяет смотреть историю изменений.
kika361 Автор
13.08.2017 12:05+1Спасибо за Ваш комментарий! Постараюсь ответить на Ваши вопросы:
Мы используем плагины для Jira — Structure и Zephyr. Structure позволяет формировать вложенные списки, а Zephyr используем только в контексте отдельного вида тикетов с возможностью добавления в тикет таблицы с кейсами. Соответственно, есть возможность приоретизации и выставления тегов тестам. Structure умеет фильтровать кейсы по любым параметрам какие нужно и при этом не терять структуру дерева.
Повторюсь, Zephyr для нас — это только отдельный вид тикетов, остальные его возможности мы не используем. Тест сьюты формируем фильтрами или «на глаз» — во время прогона принимаем решение, стоит ли идти по данной ветке, и вообще каким будет обход дерева. Это сделано специально — при таком тестировании всегда есть элемент исследования, человек не должен отключать голову, бездумно гоняя описанные шаги, и эффект пестицида снижается.
Необходимости в жесткой отчетности по прогонам у нас нет — по итогам тестирования тестировщик пишет отчет для менеджера в свободной форме о том, что было сделано и какой результат. Это обосновано культурой управления в самой компании — такая информация будет для менеджмента полезнее, чем набор пройденных и не пройденных тестов в нашем тестовом наборе. Для своего удобства тестировщик при желании может менять статусы тикетов и ликовать баги к тестам, но никто, кроме него самого, смотреть на это не будет.
Касательно черного и серого ящиков — в описанном Вами смысле мы тестируем черным ящиком. Я упоминала это в предыдущей статье https://habrahabr.ru/company/touchinstinct/blog/329000/ — для оценки рисков используем отдельный документ, если есть необходимость их задокументировать.
Безусловно, мне стоит подумать, как вписать это в текущую структуру тестовой документации, спасибо.
Элемент серого ящика в нашем тестировании присутствует в том смысле, что мы всегда отслеживаем взаимодействие клиент-сервера через сниффер, и в тестах это взаимодействие мы так же прописываем — где какой запрос должен отправляться, какой ответ должен прийти, какие ошибки может вернуть сервер и как приложение должно на это отреагировать.
Разработка продуктов итеративная, по 1-2 недели спринт в зависимости от того, как часто заказчик хочет видеть промежуточный билд. В начале итерации, пока пишется код, мы пишем тесты. Тесты регулярно уточняются и рефакторятся, каждая правка тестов проходит ревью у лида или второго тестировщика на проекте. Чаще всего промежуточные билды в итерацию тестируются исследовательским методом, написанная документация служит лишь картой, и тестовая документация не обязана иметь финальный готовый вид. Когда реализована вся функциональность, перед релизом проводится финальный багфикс и регрессионное тестирование. Соответственно, к регрессионному тестированию вся документация должна быть полностью готова. Оценка на финальную итерацию и подход к регрессии каждый раз переопределяется и зависит от состояния проекта, приоритетов заказчика, дедлайна и многих других факторов.
Вроде все) Надеюсь, я смогла ответить на все, что Вас интересовало.ekiyasheva
14.08.2017 19:15о да, более чем, спасибо!
Довольно платное решение, не каждому по карману, но действительно удобное — подробнее чек-листов и тем более чит-листов, легковеснее тест-кейсов, чтобы использовать в быстрой разработке, интегрированное с таскменеджером, да и прогоны можно прикрутить при желании, причем бесплатно.
pborodin
В какой программе рисовали диаграммы? Видел разные mindmap и ваш вариант один из самых симпатичных.
Harrix
Поддерживаю вопрос.
Mashkovalive
В скетче рисовали.