
Перевод статьи Синди Шридхаран.
В этой статье автор собирается:
- Пролить свет на некоторые предполагаемые преимущества маленьких функций.
- Объяснить, почему некоторые из преимуществ вовсе не такие радужные, как рекламируется.
- Объяснить, почему маленькие функции иногда контрпродуктивны.
- Объяснить, в каких случаях маленькие функции действительно полезны.
Среди общих советов по программированию неизменно превозносятся элегантность и эффективность маленьких функций. В книге «Чистый код» — многими воспринимаемой в качестве библии программистов — есть глава, посвящённая одним лишь функциям, и она начинается с примера поистине ужасной, и к тому же длинной функции. И дальше в книге длина функции клеймится как самый страшный грех:
Функция не только длинная, она содержит дублирующий код, кучу непонятных строковых значений и много странных и неочевидных типов данных и API. Вы разобрались в ней после трёх минут изучения? Вероятно, нет. В ней происходит слишком многое и на слишком многих уровнях абстракции. Здесь непонятные строковые значения и странные вызовы функций перемешаны с выражениями if двойной вложенности, управляемыми флагами.
В той же главе кратко обсуждается, какие качества должны сделать код «простым в чтении и понимании» и «позволить случайному читателю интуитивно понять, какого рода программе они принадлежат», а потом заявляется, что для этого необходимо делать функции меньше.
Первое правило функций гласит, что они должны быть маленькими. Второе правило гласит, что функции должны быть ещё меньше.
Идея, что функции должны быть маленькими, считается практически священной и не подлежащей пересмотру. Она часто всплывает в ходе ревизий кода, в дискуссиях в Twitter, на конференциях, в книгах и подкастах, статьях про лучшие методики рефакторинга и так далее. И недавно эта идея выскочила в ленте в виде такого твита:
В моём Ruby-коде половина методов длиной всего в одну-две строки. 93% короче 10. https://t.co/Qs8BoapjoP https://t.co/ymNj7al57j
?—?@martinfowler
Автор приводит ссылку на свою статью о длине функций, в которой пишет:
Если при взгляде на фрагмент кода вы приложили усилия чтобы понять, что тут делается, значит вам нужно извлечь это в функцию и дать ей имя в честь этого «что».
Приняв для себя этот принцип, я выработал привычку писать очень маленькие функции — обычно длиной всего несколько строк [2]. Меня настораживает любая функция длиной больше пяти строк, и я нередко пишу функции длиной в одну строку [3].
Достоинства маленьких функций пропагандируются столь часто, что всего через несколько дней эта тема всплыла в виде такого твита:
Мне нравится часть совета @dc0d_
?—?@davecheney
Некоторые так озабочены маленькими функциями, что страстно отстаивают идею абстрагирования любой и каждой части номинально сложной логики в отдельную функцию.
Нам приходилось работать с кодовыми базами, написанными людьми, впитавшими эту идею до такой нечестивой степени, что конечный результат получился адским и полностью противоречащим всем добрым намерениям, которыми был вымощен путь. В этой статье мы хотим объяснить, почему некоторые из широко разрекламированных преимуществ маленьких функций не всегда соответствуют нашим надеждам, а иногда и вовсе контрпродуктивны.
Предполагаемые преимущества маленьких функций
В подтверждение достоинств маленьких функций обычно выкатывается ряд утверждений.
Делают что-то одно
Небольшая функция имеет больше шансов делать что-то одно. Примечание: Маленькая != Одна строка.
?—@davecheney
Идея проста: функция должна делать только что-то одно, и делать её хорошо. На первый взгляд звучит очень здраво, даже в некой гармонии с философией Unix.
Неясность возникает тогда, когда нужно определить «что-то одно». Это может быть что угодно, от простого выражения возвращения до условного выражения, части математического вычисления или сетевого вызова. Как это часто бывает, «что-то одно» означает один уровень абстракции какой-то логики (обычно бизнес-логики).
Например, в веб-приложении «чем-то одним» может быть CRUD-операция вроде «создания пользователя». При создании пользователя как минимум необходимо сделать запись в базе данных (и обработать все сопутствующие ошибки). Возможно, также придётся отправить человеку приветственное письмо. Более того, кто-то ещё захочет инициировать специальное сообщение в брокере сообщений вроде Kafka, чтобы скормить событие другим системам.
Получается, что «один уровень абстракции» вовсе не один. Некоторые программисты, безоговорочно принявшие идею, что функция должна делать «что-то одно», с трудом сопротивляются стремлению рекурсивно применять этот принцип к каждой своей функции или методу.
Так что многие из них не могут остановиться, пока не сделают функцию полностью DRY и модульной — а это никогда не получается идеально
?—?@copyconstruct
То есть вместо разумной и непоколебимой абстракции, которую можно понять (и протестировать) как один элемент, мы создаём ещё более мелкие элементы, из которых формируются все компоненты «чего-то одного», пока это одно не станет полностью модульным и полностью DRY.
Ошибочность DRY
DRY is one of the most dangerous design principl?(34) floati?(25) a?(28)und ?(29)t ?(13)?(27)e to?(22)y
?—?@xaprb
DRY не обязательно синоним пристрастия делать функции как можно меньше. Но я много раз наблюдал, как второе приводит к первому. Я считаю, что DRY хороший ориентир, но очень часто прагматизм и разум кладутся на алтарь догматического следования этому принципу, в особенности программистами с Rails-убеждениями.
У Реймонда Хеттингера, одного из основных разработчиков Python, есть фантастическое выступление Beyond PEP8: Best practices for beautiful, intelligible code. Его нужно посмотреть не только Python-программистам, а вообще всем, кто интересуется программированием или зарабатывает им на жизнь. В нём очень проницательно разоблачены недостатки догматического следования PEP8 — руководству по стилю в Python, реализованному во многих линтерах. И ценность выступления не в том, что оно посвящено PEP8, а в ценных выводах, которые можно сделать, многие из которых не зависят от конкретного языка.
Посмотрите хотя бы одну минуту из выступления, во время которой рисуется пугающе точная аналогия с коварным зовом DRY. Программисты, настаивающие на широчайшем применении DRY, рискуют за деревьями не увидеть леса.
Главный недостаток в DRY – это принуждение к абстракциям, вложенным и преждевременным. Поскольку невозможно абстрагироваться идеально, нам приходится делать это неплохо, в меру своих сил. При этом нельзя дать точное определение, насколько должно быть «неплохо», это зависит от многих факторов.
На этом графике термин «абстракция» можно заменить на «функцию». Например, прикидывая, как лучше всего спроектировать уровень абстракции А, можно продумать:
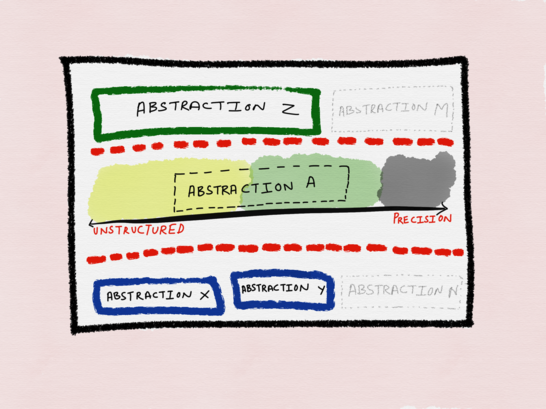
- Характер предположений, лежащих в основе абстракции А, какова вероятность (и длительность) того, что они будут логичными.
- Склонность уровней абстракций, лежащих в основе абстракции А (X и Y), а также базирующихся на ней (Z), оставаться согласованными, гибкими и корректными в реализации и проектировании.
- Каковы требования и ожидания в отношении любых будущих абстракций выше (М), или ниже абстракции А (N).
Разрабатываемая нами абстракция А неизбежно будет постоянно пересматриваться, вплоть до частичного или полного отказа. Поэтому основополагающим свойством нашей абстракции, которая неизбежно будет модифицироваться, должна быть гибкость.
И если мы прямо сейчас начнём при любой возможности использовать принцип DRY, то лишим себя в будущем этой гибкости, способности адаптироваться к любым возможным изменениям. Что нам действительно нужно сделать, так это дать себе немного свободы вносить неизбежные изменения, которые потребуются рано или поздно, а не начинать сразу же строить идеальное решение.
Лучшая абстракция — та, что оптимизируется достаточно, а не идеально. Это фича, а не баг. Необходимо понять эту важнейшую особенность абстракций, чтобы успешно их проектировать.
У Алекса Мартелли, придумавшего фразу «утиная типизация» (duck-typing) и знаменитую Pythonista, есть выступление под названием The Tower Of Abstraction; почитайте эти слайды из презентации:


У известной рубистки Сэнди Метц есть выступление All The Little Things, в котором она постулировала, что «дублирование гораздо дешевле неправильной абстракции», а значит нужно «предпочесть дублирование неправильной абстракции».
Я считаю, что абстракции вообще не могут быть «правильными» или «неправильными», потому граница между этими понятиями нечеткая и вечно меняется. Нашу тщательно выпестованную «идеальную» абстракцию от статуса «неправильной» отделяет лишь одно бизнес-требование или отчёт об ошибке.
Мне кажется, абстракцию нужно воспринимать как некий диапазон, как на графике выше. Один край диапазона — это оптимизация с точки зрения точности, в то время как абсолютно все аспекты нашего кода нужно оптимизировать до состояния абсолютной точности. Но лучшее — враг хорошего: стремление к идеалу не поможет спроектировать хорошие абстракции, поскольку требует идеального соответствия. Другая часть нашего спектра — это оптимизация с точки зрения неточности и отсутствия границ. И несмотря на максимальную гибкость, у этого подхода есть свои недостатки.
Иногда для конкретного контекста есть лишь ОДНО идеальное решение. Но контекст может в любое время измениться, как и идеальное решение https://t.co/ML7paTXtdu
?—?@copyconstruct
Как и в большинстве случаев, «идеал» находится где-то посередине. Не существует универсального идеального решения. «Идеальность» зависит от множества факторов — программистских и межличностных, — и хороший разработчик должен уметь распознать, где находится «идеальная» точка спектра для каждого контекста, и постоянно переоценивать этот идеал.
Имена
После решения, что и как мы абстрагируем, важно дать абстракции имя.
А именовать трудно.
В программировании считается прописной истиной, что давать длинные, описательные имена — это хорошо, причём некоторые выступают за замену комментариев в коде на функции, имена которых представляют собой комментарии. Смысл в том, что чем более описательное имя, тем лучше инкапсуляция.
и наконец именование. Фоулер с друзьями выступают за описательные имена,
такЧтоМыСделалиИменаКакЭтоКоторыеОченьТрудноЧитать
?—?@copyconstruct
Возможно, это прокатывает в мире Java, где многословие в порядке вещей. Но код с такими именами трудно читать. При чтении кода такие слепки из кучи слов вводят меня в лёгкий ступор, пока я пытаюсь выделить все эти слоги в имени функции, встроить её в мысленную модель, которая к тому моменту сформировалась у меня в голове, а затем решить, стоит ли перейти к определению функции и изучить её реализацию.
Но с «маленькими функциями» другая проблема: погоня за ними приводит к тому, что маленьких функций становится ещё больше, и у всех многословные имена ради отказа от комментариев и самодокументированности кода.
И меня сильно утомляет осмысление многословных имён функций (и переменных), встраивание их в мысленную модель, решение, какие изучить подробнее, а какие пропустить, и наконец сложение всех кусочков мозаики в единую картину.
Чем меньше функции, тем больше их и их имён. Лучше я буду читать код, а не имена функций.
?—?@copyconstruct
Я считаю, что ключевые слова, конструкты и идиомы, предлагаемые языком программирования, визуально воспринимаются гораздо легче, чем придуманные имена переменных и функций. Например, когда я читаю блок
if-else, то редко вдумываюсь в if или elseif, тратя больше времени на осмысление логики работы программы.И мне неприятно, когда ход моих мыслей нарушается чем-то вроде
aVeryVeryLongFuncNameAndArgList. Особенно если вызываемая функция состоит из одной строки и легко могла быть инлайнена. Контекстные переключения не дёшевы, неважно, процессорные это переключения, или программисту приходится мысленно переключаться, читая код.Ещё одно следствие избытка маленьких функций, особенно с очень описательными и неинтуитивными именами — труднее искать по кодовой базе. Функцию
createUser грепать просто, а функцию renderPageWithSetupsAndTeardowns (это имя взято в качестве яркого примера из книги Clean Code), напротив, не так просто запомнить или найти. Многие редакторы поддерживают нечёткий поиск по кодовой базе, поэтому избыток функций с похожими префиксами наверняка приведёт к очень большому количеству результатов в выдаче, что трудно назвать идеалом.Потеря локальности
Лучше всего маленькие функции работают тогда, когда для поиска определения функции нам не нужно покидать пределы файла или границы пакета. С этой целью в книге Clean Code предлагается так называемое Правило понижения (The Stepdown Rule).
Нам нужно, чтобы код читался как связное повествование. Нам нужно, чтобы за каждой функцией следовали другие функции на следующем уровне абстракции, чтобы по мере чтения списка функций мы последовательно опускались по уровням абстракции. Я называю это Правилом понижения.
В теории звучит прекрасно, но я редко видел, чтобы это работало на практике. Напротив, когда в код добавляется много функций, почти неизменно теряется локальность.
Предположим, что мы начали с трёх функций А, В и С, которые вызываются (и читаются) друг за другом. Изначально наши абстракции подкреплялись определёнными предположениями, требованиями и оговорками, которые мы усердно исследовали и аргументировали в начале проектирования.

Довольно скоро у нас появилось непредвиденное новое требование, пограничный случай или ограничение. Нужно модифицировать функцию А, поскольку инкапсулированное в ней «что-то одно» больше не подходит (или изначально не подходило и теперь требует исправления). В соответствии с советами из Clean Code мы решили, что лучше всего создать новые функции, в которые спрячем новые требования.
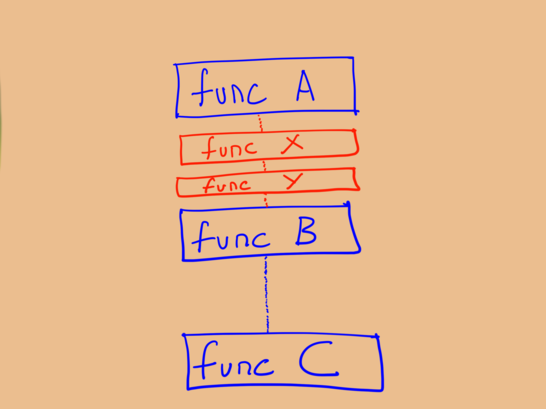
Пару недель спустя концепция снова поменялась и нам приходится создавать дополнительные функции для инкапсулирования дополнительных требований.
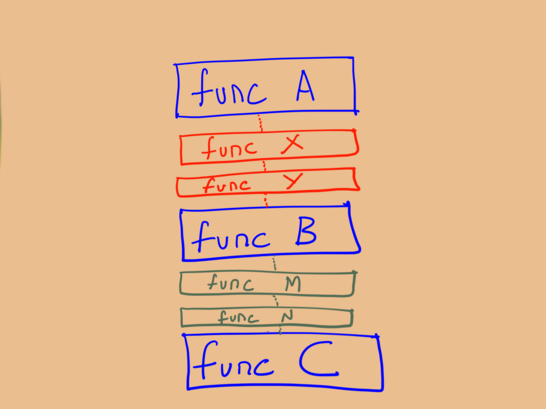
Вот мы и пришли к той самой проблеме, описанной Сэнди Метц в её статье The Wrong Abstraction. Там говорится:
Существующий код оказывает мощное воздействие. Самим своим существованием он утверждает свою корректность и необходимость. Мы знаем, что код отражает вложенные в него усилия, и мы очень не хотим их обесценить. Но, к сожалению, истина такова, что чем сложнее и непредсказуемее код, то есть чем больше мы в него вкладываем, тем больше ощущаем необходимость сохранить его («ошибка невозвратных затрат»).
Возможно, это верно для команды, изначально работавшей над кодовой базой и продолжающей её поддерживать, но встречались противоположные ситуации, когда базой начинают владеть новые программисты (или руководители). То, что начиналось с благих намерений, превращается в спагетти-код, который уж точно невозможно назвать чистым и который всё сильнее хочется реорганизовать или переписать целиком.
Кто-то скажет, что это в определённой степени неизбежно. И будет прав. Мы редко говорим о том, как важно писать код, который будет умирать постепенно (graceful death). Раньше я уже писал о том, как важно, чтобы код можно было легко вывести из эксплуатации, а для самой кодовой базы это ещё важнее.
+1. Нужно оптимизировать код, чтобы он умирал постепенно. В этом должен был помочь принцип открытости/закрытости, но не получилось
?—?@copyconstruct
Программисты слишком часто считают код «мёртвым» только в том случае, если он удалён, больше не используется или сам сервис выключен. Если же код, который мы пишем, будем считать умирающим при каждом добавлении нового Git-коммита, то это может побудить нас писать код, удобный для модифицирования. Если думать о том, как лучше абстрагировать, то это сильно помогает осознать тот факт, что создаваемый нами код может умереть (быть изменённым) уже через несколько часов. Так что куда полезнее делать код удобным для модифицирования, чем пытаться выстроить повествование, как это советуется в Clean Code.
Загрязнение классами
В языке, поддерживающем ООП, с уменьшением функций увеличивается размер или количество классов. Мы видели, как в случае с Go это приводило к разрастанию интерфейсов (в сочетании с интерфейсным загрязнением) или большому количеству мелких пакетов.
Это усугубляет когнитивные нагрузки при сопоставлении бизнес-логики с нашими абстракциями. Чем больше классов/интерфейсов/пакетов, тем труднее разобраться со всем этим одним махом, и ничто не оправдывает затраты на поддержание всех этих построенных нами классов/интерфейсов/пакетов.
Меньше аргументов
Приверженцы маленьких функций почти неизменно стремятся передавать им меньше аргументов.
Проблема в том, что из-за этого возрастает риск сделать зависимости неявными.
Кроме того, при использовании в языках с наследованием, вроде Ruby, это приводит к сильной зависимости функций от глобального состояния и синглтонов
?—?@copyconstruct
Мне встречались в Ruby классы с 5-10 маленькими методами, каждый из которых делал что-то очень простое и брал в качестве аргументов один-два параметра. Многие из этих методов изменяют общее глобальное состояние или зависят от неявно передаваемых им синглтонов, что можно расценить как антипаттерн.
Кроме того, при неявности зависимостей сильно усложняется тестирование, в придачу к трудностям настройки и сброса состояния перед каждым тестом наших крошечных функций.
Трудно читать
Я уже говорил об этом выше, но стоит напомнить: многочисленные маленькие функции, особенно длиной в одну строку, чрезмерно затрудняют чтение кодовой базы. Особенно это вредит новичкам, для которых код и должен быть оптимизирован в первую очередь.
Черты «новичка в кодовой базе»: 1. и правда новичок 2. ветеран другой подсистемы 3. исходный автор
?—?@sdboyer
прочие факторы, которые надо учесть — 1) новичок в языке программирования 2) новичок во фреймворке (rails, django и так далее) 3) новичок в организационном стиле
?—?@copyconstruct
Есть несколько видов новичков в кодовой базе. Лучше всего иметь в команде кого-то, способного проверить ряд категорий этих «новичков». Это помогает мне пересмотреть свои предположения и непреднамеренно навязанные мной какому-то новичку трудности при первом прочтении кода. Я понял, что этот подход действительно помогает сделать код лучше и проще, чем при противоположном подходе.
Простой код необязательно легче в написании, и в нём вряд ли будет применён принцип DRY. Нужно потратить кучу времени на обдумывание, уделить внимание подробностям и постараться прийти к самому простому решению, одновременно верному и лёгкому в обсуждении. Самое поразительное в этой труднодостижимой простоте, что такой код одинаково легко понимают и старые, и новые программисты, что бы ни подразумевалось под «старыми» и «новыми».
«Новичку» в кодовой базе, если ему повезло и он уже знает используемый язык и/или фреймворк, то самое трудное для него — понять бизнес-логику или подробности реализации. А если не повезло и приходится прокладывать путь сквозь кодовую базу на незнакомом языке, то главной проблемой будет пройти по канату между достаточным пониманием языка/фреймворка, чтобы можно было без затруднений понять, что делает код, и способностью выделить «что-то одно» и понять, как проработать это настолько, чтобы проект перешёл на следующую стадию.
И вряд ли в подобных ситуациях часто бывало так, что вы смотрите на незнакомую кодовую базу и думаете:
О, посмотрите на эти функции. Такие маленькие. Такие DRY. Такие прекраааааааасные.
Когда рискуешь заходить на неизведанные территории, то надеешься лишь, что придётся сделать как можно меньше мысленных скачков и переключений контекста, пытаясь найти ответ на вопрос.
Если об абстракции трудно рассуждать (или приходится ломать голову там, где в этом нет нужды), то оно того не стоит.
?—?@copyconstruct
Трата времени и сил на упрощение кода ради тех, кто будет в будущем его сопровождать или использовать, будет иметь огромную отдачу, особенно для open source-проектов.
Когда маленькие функции действительно полезны
Несмотря на всё сказанное, маленькие функции могут быть полезны, особенно при тестировании.
Сетевой ввод-вывод
Ага, расскажи мне, как всё хорошо работает, когда ты запускаешь пару десятков сервисов с разными dbs и зависимостями на своём macbook.
?—?@tyler_treat
Кроме того, большие интеграционные тесты, охватывающие многие сервисы, являются антипаттерном, но убеждать в этом людей до сих пор бесполезно.
?—?@tyler_treat
Не будем рассказывать, как лучше всего писать функциональные, интеграционные и модульные тесты для множества сервисов. Но когда речь заходит о модульных тестах сетевого ввода-вывода, то на самом деле ничего не тестируется.
Разгон и обрушение базы данных/очереди ради модульного тестирования может быть плохой идеей, но излишне усложнённые заглушки/фальшивки гораздо хуже.
?—?@copyconstruct
Не стоит быть фанатом заглушек. У них несколько недостатков. Начнём с того, что заглушки — искусственная симуляция какого-то результата. Они хороши не больше, чем позволяет наше воображение и возможность предсказать разные виды сбоев, с которыми может столкнуться приложение. Скорее всего, работа заглушек не совпадает с реальным сервисом, который они замещают, если только вы тщательно не протестируете каждую из них на соответствие. К тому же заглушки работают лучше всего, когда каждая из них в единственном экземпляре и каждый тест использует одну и ту же заглушку.
Тем не менее, заглушки всё ещё практически единственный способ модульного тестирования сетевого ввода-вывода. Мы живём в эру микросервисов и аутсорсинга вендору большинства (если не всех) проблем, не относящихся к ядру нашего основного продукта. Многие функции ядра приложения используют от одного до пяти сетевых вызовов, и при модульном тестировании лучше всего вместо этих вызовов использовать заглушки.
В целом, заглушки нужно применять только в минимальном количестве кода. Когда API вызывает почтовый сервис, чтобы отправить нашему свежесозданному пользователю приветственное письмо, нужно установить HTTP-соединение. Изолирование этого запроса в наименьшей возможной функции позволит в тестах имитировать заглушкой наименьший кусок кода. Обычно это должна быть функция не длиннее 1-2 строк, которая устанавливает HTTP-соединение и возвращает с ответом любую ошибку. То же самое относится к публикации события в Kafka или к созданию нового пользователя в БД.
Тестирование на основе свойств
Учитывая, что тестирование на основе свойств (property based testing) приносит невероятную выгоду с помощью такого небольшого кода, оно используется преступно мало. Впервые такой вид тестирования появился в Haskell-библиотеке QuickCheck, а потом был внедрён другие языки, например в Scala (ScalaCheck) и Python (Hypothesis). Тестирование на основе свойств позволяет в соответствии с определёнными условиями генерировать большое количество входных данных для какого-то теста и гарантировать его прохождение во всех этих случаях.
Многие тестовые фреймворки заточены под тестирование функций, и потому имеет смысл изолировать до одной функции всё, что может быть подвергнуто тестированию на основе свойств. Это особенно пригодится при тестировании кодирования или декодирования данных, либо для тестирования парсинга JSON/msgpack, и тому подобного.
Заключение
DRY и маленькие функции — это не обязательно плохо (даже если это следует из лукавого заголовка). Но они вовсе не обязательно хороши.
Количество маленьких функций в кодовой базе, или средняя длина функций — не повод для хвастовства. На конференции 2016 Pycon было выступление под названием onelineizer, посвящённое одноимённой программе, способной конвертировать любую программу на Python (включая саму себя) в одну строку кода. Об этом забавно рассказать перед слушателями на конференции, но глупо писать production-код в той же манере.
По словам одного из лучших программистов современности:
профессиональный совет в Go: не следуйте слепо догматическому совету, всегда руководствуйтесь своим мнением.
?—?@rakyll
Это универсальный совет, не только для Go. Сложность программ, которые мы создаём, значительно возросла, а ограничения, с которыми мы сталкиваемся, стали более разнообразными, поэтому программисты должны соответствующим образом адаптировать свое мышление.
К сожалению, ортодоксальное программирование всё ещё сильно влияет на умы с помощью книг, написанных во времена царствования ООП и «шаблонов проектирования». Многие из пропагандируемых идей и практик не подвергались сомнению в течение десятилетий и срочно требуют пересмотра. Особенно потому, что в последние годы ландшафт и парадигмы программирования сильно эволюционировали. Ходя старыми тропами, программисты становятся ленивее и погружаются в ощущение самоуверенности, которое они вряд ли могут себе позволить.
Комментарии (159)

genamodif
27.10.2017 11:49Главное не размер, а умение им пользоваться.

AntonAlekseevich
27.10.2017 12:31Была бы у меня возможность поставить +1 поставил бы за хорошую мысль.

f0rk
27.10.2017 13:48Неудачная попытка.
AntonAlekseevich
27.10.2017 16:56Я и не просил.
Просто сказать уже нельзя?
MaximChistov
27.10.2017 17:28Если бы не просили, написали бы просто «+1»
AntonAlekseevich
27.10.2017 17:45"+1" слишком коротко.
Но без "Была бы у меня возможность ...", согласен, выглядело бы лучше.
Но это уже стало бы требованием.

AndreyMtv
27.10.2017 12:52Вкусовщина какая то. Не нравится имена функций читать ей.
Основания для выделения куска кода в отдельную функцию — реализуется логически законченный процесс И данный код будет использован повторно. Оба условия обязательны. Если это одноразовый код, то выделять его в отдельную функцию можно временно для целей тестирования.
Ну и функции из одной строки это очевидный бред, до такого маразма конечно не стои опускаться.
Fesor
27.10.2017 13:37Оба условия обязательны.
То есть вы никогда кусок кода в приватный метод/функцию в контексте модуля не выносили для увеличения читабельности и снижения когнитивной нагрузки на читателя?
То что вы обозначили может быть причиной для введения новой абстракции, а функции дробить в пределах модуля — как считаете удобнее так и делайте. Главное что бы это было кохизив и со связанностью проблем небыло.
AndreyMtv
27.10.2017 14:03Для повышения чтабельности достаточно просто написать комментарий к коду. Это и полезнее будет.
Free_ze
27.10.2017 14:12Чем вам название функции не комментарий?
Это и полезнее будет.
Пищеварение улучшается и шерстка лоснится?
Bonart
27.10.2017 14:14Комментарий хуже выделения метода.
Его видит только человек, а не компилятор и не IDE.
Его актуальность очень легко утрачивается.
Неактуальный комментарий намного хуже отсутствующего.AndreyMtv
27.10.2017 14:20Компилятору на читабельность вашего кода вообще фиолетово. Можете хоть спагетти код писать. Если он будет без ашипок, компилятор это вролне устроит.
Bonart
27.10.2017 15:27- На любые ошибки в комментариях (в отличие от кода) компилятору ультрафиолетово.
- Комментария в стеке вызовов никогда не будет.
- Метод по имени найти намного проще, чем комментарий (особенно с помощью IDE)
alex_zzzz
27.10.2017 16:45-1- Актуальность имён функций утрачивается так же легко, и они так же легко врут.
- Комментарий может отсутствовать, а имя функции не может.
- Комментарии в длине не ограничены, а от длины имени функции зависит удобство её использования. Но чем короче имя функции, тем больше шансов, что оно что-то утаивает.
Fesor
27.10.2017 17:49+1а от длины имени функции зависит удобство её использования.
если ваша функция слишком длинная и скажем имеет в своем названии
Andэто признак того что оно делает слишком много.
Докблоки перед функцией никто к слову не отвечал если функция покрывает какую-то сложную концепцию или вычисления нуждающиеся в разъяснениях.
Идея "дробления" ближе к open/close принципу — методы должны соблюдать SRP просто потому что тогда больше шансов что вместо изменения имеющейся функции мы создадим новую. При этом у нас будет новое название функции.
В целом комментарии как правило создают лишнюю когнитивную нагрузку. Но не всегда конечно.
alex_zzzz
28.10.2017 21:38если ваша функция слишком длинная и скажем имеет в своем названии And это признак того что оно делает слишком много.
Ну делает и делает, это не повод её дробить. Есть другие причины для дробления ? пожалуйста. Упрощение тестирования, например. Нет других причин ? оставьте бедную функцию в покое.
В целом комментарии как правило создают лишнюю когнитивную нагрузку. Но не всегда конечно.
Я лишние функции не создают нагрузку разве?
Вот есть операция из пяти стадий, которые выполняются друг за другом и друг без друга не работают. Бьёшь большую функцию на пять маленьких и одну управляющую и получаешь в исходнике шесть артефактов вместо одного. Поди потом помни и объясняй всем, зачем они нужны и в каком порядке их правильно вызывать. Как бонус, в большой функции её интимные локальные данные были скрыты от посторонних взглядов, а теперь эти детали реализации торчат наружу в виде аргументов.
Только не надо говорить, что это не проблема. В C# для её решения сделали локальные функции.
Fesor
28.10.2017 22:46Ну делает и делает, это не повод её дробить.
Не повод конечно, это скорее как кандидат на дробление, но дробить, как вы верно подметили, нужно когда в этом виден смысл.
Я лишние функции не создают нагрузку разве?
если у вас блок с кодом и там есть пара строк которые вы хотите отдельно отметить комментарием — мы будем читать все-равно все эти три строчки. Далее чем больше блок который мы хотим отдельно выделить в контексте кода комментарием, тем больше вероятность что нам будет выгоднее вынести весь этот блок как отдельную функцию, тем самым устранив необходимость фильтровать информацию читателю.
Поди потом помни и объясняй всем, зачем они нужны и в каком порядке их правильно вызывать.
у вас будет одна публичная функция и 5 приватных. Потому знания о том что в каком порядке будет вызываться будут сокрыты.
Только не надо говорить, что это не проблема. В C# для её решения сделали локальные функции.
Это по сути и есть "приватные" функции. Можно так же объявить замыкания и дать пояснение тому что они делают при помощи переменной.
alex_zzzz
30.10.2017 16:16Далее чем больше блок который мы хотим отдельно выделить в контексте кода комментарием, тем больше вероятность что нам будет выгоднее вынести весь этот блок как отдельную функцию, тем самым устранив необходимость фильтровать информацию читателю.
В результате линейная последовательность операций получается записанной в исходнике нелинейно. И читателю (в т.ч. нам в будущем) приходится прыгать взад-вперёд по исходнику, чтобы восстановить в голове полную картину происходящего.
Если есть другие причины бить большую функцию на мелкие, кроме её размера, ? бей; не других причин ? оставь как есть, не порть.
у вас будет одна публичная функция и 5 приватных.
Или была одна приватная, стало шесть приватных, одинаковых с виду. Сразу весело.
Потому знания о том что в каком порядке будет вызываться будут сокрыты.
Не понял. Если я читаю исходник, мне не надо, чтобы логика работы была скрыта, мне надо, чтобы всё было кристально прозрачно. Если же я простой потребитель публичного API, то мне пофиг на исходник и как оно там внутри написано.
Это по сути и есть "приватные" функции. Можно так же объявить замыкания и дать пояснение тому что они делают при помощи переменной.
Вероятно, имелись в виду лямбда-функции. Но в любом случае ты понимаешь, что некоторая проблема есть, и чрезмерное количество мелких функций небесплатно с точки зрения поддержки.
Fesor
30.10.2017 17:06В результате линейная последовательность операций получается записанной в исходнике нелинейно.
Не совсем верно. У вас выходит разделение большой задачи на задачи поменьше. Есть общее описание задачи, где все разделено на этапы, и есть отдельные этапы. Те могут дробиться так же, в зависимости от того нужно это или нет.
Я не знаю. может быть мы с вами по разному код читаем, но я предпочитаю идти "сверху вниз" а не пытаться сначала прочитать все исходники на самом мелком уровне а уже потом пытаться воспроизвести в голове картину.
Или была одна приватная, стало шесть приватных, одинаковых с виду. Сразу весело.
что значит "одинаковых свиду"?
Не понял. Если я читаю исходник, мне не надо, чтобы логика работы была скрыта, мне надо, чтобы всё было кристально прозрачно.
Предположим у нас есть юзкейс, который затрагивает довольно много всего. Вы бы хотели прочитать все исходники относящиеся к этому юзкейсу или хотели бы, что бы весь сценарий был описан в одном месте с которого можно было бы спуститься чуть ниже с точки зрения детализации?
Если же я простой потребитель публичного API
Просто думайте так, как если бы вы всегда были просто потребителем публичного API. Даже когда это API разрабатываете вы.
Вероятно, имелись в виду лямбда-функции.
Bonart
29.10.2017 01:39+1Вот есть операция из пяти стадий, которые выполняются друг за другом и друг без друга не работают.
Бьёшь большую функцию на пять маленьких и одну управляющую и получаешь в исходнике шесть артефактов вместо одного.6 артефактов по 15 строк лучше одного из 90.
Поди потом помни и объясняй всем, зачем они нужны и в каком порядке их правильно вызывать.
Зачем объяснять? Параметры функций, их возвращаемые результаты и тело управляющей функции все скажут за вас.
Более того, все пять стадий и зависимости между ними станут явными и будут выражены непосредственно в коде, а не в ваших комментариях.
Как бонус, в большой функции её интимные локальные данные были скрыты от посторонних взглядов, а теперь эти детали реализации торчат наружу в виде аргументов.
Как будто что-то плохое.
Управляющая функция имеет ту же сигнатуру, что и исходная — ее детали наружу не торчат.
Аргументы стадийных функций отражают данные, необходимые для каждого этапа большого процесс.
И как бонус — вы можете переиспользовать стадийные функции в другом варианте большого процесса.
Только не надо говорить, что это не проблема. В C# для её решения сделали локальные функции.
Локальные функции шарпа сделаны совсем по другой причине. Это всего лишь сахар для тех случаев, когда лямбды не очень удобны (рекурсия и т.п.).
Druu
29.10.2017 12:01> 6 артефактов по 15 строк лучше одного из 90.
На практике, одна функция на 90 строк часто читается в несколько раз быстрее, чем 6 функций по 15.
Эти ф-и по 15 строк могут просто не выполнять какого-либо действия, которое было бы осмысленным вне общего алгоритма, в итоге вам точно так же надо будет выстроить 90-строчную ф-ю, чтобы понять, что именно делает та или иная ф-я по 15. Только сделать это надо будет в уме, на что, конечно, будет потрачено лишнее время.
fogone
29.10.2017 14:18На практике, одна функция на 90 строк часто читается в несколько раз быстрее, чем 6 функций по 15.
Если функции сделаны прилично, то вместо 90 строк обычно нужно прочесть одну из 6 и потом еще 15 (в случае, если нужны детали реализации), а то и верхнего уровня достаточно бывает. Даже не знаю, что быстрее прочесть 90 строк или 21?
Эти ф-и по 15 строк могут просто не выполнять какого-либо действия, которое было бы осмысленным вне общего алгоритма
Строки которые не содержат никакого законченного осмысленного действия, не нужно выносить в функцию, это написано в любой книге, где может упоминаться негативное влияние размера на удобство чтения и изменения. Только эта статья почему-то размышляет о функциях в контексте их размера, хотя как тут уже много раз замечали, размер лишь симптом плохо спроектированной функции, но не всегда является причиной для дробления. Опыт подсказывает, что для сложной логики бывает, что последовательность вполне равноправных действий может занимать существенное количество строк. Речь скорее о ста, чем о тысячи, конечно, второй случай с почти сто процентной вероятностью это плохой дизайн или последствия оптимизаций (этот случай обычно отмечается специальными комментариями, чтобы не было соблазна «привести в порядок», но случай очень редкий).Druu
29.10.2017 15:37> Строки которые не содержат никакого законченного осмысленного действия, не нужно выносить в функцию
Но многие, между тем, так делают, бездумно следуя неким принципам.
> Только эта статья почему-то размышляет о функциях в контексте их размера, хотя как тут уже много раз замечали, размер лишь симптом плохо спроектированной функции, но не всегда является причиной для дробления.
Статья размышляет не о функциях, статья размышляет о программистах, которые часто подвержены карго-культу и делают действия, смысла которых не понимают. Сказали человеку: «дроби ф-и так, чтобы не больше 10 строк в каждой» — и будет дробить, даже тогда, когда код из-за этого становится нечитаемым. А сделаешь замечание — то сошлется на то, что: «так Х сказал в книжке Y, и вообще это хорошая практика, везде так написано». Вы правда ни разу не встречались с такой ситуацией, когда люди выделяют ф-и _исключительно_ по той причине, что «чтобы не было длинно»?Fesor
29.10.2017 15:51Но многие, между тем, так делают, бездумно следуя неким принципам.
Принципы на то и придуманы что бы ими руководствоваться осмысленно. А то что вы описываете это больше похоже на культ карго и да, это очень большая проблема увы. Собственно вы ниже об этом упомянули.
fogone
29.10.2017 21:14Возможно меня забросают тряпками натерпевшиеся от этих, которые всё бьют и бьют, но вот ни разу не сталкивался с этим в таком масштабе, чтобы это было проблемой. Кто-то сделал не очень удачную композицию, на ревью обсудили. Сам нашел в своем коде неудачное решение, перегруппировал, разделил. А вот так, чтобы приходишь, а весь код в нелепых однострочных функциях — такого вот не видал.
Fesor
29.10.2017 14:46На практике, одна функция на 90 строк часто читается в несколько раз быстрее, чем 6 функций по 15.
без конкретных примеров это даже обсуждать нет смысла.
Эти ф-и по 15 строк могут просто не выполнять какого-либо действия, которое было бы осмысленным вне общего алгоритма
тогда чем вы руководствовались выделяя функции именно таким образом?
Druu
29.10.2017 15:46> тогда чем вы руководствовались выделяя функции именно таким образом?
Очевидно, что каким-нибудь дурацким правилом вроде: «не писать ф-й длиннее 15 строк».
Bonart
29.10.2017 18:08На практике, одна функция на 90 строк часто читается в несколько раз быстрее, чем 6 функций по 15.
В вашей практике — верю. В моей таких случаев не встречалось.
Эти ф-и по 15 строк могут просто не выполнять какого-либо действия, которое было бы осмысленным вне общего алгоритма
Заранее об этом точно не известно. Априорный прогноз с высокой вероятностью будет ошибочным.
в итоге вам точно так же надо будет выстроить 90-строчную ф-ю, чтобы понять, что именно делает та или иная ф-я по 15.
Мне этого не потребуется. Сигнатуры функций дадут понять, зачем написана каждая из них. Общая структура будет ясно читаться из тела управляющей функции. И только для выяснения деталей реализации той и иной стадии мне потребуется лезть глубже.
В вашем комментарии есть одно неявное предположение: тело функции читается лучше ее вызова (имя-параметры-результат).
Между тем, критерий выделения блока кода в функцию прямо противоположный: это есть смысл делать тогда и только тогда, когда вызов функции читается лучше ее тела.
И этот критерий точно выполняется для алгоритма, который уже разбит на пять стадий с явными связями между ними.
Никакие ограничения на размер функции и число артефактов в критерии не фигурируют, следовательно "слишком маленьких" функций не бывает, как и "слишком много" артефактов.michael_vostrikov
29.10.2017 18:33когда вызов функции читается лучше ее тела
Так вопрос не в том чтобы прочитать, а в том, чтобы понять алгоритм целиком. Когда в функцию вынесено "подключение к базе данных", это нормально. Это логически законченное действие, которое мы можем вызывать или не вызывать в других местах. А когда в функцию вынесено "первая часть вычисления SHA1", это только увеличивает когнитивную нагрузку, если надо найти почему SHA1 считается неправильно.
Bonart
29.10.2017 19:00Так вопрос не в том чтобы прочитать, а в том, чтобы понять алгоритм целиком.
Сложный алгоритм целиком гораздо проще понять, когда он декомпозирован с назначением имен и явных связей между шагами.
А когда в функцию вынесено "первая часть вычисления SHA1", это только увеличивает когнитивную нагрузку, если надо найти почему SHA1 считается неправильно.
У SHA1 есть точная спецификация. И от разбиения на функции в соответствии с этой спецификацией (включая имена из предметной области алгоритма) когнитивная нагрузка только снизится.
Когда в функцию вынесено "подключение к базе данных", это нормально.
Подключение к базе данных — это другой уровень абстракции, тут уже не просто функцию, а полноценный формальный контракт выделять надо.
michael_vostrikov
29.10.2017 20:11Ну например вот (30 строк) или вот (60 строк), а шаг вычисления вот (200 строк). Как бы вы разбили этот код на функции? И как правильные названия этих функций помогут понять, в какую надо лезть глубже, если у нас где-то используется неправильная битовая операция?
fogone
29.10.2017 21:32+1В другом комментарии писал о том, что оптимизации это совершено отдельная тема и к ним очень сложно применить правила хорошего кода, потому что их смысл часто как раз в том, чтобы увеличить производительность за счет не очень красивых приемов вроде разворачивания циклов.
michael_vostrikov
29.10.2017 21:40Так я же про обратный процесс спрашиваю)
fogone
30.10.2017 18:16Не понимаю, честно говоря, зачем вы предлагаете причесывать оптимизированный код? И вообще сути дискуссии не могу уловить — все отлично всё понимают, что размер тут оказался камнем преткновения, хотя суть только в том, чтобы сделать монструозные функции более читаемыми, изменяемыми и вообще приятными глазу. Это применимо для разросшегося метода бизнес-логики или для ситуации, когда есть смысл вынести какой-то процесс в отдельную абстракцию, но оптимизированные функции делать более приятными глазу никто не будет — их специально сделали такими, чтобы они работали быстрее и не вижу смысла пытаться проворачивать фарш обратно.
michael_vostrikov
30.10.2017 19:42Дискуссия, да и сама статья, появилась потому что многие считают, что разделение на маленькие функции всегда делает код понятнее, а это не так.
их специально сделали такими, чтобы они работали быстрее
В чем принципиальная разница с разросшимся методом бизнес-логики? Почему его можно разбить на функции, а заинлайненный для оптимизации код нельзя? Речь ведь не идет о сохранении скорости.
И подскажите, какие оптимизации вы имеете в виду, которые там кардинально на что-то влияют?
Bonart
30.10.2017 20:32Дискуссия, да и сама статья, появилась потому что многие считают, что разделение на маленькие функции всегда делает код понятнее, а это не так.
Статья появилась по старому доброму принципу "кто умеет — делает, кто не умеет — учит".
И декларируется в ней миф о вреде маленьких функций.
На деле же от маленьких функций самих по себе никакого вреда нет, а от больших — есть.
разделение на маленькие функции всегда делает код понятнее
Это ваш тезис, никак не вытекающий из всей предыдущей дискуссии. Более того, выше в этой же ветке, я прямо писал, что "это (выделение функции) есть смысл делать тогда и только тогда, когда вызов функции читается лучше ее тела."
В чем принципиальная разница с разросшимся методом бизнес-логики? Почему его можно разбить на функции, а заинлайненный для оптимизации код нельзя? Речь ведь не идет о сохранении скорости.
Для SHA1 у меня нет никакого желания реверсить код по ссылке. Я уже не раз объяснил почему и что именно я буду с ним делать. И маленьких функций в реализации будет много — спецификация дает формулы и имена для операций всех уровней.
Принципиальная разница в следующем — когда я только написал большой метод, у меня есть понимание как именно он работает, какие зависимости содержит, как лучше их назвать.
Когда есть большой легаси метод, по которому прошло множество правок и оптимизаций, выделение той или иной ответственности в функцию требует реверс-инжиниринга, и, возможно, переписывания с нуля.
Это далеко не бесплатно, поэтому декомпозицию на подзадачи крайне желательно проводить сразу, как только осознается само наличие выделенной ответсвенности, а не когда код уже превратился в спагетти.
Конечно, в программировании конфетку можно сделать из любого легаси, но лечение и здесь многократно дороже профилактики.michael_vostrikov
31.10.2017 00:34На деле же от маленьких функций самих по себе никакого вреда нет
Есть. Реализация размазывается. Нужно делить до некоторого уровня, но не меньше. Уровень определяется логической завершенностью функции, а не числом строк.
разделение на маленькие функции всегда делает код понятнее, а это не так
Это ваш тезис, никак не вытекающий из всей предыдущей дискуссии.Предыдущая дискуссия началась с категоричного высказывания "6 артефактов по 15 строк лучше одного из 90". Я привел пример, когда это не так. И в других ветках говорил так же. Почему вдруг он стал с ней не связан?
тогда и только тогда, когда вызов функции читается лучше ее тела
Так проблема не в том чтобы прочитать, а в том чтобы понять работу алогритма. У функции может быть емкое понятное название, только оно не поможет понять, почему она работает неправильно.
Я уже не раз объяснил почему и что именно я буду с ним делать.
Вы сказали, что сделаете правильно и понятно, только примера не привели, даже в псевдокоде.
Когда есть большой легаси метод, по которому прошло множество правок и оптимизаций
Нет там таких правок и оптимизаций, которые запутали бы исходный алгоритм. Был тезис, что если есть длинный код на 90 строк, то его лучше разбить на функции по 15 строк. Вот есть код, только разбить его не получается.
у меня есть понимание как именно он работает
Вот, а у другого человека нет. И чтобы понять, ему придется прыгать по всем мелким функциям, собирая все в одну картину.
Bonart
31.10.2017 01:18Есть. Реализация размазывается. Нужно делить до некоторого уровня, но не меньше.
Этот тезис противоречит вот этому:
Уровень определяется логической завершенностью функции, а не числом строк.
Т.е. вы сами же признаете, что логически завершенная функция может быть сколь угодно малого размера. Ограничением является выразительность вызова по сравнению с телом, а не какой-то пороговый минимальный размер.
Следовательно, в маленьких функциям самих по себе ничего плохого нет.
Предыдущая дискуссия началась с категоричного высказывания "6 артефактов по 15 строк лучше одного из 90".
Ничего что высказывание сделано в определенном контексте и является ответом на реплику ниже?
Вот есть операция из пяти стадий, которые выполняются друг за другом и друг без друга не работают.
Бьёшь большую функцию на пять маленьких и одну управляющую и получаешь в исходнике шесть артефактов вместо одного.Сам автор кода осознает, что его функция делится на пять стадий со связями между ними.
В этом случае преимущество разбиения на шесть меньших функций очевидно.
Вы вычеркнули контекст, добавили квантор всеобщности и получившуюся химеру подвергли критике. Но это ваша химера, я ничего подобного в виду не имел.
Пожалуйста, читайте диалог полностью, ничего не вырезая и не добавляя от себя к высказываниям собеседников.
michael_vostrikov
31.10.2017 08:08Этот тезис противоречит вот этому
Т.е. вы сами же признаете, что логически завершенная функция может быть сколь угодно малого размера.Нет там противоречия. Логическая завершенность может занимать любое количество строк. "До некоторого уровня, но не меньше" с числом строк не связано. Собственно, второе предложение и поясняет, что означает слово "уровень".
Я говорил следующее:
"далеко не всегда мелкие функции приводят к легко понимаемому коду. А по таким комментариям кажется, что всегда."
"Метод isActive() из одной строки вполне нормально выглядит. А скажем такой код уже не очень."
Я спорю с категоричностью высказывания, а не с существованием мелких функций.
Ничего что высказывание сделано в определенном контексте
Сам автор кода осознает, что его функция делится на пять стадий со связями между ними.Так в том-то и дело, что стадии можно выделить везде. В любой из приведенных реализаций функция sha1_update делится на стадии. Только если разбить, станет более запутанно.
Квантора всеобщности там бы не было, если бы вы или кто-то из собеседников привели конкретный пример. Но они говорят о "часто" или "бывает", допуская оба варианта, а вы о "лучше" и "не встречалось".
Fesor
31.10.2017 11:56по таким комментариям кажется, что всегда.
вы же уже оба пришли к тому что вся проблема в слове "маленькая", и что "размер" просто не количеством строк характеризуется.
Bonart
29.10.2017 22:23Я взял бы спецификацию из RFC3174
И реализовал по функции на каждую операцию.
По вашим ссылкам весьма агрессивная низкоуровневая оптимизация. Там я бы сохранил удобочитаемый код в качестве опорной реализации и оптимизированный для релиза (с комментариями в виде хорошо читаемого эквивалента).
если у нас где-то используется неправильная битовая операция
У вас функции тестами покрыты? Такого рода ошибки обычно хорошо ломают юнит-тесты. SHA1 по спецификации разбит на простые операции, которые очень удобно покрывать тестами.
michael_vostrikov
29.10.2017 23:53Ага, "я бы сделал хорошо и понятно")
По вашим ссылкам весьма агрессивная низкоуровневая оптимизация.
Ну и что? Вопрос как раз в обратном, как сделать тот код более понятным. Так что это наоборот подходит для примера.
Такого рода ошибки обычно хорошо ломают юнит-тесты
Ну вот сломался тест на главную функцию sha1(), и что? Скажем, по первой ссылке не будет 2 последних строчек с рекурсией, или плюс вместо минуса в середине. Как узнать, где именно ошибка? Для этого надо понять весь алгоритм, скрытый за абстрактными названиями функций.
Bonart
30.10.2017 01:21Ага, "я бы сделал хорошо и понятно")
Имея RFC сделать "хорошо и понятно" в данном случае несложно (оптимально по производительности не обещаю).
Учтите что на си я сроду не писал.
Ну вот сломался тест на главную функцию sha1(), и что?
А не главные у вас тестами покрыты?
Для этого надо понять весь алгоритм, скрытый за абстрактными названиями функций.
А зачем? Надо открыть RFC (алгоритм там уже есть) и сравнить реализации функций с ним, планомерно покрывая тестами еще не покрытое.
michael_vostrikov
30.10.2017 12:10Учтите что на си я сроду не писал.
Так речь не идет о компилируемом варианте. Просто примерно показать, как вынести код в функции. Обсуждение же о рефакторинге кода из 90 строк, а не о написании с нуля.
А не главные у вас тестами покрыты?
А не главные отрабатывают нормально. Я же указал, где ошибка. Какие тесты можно сделать, чтобы ее поймать?
Надо открыть RFC (алгоритм там уже есть) и сравнить реализации функций с ним
А там такие функции и есть, по 30-60 строк, разве что циклы не развернуты. Они не разбиты на стадии.
И да, на бизнес-логику RFC с алгоритмом нет, с чем вы будете сравнивать?Bonart
30.10.2017 12:32Просто примерно показать, как вынести код в функции.
На сишном коде, оптимизированном до полной нечитаемости?
Для которого уже есть точная спецификация?
Нафига козе баян?
Проще написать самому с нуля или взять готовую реализацию без явных косяков.
По ссылке довольно симпатичная:
https://github.com/git/git/blob/master/block-sha1/sha1.c
В вашей постановке задача не имеет смысла, а слово "просто" надо сразу брать в кавычки: низкоуровневые оптимизации по производительности не имеют ничего общего ни с декомпозицией, ни с читаемостью.
И да, на бизнес-логику RFC с алгоритмом нет, с чем вы будете сравнивать?
А бизнес-логика ничего общего с криптокодом из openssl не имеет.
И да, на сложную бизнес-логику спецификации очень даже пишутся.michael_vostrikov
30.10.2017 13:19По ссылке довольно симпатичная
Код
blk_SHA1_Update()принципиально ничем не отличается от реализации по моей первой ссылке, там тоже 30 строк. Ок, пусть будет эта, как бы вы ее разбили на стадии?
низкоуровневые оптимизации по производительности не имеют ничего общего ни с декомпозицией, ни с читаемостью.
Причем здесь оптимизация? Я же про обратный процесс спрашиваю. Вы говорите, что если есть длинный код, то надо разбить его на мелкие функции, потому что так понятнее. Непонятный оптимизированный код как раз хороший кандидат для применения этого подхода, разве нет? Речь же не идет о том, чтобы сохранить скорость работы.
А бизнес-логика ничего общего с криптокодом из openssl не имеет.
А в чем разница? Есть конкретная реализация вычислений, которая занимает много строк. Вы говорите, что такой код лучше разбивать на маленькие функции для повышения понятности. Я прошу вас показать, а вы начинаете говорить про готовые алгоритмы и переписывание с нуля. То есть такой подход работает не всегда, о чем я и сказал.
И да, на сложную бизнес-логику спецификации очень даже пишутся.
Спецификации пишутся, а готовых функций там нет. Чтобы найти, где код отличается от спецификации, надо понять, что и как он делает. То есть важна не абстракция, а детали реализации.
Bonart
30.10.2017 15:18Причем здесь оптимизация? Я же про обратный процесс спрашиваю.
Декомпозиция — способ реализовать функциональные требования максимально удобным и понятным способом.
Низкоуровневая оптимизация — изменение кода с целью реализации нефункциональных требований с учетом специфики транслятора и среды исполнения.
В коде, подвергнутом такой оптимизации, размер функций и их наличие определяется совсем не соображениями понятности, а только стоимостью с точки зрения производительности (или потребления ресурсов).
Качество такого кода по любому другому критерию может быть ниже всякой критики.
Если у вас сломался оптимизированный на низком уровне код — ищите коммит, где это произошло и разгребайте лапшу.
Непонятный оптимизированный код как раз хороший кандидат для применения этого подхода, разве нет?
Выделение функций в таком спагетти само по себе как мертвому припарки. Так что пример с оптимизированной реализацией SHA1 заслуживает приставки "анти".
Я с таким сталкивался. Иногда самым быстрым способом исправления был реверс алгоритма по коду с последующим переписыванием с нуля. Найти ошибку в исходном варианте было сложнее.michael_vostrikov
30.10.2017 17:36В коде, подвергнутом такой оптимизации, размер функций и их наличие определяется совсем не соображениями понятности, а только стоимостью с точки зрения производительности (или потребления ресурсов).
Но я ведь не прошу написать такой код. Я прошу сделать наоборот — убрать оптимизацию и сделать размер и наличие функций по соображениям понятности. Потому и пример известный выбрал, на который есть описание требований, не писать же полное ТЗ в комментарии.
Выделение функций в таком спагетти
Но ведь это просто код, не разбитый на стадии. Там наоборот нет никакого спагетти из мелких функций. И каких-то больших низкоуровневых оптимизаций нет, за исключением развернутых вычислений по третьей ссылке. На PHP или Java будет примерно то же самое.
Ок, я понял, примера применения подхода не будет.
Bonart
30.10.2017 17:51Там наоборот нет никакого спагетти из мелких функций.
Видите ли, сам термин "спагетти-код" относится как раз к непонятному коду внутри больших функций. "Спагетти из мелких функций" — это ваше изобретение, не знаю как оно выглядит.
Я прошу сделать наоборот — убрать оптимизацию и сделать размер и наличие функций по соображениям понятности.
Вы хотите чтобы за вас оптимизированный код отрефакторил кто-то другой на незнакомом ему языке? И хотите на таком примере делать выводы о пользе маленьких функций?
Это при наличии готовой спецификации и кучи готовых реализаций?
На PHP или Java будет примерно то же самое.
Фортрановскую программу можно написать на любом языке программирования.
Ок, я понял, примера применения подхода не будет.
Лучший путь деоптимизации предложенного вами кода — выкинуть его в мусорку и написать реализацию в лоб по RFC.
Там, кстати, получается множество однострочных функций.michael_vostrikov
30.10.2017 19:30Видите ли, сам термин "спагетти-код" относится как раз к непонятному коду внутри больших функций.
Тем более, это ведь именно тот случай, который предлагается исправить разбиением на функции.
Вы хотите чтобы за вас оптимизированный код отрефакторил кто-то другой на незнакомом ему языке? И хотите на таком примере делать выводы о пользе маленьких функций?
Вас же не смущает псевдокод или незнакомый язык в учебниках от известных авторов. Этот пример ничем не отличается от того кода, который предлагается разбивать на функции. Есть ТЗ, есть длинный код.
Это при наличии готовой спецификации и кучи готовых реализаций?
Именно потому что есть спецификация и другие реализации. Потому что известны требования и можно сравнить, что понятнее.
Там, кстати, получается множество однострочных функций.
Хорошо, можете привести свой вариант реализации? На любом языке.

ApeCoder
30.10.2017 19:07Там есть комменты, которые разбивают
1) Эту функцию на на куски
2) Описывают взаимосвязи между кусками типа
/*
- Where do we get the source from? The first 16 iterations get it from
- the input data, the next mix it from the 512-bit array.
*/
Вопрос,
1) почему эти взаимосвязи нельзя выразить явно в коде? Будет ли от этого понятней?
2) Есть ли какое-то предназначение у раундов?
3) Как это все было разработано? Что было в голове у автора и как он взял все эти числа? Нельзя ли это выразить конструкциями языка. Я не спец в крипто — вы можете побыть доменным экспертом?michael_vostrikov
30.10.2017 19:481) Хм, как бы вы выразили в коде описанное в комменте?
2) Раунд это одна итерация вычисления.
3) Это константы из описания алгоритма.ApeCoder
30.10.2017 21:481) var array = first_16_iterations(inputData)…
2) Чем они друг от друга отличаются? Там есть еще итерации внутри раундов. Есть у них какое-то предназначение?
3) Как появилась эта константа и почему она именно такая?
Т.е. вы понимаете смысл того, что там или фактически выполняете работу компилятора, перенося код из книжки на C и оптимизируя его?
michael_vostrikov
31.10.2017 00:501) Там примерно так и написано
#define T_0_15(t, A, B, C, D, E) SHA_ROUND(t, SHA_SRC, ...) #define T_16_19(t, A, B, C, D, E) SHA_ROUND(t, SHA_MIX, ...)
2) Раунд это понятие предметной области. В SHA_ROUND нет итераций, только битовые операции.
3) Это лучше спросить у разработчиков, придумавших SHA1.
Я никакой код на С не пишу и к приведенным ссылкам отношения не имею.
ApeCoder
31.10.2017 09:241) Это не так же — неявно что есть вход что выход
2) С точки зрения авторов кода раунд так же что-то состоящее из итераций.
/ Round 1 — iterations 0-16 take their input from 'block' /
3) То есть мы не понимаем смысла манипуляций там. Как мы тогда можем утверждать, что от разбиения на куски код станет непонятнее? Надо понять алгоритм — что там зачем и почему и тогда можно сделать функции с читаемыми названиями.
michael_vostrikov
31.10.2017 12:291) Предложите свой вариант. Только полный, а не одну абстрактную функцию без тела.
2) Не знаю, почему они так написали, в описании ясно сказано — состоит из 80 раундов.
3) Почему не понимаем. Константы это ТЗ. Неважно в какой функции они будут находиться.
Надо понять алгоритм — что там зачем и почему
И-и вот мы снова к этому пришли. Чтобы что-то изменить в незнакомом алгоритме, надо его понять.
Хороший пример кстати с комментарием. Автор явно использовал слово раунд в смысле отличном от текущего ТЗ, при том что SHA_ROUND названо правильно. Так как это пример, обозначающий некую бизнес-логику, можно предположить вариант, когда в предыдущей версии ТЗ раундом называлась группа из 20 шагов, а потом поменяли. Сильно бы помогло найти несоответствие, если бы вместо комментария было название функции, да еще спрятанное куда-нибудь в performIterations()?
alex_zzzz
30.10.2017 17:40Зачем объяснять? Параметры функций, их возвращаемые результаты и тело управляющей функции все скажут за вас.
Вижу шесть приватных функций. Нашёл, что одна из них вызывает другие. Ок, с ней понятно.
Остальные пять ? одни делают какую-то общую работу и не имеют смысла друг без друга, или логически независимы и используются или могут использоваться где-то ещё?
Если я удаляю за ненадобностью главную функцию, эти пять можно тоже удалить? IDE могут помочь это выяснить, но не точно и невсегда удобно. Если я таки удалю все функции и ничего не сломается, может всё-таки не стоило удалять ? вдруг был расчёт переиспользовать их функционал? Не зря же их кто-то (или я сам) выделил в отдельные функции.
А если не удалю, получится мёртвый код, который вроде есть, но вроде нигде не используется. Хрен знает, как он тут появился, зачем нужен и что с ним делать.
Более того, все пять стадий и зависимости между ними станут явными и будут выражены непосредственно в коде, а не в ваших комментариях.
Ну и стоило ли ломать зависимости, чтобы потом их восстанавливать? Цепочка действий и так была прекрасно обозначена в исходной функции. Зачем последовательность превращать во множество, чтобы потом из множества опять собирать последовательность? Явные зависимости, если уж есть, завсегда понятнее неявных.
Управляющая функция имеет ту же сигнатуру, что и исходная — ее детали наружу не торчат.
Мы ведь про пишущих/читающих исходники говорим, а не про стороннего пользователя, который видит только публичный API. К такому стороннему пользователю вся эта тема вообще не имеет отношения.
Под "наружу" я имею в виду сигнатуры функций.
Когда есть одна большая функция, у неё все кишки, все детали реализации внутри. Свернул функцию и кишок не видно. Надо изменить логику ? внутри функции изменил, снаружи никто не заменил.
А когда большая операция искусственно раздроблена на мелкие части, изменение внутри одной часто влечёт изменение в других. У одной изменились выходные параметры ? меняй входные у другой. Изменения серьёзнее ? переписывай другие функции целиком. Инкапсуляция близка к нулю.
Аргументы стадийных функций отражают данные, необходимые для каждого этапа большого процесс.
Нет смысла фиксировать детали реализации в сигнатурах функций. Сигнатура ? это контракт, который функций «обещает» выполнить неважно каким способом. И тот контракт видится как нечто более стабильное, чем внутренности. А при искусственном делении оказывается, что не контракт влияет на реализацию, а наоборот.
И как бонус — вы можете переиспользовать стадийные функции в другом варианте большого процесса.
Когда/если это понадобится, тогда можно будет озаботиться. Опыт показывает, что с большой вероятностью не понадобится.
Bonart
30.10.2017 17:59IDE могут помочь это выяснить, но не точно и невсегда удобно.
И точно, и удобно. По крайней мере для языков со статической типизацией.
Цепочка действий и так была прекрасно обозначена в исходной функции.
Неправда. Попробуйте определить как зависит строка 86 большой функции от строки 3. И вот здесь IDE вам скорее всего никак не сможет помочь — придется интерпретировать в голове все тело большой функции.
Нет смысла фиксировать детали реализации в сигнатурах функций.
Гораздо приятнее каждый раз перечитывать тело большой функции при каждом сколь угодно мелком ее изменении.
А при искусственном делении оказывается, что не контракт влияет на реализацию, а наоборот.
Отсутствие навыка декомпозиции — не повод от нее отказываться.
Опыт показывает, что с большой вероятностью не понадобится.
Конечно не понадобится: из тела большой функции после многих правок что-то выделить и переиспользовать сложнее, чем задублировать функциональность по месту.
alex_zzzz
31.10.2017 13:21И точно, и удобно. По крайней мере для языков со статической типизацией.
Удобно ? это когда присутствует CodeLens. Точно ? это когда отсутствует рефлексия. В C# никогда не приходилось расставлять атрибуты [UsedImplicitly]? Как-то перестаёшь после этого доверять показаниям IDE. Умом-то понимаешь, что всё, скорее всего, нормально, но вероятность, что после удаления «ненужного» где-то что-то нае*нётся, есть всегда. Причём эта низкая вероятность компенсируется неочевидностью причины и тяжестью последствий.
По поводу остального: Не надо думать, что если функция большая, то у неё внутри лапша. Забористую лапшу можно лепить и из мелких. Лапша ? проблема, размер ? не проблема и даже не источник.
ApeCoder
30.10.2017 19:12Если я удаляю за ненадобностью главную функцию, эти пять можно тоже удалить? IDE могут помочь это выяснить, но не точно и невсегда удобно.
Можно безо всякого IDE, если языке поддерживает вложенные функции
private static string GetText(string path, string filename) { var sr = File.OpenText(AppendPathSeparator(path) + filename); var text = sr.ReadToEnd(); return text; // Declare a local function. string AppendPathSeparator(string filepath) { if (! filepath.EndsWith(@"\")) filepath += @"\"; return filepath; }alex_zzzz
31.10.2017 13:37Ещё они спасают от мусора в Intellisense и красиво решают одну проблемку с лямбдами. Остаётся проблема нелинейности: код читается не как простой текст сверху вниз, а прыжками туда-сюда.
ApeCoder
29.10.2017 22:40Вот есть операция из пяти стадий, которые выполняются друг за другом и друг без друга не работают.
Если вам о ней удобно думать, как о разбитой на пять стадий, а не на 90, почему бы это разбиение не выразить явно в коде?
alex_zzzz
30.10.2017 17:49-1Ну да, пустой строкой и комментарием с названием следующей стадии.
ApeCoder
30.10.2017 19:15Почему не объяснить компилятору, дебаггеру и IDE, что это отдельные стадии, какие переменные используются только внутри стадии, а какие используются для передачи значения между ними? Дебаггер и стектрейс покажет вам на какой стадии вы находитесь, компилятор проконтроллирует, что вы случайно не переиспользовали переменную не предназначенную для этого.
И профайлер вам покажет, сколько какая стадия жрет ресурсов
alex_zzzz
31.10.2017 13:56Почему не объяснить компилятору, дебаггеру и IDE, что это отдельные стадии,
Им эта информация не нужна. Отладчик, профайлер и стектрейсы всё могут показывать с точностью до номера строки ? так оно намного интереснее. Номер строки точно указывает, где проблема, а остальной стектрейс лишь объясняет, каким путём мы сюда попали.
Но повторюсь, если есть другие причины разбивать большую функцию, кроме её размера, то можно и разбить. Нет причин ? не надо бить, это небесплатно.
AndreyMtv
27.10.2017 14:17Дополню. Естественно программы состоят из множества функций и вовсе не обязательно каждая из них используется повторно. Мой комментарий относится к "мелким, маленьким" функциям, нижнему уровню абстракции, что бы не скатиться к маразму однострочных функций.
Fesor
27.10.2017 15:12давайте так, вы пишите в коде
else? Как часто?
p.s. как размер функции относится к уровню абстракции?
AndreyMtv
27.10.2017 15:38Давайте так, мы все еще обсуждаем статью или вы уже о чем то другом хотите поговорить?
Вопрос стоит ребром, стоит ли вот эти несколько строк выделять в отдельную функцию или нет? Чем мы должны руководствоваться? По мне так, что бы не скатиться ни в одну из крайностей мало больших функций/однострочные функции достаточно двух правил, которые, я озвучил выше. Мало функций так же плохо, как и слишком много.Fesor
27.10.2017 16:33мы все еще обсуждаем статью или вы уже о чем то другом хотите поговорить?
мы обсуждаем ваше категоричное:
Основания для выделения куска кода в отдельную функцию — реализуется логически законченный процесс И данный код будет использован повторно. Оба условия обязательны.
Чем мы должны руководствоваться?Здравым смыслом, разумеется. В целом цели которые мы приследуем выделяя какой-то код в отдельные функции:
- упрощение кода для восприятия, потому что код чаще читают чем пишут
- устранение деталей, дабы можно было быстро глянуть общий флоу и если нас интересует конкретная деталь флоу — уже погружаться внутрь.
- самодокументируемый код
достаточно двух правил, которые, я озвучил выше.
и мы придем к следующей проблеме:
- интерпретация "использование повторно"
- логически законченный процесс
Мало функций так же плохо, как и слишком много.
High cohesion, low coupling. Основы структурного дизайна. 45 лет уже прошло. А мы все еще оперируем понятиями "маленький", "большой", "много", "мало", "логически законченный"...
p.s. ответьте на вопрос. Используете ли вы if в коде, существуют ли у вас "большие" блоки условий, или вы выделяете этот код в отдельные функции?
AndreyMtv
27.10.2017 17:17Используется повторно, как и логически законченный это однозначность, а вот упрощение для восприятия это как раз интерпритация. Каждый будет вертеть эту упрощение в свою сторону.
If использую. Блоки выделяю по необходимости, без фанатизма.Fesor
27.10.2017 17:51Используется повторно, как и логически законченный это однозначность
Тогда почему так много интерпритаций этих однозначных понятий?
soomrack
28.10.2017 12:26> High cohesion, low coupling. Основы структурного дизайна. 45 лет уже прошло. А мы все еще оперируем понятиями «маленький», «большой», «много», «мало», «логически законченный»…
Ну так 45 лет не для всех прошло :).
Я руководствуюсь принципами выделения кода в функцию:
1. Если код решает задачу, которую нужно решить еще в другом месте программы. Важно отметить, что это не следует из одинаковости кода! Код может быть одинаков, но решать разные задачи, в этом случае его не стоит выносить в отдельную функцию.
2. Уровень абстракции. Если для достижения уровня абстракции, на котором написан код требуется разделить его на функции, то это необходимо сделать. Обычно уровень абстракции на уровне модуля не меняется (если нужно поменять, значит стоит писать несколько модулей и объединять их в пакет).
Довольно часто это просто следствие написания алгоритма в псевдокоде:
1. если чайник не пустой -> вылить_чайник
2. налить_чайник
3. поставить_чайник_на_плиту
4. включить_плиту
5. если чайник кипит -> выключить_плиту
Butylkus
28.10.2017 14:24Я использую if-elif-else. И вызываю по условиям функции самой разной длины.
Причём повторное использование вовсе необязательно. Скажем, у меня есть функции первичной конфигурации — создать базу данных (дефолтнейм), создать к ней пользователя(дефолтюзер), заполнить базу болванкой(дефолтдамп). Это выполняется единственный раз. Дальнейшая работа программы даже после сотого перезапуска уже не обратится к этим функциям.
Насколько плох такой подход?Fesor
28.10.2017 14:27И вызываю по условиям функции самой разной длины.
ну то есть вы блоки с кодом все же выделяете в отдельные функции что бы можно было просто блок с условиями прочитать как сценарий, "если это задано, то надо делать то-то, иначе делать то-то". Это я и имел ввиду, когда спрашивал про
elseвсякие. В этом случае одно из условий "выделения функции" озвученное выше не соблюдается (либо мы имеем дело с конфликтом терминологии). но при этом нам удобнее.
Насколько плох такой подход?
Ну если вам удобно, то видимо не плохо. Плюсы минусы — вам находить.
Butylkus
29.10.2017 06:49Но не стоило бы избавиться от этих функций, перенеся их логику в основную логику программы, чтобы проверяться при запуске? Ну то есть у меня:
def create_db(): some spam def create_user(): some eggs def dump_load(): take spam with eggs insert them into base while (stopflag == False): if (%no_base%): create_db() if (%no_user%): create_user() if (%no_tables%): dump_load() main_logic_continues
Не лучше ли развернуть описанное в одну линию?
Вот главный вопрос.
ApeCoder
27.10.2017 15:46https://martinfowler.com/bliki/FunctionLength.html
Once I accepted this principle, I developed a habit of writing very small functions — typically only a few lines long [2]. Any function more than half-a-dozen lines of code starts to smell to me, and it's not unusual for me to have functions that are a single line of code [3]. The fact that size isn't important was brought home to me by an example that Kent Beck showed me from the original Smalltalk system. Smalltalk in those days ran on black-and-white systems. If you wanted to highlight some text or graphics, you would reverse the video. Smalltalk's graphics class had a method for this called 'highlight', whose implementation was just a call to the method 'reverse' [4]. The name of the method was longer than its implementation — but that didn't matter because there was a big distance between the intention of the code and its implementation.
wawa
27.10.2017 15:27Основания для выделения куска кода в отдельную функцию — реализуется логически законченный процесс И данный код будет использован повторно. Оба условия обязательны.
Все-таки не соглашусь. Читая код функции я ожидаю, что каждая ее строка будет одного уровня абстракции с другими. И если какой-то одноразовый код выбивается из контекста этой ф-ции, выпуская кишки (нижние абстракции) наружу, лучше дать ему осмысленное имя, выделив в отдельную функцию, согласно контексту вызывающей стороны. И не важно один раз будет вызвана эта функция или нет.KoCMoHaBT61
27.10.2017 21:46Абстракции-абстракции…
Сейчас они нижние, а через час — херакс, верхние. Потому, что *надо*! Прикинь… Потому, что практика, инженерия, мать-её, а не филология и розовые пони.
@#$@ филологи-говнометарии даже в комитет по стандартизации С++ пролезли, и придумали private, protected и const. Ну и, мать-их, ссылки, ради детей…Fesor
28.10.2017 00:21+1Потому, что практика, инженерия, мать-её, а не филология и розовые пони.
Ну вот смотри, Петрович, мы стены поставили, перекрытие сделали, а потом вспомнили что нужен фундамент! Ну короч мы сверху жахнули все это дело, не пропадать же. Инженерия, едрить на лево!
KoCMoHaBT61
28.10.2017 08:08Не надо сравнивать материальную индустрию и программирование. Всегда так бывает, что проект меняется по всей высоте — и фундамент перекладывается, и воду в газовые трубы пускают.

Myxach
28.10.2017 10:27Ху*к, ху*к и в продакшен — хорошая методика только в краткосрочной перспективе или при создание прототипа, в долгосрочной — врёда от неё больше, чем от других
KoCMoHaBT61
28.10.2017 10:44Это не «ху*к-ху*к и в продакшен», а практика. Заметь, что практики не вводят странных филологических ограничений — питон, яваскрипт.
К вопросу коротких функций — всё хорошо в меру. Ничего плохого в цикле на два-три экрана с индентами на 10 позиций я не вижу, если это оправдано. Также ничего плохого нет в маленьких функциях, но тут уже работает филология.
Практическая часть… В одном проекте на Эрланге я встречал маленькие функции do1, do2, do3, do4, do5… Это было разделение одной большой функции do на маленькие с паттерн-матчингом. Так лучше-бы эти @#$@ написали одну большую функцию.
В проекте на С++, который разрабатывался лет 10 я встретил несколько маленьких функций convertLogicalToPhysical, convertPhysicalToLogical. Эти термины не употреблялись херову тучу лет и никто не знал что они означают, потому, что архитектура поменялась неузнаваемо. Я потратил часа 4 на то, чтобы понять, что за херня там написана, потом плюнул и написал длинный цикл с аналогами этих дебильных функций.
Такие дела.Fesor
28.10.2017 12:38Это не «хук-хук и в продакшен», а практика.
у нас с вами может быть разная практика. Вы описываете практику где недостает рефакторинга. Ну то есть не того рефакторинга когда все к чертям сносится и пилится с нуля, а когда "узнали как это лучше назвать — переименовали".
Словом мне остается непонятна эмоциональная подоплека вашего комментария.
KoCMoHaBT61
28.10.2017 13:01Не узнаешь ты никогда как это лучше назвать — человек, который это писал уволился 10 лет назад. Проект передали индусам, потом передали обратно, потом передали китайцам, потом передали русским, потом сменилась концепция и часть кода переписали… бла-бла-бла. Как в таких условиях поймать мысль неизвестного индуса? А никак. Поэтому пусть лучше мысль будет обширная, но одна :)
Fesor
28.10.2017 13:13и причем тут тема статьи? Отсутствие культуры разработки у тех кто писал код 10 лет назад плохо коррелируется с вопросом адекватного разделения кода на модули.

Bonart
27.10.2017 13:08Неясность возникает тогда, когда нужно определить «что-то одно».
Достаточно только понимать и принимать одну вещь: "что-то одно" может быть разным для разных людей, проектов и стадий одного проекта. К счастью, этот процесс
- Однонаправленный, т.е. однажды выделенная ответственность никуда не пропадает.
- Конечный — имеет пределом однострочник.
И дальше в книге длина функции клеймится как самый страшный грех
Совершенно верно: длина функции — страшный грех, ибо является самым простым и заметным индикатором множества потенциальных и уже реализованных проблем в коде.
Если человек (а не кодогенератор) оставляет после себя длинную функцию, то ему де-факто безразличны любые проблемы с его дальнейшим сопровождением.
Как это часто бывает, «что-то одно» означает один уровень абстракции какой-то логики (обычно бизнес-логики).
Нет, не означает. Введение уровней абстракции — это ограничения на зависимости между функциями.
И меня сильно утомляет осмысление многословных имён функций (и переменных), встраивание их в мысленную модель, решение, какие изучить подробнее, а какие пропустить, и наконец сложение всех кусочков мозаики в единую картину.
Здесь была злая шутка про связь национальности и стиля программирования автора статьи. Хорошо декомпозированная функция читается лучше, а если декомпозиция проведена плохо — это не повод отказываться от нее вообще, как предлагается в статье.
Напротив, когда в код добавляется много функций, почти неизменно теряется локальность.
На самом деле нет. Пока имя функции читается лучше, чем ее тело — с локальностью все очень хорошо.
Приверженцы маленьких функций почти неизменно стремятся передавать им меньше аргументов. Проблема в том, что из-за этого возрастает риск сделать зависимости неявными.
Это дезинформация в чистом виде. Неявные зависимости возникают совсем не от желания уменьшить число аргументов, а от готовности сделать это любой ценой.
Простой код необязательно легче в написании, и в нём вряд ли будет применён принцип DRY. Нужно потратить кучу времени на обдумывание, уделить внимание подробностям и постараться прийти к самому простому решению, одновременно верному и лёгкому в обсуждении. Самое поразительное в этой труднодостижимой простоте, что такой код одинаково легко понимают и старые, и новые программисты, что бы ни подразумевалось под «старыми» и «новыми».
Это точно: все одинаково легко понимают, что такой код — неподдерживаемый шлак.
Мне встречались в Ruby классы с 5-10 маленькими методами, каждый из которых делал что-то очень простое и брал в качестве аргументов один-два параметра. Многие из этих методов изменяют общее глобальное состояние или зависят от неявно передаваемых им синглтонов, что можно расценить как антипаттерн.
А вот за такое принято бить канделябрами. Изменять глобальное состояние плохо, только маленький размер методов здесь ни при чем.
Чем больше классов/интерфейсов/пакетов, тем труднее разобраться со всем этим одним махом, и ничто не оправдывает затраты на поддержание всех этих построенных нами классов/интерфейсов/пакетов.
Это очень вредная дезинформация. Разобраться в одном интерфейсе с 40 действительно очень просто — его надо выкидывать в мусорку сразу. Но поддерживать 40 интерфейсов с 1 методом в каждом намного проще.
Ларчик открывается просто — неважно, сколько у вас интерфейсов и классов, но важно, сколько зависимостей у каждого из них.
Пока это число невелико (0-3) — нет никаких проблем в навигации по сколь угодно большому графу программных объектов.
Итог: cтатья в целом — эталон крайне ядовитой демагогии, полезна для изучения именно в таком качестве.
Butylkus
30.10.2017 11:13Правильное замечание насчёт декомпозиции. Писал длиннючий конфигуратор с кучей свитчей (олдскульная навигация с выбором меню-подменю).
Я избавился от размножения запросов к БД по всему коду, но сляпал ОГРОМНУЮ функцию, которая работает с базой. Она занимает едва ли не половину всего кода, но по сути выполняет лишь одну задачу — переформатирует строку запроса (по шаблонам SQL) согласно полученным данным при вызове и собсно общается с сервером БД. Всё. Читается элементарно, не смотря на размер. Должен ли я дробить её на сотню однострочников типа БазоПаролеМенятор, БазоЮзероУдалятор, БазоПиноЦоколятор, БазоБазоСоздаватор, БазоКурсороВозвращатор, БазоПиноПереименоватор…?
Не думаю.
Я хоть и эникейщик, но вряд ли сильно заблуждаюсь в убеждении, что единственное реально важное правило при организации функции: KISS. Абстракция реального мира — дыхание. Я не считаю нужным осознавать, какими именно мышцами между какими именно рёбрами надо совершить контракцию и ретракцию, когда и насколько надо напрягать диафрагму, какой объём воздуха всасывать и какие альвиолы наполнять. Это ОДНА, пусть и большая, но монолитная функция на том уровне абстракции, на котором она и должна быть — просто не забывай вызывать эту функцию с нужной частотой и ты будешь жить.
Myxach
27.10.2017 13:24А нельзя делить функции и методы по двум правила «Это можно не делать, что бы работал следующий код» и «Это можно понадобиться где-то ещё», первое правило позволит выделить методы, а второе функции?

webkumo
27.10.2017 13:55+1Ещё одно следствие избытка маленьких функций, особенно с очень описательными и неинтуитивными именами — труднее искать по кодовой базе. Функцию createUser грепать просто, а функцию renderPageWithSetupsAndTeardowns (это имя взято в качестве яркого примера из книги Clean Code), напротив, не так просто запомнить или найти. Многие редакторы поддерживают нечёткий поиск по кодовой базе, поэтому избыток функций с похожими префиксами наверняка приведёт к очень большому количеству результатов в выдаче, что трудно назвать идеалом.
Когда же вы уже, наконец, перестанете грепать и начнёте пользоваться нормальным семантическим поиском? Да, в ряде языков эта задача осложнена хитровы… вернотостью конфигурации подключаемого кода, но не к месту помянутая вами "многословная" java хороша как раз тем, что контекст там строго специфицируется и семантический поиск выполняется легко и быстро. Что, кстати, позволяет писать имена проще:
например не.вычислитьРазмерЭтогоЯблока а Яблоко.вычислитьРазмер. И да, то самое "загрязнение классами" так же позволяет писать более конкретные вещи.
Приверженцы маленьких функций почти неизменно стремятся передавать им меньше аргументов.
Проблема в том, что из-за этого возрастает риск сделать зависимости неявными.И какие глобальные состояния соответствуют принципу "единственной ответственности" (single responsibility)? Т.е. из-за собственного нарушения контракта концепции вы объявляете концепцию плохой? Как-то странно мне это видеть.
Я уже говорил об этом выше, но стоит напомнить: многочисленные маленькие функции, особенно длиной в одну строку, чрезмерно затрудняют чтение кодовой базы.
Говорить можно много о чём. У кого-то вообще дислексия. Что с ними делать?
А функцию, содержащую проверку + вывод (которые можно тем же тернарным оператором запихнуть в одну строку) — я бы однострочной не называл. И да, бывает выгодно такие функции выделять, чтобы разгрузить чтение кода.
PS смешались в кучу люди-кони...
- ругаемся на DRY
- ругаемся на мелкие функции (и даже про это озаглавили)
- почему-то вдруг ругаемся на моки (а в том и идея модульного тестирования — что нам важно проверить текущий модуль, а не его взаимодействие с внешними!)
- ругаемся на ООП (да, это всё ещё модно)
- ругаемсяНаВыдуманныеПроблемыВысосанныеИзПальца (ну или актуальные для людей с дислексией… но в любом случае функция с именем, состоящим из более чем 3х слов — редкость, из более чем 5и слов — крайняя редкость)
При этом суть претензий: "фанатизм — это плохо". Ну супер, чо.
PS да, я вижу, что это перевод, но на медиуме я не зарегистрирован и толстому и зелёному автору оригинала ответить не могу.
absplush
27.10.2017 13:58Имена функций A, B, C, X и Y в примерах при рассуждении о понятности кода крайне сомнительны.
Как и догматичные цитаты с критикой других догм (у которых, кстати, все-таки есть более развернутая аргументация в книгах упомятуных авторов).
Конечно, однострочные функции часто являются не лучшей практикой, но критиковать на их основе весь принцип DRY странно. Повторы в коде, содержащие некую логику, которую интуитивно не хочется инлайнить, обычно говорят о неких сущностях или отношениях, скорее всего существующих сейчас в неявных понятиях.
Отсюда получается основной лейтмотив статьи, который уловил лично я и с которым не могу согласиться — дублируемый код хорошо легче подвергается изменениям и добавлению функцианальности, чем моделирование бизнеса через абстрации.

Gorthauer87
27.10.2017 13:59Логично выделять в функцию ту часть кода, которая используется в нескольких местах.
ivorobioff
27.10.2017 15:27Никогда не понимал программистов который не задумываясь начинают фанатически делать именно так как было сказано каким-то авторитетным программистом в книгах, блогах или еще где либо. Конечно, если кто-то более опытный что-то советует то бесспорно, к его советам надо прислушаться, но это не означает что надо везде, где надо или не надо делать все именно так как он сказал, даже не задумываясь, применим ли его подход конкретно в данном случае или нет, облегчает ли он работу или только усложняет.
Я не говорю что более опытный программист просто тупа прикалывается с джуниоров и дает им левые советы. Нет, просто более опытный программист подразумевает что его слушают/читают программисты способные мыслить, анализировать и у которых есть свое мнение, ну и чувство достоинства (если так можно сказать), и они сами смогут решить когда и в каких случаях советы сеньеров уместны а в каких абсурдны.
Насчет мелких функций, думаю что не стоит специально себе ставить цель писать только короткие функции и худые классы, и хоть ты тресни. Я лично считаю что это решается по ходу написания кода. Например, если ты видишь что тебе становится трудно разбираться в коде функции так как его слишком много и в ней присутствуют два или более сюжета (да, это как в кино, другими словами, идет параллельная обработка двух или более логических линий ), которые пересекаются между собой и так далее, то конечно, стоит создать несколько парочек новых функций и упростить этим себе жизнь.
vdshat
27.10.2017 16:05Как показал жизненный опыт нужно писать спецификацию, т.к. то что для тебя очевидно, для других может быть темный лес. Уровни и способы мышления у всех тоже разные.
Был случай как один сотрудник написал супер абстрактный фреймфорк для визардов, так им никто не смог пользоваться, т.к. для начала работы нужно было написать и рекцию на то или иное действие — полная абстракция

grossws
27.10.2017 17:21Spinning up and tearing down a database/queue
это не "Разгон и обрушение базы данных/очереди", а запуск и останов.
Sdima1357
27.10.2017 17:27-1Ответ в фотографии. Все вопрос вкуса и чувства меры. Все таки программирование немного искусство и советовать художнику не пользоваться фиолетовой краской по причине неестественности цвета… Программа должна быть красивой и понятной, остальное от лукавого. Впрочем видимо споры тупоконечников и остроконечников не утихают со времён Свифта и видимо никогда не утихнут :(
Fesor
27.10.2017 17:53+1Все таки программирование немного искусство и советовать художнику
может стоит пользоваться научным методом а не в художников играть?
Sdima1357
27.10.2017 18:15Одно другому не мешает. Научный метод не панацея, мозги включать все равно нужно. И согласитесь, есть программы которые просто красивы.( в смысле исходный код красив)
Fesor
27.10.2017 19:39Научный метод не панацея, мозги включать все равно нужно.
можете пояснить мысль? То есть "научный подход" == "выключены мозги"?
в смысле исходный код красив
до первого чейндж реквеста. А так в целом ни разу не видал такого. Ну либо это было моментами. Сегодня смотришь — красиво. Завтра — чернь какая-то. В целом нам не за код платят.
Sdima1357
27.10.2017 20:54«Нам не за код платят»
За результат конечно. Однако звучит забавно, программисту и не за код. Просто приятно писать хорошо и неприятно плохо, да и нечестно в конце концов наваливать мусор в коде, даже если его никто не увидит
«До первого реквеста»
Дизайн недоработан, спек не понят или не продуман или ещё 1001 причина
Научный подход… Вы знаете сколько мне пришлось прочитать бредокода написанного людьми его исповедующего. Причём чаще всего он использовался для отмазки, почему нет результата или он неудовлетворителен, что впрочем не отменяет случаев когда он был использован к месту
Впрочем Вы и сами со всем этим сталкивались
Насчёт сабжа. Зависит от назначения и области применения программы. Иногда лучше мелкие функции по 2—3 строки иногда понятней фунции в несколько сотен строк, правда так бывает редко. Впрочем, часто это просто вопрос вкусаFesor
28.10.2017 00:35Просто приятно
поймите, "красота" кода проявляется исключительно в способности с легкостью и минимальными рисками вносить изменения в систему.
Дизайн недоработан, спек не понят или не продуман или ещё 1001 причина
То есть если мы возьмем сферический проект где у нас есть четкое ТЗ, которое никогда не меняется, можно быстро и красиво запилить что-то и возможно даже это что-то будет красивым.
Но реальность такова что люди очень плохи в формулировании своих желаний. Более того, зачастую когда клиент хочет "кнопку и что бы она вот так вот делала", он на самом деле не кнопку хочет. А хочет проблему решить. И если мы проблемы не понимаем — 10 раз придется поменять что бы мы наконец пришли к чему-то нормальному.
Если на проекте более одного стэкхолдера, то поток изменений выходит уже весьма солидный. А существуют проекты настолько масштабные в плане заинтересованных лиц, что они могут даже не знать всей системы в целом (потому некоторые практикуют штуки типа event storming, что бы люди сначала между собой определились как что работает в их бизнесе). Ну и добавим сюда "новый бизнес", это когда мы вообще понятия не имеем что будем делать. Тут очень важно "быстро" подстраиваться.
Вся философия Agile движения (не та скрамная чушь а те люди что манифест составляли) построена на принципе "иногда больше думать не эффективно и нужно ставить эксперементы и собирать реальные данные".
Научный подход… Вы знаете сколько мне пришлось прочитать бредокода написанного людьми его исповедующего.
Вы под "научным подходом" подразумеваете "паттерны и принципы"? Научный подход подразумевает то, что вы ставите под сомнение общепринятые нормы и пытаетесь разобраться в фактах. Анализируете источники информации, делаете и главное проверяете предположения. А то что вы описали больше похоже на слепое следование каким-то правилам прочитанным в статях по типу "SOLID за 10 минут".
Я знавал ребят которые проектировали системы используя SOLID (да и я сам таким грешил какое-то время). Я только спустя время осознал что это в первую очередь инструмент для рефакторинга, а не проектирования. Причем работают они только при наличии потока изменений. Без этого потока сложно анализировать эффективность принимаемых решений. Это как предположения без проверки. Полная противоположность тех самых научных подходов.
Иногда лучше мелкие функции по 2—3 строки
опять же — вопрос не в количестве строк. Размер понятие относительное. Да и "хорошо" или "плохо" — не очень то инженерные понятия.
Sdima1357
28.10.2017 00:54Смотрите мы и не спорим. Просто я имел в виду «художник» в том смысле что разных программистов можно отличить по стилю, что свойственно скорее художникам или хорошим инженерам, чем ремесленникам, которые делают одинаковые гайки по техзаданию. Ещё раз «хорошо или плохо» это субъективный критерий однако все попытки дать численные критерии качества работы программистов пока заканчиваются неудачей или провалом организаций их использующих
Fesor
28.10.2017 13:17или хорошим инженерам, чем ремесленникам, которые делают одинаковые гайки по техзаданию.
вот инженер — это немного ближе к делу.
все попытки дать численные критерии качества работы программистов пока заканчиваются неудачей или провалом организаций их использующих
проблема не с метриками а их интерпритацией. Люди вводят простые метрики потому что на них проще ориентироваться, думать никто не хочет. Но только метрики и ограничения на них это не правила. Это скорее быстрый способ в общей массе находить потенциально интересные места на которых уже стоит человеку сосредоточить внимание а не тупо запрещать коммит.
Та же штука с покрытием кода тестами например. Ну пишет вам 100%, а мутационные тесты скажут что реальное покрытие 10%. Цель то этой метрики не в том что бы убедиться что все покрыто, а что бы быстро находить код вообще не покрытый тестами, и там уже решать, покрывать или нет.
Sdima1357
28.10.2017 14:26Давайте уточним о какой группе программистов мы дискутируем.?
Архитекторы, алгоритмисты, инженеры или кодеры. Все они пишут код больше или меньше. И требования к их коду и к ним самим все таки разные. И для какой области? Веб, игрушки или медицинское оборудование. Я работаю в последней больше 15 лет.Требования к надежности кода весьма высокие. Код просматривается неоднократно и разными людьми. Быстро писать не надо — надо надежно и понятно. Поэтому мне мой опыт сложно переносить в другие области, есть инерция мышления. И все равно я утверждаю, что хороший код должен вызывать эстетическое удовлетворение, как и картина или хорошая книга. В каком стиле пишет автор кода, мне без разницы, главное чтобы было понятно и прозрачно и если можно то и красиво
PerlPower
27.10.2017 20:25+1Я может что-то упустил, но пока в метологиях ИТ научным методом и не пахнет. Зато есть толпы кукарекающих евангелистов, каждый из которых истина в последней инстанции. Одна только существование идиомы «модный фреймворк» чего стоит.
Fesor
27.10.2017 20:41но пока в метологиях ИТ научным методом и не пахнет.
Что вы имеете ввиду под "методологиях ИТ"?
толпы кукарекающих евангелистов
Научный метод как раз и призван минимизировать эффект от "кукареканья", разве нет? Критическое мышление там, анализ фактов и т.д.
Одна только существование идиомы «модный фреймворк» чего стоит.
Мода есть везде и на все. Это к вопросу о том что люди чаще всего работают в рамках чего-то общепринятого и редко выходят за эти рамки.
PerlPower
27.10.2017 21:46+1Что вы имеете ввиду под «методологиях ИТ»?
Книги о том как надо писать код, например тот же «Совершенный код». Только не надо зацикливаться на ней, существует куча других книг о том как писать приложения.
Научный метод как раз и призван минимизировать эффект от «кукареканья», разве нет? Критическое мышление там, анализ фактов и т.д.
Если мыслить критически, то любая идея о том как нужно писать код, это просто мысль вслух. Пока не были сделаны экспериментальные проверки ее эффективности. С этим у программирования большие проблемы между прочим. Потому что если мы посадим двух программистов сравнивать идеи, то по факту мы будем сравнивать программистов. Если же посадим одного и того же программиста писать систему два раза — с учетом проверяемой идеи и без, то чистота эксперимента опять нарушается. Во-первых возможна предвзятость, во-вторых несовершенство владения какой либо из идей, в третьих — при реализации второй системы у программиста будет опыт от реализации первой, в четвертых — даже если отбросить все три пункта, то все что мы сможем доказать что идея А эффективнее идеи Б для этого конкретно взятого программиста на конкретно взятом проекте.
Мода есть везде и на все. Это к вопросу о том что люди чаще всего работают в рамках чего-то общепринятого и редко выходят за эти рамки.
Вопрос не в явлении моды как таковой, а в том что есть уважаемые люди, которые с пеной у рта доказывают, что их парадигма — это ого-го! А потом проходит несколько лет и ого-го это уже полная противоположность старой парадигме. Например смешение HTML+CSS+Js. На заре интернета это было нормой, потом дурным тоном, потом с выходом реакта то наоборот считается хорошим, но теперь даже некоторые реактовщики говорят, что им это не нравится.
Получается что это либо мода, либо все еще хуже — даже у программистов кто громче кричит того и слушают.Fesor
28.10.2017 00:52Книги о том как надо писать код, например тот же «Совершенный код».
Вспомним начало 20-ого века. Были десятки книг на тему "как все устроено". А потом случилась ультрафиолетовая катастрофа и вдруг оказалось что те учения к которым все привыкли — они по факту не работают.
О дрейфе континентов человечество узнало только в 50-х годах 20-ого века. При этом идея сама была сформирована задолго до этого, просто люди посчитали это глупостью.
"Совершенный код" — это сборник лучших практик, которые собрал один человек. Это отличная книга, на самом деле, но на не код учит писать, а скорее дает вам совет. Следовать этим советам или нет — решать вам. На начальных этапах обучения когда вы еще плохо понимаете зачем оно надо — лучше все же следовать. Вам же далеко не сразу объяснили что на ноль делить на самом деле можно? А вот задавать вопросы "почему так а не иначе", это будет хорошо. И на них можно получить ответы, и найти альтернативные мнения.
Получается что это либо мода, либо все еще хуже — даже у программистов кто громче кричит того и слушают.
потому я и о говорю о развитии в людях критического мышления. Увы программисты тоже люди и проблемы у них те же.
SinsI
27.10.2017 18:43+1Слайды, уж если их в статье приводите — тоже надо переводить!
Нигде не приведено, что же такое DRY.
По существу же статьи — кардинально не согласен с пунктом про имена.
Имена — это как раз самое большое достоинство маленьких функций, потому что вместо того, чтобы вникать, что именно делают хитросплетения конструкций языка — достаточно просто прочитать название!
Если же названия получаются чересчур длинными — то это признак того, что у вас проблема в архитектуре, или в используемом языке:
Не должно быть функций renderPageWithSetupsAndTeardowns — должны быть функции
renderPage(Setups, Teardowns)Fesor
27.10.2017 20:01Не должно быть
with setups and teardownsв данном контексте лишние по семантике, это название экспоузит лишние детали. Но ничего страшного в методах типаpredictRemnantOfIntermediateAccountи т.д. нет. То есть опять же "размер" и т.д. тут определяются не количеством символов а семантикой.

Tab10id
28.10.2017 00:50А еще иногда длинные имена функций означают что класс в котором она находится делает слишком много.
Fesor
28.10.2017 00:53А еще длинные функции могут появиться как следствие сложности придумывания названий. Например когда вы еще не знаете какой-то более короткой формулировки или названия термина но все еще пытаетесь описать что тут происходит. Если у разработчика проблема с языком — то еще сложнее.
Tab10id
28.10.2017 01:05У нас эта проблема на ревью решается=) Постоянно джунов прошу разбивать свои функции и давать им адекватные имена. В данном случае только строгий контроль может чему-то научить. И да, в случае джунов, имхо, пусть лучше мелкие функции пишут, багов в этом случае по статистике меньше.

newpy
27.10.2017 19:56It is better to have 100 functions operate on one data structure than 10 functions on 10 data structures. —Alan Perlis
Дело не в размере функций.Fesor
27.10.2017 20:021000 процедур и 1 глобальная структура содержащая 100 полей?)
Дело не в размере функций.
и не в их количестве, и не в количестве структур данных. Просто это все намного проще "посчитать" а значит проще заставить начинающих следовать каким-то догмам. Гораздо сложнее например померять характеристики по настоящему влияющией на дизайн системы.
Была раньше неплохая книжка... .
.newpy
28.10.2017 14:47на каждую хорошую книжку, никуда не исчезла ;).
не менее хорошая
Fesor
28.10.2017 15:48SICP очень хорошая книжка, которая так же много чего говорит о значении абстракции.
Другой разговор, что не всегда возможно, уместно, удобно и нужно дробить большие функции.
Структурный дизайн по большому счету именно об этом и вещает. Проблема же в том что многие хотят сразу получить идеальное разделение (которого к слову нет), и в этом ключе можно тогда еще Рефакторинг Фаулера и "Эффективная работа с легаси кодом" добавить. Эти книги проповедуют "эволюционный дизайн". К сожалению для того, что бы эти подходы работали, в команде должны быть люди с довольно высоким уровнем личной ответственности.
michael_vostrikov
27.10.2017 20:27В целом в статье есть правильные мысли. Тоже сталкивался с таким. Когда ищешь ошибку среди множества мелких взаимосвязанных функций, надо зайти в каждую, проверить что она делает, и совместить все это в голове.
Код читают не чтобы почитать, а чтобы разобраться и исправить. Понятное название позволяет решить, надо или нет разбираться в этой части кода. И вот решаешь что надо проверить этот метод в стороннем коде, заходишь туда, а там 2 строки с такими же понятными названиями уровнем пониже. Заходишь в каждый, а там тоже по 2 метода. Так просто сложнее искать ошибку.
Дело не в количестве строк, а в контексте. Одни говорят, что маленькие функции хорошо, другие что плохо, а имеют в виду разные ситуации. МетодisActive()из одной строки вполне нормально выглядит.
А скажем такой код уже не очень. Гораздо понятнее, если все части алгоритма будут вместе.
Скрытый текстstatic void someimpl_update(SOMEIMPL_CTX *c, const void *data, size_t len) { const unsigned char *ptr = data; size_t res; if ((res = c->num)) { res = someimpl_update_first_part(res, c, ptr, len); ptr += res; len -= res; } res = someimpl_update_second_part(len); len -= res; if (len) { someimpl_update_third_part(c, ptr, len); ptr += len; } if (res) { someimpl_update(c, ptr, res); } } size_t someimpl_update_first_part(size_t res, SOMEIMPL_CTX *c, const unsigned char *ptr, size_t len) { res = someimpl_update_recalc_res(res); if (len < res) res = len; someimpl_update(c, ptr, res); return res; } size_t someimpl_update_second_part(size_t len) { return len % SOMEIMPL_CBLOCK; } size_t someimpl_update_recalc_res(size_t res) { return SOMEIMPL_CBLOCK - res; } void someimpl_update_third_part(SOMEIMPL_CTX *c, const unsigned char *ptr, size_t& len) { someimpl_block_data_order(c, ptr, len / SOMEIMPL_CBLOCK); c->Nh += len >> 29; c->Nl += len <<= 3; if (c->Nl < (unsigned int)len) c->Nh++; }Fesor
27.10.2017 20:42Одни говорят, что маленькие функции хорошо, другие что плохо
но вы описали не проблему размера функций, а проблему зависимости между ними. Это немного другая история и с этим у разработчиков в среднем не так хорошо как хотелось бы.
michael_vostrikov
27.10.2017 21:01Так они взаимосвязаны. Много мелких функций значит они друг из друга вызываются, результаты одних зависят от других. Глядя на код функции нельзя сказать при каких условиях она вызывается. Условия приходится смотреть в одном месте, действия в другом.
Fesor
28.10.2017 00:55потому функции надо объединять в модули. А получившиеся модули в другие модули. И делать так что бы модули выделяли какие-то функции более общие которые позволят нам иметь минимум точек взаимодействия между этими модулями. И да, это сложно.
Druu
28.10.2017 07:25> И да, это сложно.
И, значит, нарушает KISS.ApeCoder
28.10.2017 10:04Делать просто сложно :) делать просто — нарушает KISS
Druu
29.10.2017 12:08> делать просто — нарушает KISS
Делать просто — не может нарушать KISS, потому что это _и есть_ KISS :)
И, да, делать просто — просто, в этом весь смысл. Если вам делать что-то сложно — значит, вы делаете что-то непростое. Не надо этого делать :)ApeCoder
29.10.2017 23:17И, да, делать просто — просто, в этом весь смысл.
Самое простое что можно делать это взять код, и приписать сверху то, что вам надо. Правда, результат будет сложным. Сделать так, чтобы результирующий код был простым сложнее — надо разобраться в том, что вам надо и что уже сделано до вас и отрефакторить чтобы результат был простым.
Fesor
28.10.2017 12:40KISS это когда легко пользоваться, точнее, когда реализация минимизирует риск неверного использования. И уж поверьте это не "просто" так сделать. Пример — USB Type A и USB Type C, каким проще пользоваться с точки зрения пользователя? Какой проще сделать было?
Druu
29.10.2017 12:13-1> KISS это когда легко пользоваться, точнее, когда реализация минимизирует риск неверного использования.
А «использование кода» (мы ведь о коде?) — это, в первую очередь, его чтение, все остальные варианты использования, в сущности, встречаются пренебрежимо редко. И если у вас какая-то сложная неинтуитивная структура зависимостей — то это плохо, потому что плохо читается. Даже цельная простыня читается лучше.

BalinTomsk
27.10.2017 20:50В одном серверном коде (Blackberry Server) у нас в функции стартующего треда было больше 10,000 строк (больше мегобайта).
PerlPower
27.10.2017 21:05+1Как-то раз мне попался проект с отчетами на полторы сотни полей, где одно поле считается на базе другого или нескольких, причем одно из них могло быть написано пару сотен строк назад. Это делал здоровый метод на пару тысяч строк. Я подумал, а почему бы не отрефакторить и не наплодить методов calcWithVAT, calcWithVATDifference, calcWithVATPredicted и т.п. Первое с чем я столкнулся — проброс зависимостей, он не решался даже путем закидывания нужных величин в приватные члены класса — когда этих полей столько и они по смыслу отличаются самую малость, то нужно чтобы перед глазами было как можно больше — и комментариев и формул. Второе — просто было неудобно проверять код по спецификации, а делать это нужно было часто. Когда ты перескакиваешь на метод, то контекст в голове сбивается просто от того что экран «моргнул». В итоге я оставил здоровый метод как есть просто поменяв порядок вычисления полей, чтобы он совпадал со спецификацией. Получилась портянка в стиле literate programming.
На основании похожих случаев я пришел к выводу, что дробить метод на мелкие смысла не имеет в двух случаях:
— если собрать алгоритм в голове целиком становится слишком сложно — нужно видеть что откуда приходит, и какие есть возможные ветвления и что именно может произойти в этих ветвлениях
— если частые изменения спецификации заставляют менять сразу несколько методов сразу на регулярной основе, и дело не в плохой декомпозиции, а в том что, спецификация постоянно меняется

RomanPokrovskij
27.10.2017 21:57Мне рассказывали о компании где нельзя чекинить код методов/функций больших чем одна страница, анализатор не пропускает, я фыркнул, бросились убеждать как это прекрасно. Я было опечалился, что сложно мне будет со своей привязанностью к вложенным функциям (local functions, при кодировании рекурсии — исключительно точный инструмент). Но потом подумал а как они считают длину?
Кто знает, для популярных анализаторов, когда считают длину функций из суммы количества строк/оппераций вычитают инструкции/строки относящиеся к local/inner functions?Myxach
28.10.2017 02:45Вложенные функции, он считает за отдельные, ну у меня по крайнее мере — он перестал считать их за часть функции

Telichkin
27.10.2017 23:23+1Есть смысл соблюдать DRY, только когда логика, которую можно обобщить, уже выражена в коде. Если логика для обобщения находится только в голове у автора, скорее всего, полученный в итоге DRY-подобный код будет сложно переиспользовать, он будет казаться чужеродным в остальных частях приложения. По-сути это одна из форм проявления преждевременной оптимизации.
ArtStea1th
27.10.2017 23:29вот не рассказывайте всем, что однострочные методы — это плохо, всё зависит от ситуации, или Вы просто не умеете их писать
чтобы не быть голословным, ниже код, писал не так давно, упростил для комментария:
Пример класса:
ArtStea1th
28.10.2017 00:59Добавлю ещё в защиту своего комментария с примерами кода и однострочными методами.
благодаря следованию мудрым советам Дяди Боба, в частности SRP (также и в контексте методов) и правильному именованию
+ резко снижается шанс допустить ошибку, и легче найти и исправить в случае чего
+ код тестопригоден
+ код легко читается и понимается, всё очевидно
+ нет надобности в комментариях
и ещё один плюс, код в примере критичен по отношению к производительности, и не могу сказать про все языки и\или виртуальные машины (или отсутствие оных), но в моём случае, поскольку это .NET
+ CLR в рантайме просто отлично инлайнит короткие методы, в итоге мы получаем всё плюсы описанные выше без негативного влияния на производительнось
быстро, красиво и удобно, PROFIT!michael_vostrikov
28.10.2017 08:49код легко читается и понимается, всё очевидно
Вот про это и написано в статье, что далеко не всегда мелкие функции приводят к легко понимаемому коду. А по таким комментариям кажется, что всегда.
В вашем коде у компонента независимое API, поэтому там неважна длина методов. А вот если вы метод ADD() разобьете на 4 функции, то понять работу и найти ошибку в логике будет сложнее.
Fesor
28.10.2017 12:43А по таким комментариям кажется, что всегда.
Цель то не в том что бы функции были маленькими, а в том что бы SOLID принципы соблюдались, а они раскрывают другие цели. Статистически просто если мы пишем маленькие функции — этот код с большей вероятностью будет соблюдать S (но бездумное уменьшение всего и вся или соблюдение этих принципов только в масштабах юнитов кода (классы, функции) а не модулей/компонентов/подсистем может привести к dependency hell.
ArtStea1th
28.10.2017 14:02Приношу свои извинения, вероятно у меня не совсем получилось донести мысль. Конечно же, я не хотел сказать, что все маленькие функции\методы — это хорошо, я скорее хотел сказать, что не все маленькие функции\методы это плохо. Поэтому и написал в первом комментарии, что «всё зависит от ситуации», главное не переусердствовать.
По поводу ADD() вы просто не знакомы с кодовой базой моего проекта, по «выдранному из контекста» коду это не так очевидно и там на самом деле ещё есть что «выделить», правда разделив выполнение на 3 а не на 4 части ).
Методов, подобных инструкции ADD() много (как я уже писал больше сотни), и подавляющее большинство из них таких как INC(), DEC(), ASL(), LSR(), AND(), ORA(), и пр. выполняются по одной и той же схеме:
1. манипулялии с одним набором флагов
2. непосредственно операция
3. манипулялии с другим набором флагов
Инструкции не вызываются непосредственно, они вызываются из коллекции по коду операции (индексу) в зависимости от исполняемого эмулируемой системой кода.
Сейчас все эти приватные методы, представляющие инструкции просто последовательно объявлены в классе и «вбиты» в инициализвтор коллекции (Action[255]).
Т.е. получается такая хорошая «простыня» на почти 700 строк практически однотипного кода.
Я думаю из описания становится очевидно, что необходимо в будущем, когда вернусь к этой части системы создать класс, например «Instruction», и ннкапсулировать в него последовательное выполнение предварительных действий, с проверкой предусловий, т.е. на какие флаги влияет инструкция, потом выполнение непосредственно тела в большинстве случаев это будет однострочное лямбда выражение, и постусловий (так же как и с предварительными).
Для вызывающего кода наружу будет только один метод вроде «Execute()», и всё это положить в какой-нибудь класс типо «InstructionSet», который выполнит первоначальную инициализацию (конструирование всех инструкций, можно например из xml-ки десериализовать или прямо в коде проинициализировать), а так же по обращению из «ядра» по «опкоду» выполнять инструкцию из внутренней коллекции. Инициализацию и выполнение можно так же отделить, но я думаю в моём случае пока в этом нет необходимости, потом будет видно.
В результате избавимя от «простыни» дублирующегося кода.ArtStea1th
28.10.2017 14:43Да, я согласен, возможно это в какой-то степени усложнит код однако, я считаю, в моём случае это приемлемая цена.
Tab10id
28.10.2017 01:34Статья пример неправильного применения коротких функций. Каша из слабосвязанных аргументов, которые хоть и иллюстрируют проблему, но совсем не ту о которой пишет автор.
По факту, мелкие функции действительно бывают огромной проблемой, но только потому, что выделяют не те фрагменты и не в те места.
Действительно все крутится вокруг SRP. И хоть в ООП данный подход и приводит к появлению множества различных уровней абстракций, при правильной реализации «осознать» такой код значительно проще, чем кашу из методов (будь они хоть длинными, хоть короткими).ArtStea1th
28.10.2017 02:10Да, полностью с Вами согласен, проблема скорее в неправильном выделении абстракций, а не в «маленьких функциях».

PFight77
28.10.2017 16:47Каждая функция — абстракция. Собственно, мысль автора — если мы принудительно ограничиваем размер функций, то это порождает массу плохих (непродуманных) абстракций.
Fesor
28.10.2017 17:03Но намного проще сказать людям делать маленькие функции нежели попросить их правильно абстракции выделять. Некоторые (например Сэнди Мэтс) умышленно идут на подобное упрощение. Правда она потом поясняет и зачем, и связь с абстракцией, и предупреждает о возможных проблемах, но людям проще делать маленькие функции по количеству строк.
Druu
29.10.2017 12:42> Но намного проще сказать людям делать маленькие функции нежели попросить их правильно абстракции выделять.
Сказать-то проще, но зачем? Если вы так скажете, то в итоге как раз и получите то, о чем пишет автор статьи. Использование маленьких функций — это инструмент, а не цель. И человек должен понимать, зачем этот инструмент применяет, а иначе это будет просто карго-культ с закономерным результатом.fogone
29.10.2017 14:31О чем угодно можно сказать: делай это с умом и будет тебе счастье. Но как я уже написал чуть выше, размер — это симптом, он подсказывает, что возможно этот метод можно упростить, вынести в функции куски, которые занимаются более низкоуровневыми вещами. Особенно если ты начинающий разработчик, то это очень хороший повод обратить внимание на тот код, что ты написал. Опытный обычно или делает на автомате такие вещи или новым трюкам его уже не научишь.
Druu
29.10.2017 15:32> Но как я уже написал чуть выше, размер — это симптом
Если воспринимать длину как _возможный симптом_, эдакий маркер, который показывает, что надо обратить внимание — то все, конечно, хорошо. Плохо, когда размер ф-и интерпретируется как руководство к действию.
Fesor
28.10.2017 02:11И хоть в ООП данный подход и приводит к появлению множества различных уровней абстракций
Ну как сказать, мне кажется это распространенное заблуждение и следствие неправильного проектирования. Хотя быть может я вас плохо понял.

lain8dono
28.10.2017 10:59Маленькие функции VS большие функции? Как по мне они должны быть средними по размеру. Разве это не решает все проблемы?
На мой взгляд решение такое: кода должно быть меньше. Если разбивание на мелкие ф-ии увеличивает объём кода — это очень плохо. Если разбивание на более мелкие ф-ии уменьшает объём кода — это очень хорошо. При этом под объёмом кода понимается и количество строк и ментальная нагрузка, которую этот код создаёт.
Проще — лучше. Но только до тех пор, пока код решает те задачи, которые перед ним ставятся.
Абстракции — это хорошо. Ровно до тех пор, пока они уменьшают объём кода. И не стоит забывать, что объём кода — это и ментальная нагрузка. Если вы разбиваете код на много мелких частей, то не стоит забывать о сложности связей между этими частями.
Кроме того надо не забывать о производительности и оптимизациях. Но тут стоит напомнить о бенчмарках (без них можно даже не начинать). И о том, как этот код будет использоваться. Если ты будешь писать несколько часов такой код, который отработает за секунду, вместо того, чтоб потратить пять минут на код, который будет работать десять… Эй! Это же утилита, которую ты запустишь один раз! Другими словами оптимизировать код нужно по тем совокупным ресурсам, которые на него затрачиваются сегодня и завтра. Иногда будет дешевле написать супероптимизированный код. Но далеко не всегда. Кстати во многих случаях простой тупой код с парой хаков будет работать быстрее, чем сложная запутанная система. Но разумеется есть исключения.
И в целом код должен делать то, что от него хотят. И не больше. Иногда твоей задачей будет написание кода, который противоречит твоим религиозным взглядам на то, как идеальный код должен выглядеть.
Универсальный совет: прежде чем лететь к архитектурным звёздам или погружаться в глубины оптимизаций, следует провести пятиминутный анализ того, а зачем оно вообще нужно.
ApeCoder
28.10.2017 21:05Абстракции — это хорошо. Ровно до тех пор, пока они уменьшают объём кода. И не стоит забывать, что объём кода — это и ментальная нагрузка. Если вы разбиваете код на много мелких частей, то не стоит забывать о сложности связей между этими частями.
Вопрос, какой объем кода считается — общий? Или на конкретном уровне абстракции?
Разбиение документа на части заголовками увеличивает объем, но разобраться в результате проще, потому, что на верхнем уровне есть ограниченный объем глав, и можно понять где заканчивается конкретная глава.
G-M-A-X
30.10.2017 11:13Функции не должны быть ни маленькими, ни средними, ни большими.
Они должны быть понятными.
Размер — это средство, а не цель. Но многие это путают.
Fesor
Давайте так, вся проблема с определением "дублирование" и "маленькое". В целом вся статья сводится к принципу единой ответственности который хоть и звучит очень просто на поверху оказывается далеко не столь очевидным.
Если рассматривать код через призму потока изменений требований, все становится намного проще. Два куска кода которые выглядят одинаково но имеют под собой двух разных стэкхолдеров, которые могут генерировать изменения независимо друг от друга, как бы говорят что несмотря на похожесть это все же разный функционал и не надо его DRY-ить.
Так же и по поводу "маленькое". Вопрос в том сколько причин для изменений. У вас может быть кусок кода в 1000 строк у которого все еще только одна причина для изменений.
Так же можно попробовать углубиться в Responsibility Driven Design. Там много приемов для выделения ролей и зон ответственности кода.