
Hetzel edition of 20000 Lieues Sous les Mers
Заметка о том, насколько мы “реаниматоры” по части тестов (кто знаком с творчеством Говарда Филлипса Лавкрафта, тот поймет).
В продолжение темы тестирования и тестов, хотелось бы немного написать о нашем подходе, как он выглядит на наших Single Page Applications (SPA), написанных на React.js, как нам помогал в этом Test-Driven Development (TDD) и почему мы пришли к тому, что редукторы и API-сервисы покрывать тестами тоже нужно.
Сразу скажу, что если вы ожидаете тут увидеть jest, snapshot testing или storyshots, то сразу закрывайте эту заметку. Если вы ожидаете найти тут что-то из свежих библиотек или подходов, то тоже немедленно закрывайте. Ничего из названного мы не использовали. Возможно, в новый проект мы войдем с этими инструментами, а пока получилось так, как получилось.
К тому, как наши тесты выглядят сейчас, мы пришли сами, хотя многие из этих техник описаны на различных сайтах и форумах. Как дополнение, я приведу эти ссылки ниже.
Инструменты

У нас очень стандартный и, можно сказать, джентельменский набор инструментов.
Для запуска и описания (в стиле BDD) тестов мы используем библиотеку mocha. Заглушек и шпионов нам предоставляет sinon, функции-проверки мы используем из библиотеки chai, монтируем GUI-элементы при помощи enzyme. Для создания функциональных или end-to-end тестов мы используем protractor c jasmine framework.
К сожалению, у нас не было должного упора на pentests, единственное что мы использовали по этой части для поиска уязвимостей, это модуль nsp и nodesecurity.io. На клиенте, правда, мы ничего не обнаружили, а вот в модулях сервера кое-что нашли:
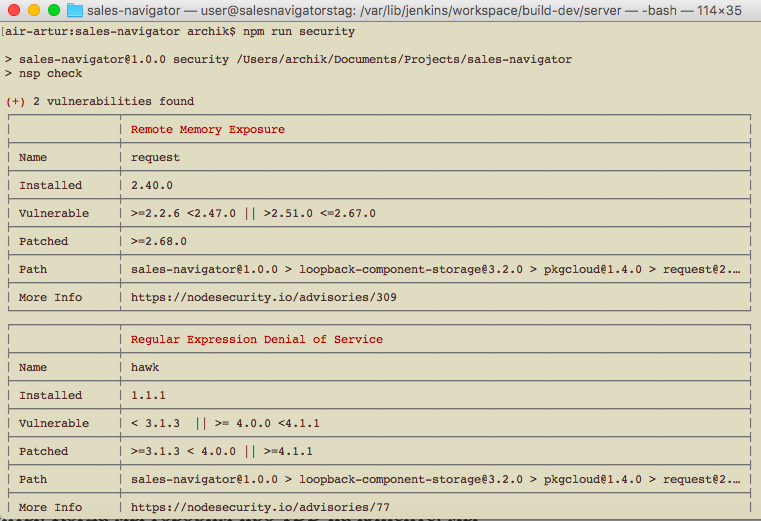
Также один из этапов тестирования?—?это проверка формата и стиля кода при помощи инструмента eslint.
Component-Driven Development через Test-Driven Development
В разработке и тестировании мы все еще придерживаемся знаменитого принципа test-first. И, как правило, у многих клиентских разработчиков возникает вопрос, как можно написать тесты, проверяющие HTML-структуру документа, когда этого документа еще не существует, когда ты еще совсем не представляешь, какие теги и стили в процессе разработки тебе придется использовать.
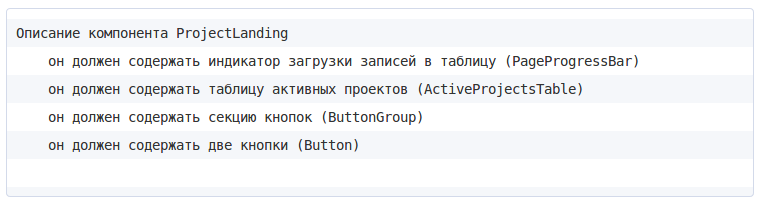
Современная разработка клиентского приложения базируется на понятии компонента. Любой макет дизайнера, в процессе декомпозиции, разбивается на составные и фундаментальные компоненты. Когда мы говорим про TDD на клиенте, мы подразумеваем компонентный уровень, нам не особо важно реализован ли этот GUI-элемент тэгом p или тэгом div, важно что он реализован. Т.е. не имея ещё реализации следующего составного компонента (страницы):
мы уже можем начать с теста, который бы проверял наличие данного компонента, как такового, а также его внутренний скелет:
Не стоит забывать, что тесты это тоже часть вашего приложения, и в этой части, не менее чем в других, важны принципы «Don’t Repeat Yourself» (DRY), «You ain’t gonna need it» (YAGNI), «Keep it simple, stupid» (KISS) и чистота кода.
Любой наш тестовый файл начинается с описания фабричного метода, который монтирует тестируемый компонент и вешает шпионов на возможные действия, которые может совершить пользователь, работая с данным компонентом. Чаще всего это относится конечно к компонентам, которые подписаны на изменение хранилища данных. Действия, условно, можно разделить на изменяющие состояние хранилища (они же в свою очередь делятся на персистентные и не персистентные) и переходы по страницам.

Фабричный метод для удобства возвращает смонтированный, при помощи библиотеки enzyme, компонент и функции-действия, которые подменены шпионами библиотеки sinon. Так как это составной компонент, который подписан на хранилище, мы применяем одну хитрость, чтобы не эмулировать хранилище в файле компонента мы экспортируем его двумя способами:
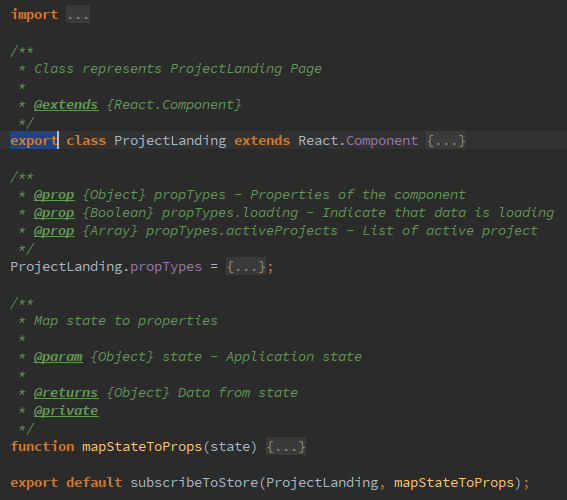
Первый для тестов, а второй, оборачивается компонентом высшего порядка (Higher-Order Component), непосредственно для подписи на изменения состояния хранилища.
А вот и первый “красный” тест
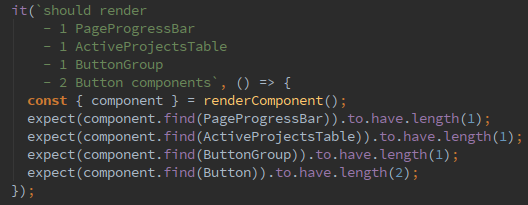

Теперь реализуем метод render у компонента, работаем по всем канонам красно-зеленого рефакторинга. После, запускаем тест снова:
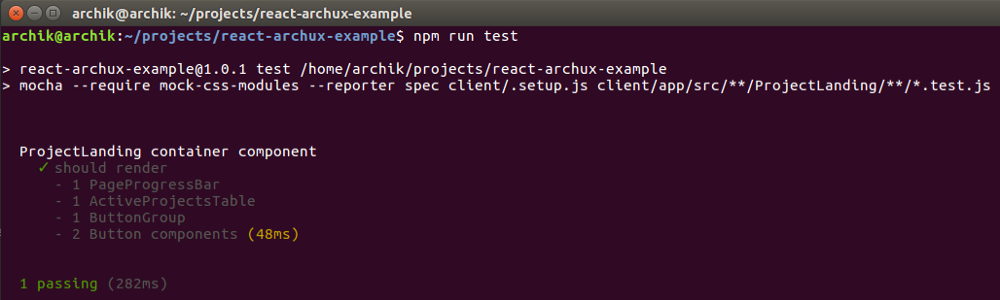
Далее мы уже подробнее можем протестировать свойства вложенных компонентов, их текущее состояние и характеристики, зависящие от пробрасываемых значений из родительского тестируемого элемента (логические флаги, названия кнопок, тестовые данные):
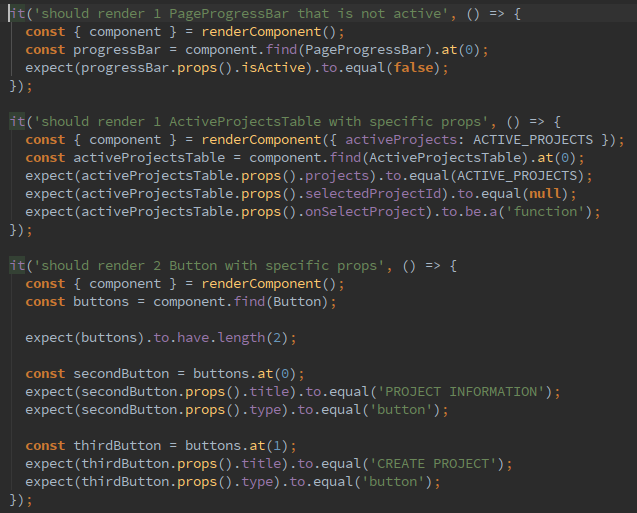
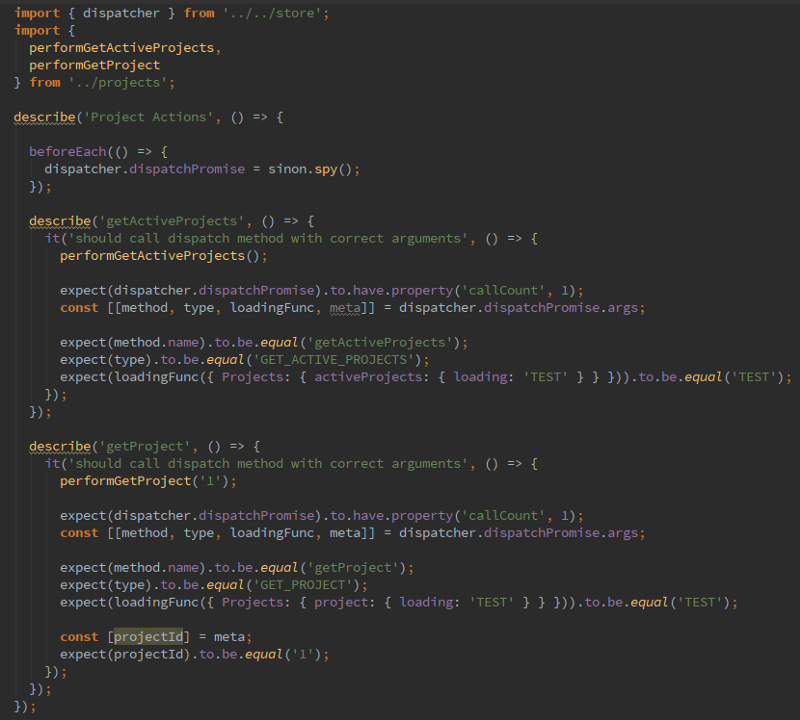
Следующий шаг?—?это проверка действий. Это тоже можно сделать в стиле test-first. Мы предполагаем, что действие “Получить активные проекты” будет вызвано внутри методов жизненного цикла компонента при его монтировании. В тоже время, действие перехода вызывается при нажатии на кнопку. Т.е. нужно симулировать нажатие на кнопку. Эти предположения позволяют нам реализовать следующую пару тестов еще до начала реализации самой логики в компоненте. Еще одна хитрость?—?для действий мы используем отдельное импортируемое пространство имён, это делает чище секцию импортов в целевом компоненте и предоставляет удобство при тестировании для моков, заглушек и шпионов.
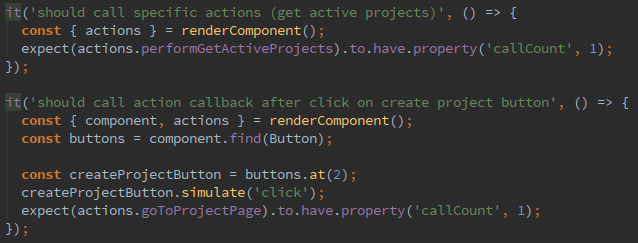
TDD в действии, так сказать. В том же ключе мы двигаемся дальше, пока полностью не реализуем данный компонент. С этим подходом мы разработали все наши компоненты, начиная от простых и фундаментальных, заканчивая составными и подписанными на хранилище.
“Мне кажется, что разрабатывать тесты мне нравится даже больше, чем писать непосредственно сам код приложения”
Андрей Антонюк, разработчик
И да, чуть не забыл упомянуть, чтобы не загромождать тесты кодом, мы выносим тестовые данные и тестовые структуры в отдельные файлы:


Функциональные тесты
Все выглядит так, как-будто мы достаточно исчерпывающим образом тестируем целевой компонент модульными и системными тестами. Однако монтирование компонента это искусственная среда (TestBed), к сожалению таким способом мы не имитируем реальный случай использования. Для такого рода эмуляции у нас есть функциональные тесты и, уже давно зарекомендовавший себя, protractor.
В проекте мы активно используем популярный шаблон PageObject. Работая со страницей как с объектом, предоставляющим нам методы доступа к ее элементам, мы по-прежнему можем продолжать работать в стиле test-first.
“Мне нравится шаблон PageObject, с ним тесты становятся чистыми, простыми и понятными” Дмитрий Сантоцкий, разработчик
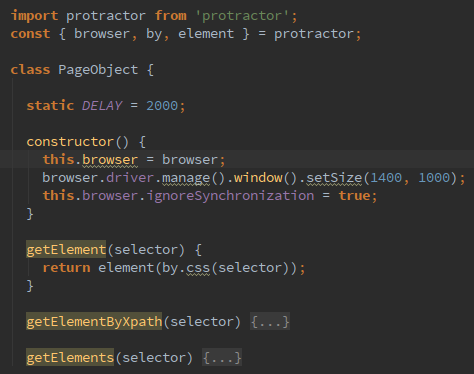
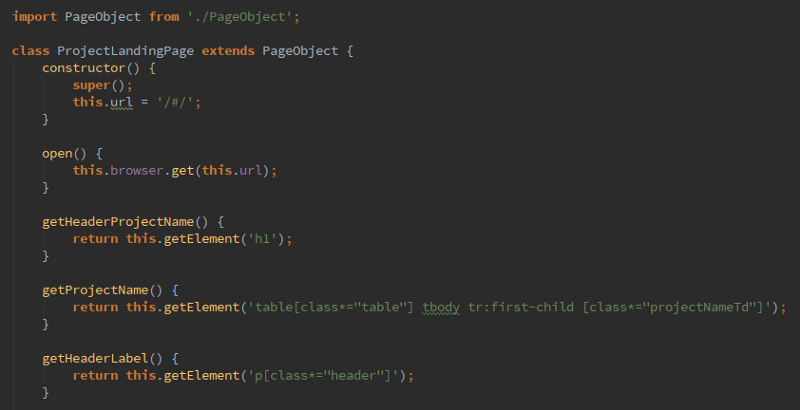
На этапе написания тестов нам не надо фокусироваться на конкретных селекторах и HTML-структуре. Если мы тестируем заголовок, то мы просто вызываем метод getHeaderLabel. В таком ключе мы легко можем работать по TDD.

На стадии красно-зеленого рефакторинга, реализуя страницу, мы укажем конкретные селекторы:
Редукторы через Unit Testing
Тестировать имеет смысл все, что содержит в себе какую-то логику, какие-то условия. Редукторы, как правило, реализуются в виде чистых функций (pure function). Что может быть идеальнее для тестов? Никаких побочных эффектов или зависимостей, которые надо обрабатывать моками или заглушками, только входные и выходные данные. Грех не покрыть их тестами!
А если серьезно, то в редукторах у нас хоть и тривиальная, но достаточно важная логика. Мы меняем состояние и в этом случае отдельные части хранилища обязательно должны быть проверены. Кроме этого, мы довольно часто прямо в редукторах можем как-то обрабатывать массивы данных, писать какие-то условия. В этих местах люди частенько ошибаются. Так сказать, спотыкаются на ровном месте. Это не раз было замечено на наших проектах. Когда ты пишешь редуктор через тесты, ты, как минимум, два раза подумаешь, какие данные из пришедшего события он должен обработать и какое новое состояние примет хранилище, после такой обработки.

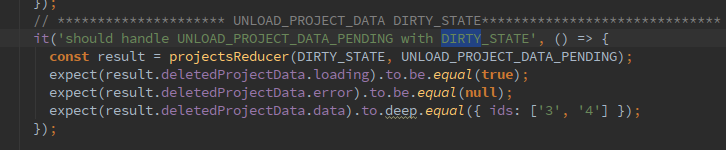
Одна из наших частых техник?—?это тесты при начальном состоянии хранилища (INIT_STATE) и при измененном (DIRTY_STATE). Первым, кто начал разделять тесты редукторов на “с начальным состояние” и “с измененным состоянием”, был наш разработчик Дима Полуян. По его мнению, тесты с измененным состоянием даже более полезны, чем с начальным.
API-сервисы и действия через Unit Testing
Тут тот же принцип, что и с редукторами. Вы несколько раз обдумаете, какой endpoint вам следует вызвать и как именно сформировать запрос на эту точку. В конце концов подход TDD подразумевает написание кода через тесты, а это значит, что ни сервисы ни редукторы не могут быть реализованы без написанных предварительно тестов.
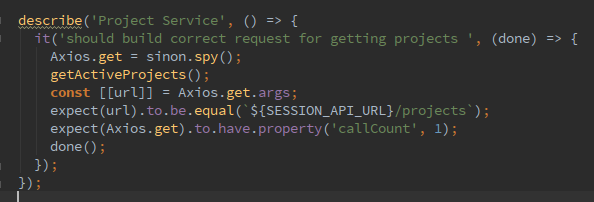
Нужно передать много параметров, формирующих значение фильтра для поиска данных. Какой глагол HTTP вы для этого выберите? Обычно об этом думают, когда приступают к реализации конечной точки сервиса. При подходе test-first, вам придется подумать об этом во время реализации теста.
Конечно мы, как огромные лентяи, не сразу пришли к тому, что и сервисы стоит покрывать тестами. Все началось с ряда мелких ошибок. Некоторые endpoints вызывались в разных местах, но с различным параметром фильтра. Внутри сервисного метода была написана логика (условие), которая в зависимости от параметров формировала необходимое значение фильтра, либо посылала запрос без него. Спустя какое-то время, один из разработчиков добавил в сервисный метод значение параметра по умолчанию (default function parameters) для фильтра. Это сломало то место, где метод вызывался без параметров, данные приходили не те.
Этот случай послужил началом и призывом к тому, чтобы API-сервисы разрабатывать тоже через тесты.
Практически те же мотивы и для функций-действий. При чем для них тесты пишутся сразу же вместе с тестами для редуктора, они как бы неразрывны и идут в связке.
Учебные тесты
Еще один тип тестов, которые мы были вынуждены использовать?—?это учебные тесты. На одном из наших проектов сервер разрабатывала независимая команда Go-разработчиков. К сожалению, старт разработки серверной части был запланирован после старта клиентской части. Поначалу, мы разработали API-сервисы с макетными данными. Формат данных базировался на описании Go-разработчиков через чаты и документацию, которая поставлялась раньше, чем endpoints. С появлением какой-нибудь конечной точки, ее изучение (проверка и понимание формата) и интеграция с ней проходили через учебные тесты.
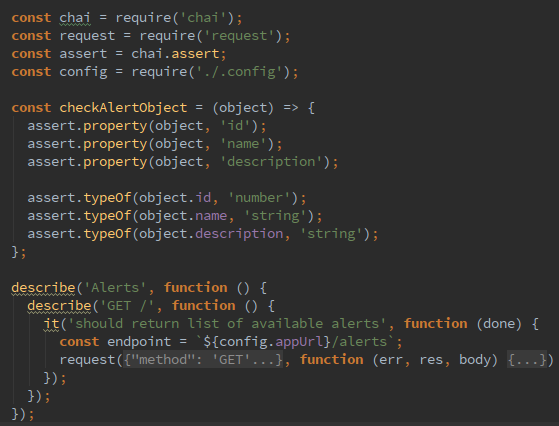
Так мы синхронизировались по знаниям с документацией и страховали себя на предмет ошибок не с нашей стороны. Go-разработчики не покрывали конечные точки сервисов интеграционными тестами, но это не была проблема, это сделали мы учебными тестами. В конечном итоге, даже перед поставкой собранной клиентской части, мы высылали PMO отчет о том, что все конечные точки сервисов стабильны и приложение в части интеграции будет работать так, как это ожидается. Можно сказать, что учебные тесты превратились для нас в проверку работоспособности (smoke test, sanity check)

->Подробнее об учебных тестах: Борьба с неизвестностью
Continuous Integration and Delivery

Наличие тестов в репозитории само по себе бесполезно, если они никак не автоматизированы и не задействованы в процессах CI/CD.
В нашем случае тесты прогоняются целых 3 раза.
Первый этап?—?это коммит разработчика, который он совершает со своей машины. При совершении этой операции, автоматически срабатывает git pre-commit hook, который прогоняет все тесты на локальной машине разработчика. В случае успеха, код попадает в gitlab и merge request отправляется на кодревью.
Если все ок, то ветка сливается в develop и тут запускается вторая прогонка тестов на удаленной машине, это, так называемый, gitlab runner, функционал которого нам предоставляет gitlab ci.

И последний этап?—?это релиз, прогонка тестов, которая инициируется инструментом Jenkins по окончанию каждого спринта, это часть процесса CD (раньше мы запускали сборку на Jenkins чаще и по расписанию)
Покрытие
Оно у нас есть, но я в него не верю. Мы используем модуль nyc, который под капотом все тот же Istanbul. Почему не верю? Потому что все инструменты измеряющие покрытие “глупые”. Они проверяют просто сам факт вызова в тестах той или иной функции (класса/метода), но этот подход в пух и прах разбивает, так называемый, калькуляторный пример.
Предположим, вам необходимо протестировать функцию математического деления. Написав один тест “2 / 2 = 1”, инструмент проверки покрытия тестами покажет после запуска значение 100%. Но так ли это? Вы видите 100% и это вроде как индикатор того, что работа сделана хорошо, однако можно ли просто подсчет вызовов считать хорошим покрытием кода тестами?
А как же “2 / 0”? Или “2 / null”? Или “NaN / undefined”?
***
Как-то все просто и складно. А где же какие-нибудь сложности?
Если по окончанию заметки именно эта мысль поселилась в вашей голове, то это значит, что мы достигли своей цели. А как вы тестируете ваши React.js приложния? Пишите на artur.basak.devingrodno@gmail.com
http://chaijs.com
http://sinonjs.org
https://mochajs.org
http://airbnb.io/enzyme
http://eslint.org
https://nodesecurity.io
https://www.npmjs.com/package/nsp
https://www.npmjs.com/package/nyc
https://about.gitlab.com/features/gitlab-ci-cd
https://jenkins.io
React Testing:
https://facebook.github.io/react/docs/test-utils.html
https://github.com/reactjs/redux/blob/master/docs/recipes/WritingTests.md
https://facebook.github.io/react/blog/2014/09/24/testing-flux-applications.html
Другой мир:
https://facebook.github.io/jest
https://facebook.github.io/jest/docs/snapshot-testing.html
https://github.com/storybooks/storybook/tree/master/addons/storyshots
Комментарии (13)

vintage
07.08.2017 10:23-2В качестве обмена опытом, давайте я расскажу, как писались бы эти тесты у нас.
Структура вашего компонента довольно простая, и описывается следующим кодом:
$my_project $mol_page title @ \Active projects body / <= Active $mol_grid records <= projects / selected foot / <= Info $mol_button_minor title <= info_title @ \Project information event_click?val <=> event_info?val null <= Create $mol_button_minor title <= create_title @ \Create project event_click?val <=> event_create?val null
Визуализация компонентаDruu
07.08.2017 11:59А можно узнать, насколько затратными и насколько статистически качественными у вас получаются тесты? Сколько строк тестов приходится на одну строку тестируемого кода и сколько реальных ошибок в среднем успевает отловить тест, будучи неизменным после того, как компонент полностью реализован?

archik Автор
07.08.2017 12:10Хороший вопрос, к сожалению, не могу конструктивно ответить на него, так как не проводились замеры подобных метрик. Но это хорошая идея сделать это в следующий раз и на основе этих замеров понять, что и вправду эффективно, а что нет.
Если не вдаваться в цифры, то тесты написанные на редукторы, сервисы и действия достаточно статичны. Реже менялись компонентные тесты (в нашем случае приложение не большое и требования не сильно прыгали, я допускаю, что на некоторых проектах скелеты составных компонентов могут по 100 раз переписываться). Наименее статичны были e2e тесты.
Кода тестов, конечно же больше, чем кода самой логики.
Количество отловленных ошибок было не велико, основной посыл в технике TDD, это не поймать ошибки, а разработать функционал через тесты, но те, что были пойманы очень ценны. Без тестов они могли бы жить долго до ручного обнаружения.

vitvad
10.08.2017 08:56+1хорошая статья, к некоторым вещам которые здесь описаны пришел сам со временем, к примеру описывать 2 экспорта для компонента и HOC-обертки.
у меня тоже сейчас для юнит тестов mocha+chai+sinon + enzyme, чем больше пользуюсь mocha тем больше скучаю по жасмину с его нормальным синтаксисом и нормальными spy.
пара вопросов:
1) если вы используете protractor то вопрос зачем использовать mocha если можно заменить зоопарк (mocha+chai+sinon) на jasmine и использовать одну либу для e2e и юнит тестов?
кстати большую часть интеграционных тестов можно писать тут же при использовании `enzyme mount`
2) как вы тестируете third-party компоненты которые в render возвращают null или пустой div, а на componentDidMount
вставляют большой кусок HTML с логикой.
в таких компонентах
— покажет только верхний div. и поискmount(<ThirdPartyComponent {...props} />).debug()
не найдет этого элемента…(wrapper.find('.some_element_inside'))
хотя при
— покажет полный HTML который компонент должен был отрендерить.mount(<ThirdPartyComponent {...props} />).html()
я на данный момент обхожу это так:
import cheerio; const wrapper = mount(<ThirdPartyComponent {...props} />); const $ = cheerio.load(wrapper.html()); $('.some_element_inside').length // will find element.
может у вас есть идеи как с этим еще можно работать?justboris
10.08.2017 11:39Попробуйте expect. Это набор матчеров и мок-функций в стиле Jasmine.
vitvad
10.08.2017 17:59я им и пользуюсь, но.он.меня.бесит.многословностью.и.точками(«впрочем тут уже дело привычки»)
justboris
10.08.2017 18:02+1Вы говорите про chai. А я говорю про expect. Там обычные джасминовские
expect(myValue).toEqual(123); var spy = expect.createSpy() spy(); expect(spy).toHaveBeenCalled();
Все как в Jasmine только без Jasmine.
vitvad
10.08.2017 18:04+1хм, вы мне раскрыли глаза, я почему-то думал что это chai-expect
не успел отредактировать свой предыдущий коментарий, добавлю здесь:
… В jasmine при включенном автокомплите camelCase быстрее получится найти метод чем писать 3 метода по отдельности...
archik Автор
10.08.2017 12:18Спасибо за комментарий
1) Как сказал бы один из наших разработчиков (Макс): «Так исторически сложилось»
Если серьезно, то е2е тесты появились позже, чем остальные. И вы абсолютно правы, если бы мы стартовали все одновременно, то одного jasmine нам было бы достаточно. Однако тогда мы сделали ставку на mocha.
Мы могли бы взять mocha в качестве фреймворка для protractor, но такая связка, как написано на офф сайте: «Limited support», jasmine же фреймворк по умолчанию и он же лучше всего поддерживается командой protractor. Я сомневаюсь, что мы встретили бы какие-то проблемы с mocha, но все же решили использовать jasmine. И как вы верно заметили, сейчас есть конфуз, 2 BDD фреймворка в проекте.
2) Очень интересный вопрос. Возможно кто-то из мимо проходящих хабровчан сможет помочь. К сожалению, мне не чего ответить, так как подобных компонентов у нас не было, где бы render возвращал null.
samizdam
Молодцы. Спасибо за развёрнутый материал.
После того как пришёл к TDD, первое чем интересуюсь с началом использования новой технологии, языка, фреймворка, это "как это добро можно затратить".
Думаю, если мне теперь когда нибудь понадобится react.js, то Ваша статья весьма пригодиться.