 H2O – библиотека машинного обучения, предназначенная как для локальных вычислений, так и с использованием кластеров, создаваемых непосредственно средствами H2O или же работая на кластере Spark. Интеграция H2O в кластеры Spark, создаваемые в Azure HDInsight, была добавлена недавно и в этой публикации (являющейся дополнением моей прошлой статьи: R и Spark) рассмотрим построение моделей машинного обучения используя H2O на таком кластере и сравним (время, метрика) его с моделями предоставляемых sparklyr, действительно ли H2O киллер-приложение для Spark?
H2O – библиотека машинного обучения, предназначенная как для локальных вычислений, так и с использованием кластеров, создаваемых непосредственно средствами H2O или же работая на кластере Spark. Интеграция H2O в кластеры Spark, создаваемые в Azure HDInsight, была добавлена недавно и в этой публикации (являющейся дополнением моей прошлой статьи: R и Spark) рассмотрим построение моделей машинного обучения используя H2O на таком кластере и сравним (время, метрика) его с моделями предоставляемых sparklyr, действительно ли H2O киллер-приложение для Spark?
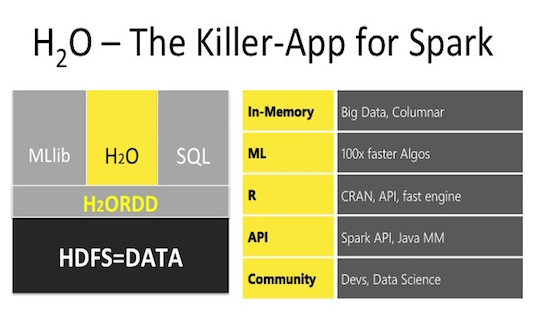
Обзор возможностей H20 в кластере HDInsight Spark
Как было сказано в предыдущем посте, на тот момент было три способа построения моделей МО используя R на кластере Spark, напомню, это:
1) Пакет sparklyr, который предлагает разные способы чтения из различных источников данных, удобную dplyr-манипуляцию данных и достаточно большой набор различных моделей.
2) R Server for Hadoop, ПО от Microsoft, использующее свои функции для манипуляций данных и свои реализации моделей МО.
3) Пакет SparkR, который предлагает свою реализацию манипуляций данных и предлагал малое число моделей МО (в настоящее время, в версии Spark 2.2 список моделей значительно расширился).
Подробнее функциональные возможности каждого варианта можно посмотреть в Таблице 1 предыдущего поста.
Теперь появился четвертый способ — использовать H2O в кластерах Spark HDInsight. Рассмотрим вкратце его возможности:
- Чтение-запись, манипуляция данными – непосредственно в H2O их нет, необходимо передавать (конвертировать) готовые данные из Spark в H20.
- Моделей машинного обучения чуть меньше, чем в sparklyr, но все основные имеются, вот их список:
- Generalized Linear Model
- Multilayer Perceptron
- Random Forest
- Gradient Boosting Machine
- Naive-Bayes
- Principal Components Analysis
- Singular Value Decomposition
- Generalized Low Rank Model
- K-Means Clustering
- Anomaly Detection via Deep Learning Autoencoder.
- Дополнительно можно использовать ансамбли и стекинг нескольких моделей, используя пакет h2oEnsemble.
- Удобство моделей H2O в том, что есть возможность сразу оценивать метрики качества, как на тренировочной, так и на валидационной выборке.
- Настройка гиперпараметров алгоритмов по фиксированной сетке или случайным выбором.
- Полученные модели можно сохранить в бинарный вид или в чистый Java код "Plain Old Java Object". (POJO)
В целом, алгоритм работы с H2O заключается в следующем:
- Чтение данных, используя возможности пакета sparklyr.
- Манипуляция, трансформация, подготовка данных, используя sparklyr и replyr.
- Конвертация данных в H2O формат, используя пакет rsparkling.
- Построение моделей МО и предсказывание данных, используя h2o.
- Возвращение полученных результатов в Spark и/или локально в R, используя rsparkling и/или sparklyr.
Используемые ресурсы
- Кластер H2O Artificial Intelligence for HDInsight 2.0.2.
Данный кластер представляет собой законченное решение с API для Python и Scala. R (видимо пока) не интегрирован, но его добавление не составляет труда, для этого необходимо следующее: - R и пакеты sparklyr, h2o, rsparkling инсталлировать на все узлы: головные и рабочие
- RStudio инсталлировать на головной узел
- putty клиент локально, для установления ssh сессии с головным узлом кластера и туннелирования порта RStudio на порт локального хоста для доступа к RStudio через веб-браузер.
Важно: устанавливать пакет h2o необходимо из исходников, выбирая версию, соответствующую версии как Spark, так и пакета rsparkling, при необходимости перед загрузкой rsparkling необходимо указывать используемую версию sparklingwater (в данном случае options(rsparkling.sparklingwater.version = '2.0.8'. Таблица с зависимостями по версиям приведена здесь. Устанавливать ПО и пакеты на головные узлы допустимо непосредственно через консоль узла, а вот на рабочие узлы прямого доступа нет, поэтому разворачивание дополнительного ПО необходимо делать через Action Script.
Вначале разворачиваем кластер H2O Artificial Intelligence for HDInsight, конфигурация используется такая же, с 2 головными узлами D12v2 и 4 рабочими узлами D12v2 и 1 узел Sparkling water (служебный). После успешного разворачивания кластера, используя подключение по ssh к головному узлу, устанавливаем туда R, RStudio (текущая версия RStudio уже с интегрированными возможностями по просмотру фреймов Spark и состояния кластера), и необходимые пакеты. Для установки пакетов на рабочие узлы создаем скрипт установки (R и пакетов) и инициируем его через Action Script. Возможно использовать готовые скрипты, располагающиеся здесь: на головные узлы и на рабочие узлы. После всех успешных установок переустанавливаем ssh соединение, используя туннелирование на localhost:8787. Итак, теперь в браузере по адресу localhost:8787 мы подключаемся к RStudio и продолжаем работать.
Достоинство использования R заключается еще и в том, что установив Shiny сервер на эту же головную ноду и, создав простой веб-интерфейс на flexdashboard, возможно все вычисления на кластере, подбор гиперпараметров, визуализацию результатов, подготовку отчетов и прочее, инициировать на созданном web-сайте, который уже будет доступен отовсюду по прямой ссылке в браузере (здесь не рассматривается).
Подготовка и манипуляция данных
Использовать я буду тот же набор данных, что и в прошлый раз, это информация о поездках на такси и их оплате. Скачав данные файлы и поместив их в hdfs, читаем их оттуда и делаем необходимые преобразования (код приведен в прошлом посте).
Модели машинного обучения
Для более-менее сопоставимого сравнения выберем общие модели как в sparklyr, так и в h2o, для задач регрессии таких моделей оказалось три — линейная регрессия, случайный лес и градиентный бустинг. Параметры алгоритмов использовались по умолчанию, в случае их отличий, они приводились к общим (по возможности), проверка точности модели осуществлялась на холдаут выборке в 30%, по метрике RMSE. Результаты приведены в Табл.1 и на Рис.1.
Табл.1. Результаты моделей
| Модель | RMSE | Время, сек |
|---|---|---|
| lm_mllib | 1,2507 | 10 |
| lm_h2o | 1,2507 | 5,6 |
| rf_mllib | 1,2669 | 21,9 |
| rf_h2o | 1,2531 | 13,4 |
| gbm_mllib | 1,2553 | 108,3 |
| gbm_h2o | 1,2343 | 24,9 |

Рис.1 Результаты моделей
Как видно из результатов, явно видно преимущество одних и тех же моделей h2o перед их реализацией в sparklyr, как по времени исполнения, так и по метрике. Безусловный лидер из h2o gbm, обладает хорошим временем исполнения и минимальным RMSE. Не исключено, что осуществляя подбор гиперпараметров по кросс-валидациям, картина могла бы быть иной, но в данном случае «из коробки» h2o быстрее и лучше.
Выводы
В данной статье дополнены функциональные возможности машинного обучения, используя R с H2O на кластере Spark, используя платформу HDInsight, и приведен пример преимущества данного способа в отличие от моделей МО пакета sparklyr, но в свою очередь sparklyr обладает существенным преимуществом по удобной предобработке и трансформации данных.
###Подготовительная часть (подготовка данных) приведена в прошлом посте
features<-c("vendor_id",
"passenger_count",
"trip_time_in_secs",
"trip_distance",
"fare_amount",
"surcharge")
rmse <- function(formula, data) {
data %>%
mutate_(residual = formula) %>%
summarize(rmse = sqr(mean(residual ^ 2))) %>%
collect %>%
.[["rmse"]]
}
trips_train_tbl <- sdf_register(taxi_filtered$training, "trips_train")
trips_test_tbl <- sdf_register(taxi_filtered$test, "trips_test")
actual <- trips.test.tbl %>%
select(tip_amount) %>%
collect() %>%
`[[`("tip_amount")
tbl_cache(sc, "trips_train")
tbl_cache(sc, "trips_test")
trips_train_h2o_tbl <- as_h2o_frame(sc, trips_train_tbl)
trips_test_h2o_tbl <- as_h2o_frame(sc, trips_test_tbl)
trips_train_h2o_tbl$vendor_id <- as.factor(trips_train_h2o_tbl$vendor_id)
trips_test_h2o_tbl$vendor_id <- as.factor(trips_test_h2o_tbl$vendor_id)
#mllib
lm_mllib <- ml_linear_regression(x=trips_train_tbl, response = "tip_amount", features = features)
pred_lm_mllib <- sdf_predict(lm_mllib, trips_test_tbl)
rf_mllib <- ml_random_forest(x=trips_train_tbl, response = "tip_amount", features = features)
pred_rf_mllib <- sdf_predict(rf_mllib, trips_test_tbl)
gbm_mllib <-ml_gradient_boosted_trees(x=trips_train_tbl, response = "tip_amount", features = features)
pred_gbm_mllib <- sdf_predict(gbm_mllib, trips_test_tbl)
#h2o
lm_h2o <- h2o.glm(x =features, y = "tip_amount", trips_train_h2o_tbl)
pred_lm_h2o <- h2o.predict(lm_h2o, trips_test_h2o_tbl)
rf_h2o <- h2o.randomForest(x =features, y = "tip_amount", trips_train_h2o_tbl,ntrees=20,max_depth=5)
pred_rf_h2o <- h2o.predict(rf_h2o, trips_test_h2o_tbl)
gbm_h2o <- h2o.gbm(x =features, y = "tip_amount", trips_train_h2o_tbl)
pred_gbm_h2o <- h2o.predict(gbm_h2o, trips_test_h2o_tbl)
####
pred.h2o <- data.frame(
tip.amount = actual,
as.data.frame(pred_lm_h2o),
as.data.frame(pred_rf_h2o),
as.data.frame(pred_gbm_h2o),
)
colnames(pred.h2o)<-c("tip.amount", "lm", "rf", "gbm")
result <- data.frame(
RMSE = c(
lm.mllib = rmse(~ tip_amount - prediction, pred_lm_mllib),
lm.h2o = rmse(~ tip.amount - lm, pred.h2o ),
rf.mllib = rmse(~ tip.amount - prediction, pred_rf_mllib),
rf.h2o = rmse(~ tip_amount - rf, pred.h2o),
gbm.mllib = rmse(~ tip_amount - prediction, pred_gbm_mllib),
gbm.h2o = rmse(~ tip.amount - gbm, pred.h2o)
)
)