Статистика знает все. И Ильф и Е. Петров, «12 Стульев»
Представьте себе, что вы строите крупный торговый центр и желаете оценить автомобильный поток въезда на территорию парковки. Нет, давайте другой пример… они все равно этого никогда не будут делать. Вам необходимо оценить вкусовые предпочтения посетителей вашего портала, для чего необходимо провести среди них опрос. Как увязать количество данных и возможную погрешность? Ничего сложного — чем больше ваша выборка, тем меньше погрешность. Однако и здесь есть нюансы.

Теоретический минимум
Не будет лишним освежить память, эти термины нам пригодятся далее.
- Популяция – Множество всех объектов, среди которых проводится исследования.
- Выборка – Подмножество, часть объектов из всей популяции, которая непосредственно участвует в исследовании.
- Ошибка первого рода — (?) Вероятность отвергнуть нулевую гипотезу, в то время как она верна.
- Ошибка второго рода — (?) Вероятность не отвергнуть нулевую гипотезу, в то время как она ложна.
- 1 — ? — Статистическая мощность критерия.
- ?0 и ?1 — Средние значения при нулевой и альтернативной гипотезе.
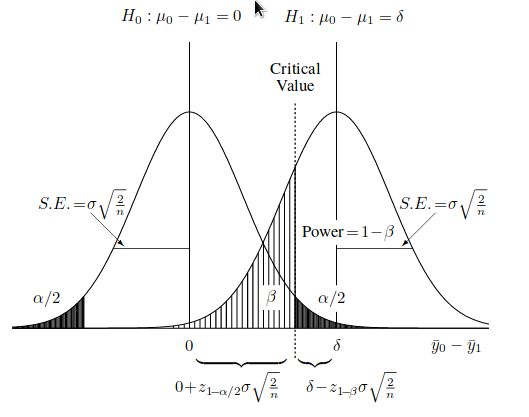
Уже в самих определениях ошибки первого и второго рода имеется простор для дебатов и толкований. Как с ними определиться и какую выбрать в качестве нулевой? Если вы исследуете уровень загрязнения почвы или вод, то как сформулируете нулевую гипотезу: загрязнение присутствует, или нет загрязнения? А ведь от этого зависит объем выборки из общей популяции объектов.
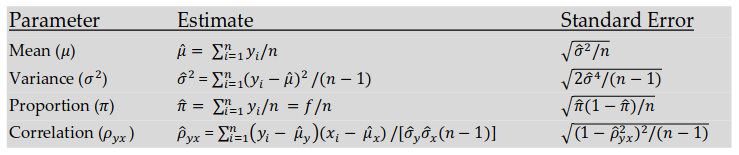
Исходная популяция, также как и выборка может иметь любое распределение, однако среднее значение имеет нормальное или гауссово распределение благодаря Центральной Предельной Теореме.
Относительно параметров распределения и среднего значения в частности возможно несколько типов умозаключений. Первое из них называется доверительным интервалом. Он указывает на интервал возможных значений параметра, с указанным коэффициентом доверия. Так например 100(1-?)% доверительный интервал для ? будет таким (Ур. 1).
- df — Степень свободы = n — 1, от английского «degrees of freedom».
- — Двусторонняя критическая величина,
t-критерий Стьюдента.
Второе из умозаключений — проверка гипотезы. Оно может быть примерно таким.
- H0: ? = h
- H1: ? > h
- H2: ? < h
С доверительным интервалом 100(1-?) для ? можно сделать выбор в пользу H1 и H2 :
- Если нижний предел доверительного интервала
100(1-?) < h, то тогда отвергаем H0 в пользу H2. - Если верхний предел доверительного интервала
100(1-?)> h, то тогда отвергаем H0 в пользу H1. - Если доверительного интервала
100(1-?)включает в себя h, то тогда мы не может отвергнуть H0 и такой результат считается неопределенным.
Если нам нужно проверить значение ? для одной выборки из общей совокупности, то критерий обретет вид.
- Отбраковать H0 и принять H1: ? > h, если .
- Отбраковать H0 и принять H2: ? < h, если .
- Невозможно отвергнуть H0, если .
Где .
Доверительный интервал, погрешность и размер выборки
Возьмем самое первое уравнение и выразим оттуда ширину доверительного интервала (Ур. 2).
В некоторых случаях мы можем заменить t-статистику Стьюдента на z стандартного нормального распределения. Еще одним упрощением заменим половину от w на погрешность измерения E. Тогда наше уравнения примет вид (Ур. 3).
Как видим погрешность действительно уменьшается вместе с ростом количества входных данных. Откуда легко вывести искомое (Ур. 4).
Практика — считаем с R
Проверим гипотезу о том, что среднее значение данной выборки количества насекомых в ловушке равно 1.
- H0: ? = 1
- H1: ? > 1
| Насекомые | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|---|
| Ловушки | 10 | 9 | 5 | 5 | 1 | 2 | 1 |
> x <- read.table("/tmp/tcounts.txt")
> y = unlist(x, use.names="false")
> mean(z);sd(z)
[1] 1.636364
[1] 1.654883Обратите внимание, что среднее и стандартное отклонение практически равны, что естественно для распределения Пуассона. Доверительный интервал 95% для t-статистики Стьюдента и df=32.
> qt(.975, 32)
[1] 2.036933и наконец получаем критический интервал для среднего значения: 1.05 — 2.22.
> ?=mean(z)
> st = qt(.975, 32)
> ? + st * sd(z)/sqrt(33)
[1] 2.223159
> ? - st * sd(z)/sqrt(33)
[1] 1.049568В итоге, следует отбраковать H0 и принять H1 так как с вероятностью 95%, ? > 1.
В том же самом примере, если принять, что нам известно действительное стандартное отклонение — ?, а не ее оценка полученная с помощью случайной выборки, можно рассчитать необходимое n для данной погрешности. Посчитаем для E=0.5.
> za2 = qnorm(.975)
> (za2*sd(z)/.5)^2
[1] 42.08144Поправка на ветер
На самом деле нет никаких причин, полагать, что нам будет известна ? (дисперсия), в то время как ? (среднее) нам еще только предстоит оценить. Из-за этого уравнение 4 имеет мало практической пользы, кроме особо рафинированных примеров из области комбинаторики, а реалистичное уравнение для n несколько сложнее при неизвестной ? (Ур. 5).
Обратите внимание, что ? в последнем уравнении не с шапкой (^), а тильдой (~). Это следствие того, что в самом начале у нас нет даже оценочного стандартного отклонения случайной выборки — , и вместо нее мы используем запланированное — . Откуда же мы берем последнее? Можно сказать, что с потолка: экспертная оценка, грубые прикидки, прошлый опыт и т. д.
А что на счет второго слагаемого правой стороны 5-го уравнения, откуда оно взялось? Так как , необходима поправка Гюнтера.
Помимо уравнений 4 и 5 есть еще несколько приблизительно-оценочных формул, но это уже заслуживает отдельного поста.
Использованные материалы
Комментарии (16)

dem0n3d
12.10.2017 00:17Популяция, Выборка, Ошибка первого рода, Ошибка второго рода, Синхрофазотрон… Не статья, а конспект едва ли не целого семестра по математической статистике. Никому, кроме (бывших) слушателей этих лекций, она понятна не будет.

temujin Автор
12.10.2017 17:48Это преувеличение. Те, кто занимаются случайными выборками имеют представление о предмете. Те же, кто первый раз в этим сталкивается, могут не понять о чем идет речь. Готов подсказать, если есть интерес, но непонятно кое-что.

rokobungi
12.10.2017 22:22Я не понаслышке знаком с обработкой случайных выборок и разработке математических моделей на основании результатов анализа. Дисперсия, критерий Стьюдента, СКО для меня не пустой звук. Но Ваше определение доверительного интервала вынудило меня приостановить чтение в этом месте и перечитать его ещё раз. Нет, я понял, что Вы имели ввиду, но определение написано очень, простите, заумно, и никогда Вы таким определением не объясните простому обывателю, что такое «доверительный интервал».
temujin Автор
12.10.2017 23:49Думаю, что простому обывателю в самом деле будет непонятно. Я написал это по следам практической задачи, которую мне пришлось решать, и это скорее для тех, у кого подобная задача имеется.
Andronas
12.10.2017 09:32Было бы неплохо разобрать и сделать несколько вводных лекций по следам этой лекции

Leg3nd
12.10.2017 13:44Я чего-то не понимаю или как среднее арифметическое из выборки: 10, 9, 5, 5, 1, 2, 1 может быть 1.636364? Ведь (10+9+5+5+1+2+1) / 7 = 4.714
temujin Автор
12.10.2017 13:49Таблица означает следующее:
- 10 ловушек с 0 насекомыми:
- 9 ловушек с 1 насекомым
- 5 — с 2,
- 5 — с 3
- 1 — с 4
- 2 — с 5
- 1 — с 6
получается 54 экземпляра делить на 33 ловушки.
Recloser
12.10.2017 23:42А что за переменная
bв четвертой строчке первого блока кода:
> x <- read.table("/tmp/tcounts.txt") > y = unlist(x, use.names="false") > > z <- c(b) > mean(z) [1] 1.636364 > mean(z);sd(z) [1] 1.636364 [1] 1.654883
Получается переменная
zникак не связана сxиy?temujin Автор
12.10.2017 23:44Да, это опечатка, спасибо что заметили. На самом деле z даже не нужно.
> x <- read.table("/tmp/tcounts.txt") > y = unlist(x, use.names="false") > mean(y);sd(y) [1] 1.636364 [1] 1.654883
Recloser
13.10.2017 13:54А в статье снова неувязка :) поменяйте тогда
yнаzво второй строчке.
(Простите, веткой выше нужно комментарий поставить)
vanxant
Терминологическая поправка: буржуйское population в смысле статистики на русском называется не популяцией, а генеральной совокупностью.
temujin Автор
Честно говоря меня тоже одолевали сомнения, хотелось в одно слово перевести.