На первый взгляд, Clean Architecture – довольно простой набор рекомендаций к построению приложений. Но и я, и многие мои коллеги, сильные разработчики, осознали эту архитектуру не сразу. А в последнее время в чатах и интернете я вижу всё больше ошибочных представлений, связанных с ней. Этой статьёй я хочу помочь сообществу лучше понять Clean Architecture и избавиться от распространенных заблуждений.
Сразу хочу оговориться, заблуждения – это дело личное. Каждый в праве заблуждаться. И если это его устраивает, то я не хочу мешать. Но всегда хорошо услышать мнения других людей, а зачастую люди не знают даже мнений тех, кто стоял у истоков.
Истоки
В 2011 году Robert C. Martin, также известный как Uncle Bob, опубликовал статью Screaming Architecture, в которой говорится, что архитектура должна «кричать» о самом приложении, а не о том, какие фреймворки в нем используются. Позже вышла статья, в которой Uncle Bob даёт отпор высказывающимся против идей чистой архитектуры. А в 2012 году он опубликовал статью «The Clean Architecture», которая и является основным описанием этого подхода. Кроме этих статей я также очень рекомендую посмотреть видео выступления Дяди Боба.
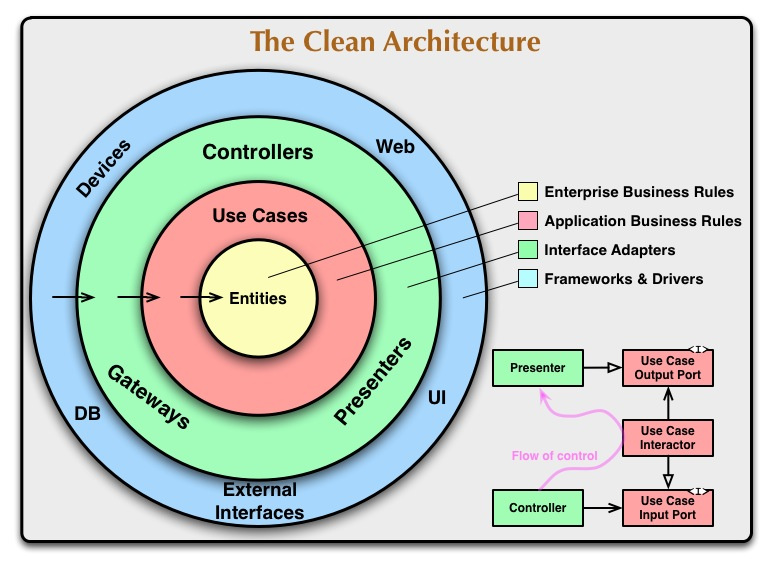
Вот оригинальная схема из статьи, которая первой всплывает в голове разработчика, когда речь заходит о Clean Architecture:
В Android-сообществе Clean стала быстро набирать популярность после статьи Architecting Android...The clean way?, написанной Fernando Cejas. Я впервые узнал про Clean Architecture именно из неё. И только потом пошёл искать оригинал. В этой статье Fernando приводит такую схему слоёв:
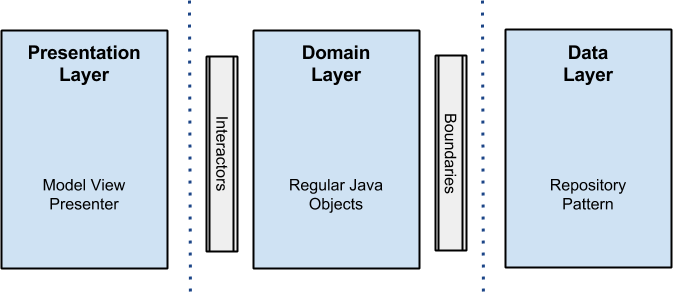
То, что на этой схеме другие слои, а в domain слое лежат ещё какие-то Interactors и Boundaries, сбивает с толку. Оригинальная картинка тоже не всем понятна. В статьях многое неоднозначно или слегка абстрактно. А видео не все смотрят (обычно из-за недостаточного знания английского). И вот, из-за недопонимания, люди начинают что-то выдумывать, усложнять, заблуждаться…
Давайте разбираться!
Сlean Architecture
Clean Architecture объединила в себе идеи нескольких других архитектурных подходов, которые сходятся в том, что архитектура должна:
- быть тестируемой;
- не зависеть от UI;
- не зависеть от БД, внешних фреймворков и библиотек.
Это достигается разделением на слои и следованием Dependency Rule (правилу зависимостей).
Dependency Rule
Dependency Rule говорит нам, что внутренние слои не должны зависеть от внешних. То есть наша бизнес-логика и логика приложения не должны зависеть от презентеров, UI, баз данных и т.п. На оригинальной схеме это правило изображено стрелками, указывающими внутрь.
В статье сказано: имена сущностей (классов, функций, переменных, чего угодно), объявленных во внешних слоях, не должны встречаться в коде внутренних слоев.
Это правило позволяет строить системы, которые будет проще поддерживать, потому что изменения во внешних слоях не затронут внутренние слои.
Слои
Uncle Bob выделяет 4 слоя:
- Entities. Бизнес-логика общая для многих приложений.
- Use Cases (Interactors). Логика приложения.
- Interface Adapters. Адаптеры между Use Cases и внешним миром. Сюда попадают Presenter’ы из MVP, а также Gateways (более популярное название репозитории).
- Frameworks. Самый внешний слой, тут лежит все остальное: UI, база данных, http-клиент, и т.п.
Подробнее, что из себя представляют эти слои, мы рассмотрим по ходу статьи. А пока остановимся на передаче данных между ними.
Переходы
Переходы между слоями осуществляются через Boundaries, то есть через два интерфейса: один для запроса и один для ответа. Их можно увидеть справа на оригинальной схеме (Input/OutputPort). Они нужны, чтобы внутренний слой не зависел от внешнего (следуя Dependency Rule), но при этом мог передать ему данные.
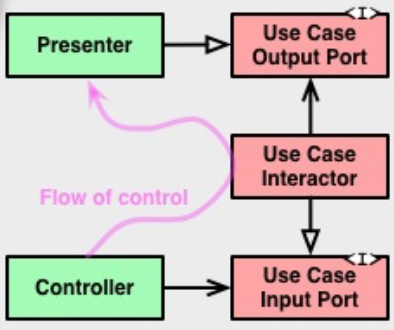
Оба интерфейса относятся к внутреннему слою (обратите внимание на их цвет на картинке).
Смотрите, Controller вызывает метод у InputPort, его реализует UseCase, а затем UseCase отдает ответ интерфейсу OutputPort, который реализует Presenter. То есть данные пересекли границу между слоями, но при этом все зависимости указывают внутрь на слой UseCase’ов.
Чтобы зависимость была направлена в сторону обратную потоку данных, применяется принцип инверсии зависимостей (буква D из аббревиатуры SOLID). То есть, вместо того чтобы UseCase напрямую зависел от Presenter’a (что нарушало бы Dependency Rule), он зависит от интерфейса в своём слое, а Presenter должен этот интерфейс реализовать.
Точно та же схема работает и в других местах, например, при обращении UseCase к Gateway/Repository. Чтобы не зависеть от репозитория, выделяется интерфейс и кладется в слой UseCases.
Что же касается данных, которые пересекают границы, то это должны быть простые структуры. Они могут передаваться как DTO или быть завернуты в HashMap, или просто быть аргументами при вызове метода. Но они обязательно должны быть в форме более удобной для внутреннего слоя (лежать во внутреннем слое).
Особенности мобильных приложений
Надо отметить, что Clean Architecture была придумана с немного иным типом приложений на уме. Большие серверные приложения для крупного бизнеса, а не мобильные клиент-серверные приложения средней сложности, которые не нуждаются в дальнейшем развитии (конечно, бывают разные приложения, но согласитесь, в большей массе они именно такие). Непонимание этого может привести к overengineering’у.
На оригинальной схеме есть слово Controllers. Оно появилось на схеме из-за frontend’a, в частности из Ruby On Rails. Там зачастую разделяют Controller, который обрабатывает запрос и отдает результат, и Presenter, который выводит этот результат на View. Многие не сразу догадываются, но в android-приложениях Controllers не нужны.
Ещё в статье Uncle Bob говорит, что слоёв не обязательно должно быть 4. Может быть любое количество, но Dependency Rule должен всегда применяться.
Глядя на схему из статьи Fernando Cejas, можно подумать, что автор воспользовался как раз этой возможностью и уменьшил количество слоев до трёх. Но это не так. Если разобраться, то в Domain Layer у него находятся как Interactors (это другое название UseCase’ов), так и Entities.
Все мы благодарны Fernando за его статьи, которые дали хороший толчок развитию Clean в Android-сообществе, но его схема также породила и заблуждение.
Заблуждение: Слои и линейность
Сравнивая оригинальную схему от Uncle Bob’a и cхему Fernando Cejas’a многие начинают путаться. Линейная схема воспринимается проще, и люди начинают неверно понимать оригинальную. А не понимая оригинальную, начинают неверно толковать и линейную. Кто-то думает, что расположение надписей в кругах имеет сакральное значение, или что надо использовать Controller, или пытаются соотнести названия слоёв на двух схемах. Смешно и грустно, но основные схемы стали основными источниками заблуждения!
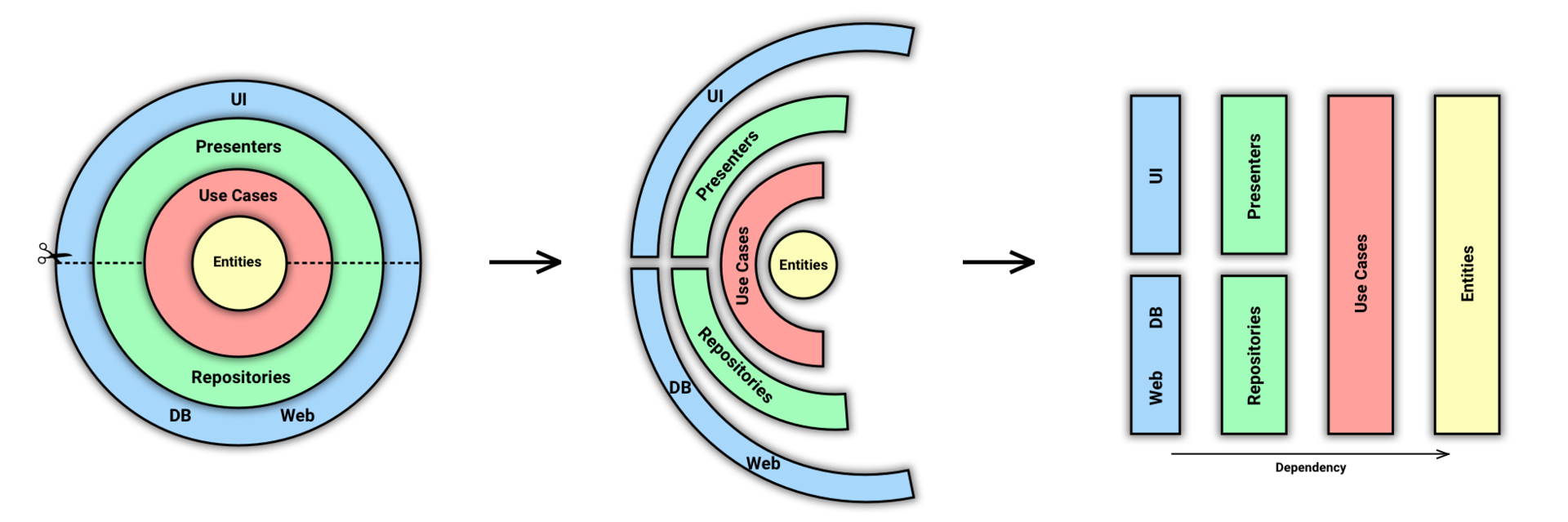
Постараемся это исправить. Для начала давайте очистим основную схему, убрав из нее лишнее для нас. И переименуем Gateways в Repositories, т.к. это более распространенное название этой сущности.
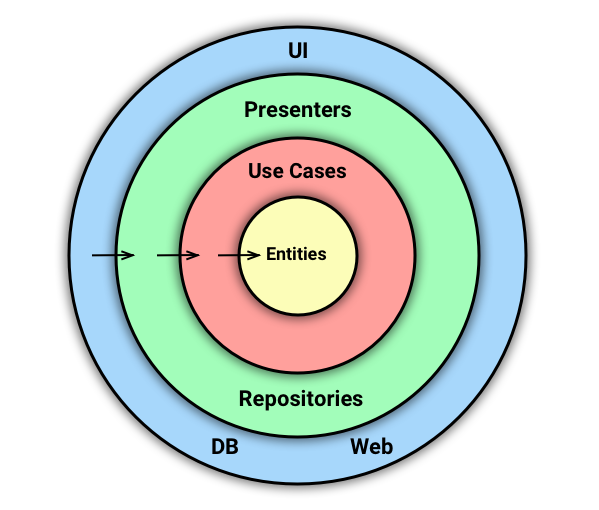
Стало немного понятнее. Теперь мы сделаем вот что: разрежем слои на части и превратим эту схему в блочную, где цвет будет по-прежнему обозначать принадлежность к слою.
Как я уже сказал выше, цвета обозначают слои. А стрелка внизу обозначает Dependency Rule.
На получившейся схеме уже проще представить себе течение данных от UI к БД или серверу и обратно. Но давайте сделаем еще один шаг к линейности, расположив слои по категориям:

Я намеренно не называю это разделение слоями, в отличие от Fernando Cejas. Потому что мы и так делим слои. Я называю это категориями или частями. Можно назвать как угодно, но повторно использовать слово «слои» не стоит.
А теперь давайте сравним то, что получилось, со схемой Fernando.
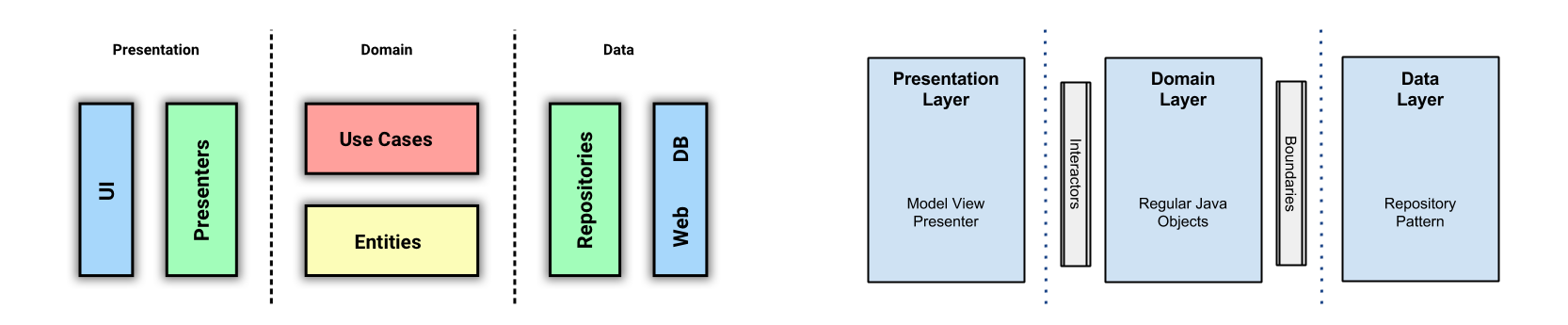
Надеюсь теперь вcё начало вставать на свои места. Выше я говорил, что, по моему мнению, у Fernando всё же 4 слоя. Думаю теперь это тоже стало понятнее. В Domain части у нас находятся и UseCases и Entities.
Такая схема воспринимается проще. Ведь обычно события и данные в наших приложениях ходят от UI к backend’у или базе данных и обратно. Давайте изобразим этот процесс:
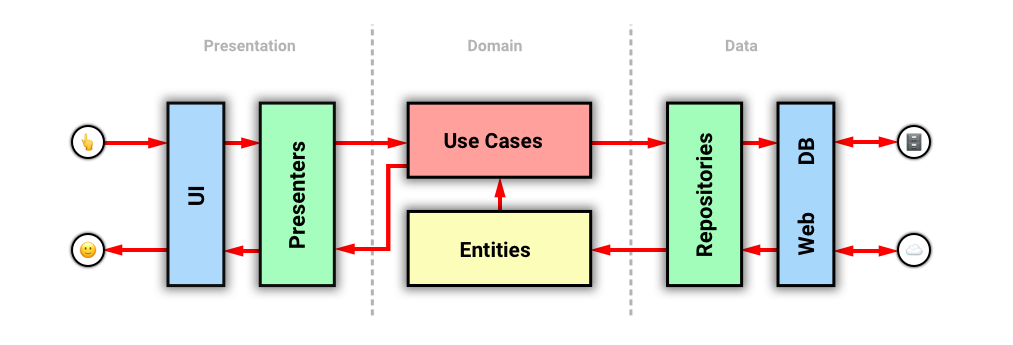
Красными стрелками показано течение данных.
Событие пользователя идет в Presenter, тот передает в Use Case. Use Case делает запрос в Repository. Repository получает данные где-то, создает Entity, передает его в UseCase. Так Use Case получает все нужные ему Entity. Затем, применив их и свою логику, получает результат, который передает обратно в Presenter. А тот, в свою очередь, отображает результат в UI.
На переходах между слоями (не категориями, а слоями, отмеченными разным цветом) используются Boundaries, описанные ранее.
Теперь, когда мы поняли, как соотносятся две схемы, давайте рассмотрим следующее заблуждение.
Заблуждение: Слои, а не сущности
Как понятно из заголовка, кто-то думает, что на схемах изображены сущности (особенно это затрагивает UseCases и Entities). Но это не так.
На схемах изображены слои, в них может находиться много сущностей. В них будут находиться интерфейсы для переходов между слоями (Boundaries), различные DTO, основные классы слоя (Interactors для слоя UseCases, например).
Не будет лишним взглянуть на схему, собранную из частей, показанных в видео выступления Uncle Bob’a. На ней изображены классы и зависимости:

Видите двойные линии? Это границы между слоями. Разделение между слоями Entities и UseCases не показаны, так как в видео основной упор делался на том, что вся логика (приложения и бизнеса) отгорожена от внешнего мира.
C Boundaries мы уже знакомы, интерфейс Gateway – это то же самое. Request/ResponseModel – просто DTO для передачи данных между слоями. По правилу зависимости они должны лежать во внутреннем слое, что мы и видим на картинке.
Про Controller мы тоже уже говорили, он нас не интересует. Его функцию у нас выполняет Presenter.
А ViewModel на картинке – это не ViewModel из MVVM и не ViewModel из Architecture Components. Это просто DTO для передачи данных View, чтобы View была тупой и просто сетила свои поля. Но это уже детали реализации и будет зависеть от выбора презентационного паттерна и личных подходов.
В слое UseCases находятся не только Interactor’ы, но также и Boundaries для работы с презентером, интерфейс для работы с репозиторием, DTO для запроса и ответа. Отсюда можно сделать вывод, что на оригинальной схеме отражены всё же слои.
Заблуждение: Entities
Entities по праву занимают первое место по непониманию.
Мало того, что почти никто (включая меня до недавнего времени) не осознает, что же это такое на самом деле, так их ещё и путают с DTO.
Однажды в чате у меня возник спор, в котором мой оппонент доказывал мне, что Entity – это объекты, полученные после парсинга JSON в data-слое, а DTO – объекты, которыми оперируют Interactor’ы…
Постараемся хорошо разобраться, чтобы таких заблуждений больше не было ни у кого.
Что же такое Entities?
Чаще всего они воспринимаются как POJO-классы, с которыми работают Interactor’ы. Но это не так. По крайней мере не совсем.
В статье Uncle Bob говорит, что Entities инкапсулируют логику бизнеса, то есть всё то, что не зависит от конкретного приложения, а будет общим для многих. Но если у вас отдельное приложение и оно не заточено под какой-то существующий бизнес, то Entities будут являться бизнес-объектами приложения, содержащими самые общие и высокоуровневые правила.
Я думаю, что именно фраза: «Entities это бизнес объекты», – запутывает больше всего. Кроме того, на приведенной выше схеме из видео Interactor получает Entity из Gateway. Это также подкрепляет ощущение, что это просто POJO объекты.
Но в статье также говорится, что Entity может быть объектом с методами или набором структур и функций. То есть упор делается на то, что важны методы, а не данные.
Это также подтверждается в разъяснении от Uncle Bob’а, которое я нашел недавно:
Uncle Bob говорит, что для него Entities содержат бизнес-правила, независимые от приложения. И они не просто объекты с данными. Entities могут содержать ссылки на объекты с данными, но основное их назначение в том, чтобы реализовать методы бизнес-логики, которые могут использоваться в различных приложениях.
А по-поводу того, что Gateways возвращают Entities на картинке, он поясняет следующее:
Реализация Gаteway получает данные из БД, и использует их, чтобы создать структуры данных, которые будут переданы в Entities, которые Gateway вернет. Реализовано это может быть композицией
class MyEntity { private MyDataStructure data;}или наследованием
class MyEntity extends MyDataStructure {...} И в конце ответа фраза, которая меня очень порадовала:
And remember, we are all pirates by nature; and the rules I'm talking about here are really more like guidelines…
(И запомните: мы все пираты по натуре, и правила, о которых я говорю тут, на самом деле, скорее рекомендации…)
Действительно, не надо слишком буквально всё воспринимать, надо искать компромиссы и не делать лишнего. Все-таки любая архитектура призвана помогать, а не мешать.
Итак, слой Entities содержит:
- Entities – функции или объекты с методами, которые реализуют логику бизнеса, общую для многих приложений (а если бизнеса нет, то самую высокоуровневую логику приложения);
- DTO, необходимые для работы и перехода между слоями.
Кроме того, когда приложение отдельное, то надо стараться находить и выделять в Entities высокоуровневую логику из слоя UseCases, где зачастую она оседает по ошибке.
Заблуждение: UseCase и/или Interactor
Многие путаются в понятиях UseCase и Interactor. Я слышал фразы типа: «Канонического определения Interactor нет». Или вопросы типа: «Мне делать это в Interactor’e или вынести в UseCase?».
Косвенное определение Interactor’a встречается в статье, которую я уже упоминал в самом начале. Оно звучит так:
«...interactor object that implements the use case by invoking business objects.»
Таким образом:
Interactor – объект, который реализует use case (сценарий использования), используя бизнес-объекты (Entities).
Что же такое Use Case или сценарий использования?
Uncle Bob в видео выступлении говорит о книге «Object-Oriented Software Engineering: A Use Case Driven Approach», которую написал Ivar Jacobson в 1992 году, и о том, как тот описывает Use Case.
Use case – это детализация, описание действия, которое может совершить пользователь системы.
Вот пример, который приводится в видео:

Это Use Case для создания заказа, причём выполняемый клерком.
Сперва перечислены входные данные, но не даётся никаких уточнений, что они из себя представляют. Тут это не важно.
Первый пункт – даже не часть Use Case’a, это его старт – клерк запускает команду для создания заказа с нужными данными.
Далее шаги:
- Система валидирует данные. Не оговаривается как.
- Система создает заказ и id заказа. Подразумевается использование БД, но это не важно пока, не уточняется. Как-то создает и всё.
- Система доставляет id заказа клерку. Не уточняется как.
Легко представить, что id возвращается не клерку, а, например, выводится на страницу сайта. То есть Use Case никак не зависит от деталей реализации.
Ivar Jacobson предложил реализовать этот Use Case в объекте, который назвал ControlObject.
Но Uncle Bob решил, что это плохая идея, так как путается с Controller из MVC и стал называть такой объект Interactor. И он говорит, что мог бы назвать его UseCase.
Это можно посмотреть примерно в этом моменте видео.
Там же он говорит, что Interactor реализует use case и имеет метод для запуска execute() и получается, что это паттерн Команда. Интересно.
Вернемся к нашим заблуждениям.
Когда кто-то говорит, что у Interactor’a нет четкого определения – он не прав. Определение есть и оно вполне четкое. Выше я привел несколько источников.
Многим нравится объединять Interactor’ы в один общий с набором методов, реализующих use case’ы.
Если вам сильно не нравятся отдельные классы, можете так делать, это ваше решение. Я лично за отдельные Interactor’ы, так как это даёт больше гибкости.
А вот давать определение: «Интерактор – это набор UseCase’ов», – вот это уже плохо. А такое определение бытует. Оно ошибочно с точки зрения оригинального толкования термина и вводит начинающих в большие заблуждения, когда в коде получается одновременно есть и UseCase классы и Interactor классы, хотя всё это одно и то же.
Я призываю не вводить друг друга в заблуждения и использовать названия Interactor и UseCase, не меняя их изначальный смысл: Interactor/UseCase – объект, реализующий use case (сценарий использования).
За примером того, чем плохо, когда одно название толкуется по-разному, далеко ходить не надо, такой пример рядом – паттерн Repository.
Доступ к данным
Для доступа к данным удобно использовать какой-либо паттерн, позволяющий скрыть процесс их получения. Uncle Bob в своей схеме использует Gateway, но сейчас куда сильнее распространен Repository.
Repository
А что из себя представляет паттерн Repository? Вот тут и возникает проблема, потому что оригинальное определение и то, как мы понимаем репозиторий сейчас (и как его описывает Fernando Cejas в своей статье), фундаментально различаются.
В оригинале Repository инкапсулирует набор сохраненных объектов в более объектно-ориентированном виде. В нем собран код, создающий запросы, который помогает минимизировать дублирование запросов.
Но в Android-сообществе куда более распространено определение Repository как объекта, предоставляющего доступ к данным с возможностью выбора источника данных в зависимости от условий.
Подробнее об этом можно прочесть в статье Hannes Dorfmann’а.
Gateway
Сначала я тоже начал использовать Repository, но воспринимая слово «репозиторий» в значении хранилища, мне не нравилось наличие там методов для работы с сервером типа login() (да, работа с сервером тоже идет через Repository, ведь в конце концов для приложения сервер – это та же база данных, только расположенная удаленно).
Я начал искать альтернативное название и узнал, что многие используют Gateway – слово более подходящее, на мой вкус. А сам паттерн Gateway по сути представляет собой разновидность фасада, где мы прячем сложное API за простыми методами. Он в оригинале тоже не предусматривает выбор источников данных, но все же ближе к тому, как используем мы.
А в обсуждениях все равно приходится использовать слово «репозиторий», всем так проще.
Доступ к Repository/Gateway только через Interactor?
Многие настаивают, что это единственный правильный способ. И они правы!
В идеале использовать Repository нужно только через Interactor.
Но я не вижу ничего страшного, чтобы в простых случаях, когда не нужно никакой логики обработки данных, вызывать Repository из Presenter’a, минуя Interactor.
Repository и презентер находятся на одном слое, Dependency Rule не запрещает нам использовать Repository напрямую. Единственное но – возможное добавления логики в Interactor в будущем. Но добавить Interactor, когда понадобится, не сложно, а иметь множество proxy-interactor’ов, просто прокидывающих вызов в репозиторий, не всегда хочется.
Повторюсь, я считаю, что в идеале надо делать запросы через Interactor, но также считаю, что в небольших проектах, где вероятность добавления логики в Interactor ничтожно мала, можно этим правилом поступиться. В качестве компромисса с собой.
Заблуждение: Обязательность маппинга между слоями
Некоторые утверждают, что маппить данные обязательно между всеми слоями. Но это может породить большое количество дублирующихся представлений одних и тех же данных.
А можно использовать DTO из слоя Entities везде во внешних слоях. Конечно, если те могут его использовать. Нарушения Dependency Rule тут нет.
Какое решение выбрать – сильно зависит от предпочтений и от проекта. В каждом варианте есть свои плюсы и минусы.
Маппинг DTO на каждом слое:
- Изменение данных в одном слое не затрагивает другой слой;
- Аннотации, нужные для какой-то библиотеки не попадут в другие слои;
- Может быть много дублирования;
- При изменении данных все равно приходится менять маппер.
Использование DTO из слоя Enitities:
- Нет дублирования кода;
- Меньше работы;
- Присутствие аннотаций, нужных для внешних библиотек на внутреннем слое;
- При изменении этого DTO, возможно придется менять код в других слоях.
Хорошее рассуждение есть вот по этой ссылке.
С выводами автора ответа я полностью согласен:
Если у вас сложное приложение с логикой бизнеса и логикой приложения, и/или разные люди работают над разными слоями, то лучше разделять данные между слоями (и маппить их). Также это стоит делать, если серверное API корявое. Но если вы работаете над проектом один, и это простое приложение, то не усложняйте лишним маппингом.
Заблуждение: маппинг в Interactor’e
Да, такое заблуждение существует. Развеять его несложно, приведя фразу из оригинальной cтатьи:
So when we pass data across a boundary, it is always in the form that is most convenient for the inner circle.
(Когда мы передаем данные между слоями, они всегда в форме более удобной для внутреннего слоя)
Поэтому в Interactor данные должны попадать уже в нужном ему виде.
Маппинг происходит в слое Interface Adapters, то есть в Presenter и Repository.
А где раскладывать объекты?
С сервера нам приходят данные в разном виде. И иногда API навязывает нам странные вещи. Например, в ответ на login() может прийти объект Profile и объект OrderState. И, конечно же, мы хотим сохранить эти объекты в разных Repository.
Так где же нам разобрать LoginResponse и разложить Profile и OrderState по нужным репозиториям, в Interactor’e или в Repository?
Многие делают это в Interactor’e. Так проще, т.к. не надо иметь зависимости между репозиториями и разрывать иногда возникающую кроссылочность.
Но я делаю это в Repository. По двум причинам:
- Если мы делаем это в Interactor’e, значит мы должны передать ему LoginResponse в каком-то виде. Но тогда, чтобы не нарушать Dependency Rule, LoginResponse должен находиться в слое Interactor’a (UseCases) или Entities. А ему там не место, ведь он им кроме как для раскладывания ни для чего больше не нужен.
- Раскладывание данных – не дело для use case. Мы же не станем писать пункт в описании действия доступного пользователю: «Получить данные, разложить данные». Скорее мы напишем просто: «Получить нужные данные»,– и всё.
Если вам удобно делать это в Interactor, то делайте, но считайте это компромиссом.
Можно ли объединить Interactor и Repository?
Некоторым нравится объединять Interactor и Repository. В основном это вызвано желанием избежать решения проблемы, описанной в пункте «Доступ к Repository/Gateway только через Interactor?».
Но в оригинале Clean Architecture эти сущности не смешиваются.
И на это пара веских причин:
- Они на разных слоях.
- Они выполняют различные функции.
А вообще, как показывает практика, в этом ничего страшного нет. Пробуйте и смотрите, особенно если у вас небольшой проект. Хотя я рекомендую разделять эти сущности.
RxJava в Clean Architecture
Уже становится сложным представить современное Android-приложение без RxJava. Поэтому не удивительно, что вторая в серии статья Fernando Cejas была про то, как он добавил RxJava в Clean Architecture.
Я не стану пересказывать статью, но хочу отметить, что, наверное, главным плюсом является возможность избавиться от интерфейсов Boundaries (как способа обеспечить выполнение Dependency Rule) в пользу общих Observable и Subscriber.
Правда есть люди, которых смущает присутствие RxJava во всех слоях, и даже в самых внутренних. Ведь это сторонняя библиотека, а убрать зависимость на всё внешнее – один из основных посылов Clean Architecture.
Но можно сказать, что RxJava негласно уже стала частью языка. Да и в Java 9 уже добавили util.concurrent.Flow, реализацию спецификации Reactive Streams, которую реализует также и RxJava2. Так что не стоит нервничать из-за RxJava, пора принять ее как часть языка и наслаждаться.
Заблуждение: Что лучше Clean Architecture или MVP?
Смешно, да? А некоторые спрашивают такое в чатах.
Быстро поясню:
- Архитектура затрагивает всё ваше приложение. И Clean – не исключение.
- А презентационные паттерны, например MVP, затрагивают лишь часть, отвечающую за отображение и взаимодействие с UI. Чтобы лучше понять эти паттерны, я рекомендую почитать статью моего коллеги dmdev.
Заблуждение: Clean Architecture в первых проектах
В последнее время архитектура приложений на слуху. Даже Google решили выпустить свои Architecture Components.
Но этот хайп заставляет молодых разработчиков пытаться затянуть какую-нибудь архитектуру в первые же свои приложения. А это чаще всего плохая идея. Так как на раннем этапе куда полезнее вникнуть в другие вещи.
Конечно, если вам все понятно и есть на это время – то супер. Но если сложно, то не надо себя мучить, делайте проще, набирайтесь опыта. А применять архитектуру начнете позже, само придет.
Лучше красивый, хорошо работающий код, чем архитектурное спагетти с соусом из недопонимания.
Фффух!
Статья получилась немаленькой. Надеюсь она будет многим полезна и поможет лучше разобраться в теме. Используйте Clean Architecture, следуйте правилам, но не забывайте, что «все мы пираты по натуре»!
Комментарии (192)

mefi100fell
11.08.2017 14:12+3Отличная статья. Спасибо. Особенно за главный посыл: «Все мы пираты по натуре».

basnopisets
11.08.2017 14:58+3Хорошая статья!
Про отсутствие знака равенства между MVP и Clean Architecture (и любой архитектурой приложения в целом) можно бы и поподробнее, а то заблуждение довольно распространенное. Мне даже как то минуса прилетали за попытки его опровергнуть


gandjustas
11.08.2017 15:55+2Продолжается соревнование сколько же классов надо чтобы вывести список заказов на экране :)
Nikita_Danilov
11.08.2017 16:30+2Сколько слоев, абстракций, интерфейсов и классов…
Но потом в 9 из 10 случаев выясняется что никто и не планирует никогда менять БД, менять протокол доступа или чтобы то ни было вообще менять, а всё равно через 3 года потребуется переписать.
Jeevuz Автор
11.08.2017 17:10+24 слоя, пара интерфейсов плюс пара классов. Не очень много, если не перебарщивать.
Все это не только для того, чтобы что-то менять. Помогает структурировать и разрабатывать командой. Тестировать, если эта роскошь доступна.Nikita_Danilov
11.08.2017 17:30+1Меня сильно напрягает стремление каждый слой отделить строго своим собственным набором сущностей/DTO объектов (абсолютно идентичных), а потом перегонять всё через AutoMapper туда-сюда по несколько раз. Поверх них еще навернуть абсолютно на любую зависимость интерфейсы, на каждую сущность интерфейсы либо абстрактные классы. Потом приходят люди и пытаются это осознать месяцами.
Полностью согласен с последней мыслью «Лучше красивый, хорошо работающий код, чем архитектурное спагетти с соусом из недопонимания.», и благодарен что она прозвучала. :)
Но всё равно часто забывают про целесообразность накручивания, именно целесообразность, а не «потому что могу забубенить такое».rraderio
11.08.2017 17:33+1отделить строго своим собственным набором сущностей/DTO объектов (абсолютно идентичных)
Зачем, если они идентичны?Nikita_Danilov
11.08.2017 17:44Потому что — было так канонично. На самом деле в статье про это упоминается, что в своё время маниакально стремились под каждый слой сделать отдельные DTO, аукается до сих пор.
Jeevuz Автор
11.08.2017 18:03Согласен с тем, что не нужно overengineering делать только для соблюдения "канонов". И старался это донести в статье. Даже хотел добавить о принципах YAGNI и KISS.

Cromathaar
12.08.2017 02:31+1Потому что это вопрос не разделения слоев (слои разделять надо), а выделения слоев. Описанный вами случай получается именно тогда, когда слои выделяют преждевременно, а не когда их в принципе разделяют. Ну а навешивание интерфейсов на все подряд — это банальное непонимание DI (который инъекция), к слоям оно имеет такое себе отношение.
Как тут не вспомнить Эйнштейна: «Всё должно быть изложено так просто, как только возможно, но не проще».

franzose
12.08.2017 02:00+1Ну, да. А потом мы в коде наблюдаем тут и там
::getInstanceи кучу других замечательных статических методов, отсутствие DI-контейнера (и незнание, что это такое вообще) и каких бы то ни было тестов. А что? Всё равно ж БД менять не будем, всё равно не понимаем отличие сущности от DTO и называем и то и другое моделями. Поэтому зачем усложнять?

ImangazalievM
11.08.2017 15:59Я всегда думал, что Entity — это POJO. Тогда что вы понимаете под объектами бизнес-логики? Статью я прочитал, поэтому прошу не определение, а конкретные примеры
Jeevuz Автор
11.08.2017 16:26Предположим, есть бизнес по продаже печенек. И есть правило, что всегда две печеньки продают со скидкой в 20%. Пишем мы для этого бизнеса приложение. Расчет скидки попадает в Entity. То есть будет класс, в котором метод для расчета скидки или функция такая. Это и есть Entity, логика бизнеса. Потому что это правило, которое будет общим для всех приложений, на какой платформе мы бы ни писали. Это логика бизнеса (в понимании сферы деятельности, компании, продуктов и т.п.).
Есть проблема в сочетании "бизнес-логика". В понимании разработчиков оно стало синонимом слова "логика" в целом, как мне кажется. Я поэтому стараюсь избегать его и говорить "логика бизнеса" или "логика приложения".
Nikita_Danilov
11.08.2017 16:38Можете, пожалуйста, привести примеры когда это «просто логика», а это «логика бизнеса»?
Jeevuz Автор
11.08.2017 17:03Конечно. Просто логика — это логика в общем понимании, любая. А логику бизнеса я описал выше.
Другими словами, есть те, кто путает понятия логики приложения и логики бизнеса.
А вы хотите похейтить или какой-то конструктив будет? ;)
Nikita_Danilov
11.08.2017 17:07Конструктив, наверное, но сначала хотел услышать мнение, не испортив его своим. :)
По моему опыту, я как то перестал видеть грань между «просто логикой» и «бизнес-логикой», став называть всё «логикой».
Обычно под «просто логику» попадает сначала то, до чего Бизнесу пока нет дела. Но со временем, этот кусок логики может затронуть бизнес и начать влиять на него. Тогда она превращается в бизнес-логику.
Касалось это по сути всего: обработки ошибок, значений по-умолчанию, валидаций и т.д.
gandjustas
11.08.2017 18:45+1Вот это вы зря привели такой пример. Если попробовать написать такой код, то будет сложно отделить Entity от UseCase. Как раз скидка 20% это usecase (interactor), а entity станет plain-object. Если масштабировать пример на разные правила скидок, то каждое правило будет своим объектом usecase, а список покупок будет List. Так удобнее даже в самых простых случаях когда один товар продается со скидкой.
Jeevuz Автор
11.08.2017 20:29Все зависит от того, что вы понимаете под use case. Скидка это Entity. И это не plain-object. Так же как вы написали можно масштабировать и с Entity, не вижу разницы.
gandjustas
12.08.2017 01:00Какой класс будет заниматься собственно применением скидки к заказу? Класс заказа, класс скидки?

sasha1024
12.08.2017 01:09+1А какая разница?
Да хоть обычная функция, принимающая в качестве параметров скидку и заказ.
ООП — это офигенно, но часто люди понимают слишком буквально.gandjustas
12.08.2017 01:20+1Разница есть, потому что "обычных функций" много и их распределение по "модулям" важно. В этом и суть архитектуры. Иначе получится что каждая сущность превратитcя в god-object.
sasha1024
12.08.2017 01:57Важно, но распределение по слоям — важнее (на порядки).
Фактически (на крайняк) можно считать entities тупо одним модулем (с каким-то количеством классов или даже PODO-структур внутри, вокруг которых набросаны методы/функции). Главное не смешать entities и view или entities и db (например), а разные entity как-то между собой разберутся.
Jeevuz Автор
12.08.2017 01:16Все зависит от use case когда нам нужна скидка. Пусть надо показать товары и цену. Для этого будет use case. Он получит Entity для расчета скидки, товары. Используя то что у него есть и применив логику для расчета скидки получит цену. И отдаст дальше.
Поэтому я отвечу, что Interactor, используя логику из Entity.gandjustas
12.08.2017 01:22Ну вот на сайте набиваешь корзину и тебе в правом верхнем углу нужно вывести сумму заказа с учетом скидок.
Какую логику из Entity будет использовать Interactor?
Jeevuz Автор
12.08.2017 01:33+1Пусть у тебя там 11 печенек. Берешь этот лист печенек, даешь их CookiePriceEntity, например. Та смотрит, что 10 делится на 2 и считает их цену за вычетом 20%, плюс цена 11-й печеньки. Ты получил свою цену в CalculatePriceInteractor-e своём, и отдал в UI.
gandjustas
12.08.2017 17:15+1CookiePriceEntity имеет только одну функцию получения цены со скидкой? Это только entity? Что тогда делает interactor?
Jeevuz Автор
13.08.2017 22:33В предыдущем посте же я написал, что он делает…
Реализует use case, то есть то, что нужно пользователю — отображение цены. Используя entity для подсчета цены со скидкой в нашем примере.

terrakok
13.08.2017 15:39+2Я кажется понимаю, что именно у всех вызвало "несварение". Смотрите: Ентити = список полей с данными + набор функций над этими полями.
Там не может быть методов, которые затрагивают другие поля или Ентити.
Никто же не будет выносить метод toString или hashcode в UseCase? В Entity только методы самого объекта, которые одинаковые в независимости от платформы, где используется этот объект.
Например представим метод getShortDescription, который возьмет только первый 20 символов из поля description.
- Если эта логика обусловлена бизнесом, то такому методу самое место в Entity.
- Если это особенность какой-то логики обединения description из разных Entity — то это будет в интеракторе.
- Если это только особенность UI, то это будет в презентере
gandjustas
13.08.2017 19:01Уходим от темы в неизвестном направлении. Давайте вернемся.
Рассмотрим простой случай. Есть простая логика расчета скидки. "Три по цене двух". Есть простой класс, который эту логику реализует.- — берет заказ на входе и возвращает "рассчитанный заказ" на выходе.
Этот класс будет entity или interactor\usecase? И почему?
Класс "логики скидки" своих данных не имеет и никуда не сохраняется.VolCh
13.08.2017 20:26По сути это будет Domain Service — вырожденный случай Entity без собственных данных (хотя внутри может быть какая-нибудь мемоизация, например). В слоях и поста он будет относиться к слою entity, а вызываться из слоя interactor\usecase. Почему? Скорее всего потому, что правило вычисления скидки независит от сценариев использования. Сценарии могут определять вычислять скидку или нет, по какому из доступных способов вычислять скидку ("десять процентов", "три по цене двух", "накопительная скидка по бонус-карте"), но сам алгоритм вряд ли зависит от сценария использования и может использоваться во многих.
terrakok
13.08.2017 22:30Вы привязались к примеру со скидкой.
Он не абсолютно удачный, так как можно сказать, что скидка на печеньки — особенность мобильного приложения одного конкретного магазина, при таком взгляде скидка будет в юзкейсе. Так как при переносе Entity на другую платформу, скидку переносить не нужно.
Но если взять пример Jeevuz, в котором скидка на печеньки — некоторая базовая штука (представьте, что это правило всех землян — делать скидку на несколько печенек), то это правило описывается, например, прямо в классе печеньки — и тогда все будет как описаноJeevuz Автор
13.08.2017 22:59Если нет бизнеса, и наше приложение само по себе, то скидка все равно может быть в Entity по определению:
If you don’t have an enterprise, and are just writing a single application, then these entities are the business objects of the application. They encapsulate the most general and high-level rules. They are the least likely to change when something external changes.
Просто скидка что-то очень общее. То что вряд ли будет меняться часто. И не будет зависеть от того надо ли показывать ее с бонусами или без скидки цену выводить и тп.
И опять же:
прямо в классе печеньки
Не обязательно в классе печеньки это делать. Даже я бы сказал не стоит может. Вдруг это работает и на печеньки и на конфетки. Это уже деталь реализации, так можно, но хочу заострить внимание, что это не обязательно так.
VolCh
13.08.2017 23:08+2Просто скидка что-то очень общее. То что вряд ли будет меняться часто.
Очень сильно зависит от бизнеса. В общем случае я бы моделировал скидки как стратегии, которые выбираются по соответствию сущностей спецификациям.
sasha1024
13.08.2017 22:33+1<offtop>
На самом деле Класс не может быть таким.
Класс обязан иметь данные (необязательно известные, например, abstract/pimpl) или быть таким, что сам факт его создания/уничтожения на что-то влияет (RAII), иначе это просто набор функций, а не класс.
Класс не набор функций, класс — это спецификация для экземпляра. Когда мы декларируем классFoo, мы должны сразу задуматься над тем, что олицетворяет собой один экземпояр этого класса; на что будет влиять то, вызвали ли мыfoo1.bar()илиfoo2.bar()или дажеfoo1.clone().bar(); если ни что / ни на что, то это не класс.
Хотя, конечно, в языках, которые не поддерживают нормальные namespace'ы, каждую функцию приходится волей-неволей пихать в «класс» (с приватным конструктором, «static class» или singleton). Но они от этого классами не становятся, просто наборы функций. Java/C# в этом плане здорово подосрали, испортив восприятие многими людьми парадигмы ООП.
</offtop>
А так полностью согласен в ответом terramok, что этот «класс» (на самом деле не класс, а просто subnamespace, но кто ж из современных ЯП такое выводит в отдельную категорию) должен быть или в entities, или в use-case в завимисоти от роли скидок.VolCh
13.08.2017 22:58Java/C# в этом плане здорово подосрали, испортив восприятие многими людьми парадигмы ООП.
Как по мне, то началось это с C++, но дело не в неймспейсах, а в отходе от парадигмы "всё есть объект и даже класс". С этой точки зрения статические методы вполне допустимы, если воспринимать класс как объект, знающий как создавать экземпляры определенного типа, как фабрику. Ну а ответом на вопрос "как создавать" вполне может быть "Никак, запрещено".
sasha1024
13.08.2017 23:07Та в том, то и дело, что не всё — класс.
В этом и разница между ООП и культом карго а-ля ООП; как в процедурных языках не всё — процедуры, в функциональных языках не всё — функции, так и в объектно-ориентированных не всё — объекты/классы.
Статические методы запрещать не стоит. А вот запрещать функции прямо в namespace'е (в Java и C#) было маразмом. И делать namespace' неполноценной сущностью (почему нельзя в одном файле сделать несколько namespace'ов, в смысле сразу дочерние namespace'ы? почему нельзя implement'ить concept/interface namespace'ом? и т.д.)Ну а ответом на вопрос «как создавать» вполне может быть «Никак, запрещено».
И тогда это не класс :) по-моему (если запрещено создавать вообще, а не protected constructor / abstract class).
Так что C++ даже больше ООП, чем…VolCh
13.08.2017 23:12Есть языки, в которых всё объект, ну или всё выглядит как объект. Правда, мне для таких языков больше нравится "объектные", а не "объектно-ориентированные".
И тогда это не классИ тогда это не класс
Класс, поскольку является спецификацией объектов определенного типа. Спецификация гласит "Объекты данного типа в истеме запрещены" :)
sasha1024
13.08.2017 23:37Есть языки, в которых всё объект, ну или всё выглядит как объект.
Я в курсе. Но я с этим не согласен: нужно отделять мухи от котлет. И уж особенно убого попытка запихнуть всё в классы выглядит в современных мейнстримовых языках (в каких-то очень хитрожопых языках спецназначения концепция «всё объект» может быть и прокатила бы, но для универсального языка это не так).
Спецификация гласит «Объекты данного типа в истеме запрещены» :)
Эээ :). Это было бы логично, если бы не одно но: объекты такого вида реально не запрещены. Вот если бы можно было декларировать какие-то общие требования а-ля: «запрещено создавать объекты с методом equals, но без метода hashCode», «запрещено создавать объекты, у которых есть поля foo и bar одновременно» (второе очень абстрактный, почти бесполезный вырожденный пример, но показывает corner-cases идеи о требованиях) и т.п. — то это было бы нормально. Но ведь если задекларировалиclass {X integer, Y integer}илиclass {method getSomething() {…}}как static (или с private constructor'ом), то никто не мешает рядом задекларировать такое же без пометки static (с публичным constructor'ом) и создавать экземпляры уже его. Поэтому логически это лишено смысла.
Зачем декларировать что-то, что нельзя создавать? Я понимаю, что существующие средства (классы) пытаются натянуть на свои цели (создать группу методов). И вроде как потребность удовлетворена, концепцию namespace'ов можно до конца не развивать. Но это ошибочный путь, свернув с логичной дороги, мы только теряем и будем терять ещё больше.sasha1024
13.08.2017 23:45Редакция не прокатила:
В каких-то экспериментальных или специальных языках, где само понятие «объекта» более размазано, такое может и прокатило бы. Но для универсального языка это неправильно (причём проблема даже не только в засорении понятия объект, а и недоразвитии параллельных направлений из-за этого).
sasha1024
13.08.2017 23:15ИМХО, конечно. Но это ИМХО для меня важное. Я просто не понимаю, как люди могут мыслить по-другому.
Jeevuz Автор
13.08.2017 22:52Будет Entity. Потому что это логика общая для всего бизнеса, а не только для приложения.
Jeevuz Автор
13.08.2017 22:50Не согласен с приведенной формулой. Entity не обязано иметь список полей.
Оно может быть просто функцией, может быть объектом наследующим тот у которого нужные поля, может принимать этот объект на вход метода, может просто принимать все поля на вход метода.
Entity также вполне может работать с несколькими объектами и использовать их поля для выполнения свой функиции. Ведь Entity это логика, метод, функция.
логики обединения description из разных Entity
Эта фраза подразумевает, что Entity объект. С чем я не согласен, как уже сказал.
Это не обязательно. А когда Entity не объект, то такая логика может быть в Entity, а не в интеракторе. Интерактор возьмет Entity, даст ей список разных description и Entity сделает что нужно с ними.
Интерактор же может потом еще другую логику из другой Entity применить или логику, которая не от бизнеса, а специфичная для приложения.
VolCh
13.08.2017 23:05+2Тут надо четко разграничать в каком контексте мы говорим об Entity. Entity дяди Боба — это Domain Эванса, состоящий из его Entity, ValueObject, Repository, Event, Service и т. д.
franzose
14.08.2017 00:54Оно может быть просто функцией
Если это функция, то как хранить состояние? Ведь у сущности есть состояние, которое обычно выражается значениями внутренних полей. И есть методы, которые это состояние показывают либо изменяют.
Jeevuz Автор
14.08.2017 03:15Так и сделать сущность отдельную. А функция её примет. Зачем логике внутреннее состояние?
Не обязательно смешивать логику и сущность, я об этом.franzose
14.08.2017 03:38+2Так соль-то в том, что как раз сущность и обладает бизнес-логикой. Иначе она будет анемичной с геттерами да сеттерами.
VolCh
14.08.2017 09:12Как минимум, смешивать имеет смысл когда логика изменяет только сущность или даёт какой-то результат, зависящий исключительно от состояния сущности и явно переданных параметров. Это даёт возможность пользоваться всем преимуществами инкапсуляции, прежде всего контролировать мутации состояния сущности.
Jeevuz Автор
14.08.2017 09:49Смешивать не проблема. Просто я говорю, что это не является обязательным.
2creker
11.08.2017 18:22+1Уже становится сложным представить современное Android-приложение без RxJava.
Посмотрите официальный исходный код телеграмм клиента. По моему достаточно большой проект. Но там нет данных паттернов и rxjava. (насколько я разобрался)
Это все хорошо — разделение на независимые компоненты итд + dependency injection итд. Но очень часто нет четкого понимания всего приложения — каким оно будет в конечном итоге, какие фичи будут реализованы, какие нет. Требования к приложению часто меняются очень быстро и банально приходится переписывать целые куски.
Если же сразу закладываться на расширяемую архитектуру, то не понятно насколько ее потребуется расширять в будущем(чтобы пользоваться преимуществами такой архитектуры). Это я все к тому, что часто проще начать писать как можно проще, чтобы как можно быстрее сделать прототип. Конечно какие -то базовые вещи надо соблюдать — отдельно модели, отдельно http client, что-то вроде single responsibility.
Jeevuz Автор
11.08.2017 18:25Не так уж и много эта архитектура просит закладываться. Отдача есть и в небольших проектах.
Если проще без архитектуры — пишите без. Но если после этого будет сложнее расширять проект или следующий разработчик будет огорчен — это на вашей совести ;)
Не понял при чем тут Телеграмм и Rx… Использовать технологию или нет — дело разработчика.
gandjustas
11.08.2017 19:24+1Я вот не очень понимаю что в вашем понимании "архитектура"? Это отдельные артефакты, которые не являются кодом приложения? Или отдельные классы, которые делают что-то (что?) Или отдельная активность (какой результат этой активности)?
Я всегда считал что архитектура приложения это правила декомпозиции задачи и композиции решения. Ты их в любом случае вырабатываешь в процессе написания кода.
Jeevuz Автор
11.08.2017 20:24Архитектура это набор рекомендаций/правил к тому как это делать.
gandjustas
12.08.2017 17:17Тогда что значит "без архитектуры"? на каждый блок кидать кубик — как лучше делать? Все равно человек своими внутренними правилами руководствуется, потому что так мозг меньше напрягается.

alaershov
11.08.2017 18:22+1Спасибо за прекрасную статью! Многое разложилось по полочкам.
Есть вопрос по реализации репозитория, которыйGateway. Если мы радостно впустили Rx в свою жизнь, чему я несказанно рад, то кто отвечает за управление потоками, в виде навешиванияsubscribeOn(...)или ещё чего-то? Я встречал два противоположных взгляда:
- "Я умный репозиторий, и я сам решу, в каком потоке у меня будут идти запросы в сеть"
- "Я синхронный репозиторий, и мне всё равно, в каком потоке меня будут использовать"
Вот с тем, что навешивать
observeOn(mainThreadScheduler)наInteractor— это ответственность презентера, всё вроде ясно, хотя и тут нет единообразия. А как быть с фоновыми потоками?Jeevuz Автор
11.08.2017 18:49Если вопрос о моем мнении, то я использую вариант №1. Он кажется мне логичнее, тк логика без понятия откуда данные приходят. Репозиторий скорее знает откуда идут данные, ему и решать что за поток.
filatoff
11.08.2017 18:43Спасибо за статью.
Можете объяснить, какой будет поток данных в случае, если необходимо получать данные от сервиса геолокации, к примеру, и обновлять UI без явного запроса пользователя?Jeevuz Автор
11.08.2017 18:46Геолокация = данные. Данные получает репозиторий. Явного участия юзера нет, но косвенно он захотел получать обновления местоположения установив/открыв приложение. Поэтому где-то на открытии мы можем вызвать свой "use case отображения местоположения" а тот уже попросит репозиторий уведомлять его и будет отдавать результат в UI.
Примерно так.

oleg_shishkin
11.08.2017 20:16+1Самое главное в этой статье — чтобы у всех в том числе у автора пришло бы понимание, что данная архитектура пришла из больших бизнес систем. Где основное требование — это их полная адаптивность и независимость, позволяющая быстро перестраиваться под изменяющиеся внешние требования. Поэтому например автор ратует за RxJava(которую я думаю специально притащили с винды) — не понимая, что она жестко требует от системы наличия ПОСЛЕДОВАТЕЛЬНОСТЕЙ и только ПОСЛЕДОВАТЕЛЬНОСТЕЙ. И если вам потребуется завтра где-то ввести параллельную новую ветку — вся ваша система слетит. В мире Clean Architecture царят только события. И правильная(продуманная) обработка событий — основа данной архитектуры. Поэтому вопрос как делить на слои и сколько будет слоев — абсолютно вторичен и не играет большой роли. Важно чтобы слои были абсолютно независимы. Чтобы объект слоя принимал и отдавал события (объект, который содержит все что нужно для дальнейшей обработки). Поэтому бесперебойная транспортная система — это основа данной архитектуры, от которой зависит вся система в целом. И на андроиде просто приходиться подстраиваться под ее lifecycle, соответственно подстраиваясь под все повороты. Как и в жизни. То заказчик отъехал, то деньги не заплатил, то ему уже не нужен товар. Clean Architecture — это попытка достоверно описать нашу жизнь. Ее оптимизировать и улучшить
Jeevuz Автор
11.08.2017 20:20Последовательность != Прямолинейность. RxJava отлично справляется с параллельными ветками. И любой поток — последовательность событий. Так что, я не понимаю к чему первая половина коммента.
oleg_shishkin
11.08.2017 21:10Последовательность — это разделенные по времени(асинхронные) события. Т.е. если смотреть сверху в течении промежутка времени — то параллельный поток событий можно отобразить на последовательность событий. Т.е. RxJava возможно использовать, если Вы гарантируете, что при дополнительном ветвлении параллельного потока событий не произойдет смена логики. Например — вы поставляете товар заказчикам. Обычная последовательность. Вдруг ваш основной заказчик — вдруг не может оплатить/разгрузить товар или любое др событие. Ваша последовательность заказал — доставил — оплатил ломается. Вывалиться по ошибке — можно (у RxJava только 2 состояния). Но это ваш основной заказчик. Или на Android — например Activity имеет несколько взаимозависимых фрагментов. Но Activity создает фрагменты в любом порядке — ей плевать на все ваши зависимости. Или жизненный цикл activity — когда событие onDestroy activity может приходить после события onCreate этой же activity — хотя по логике activity должна быть уничтожена, а потом создана — но это Activity — ей можно все (это встречается повсюду в тесте monkey, когда события сыплются как из пулемета). Вот на таких последовательностях и ломается RxJava. Или более сложная система — система с гарантированной доставкой. Поддерживает несколько каналов связи (абсолютно ничем несовместимых кроме интерфейса — принять/передать) и динамически сменяет каналы в зависимости от возможностей среды и имеет сложную логику контроля доставки, которая не подразумевает 100% вероятности доставки. Т.е. RxJava — это решение, когда подразумевается 100% вероятные решения (положительные/отрицательные), когда внешняя логика поведения гарантированно неизменна. А не так как на Android — захочется ей и тебе прилетит в listener null вместо объекта (monkey очень дает много пищи для размышлений)
Jeevuz Автор
11.08.2017 21:44Вы вешаете проблемы Android на плечи RxJava.
Это инструмент. Не нравится не пользуйтесь.
Если вам не нравится ArrayList вы можете писать на массивах. Это ваш выбор.
Не вижу особой связи со статьей. Я сказал, что можно не париться о RxJava, но вы не обязаны этому совету следовать. Не хотите — не используйте. В чем проблема-то?oleg_shishkin
11.08.2017 22:14RxJava пришла с платформы Windows. Она имеет все особенности Windows (потому что на ней писалась). Попытки привязать к ней lifecycle и прочие плюшки android — остаются плюшками. Использовать систему написанную под одну систему на другой — глупо, но можно. Как например использовать реляционные БД для хранения объектов (которые разрабатывались вообще не для этого и должны использоваться не для этого) и соответственно писать ORM для реляционных БД. Использовать можно все. И микроскопом можно забивать гвозди. Но давайте использовать лучше молоток для этого, а микроскоп использовать для другого. Т.е. оставим каждому инструменту свою область применения.
sasha1024
12.08.2017 00:53+1А мне нравится идея ORM.
oleg_shishkin
12.08.2017 01:13-1Сама идея прекрасна, но ее лучше всего реализовать на объектных БД. Она начинает сильно проседать на объектах с большим количеством листьев. Т.е. возьмем счет-фактуру — пока в ней до 10 строк все более менее прекрасно, но когда более 100 записей — тянуть хвост в 100 записей, когда дай бог изменяется 1 строка глупо. Т.е. для каждой области должны быть свои решения. Много деревьев и мало листьев — самое место ORM. Где надо работать с огромными простынями — глупо использовать ORM. Просто решения для БД в 2 Мб одни, а для 500 Мб на мобиле с андроид 2.36 и 48 метрами под activity совсем другие. Тогда уже смотрят как выбирать данные — курсорно (аля Oracle) или листами(кортежами — наборами строк как в MS SQL). Тогда уже не до объектов — а строго только через View БД, включающими только столбцы для просмотра.
gandjustas
12.08.2017 01:24+1А зачем тянуть 100 строк? Почему нельзя вытянуть одну строку и поменять её?
И при чем тут ORM?
sasha1024
12.08.2017 01:47+2Эмм, а зачем для объектных СУБД ORM? ORM как раз и нужна для того, чтобы сымитировать объектную СУБД из реляционной. Если СУБД уже объектная (по-настоящему объектная, а не маркетологически), то ORM не нужен.
тянуть хвост в 100 записей
Это вопрос качества ORM. Хорошая ORM (правда на практике я таких не видел, кроме недописанной своей) позволяет загружать любые данные сразу, по востребованию или никогда. А-ля var bill := Invoices.byId(7631).load('itemCount', 'totalPrice', 'items(filter: $.enabled, order: [$.title ASC], offset: 20, limit: 10)') — загружает счёт №7631, при этом в дополнение к стандартным свойствам загружает лишь количество строк, общую стоимость и те-из-строк-которые-enabled-отсортированные-по-title-начиная-с-20й-по-29ю (остальные связи один-ко-многим и даже многие-к-одному у Invoice пока не загружаются).
Много деревьев
По-моему, деревья всегда очень глубокие.
строго только через View БД
Хорошая ORM ни к каким реляционным возможностям доступ не ограничивает. Объектное возможности — это строгое надмножество реляционных возможностей. Делая объектный адаптер к реляционному, ми теоретически ничего не теряем.oleg_shishkin
12.08.2017 09:18Хорошая ORM ни к каким реляционным возможностям доступ не ограничивает. Объектное возможности — это строгое надмножество реляционных возможностей. Делая объектный адаптер к реляционному, ми теоретически ничего не теряем.
Чисто только теоретически. Это тоже самое, что и связывание таблиц в SQL запросах. На бумаге и в теории все просто. В реальности уже на join таблиц > 8 получаешь проседание, а при >16 оно может быть просто критическим.
В реальности например всегда требуется просмотр всего инвойса. Соответственно ORM тянет все содержимое инвойса — целостной сущности. Меняем 1 строку и записываем — ORM по этой команде должна обновить инвойс — что делается почти всегда 2 операциями — удалить старую сущность, а затем добавить новую сущность. При этом вы всегда попадаете на удаление/вставку туевой хучи данных. Это как использовать 1с из коробки. Все прекрасно пока листьев мало. Т.е. все прекрасно — но только для конкретных условий. Разработчик не может мыслить реляционно — бога ради пускай использует ORM пока не нарвется (а в большинстве случаев — и нет) в провале производительности. Вопрос для примера — заказчик требует просмотра сразу отсортированных 10000 записей на экран смарта(ему так нравиться). Как это организовать в RecyclerView(помним что всего одна строчка кода — cursor.getCount() приводит к fetch всех 10000 строк в БД)? Но самый страшный вопрос — как организовать обновление этого списка при новомодном livedata(обновление UI при изменении данных). Помним, что при этом он может с легкостью выйти из просмотра списка(destroy fragment и все прелести после этого) и при этом он должен быть в рамках нашей архитектуры, когда UI отделен от выборки данных.sasha1024
12.08.2017 11:22+2В реальности уже на join таблиц > 8 получаешь проседание
Можете привести пример реального проседающего запроса из практики? Чтобы я конкретно представлял, что именно Вы имеете в виду, а не думал о чём-то другом.
В моём представлении join из 8 таблиц будет сильно проседать только если СУБД по глупости выбрало неправильную стратегию join'а.
И как раз дополнительный слой между СУБД и потребилитем данных имеет все шансы позволить решать эту проблему автоматически; например, если СУБД стабильно выбирает неправильный порядок nested look для запроса SELECT i.*, o.* FROM order_items i JOIN orders o ON i.order_id=o.id WHERE o.date BETWEEN? AND ?, делать автоматически SELECT * FROM orders WHERE date BETWEEN? AND? и SELECT * FROM order_items WHERE order_id IN (<список id из прошлого запроса>).
Хотя, может, я слишком оптимистично на это смотрю.
В реальности например всегда требуется просмотр всего инвойса. Соответственно ORM тянет все содержимое инвойса — целостной сущности.
И правильно.Меняем 1 строку и записываем — ORM по этой команде должна обновить инвойс — что делается почти всегда 2 операциями — удалить старую сущность, а затем добавить новую сущность. При этом вы всегда попадаете на удаление/вставку туевой хучи данных.
Мне кажется, даже наитупейшие ORM такого делать не должны. Только изменённая строчка записывается (одним UPDATE'м).
Разработчик не может мыслить реляционно
Проблема не в том, что разработчик не может мыслить, а проблема в том, что это неэффективно. Эффективно юзать объектную СУБД с объектным языком запросов. Но таких пока не подвезли (или те, что есть, по каким-то причинам не подходят), поэтому юзаем реляционную СУБД с прослойкой над ней.
Я не спорю, что большинство реальных имплементаций ORM suck. Но не стоит из-за этого считать ущербной саму идею.
Вопрос для примера… 10000 записей на экран смарта
Ну, 10000 записей на экран не влазят. По-любому должна быть какая-то page'инация или дозагрузка при прокрутке.RecyclerView… livedata
Честно говоря, я не в курсе разработки для Android; можете для идиотов пояснить, в чём проблема?UI отделен от выборки данных
Может быть я неправильно интерпретирую данную архитертуру, принимая желаемое (то, как считаю правильным писать я) за действительное (то, что описано в этой статье). Но по-моему действию, UI как раз должен управлять выбором данных — только через другие слои. То есть когда нужны ещё записи, он запрашивает не «ещё 10 строк из такой-то таблицы; а к каждой из них выкачать ещё то-то из таких-то таблиц; и произвести такие-то рассчёты над этим», а «ещё 10 entities по такому-то условию». Ну а дальше уже через Repositories в DB (хотя, ещё раз повторюсь, я никогда не писал для Android).oleg_shishkin
14.08.2017 12:41Я максимально пытаюсь уйти от архитектуры андроид с ее неполноценными жизненными циклами. И максимально адаптировать архитектуру под активный легкий клиент — пассивный сервер. Но жизнь возвращается и все эти livedata, над которыми смеялись разрабы 20 лет назад — как будто и не было этих лет. И в данных условиях приходится отказываться от пассивных серверов, к каким-то другим решениям. И в настоящее время ищется такое решение. Которое видится в архитектуре ядро + подключаемые легкие модули (аналог Clipper 5, если кто знаком с его архитектурой). Админ только управляет загрузкой/связыванием модулей. Не путать c Dagger 2 — правильной будет архитектура ядро + подключаемые(именованные) процессы (c EventBus внутри каждого) — но она очень тяжеловесна — но позволяет все.
sasha1024
14.08.2017 14:47+1Честно говоря, мало понял, о чём Вы говорите. Не в смысле, что Вы в чём-то неправы (и поэтому не понял), а просто не понял из-за малой осведомлённости.
oleg_shishkin
14.08.2017 15:11-1В стародавние времена был такой язык Clipper (писала писала группа разрабов объединенных под крылом Nantucket). Они предложили революционную тогда технологию для приложения — микроядро(загружала/выгружала модули и делала сборку мусора). Идею портировали под Linix — но проект умер. По сравнению с Clipper Clean Architecture — просто дитя той архитектуры. Ты мог подключить динамически любые модули в любое время, разбить свое приложение как тебе нравиться — поддерживая интерфейс только модульности. Поэтому вопрос о Clean Architecture — это вопрос о частном разбиении на слои(модули), где каждый может разбивать свое приложение как хочет — и будет прав. Одно плохо, что в android начинают затаскивать кусочки всякой всячины. И приходится следовать моде. То узкие штаны, то широкие.
franzose
13.08.2017 11:18+1А для чего нужна куча джойнов? В крайнем случае один запрос можно разбить на несколько более мелких.
Вопрос для примера — заказчик требует просмотра сразу отсортированных 10000 записей на экран смарта(ему так нравиться).
Объяснить, что сразу 10 000 записей выводить на экран не стоит, а стоит сделать пагинацию или «бесконечную» подгрузку, и указать на производительность.
oleg_shishkin
14.08.2017 12:20Клиент за 1 лицензию на 1 устройство платит на уровне лицензии 1с. Поэтому вопрос не стоит как-то отпадает сразу. Помним — это не Россия.
Использовалось несколько вариантов загрузки больших списков:
— тройная буферизация + метод скользящего окна
— постоянный курсор в памяти + fetch при достижении предпоследней страницы (самый тормозной)
— подгрузка данных в фоне небольшими порциями
у каждого метода есть свои плюсы и минусы. Хотелось бы узнать — кто еще что может предложить?franzose
14.08.2017 13:37Не понял, как одно связано с другим.
oleg_shishkin
14.08.2017 13:49Клиент хочет список из > 10000 строк и чтоб он появлялся с задержкой не более 2 сек и чтоб он лазил по-нему/скроллил/фильтровал/искал с задержкой не более 2 сек. И его не волнует, что это андроид например 2.36 (и 48 метров под activity). Он заплатил. И вот теперь может, кто подскажет еще решения полной работы с длинными списками. В свете последней новомодной livedata (помним что content provider в 99 случаях из 100 возвращает только то что таблица изменилась)
oleg_shishkin
14.08.2017 13:58Для примера попробовать силы могу предложить — загрузите в андроид КЛАДР и попробуйте сделать в нем удобный поиск/фильтрацию (т.е. например проверку достоверности паспортных данных). И попробовать поработать например с местом жительства Солнечный/Советский
mayorovp
12.08.2017 11:14Entity Framework:
var bill = ctx.Invoices.Single(x => x.Id == 7631); ctx.Entry(bill).Collection(x => x.Items).Query().Where(x => x.Enabled).OrderBy(x => x.Title).Skip(20).Take(10).Load(); var itemCount = ctx.Entry(bill).Collection(x => x.Items).Query().Count();
Или вам принципиально чтобы это делалось одним запросом?
sasha1024
12.08.2017 11:39Из приведенного куска кода я не могу понять, в каком месте из БД загружаются поля самого bill. Вот это вот var bill = ctx.Invoices.Single(x => x.Id == 7631) — это чисто создание запроса (а потому будет lazy load или явный load по какой-то команде) или это уже загрузка?
Или вам принципиально чтобы это делалось одним запросом?
Безусловно. Само ORM из это потом может разбить на несколько SQL-запросов. Но запрос от пользователя к ORM должен быть строго 1.
И ещё Вы пропустили подсчёт суммарной стоимости (aggregate-сумма цен всех item'ов в счёте, даже тех, что не попали в выборку из-за не-enabled либо паджинации).mayorovp
12.08.2017 11:46var bill = ctx.Invoices.Single(x => x.Id == 7631)— это уже загрузка.
Суммарная стоимость:
var totalPrice = ctx.Entry(bill).Collection(x => x.Items).Query().Sum(x => x.Price * x.Count).
Полностью вот так получится:
var bill = ctx.Invoices.Single(x => x.Id == 7631); var items = ctx.Entry(bill).Collection(x => x.Items).Query(); items.Where(x => x.Enabled).OrderBy(x => x.Title).Skip(20).Take(10).Load(); var itemCount = items.Count(); var totalPrice = items.Sum(x => x.Price * x.Count);sasha1024
12.08.2017 11:57-2Ну значит Entity Framework, с моей точки зрения — ещё один отстой, не реализующий до конца ORM. Но спасибо за экскурс по нему. На практике часто приходится пользоваться тем, что есть, даже если оно некрасивое (а не велосипедить по каждому чиху).
И ещё — меня смущает — не будет ли Entity Framework выгружать все item'ы счёта для подсчёта стоимости (сделает ли она items.Sum(x => x.Price * x.Count) на уровне СУБД)?mayorovp
12.08.2017 11:58+2Сделает на уровне СУБД, конечно же. Точно так же как на уровне СУБД делаются сравнение
x.Id == 7631, проверкаx.Enabled, сортировка поx.Title, а также операции.Skip(20)и.Take(10)и подсчет.Count()sasha1024
12.08.2017 12:02Интересно, как это технически реализовано.
На вход Item::Sum передаётся closure.
Что дальше? Неужели как-то методами Reflection парсится эта кложура? Не думал, что в C# такое возможно.mayorovp
12.08.2017 12:06+2Нет, на вход передается подготовленное компилятором AST.
Эквивалентный код:
var x = Expression.Parameter(typeof(InvoiceItem)); var body = Expression.Multiply(Expression.Property(x, "Price"), Expression.Property(x, "Count")); var totalPrice = items.Sum(Expression.Lambda<Func<InvoiceItem, decimal>>(body, x));
mayorovp
12.08.2017 12:17+1PS Кстати, парсить байт-код через рефлексию тоже возможно, для этого есть библиотека DelegateDecompiler.
Но нам она не понравилась (в основном, из-за бага #52, который так и не исправили несмотря на мой PR).
mayorovp
12.08.2017 11:53PS чем запрос от пользователя к ORM отличается от вызова подпрограммы? Для любой ORM можно написать свою функцию которая будет делать несколько запросов и возвращать что требуется.
sasha1024
12.08.2017 12:56Тем, что ORM должен предоставлять действительно объектный интерфейс над реляционной СУБД — а не просто какой-то интерфейс (чуть побольше возможностей, чем чисто реляционный, но всё равно ни то, ни сё).
Вот в ту же степь: GraphQL.
P.S.: Хотя то, что C# в целом и Entity Framework в частности позволяют делать items.Sum(x => x.Price * x.Count) на уровне СУБД, меня, конечно, приятно удивило. Я ожидал чуть больших заморочек для проброса запросов на уровень СУБД (мой пример выше с totalPrice предполагал наличие явно объявленного в классе Invoice свойства totalPrice с некоторым атрибутом (аннотацией), принимающим строковый фрагмент квазиSQL-кода в качестве параметра). Но всё равно — они (Entity Framework) очень постарались, что бы реализовать неполный объектный интерфейс (лучше б наоборот: сделали красивый интерфейс, а потом постепенно улучшали реализацию, ИМХО).gandjustas
12.08.2017 17:24Простите, кому должен? И кто вообще придумал эту глупость?
ORM помогает строить запросы к базе и отображать результаты запроса на объекты.
Ты еще больше удивишься, когда узнаешь что EF умеет делать "действительно объектный интерфейс над РСУБД", со всеми гадостями типа lazyload. Только им никто не пользуется в наше время.
sasha1024
12.08.2017 17:39«Должен» в смысле «„так правильно“ по моему личному мнению». Вы можете придерживаться другого мнения, кто ж спорит.
lazyload
«Загрузить всё то, что мне надо сразу (наиболее эффективным методом) по моему явному запросу» ? «lazyload».
Действительно объектного интерфейса в Entity Framework по этой причине не вижу. (Как и в большинстве других ORM, на самом деле.) (Хотя у него есть какие-то свои плюсы.)gandjustas
12.08.2017 17:44EF умеет и LL, и практически любой запрос (с проекциями и джоинами) без ручного выпиливания SQL.
Действительно объектного интерфейса в Entity Framework по этой причине не вижу.
Тогда пример "Действительно объектного интерфейса" в студию!
sasha1024
12.08.2017 18:53То, с чего началась эта подподветка:
var bill := Invoices.byId(7631).load('itemCount', 'totalPrice', 'items(filter: $.enabled, order: [$.title ASC], offset: 20, limit: 10)') — загружает счёт №7631, при этом в дополнение к стандартным свойствам загружает лишь количество строк, общую стоимость и те-из-строк-которые-enabled-отсортированные-по-title-начиная-с-20й-по-29ю (остальные связи один-ко-многим и даже многие-к-одному у Invoice пока не загружаются)
— Entity Framework может?
То есть:- По умолчанию для каждого класса загружается какой-то его стандартный набор свойств. Каждое из которых может быть полем, значением-вычисляемым-СУБД, связью многие-к-одному, связью один-ко-многим или ещё чем-то. Хорошо бы стандартный набор свойств для каждого класса был настраиваемым — но обычно это просто все поля соответствующей таблицы (но без значений-вычисляемых-СУБД, связей и пр.).
- Делая явный запрос к ORM (мол, загрузи мне то-то, то-то и то-то), есть возможность запросить свойства в дополнение к обычным (например, некоторые значения-вычисляемые-СУБД или часть из связей). Причём если дополнительное свойство — связь (т.е. фактически entity или набор of entities), то для него тоже можно запросить дополнительные свойства — и так до любой конечной глубины (аналогично вот этому). Причём это касается и запросов к ORM вида загрузи мне одну сущность, и запросов к ORM вида загрузи мне набор.
- Потом, конечно, не загруженно можно дозагружать через lazy load или отдельными явными дозагрузками.
Вот меня интересует второй пункт, например:
var bill := Bills.byId(3287, [ //bill №3287 с доп. загр. сл. св.:
Bill::itemCount, //значение-вычисляемое-БД
Bill::totalPrice, //значение-вычисляемое-БД
manyToOne(Bill::customer, [ //мн-к-од с доп. загр. след. св.:
Customer::invoiceCount, //значение-вычисляемое-БД
manyToOne(Customer::targetGroup, […]), //мн-к-од с доп. св.
Customer::assignedManager //мн-к-од без доп. загр. свойств
]),
Bill::amendments, //од-ко-мн (все строки, без доп. загр. свойств)
oneToMany( //один-ко-многим (не все строки, с доп. свойствами):
Bill::items,
.orderBy = order(BillItem::title, ASC),
.limit = 50,
.rowExtraProps = [
BillItem::productType,
manyToOne(BillItem::performer, […])
]
)
]);
mayorovp
12.08.2017 20:15При желании — нечто похожее несложно сделать средствами языка, поэтому не вижу смысла включать эту функциональность в ORM.
var bill = ctx.Bills.Find(3287) .LoadItemCount(ctx) .LoadTotalPrice(ctx) .LoadCustomers(ctx, ...)sasha1024
12.08.2017 20:42Хех, так это, с моей точки зрения, сама суть ORM. ORM должен предоставлять пользователю объектный интерфейс (язык объектных запросов), иначе это не вполне ORM.
Потом, в Вашем варианте, насколько я вижу, операции выполняются пошагово. То есть бы сначала получаем Bill (ctx.Bills.Find(3287)), потом у него количество элементов (bill.LoadItemCount(ctx) — и возвращаем снова bill (offtop: method-chaining, IMHO, уже признак плохого дизайна)), потом получаем суммарную стоимость (bill.LoadTotalPrice(ctx) — и возвращаем снова bill), потом получаем заказчика (bill.LoadCustomers(ctx)). Это как раз то, чего я хочу избежать.
Мы должны просто передать в ORM спецификацию того, что мы хотим получить — и она должна обратиться в СУБД сама, сделав минимум запросов (точнее необязательно минимум, а сконструировав запросы наиболее оптимальным способом — а некоторых кривых СУБД разбить один запрос на два оказывается эффективнее). В нашем примере — это один однострочный запрос из таблицы bills и два многострочных запроса: из таблиц bill_amendments и bill_items.
gandjustas
12.08.2017 21:05Както-так:
from b in bills where b.id = 3287 select new { Bill = b, ItemCount = b.Items.Count(), ItemsFiltered = b.Items.Where( i => i.Enabled).OrderBy(i => i.Title).Skip(20).Take(10) };
Только смущает план этого запроса. Мне кажется лучше будет сделать два — один на bill и количество, а второй на items.
Ну и по хорошему надо точную проекцию выписывать, а не загружать целые объекты.
sasha1024
12.08.2017 22:07Неплохо. Но Вы потеряли totalPrice. И ещё вопрос: оно Bill, ItemCount и TotalPrice (если его добавить) одним SQL-запросом получать будет (или 3 разных)?
mayorovp
13.08.2017 10:36Если делать так — то одним. Но его план будет страшным, поэтому я никому не рекомендую так делать.
sasha1024
13.08.2017 11:35Хреново, что план будет страшным.
В идеале, по-моему, это стоит добывать двумя запросами: один (bills b JOIN (SELECT bill_id AS id, … FROM bill_items GROUP BY bill_id) s ON b.id=s.id) для свойств bill'а и агрегатов над item'ами (которые по сути тоже свойства bill'а) и второй собственно для item'ов (SELECT … FROM items — без группировки).
В идеале оно бы должно само разбить. Странно, что оно делает один. (Я ожидал, что оно по тупости наоборот слишком много запросов сделает.)mayorovp
13.08.2017 11:41С чего бы оно много запросов делало? 1 запрос всегда преобразуется в 1 запрос.
sasha1024
13.08.2017 11:54(До слов «1 запрос всегда преобразуется в 1 запрос» я думал, что это временный баг, мол, пока генерится один запрос, а потом подправят.) Тогда это не то, что я думал, и смысла в этой фиче, соответственно, гораздо меньше.
gandjustas
13.08.2017 19:07Это не баг, а фича. EF (и другие linq-генераторы) не пытается умничать. Ты написал запрос — один запрос улетит в базу. Хочешь несколько — пиши несколько. Если написал что-то что не преобразуется в SQL — получи эксепшн, никакие воркэраунды EF делать не будет.
Гораздо хуже, когда Фреймворк начинает "умничать" генерируюя кучу работы из одного оператора или наоборот. В это случае получается слабоконтролируемое и слабопрогнозируемое поведение.
Вообще одно из качеств хорошего Фреймворка — он не умничает.
sasha1024
13.08.2017 19:15Я просто достаточно смутно представляю себе, как два несвязанные запроса из двух различных таблиц можно эффективно реализовать одним SQL-запросом. Например, получить все bill'ы с такой-то даты по такую, отсортированные по дате — и для каждого из них получить по 10 первых пунктов (пункты отсортированны по названию). Это как вообще одним SQL-запросом, по-моему, это рациональнее двумя делать — нет?
gandjustas
13.08.2017 19:39А в чем проблема?
1) Есть запрос, который возвращает нужные bill
2) Есть запрос, который возвращает по 10 первых пунктов для каждого bill
3) делаем джоин этих запросов
получится по одной строке для каждого пункта, а колонки в начале строки будут содржать информацию из bill.
Что рациональнее знает оптимизатор, потому что владеет не только структурой, но и реальной статистикой распределения данных с учетом фактических параметров (хотя сама по себе задача построения оптимального плана выбора по диапазону дат сосвсем нетривиальна).
sasha1024
13.08.2017 19:54Уточню: получить первые 15 bill'ов с такой-то даты по такую (отсортированные по дате) — и для каждого из них получить по 10 первых пунктов (пункты отсортированны по названию).
То есть дублировать информацию про bill в каждом из 10 (или меньше) его item'ов? Ну, мне кажется, рационально так было бы делать в том случае, если основной запрашиваемой сущностью был item (и мы бы его джоинили с родительским bill'ом). Но когда (в нашем случае) основной запрашмиваемой сущностью является bill — это как-то странно.
И вообще, как Вы таки напишете запрос, возвращающий по 10 item'ов для каждого bill'а, соответствующего определённому условию? Может, как-то можно, но я этого способа просто не знаю. Только с двумя запросами.
В идеальном мире SQL должен был бы поддерживать табличный тип данных. Тогда бы мы написали:
SELECT b.*, (SELECT i.* FROM bill_items i WHERE i.bill_id=b.id ORDER BY i.title LIMIT 10) AS items /*в этой ячейке целая таблица (или курсор view)*/ FROM bills b WHERE …Но в SQL пока такого не подвезли.
Offtop: хренасе хабр SQL-код рендерит, лучше уж <code>, чем <source>.gandjustas
13.08.2017 21:41Напишу такой запрос через row_number() over (partition… order by ...). Это совсем несложно. В EF этакое делается как раз через skip\take
Что касается дублирования информации в возвращаемом resultset, то чаще всего оно ничтожно мало по сравнению со временем чтения с диска. То есть лучше силы потратить на выписывание проекций и индексы, чем на попытку уменьшить данные передаваемые от СУБД к приложению.
Кроме того затягивать в приложение за раз больше 1000 строк — вообще странная затея.
sasha1024
13.08.2017 22:18Т.е.
WHERE row_number() OVER (PARTITION …) <= 10— так что ли?
Что касается дублирования информации в возвращаемом resultset, то чаще всего оно ничтожно мало по сравнению со временем чтения с диска
Я понимаю, что дублирование информации в возвращаемом resultset практически не влияет на производительность по сравнению с чтением с диска. Тут дело не в производительности. А в том, что это банально против логики (и гнаться за производительностью конкретно в этом случае мне кажется чем-то в стиле «premature optimization»).
Если целью запроса является дочерняя сущность, то подгрузить сразу и родительскую через JOIN (и пусть она дублируется) — конечно, не вопрос. Но если целью запроса является именно родительская сущность (а первые дочерние 5 штук идут просто как дополнительная информация), то размазывать родительские экземпляры на несколько строк каждый и в таком неудобном для чтения виде их возвращать — некрасиво, Вам не кажется?
Опять же таки: а что если мы для родительской сущности запрашиваем сразу несколько видов дочерних сущностей? Ну, например, если хотим такой результат в UI:• bill #1 (первые 3 item'а этого bill'а) (первые 3 amendment'а bill'а)
— неужели Вы будете JOIN-ить всё со всем, и потом выковыривать эти 10 bill'ов, размазанные по 90 записям?
• bill #2 (первые 3 item'а этого bill'а) (первые 3 amendment'а bill'а)
• …
• bill #10 (первые 3 item'а этого bill'а) (первые 3 amendment'а bill'а)
Кроме того затягивать в приложение за раз больше 1000 строк — вообще странная затея.
А где Вы увидели больше 1000 строк? Во-первый, цифры LIMIT'ов были от балды (просто чтобы продемонстрировать возможную необходимость сортировки/лимитирования/прочая, а не что нам достаточно тупо достать все item'ы для каждого bill'а в любом порядке); во-вторых, даже при тех цифрах получалось максимум 15 bill'ов + 15*10 item'ов = 165 записей (а на самом деле логически всего 15, потому что цель запроса именно bill'ы, а остальное просто сопровождающая информация; в новом примере же максимум 10 bill'ов + 10*3 item'ов + 10*3 amendment'ов = 70 записей — а логически опять таки всего 10 основных экземпляров + несущественная сопровождающая информация для них).gandjustas
13.08.2017 22:25+2WHERE row_number() OVER (PARTITION …) <= 10 — так что ли?
да
Что касается скорости. Я напишу для начала как проще (меньше писать), а потом буду смотреть планы. Гадать, не имея реальной схемы, реальных данных и реальных запросов, вообще бессмысленно.
gandjustas
13.08.2017 19:04На практике один "большой и страшный запрос от EF" имеет план лучше, чем два запроса с передачей данных вручную. Потому что большинство баз умеют строить планы исходя из повторного использования частей запросов (подзапросов и джоинов) и дают лучший результат, чем ручное последовательное скармливание запросов базе.
sasha1024
13.08.2017 19:06Что значит «с передачей данных вручную»?
gandjustas
13.08.2017 19:09Обычно несколько запросов надо когда ты первым запросом получаешь набор данных, а потом во второй передает результаты первого (обработанные каким-либо образом).
sasha1024
13.08.2017 22:58Та дело не в скорости. Дело в логике. А если три-четыре-пять разных видов дочерних entity для каждого счёта нужно доставать, например, ожидается такая табличка в UI:
№ счёта | Первые 3 к-агента | П-вые 5 пунктов | П-е 4 правки | П-е 3 foo | П-е 3 bar
--------+-------------------+-----------------+--------------+-----------+----------
… | …, …, … | …, …, …, …, … | …, …, …, … | …, …, … | …, …, …
--------+-------------------+-----------------+--------------+-----------+----------
… | …, … | …, …, … | | | …, …
--------+-------------------+-----------------+--------------+-----------+----------
… | … | …, …, …, …, … | … | …, …, … | …, …, …
--------+-------------------+-----------------+--------------+-----------+----------
… | …, … | …, …, … | | … |
--------+-------------------+-----------------+--------------+-----------+----------
… | … | …, …, …, …, … | … | …, …, … | …, …, …
--------+-------------------+-----------------+--------------+-----------+----------
… | …, …, … | …, …, …, …, … | …, …, … | …, …, … | …, …, …
--------+-------------------+-----------------+--------------+-----------+----------
… | …, … | …, …, … | | | …, …
--------+-------------------+-----------------+--------------+-----------+----------
… | … | …, …, …, …, … | … | …, …, … | …, …, …
--------+-------------------+-----------------+--------------+-----------+----------
… | …, … | …, …, … | | … |
--------+-------------------+-----------------+--------------+-----------+----------
… | … | …, …, …, …, … | … | …, …, … | …, …, …
— да, вот такую вот детальную сводную таблицу по последним 10 счетам заказчик, допустим, захотел — Вы действительно будете скрещивать всё со всеми (не обращая внимания, что основая цель запроса — счета (нам нужно вернуть 10 счетов по определённому признаку), а всё остальное — только сопровождающая информация)?gandjustas
14.08.2017 17:42Не пойму сути вопроса. Если надо отобразить результат джоина из 10 таблиц, то придется сделать джоин из 10 таблиц. Можно написать одним linq запросом, можно несколькими.
sasha1024
14.08.2017 18:47Надо отобразить не результат джоина 10 таблиц.
Надо отобразить несколько счетов по какому-то условию (например, последние 10 какого-то типа).
Но счета нужно отображать с подробностями: по каждому счёту мы отображаем:- первые несколько пунктов этого счёта (много не надо, много некрасиво, допустим, первые 5, а если их больше, то дальше троеточие);
- список контактных лиц со стороны заказчика касательно этого счёта (обычно одно, иногда 2, если больше — троеточие);
- историю правок этого счёта (опять таки не всю — первые 3 правки, а если их больше, то после них троеточие);
- первые M сепулек по этому счёту;
- первые N бубячек по этому счёту.
В SQL способа сделать это красиво одним запросом, насколько я знаю, не подвезли.
Очевиднейшим решением было бы что-то типа:
SELECT
b.*,
(SELECT * FROM bill_items WHERE bill_id=b.id LIMIT 5) as items,
(SELECT * FROM bill_contacts WHERE bill_id=b.id LIMIT 2) as contacts,
(SELECT * FROM bill_amendments WHERE bill_id=b.id LIMIT 3) as amendments,
(SELECT * FROM bill_foos WHERE bill_id=b.id LIMIT m) as foos,
(SELECT * FROM bill_bars WHERE bill_id=b.id LIMIT n) as bars
FROM bills b
WHERE …;
Но даже тип данныхROWподдерживается (и может возвращаться) не всеми RDBMS (и не всеми клиентскими либами может приниматься), не говоря уже о типе данныхROW[](a.k.a.ROWSa.k.a.TABLE), поэтомуitems,contacts,amendments,foos,barsзапихать некуда.
Поэтому, по-моему, правильно (на данном этапе развития SQL) сделать это несколькими запросами (минимум 6-ю: 1-й — счета, 2-й — пункты (сразу для всех нужных счетов, по 5 для каждого), 3-й — контактные лица (сразу для всех нужных счетов, по 2 для каждого), 4-й — правки (сразу для всех нужных счетов, по 3 для каждого), 5-й — сепульки (аналогично), 6-й — бубячки (аналогично)).
А вот что Вы предлагаете сделать в такой ситуации, я так и не понял. Когда дочерняя сущность была одна (пункты, без контактов/правок/сепулек/пупячек), Вы предлагали джоинить? — я потому и привёл данный пример, чтобы показать, что джоинить в данном случае не вариант (причём даже не с точки зрения производительности, а чисто логически). Что Вы предлагаете теперь?
? Джоинить — нормальный вариант, когда связь многие-к-одному, а не один-ко-многим.mayorovp
14.08.2017 19:36EF в такой ситуации использует (LEFT) JOIN + UNION ALL
(Что вполне нормально работает пока оптимизатор запросов на стороне СУБД укладывается в свои ограничения по времени)
sasha1024
14.08.2017 19:49LEFT JOIN кого с кем? — bill'ов с наборами детей каждого типа (в смысле отдельно
bills LEFT JOIN bill_items, отдельноbills LEFT JOIN bill_contacts, отдельноbills LEFT JOIN bill_amendmentsи т.д.)?
А как тогда потом UNION'ить, если даже количество столбцов у разных типов детей может отличаться (не говоря уже об их типах и семантике)? — добить NULL'ам до ширины самого широкого ребёнка?
По-моему, это изврат.
И Вы уверены, что это будет действовать быстрее, чем сначала выбрать инфу по собственно bill'ам (и тем таблицам, с которыми они ассоциируются многие-к-одному), получив при этом набор id'шников — а потом по этому набору id'шников спокойно повыбирать детей (один-ко-многим) разных типов отдельными запросами? Ну, ок, ладно, пусть по-Вашему быстрее, но… даже не знаю… я б так не делал, во-вторых, какая-то низлежащая RDBMS может на излишне сложном запросе глюкануть, а во-первых, это просто извращение сути реляционной модели, по-моему.mayorovp
14.08.2017 19:51Нет, у каждого дочернего элемента свой набор полей, чужие — NULLы.
Про глюки RDBMS на сложных запросах согласен, поэтому от таких запросов при оптимизации по возможности избавляюсь.
sasha1024
14.08.2017 20:24Нет, у каждого дочернего элемента свой набор полей, чужие — NULLы.
А. Уже лучше. Я как-то не подумал.
Я просто когда-то давно писал ORM, там именно так реализовано было: многие-к-одному вставляются в тот же основной запрос, один-ко-многим разворачиваются в отдельные.
Но всё равно мне кажется все случаи красиво одним запросом не реализовываются :). Но да, это получается уже совсем какие-то специфические и редкие кейсы, которые в двух словах не опишешь.Upd.: Вообще, подумал, да, Вы правы, в условиях неглючной низлежащей СУБД чаще всего нету смысла разворачивать в несколько запросов.
gandjustas
14.08.2017 20:46+1По-моему, это изврат.
Это не важно, потому что делается внутри. Ты видишь фактический результат как набор объектов со вложенными коллекциями.
gandjustas
14.08.2017 20:45Поэтому, по-моему, правильно
Это на основании чего правильно?
А вот что Вы предлагаете сделать в такой ситуации, я так и не понял
Предлагаю сделать банально как удобнее. Мне удобнее например один запрос родить. А дальше уже смотреть планы и оптимизировать если надо.
sasha1024
14.08.2017 20:47См. #comment_10360412 — до данного момента я просто банально не мог додуматься, как красиво сделать один запрос. (Извиняюсь за зря потраченное время.)
Jeevuz Автор
12.08.2017 01:37+1Не ну хейт это конечно хорошо, а где конструктив, какие предложения? Callback-hell? Нет, спасибо.
Использовать надо то, что хорошо работает. Но не везде его сунуть, тут абсолютизация ни к чему. Раз RxJava хороша для чего-то, мы её используем. А там где не подходит, обойдемся без неё.
По-прежнему не понимаю посыл этих огромных комментариев от вас....
mayorovp
12.08.2017 11:09Вот не верю что после onDestroy в activity могут вообще прилетать хоть какие-то события. Такое ощущение, что у вас проблемы не с RxJava, а с избыточным использованием статических полей.
oleg_shishkin
11.08.2017 21:40Реальный пример из жизни — крутой проект полностью на Rx. Дали оценить. Тыкаю пальцем и говорю — вот здесь может происходить смена логики — что делаете. Ответ — подменяем последовательность. Но этого же не видно в коде. Да не видно. И кто кроме разраба это знает? Сколько раз писались заново целые огромные куски кода — после того как уходил разработчик или забывал сам что и где. Как сопровождать такую систему. Да rxjava — мощная система — но лучше ее использовать для прямых по логике вычислений в условиях без смены внешнего окружения.
LiaminRoman
11.08.2017 20:21Спасибо за статью.
Подскажите, пожалуйста, мне не понятна ситуация с направлением зависимости от Repository (более внешний круг) к Use case (более внутренний круг). Я предполагал, что Use case делает вызовы к Repository, но если это так, то Use case должен знать интерфейс Repository тем самым зависимость идет в обратную сторону? Я что-то неверно понял?Jeevuz Автор
11.08.2017 20:22+1Прочтите про dependency inversion. И раздел статьи про переходы между слоями.
VolCh
13.08.2017 22:28Интерфейс репозитория объявляется на, как правило, уровне бизнес-логики (слой entities), а реализуется на уровне инфраструтктуры (слой interface adapters). На уровень логики приложения (use cases) передаются конкретные интерфейсы как экземпляры абстрактного интерфейса, интеракторы оперируют только абстрактными методами, объявленными в слое бизнес-логики, хотя у конкретного репозитория могут быть и другие.

Alex_ME
11.08.2017 21:27Entities по праву занимают первое место по непониманию.
Я вот пытаюсь понять, но никак не понимаю.
Возможно, мой вопрос будет оффтопом, потому что я пишу вам из мира веб-разработки, но принципиально ничего не меняется, как мне кажется (Onion Architecture), а entity это вообще из DDD.
В целом концепция понятна, как и её плюсы.
Самое непонятное — как подружить Entity с каким-либо источником данных, например (чаще всего) ряляционной БД. Т.к. и в мобильной разработке есть базы данных, то надеюсь, этот комментарий будет уместен.
Допустим (кривой, очень пример), что у нас есть entity ShoppingCart, в которой печеньки. И у него метод MakeOrder(), который проверяет, что если в корзине две печеньки, то необходимо сделать скидку 20%. На первый взгляд, все просто
... public Order MakeOrder() { Order order = new Order(items); // На самом деле тут может быть много разных скидок и if не лучшее решение if (items.Count == 2) { // Предположим, что класс Order хранит RawPrice, Discount и сам вычисляет цену со скидкой order.Discount = 0.2; } }
Да, но теперь вспоминаем, что
items(и другие необходимые поля) хранятся в БД и прежде чем выполнять эту операцию необходимо всё загрузить. Что же делать?
Обычно, я реализую подобную логику запросами к БД (при помощи ORM) (может быть и другой источник данных).
int itemsCount = itemsRepository.Count(i => i.CardId == myCartId); Order order = new Order(); order.RawPrice =itemsRepository.Where(i => i.CardId == myCardId).Sum(i => i.Product.Price); if(itemsCount == 2) order.Discount == 0.2; // Еще записать список item'ов ordersRepository.Insert(order); // Коммит транзакции
Такой подход более понятен с точки зрения БД и реально происходящих действий. Недавно, в одной статье прочитал следующее:
Агрегат обычно загружается из базы данных целиком.
Т.е. получается вся сущность загружается, возможно, вместе с коллекциями, чтобы потом работать с ней OOP-style? Звучит, как много лишней нагрузки на БД. Действительно, такой подход часто применяется и преимущества перевешивают недостатки? (Я понимаю, что нет универсального решения).
Другим фактором, вызывающем много вопросов и непоняток является выбор, в какой entity размещать ту или иную логику. Т.к. нередко операция затрагивает несколько сущностей, есть несколько вариантов по размещению реализации. В вышеприведенном примере, возможно, можно было бы реализовать в Order, и не факт, как лучше.

ghost404
11.08.2017 22:00+1Всё просто.
Если вашей сущности не хватает данных для проверки бизнес ограничения вы можете:
А) передать ей эти данные в аргументе функции
Б) вынести проверку бизнес ограничения в сервис доменного слоя
У Вернона есть упоминание о сервисах доменного слоя. Рекомендую почитать.
gandjustas
12.08.2017 00:58Тогда проще сразу все всю логику поместить в "сервис доменного слоя" (DomainService), потому что
1) Лучше иметь логику в однотипных классах, чем в разноипных
2) Нет проблемы перемещать потом код из Entity в DomainService если вдруг появятся параметры.
3) Вариант с передачей параметра в метод Entity нежизнеспособен, потому что нужен код, который эти "параметры" достанет из баз и это будет DomainServicefranzose
12.08.2017 02:30Вариант с передачей параметра в метод Entity нежизнеспособен, потому что нужен код, который эти "параметры" достанет из баз и это будет DomainService
Как мне кажется, тут дело не в том, кто что откуда достаёт, а кто решает, что с этим делать. Т.е. сущность получает данные и именно она знает, как с ними работать.
ghost404
12.08.2017 13:14+1Именно. Сущности можно передавать сервис доменного слоя, а бизнес логику всё равно лучше выполнять в сущности.
Можно сделать интерфейс сервиса доменного слоя который должен возвращать данные для сущности которая будет выполнять бизнес ограничение, а реализацию сервиса который будет стучаться в БД или ещё куда можно разместить на инфраструктурном слое.
franzose
12.08.2017 02:27+1Самое непонятное — как подружить Entity с каким-либо источником данных, например (чаще всего) ряляционной БД.
Взять адекватную реализацию ORM.
Alex_ME
12.08.2017 21:58Entity Framework — достаточно адекватная? Я описал, какие затруднения вызывает подход. Сущность (точнее, Aggregation Root) для выполнения бизнес-правил должна быть загружена (и это легко сделать с помощью того же EF), но это overhead — зачем загружать всю сущность?
Код с непосредственными LINQ запросами получается, как мне кажется, более эффективным.
franzose
13.08.2017 02:59Ну, я не вижу проблемы в том, чтобы не грузить всю сущность целиком. Это зависит от задачи.
gandjustas
13.08.2017 19:11Это почти гарантированный способ убить производительность.
https://habrahabr.ru/post/230479/
mayorovp
13.08.2017 10:39А это вообще законно — иметь в памяти неполностью загруженный объект?
PS Если очень хочется грузить сущность по частям — можно разные части вынести в отдельные сущности с отношением 1 к 1.
VolCh
13.08.2017 22:48Действительно, такой подход часто применяется и преимущества перевешивают недостатки?
Очень часто применяется на начальных этапах разработки из-за простоты реализации. Довольно часто остаётся до конца жизни проекта, если именно это место не становится бутылочным горлышком, сильно тормозящим какой-то частый/важный юзкейс. Если становится, то начинаются различного рода оптимизации.
Т.к. нередко операция затрагивает несколько сущностей, есть несколько вариантов по размещению реализации.
Если сущности являются частями одного агрегата, то хорошее место — ближайший общий "подкорень". Если слабо связаны между собой и сложно определить к какой из сущностей относится, то часто лучшее место отдельный доменный сервис. Ваш пример выглядит таким. Вариант — создание ордера на основе корзины ответственность фабричного метода класса ордера или фабрики ордеров. Дабы сильно не связывать корзину и ордер, собственно проверку можно делать используя паттерн спецификация как-то типа (псевдокод)
class Order { public static makeFromCart(ShoppingCart cart) { var order = new self(); var spec = new ItemsCountCartSpecification(2); if (spec.satisfiedBy(cart)) { order.discount = 0.2; } return order; } }
ghost404
11.08.2017 21:50Я видел уже эту схему, но она мне показалась странной. Я ее не понял и прошел мимо.
Теперь я понял эту архитектуру.
Спасибо вам за это.
Правда мне всё равно она кажется немного странной.
Мне больше по душе классическая архитектуру DDD приложений + CQRS.ghost404
12.08.2017 14:50+1На мой взгляд Clean Architecture не очень подходит для больших и долгоиграющих проектов со сложной бизнес логики (читай DDD).
Классическая архитектура DDD приложений имеет слои:
- Presentation layer
- Application layer
- Domain layer
- Infrastructure layer
- Persistence layer
И вот вся это катавасия из Clean Architecture:
- Controller
- Presenter
- Reques modal
- Rrsponse model
- Interactor
Очень похожа на CQRS и находится на одном уровне — Application. Мы просто разделяем потоки и то что могло выполнятся в контроллере выполняется в Interactor или Command Heandlers в CQRS подходе.
А все самое интересное из DDD оказалось спрятано за неоднозначным понятием Entities.
Application layer оказался эквивалентен Infrastructure layer, а Presentation layer эквивалентен Persistence layer.
В общем, очень странная архитектура на мой взгляд. Хотя многие могут не согласиться со мной.
Cromathaar
12.08.2017 00:27Вопрос в том, должен ли зеленый слой (Репозитории) знать о желтом (Энтити). Мне кажется, Дядька Боб переборщил с использованием термина «Entity» на своей flow-диаграмме, из-за чего у вас образовалась стрелка от Repositories к Entity на последнем рисунке в разделе «Заблуждение: Слои и линейность». На мой взгляд, как раз-таки интерактор (розовый) должен лезть через гейтвэй (зеленый) в БД, получать от него DTO и с помощью них инициализировать энтити (розовый создает желтый), выполняя в них бизнес-логику в нужном порядке и реализуя таким образом юз кейс. Тогда мы получим ровно такой же флоу, как на кольцевой диаграмме, где каждый внешний слой именно что отделяет внешнего соседа от внутреннего. В более простых приложениях, в которых вообще нет никакой предметной области, слой Энтити просто будет отсутствовать как факт.
sasha1024
12.08.2017 01:02+1А как может быть приложение без предметной области?
Cromathaar
12.08.2017 01:41Любой CRUD как простейший пример. Вообще, что считать предметной областью — вопрос интересный. По сути это бизнес-правила из реального мира, которые, что логично, не зависят от конкретного приложения. Расчет налогов, например. Какое приложение не пиши, но бизнес-компоненты, реализующие подсчет условного НДФЛ, будут применять одну и ту же логику при калькуляции (поэтому Мартин и говорит, что Entities — это объекты, которые можно таскать за собой из приложения в приложение, если, конечно, их предметные области пересекаются). Если вся бизнес-логика — это специфичные для приложения воркфлоу и сущности, то вряд ли можно говорить о наличии предметной области и соответствующего (желтого) слоя.
sasha1024
12.08.2017 02:08что считать предметной областью — вопрос интересный
Вообще, да, согласен, что разделение между entities и use-cases (между бизнес-логикой и логикой приложения) достаточно условное.
Таким образом согласен и с Вашим предыдущим комментарием.
franzose
12.08.2017 02:32Репозиторий — это, по сути, коллекция сущностей. Поэтому совершенно нормально, что репозиторий работает именно с сущностями, а не с массивами или какими-то другими сырыми данными.
Cromathaar
12.08.2017 03:20Репозиторий, как впрочем и гейтвэй — это фасад/прокси к источнику данных. Его задача извлечь данные и отдать их запрашивающему. Создавать объекты предметной области — не его задача. Это не считая того, что бизнес-объект может инициироваться аккумулированными данными из запросов к разным репозиториям/гейтвэям.
franzose
12.08.2017 03:43Думаю, Фаулер бы с вами не согласился. Если совсем по DDD-шному, то репозиторий должен быть один на весь агрегат. А TableGateway и RowGateway — это более низкоуровневые вещи.
Cromathaar
12.08.2017 04:10Да вряд ли бы не согласился. «Conceptually, a Repository encapsulates the set of objects persisted in a data store and the operations performed over them, providing a more object-oriented view of the persistence layer». В заблуждение тут может ввести термин «domain object». С доменами вообще нынче дикая путаница. Data Mapper маппит результаты запроса к источнику данных (например, БД) в объекты-сущности. Сущности эти относятся к зеленому слою (слою доступа к данным, DAL). Репозиторий хранит коллекцию этих сущностей и предоставляет упрощенные методы работы с ней (т.е. он фасад). На выход репозиторий выдает те же самые объекты «зеленых» сущностей. Интерактор (розовый слой) берет эти сущности и с помощью содержащихся в них данных инициирует объекты предметной области (желтый слой), которые, в отличии от сущностей, содержат методы обработки этих данных (т.е. правила предметной области).
Если предметной области нет, то розовый слой вполне себе может взаимодействовать сразу с «зелеными» сущностями, просто прогоняя полученные из них данные через какой-то рабочий процесс и выплевывая их наверх презентатору. Собственно, такой подход и показан на диаграмме в книге Фаулера.Cromathaar
12.08.2017 04:23Пардон, сам уже с цветами запутался и вас запутал.
>>> Интерактор (розовый слой) берет эти сущности и с помощью содержащихся в них данных инициирует объекты предметной области (желтый слой), которые, в отличии от сущностей, содержат методы обработки этих данных (т.е. правила предметной области).
Конечно же зеленый контроллер берет зеленые же сущности и инициирует розовый интерактор, который уже выполняет какие-то действия (рабочий процесс) с этими данными. В случае сложной предметной области и наличия желтого слоя, интерактор создает желтые объекты бизнес-логики и отдает данные им на обработку. Таким образом зеленый слой вообще ничего не знает о наличии желтого, соответственно никак не может создавать его объекты напрямую.
В примере из книги Фаулера в итоге ничего не нарушается, если принять во внимание, что «client» — это контроллер, а получает он от репозитория те самые зеленые сущности.ghost404
12.08.2017 13:44+1Вообще-то, по Эванса, сущность это слой бизнес лигики (domain), а контроллеры это слой приложения (application).
Репозитории это тоже слой бизнес логики, а реализация репозиторий под конкретное хранилище это вообще слой инфраструктуры которого нет в Clean Architecture
ilinandrii
12.08.2017 01:39+1Спасибо большое за статью. Все очень доходчиво и даны ответы на все вопросы, которые у меня возникали при прочтении.

qwert2603
12.08.2017 06:37Доброе утро! У меня возникла пара вопросов:
- Может ли интерактор иметь состояние? Например, кол-во уже загруженных элементов списка для пагинации. Но, если он может иметь состояние, то один интерактор может использоваться только с одним презентером...
- Вся ли бизнес-логика должна содержаться в интеракторе? К примеру, на экране авторизации кнопка "Войти" должна быть
enabled, только если вloginEditTextвведено больше 4 символов. Нужен ли в этом случае методboolean canLogin(String login)в интеракторе?
mayorovp
12.08.2017 11:28Один интерактор с одним презентером — это как раз не проблема. Но надо понимать, что одно и то же ядро может использоваться самыми разными приложениями — и не везде есть удобный механизм для хранения объектов. Например, в веб-приложении. Да и в том же Андроиде процессы могут быть в любой момент убиты системой, что также не упрощает хранение состояния. Отсюда сразу же полезут механизмы сохранения и загрузки состояния, пользовательские сессии, дальше — проблемы нескольких открытых окон у одного пользователя...
Поэтому проще просто не делать так.
Sie
14.08.2017 09:53+1Спасибо за статью очень интересно было почитать. Все разложено по полочкам.
Так же спасибо за ссылки на оригинальные статьи.
franzose
Очень крутая статья, большое спасибо! Впервые за долгое время встречаю статью, где буквально на пальцах объясняется, что да как. Да еще и на русском) Да еще и вовремя.