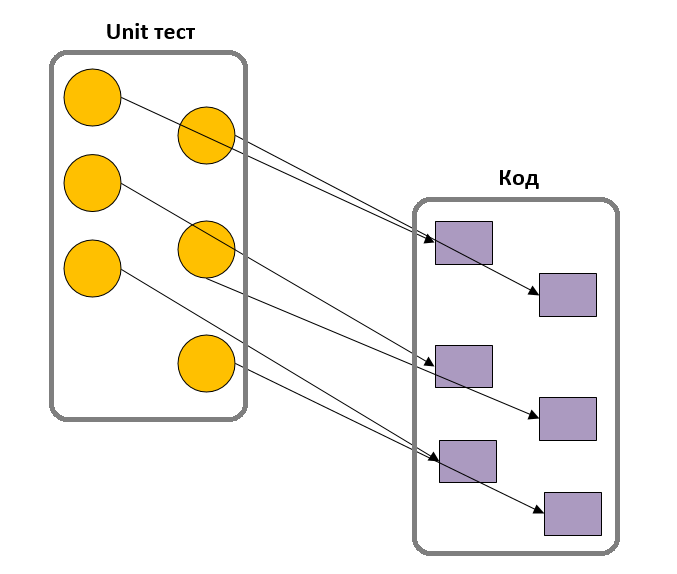
Несмотря на различные трактовки юнит тестирования, есть несколько вещей которые объединяют этот термин.
Но есть моменты, в определении юнит тестирования, которые до сих являются спорными. В частности, что рассматривается под юнитом (единицей тестирования)? Подход ООП рассматривает класс как юнит, процедурный (или функциональный) подход, рассматривает одну функцию как юнит. Некоторые разработчики берут несколько классов и считают это юнитом, или берут набор методов в качестве юнита. Но на самом деле это ситуационная вещь, команда сама решает, что должно быть единицей тестирования в их системе.
Преимущества юнит-тестирования очевидны:
- Являются низкоуровневым и фокусируется на маленькой части ПО
- Тесты пишут сами разработчики
- Тесты выполняются очень быстро, можно выполнять тесты несколько раз в минуту
- При разработке можно выполнять не все тесты, а только те, которые необходимы именно вам
Таким образом, при использовании юнит тестирования скорость разработки существенно не уменьшается, но при этом возрастает качество самого продукта.
Важное различия в юнит тестировании, это какой тип тестирования вы выберите: Solitary (одинокий) и Sociable (общительный) тест. Термины впервые ввел Jay Fields.
Sociable (общительный) тест — это тест который использует реальные методы (или классы), которые входят в тестируемую единицу. Например, вы тестируете метод «цена» из класса заказов. Методу «цена» необходимо вызвать методы из класса клиент и продукт. В данном виде тестов будут вызваны именно эти методы, и ошибка в этих методах приведет к ошибке теста. Методы из классов клиент и продукт называется партнеры (collaborators).

Solitary (одинокий) тест — это тест, который в качестве партнеров использует дубли (TestDouble). Тест-дубли — это общий термин для любого случая, в котором вы заменяете реальный объект, исключительно для целей тестирования.

Хорошую классификация дублей сделал Жерар Мезарос (Gerard Meszaros), более подробно об этом можно почитать здесь
Каждый из этих методов тестирования имеет свои достоинства и недостатки, и между сторонниками этих двух методов ведутся горячие споры. Сторонников Solitary (одинокий) тестов также условно называют Mock-исты (Mock — подделка), а сторонников Sociable (общительный) тестов условно называют Classicists (не смог найти аналогов в русском языке). Хочется отметить, что сторонники Sociable (общительного) тестирования, также используют дубль-тесты для доступа к внешним ресурсам, например, к БД. Отчасти, это делается по причине скорости доступа. Но использовать дубли для доступа к внешним ресурсам это не абсолютное правило, если доступ к ним стабилен и достаточно быстр, то можно обойтись и без дублей. В любом случае разработчик сам решает, когда ему лучше применить дубли.
Одно из достоинств техники тестирования Solitary (одинокий) в том, что разработчики фокусируются на поведении приложения, а не на состоянии. Недостаток в том, что подделки могут замаскировать ошибку, которая присутствует в методе-партнере. Поэтому, при использовании тестов-дублей необходимо выполнять интеграционное тестирование. Достоинство тестирования Sociable (общительный) в том, что это уже по сути начальное интеграционное тестирование, но недостаток в том, что если упадет один метод это приведет к падению всех тестов, связанных с этим методом, что затрудняет отладку.
Я не буду подробно останавливаться на достоинствах и недостатках того или иного подхода в тестировании, об этом можно почитать у Фаулера в статье Mocks Aren't Stubs
Основные свойства unit-тестирования – это небольшой объем, сделанный самим программистом, и скорость – что означает, что они могут выполняется часто во время программирования.
Разработчики могут выполнять их после любого изменения в коде. Но не обязательно запускать всегда все тесты, достаточно выполнить только те тесты, которые взаимодействуют с кодом, над котором вы трудитесь в текущий момент.
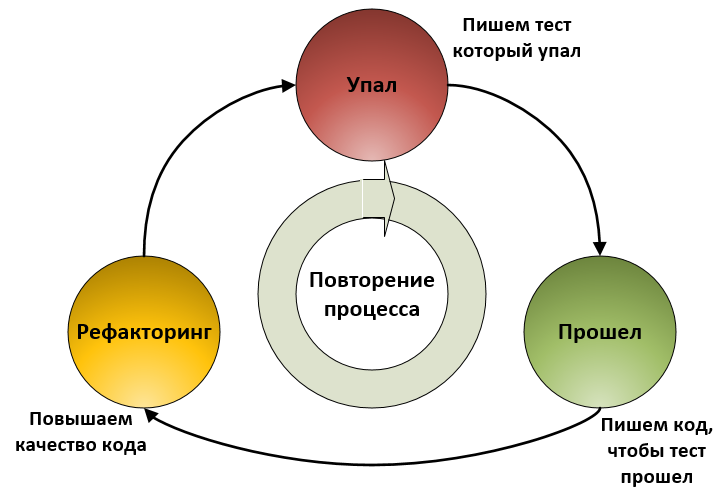
В конце 1990-х годов Кент Бек разработал технику «разработка через тестирование» (Test-Driven Development, TDD), как часть экстремального программирования. Эта техника для построения ПО, которая управляет процессом разработки через написание тестов. В сущности, повторяет три простых правила:
- Сначала пишется тест
- Затем пишется код под этот тест
- Рефакторинг нового и старого кода, чтобы улучшить качество кода
Процесс начинается заново пока не получится желаемый результат.
Написание теста первым дает два преимущества:
1. Это способ получить само-тестируемый код
2. Думая сначала о тесте вы заставляете себя думать об интерфейсе самого кода. Эта фокусировка на интерфейсе и на том как вы используете класс помогает вам разделить интерфейс от реализации.
Самая большая ошибка при использовании данной методологии — это пренебрежение третьим шагом, рефакторинг. Это приводит к тому, что код будет “грязным” (но по крайней мере, будут тесты).
BDD (Behaviour Driven Development) или разработка на основе поведения, появилось в процессе эволюции unit-тестирования и разработана Дэном Нортом (Dan North) в 2006г. Как утверждает сам автор, методология должна помочь людям изучить TDD. Она появилось из agile практик и предназначена сделать их более доступными и эффективными для команд-новичков в Agile.
Со временем, BDD стало охватывать более широкую картину agile-анализа и автоматическое приемочное тестирование.
Это привело к тому, что сами тесты стали переименовывать в поведение (спецификации), что позволило сфокусироваться на том, что объекту нужно сделать. Таким образом, разработчики стали создавать для себя документацию и записывать названия тестов в виде предложений. Они обнаружили, что созданная документация, стала доступна бизнесу, разработчикам и тестерам.
Считается, что разработка на основе поведения одно из ответвлений Mock-стилей (или Solitary-тест), т.е. тесты преимущественно строятся с использованием дублей.
Позднее, появился стиль написания тестов Given-When-Then, или, как его стали называть, спецификация поведения системы. Стиль был разработан Дэном Нортом (Dan North), совместно с Крисом Маттисом (Chris Matts). Идея заключается в том, чтобы разбить написание тестового сценария на три раздела:
- Дано (Given) — состояние, до того, как вы начнете описывать поведение. можно рассматривать как предварительное условие теста.
- Когда (When) — поведение, которое вы описываете.
- Тогда (Then) — изменения, которые вы ожидаете от поведения
Пример:
Описание: Пользователь продает акции.
Сценарий: Пользователь запрашивает продажу до закрытия торгов
Дано (Given): У меня есть 100 акций MSFT и 150 акций APPL и время до закрытия торгов.
Когда (When): Я прошу продать 20 акций MSFT
Тогда (Then): У меня должно остаться 80 акций MSFT и 150 акций APPL и заявка на продажу 20 акций должна быть выполнена.
Не взирая на то, что с момента появлений методологий TDD и BDD прошло довольно много времени, многие разработчики до сих пор спорят друг с другом о целесообразности их применения. Кто-то утверждает, что нет необходимости писать тесты перед кодом, другие заявляют, что написание тестов после кода бессмысленно. Но и та и другая стороны согласны в одном, что тесты нужно писать! Методология BDD с точки зрения программистов, как утверждает сам ее автор (BDD IS LIKE TDD IF…), не отличается от TDD. Там используются все те же правила, что и в TDD: тест, код, рефакторинг. Отличие заключается в том, что BDD охватывает более широкую публику. Спецификации становятся доступными не только программистам, но и людям, не разбирающимся в коде, но имеющим отношение к разработке ПО. Таким образом, в процесс создания тестов подключается вся команда: аналитики, тестеры, менеджеры.
Одно очевидное преимущество юнит-тестов в том, что они могут радикально уменьшить число ошибок, которые попадают в продукт. В основе этого лежит культура, в результате которой разработчики думают о написании кода и тестов вместе.
Но самое большое преимущество не в том, чтобы просто избегать ошибок в продукте, а в уверенности в том, что вы можете вносить изменения в систему. Старый код часто является ужасной картиной, где разработчики боятся его менять. Даже исправление одной ошибки может быть опасно, т.к. вы можете создать больше ошибок, чем исправите. В таких случаях, добавление новых возможностей происходит очень медленно, вы также боитесь сделать рефакторинг системы, увеличивая тем самым технический долг (TechnicalDebt) и попадаете в плохую спираль, где каждое изменение заставляет людей боятся еще большего изменения.
С тестами другая картина. Здесь люди уверены, что фиксация ошибок, может быть сделана безопасно, потому что, если вы допустили оплошность, то детектор ошибок сработает, и вы можете быстро восстановить и продолжить. С помощью этой системы безопасности, вы можете всегда поддерживать код в хорошей форме и уже не окажетесь в плохой спирали.
В качестве детектора ошибок (само-тестируемая система) выступает процесс выполнения серии автоматических тестов (не только юнит), и вы уверены, что тесты пройдут и ваш код не содержит существенных дефектов. Если кто-то в команде случайно сделает ошибку, сработает детектор. Выполняя тесты часто, несколько раз в день, вы можете обнаружить ошибки сразу после их появления, поэтому вы можете просто посмотреть последние изменения, что значительно облегчает поиск ошибок. Никакой программный эпизод не завершен без рабочего кода, и тестов, поддерживающих его работу.
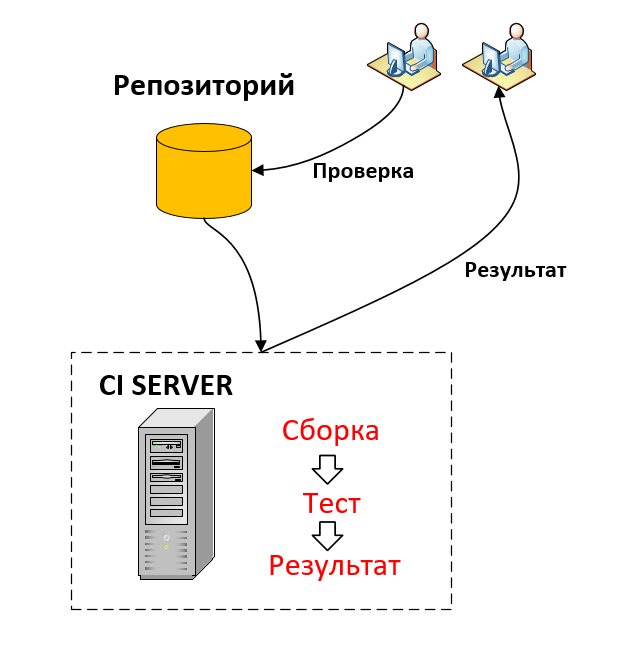
Само тестируемая система – это часть Continuous Integration (непрерывная интеграция) и Continuous Delivery (непрерывная доставка), но это тема уже выходит за рамки данной статьи.
Одним из важных действий команды, которая практикует различные тесты – это реакция на ошибку в продукте. Обычная реакция команды, это сначала написать тест, чтобы обнажить ошибку, и только потом попытаться исправить ее. Часто написанием этого теста будет серия тестов, которая постепенно сужает область действия до тех пор, пока вы не добьетесь юнит-теста, который эмулирует ошибку. Эта техника гарантирует, что после исправления ошибки, она останется фиксированной. Позиция должна быть в том, что любая ошибка, это не просто провал в коде, это также провал в защите тестирования.
В качестве детектора ошибок или автоматических тестов, выступают не только unit-тесты, но также интеграционные тесты, и другие автоматические тесты. Но unit-тесты здесь играют основу, т.к. написать их просто и выполняются они очень быстро.
Высокоуровневые тесты — это вторая линия обороны. Если вы получили ошибку в высокоуровневом тестировании, то это не просто ошибка в коде, это отсутствующий или некорректный юнит тест!
Список источников:
- Martin Fowler UnitTest
- Martin Fowler TestPyramid
- Martin Fowler SelfTestingCode
- Martin Fowler TestDrivenDevelopment
- James Shore The Art of Agile Development: Test-Driven Development
- Введение в программирование через поведение (BDD)
- Martin Fowler GivenWhenThen
Комментарии (34)

Griboks
21.08.2017 12:17Насколько я понял, тестирование — это верификация в программировании. Во всяком случае, юниты тестирование.
А как обстоят дела с моделированием? Какие комплексные технологии и методологии используются при моделирование работы кода? Возможно, следует написать об этом отдельную статью?

dr_Irbisov
21.08.2017 12:33Но использовать дубли для доступа к внешним ресурсам это не абсолютное правило, если доступ к ним стабилен и достаточно быстр, то можно обойтись и без дублей.
Мне казалось, что основная задача использования дублей — это сокращение «кода под тестами». Т.е. мы хотим проверить работу юнита(как бы масштабно мы его не определяли) — и мы не хотим зависеть от потенциальных проблем со стороны внешних зависимостей. Подключая сь к БД, даже если соединение быстрое и стабильное, мы увеличиваем количество мест, где может произойти ошибка, перестаем тестировать исключительно текущий модуль.
fmva Автор
21.08.2017 12:57Стоит ли подключаться к БД, чтобы тестировать модуль, решает сам разработчик. Да, вы правы, мы получаем зависимость. Но как я писал выше, есть сторонники Sociable (общительных) тестов, которые строят архитектуру тестирования именно на зависимостях, и как они утверждают, найти такую ошибку не составляет труда. Это спорный момент, стоит ли делать зависимости или дубли, здесь каждый сам решает для себя, как ему удобнее, и главное, как удобнее для проекта.
VolCh
21.08.2017 14:08По-моему, в любом случае черезчур общительные тесты (читай использующие внешние ресурсы) — это точно не юнит-тесты (если взаимодействие с ними не единственная отвественность модуля). Всегда понимал Sociable Unit Tests как тесты, которые не мокают/стабят код, который тестируется в соседнем тесте, код, который принадлежит к той же кодовой базе, что и тестируемый.
nohuhu
22.08.2017 08:55Это спорный момент, стоит ли делать зависимости или дубли, здесь каждый сам решает для себя, как ему удобнее, и главное, как удобнее для проекта.
Если чутка покопаться, то никакой спорности в этом моменте нет. Разница между доступом к ресурсу и доступом к дублю в поведении: дубль ведёт себя так, как вам нужно. Нужно, чтобы давал правильный ответ — всегда даёт правильный, нужно, чтобы давал отказ — всегда даёт отказ. В отличие от внешних ресурсов, поведение которых по прошествии времени меняется неизбежно.
Многие, очень многие (подавляющее большинство?) разработчиков думают о тестах
свысокас позиции текущего момента в разработке: работает/не работает прямо сейчас. Основная ценность же набора тестов, особенно юнит тестов, состоит в нахождении регрессий. И основная ценность дублирования состоит в обеспечении отсутствия ложных регрессий.
От лени всё это. "Да чего дублировать, и так же работает". Ну, сейчас работает. А когда через год или два администраторы базы устроят лёгкий рефакторинг и у вас UI сойдёт с ума на тестах, может уйти куча времени на разбор полётов и устранение проблем. И никто это не отловит заранее, потому что их тесты работают же, а ваши они не смотрят. ;)
t-nick
21.08.2017 13:14+1Упущенный но существенный момент — сложность юнита. Чем она меньше, тем проще написать тесты, тем менее хрупкими они будут, тем быстрее они будут исполняться. Ну и как следствие, сложный тест — индикатор («запашок») плохого дизайна.
alek_sys
22.08.2017 01:29+1Важное различия в юнит тестировании, это какой тип тестирования вы выберите: Solitary (одинокий) и Sociable (общительный) тест.
Если уж говорить про TDD, то часто применяют термин "пирамида тестов" — т.е. не выбирается один или другой подход, а они вполне себе друг друга дополняют. Типичная итерация TDD может выглядеть так:
- написали (расширили базовым кейсом) end-to-end тест самого высокого уровня. Это что-то, что работает с реальным приложением — нажимая кнопки как реальный пользователь, работая с настоящей базой и т.п. и вообще работает с системой как "внешний" наблюдатель. Таких тестов мало, они медленные, и проверяют именно пользовательские сценарии
- на уровне интеграционных тестов (видимо это и есть таинственные "общительные", я никогда такого термина не слышал) написали тест для публичного API. Тут уже какие-то внешние компоненты могут быть замоканы, может использоваться in-memory БД и т.п. Тем не менее, мы работаем с системой через внешний публичный API. Этих тестов уже больше, они относительно быстрые.
- спустились на уровень юнит-тестов. Тут уже никаких вариантов с подключением к базе быть не может, если юнит-тест падает от того, что база недоступна — это очень плохой юнит-тест. Таких тестов может быть очень много, работают они быстро, и работают в изоляции — крайне редко нужно чтобы использовалась реальная внешняя зависимость для юнита.
Проблема "общительных" тестов в применении к юнит-тестам (сам термин не очень корректный и я не слышал, чтобы он вообще использовался) это отсутствие локализации ошибки. В идеале, по упавшему тесту должно быть возможно без всяких неоднозначностей определить, в каком компоненте (функции / классе / компоненте) ошибка. А с наличием зависимостей мы получаем неоднозначность — это наша system under test упала? Или ее зависимость?
ZyXI
22.08.2017 01:44Нет, «интеграционные» тесты не общительные, общительные тесты всё ещё юнит?тесты, никакого (публичного) API не используется. Разница только и исключительно в том, что вы в юнит?тестах заменили на дубли (mock, dummy, …): в «общительных» тестах вы меняете только лишь тяжёлые вещи (вроде того же подключения к БД). В одиноких вы меняете всё, что можете заменить без того, чтобы тест потерял всякий смысл.
А как проблема «общительных» решается уже писали:
- Вообще?то юнит тесты быстрые, запускаются часто (зачастую до коммита вообще, если их можно запустить локально), обычно можно запускать конкретные тесты. Если вы поменяли какую?то тестируемую систему и упал юнит?тест, то искать «кто виноват» на уровне SUT не нужно независимо от того, какой тест упал: вы поменяли одну конкретную систему. А если вы поменяли сразу много и только потом пустили юнит тесты, то что?то у вас с процессом разработки не так.
- Если тестируется и некая система, и её зависимости, то вы просто начинаете исправление с зависимостей, а потом перезапускаете тесты. Главное, чтобы тестировалось и то, и то.
VolCh
22.08.2017 10:12Как по мне, то общительные тесты не интеграционные в привычном понимании, а вполне себе юнит, в том смысле, что не используют внешние ресурсы, но в тест-кейсах задействуется не один юнит, а несколько — один целевой и "библиотечные".
Например, есть код типа
class Order { public function __construct(Customer $customer) {}; }
Если в тестах мы будем $customer мокать/стабить, то это будет "одинокий" тест, если просто подставим new Customer(), то это будет "общительный". При этом исходим из предположения, что когда дело доходит до тестов класса Order, то класс Customer уже протестирован, и падающие тесты Order будут означать, скорее всего, ошибку в Order.
Sinatr
22.08.2017 10:22Не эксперт в данном вопросе.
Таким образом, при использовании юнит тестирования скорость разработки существенно не уменьшается
Не понятно как пришли к такому выводу. Перечисленные пункты никакого отношения к выводу не имеют. Стоит ли читать дальше?Sinatr
22.08.2017 10:27Имеется в виду «существенно не увеличивают время компиляции» что ли?
fmva Автор
24.08.2017 04:56я хотел сказать, что юнит тестирование намного быстрее, чем другие виды тестирования. Главное, из-за времени выполнения самих тестов. А также, по причине того, что тесты пишут сами разработчики, а не третьи лица. По поводу скорости разработки, да скорость разработки, при написании тестов, уменьшается, но не существенно, при грамотном подходе и наличии опыта.
t-nick
22.08.2017 13:36Классические юнит тесты (те что общительные) проверяли состояние (до/после), что зачастую требовало раскрытия внутреннего состояния юнита и нарушало инкапсуляцию.
Моки, на мой взгляд, стали революцией в юнит тестировании, так как позволили писать тесты только для публичного интерфейса юнита заменив проверку состояния на проверку поведения. Последняя предъявляет более высокие требования к дизайну делая код чище/лучше (можно получить код соответсвующий SOLID принципам ничего не зная о последних).
В TDD c изолированными (Solitary) тестами фаза рефакторинга практически отсутствует (если тесты и юниты достаточно простые) и заменяется проектированием. В классических тестах требования к дизайну минимальны (главное получить нужное состояние на выходе, что можно сделать бесчисленным количеством способов), и в фазе рефакторинга каждый улучшает код как может или не делает этого вовсе. Моки можно сделать строгими задавая ожидаемое поведение, любое неожиданное поведение (вызов не ожидаемого метода или метода с параметром отличным от ожидаемого) приведет к провалу теста. Тесты состояния менее чувствительны к сайд эффектам, так как зависимости могут быть неявными (DI — необязателен). Можно изменить поведение на некорректное таким образом, что тест состояния останется зеленым делая его практически бесполезным. Чтобы этого избежать тест должен запускаться на множестве входных данных, что делает его медленнее.
В связи со всем вышесказанным считаю классические юнит тесты устаревшим подходом, по которому, однако, написано очень много материалов (особенно от авторитетных светил вроде Дяди Боба), что вносит путаницу и уводит новичков от прогресса.

Tab10id
25.08.2017 13:49Хочу заметить еще один важный плюс изолированных тестов. В процессе разработки очень полезно использовать такую метрику как «покрытие кода». Проблема данной метрики в том, что она всегда врет. Если имеется 100% показатель покрытия кода, это всего лишь значит что мы прошлись по коду, но совершенно не значит что мы проверили его работоспособность. Имея неизолированный тест мы увеличиваем покрытие соседних юнитов, не проверяя их работоспособность. Наличие дублеров делает данную метрику чуть более «честной», так как мы вызываем только тестируемый код.

Varim
25.08.2017 15:14Наличие дублеров делает данную метрику чуть более «честной», так как мы вызываем только тестируемый код.
Как по мне то «Наличие дублеров делает данную метрику чуть более «ошибочной»», так как мы вызываем только код одного класса, а не ту связку классов которая будет в продакшине.Tab10id
25.08.2017 15:36Предполагается что остальные классы тоже будут покрыты=).
То что один юнит будет вызывать другой юнит с заданными параметрами и нужное количество раз как раз таки удобно тестировать с помощью моков. Ну и интеграционные тесты никто не отменяет, просто не нужно оценивать покрытие на основе интеграционных тестов.Varim
25.08.2017 15:50Например интеграционные тесты вызывают метод с параметрами:
(А=1, В=0) либо (А=0, В=1).
А юнит тест в придачу может вызывать случай (А=1, В =1), что в реальности не требуется, но делает покрытие 100%.
Вопрос в том, что такое 100% покрытие. Если одна и та же ветка кода вызывается два раза, это 200% покрытия? Что на самом деле нам говорит покрытие в 100%?VolCh
25.08.2017 16:25ЧТо каждая значимая строчка кода вызывалась минимум один раз во время прохождения тестов.
Varim
25.08.2017 16:35Вот именно, не больше, не меньше.
Но разве это ценность?
Причем не значимая строчка кода, а просто строчка кода.
Мне думается это не совсем тот результат который я бы хотел.
Мне лично, удобно использовать Solitary (одинокий) UnitTests для TDD, для быстроты разработки. Изолированность класса тут то что надо.
А для тестирования системы необходим инструмент который тыкает на кнопки вместо пользователя, ну или хотя бы дергает сервисы по сценариям пользователя.
Я к тому что процент покрытия тестами это на мой взгляд достаточно бесполезная метрика.Varim
25.08.2017 16:40То есть если видишь что у тебя 70% покрытия тестами, то думаешь ну и фиг с ним. Будут баги, на багу сделаю интеграционный тест, если % покрытия при этом увеличится то и хорошо, а если нет то и пошел этот процент в Ж.
ZyXI
25.08.2017 17:42А что в проекте делают незначимые строчки кода? Ухудшают читаемость?
Мои наблюдения таковы, что в проекте, с которым я сейчас больше всего работаю, покрытие обычно отсутствует в коде обработки ошибок, дополнительно часть функциональности унаследована с тех времён, когда тестов ещё особо не писали. Как результат, я уже несколько раз наталкивался на ошибки в коде обработки ошибок, который я случайно или намеренно задействовал в интеграционных тестах других систем. Если бы не было таких «унаследованных» систем, то можно было бы реализовать требование «100?% покрытие», что автоматически означало бы «не забудьте тестировать обработку ошибок». Правда сама цифра мне как?то без разницы, главное, чтобы обработку ошибок тестировали, это просто простейший вариант заставить контрибьюторов с излишне «позитивным» мышлением делать «негативные» тесты до review.
Varim
25.08.2017 18:06Если не ошибаюсь, Кнут шутил/утверждал что в любой программе, есть меньшая по объему корректная программа.
На практике все программы не идеальные, помимо того что они должны делать, они содержат какие то избытки либо недостатки логики.
Мне довелось работать на медицинском проекте, где по стандартнам необходимо 100% тестирование.
Так вот, в основном это были юнит тесты, которые тестировали не только ту работу, которая необходима для устройства, но и какой то левый непонятный код.
Поскольку был не TDD, то есть не сначала тесты, а сначала несколько лет писалась логика, потом, перед сдачей, выделили время на покрытие тестами.
Как это делалось — бралась ветка if(condition){block1}else{block2} и под условия писался юнит тест.
Что тестировал этот тест?
Все что мог, в том числе излишнюю логику и даже замораживал, а не тестировал, код тех баг, которые неосознанно в код внес программист.
Это была заморозка логики, а вовсе никакой нифига не тест.
Поскольку программы пишутся не минимальные то и 100% покрытия это абсурд.VolCh
25.08.2017 18:37Это была заморозка логики, а вовсе никакой нифига не тест.
Это и есть основное назначение юнит-тестов :) При практически идеальном покрытии кода этими тестами они упадут при малейшей попытке изменить логику. Они являются красным индикатором "ЛОГИКА ИЗМЕНЕНА!!!". А желательное это изменение ил инет — решать разработчику. В перовом случае править тесты, во втором — код.
ZyXI
25.08.2017 19:35Так для недопущения таких ситуаций reviewer’ы потом смотрят и на код, и на тесты и спрашивают «а чего это ваш код ведёт себя именно так?» в особых случаях. С полным покрытием такие «особые случаи» можно легче заметить по тестам, без полного покрытия их и не заметит никто. Если нет людей, которые проверяют код, то тесты в любом случае не сильно помогут. Только стремиться к 100?% покрытию функциональными, а не юнит, тестами с этой точки зрения имеет наибольший смысл: видно, что код реально может быть вызван, а понять, адекватно ли поведение, легче.
Varim
25.08.2017 19:46+1стремиться к 100?% покрытию функциональными, а не юнит, тестами
Юнит тесты, тоже функциональные. Вы наверно имеете в виду интеграционные тесты и выше — System и AcceptanceZyXI
25.08.2017 20:04Эм, приёмочные тесты и есть функциональные, сравните определение в https://en.wikipedia.org/wiki/Functional_testing («a type of black-box testing that bases its test cases on the specifications of the software component under test») и https://en.wikipedia.org/wiki/Acceptance_testing («a test conducted to determine if the requirements of a specification or contract are met»). В https://ru.wikipedia.org/wiki/Разработка_через_тестирование вообще прямо написано
Приёмочные (функциональные) тесты (англ. customer tests, acceptance tests) — тесты, проверяющие функциональность приложения на соответствие требованиям заказчика.
VolCh
25.08.2017 18:33Не учитываются в покрытии строки комментариев, строки деклараций и т. п. "Значимая" тут -"исполняемая".
Юнит-тесты — не инструменты выявления ошибок, не инструменты тестирования системы или пользовательских сценариев, это лишь инструмент фиксации желаемого поведения отдельных кусков кода.
Я лично считаю, что юнит тесты должны быть "одинокими", в том числе и потому что так метрика покрытия кода юнит-тестами даёт более полезное значение — автор теста хотел покрытыть тестами именно покрытую строку, а не она "сама" покрылась, может даже без ведома автора.
Varim
25.08.2017 18:45Юнит-тесты — не инструменты выявления ошибок, не инструменты тестирования системы или пользовательских сценариев
Все таки, если говорить о TDD, то это хотя бы инструмент выявления недоработок.
это лишь инструмент фиксации желаемого поведения отдельных кусков кода.
Не только желаемого, но и инструмент фиксации случайно протестированных багов.VolCh
25.08.2017 18:50Все таки, если говорить о TDD, то это хотя бы инструмент выявления недоработок.
Не согласен. При TDD мы сначала фиксируем желательное поведение в тестах, а потом добиваемся его от кода. В конце рефакторм так, чтобы поведение не изменилось.
Не только желаемого, но и инструмент фиксации случайно протестированных багов.
Фиксация желаемого поведения заключается в коде теста. Если вы ошиблись в коде теста, значит вы ошиблись в выражении того, какое поведение вы считаете желаемым. Как говорится "телепаты в отпуске", а "написанное пером не вырубишь топором" :)
Varim
25.08.2017 19:04+1Если вы ошиблись в коде теста, значит вы ошиблись в выражении того, какое поведение вы считаете желаемым.
Вот кстати, ведь в реализации метода можно использовать больше или меньше условий чем подразумевает тест.
Инструменты покрытия, считают процент только по строкам кода, или еще и по количеству комбинации условий в операторе IF?ZyXI
25.08.2017 19:40То, что я видел — по строкам. Ещё наши
assert(false)за код принимают :) (Хотя сами виноваты, нужно компилировать с-DNDEBUG, иначе там реально будет код.)
VolCh
Непонятная фраза. Тесты в контексте TDD/BDD — это средство фиксации поведения и детектирования его изменения. Ошибка означает, что или не зафиксировали требуемое поведение, или зафиксировали ошибочное.
По практике основная причин этого — плохо сформулированные требования или плохая работа с ними: или поведение в каком-то особом случае не определено и разработчик интерпретировал его по другому чем ожидал заказчик ("это же очевидно, что бухгалтер не может подписывать счёт раньше менеджера"), или определено ошибочно, а разработчик просто реализовал его, или никто, прежде всего команда QA не заметили, что опеределенное четко сформулированное требование не выполняется. Чаще всего первая или вторая ситуация, то есть плохие требования.
fmva Автор
Согласен, что плохо сформулированное требование может привести к не тому результату, который ожидал заказчик. Но если взглянуть на проблему с позиции продукта, не разработчиков, то по сути была допущена ошибка. Хотя, я в этом предложении имел виду именно что не зафиксировали требуемое поведение