
Glenn Jones
Многие розничные компании хостят сайт прямо в своей серверной. Подход удобен тем, что данные находятся дома, и, если речь о розничной сети или другом крупном бизнесе, — линки, питание и потоковый антивирус на месте. При переезде на площадку в большой дата-центр вместе со всей инфраструктурой переносится и сайт. А я — тот человек, который отвечает, чтобы всё это гладко работало. И сегодня хочу поговорить с вами о проблемах роста сайта и том, как их видит сервис-провайдер. Сразу же оговорюсь, что речь пойдет в основном о виртуальной инфраструктуре.
Веб-проект и проблемы роста
Сайт. Начало. Как правило, веб-проект, если он небольшой, имеет под собой один сервер, который отвечает за всё сразу. Иногда на нем размещается несколько сайтов.
Один сервер за всех.
На этом сервере размещаются базы данных и все приложения. Нагрузка растёт. Вот уже сервер начинает захлёбываться. Это может быть следствием конкуренции за ресурсы между базой данных и приложением. Либо сайт разросся, и одного сервера стало мало. Если используется виртуальная инфраструктура, просто разносим базы данных и приложения по разным виртуальным машинам, не вдаваясь в тонкости распределения ресурсов на уровне операционной системы.
Совсем не избежать разделения, когда наращивать процессор уже некуда, или когда база становится настолько широкой, что упирается в оперативку. Тогда клиент либо привозит своё железо (редко), либо берёт в аренду ресурсы облака (чаще).
Ещё одна возможная причина — необходимость физически разделить админов баз данных от разработчиков. Здесь пока не говорю о каком-то трехзвенном ландшафте, — это самый старт проекта, всего один или два сервера. Но и на этом этапе можно ограничить доступ к серверу баз данных для тех, кому нужны только сервера приложений.

Получается вот так, две виртуальные машины.
Растем дальше. Нагрузка продолжает расти, и мы сталкиваемся с необходимостью масштабироваться на уровне серверов приложений. Это наиболее простая в плане наращивания ресурсов часть системы — просто добавляем новых машин. Так у нас появляется второй сервер приложений. База данных занимает, как правило, мало места, поэтому пока не дублируется, а при необходимости масштабируется вертикально путём добавления оперативной памяти и ЦПУ.
На этом же этапе добавляем перед серверами приложений фронтэнд для балансировки. Сервер приложений — самое ненадёжное место в инфраструктуре, т.к. на нем внедряется новый код, который независимо от тщательности тестирования всегда самый «молодой» на проекте. Поэтому второй сервер приложения — это еще и резерв: можно уводить один из них в офлайн для накатки релизов или нагрузочных тестирований. Появляется какая-никакая, но уже отказоустойчивость.
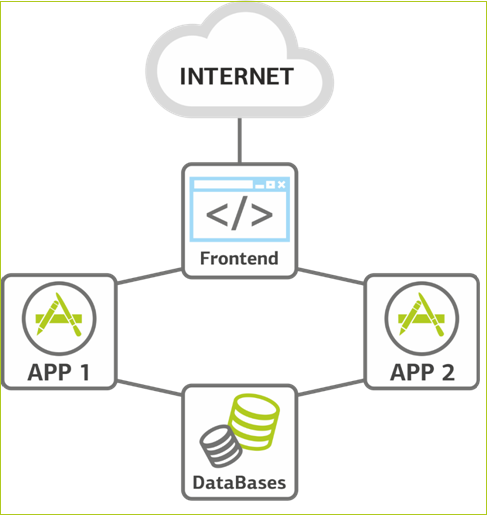
Фронтэнд балансирует нагрузку.
Резервирование. Следующий этап, когда мы разносим все роли и резервируем все узлы. Прежде чем переходить к архитектуре типа «давайте резервировать всё», мы должны понимать, зачем мы это делаем, потому что так мы усложняем всю инфраструктуру решения, а значит добавляем дополнительные точки отказа и риски. Сначала оцениваем стоимость простоя. Во-первых, прямые убытки: заказы, которые мы не смогли провести, потому что у нас сайт не работал. Во-вторых, пользователи, которых мы потеряли из-за того, что сделав один заказ у конкурентов, они перешли к нему.
Решение может быть разнесено по географии в два разных дата-центра. Геокластер дороже, но есть такая штука, как численная оценка рисков и цены простоя каждого из узлов. Если цена даунтайма перевешивает цену решения, надо резервировать. Все интернет-магазины и прочие продавцы отлично знают цену даунтайма. Кроме того, часто e-commerce и кассы в магазине, условно, завязаны на общую ИТ-инфраструктуру, поэтому встать может всё и сразу. А вот, к примеру, банки знают не все, но интуитивно понимают, что так лучше не встревать. Вопрос в том, что кроме прямой цены есть ещё репутационные потери, которые важны банку. Я знаю несколько компаний, у которых построены модели репутационных убытков: так делать правильно :-).
Разносим функции фронтэнда. Переключение между двумя фронтэндами настраивается с помощью виртуального IP-адреса. Сделать это можно двумя способами. Первый вариант — «active-standby», когда один фронтэнд активный, а другой — пассивный. Виртуальный IP работает на одном из фронтэндов и в случае каких-то сбоев переезжает на другой. Второй вариант — «active-active». Это два виртуальных IP, которые находятся на двух серверах. Запросы параллелятся на оба сервера, и если недоступен один из них, оба виртуальных IP переезжают на второй сервер. Но в стандартном режиме мы работаем на двух IP, тем самым разносим нагрузку.
По мере того, как растет количество серверов приложений, встает несколько основных вопросов. Вопрос первый — это контроль и хранение сессий пользователя. Нужно сделать так, чтобы если по каким-то причинам сессия была перекинута на другой сервер приложения, пользователю не приходилось бы логиниться заново и возвращаться на несколько шагов назад. Первый способ решения — использование отдельного модуля для хранения сессий. Для этого хорошо подходит NoSQL база данных, где, например, хранятся данные пользовательских сессий. К ней обращаются все сервера приложений за актуальными данными. Второй способ, тоже рабочий, но не такой функциональный, — отслеживание пользовательских сессий на уровне балансировщика. В том случае сессия всегда отправляется тот сервер приложений, с которым пользователь уже начал работу. Второй вариант иногда более простой и дешевый, но это скорее костыль.
Отдельного внимания заслуживает работа с репозиториями и изменениями. И здесь снова есть два основных подхода. Первый — более рискованный, костыльный. У нас есть какой-то основной сервер, на который мы ставим все обновления, как оттестированные, так и нет. Дальше с помощью синхронизации, например, rsync'ом, переносим его на все другие сервера. Понятно, в чем риск такого подхода: любая ошибка разработчика — мы положили систему. Второй подход — хранение репозиториев. Как правило, мы работаем именно так. Для хранения репозиториев есть, например, Git и Mercurial.

Резервирование всех элементов.
Пиковые нагрузки. В этом месте при росте нагрузки на сайт, как правило, приходит понимание, что с железом (если оно ещё вдруг осталось) пора завязывать и переходить в облако на виртуальные машины. Это очень важно из-за сезонных пиков той же розницы — они могут требовать в 2-4,6 раза большей инфраструктуры, которая весь остальной год будет просто простаивать. Ну и заказчику удобно как — расти вверх по памяти и ядрам.
Надо сказать, что сезонные пики у всех разные: например, спортинвентарь и бытовую разрывают за неделю до нового года, а 29 декабря у них уже спад. С другой стороны, у доставки еды только-только начинается пик 30 декабря утром, и ещё каждый вечер пятницы и субботы, когда нормальные люди открывают техокна для разных профилактических работ. У сайта с архивом военных данных пик — на 9 мая. У туристов — летом. И так далее. Мы делали исследование по сезонной нагрузке, чтобы понять, насколько велика волна и у кого какая она есть. Как показала практика, на текущий момент для нашего объёма мощностей любая сезонная нагрузка на клиентских ресурсах — это ничтожные колебания по нагрузке виртуальных серверов. Пик по сайтам — десятые доли процента вычислительной мощности ЦОД. И это ещё без учёта резервирования на случай выхода из строя физических хостов.
Нужно еще больше. С резервированием разобрались, но сайт продолжает расти. Здесь уже масштабируем систему по горизонтали, увеличивая количество виртуальных машин там, где не хватает ресурсов. Фронтенд масштабировать обычно смысла нет — там минимум нагрузки и требуется только резервирование.
С базами данных ситуация в плане масштабирования сложнее. В случае с SQL-подобными базами данных мы поступаем следующим образом: есть одна база, для её резервирования мы собираем кластер с «плавающим» IP-адресом и ставим рядом вторую. При падении первой базы, происходит переключение на вторую, и мы продолжаем работать. Так как в веб-приложениях 90% нагрузки на БД — это селекты (запросы на чтение), можно настроить репликацию и распределить большую часть этой нагрузки на slave-серверы. На моей памяти есть проект, где таких slave-серверов 15 штук. Для целостности процесса репликации slave-серверы сконфигурированы только на чтение (read-only).
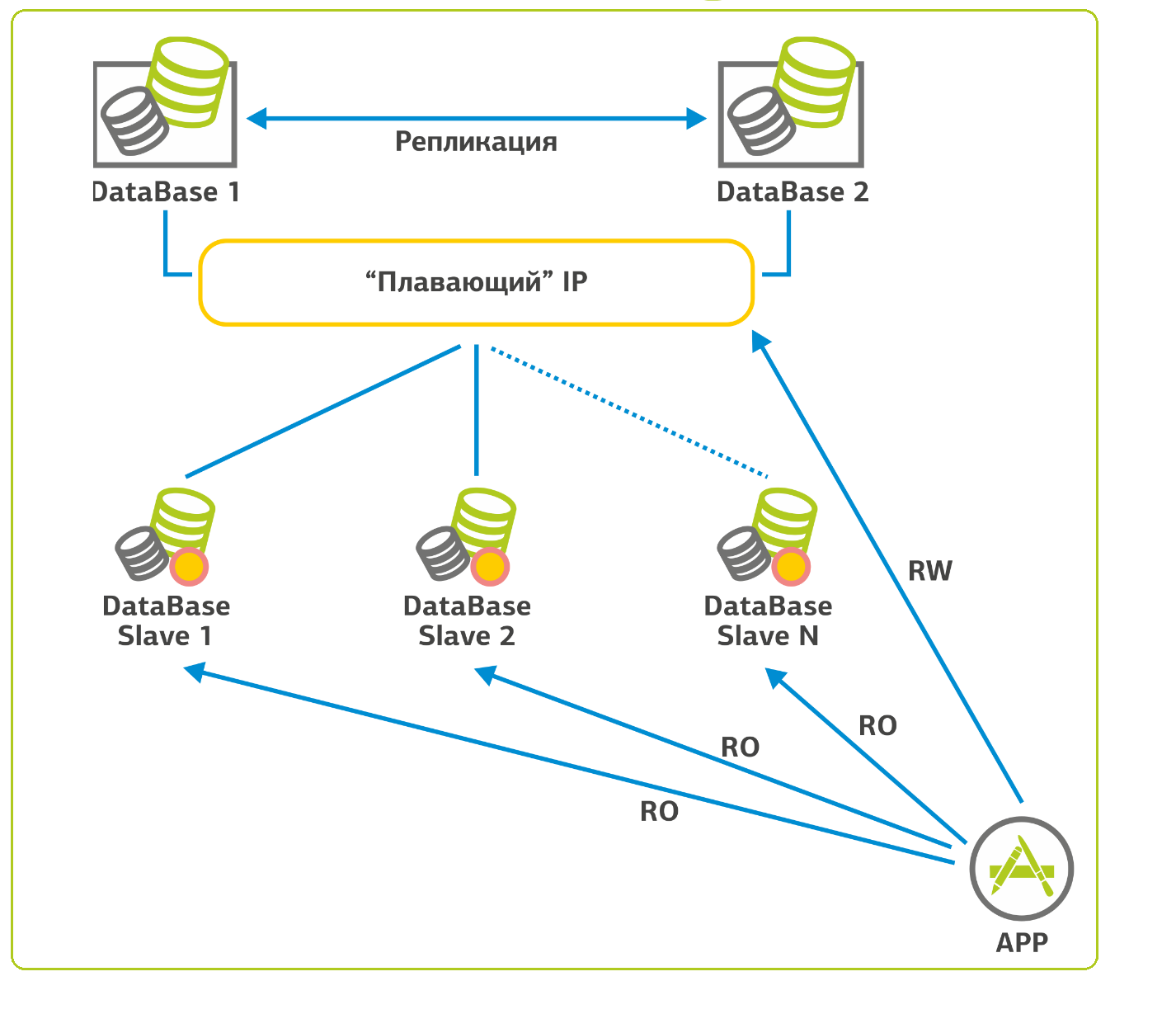
Вот примерно так.
К нам приехал сайт
Теперь поговорим о том, что происходит у нас, когда приезжает клиентский сайт. Здесь кроется самое веселье.
Начинается часто с замены операционок и web-сервера. Обычная ситуация — я вижу старые убунты и старые версии разных модулей, которые патчили последний раз года два назад. Один раз принесли даже корпоративный сайт на Федоре (напомню: тестовой площадки для RedHat). А мы отвечаем за безотказную работу, поэтому при всей моей платонической любви к Fedora Core, оставить эту ось я там просто не мог. При финансово подкреплённом SLA мы даже не узнаем, из-за чего она упала. В своих проектах предпочтение отдаем RedHat, CentOS и Unbreakable Linux (ранее дистрибутив назывался менее пафосно — Oracle Enterprise Linux). Соответственно и сертифицируются наши linux-администраторы по программе RedHat: RHCE — минимальный уровень, для допуска к продуктивному серверу.

Так выглядит SLA на сервис: общий уровень доступности не может быть выше самого слабого звена.
Многие готовы спокойно переносить почту, но не готовы заносить к нам основной сайт без длительных тестов. Интернет-магазины крупных компаний, например, переносятся последними — сначала клиент ставит пару промо-страниц или что-то ещё, не очень далеко ушедшее от static HTML, и всё тщательно обкатывает. А уже после всех тестов дает добро на переезд сайта.
Вместо заключения
Поговорим о «фантастических тварях», обитающих на сервере. Очень часто получается так, что на сайте, пережившем уже 3–5 лет продакшна, часть сервисов втыкал старый админ, часть — новый. Не всегда это делается должным образом: зачастую программы собираются из исходников, а пакетный менеджер и вовсе «поломан». Никто не проверяет выход следующих версий и, как правило, такие системы не обновляются. Кусочки иногда работают дырявыми по нескольку лет. Например, были боли с Tomcat — его собирают «как есть» и не трогают. Обычно обновлять его заставляют разработчики. Когда они получают новые функции, админа больше никто не дёргает, он забивает на апдейт продукта, и все живут на одной версии долго и счастливо. Пока не прихожу злой я и не начинаю показывать пальцем на разные дырки.
Если на сервере зоопарк, мы предлагаем план миграции: разворачиваем у себя нужную инфраструктуру, уже свежую и ровную, и перетаскиваем на нее проекты. Конкретно мы таскаем Linux с Linux'а, с Windows работает другая команда. Даём доступ к платформе — и заказчик или его разработчик начинает переносить. Иногда это поручается нам.
На новой инфраструктуре разворачиваются копия баз данных и скриптов сайта. Далее совместно с заказчиком приступаем к функциональному и нагрузочному тестированию. Со своей стороны, мы настраиваем сбор метрик производительности и контролируем логи ошибок. По результатам тестирования совместно с командой разработчика проводим донастройки (тюнинг).
Когда результаты тестов, в том числе функциональных, удовлетворительны, ошибок больше нет, мы готовим сервис к выходу в продуктив: настраиваем мониторинг, заново синхронизируем данные с продуктивной системой и переключаем нагрузку на новую инфраструктуру. И следим, чтобы инфраструктура успевала за ростом сайта.
На сегодня всё, задавайте вопросы в комментариях.
Комментарии (16)

mvalery
11.08.2017 23:45А как организовать «плавающий IP»? Если есть информация по VMware ESXi — еще лучше.

axmetishe
12.08.2017 07:02+2Например VRRP, демон keepalived, можно Nginx, есть и другие варианты, лично я выбираю keepalived при работе с базами.

sborisov
12.08.2017 10:45Так вроде kernel.org работает на Fedora и ничего. Странный парень...

plin2s
12.08.2017 18:13А что такого ценного в kernel.org чтобы о нем сильно заботиться? Товар не продает, денег не приносит, даже рекламы нет (лого дистртбутивов мне не кажется прямой рекламой). Тем более что есть куча зереал.Даже если он сляжет на пару недель, трагедии не произойдет.
В посте же речь, насколько я вижу, про ифраструктуру, которая не только электричество потребляет, но и приносит немалую прибыль.

zm_llill
13.08.2017 03:23А в чем преводсходство Красной Шапки над Дебиановцами? По тексту заметил снисходительно-пренебрежительный тон по отношению к Убунте, поэтому и возник такой вопрос.

BOPOHA
13.08.2017 04:06Это холиварная тема.
Например, чем мне не нравится убунта (и частично это присуще дебиану, но только частично): в рамках LTS релиза может мажорно измениться версия ядра; мейнтернеры делают так, чтобы после установки сервисов, они автоматом стартовали; репы типа большие, но недостаточное тестирование; медленная реакция на проблемы в багтреккерах; сам deb как формат пакетов ...zm_llill
13.08.2017 04:39Конечно, не ради холивара спросил, а опыта перенять.
5000shazams Автор
14.08.2017 14:05Тут ведь как… Можно и Убунту сделать стабильной, но есть еще трудозатраты по поддержке. Отсюда и предпочтение к Красной Шапке.

navion
13.08.2017 15:16+1Unbreakable Linux (ранее дистрибутив назывался менее пафосно — Oracle Enterprise Linux)
Это ядро, а дистрибутив называется почти также: Unbreakable Enterprise Kernel for Oracle Linux.
я вижу старые убунты
IBM не такая привередливая и поддерживает большинство приложений на актуальных Ubuntu LTS.
EgorBayandin
14.08.2017 11:51С почему общий SLA 99,9? Вероятность несвязных событий считается как произведение вероятностей, те общий SLA системы получается 99,8%
5000shazams Автор
14.08.2017 14:08My bad. Картинка отражает правило проектирования. Оно не описывает вероятность факапа, оно говорит о том, что надежность системы в первую очередь определяется надежностью самого слабого звена. В эксплуатации, конечно, будет "?".
questor
Есть что рассказать про опыт конкретных движков типа вордпресса или Битрикс, всю
радостьболь работы с ними?5000shazams Автор
Мне, как админу не важно — битрикс, вордпресс, джумла или что-то еще. Модули разные, а проблемы и схема масштабирования примерно похожи.