
Список инструментов
- Proxmox
- ZFS
- LXC
- MongoDB в качестве подопытной базы
Предисловие
Меня зовут Евгений Савёлов, я занимаюсь сетями, виртуализацией, Windows и Linux серверами, координирую работу программистов и заказчиков в небольшой компании.
Я вижу, что многие используют системы виртуализации, такие как Proxmox, но не знают как использовать преимущества LXC и ZFS. Многие просто используют классические файловые системы, такие, как Ext4, и классические методы клонирования и резервного копирования контейнеров. Это приводит к простоям во время клонирования больших контейнеров и к высокой нагрузке на сервер.
Постараюсь поделиться своим опытом.
Так же я подготовил материал в виде 6 минутного скринкаста. Голосового сопровождения нет, поэтому наушники можете не искать :). Зато есть аннотации снизу.
Исходные настройки
Proxmox
Установлен сразу на ZFS
ZFS
Поддержка включена по умолчанию для Proxmox. Настройки по-умолчанию неплохие. Сомнения вызывают: swap раздел на ZFS и размер блока zvol для KVM виртуальных машин.
LXC
Поддержка включена по умолчанию для Proxmox. Настройки по-умолчанию отличные.
MongoDB
Тестовая база на 50Gb внутри LXC контейнера, созданного с помощью Web консоли Proxmox
Клонирование и тестирование
1. Познакомимся с исходным контейнером
Root файловая система контейнера занимает 56.5GiB на диске с учетом снимков и 30Gib на диске без учета снимков.
zfs list rpool/data/containers/subvol-105-disk-1
NAME USED AVAIL REFER MOUNTPOINT
rpool/data/containers/subvol-105-disk-1 56.5G 98.3G 30.0G /rpool/data/containers/subvol-105-disk-1Ниже видно, что наш контейнер занимает 44.4GiB места логически (без учета снимков и сжатия LZ4).
zfs get logicalreferenced rpool/data/containers/subvol-105-disk-1
NAME PROPERTY VALUE SOURCE
rpool/data/containers/subvol-105-disk-1 logicalreferenced 44.4G -
Внутри контейнера Ubuntu 14.04 с базой данных MongoDB 3.4
2. Создадим новый контейнер в Proxmox, в качестве основы для клона.
Во время создания нового контейнера будьте внимательны, в качестве шаблона вы должны обязательно указать шаблон, используемый в основном контейнере.
То есть, если основной контейнер — Ubuntu 14.04, то новый контейнер тоже должен быть Ubuntu 14.04.
Если этого не сделать, то вероятно после клонирования файловой системы из исходного контейнера, новый контейнер не запустится. Дело в том, что кроме файловой системы контейнеры обладают некими атрибутами запуска, зависящими от ОС внутри контейнера.
3. Уничтожим файловую систему нового контейнера.
Номер, внутри квадратных скобок замените на номер нового контейнера. Внимание: эта операция необратима!
zfs destroy rpool/data/images/vm-[111]-disk-14. Сделаем моментальный снимок исходного контейнера
Снимок — это одна атомарная операция.
ZFS гарантирует, что снимок будет сделан мгновенно, независимо от размера файловой системы. Так же мы можем быть уверенны, «внутри» операции получения снимка не будут изменены никакие данные файловой системы (консистентность).
zfs snapshot rpool/data/images/vm-[105]-disk-1@demo
#demo - имя снимка5. Сделаем клон файловой системы исходного контейнера.
Клонирование файловой системы всегда выполняется с указанием снимка другой файловой системы. Имя клона нужно указывать с учетом имени нового контейнера, тогда после создания файловой системы не нужно будет менять точки монтирования, что бы запустить контейнер.
zfs clone rpool/data/images/vm-[105]-disk-1@demo rpool/data/images/vm-[111]-disk-1 6. Запустим вывод zfs list и продемонстрируем, что клон не расходует дополнительного места.
Ниже видно, что наш контейнер занимает 112KiB на диске и ссылается на 30,0Gib
zfs list rpool/data/containers/subvol-111-disk-1
NAME USED AVAIL REFER MOUNTPOINT
rpool/data/containers/subvol-111-disk-1 112K 98.2G 30.0G /rpool/data/containers/subvol-111-disk-1
7. Запустим контейнер-клон и продемонстрируем, что все работает. Поменяем часть базы данных.
Запустить контейнер можно из Web интерфейса Proxmox или используя следующую команду:
pct start 111
Что бы узнать IP адрес нового контейнера можно зайти в него.
lxc-attach -n 111
ifconfig
exit
Нам остается подключаться к клонированной базе данных, например используя MongoBooster и поменять часть данных. Я наложу сложный индекс.
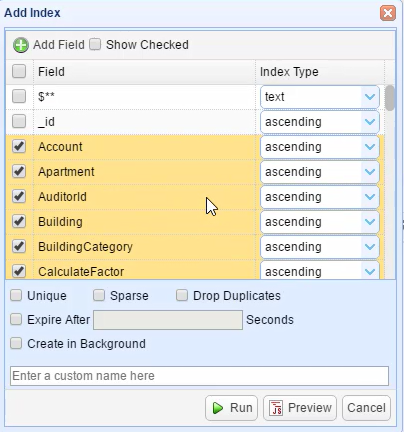
8. Запустим вывод zfs list и продемонстрируем, что клон расходует место, которое требовалось для изменения части базы данных.
Место расходуется только на измененные блоки.
Обычно чем больше размер блока, тем больше места будет израсходовано, но в zfs используется прозрачное lz4 сжатие, которое снижает накладные расходы на использование эффективных 128KiB блоков.
Ниже видно, что наш контейнер занимает 144MiB на диске и ссылается на 30,1Gib
zfs list rpool/data/containers/subvol-111-disk-1
NAME USED AVAIL REFER MOUNTPOINT
rpool/data/containers/subvol-111-disk-1 144M 98.2G 30.1G /rpool/data/containers/subvol-111-disk-1
9. Результаты
В дальнейшем нам не потребуется удалять или создавать контейнеры в Proxmox. Мы просто уничтожаем файловую систему клона и снова снимаем клон с Production базы.
Это выполняется моментально. Сетевые настройки клона не будут меняться, так как у него не будет меняться Mac адрес.
Вместо заключения
Полагаюсь на ваши комментарии. Постараюсь ответить на все интересные вопросы и дополнить статью этими вопросами и ответами на них, приятного просмотра.
Комментарии (33)

FuN_ViT
29.10.2017 13:01Если не путаю — рекомендуется или останавливать mongodb или использовать db.fsyncLock()/db.fsyncUnlock().
Иначе, под нагрузкой — вас ждет «сурприз».
gluko Автор
29.10.2017 16:08+1Сюрприза не будет. Указанная операция не имеет смысла, так как клонирование production базы проводится для тестирования либо для дальнейшей разработки. То есть мы хотим получить точную копию Production базы в Dev или Test окружении. При этом мы естественно не хотим останавливать Prod (что вы предлагаете сделать).
Кроме того, если обратиться к документации Wired Tiger, то мы увидим следующее:
«MongoDB configures WiredTiger to create checkpoints (i.e. write the snapshot data to disk) at intervals of 60 seconds or 2 gigabytes of journal data.
During the write of a new checkpoint, the previous checkpoint is still valid. As such, even if MongoDB terminates or encounters an error while writing a new checkpoint, upon restart, MongoDB can recover from the last valid checkpoin»
Это значит, что Монга сама откатит состояние базы к последнему валидному состоянию9660
30.10.2017 05:24Это значит, что Монга сама откатит состояние базы к последнему валидному состоянию
Это значит, что мы не получим клон базы. Такой результат не всем подходит.gluko Автор
30.10.2017 08:24+1Не пониманию ваше непонимание. Попробую еще раз объяснить.
Перед созданием клона мы ОБЯЗАНЫ создать моментальный снимок. Затем мы можем использовать этот снимок для создания клона, допустим через секунду или через день, не важно. Данные в этом снимке запечатлены в точный момент времени. Снимок атомарен! Мы получаем внешнюю по отношению к базе данных консистентность.
Так вот, когда база запустится, она просто отбросит все операции, которые были сделаны после последней контрольной точки, если это потребуется для сохранения внутренней консистентности.
Так как контрольные точки база делает либо каждые 60 секунд, либо каждые 2GiB данных, в зависимости от того, что случится быстрее, Разработчик получит 100% рабочую базу данных практически на момент создания снимка.
Если вас что-то смущает, поясните пожалуйста, я не понимаю.
PS мы используем это в процессе разработки больше 2х лет.9660
30.10.2017 08:52-1А что такое по вашему клон? Думаю корень наших непониманий в этом.
Я считаю что клон в терминах БД это точная копия данных.
Вы, кажется, считаете что это работоспособная БД с какими-то консистентными данными.
Какие-то товарищи (возможно твитер) подобным способом делают копии БД на zfs, но они предварительно лочат таблицы на запись, делают flush и только потом делают снимок. Утверждают что все хорошо и быстро.gluko Автор
30.10.2017 08:59+4Я понял, вы придираетесь к мелочам, вместо того что бы оценить, а нужно ли то, что вы предлагаете разработчикам и тестировщикам? Всегда стоит конкретная задача, мы не делаем сферических коней в вакуме. Так вот, копия такого уровня консистентности, подходит как для разработки, так и для тестирования.
Думаю, что проблема в понимании кроется еще и в том, что вы не работали с NoSQL базами. Там нет релляций. Коллекции данных не связаны базой данных так, как они были бы связаны в SQL. Логика сохранения консистентности частично обязана присутствовать в самом приложении в связи с этим. Архитектура такова.
dreesh
30.10.2017 17:19Мне казалось, что клонирование это создание точной копии на другом носители с возможностью транспортировки в другое место планеты/солнечной системы/галактики. А так получается copy-on-write копия.
gluko Автор
30.10.2017 17:21То, о чем вы говорите, это уже репликация (репликацию можно сделать в другую файловую систему, в файл, или на удаленную площадку).
С точки зрения практической ценности, описанное в статье можно называть клоном, который мы можем использовать в разработке и тестировании.
Главное преимущество описано: не нагружает сервер и не занимает время.
Я показал как можно использовать превосходную технологию. Вам решать когда и где :)
FyvaOldj
29.10.2017 17:52А как решить проблему что нельзя удалить исходную файловую систему, если есть клон?
То есть клон годится как временное решение или как решение когда изменяется немного данных.
Но для жизни годами — клон это не круто. Из 50 Г вы получите 100 Г и от изначальных 50 Г избавиться невозможно. Несмотря что данные уже переписаны сверху на 100 раз
gluko Автор
29.10.2017 18:29Нет такой проблемы. Почитайте про zfs promote
docs.oracle.com/cd/E19253-01/820-0836/gbcxz/index.html
У них правда стили отвалились после перехода на HTTPS.
R0MaNbI4
30.10.2017 08:03+3Впредь при монтаже рекомендую придерживаться так называемой Title/Action Safe Area, потому что при перемотке видео вылезает полоса прокрутки и закрывает текст

Как правило, кнопка для включения этой сетки находится на видном месте

gsl23
30.10.2017 08:04В данном случае, нагрузка на Dev'е будет сказываться на Prod, (т.к. обе бд по сути будут использовать одни и те же блоки, пока они не изменены). Это важный момент, мало кого устраивает такой расклад. Это надо оговаривать. Не говоря о том что ZFS сам по себе не быстр (но это уже offtop).
gluko Автор
30.10.2017 08:14+1Поясню свою точку зрения. Допустим для проекта мы арендуем вот такую машину www.hetzner.com/dedicated-rootserver/ex51-ssd
Зеркало из 2 SSD, с постоянной репликацией на удаленную площадку.
Допустим программист приступает к написанию новой фичи, а тестировщик приступает к тестированию старой. Если мы будем копировать 50GiB базу для программиста, затем 50GiB базу для тестировщика, что бы они могли работать с ними в «песочнице», то нам потребовалось бы сразу дополнительно 100GiB. К тому же при копировании мы бы очень сильно нагрузили IO и CPU сервера, что длительное время сказывалось бы на Prod. Наши клиенты (это внутренний проект небольшой компании, поэтому одного боевого сервера нам хватает) испытывали бы неудобства, приложение бы тормозило.
Теперь по поводу того, что используются одни и те же блоки данных для Prod, Dev и Test. Это чудесно!!! Дело в том, что ZFS считает эти блоки 1 раз, для всех сразу, тем самым серьезно снизится нагрузка на IO. Если хотите понять почему это произойдет, почитайте как работает адаптивная замена кэша в ZFS
acmnu
30.10.2017 10:46К тому же при копировании мы бы очень сильно нагрузили IO и CPU сервера, что длительное время сказывалось бы на Prod.
Обычно dev/test разворачивают с бэкапа. (вы же их делаете?) Для разработки отставание клона в день-два не существенно.
Если мы будем копировать 50GiB базу для программиста, затем 50GiB базу для тестировщика,
Можно сделать один клон с бэкапа, а потом делить его снепшотами как угодно. Кроме того, в зависимости от того какую вы базу используете вам может быть доступен standby, который для таких целей весьма удобен.
gluko Автор
30.10.2017 11:00+1Обычно dev/test разворачивают с бэкапа. (вы же их делаете?) Для разработки отставание клона в день-два не существенно.
На самом деле последнее время так и происходит.
Цепочка реплик выглядит так:
Prod Server -> Backup Server (удаленная площадка) -> Hyper-V VM на ноутбуке разработчика
Но зачастую держать отдельную машину для тестирования и разработки не имеет смысла. Например базы для тестирования мы получаем именно описанным мною в статье способом!
Не забудьте, что база должна жить рядом с приложением! Если между ними будет высокий Latancy, будет худо.
То есть я хочу сказать, простую вещь. Реплики то мы делаем, но на той стороне некому запустить базу и приложение, на это нужны громадные ресурсы, которыми не обладает наш Backup Server.
gluko Автор
30.10.2017 08:47+1«Не говоря о том что ZFS сам по себе не быстр (но это уже offtop)»
Да, есть нюансы, но их обсуждение потребует отдельной статьи. Знаете я очень много думал, а не перейти ли на другую файловую систему, скажем более быструю… Но каждый раз прихожу к тому, что слишком многое теряю в этом случае. Короче мое мнение: ZFS не самая быстрая, но точно самая надежная и одна из самых удобных! Я не отрицаю, что у ZFS есть недостатки, но ничего лучше я не видел.acmnu
30.10.2017 10:50Самое крутое известное мне решение для БД это Oracle ASM. Естественно он строго под Oracle, а вот ZFS это последнее что я бы применил. И дело не в тормознутости, а в том, что все нормальные базы данных так или иначе имплементируют логику работы с диском напрямую (своя блочная логика например, asyncio и derectio, и т.д.). Фактически традиционная FS для базы данных лишняя сущность и её используют только для удобства админа.
ant_perch
30.10.2017 10:55Подача в виде скринкаста имеет право на жизнь. Она очень поможет новичкам, которым еще сложно ориентироваться в настройках и интерфейсах нового ПО.
balexa
30.10.2017 11:38Весьма странное решение, если не сказать более грубо.
Во первых как уже сказали, для подобных целей база должна разворачиваться из бакапа.
Во вторых, и это главное, у вас на UAT и DEV окружении используются сырые данные с прода? Серьезно? Там контакты ваших клиентов, их имена, фамилии и платежные данные, я так понимаю. И они у вас без какого либо маскирования 1) доступны всем разработчикам-тестировщикам-эникейщикам-уборщице? 2) вы реально используете их в тестах и разработке?gluko Автор
30.10.2017 13:10Отчасти вы конечно же правы. Но вы снова забываете о контексте. Нельзя бездумно перенимать чужой опыт. Как я уже говорил, наш проект для внутренних нужд. Там нет персональных данных. Кроме того им занимается, внимание — 1 senior Fullstack .net программист, который является нашим сотрудником, работает fulltime. У него и так есть доступ ко многим вещам.
И да, порой тесты и разработка гораздо эффективнее, когда работа идет с реальным данными.balexa
30.10.2017 13:22Кроме того им занимается, внимание — 1 senior Fullstack .net программист, который является нашим сотрудником, работает fulltime. У него и так есть доступ ко многим вещам.
Так с этого и надо было начинать, что это внутренняя разработка, которой занимается один человек, который отвечает за бакенд, фронтенд и я так полагаю тестирование. А то «высокие нагрузки, большие данные, контейнеры».
Ваш опыт очевидно не подходит в случае если проектом занимается людей чуть больше одного и приложение хранит хоть какие-то данные пользователей. Короче если приложение критично для компании.
И да, порой тесты и разработка гораздо эффективнее, когда работа идет с реальным данными.
Какая вам разница, данные реальные или замаскированные? А вот если из-за ошибки в скрипте или конфигах вы на кастомеров из 50-гиговой базы разошлете неверные платежки или просто заспамите их, то будет весело.
budarov
30.10.2017 13:26+1Ну, насколько я понял, статья о связке технологий, позволяющей очень гибко управлять инфраструктурой, а не о бизнес процессах и данных пользователей…
И у всех случается, что в самый не подходящий момент начинает проявляется какой нибудь неприятный баг с какими нибудь «неправильными» данными, какие появились вот только сейчас, и нужно оперативно исправить… и что? Делать бэкап, разворачивать dev из него и тратить на это время? Или предоставить среду для дебаггинга уже через минуту… тут уж решайте сами, что для вас правильнее, это бизнес процесс, у всех они разные с разными данными а статья про то.balexa
30.10.2017 13:42И у всех случается
Нет, не у всех. У нас не случается. И не случается там, где процесс разработки поставлен не по принципу «на проекте работает один фулстек сеньор с полным доступом ко всему».
неприятный баг с какими нибудь «неправильными» данными
Для этого есть логи. Да, представьте себе, люди умудряются писать софт, который позволяет отследить такие случаи, не имея доступа к продакшен данным.
Делать бэкап, разворачивать dev из него
Если у вас неприятность на проде, бакап делать уже поздно. В данном случае вам нужна утилита, которая позволяет выгружать конкретную запись (и все связанные), одновременно это маскируя. Пишется это буквально на коленке за день максимум. Нет, когда случился инцидент писать ее уже поздно. Она должна быть написана до.
это бизнес процесс, у всех они разные с разными данными
Именно так. В случае с ситуацией автора (один разработчик-мастер-на-все-руки, нет пользовательских данных, нет никаких ограничений по безопасности, у всех есть доступ ко всему, полная демократия) это решение подходит. Просто не надо выдавать подобное решение за какой-то best-practice.gluko Автор
30.10.2017 16:49Если у вас неприятность на проде, бакап делать уже поздно.
В том то и дело, что не поздно. На проде делаются моментальные снимки каждый час по крону. Эти же снимки затем отправляются на бэкап ассинхронно.
То есть ZFS дает нам возможность версионирования прода. Мы делаем клон с любого удобного снимка. То есть у нас так и так все карты на руках.

antirek
01.11.2017 06:22Не понял, база монго находится внутри контейнера? Серьезно?
Всегда считал, что данные не должны находиться в контейнерах.gluko Автор
01.11.2017 07:39Вы очевидно путаете контейнеры и Docker :)
Контейнеры в практическом смысле тоже самое что виртуальные машины.
Докер — очень своеобразная штука. Докер использует контейнеры, но можно сказать выворачивает «идею» наизнанку…
Короче в сети есть мнение что docker = container. Это не так! Возможно я сделаю об этом отдельную статью.
Контейнеры = виртуальные машины (если не брать во внимание «иллюзию» изоляции)
Как это не печально, докер сдел так, что когда люди слышат слово «контейнер», они думают «докер». Черт возьми, как сильно они ошибаются!
Почитайте как работают Linux Container (LXC) или FreeBSD jails! Мне очень повезло, я познакомился с Jails во FreeBSD еще до того как появился Docker и начал засирать мозги специалистам.
TyVik
Нет, нет и ещё раз нет. Всякие видео и скринкасты ужасны в качестве подачи материала. Даже доклады с конференций желательно выкладывать вместе с текстовой расшифровкой. Почему? Они не индексируются, времени на изучение тратится больше, прямая навигация затруднительна, в конце концов у меня под рукой может банально не быть наушников.
gluko Автор
Насчет наушников — в видео нет голосового сопровождения, только аннотации. Про подачу материала я понял. Я попробую снять статью с публикации и добавить полное текстовое описание скринкаста. Спасибо за отзыв!
gluko Автор
Готово!
Xalium
лучше и текст и видео.