ANTLR — это генератор парсеров, который позволяет создавать парсер по описанию грамматики на одном из основных языков программирования. Он сам написан на java и прекрасно работает с Java.
Пошаговое руководство:
1) Поставить Oracle Java JDK и Intellij Idea, (можно пропустить этот шаг, если они уже поставлены), и запустить Intellij Idea
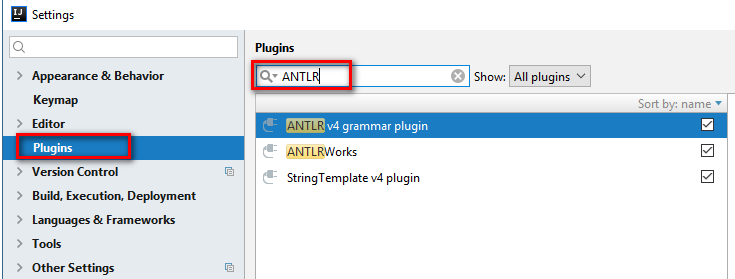
2) File-Setting-Plugins

Bвести в поле поиска ANTLR и поставить плагин ANTLR v4 grammar plugin. Возможно, понадобится дополнительный поиск по всем репозиториям.
3) Для Maven проекта добавить в pom.xml или создать новый проект.
в dependencies
<dependency>
<groupId>org.antlr</groupId>
<artifactId>antlr4-runtime</artifactId>
<version>4.7</version>
</dependency> и в plugins
<plugin>
<groupId>org.antlr</groupId>
<artifactId>antlr4-maven-plugin</artifactId>
<version>4.7</version>
<executions>
<execution>
<goals>
<goal>antlr4</goal>
</goals>
</execution>
</executions>
</plugin>Подробности https://github.com/antlr/antlr4/blob/master/doc/java-target.md
4) Далее создам и добавляем вручную файл грамматики с расширением .g4. Имя файла должно совпадать с словом после grammar в первой строчке. Составляется она примерно так: берем то, что нужно парсить, и разбиваем на отдельные токены. Для токенов описываем лексемы, например все английские буквы [a-zA-Z];, все числа [0-9] и т.п.. Для примера взято содержимое примера с официального сайта для файла Hello.g4
// Define a grammar called Hello
grammar Hello;
r : 'hello' ID ; // match keyword hello followed by an identifier
ID : [a-z]+ ; // match lower-case identifiers
WS : [ \t\r\n]+ -> skip ; // skip spaces, tabs, newlines5) Далее правой кнопкой мыши кликнуть по второй строчке файла, которая начинается с r и выбрать пункт меню Test Rule r
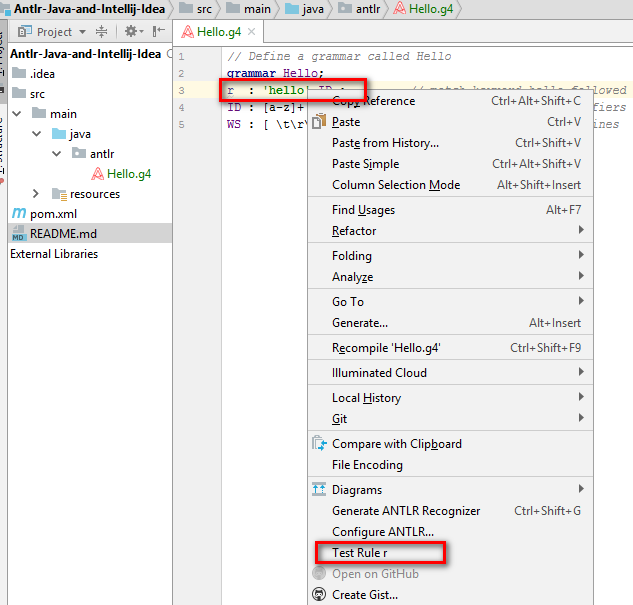
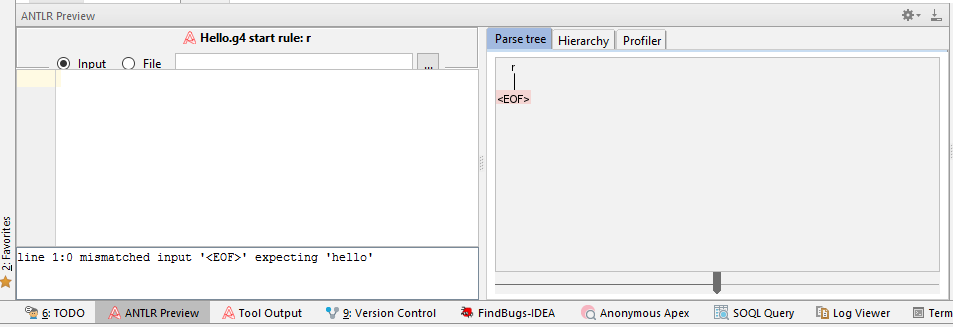
Внизу откроются окна проверки грамматики. В данном случае, плагин показывает ошибку, скорее всего связанную с тем, что это тестовый пример, однако парсер генерируется. Про это можно почитать здесь https://github.com/antlr/antlr4/issues/118, и пока ее проигнорируем. Но в реальных проектах, надо бы внимательнее обращать внимание на эти ошибки.
6) Кликаем по файлу грамматики правой кнопкой мыши, выбираем пункт меню Configute ANTLR Recoqnizer и генерируем парсер
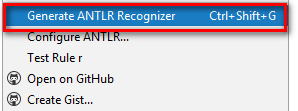
После этого появится в правом нижнем углу сообщение об успехе
7) Далее снова кликаем по файлу правой кнопкой мыши и выбираем пункт меню Configute ANTLR,
и выходит окно для конфигурирования генерации файлов
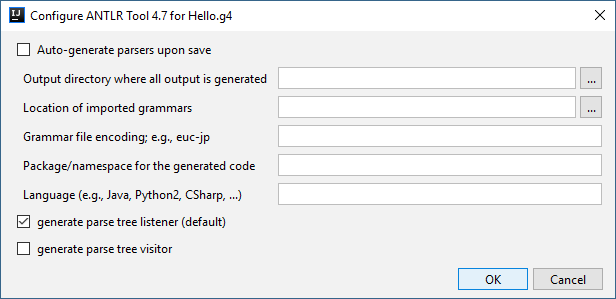
В этом окне вводим данные о папке назначения и языке программирования, в нашем случае Java, нужны ли visitor или listener, а также другую требуемую информацию, и нажимаем кнопку ОК
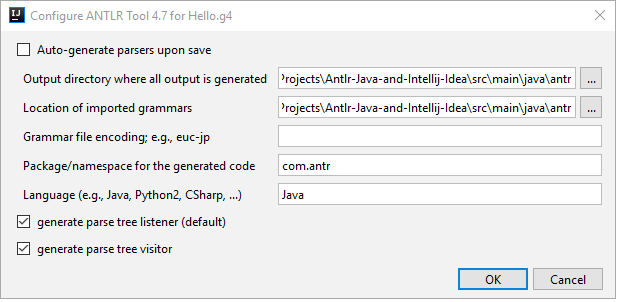
И ANTLR после этого генерирует файлы для распознавания. Тем не менее, хотя выходной каталог указан, часто создается новая папка gen в корне проекта, причем java не распознает эти файлы.
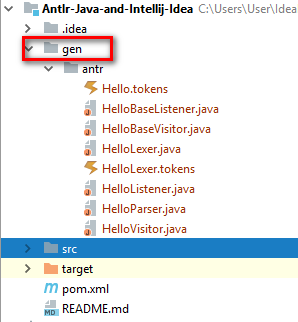
Для того, чтобы java увидела эти файлы, папку нужно либо пометить правой кнопкой мыши «Mark Directory As» на «Generated Sources Root» на папку gen.

И должно получится так:
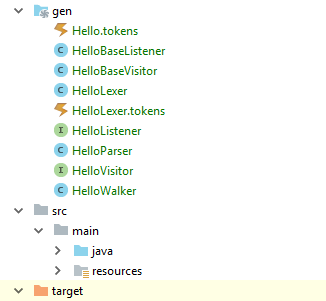
8) ANTLR сгенерировал такие классы:
Класс HelloParser.java — это описание класса парсера, то есть синтаксического анализатора, отвечающего грамматике Hello:
public class HelloParser extends Parser { ... }Класс HelloLexer.java — это описание класса лексера, или лексического анализатора, отвечающего грамматике HelloInit:
public class HelloLexer extends Lexer { ... }Hello.tokens, HelloLexer.tokens — это вспомогательные классы, которые содержат информацию о токенах HelloListener.java, HelloBaseListener.java, HelloBaseVisitor, HelloVisitor — это классы, содержащие описания методов, которые позволяют выполнять определенный действия при обходе синтаксического дерева
9) После этого добавим класс HelloWalker (хотя это класс не обязателен, этот код можно изменить и добавить в Main для вывода информации)
public class HelloWalker extends HelloBaseListener {
public void enterR(HelloParser.RContext ctx ) {
System.out.println( "Entering R : " + ctx.ID().getText() );
}
public void exitR(HelloParser.RContext ctx ) {
System.out.println( "Exiting R" );
}
}10) И, наконец, класс Main — точка входа в программу
public class Main {
public static void main( String[] args) throws Exception
{
HelloLexer lexer = new HelloLexer(CharStreams.fromString("hello world"));
CommonTokenStream tokens = new CommonTokenStream(lexer);
HelloParser parser = new HelloParser(tokens);
ParseTree tree = parser.r();
ParseTreeWalker walker = new ParseTreeWalker();
walker.walk(new HelloWalker(), tree);
}
}11) Запускаем метод main, и получаем на выходе в консоли успешно отработанный парсинг
Entering R : world
Exiting R> Код проекта выложен здесь
Комментарии (8)
Hixon10
07.11.2017 21:42Отличное введение в тему — tomassetti.me/antlr-mega-tutorial
Готовые грамматики для много чего — github.com/antlr/grammars-v4
grossws
Если уж используете
antlr4-maven-pluginи, собственно,maven, то лучше уж использовать принятые соглашения:*.g4располагать вsrc/main/antlr4/, сгенерированные файлы будут лежать вtarget/generated-sources/antlr4/, которую IDEA автоматически пометит как generated sources root.Также,
ANTLRInputStreamdeprecated, так что лучше использоватьCharStreams.from*(CharStreams.fromStringв данном случае).savimar Автор
В target/generated-sources/antlr4/ Idea не помечает generated sources root, ни автоматически,
ни вручную, вообще их не видит, (да и не должна видеть эти файлы), так что вернула в gen, остальное исправлено
grossws
У меня 2017.2.5 помечает автоматически. Вы уверены, что у вас maven-проект, а не что-нибудь другое, куда
pom.xmlдобавился позже? Если не удаётся пометить вручную — идите в youtrack.jetbrains.com, УМВР.С чего вы взяли, что IDEA не должна их видеть я не понял. У меня аналогично видятся файлы в
target/generated-sources/annotations, сгенерированныеorg.immutables:value.KvanTTT
Устарел, но при этом не понятно как, например, на новом API просто заюзать регистронезависимый поток? А он много где используется: диалекты SQL, PHP. Автор ANTLR консервативен и без особо охоты мержит риквесты с фичами, однако из-за нововведений с юникодом приходится использовать такие вот deprecated классы.
grossws
А где в antlr4
ANTLRInputStreamдаёт поддержку case insensitive? Мне пока не приходилось развлекаться с регистронезависимыми языками. Нельзя ли её сделать на уровне созданияTokenStream?KvanTTT
Пока что поддерживается в плагине antlr4test-maven-plugin и используется для грамматик в оффициальном репозитории.
Но, возможно, скоро он будет доступен и из коробки: https://github.com/antlr/antlr4/pull/2046
У меня пока что особо не получалось, вот даже вопрос на stackoverflow создавал.
grossws
Понятно. Мне пока не актуально, но спасибо за развёрнутый ответ.