
Проведение конкурсов для IT-специалистов сейчас в моде: Kaggle с его задачами по Data Science, сплоченная тусовка олимпиадного программирования, набирающие популярность площадки для конкурсов по искусственному интеллекту, всевозможные хакатоны для мобильных разработчиков, олимпиады для админов, capture the flag для безопасников. Казалось бы, специалисту любой сферы несложно найти себе подходящую движуху, поучаствовать, прокачаться и что-нибудь выиграть.
Обделенными в этом плане остались лишь web-разработчики. Мы в Mail.Ru Group решили исправить это досадное недоразумение и теперь с радостью представляем вам HighLoadCup — конкурсную площадку на стыке backend-разработки и администрирования web-сервисов.
Если считаете себя хорошим web-разработчиком, умеете в deploy и highload — добро пожаловать!
Сроки, призы
Сразу о главном — первый, пилотный чемпионат стартовал вчера, 10-го августа, и продлится вплоть до конца лета — 31-го августа мы подведем итоги и вручим призы. Призовой фонд включает Apple iPad Air 2 Cellular 16 GB за первое место, WD MyCloud 6 TB за второе и третье места, WD MyPassport Ultra 2 TB за места с 4 по 6 включительно. По традиции, ТОП-20 участников получат футболки с символикой чемпионата.
Механика чемпионата
Участникам дается задание на написание небольшого web-сервиса, работающего с данными определенной структуры и реализующего API к этим данным. Контейнер с реализованным сервисом загружается к нам на сервера, там мы его стартуем и начинаем обстреливать HTTP-запросами. По результатам таких обстрелов мы подсчитываем количество правильных и неправильных ответов, RPS и скорость ответа, и по заранее определенной метрике формируется рейтинговая таблица. Автор наиболее быстрого и отказоустойчивого сервиса и оказывается победителем.
Как это устроено
Решения отправляют с помощью локально установленного docker-клиента в специальное хранилище. Затем отправленный нам сервис проверяется автоматически системой CodeHub-CodeRunner, разработанной сотрудниками лаборатории Технопарка Mail.Ru Group.
При проектировании решения участник не ограничен ничем, можно использовать абсолютно любые языки и стеки технологий, от классических схем со скриптовым языком и СУБД до самописных велосипедов на C, держащих все нужные данные просто в памяти.
Итак, фактически нужно сделать следующее:
- создать автономное отзывчивое серверное приложение;
- собрать его в docker-контейнер и залить в хранилище;
- обстрелять приложение на выданных боевых данных;
- … победить.
Все решения запускаются как docker-контейнеры на одинаковых серверах с Intel Xeon x86_64 2 GHz 4 ядра, 4 GB RAM, 10 GB HDD.
Система обстрела
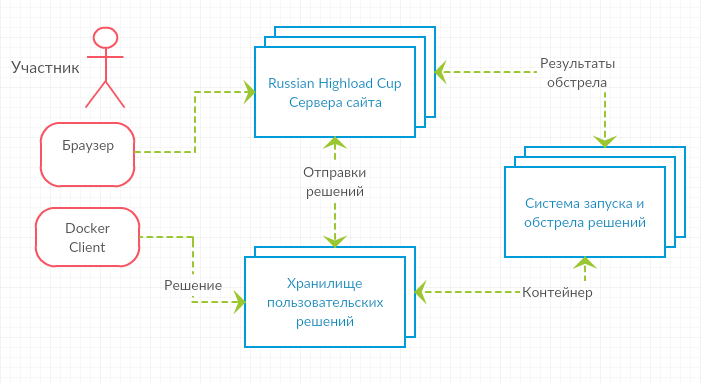
Система проверки изначально создавалась для другого чемпионата (который нам еще предстоит запустить ;) и была доработана для проведения Highload-соревнований. Внутри запускается yandex-танк с движком phantom, который ведет обстрел в несколько потоков с линейно растущим профилем нагрузки. Предварительно, до начала обстрела у пользовательского решения есть время порядка нескольких минут, чтобы обработать данные из подложенного нами в контейнер JSON-файла. Корректная работа с этими данными — необходимое условие победы. Существует два типа проверки — экспресс-проверка и рейтинговая проверка. Об этом ниже.
Как проверяются решения
Типы проверки решения: экспресс-обстрел и рейтинговая проверка.
Экспресс-обстрел доступен неограниченное число раз в сутки, составляет по объему примерно 1/10 от рейтинговой проверки решения. Экспресс-проверка не отличается от рейтинговой по структуре, но использует другой набор данных и является способом узнать, готово ли решение для рейтинговой проверки. Предполагается, что экспресс-обстрел занимает не более 3 минут.
Рейтинговая проверка проводится так же, как и экспресс-проверка, просто на большем количестве данных и запросов. Примерно вот так:
- перед обстрелом запланировано 180 секунд ожидания для того, чтобы решение участника могло проанализировать переданные тестовые данные и подготовиться к обстрелу;
- 180 секунд длится первая фаза с линейным профилем от 1 до 200 RPS — будет выпущено: integral (199/180x + 1) dx from 0 to 180 = 18090 GET-запросов;
- 120 секунд длится вторая фаза с постоянным профилем в 100 RPS — будет выпущено: 100 * 120 = 12 000 POST-запросов, меняющих данные;
- 120 секунд длится третья фаза с линейным профилем от 200 до 2 000 RPS — будет выпущено: integral (1800/120x + 200) dx from 0 to 120 = 132 000 GET-запросов;
- валидация ответов ~20 секунд — анализ результатов на сайте ~30 секунд.
Таким образом, сначала проверяется умение участника разложить данные в нужные ему структуры. В первой фазе обстрела проверяется работа сервиса с начальной небольшой нагрузкой. Во второй — корректность обновления сервисом данных и возможная инвалидация кешей (если они понадобятся решению). В третьей же фазе обстрела мы постепенно наращиваем нагрузку, чтобы пощупать решение на прочность.
По результатам рейтинговой проверки участник занимает определенные места в лидерборде текущего чемпионата. Всего обстрел длится порядка 15 минут (при отсутствии очереди). Всего запросов в обстреле: 162 090. Возможно, в ходе чемпионата это число будет увеличиваться.
Решение участника является контейнером docker, который получен с помощью команды docker build. Максимальный размер контейнера на диске не должен превышать 5 Гб. Система проверки выполнит сначала docker pull и затем docker run. В случае успеха, начнется обстрел решения. Участник может использовать любые серверные технологии, языки, фреймворки по своему усмотрению (C++, Java + Tomcat, Python + Django, Ruby + RoR, JavaScript + NodeJs, Haskell или что-то еще). Также и для хранения данных: MySQL, Redis, MongoDB, Memcached — всё, что получится запихнуть в docker.
В результате обстрела получаются логи и метрики, которые затем будут показываться участникам в виде графиков на странице решения. Отдельно отслеживаются следующие метрики:
- основные метрики;
- корректность ответа;
- время ответа на запрос;
- количество ответов в секунду.

Рейтинг решения считается следующим образом: мы берем время всех верных ответов, которые успел дать API во время обстрела. Прибавляем к этому штрафное время для каждого неправильного ответа или запроса, ответ на который мы не смогли получить (штрафное время всегда равно общему таймауту запроса). Участник, суммарное время которого окажется меньше прочих, оказывается выше в лидерборде и имеет шанс стать победителем чемпионата.
Задача
В задаче первого чемпионата участникам нужно написать быстрый сервер, который будет предоставлять Web-API для сервиса путешественников. В начальных данных для сервера есть три вида сущностей: User (Путешественник), Location (Достопримечательность), Visit (Посещения). У каждой свой набор полей. Необходимо реализовать следующие запросы:
GET /<entity>/<id>для получения данных о сущности;GET /users/<id>/visitsдля получения списка посещений;GET /locations/<id>/avgдля получения агрегированных данных;POST /<entity>/<id>на обновление сущности;POST /<entity>/newна создание сущности.
Максимальное штрафное время на запрос равно таймауту и составляет 2 секунды (2кк микросекунд). Сразу перед запуском мы подкладываем в контейнер с сервисом данные в формате JSON (они будут доступны в /tmp/data). Решению дается некоторое время для того, чтобы вычитать эти данные и разнести их по внутренним структурам (допустим, разложить в БД).
HTTP-запросы приходят в поднятый контейнер на 80 порт, с заголовком Host: travels.com по протоколу HTTP/1.1, один запрос — одно соединение. Сетевые потери полностью отсутствуют.
Более подробное описание задачи, мини-tutorial для быстрого старта и прочие вспомогательные материалы вы найдете на сайте чемпионата. Кроме того, заходите к нам в Telegram, там всегда рады ответить на вопросы.
Регистрируйтесь, выигрывайте! Удачи!
Комментарии (67)

vird
11.08.2017 14:08Я нигде не нашёл информации про допустимый размер JSON. Он умещается в память?
KirEv
11.08.2017 14:25+1вот же пишут:
будет доступен файл data.zip с архивироваными «боевыми» данными (примерно 200 килобайт для предварительного и 20 мегабайт для полного обстрела)
скачал тестовый архив, 196кб, в нем 3 json«a в сумме дают чуть больше 1мб, если эта информация поможет :)
KirEv
11.08.2017 14:31+2Недопонимание
В Location (Достопримечательность) записаны следующие данные:
id — уникальный внешний id достопримечательности. Устанавливается тестирующей системой. 32-разрядное целое число.
place — описание достопримечательности. Текстовое поле неограниченной длины.
country — название страны расположения. unicode-строка длиной до 50 символов.
city — название города расположения. unicode-строка длиной до 50 символов.
distance — расстояние от города по прямой в километрах. 32-разрядное целое число.
из location_1.json
«distance»: 6, «city»: «Москва», «place»: «Набережная», «id»: 1, «country»: «Аргентина»
distance — расстояние от города по прямой в километрах, расстояние к чему?
если
country — название страны расположения. unicode-строка длиной до 50 символов.
и
city — название города расположения. unicode-строка длиной до 50 символов.
то почему «city»: «Москва» и «country»: «Аргентина» а не «Россия»?
с толку сбивает, или я что-то не понимаю?
q1t
11.08.2017 15:39+3Да по моему просто рандомно сгенерированные данные, за действительность брать не нужно. А distance — от города до достопримечательности.
sat2707 Автор
11.08.2017 15:42+1Да, именно так. У нас там есть Москва внутри Аргентины, Кремль в 100 км от Москвы, 130-летние люди, все это посещающие… Это все прелести генеренных тестовых данных, отнеситесь к ним с юмором :)

Alexeyco
11.08.2017 17:10+2С каким юмором? Человеку 130 лет, он вынужден ехать в Аргентину, чтобы попасть в Москву. Обычное дело.
KirEv
11.08.2017 15:55Как воспринимать от «города до достопримечательности»?
Если есть конечный пункт (достопримечательность), должен быть начальный (город). И согласитесь, странно в голове поместить, когда начальный пункт заканчивается к конечном (от города до достопримечательности, но достопримечательность находиться в городе).
Город как некая единица A к которой может относится достопримечательность B?
Город как некая единица Z с множеством достопримечательностей [A`,B`,..,Z`]? тогда от города, скорее всего, понимать как от некоторой начальной точки с чего город начинается, ну не знаю, нулевой километр, например.
Вообще, читая описание задания и методов, мое недопонимание самоисчерпывающее из контекста задачи, тупо лупим от города до достопр., и все, алгоритм работает, но както при привычке и работе охота понимать контекст, а не лепить догадки))
Не хочу показаться придирчивым =)
Задача интересная, не то что «посчитать комбинации проколов трамвайного талона NxK компостером IxJ» и всякое такое, было както у нас )sat2707 Автор
11.08.2017 17:24Наверное логичнее это воспринимать как нулевой километр города, да :)
Город -> Достопримечательность -> Визит < — Юзер
Что-то такое

ReklatsMasters
11.08.2017 15:30+3Вот и посмотрим насколько решения на nodejs конкурентноспособны. Хотя, если nodejs решение войдёт в топ, хейтеры js найдут к чему придраться.
Laney1
11.08.2017 16:13парсить запросы сейчас все умеют достаточно быстро. Думаю, основной фокус будет в других вещах: где и как хранить данные, как это все синхронизировать, нужно ли кэширование, и если нужно — то опять же какое. Ни разу не удивлюсь, если в топе окажется грамотно настроенная система на node


Laney1
11.08.2017 16:04Все решения запускаются как docker-контейнеры на одинаковых серверах с Intel Xeon x86_64 2 GHz 4 ядра, 4 GB RAM, 10 GB HDD
лучше указать точную марку процессоров, чтобы можно было судить о поддержке технологий — AVX, AVX2 и т.п. Также, еще больше не помешает указать версию ядра


SeriousDron
11.08.2017 16:44+13Вобщем-то задача не совсем про highload получилась. В реальном highload нужен большой RPS, и возможность легко масштабироваться, а latency не так критична. А 2000 RPS выдаст вообще что угодно не сильно скриптовое.
Опять же, важно чтобы когда у вас вместо 5000 RPS стало 50000 RPS вы просто добавили серверов. А когда надо добавить фичу — просто ее добавили. А здесь победит C/C++-шный велосипед, с libevent, hashmap и btree в памяти и конечным автоматом вместо полноценного парсера JSON. Как это относится к highload — сложно сказать.
Я даже думал написать такой на Scala (на плюсах 10 лет не писал), но объективно понимаю что код который хочется писать (production-ready) даже близко к топу не окажется.
Может стоило скажем запускать 2-5-10 слабых контейнеров чтобы частью задачи было распределение нагрузки и синхронизация хранилища? Тут уже встал бы вопрос делать одно выделенное хранилище или распределять запросы, скажем по id. И как тогда считать запросы на аггрегацию. Желательно чтобы еще посреди теста рандомные контейнеры дохли и новые поднимались.
И объем данных увеличить чтобы не влезал в оперативную память, а в идеале и на винт одной единственной машины. В принципе тоже понятно как решать такую задачу, но уже скорее использовали бы какие-то СУБД чтобы не изобретать кластеризацию на коленке.sat2707 Автор
11.08.2017 17:27+1Дааа! Всё это у нас в планах :) Просто в первом, тестовом чемпионате мы не стали так упарываться. Чтобы, во-первых, порог входа, а во-вторых, сложность отладки для нас самих. Сами знаете, как это бывает :)
Но упороться очень хочется! Если первый чемпионат пройдет хорошо, обязательно обмеряем и durability, и распределенные игрища, и контейнеры будет рандомно шатдаунить, чтобы посмотреть на балансировку…
Короче, у нас много веселых идей, но все они не для первого запуска, поэтому и делаем пока что вот такой странный хайлоад, который больше просто про нормальный backend :)
knstqq
11.08.2017 16:46Я что-то не понял из интерфейса и описания: сколько будет раундов?
Первый раунд — это первый чемпионат? Или в этом чемпионате будет много раундов?
sat2707 Автор
11.08.2017 20:01нет, чемпионат состоит ровно из одного раунда. возможно мы добавим еще немного факультативных раундов (для желающих посложнее например). но перечисленные 6 призов — по результатам одного раунда
svr_91
11.08.2017 16:53А запросы идут один за другим или несколько параллельно?
sat2707 Автор
11.08.2017 17:29Несколько. Процитирую с сайта:
Перед обстрелом запланировано 180 секунд ожидания для того чтобы решение участника могло проанализировать переданные тестовые данные и подготовиться к обстрелу.
180 секунд длится первая фаза с линейным профилем от 1 до 200 RPS.
120 секунд длится вторая фаза с постоянным профилем в 100 RPS
120 секунд длится третья фаза с линейным профилем от 200 до 2000 RPS.svr_91
11.08.2017 18:27А как тогда обрабатывать запросы на модификацию одновременно с запросами на чтение?
SeriousDron
11.08.2017 18:46А в чем проблема-то? Так же как вы и вы жизни обрабатываете. Либо БД сама разрулит, либо, если все в памяти — использовать конкурентные структуры данных.
Но на самом деле еще проще, на самом деле одновременных запросов на запись и чтение вроде не намечается. Вся запись в фазе 2
sat2707 Автор
11.08.2017 20:02+1В первом чемпионате мы решили эту проблему за вас — первая фаза это readonly-запросы, вторая — post с редактированием/добавлением данные, третья — снова get-запросы


voidnugget
11.08.2017 18:09-2собрать его в docker-контейнер и залить в хранилище
Эм… докер уже сам по себе большое бутылочное горлышко.
Ок
- Overlay / macvlan / OVS драйвер докера уже имеет довольно высокие накладные расходы и не подходит для чего-то серьёзного.
- Есть очень много настроек уровня ядра: шедуллер iommu vfio большие страницы афинность
- Если речь идёт о 10/40Gbit трафика и 1М+ RPS с poll-mode драйверами на DPDK ?
При проектировании решения участник не ограничен ничем
Вы уже поставили довольно много палок в колёса участникам используя посредственное окружение и очень субъективную оценку.
\o/
Прикольно когда организаторы чемпионата по highload'у не знают какой нынче highload бывает.
У меня малость пригорает.
square
11.08.2017 19:07+1Не стоит так уж строго судить, это просто первая попытка у ребят, на мой взгляд инициатива довольно интересная. Да и условия равные для всех, вполне можно поучаствовать даже, например, из чистого интереса, посмотреть на что способен твой привычный подход
voidnugget
11.08.2017 19:27Это не "мой привычный подход", просто есть user-space решения которые позволяют обрабатывать больше одного миллиона запросов в секунду. Существующие kernel-space решения имеют довольно много ограничений: лишних копирований буферов с kernel-space в user-space, смен контекстов выполнения, избыточного менеджмента памяти etc
Меня кумарит немного факт что highload рассматривается только в рамках общепринятых прикладных решений которые не работают с железом напрямую — там уже задача ставится как "давайте обработаем запрос клиента за 800 процессорных тактов с когерентностью кэша и использованием cache streaming подходов".
sat2707 Автор
11.08.2017 20:04Видим, что пригорает :)
Всем не угодишь, к сожалению. Мы рассматривали вариант дать прям живых тачек, отказались от него по понятным причинамvoidnugget
11.08.2017 20:25Спасибо, предположил "понятные причины".
Понял что можно особо не распыляться — всё равно никто не поймёт "масштабов бедствия".

babylon
11.08.2017 20:41Почему не рассмотрели моё задание? Оно не такое тривиальное как может показаться:)


fahreeve
11.08.2017 22:06+9У нас был один сервер, 5 дисков, 20 пакетиков с растворимым кофе и 48 часов до начала чемпионата. Не то чтобы это много, но раз уж решил быть организатором, то надо провести его до конца. Единственное, что беспокоило — это докер. В мире нет никого более беспомощного, безответственного и безнравственного, чем человек запускающий все в одном контейнере. И я знал, что довольно скоро мы в это окунёмся…

e_Hector
11.08.2017 22:16Не работает кнопка войти на https://highloadcup.ru, ничего не происходит после нажатия (Chrome 59.0.3071.115)

nekt
11.08.2017 23:04Прочитал эту статью днем, пока ехал с работы, подумал. И решил спросить — а можно ли от одного участника несколько образов выставить? Интересно было бы посмотреть распределение в итоговых результатах различных подходов.
sat2707 Автор
12.08.2017 00:40Можно, по дефолту мы даем каждому участнику два тега в docker registry, можно параллельно тюнить два стека технологий. В принципе, ничто не мешает и в один контейнер два стека запихать, и включать один либо второй :)
antonksa
12.08.2017 23:09Тарантул с нжинксом интересно выложит кто-то?
А вообще бредовый конечно квест. 2000 rps выдержит что угодно, а мерять latency… Осипов сказал, например, что в тарантуле пожертвовали latency ради throughput.voidnugget
12.08.2017 23:52Есть lock-free и есть wait-free подходы, а в системах реального времени используется временное разделение…
По CAP теореме можем пожертвовать либо консистентностью либо доступностью, а в случае с высоконагрузом это значит задержка vs пропускная способность.
На DPDK, к примеру, решения работают напрямую с железом — там нет распространённых накладных расходов на коммуникацию и трансляцию вызовов, высоконагрузы уже начинаются с 1М RPS.
В приложениях на golang'e с использованием fasthttp тот же nginx или haproxy уже является бутылочным горлышком при RPS 80K+. Сторонние кэши типа redis/memcached тоже не вписываются из-за больших накладных расходов на коммуникацию. C fasthttp и тюнингом настроек ядра можно выжать 300К rps… опять же, тут никто не даст поправить sysctl или ядро пересобрать с rt патчами.
Было бы лучше смотреть на flame-graph'ы под нагрузкой и метрики сложности CFG, чем проводить эстимации в RPS'e — это была бы более точная эстимация при совместном использовании распространённых производительных решений.
ewgRa
14.08.2017 01:591. А можно как-нибудь получить более детальное описание, на какие запросы 400 надо отвечать?
В результатах только пишется что Code не совпадает, посмотреть тело запроса нельзя.
«Фаза обстрела # 2 (POST)», Locations — «Ответов с неверным http-кодом 3», и непонятно как это исправлять.
Уже все перебрал, и id <= 0, и добавление location уже существующего, и какие-то органичения, следующие из описания сущностей, кстати, там непонятна формулировка: «unicode-строка длиной до 50 символов.», часто сталкивался что люди по-разному такую формулировку понимают, "<" или "<=".
Плюс к этому непонятно, какие поля надо проверять на обязательность заполнения, какие нет, какие поля на что проверять (существование связанных сущностей и т.п.), а каким можно доверять.
В общем хотелось бы более четкого описания на что отвечать 400.
2. Еще по user.birth_day, в описании «Ограничено снизу 01.01.1930 и сверху 01.01.1999-ым.». В тестовом data.zip, первый же user имеет "-1720915200", это 1915 год. Что делать с таким юзером?
3. В фазе 1 остался один неверный ответ из 125 — 1. /locations/353/avg?toAge=34&fromAge=24. Тоже непонятно как исправлять с черным ящиком. Сильно сомнительно, что где-то ошибка в алгоритме, или в округлениях, которая вылазит только в одном случае.ewgRa
14.08.2017 11:57по 1. увидел что можно лог сервера смотреть, попробую print запроса делать, надеюсь это не будет считаться нарушением правил?

robert_ayrapetyan
15.08.2017 08:31Оч. прошу пушнуть https://github.com/sat2707/hlcupdocs/issues/26, три дня убил на чемпионат.
EjIlay
sat2707 Автор
Честно говоря, с докером и так много повоевали, на compose просто сил не хватило. А с compose мы получили бы какое-то убер-преимущество?
EjIlay
Участники бы получили: сейчас нужно все собрать в одном докере и решить проблемы зависимостей, если вдруг случатся, ну и потратить на это врем гарантированно. Либо засунуть докер в докер, чтобы не воевать с зависимостями.
Еще вариант — написать all-in-one решение, те отнестить к вашему капу как к олимпиадной задаче, а не похожей на реальнй хайлоад
sat2707 Автор
Принято. Если этот пилотный чемпионат взлетит — до следующего проведения подумаем о пороге входа с точки зрения докера )