
Это довольно много. Если бы Вы задались целью прочитать все сообщения всех пользователей, это бы заняло больше 150 тысяч лет. При условии, что Вы довольно прокачанный чтец и тратите на каждое сообщение не больше секунды.
При таком объёме данных критически важно, чтобы логика хранения и доступа к ним была построена оптимально. Иначе в один не такой уж и прекрасный момент может выясниться, что скоро всё пойдёт не так.
Для нас этот момент наступил полтора года назад. Как мы к этому пришли и что получилось в итоге — рассказываем по порядку.
История вопроса
В самой первой реализации сообщения ВКонтакте работали на связке PHP-бэкенда и MySQL. Это вполне нормальное решение для небольшого студенческого сайта. Однако этот сайт безудержно рос и начал требовать оптимизировать структуры данных под себя.
В конце 2009 года было написано первое хранилище text-engine, а в 2010 на него перевели сообщения.
В text-engine сообщения хранились списками — своего рода «почтовыми ящиками». Каждый такой список определяется uid’ом — пользователем-владельцем всех этих сообщений. У сообщения есть набор атрибутов: идентификатор собеседника, текст, вложения и так далее. Идентификатор сообщения внутри «ящика» — local_id, он никогда не изменяется и назначается последовательно для новых сообщений. «Ящики» независимы и друг с другом внутри движка никак не синхронизируются, связь между ними происходит уже на уровне PHP. Посмотреть на структуру данных и возможности text-engine изнутри можно здесь.
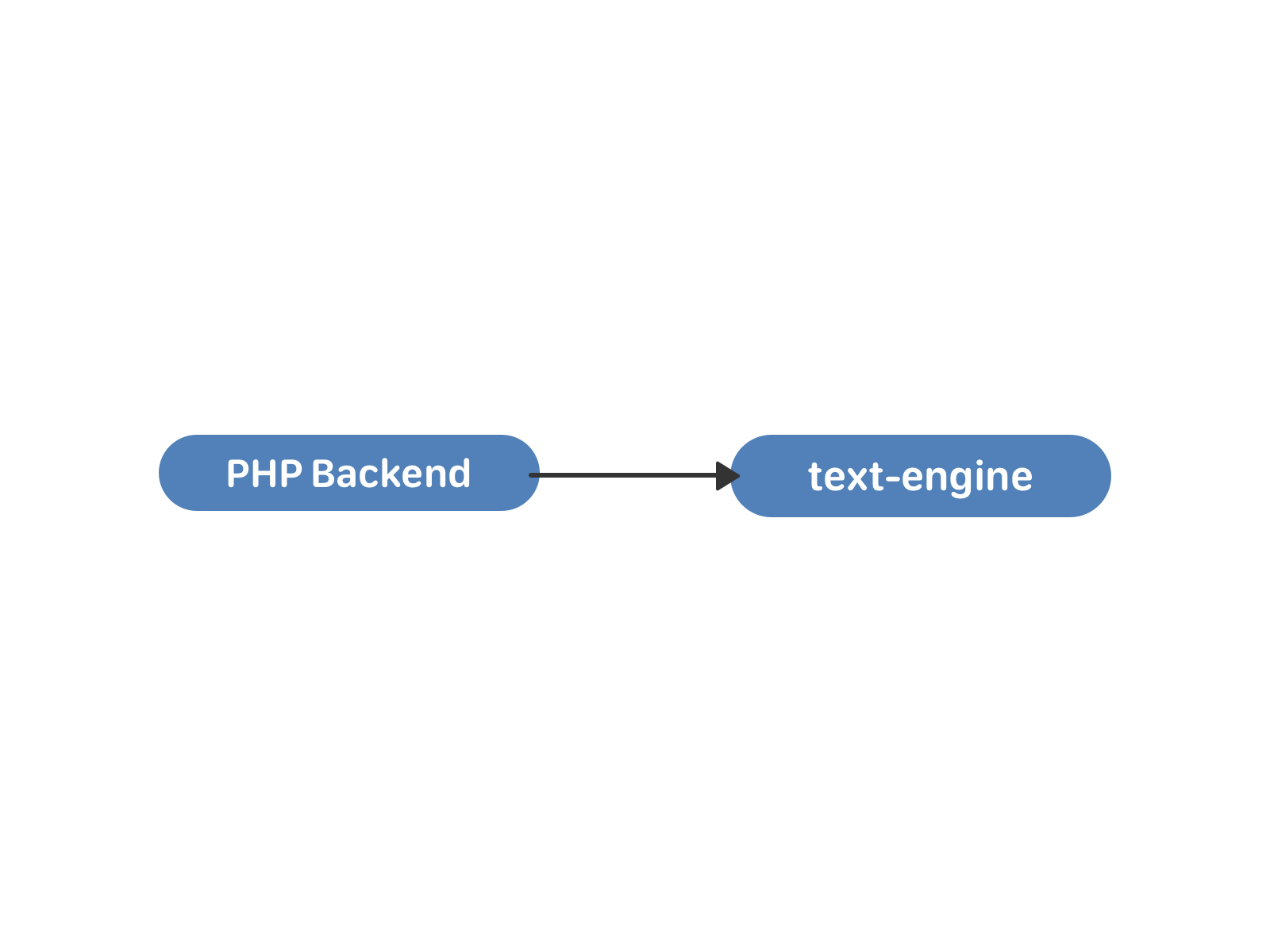
Этого было вполне достаточно для переписки двух пользователей. Угадайте, что случилось потом?
В мае 2011 года ВКонтакте появились беседы с несколькими участниками — мультичаты. Для работы с ними мы подняли два новых кластера — member-chats и chat-members. Первый хранит данные о чатах по пользователям, второй — данные о пользователях по чатам. Кроме самих списков это, например, пригласивший пользователь и время добавления в чат.
— PHP, давай отправим сообщение в чат, — говорит пользователь.
— Ну давай, {username}, — говорит PHP.
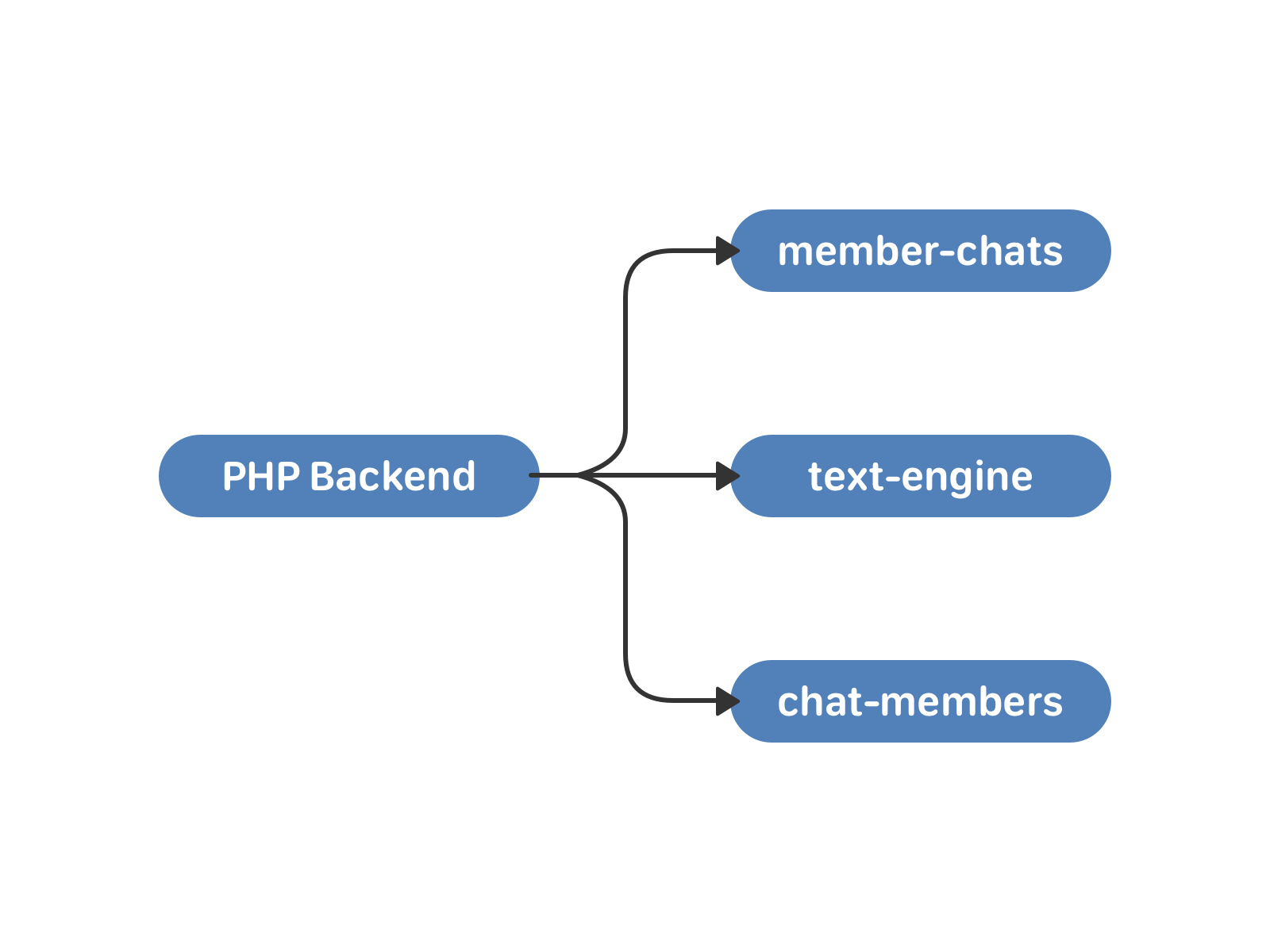
В этой схеме есть минусы. Синхронизация по-прежнему возложена на PHP. Большие чаты и пользователи, которые одновременно отправляют сообщения в них — опасная история. Поскольку экземпляр text-engine зависит от uid, участники чата могли получать одно и то же сообщение с разницей во времени. С этим можно было жить, если бы прогресс стоял на месте. Но не бывать такому.
В конце 2015 года мы запустили сообщения сообществ, а в начале 2016 — API для них. С появлением крупных чат-ботов в сообществах о равномерности распределения нагрузки можно было забыть.
Годный бот генерирует несколько миллионов сообщений в сутки — даже самые словоохотливые пользователи таким похвастаться не могут. А это значит, что некоторым экземплярам text-engine, на которых жили такие вот боты, стало доставаться по полной.
Движки сообщений в 2016 году — это по 100 экземпляров chat-members и member-chats, и 8000 text-engine. Они размещались на тысяче серверов, каждый с 64 Гб памяти. В качестве первой экстренной меры мы увеличили память ещё на 32 Гб. Прикинули прогнозы. Без кардинальных изменений этого хватило бы ещё примерно на год. Нужно либо разживаться железом, либо оптимизировать сами БД.
В силу особенностей архитектуры наращивать железо имеет смысл только кратно. То есть, как минимум удвоить количество машин — очевидно, это довольно дорогой путь. Будем оптимизировать.
Новая концепция
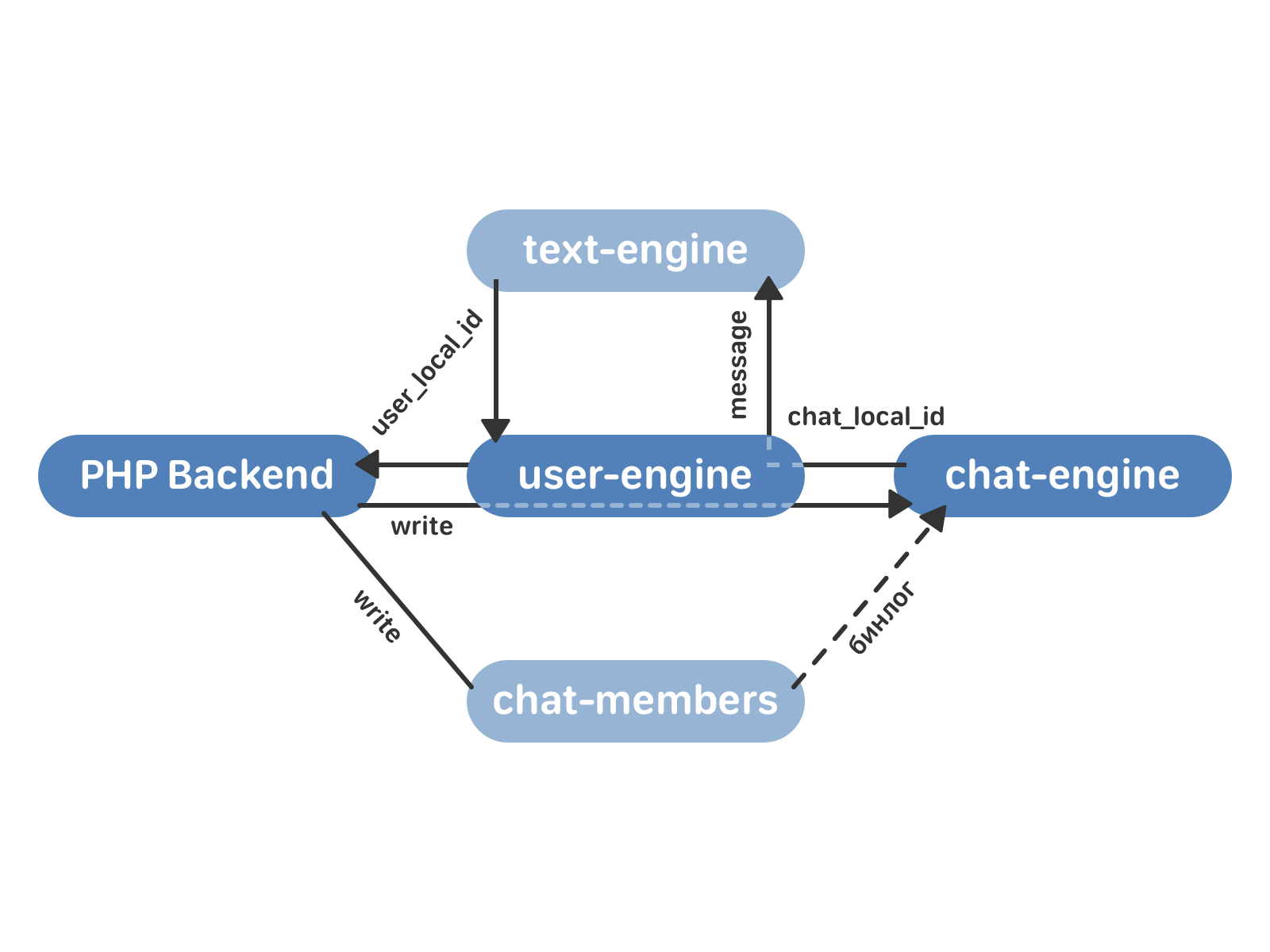
Центральная сущность нового подхода — чат. У чата есть список сообщений, которые относятся к нему. У пользователя есть список чатов.
Необходимый минимум — это две новые базы данных:
- chat-engine. Это хранилище векторов чатов. У каждого чата есть вектор сообщений, которые к нему относятся. У каждого сообщения есть текст и уникальный идентификатор сообщения внутри чата — chat_local_id.
- user-engine. Это хранилище векторов users — ссылок на пользователей. У каждого пользователя есть вектор peer_id (собеседников — других пользователей, мультичатов или сообществ) и вектор сообщений. У каждого peer_id есть вектор сообщений, которые к нему относятся. У каждого сообщения есть chat_local_id и уникальный идентификатор сообщения для этого пользователя — user_local_id.

Новые кластеры общаются между собой с помощью TCP — это гарантирует, что порядок запросов не изменится. Сами запросы и подтверждения для них записываются на жёсткий диск — поэтому мы можем восстановить состояние очереди в любой момент времени после сбоя или перезапуска движка. Поскольку user-engine и chat-engine это 4 тысячи шардов каждый, очередь запросов между кластерами будет распределяться равномерно (а в реальности её нет вообще — и это работает очень быстро).
Работа с диском в наших базах в большинстве случаев основана на сочетании бинарного лога изменений (бинлога), статических снимков и частичного образа в памяти. Изменения в течение дня пишутся в бинлог, периодически создаётся снимок текущего состояния. Снимок представляет собой набор структур данных, оптимизированных для наших целей. Он состоит из заголовка (метаиндекса снимка) и набора метафайлов. Заголовок постоянно хранится в оперативной памяти и указывает, где искать данные из снимка. Каждый метафайл включает данные, которые с большой вероятностью потребуются в близкие моменты времени — например, относятся к одному пользователю. При запросе к базе с помощью заголовка снимка читается нужный метафайл, а затем учитываются изменения в бинлоге, произошедшие уже после создания снимка. Прочитать подробнее о преимуществах такого подхода можно здесь.
При этом данные на самом жёстком диске изменяются только раз в сутки — глубокой ночью по Москве, когда нагрузка минимальна. Благодаря этому (зная, что структура на диске в течение суток постоянная) мы можем позволить себе заменить векторы на массивы фиксированного размера — и за счёт этого выиграть в памяти.
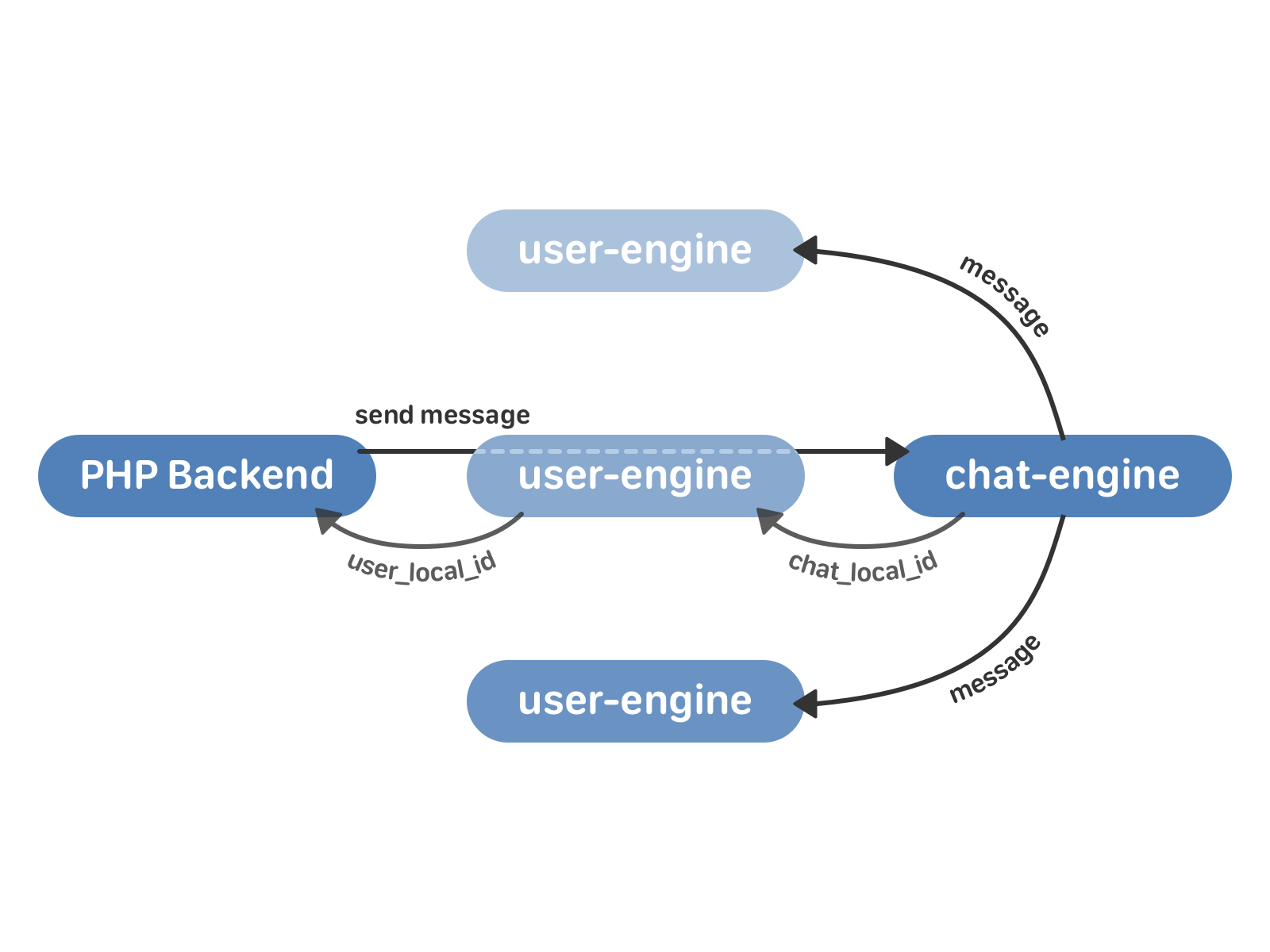
Отправка сообщения в новой схеме выглядит так:
- PHP backend обращается к user-engine с запросом на отправку сообщения.
- user-engine проксирует запрос в нужный экземпляр chat-engine, который возвращает в user-engine chat_local_id — уникальный идентификатор нового сообщения внутри этого чата. Затем chat_engine рассылает сообщение всем получателям в чате.
- user-engine принимает от chat-engine chat_local_id и возвращает в PHP user_local_id — уникальный идентификатор сообщения для этого пользователя. Этот идентификатор затем используется, например, для работы с сообщениями через API.
Но помимо собственно рассылки сообщений нужно реализовать ещё несколько важных вещей:
- Подсписки — это например, самые свежие сообщения, которые Вы видите, открывая список диалогов. Непрочитанные сообщения, сообщения с метками («Важные», «Спам» и т.д.).
- Сжатие сообщений в chat-engine
- Кэширование сообщений в user-engine
- Поиск (по всем диалогам и внутри конкретного).
- Обновление в реальном времени (Longpolling).
- Сохранение истории для реализации кэширования на мобильных клиентах.
Все подсписки — это быстро изменяющиеся структуры. Для работы с ними мы используем Splay-деревья. Такой выбор объясняется тем, что в вершине дерева у нас иногда хранится целый отрезок сообщений из снимка — например, после ночной переиндексации дерево состоит из одной вершины, в которой лежат все сообщения подсписка. Splay-дерево позволяет легко выполнять операцию вставки в середину такой вершины, не думая о балансировке. Кроме того, Splay не хранит лишних данных, и это экономит нам память.
Сообщения подразумевают большой объём информации, в основном текстовой, которую полезно уметь сжимать. При этом важно, чтобы мы могли точно разархивировать даже одно отдельное сообщение. Для сжатия сообщений используется алгоритм Хаффмана с собственными эвристиками — например, мы знаем, что в сообщениях слова чередуются с «не словами» — пробелами, знаками пунктуации, — а также помним о некоторых особенностях использования символов для русского языка.
Поскольку пользователей гораздо меньше, чем чатов, для экономии random-access запросов к диску в chat-engine мы кэшируем сообщения в user-engine.
Поиск по сообщениям реализован как диагональный запрос из user-engine ко всем экземплярам chat-engine, которые содержат чаты этого пользователя. Результаты объединяются уже в самом user-engine.
Что ж, все детали учтены, осталось перейти на новую схему — и желательно так, чтобы пользователи этого не заметили.
Миграция данных
Итак, у нас есть text-engine, который хранит сообщения по пользователям, и два кластера chat-members и member-chats, которые хранят данные о мультичатах и пользователях в них. Как от этого перейти к новым user-engine и chat-engine?
member-chats в старой схеме использовался преимущественно для оптимизации. Мы довольно быстро перенесли нужные данные из него в chat-members, и далее в процесе миграции он уже не участвовал.
Очередь за chat-members. Он включает 100 экземпляров, в то время как chat-engine — 4 тысячи. Для переливки данных нужно привести их в соответствие — для этого chat-members разбили на те же 4 тысячи экземпляров, а после включили чтение бинлога chat-members в chat-engine.
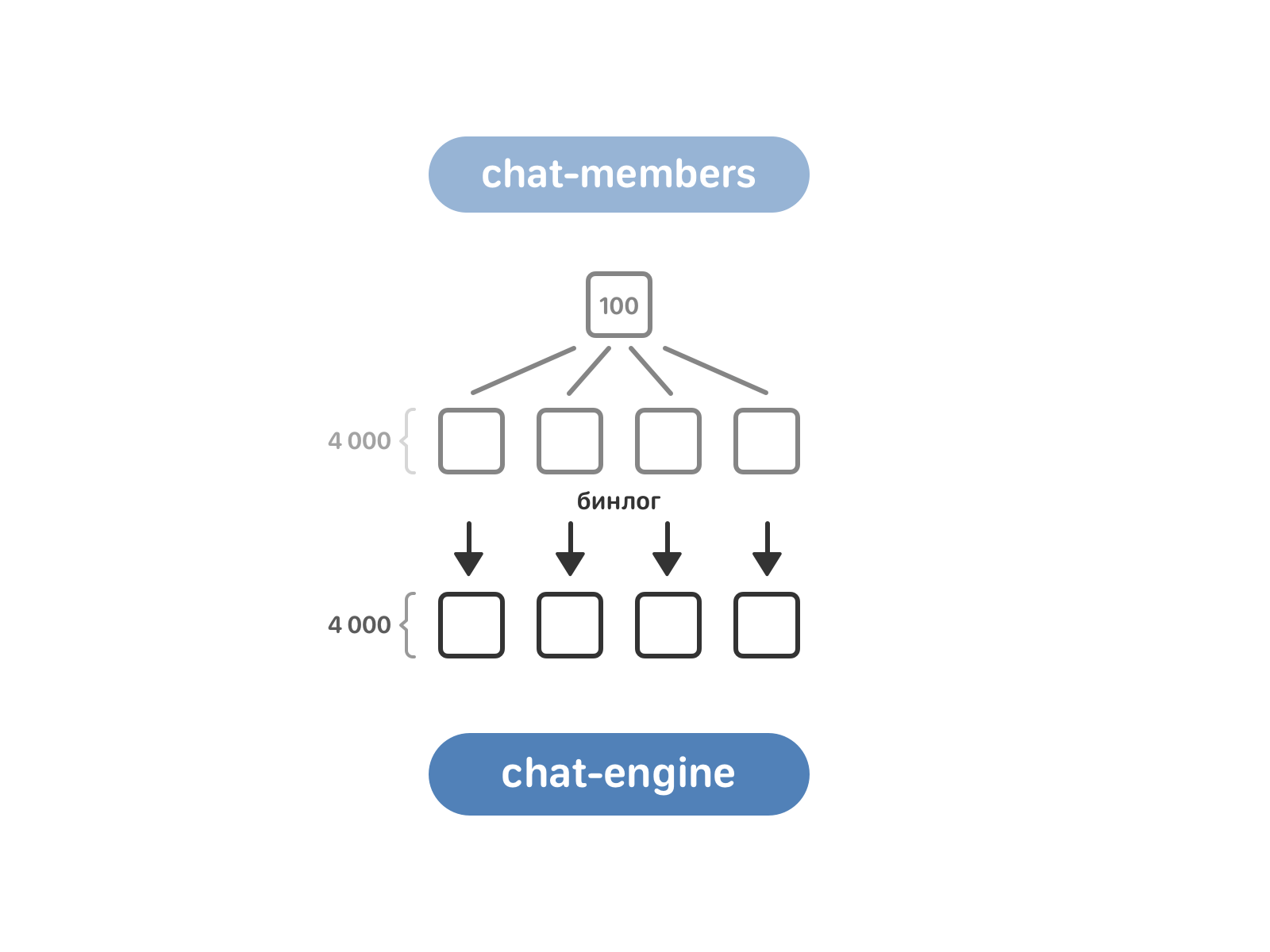
Теперь chat-engine знает о мультичатах из chat-members, но ему пока ничего не известно о диалогах с двумя собеседниками. Такие диалоги лежат в text-engine с привязкой к пользователям. Здесь мы забирали данные «в лоб»: каждый экземпляр chat-engine запрашивал у всех экземпляров text-engine, есть ли у них нужный ему диалог.
Отлично — chat-engine знает, какие есть мультичаты, и знает, какие есть диалоги.
Нужно объединить сообщения в мультичатах — так, чтобы в итоге для каждого чата получить список сообщений в нём. Сначала chat-engine забирает из text-engine все сообщения пользователей из этого чата. В некоторых случаях их довольно много (до сотни миллионов), но за очень редким исключением чат полностью помещается в оперативную память. Мы имеем неупорядоченные сообщения, каждое в нескольких копиях — ведь вытаскиваются они все из разных экземпляров text-engine, соответствующих пользователям. Задача в том, чтобы отсортировать сообщения и избавиться от копий, которые занимают лишнее место.
У каждого сообщения есть timestamp, содержащий время отправки, и текст. Используем время для сортировки — помещаем указатели на самые старые сообщения участников мультичата и сравниваем хэши от текста предполагаемых копий, двигаясь в сторону увеличения timestamp. Логично, что у копий будут совпадать и хэш, и timestamp, но на практике это не всегда так. Как Вы помните, синхронизация в старой схеме осуществлялась силами PHP — и в редких случаях время отправки одного и того же сообщения отличалось у разных пользователей. В этих случаях мы позволяли себе редактировать timestamp — обычно, в пределах секунды. Вторая проблема — разный порядок сообщений для разных получателей. В таких случаях мы допускали создание лишней копии, с разными вариантами порядка для разных пользователей.
После этого данные о сообщениях в мультичатах направляются в user-engine. И здесь возникает неприятная особенность импортированных сообщений. В нормальном режиме работы сообщения, которые приходят в движок, упорядочены строго по возрастанию user_local_id. Импортированные из старого движка в user-engine сообщения теряли это полезное свойство. При этом для удобства тестирования нужно уметь быстро к ним обращаться, что-то в них искать и добавлять новые.
Для хранения импортированных сообщений мы используем особенную структуру данных.
Она представляет собой вектор размера , где все — различны и упорядочены по убыванию, с особым порядком элементов. В каждом отрезке с индексами элементы отсортированы. Поиск элемента в такой структуре выполняется за время через бинарных поисков. Добавление элемента выполняется амортизированно за .
Итак, мы разобрались с тем, как переливать данные из старых движков в новые. Но этот процесс занимает несколько дней — и вряд ли на эти дни наши пользователи бросят привычку писать друг другу. Чтобы не потерять сообщения за это время, мы переключаемся на схему работы, которая задействует и старые, и новые кластеры.
Запись данных идёт в chat-members и user-engine (а не в text-engine, как при нормальной работе по старой схеме). user-engine проксирует запрос к chat-engine — и здесь поведение зависит от того, смержен уже этот чат или еще нет. Если чат еще не смержен, chat-engine не записывает сообщение к себе, и его обработка происходит только в text-engine. Если чат уже смержен в chat-engine, он возвращает в user-engine chat_local_id и рассылает сообщение всем получателям. user-engine проксирует все данные в text-engine — чтобы в случае чего мы всегда могли откатиться назад, имея все актуальные данные в старом движке. text-engine возвращает user_local_id, который user-engine сохраняет у себя и возвращает в бэкенд.
В итоге процесс перехода выглядит так: подключаем пустые кластеры user-engine и chat-engine. chat-engine читает весь бинлог chat-members, затем запускается проксирование по схеме, описанной выше. Переливаем старые данные, получаем два синхронизированных кластера (старый и новый). Остается только переключить чтение с text-engine на user-engine и отключить проксирование.
Результаты
Благодаря новому подходу улучшились все метрики качества работы движков, решены проблемы с консистентностью данных. Теперь мы можем быстрее внедрять новые фичи в сообщениях (и уже начали это делать — увеличили максимальное число участников чата, реализовали поиск по пересланным сообщениям, запустили закреплённые сообщения и подняли лимит на общее число сообщений у одного пользователя).
Изменения в логике действительно грандиозные. И хочется отметить, что это не всегда означает целые годы разработки огромной командой и мириады строк кода. chat-engine и user-engine вместе со всеми дополнительными историями вроде Хаффмана для сжатия сообщений, Splay-деревьев и структуры для импортированных сообщений — это менее 20 тысяч строк кода. И написали их 3 разработчика всего за 10 месяцев (впрочем, стоит иметь в виду, что все три разработчика — чемпионы мира по спортивному программированию).
Более того, вместо удвоения числа серверов мы пришли к уменьшению их числа наполовину — сейчас user-engine и chat-engine живут на 500 физических машинах, при этом у новой схемы есть большой запас по нагрузке. Мы сэкономили кучу денег на оборудовании — это около $5 млн + $750 тысяч в год за счёт операционных расходов.
Мы стремимся находить лучшие решения для самых сложных и масштабных задач. У нас их предостаточно — и поэтому мы ищем талантливых разработчиков в отдел баз данных. Если Вы любите и умеете решать такие задачи, отлично знаете алгоритмы и структуры данных, приглашаем Вас присоединиться к команде. Свяжитесь с нашим HR, чтобы узнать подробности.
Даже если эта история не про Вас, обратите внимание, что мы ценим рекомендации. Расскажите другу о вакансии разработчика, и, если он успешно пройдёт испытательный срок, Вы получите бонус в размере 100 тысяч рублей.
Комментарии (87)

foxyrus
17.11.2017 15:22+6А что происходит с удаленными сообщениями (или при удалении профиля)?

LexS007
17.11.2017 15:33+2Автоматически пакуются и отправлются ФСБ на хранение)

daggert
17.11.2017 15:55+4Пакуются? В смысле? Вы верно путаете, друг мой, все печатается, подшивается в коллекции и вшивается в личные дела гражданина.

5exi
19.11.2017 11:41Вам смешно. А меня как на сисадмина предприятия пришёл запрос из органов. Предоставить для судебного разбирательства всю переписку сотрудника в печатном виде с 2011 года и распечатать все вложения. (((

sumanai
19.11.2017 16:24и распечатать все вложения. (((
Архивы в шестнадцатеричном виде предоставили?
daggert
19.11.2017 20:05+1О нет, мой товарищ по несчастью, я ничуть не смеюсь. Я распечатывал переписку сотрудника, подшивал, в приемной ставили печать на нитках, я вкладывал все это в папки и отсылал в местное отделение ФСБ.

ilyaplot
17.11.2017 15:39Соц. сети ничего не удаляют. Помечаются как удаленные и все. После удаления есть же возможность восстановить профиль.

bgBrother
17.11.2017 15:56Не раз замечал, что очень старые сообщения с некоторых диалогов «пропадают». Видимо, при определенном количестве сообщений в диалоге их со временем принудительно «удаляют». Вряд ли удаляют физически и полностью, скорее архивируют в другое хранилище для оптимизации основного. Иначе не вижу смысла делать подобное.
Профиль, кстати, нельзя восстановить через пол года после «удаления».khim
17.11.2017 17:51Видимо, при определенном количестве сообщений в диалоге их со временем принудительно «удаляют».
Нет, всё проще. Так как выдавать данные нужно в 100 чаще, чем менять, то всё это хранится, по большей части, в структурах, которые не позволяют данные удалять и вообще как-то менять. При необходимости что-то изменить «сбоку» создаётся структура, которая показывает — что, как, и где изменено.
Однако периодически (иногда — по времени, иногда — при накоплении определённого «процента изменений») всё это выкидывается, «упаковывается» и заменяется на «свежую версию».
Хотите посмотреть как это всё работает локально, в миниатюре? Почитайте и/или поэкспериментрийте с git gc — идея там та же.

dmitryegorov Автор
17.11.2017 21:53Да, есть лимит сообщений на одного пользователя. Но он, как бы так сказать, очень большой) В старом движке он был 10 миллионов на пользователя, в новом подняли до 15 миллионов. Немногие могут похвастаться столь бурной перепиской. По достижении лимита мы отрезаем последние 5 миллионов сообщений.
Grief
18.11.2017 02:10Как происходит процесс «отрезания»? Они становятся навсегда недоступными? В счет 15 миллионов идут «удаленные» сообщения?
General_Failure
18.11.2017 11:12По достижении лимита мы отрезаем последние 5 миллионов сообщений
Про последние — надеюсь опечатка? А то обидно будет строчить-строчить, а потом собеседник вдруг увидит ваши сообщения десятилетней давности вместо свежих
saggid
18.11.2017 12:02Наверное, имелось ввиду последние в том смысле, что самые старые. Самые последние, если идти от самых актуальных к самым старым сообщениям)
dmitryegorov Автор
19.11.2017 11:37Нет, просто недостаточно точное слово, которое можно неправильно понять. По дате — конечно же, самые старые. Аналогичный эффект можно наблюдать на стенах некоторых крупных сообществ с удалением старых постов.
ZeXTeR
19.11.2017 11:42Если я правильно понял, то такой подход применяется потому, что "можем столько хранить" и для того, чтобы "не дергать пользователя лишний раз". Но всё же, не слишком ли большой лимит? На сколько быстро он набирается?
dmitryegorov Автор
19.11.2017 11:46Да, это делается именно для экономии места. В первую очередь в оперативной памяти. Лимит практически недостижим для обычных активных пользователей — у них обычно всего несколько сотен тысяч сообщений за несколько лет использования. Но все же имеется очень небольшое количество людей, у которых личные сообщения представляют собой откровенную мусорку и они упираются в него. Но наши основные «клиенты» этой фичи — это чат-боты.
dmitryegorov Автор
17.11.2017 16:32+2В user-engine ссылки на них cначала помечаются удаленными и в течении 3 недель их можно восстановить. Потом они удаляются из снимков и дальше их можно достать только из бинлогов специальными утилитами. В chat-engine они на текущий момент сохраняются в снимке и дальше. Мы исследовали насколько «похудеет» chat-engine, если вычистить сообщения, на которые больше нет ссылок, но получили, что в ближайшее время это не осмысленно. Задача сложная, а профита немного — мы их и так разово «удалили» когда переезжали со старого движка.
Invisibler
21.11.2017 00:05зато я теперь знаю, кого благодарить за каждый 10-й старый репост в свою барахолку с «неизвестная ошибка»


digore
17.11.2017 15:50Интересно узнать, указанные 500 серверов — это сервера с какими характеристиками?
dmitryegorov Автор
17.11.2017 16:39Узкое место здесь — trade-off между оперативной памятью и нагрузкой на диск. Диски HDD, 8 штук на сервер, оперативку заранее расширили до 128Гб (на один unit).
KirEv
18.11.2017 12:06HDD? SSD не используете? понятное дело гиг SSD дороже раза в 3-4 чем hdd, но скорость чтения\записи выше в разы, hdd в целях экономии $?
dmitryegorov Автор
19.11.2017 11:53В первую очередь это path dependence. Переход на SSD требует достаточно больших разовых кап.вложений, большого количества админского и инженерского труда, поэтому надо сначала хорошо оценить эффект от перехода. Но вообще лично я вижу в переходе на SSD большой потенциал. Кстати, фраза про «скорость» чтения и записи все же не точна. Сама скорость такая же, профит в random-access, где разница несколько порядков. И в этой задаче потенциал большой, а вот люди, которые отдают видео с SSD умеют упираться именно в скорость чтения.
RedQuark
17.11.2017 16:16Удалять сообщения, которые удалили у себя пользователи не пробовали? Почему то уверен, что даже если прислать письменное требование удалить персональные данные, оно будет не выполнено.
KirEv
18.11.2017 12:08возможно ради сохранения структуры индексов, например по прямой ссылке, несколько лет назад удаленные личные фотографии, открывались по прямой ссылке, причем в альбоме и т.п. фотки давным давно нет. Помню скидывал кому нужно пряму ссылку на фото, и картинка просматривалась без авторизаций и т.п., не смотрел работает это сейчас или нет. )

Asm0
20.11.2017 20:08Да, это всё актуально.
Но недавно заметил ещё такую вещь: при преобразовании ссылки на изображение в объект (собственно изображения) для вставки его в диалог, парсер отказывается преобразовывать и оставляет как ссылку. Но происходит это не всегда, так что отловить пока не удалось.

inoyakaigor
17.11.2017 16:47Теперь ясно откуда взялась проблема с чатами, когда заходишь в чат с большим количеством непрочитанных и листая его ближе к концу некоторые сообщения не подгружались. Из-за чего часто терялся контекст беседы. Чтобы их увидеть приходилось обновлять страницу.

nanshakov
17.11.2017 17:13+1«Прочитать подробнее о преимуществах такого подхода можно здесь.» ссылка утеряна

DexterHD
17.11.2017 17:39+5Почитаешь вот такую статью и думаешь: «Какой же фигней я занимаюсь, а ребята клевые штуки пилят».
ArmanPrestige
17.11.2017 18:11+2Однозначно… читаешь и только расстраиваешься :(

TheKnight
17.11.2017 19:47А что мешает самим писать такие штуки? В ВК закрыли набор?
Парсер сволочь, съел тег trollDexterHD
17.11.2017 20:01Отсутсвие фундаментального IT образования, глубоких познаний в алгоритмах и спортивном программировании например?

gudvinr
18.11.2017 00:35Это решается самообразованием и практикой. Практика и взаимодействие с сообществом важнее, чем глубокие знания и изучение университетской программы.
А для того, чтобы пилить классные штуки, строго говоря, спортивное программирование вряд ли пригодится.
MrShoor
18.11.2017 01:02Спортивное программирование учит делать правильную декомпозицию задачи. Смотреть на задачу с нужной стороны. А классные штуки включают эту самую грамотную декомпозицию и красивое решение (хотя тут надо определиться что значит классные штуки). Само собой в продакшне не надо писать код, чтобы через 30 минут было готово, и для продакшна нужны и другие навыки, помимо спортировного программирования, но сам навык спортивного программирования сильно помогает. И вот статья выше — как раз этот случай.
DexterHD
18.11.2017 14:50Под «классными штуками» я тут прежде всего имел ввиду сложные технические решения с прикладным применением математики. А под условной «фигней» стандартные бизнес-проекты на fullstack веб-фреймворках. Самообразование это безусловно хорошо, но рано или поздно упираешься в потолок, когда недостаточно именно фундаментальных знаний, для того, чтобы решать сложные задачи бизнеса, требующие применения математики и знания фундаментальных вещей из области Computer Science и расти дальше.
Когда я начинал программировать на стыке 2000-ных, у меня была только книжка по VB6, и книжка по PHP4, при этом до 2004 года не было интернета. И до настоящего времени не было возможности получить IT образования.
В итоге я дополз до должности тимлида в небольшой компании за 12 лет.
Многие выпускники IT вузов до той же должности добегают за 2-3 года.
При этом я в общем то практически все время занимался «веб-сайтами».
А ребята с фундаментальным образованием занимаются тем что описано выше.
Меня же, даже с сегодняшним багажом опыта и знаний всего начиная от dev заканчивая ops вряд ли возьмут в тот же VK, потому что для меня «алгоритм Хаффмана» и «Spray-деревья» это какие то неимоверные материи, к пониманию которых я даже не смогу подойти. А все знания и опыт полученные за все это время они достаточно поверхностны и не подкреплены фундаментом, т.е. имеют кучу пробелов и недопонимания.
Так что я немного не соглашусь. Без фундаментальных знаний на текущем витке развития IT отрасли скоро можно будет стать разве что эникейщиком. Это в конце 80-ых и в начале 90-ых можно было до всего дойти самому, когда индустрия только зарождалась.Lelushak
18.11.2017 15:30У вас очень радужное представление о качестве современного образования в отечественных(?) IT вузах. Могу вас заверить, что 99% айти выпускников знают про «алгоритм Хаффмана» и «Spray-деревья» не больше вашего, потому что их принципиально нет в курсах, либо они проходится мимолётом. Никаких действительно фундаментальных знаний, кроме основ высшей математики, вы там не получите. А математика закончится за два-два с половиной года и будет её относительно мало.
Не могу, правда, говорить за самые топовые российские университеты, может там дела обстоят получше.DexterHD
18.11.2017 16:28Может быть. Но я сужу по тому образованию что я получил в итоге. Я учился далеко не в лучшем вузе в полнейших ***нях (простите) и не на IT специальность а на автоматизацию технологических процессов, но даже там нам поверхностно давали к примеру «нечеткую логику» и «введение в нейронные сети» на последних курсах. На минуточку это были 2007-2008 годы. И мне всегда казалось что уж в нормальных IT вузах должны преподавать все начиная от двоичной системы заканчивая блокчейном и ML на порядки лучше и глубже чем подобные вещи давали нам (из тех что нам вообще давали).
tangro
19.11.2017 02:23Хаффмана и деревья сейчас дают даже в некоторых школах с мат.уклоном, не говоря уже о всех ИТ-специальностях в вузах.
dmitryegorov Автор
19.11.2017 12:00Вообще, в топовых российский универах сейчас можно получить великолепное образование. Правда, есть одна важная деталь — если этого хотеть. Иногда даже «сильно хотеть». И это не всегда ограничивается только парами, есть развитая система дополнительных возможностей в виде различных семинаров, спец.курсов, кружков, лабораторий, школ, etc. И это касается не только IT. Я вот учился в магистратуре на экономической специальности и там все один в один с точностью до специфики отрасли.
nightwolf_du
20.11.2017 10:27Справедливости ради, в локальном вузе Хаффман был, но в конце первого курса, закрывая первый семестр «языков высокого уровня». Хоть как-то разобралось в предмете (по моим нынешним мерам) на тот момент человека 3-4 из 40.
Обычная очередь давалась где-то там же, очередь с приоритетом до конца 3 курса не встречалась, а дальше я не учился. Префиксное дерево мб один раз встречалось в курсе дискретки на 3ем, мб нет.
«Расширяющиеся деревья» до текущего момента не встречал, но с ними хотя бы после красно-черного идея понятна, расширяется идея перебалансировки.
MrShoor
18.11.2017 00:56Не то чтобы я гуру спортивного программирования, но могу сказать, что этот навык качается. Просто начинайте участвовать и решать задачи, которые решают олимпиадники. Сначала будет тяжко, но вы удивитесь, насколько быстро можно минимально прокачаться в данной теме. Пишите свои велосипеды и изучайте решения других. Изучайте структуры данных, и как они устроены внутри.
Буквально через пару недель будет новогоднее соревнование тут: adventofcode.com
Можете к нему присоединиться, это фаново и весело качать свои навыки на таком соревновании.
А прямо сейччас на этом же сайте можете порешать задачи с предыдущего года. Задачи реально классные.
DexterHD
17.11.2017 20:02+1Я наоборот радуюсь за молодых ребят. Конечно немного печально что сам может быть к такому коду ни когда и не прикоснусь но радует что люди с горящими глазами пилят классные штуки.

impetus
17.11.2017 18:06+1Скажите пожалуйста, я правильно понял, что значительная часть хранимых у вас текстовых данных — это сообщения чат-ботов? Какой примерно общий % от всех сообщений отправлен именно чат-ботами, ну хотя бы примерно, можете сказать?
dmitryegorov Автор
17.11.2017 18:31+1Нет, сам % данных от ботов не такой уж и значительный. Но он вызывает перекосы в распределении нагрузки между инстансами движков и проблемы возникают из-за этого. Подсчитать точную долю чат-ботов мы не можем, т.к. они не размечены и мы не можем автоматическими методами с уверенностью выделить их. А гадать лучше не буду — слишком уж велик шанс сильно ошибиться.

Arris
17.11.2017 21:58А отличить чат-бота от нормального пользователя вы можете? Хотя бы по числу сообщений / минуту.
dmitryegorov Автор
17.11.2017 22:18Бывают, к примеру, очень активные лички групп, которые могут легко превзойти по активности слабенькие чат-боты. Если постараться, то скорее всего можно придумать весьма точное решение этой задачи, но в этом не было необходимости.

lain8dono
17.11.2017 22:48А могли бы сделать api для ботов вместе с добровольно-принудительной возможностью помечать учётки в качестве ботов.
dmitryegorov Автор
19.11.2017 12:04Добровольно-принудительная регистрация — это как-то слишком=) Надо сделать правильные удобные инструменты и лимиты, чтобы создатели ботов сами были заинтересованы пользоваться ими.
lain8dono
19.11.2017 12:38В данном случае это и есть добровольно-принудительно. Хочешь удобные инструменты — регистрируй бота. Хочешь мимикрировать — используй менее удобный api.
На самом деле даже просто возможность отметить аккаунт в качестве бота — уже само по себе достаточно неплохо.
Chaak
18.11.2017 12:07Кстати, думали над оптимизацией чат ботов, что они содержат дублирующиеся сообщения и на этом можно значительно сэкономить?
dmitryegorov Автор
19.11.2017 12:06Еще не думали. Мы не успели исчерпать более простые с точки зрения идеи и реализации оптмизации. Кроме того, частично с этим разберется Хаффман.
impetus
18.11.2017 21:29А вообще, как вы считаете — сущетсвуют ли чаты (в т.ч. групповые), состоящие только из сообщений ботов?
Какова на ваш взляд ценность хранения истории таких чатов, и её стоимость?dmitryegorov Автор
19.11.2017 12:08Понятия не имею, честно. Субъективно, если такие и есть, то едва ли их хоть сколько-нибудь значительное количество. Все активные боты, которые у нас всплывали, общаются со вполне реальными пользователя.
algotrader2013
19.11.2017 13:55Рассматривали ли вариант создания двух типов инстансов: для нормальных людей, и гиперактивных (>100K сообщений, к примеру), и реализации отдельных алгоритмов для таких инстансов?
ananazzz
17.11.2017 18:19-6Просто надо меньше рекламы встраивать в звуки\видео, и всё будет работать как надо.


Hint
18.11.2017 10:01А в каком виде хранятся сообщения? В итоговом html? Или с использованием какой-то своей разметки, и каждый раз при отображении происходит преобразование в html? Или в двух вариантах?
dmitryegorov Автор
19.11.2017 12:10Все хранится в бинарном виде в одном варианте (там, кстати, не только текст же). PHP-код (или даже клиенты) его немного обрабатывают при получении — так, к примеру, сделаны упоминания в чатах.


staspavlov92
19.11.2017 12:11И тем не менее, сообщения ВК работают все хуже и хуже, особенно в мультичатах. Подгрузка новых сообщений часто работает долго или не работает вообще, приходится обновлять страницу. В мобильных клиентах часто пока не отправишь сообщение, не подгрузит, даже при принудительном обновлении диалогов прокруткой вниз. В активных мультичатах, где сообщения пишутся потоуом одновременно хотя бы 5-10 людьми, это сильно мешает. О вечных проблемах с загрузкой вложений я уже молчу, уже почти раз в неделю натыкаюсь на то, что вложения, особенно фото, просто не загружаются.
An_Tux
19.11.2017 12:11Кстати на счёт политики хранения данных и восстановления. Лично около года назад столкнулся с такой бедой, что при покупке симкарты и попытке зарегестрироваться в ВК — мне предложили восстановить доступ к странице ранее привязанной к этому номеру. Вам не кажется, что это огромное упущение? Люди меняют номера и забывают пароли от страниц. Недавно у одной знакомой так взломали старую страницу (привязанный номер уже принадлежал не ей) и шантажировали распространением личной информации, при этом делал это явно не дилетант. А что если человек погиб? Получается его мобильный номер оператор заблокирует через N месяцев и продаст другому человеку, а в соц сетях останется множество личной информации, к которой может получить доступ человек не особо порядочный. Я знаю, что этот вопрос поднимался уже не раз и ранее, но подскажите, если ли какие-то движения в его решении?
dmitryegorov Автор
19.11.2017 12:20Какой-то способ авторизации все равно нужен. Не по отпечатку же пальца и скану сетчатки это делать?) По крайней мере в 2017 году. С таким же успехом у людей могут увести почту, к примеру. Если вы активный пользователь и храните в ВК важные вам данные, то уж проследите, чтобы номер телефона был актуальный. Он не так часто меняется. В крайнем случае страницу можно удалить.
Страницы погибших людей мы умеем блокировать через обращение в поддержку от родственников.An_Tux
19.11.2017 14:17Я не сторонник тенденции глобальной деанонимизации, но думаю тут было бы очень кстати указывать паспортные данные или ещё какой-то дополнительный метод подтверждения личности (перед восстановлением) после длительного простоя страницы (скажем более 2-х месяцев).
На счёт блокировки по обращению, не знал, что такая возможность есть и думаю родственники умерших тем более не знаю этого. Учитывая, что часто им и не до этого, да и возможно они вообще в соц сетях не сидят даже. Опять же строю эти выводы на личном опыте. К сожалению знаю с десяток страниц людей, которые умерли, но страницы не заблокированы уже несколько лет… В таком случае вопрос их активации лишь вопрос времени.
sumanai
19.11.2017 16:29С таким же успехом у людей могут увести почту, к примеру.
Почту можно защитить намного лучше, чем номер телефона, который вообще никак не подконтролен и принадлежит оператору.
В крайнем случае страницу можно удалить.
Этот процесс затянут на полгода или около того, насколько я помню.


dsmv2014
20.11.2017 19:01Сейчас существует возможность прямого подключения дисков по M.2 к FPGA. И это даёт возможность реализации быстрого поиска.

FreakII
20.11.2017 20:10Переписать-то переписали, но вот часть сообщений за 2008-2009 год отображаются как "...". Не сказать, что там что-то особо важное, но все-таки
nightwolf_du
Это всё конечно прекрасно, но специально сейчас зашел в контакт и попытался пролистать историю общения с девушкой с 2015 года. Оооочень медленно подгружает пачки сообщений и оооочень медленно отображает их с скроллируемой области просмотра.
А ведь когда-то быстро работало. Лет пять назад.
ilyaplot
А я считаю, что долгая загрузка старых данных — это нормально, т.к. эти данные практически не востребованы. Хорошо, что они вообще отображаются.
bgBrother
bgBrother
Не уверен, конечно, но скорее всего задержки из-за интеграции кода сообщений в body и отрисовки, а не из-за подгрузки с сервера. Только что через поиск нашел сообщения за февраль 2016 года, зашел в полную переписку и… другие сообщения с этой датой моментально подгружаются.
bgBrother
В одном из мобильных клиентов, кстати, есть функция «В начало переписки», которая так же моментально работает.
dmitryegorov Автор
Как выше уже правильно сказали, в этом виновата не серверная часть. Сама БД достанет их и вернет PHP-коду за доли секунды.
bgBrother
Рассматривали вариант с выгрузкой html-кода «не нужных» сообщений при долгом пролистывании? Если да, какие подводные камни в этом варианте?
dmitryegorov Автор
Не могу ответить с уверенностью на этот вопрос. Я занимаюсь непосредственно базами данных и их использованием. Это уже лучше у фронтендеров спрашивать. Но почти наверняка на это просто не хватает времени. Все же у нас слишком маленькая команда чтобы добраться до всех таких мелочей — кейс довольно редкий. И, как и всегда в таких задачах, есть вопрос что такое «не нужное сообщений». От ответа на него сильно зависит эффективность.
nightwolf_du
Как программист, я понимаю что это фронт-енд наркомания, кэши и всякое такое.
И что тормоза со списком сообщений скорее всего связаны с генерацией пачки тегов, накатыванием на них стилей, циклом рендеринга браузера, постраничным пачечным вытягиваем и простаскиванием всего этого добра через прорву кэшей.
А как пользователь — негодую, что 5 лет назад я в чатиках(речь не только о контакте) мог листать десятки тысяч сообщений, а теперь — сотни с трудом.
khim
Так-то мне тоже не нравится что компьютер, с которым я познакомился в школе (Yamaha КУВТ — целых 128K памяти и ещё 128К видеопамяти… роскошь по тем временам невиданная...) загружал файл в 200K примерно за то же время, что и какой-нибудь Pixel C, имеющий в десять тысяч раз больше памяти и примерно в столько же раз более быстрый процессор… но… перделки важнее — и, увы, я говорю это без сарказма, хотя и с некоторой грустью…
dissdoc
Я могу предположить, что связано это с архивированием старых сообщений.
Можно предположить, что за 2015 год сообщения — это менее актуальные сообщения, чем за 2017, следовательно их можно отложить далеко и надолго. Убрать из кэша или еще откуда (все зависит от архитектуры), а следовательно и запрос к ним требует определенной логики: найти то место, где лежат именно эти сообщения, затем подтянуть сообщения из данного места, достать сообщения за определенный период (вы же на сразу все сообщения за 15ый год получаете), затем взять нужное смещение + дельту на всякий случай, положить в кэш и выдать вам — вот вам и простой по времени
timoshchuk_sergei