Самое главное, что, скорее всего, вам о них просто не сообщат. Как часто вы отправляли ошибки в Microsoft, когда вас об этом просили? :) Пользователи, как правило, либо просто перезапускают приложение,

и это не вносит абсолютно никакой ясности в понимание проблемы. В результате у пользователей формируется негативный опыт от использования вашей программы, а вы не имеете никакой возможности что-то с этим сделать.
Ну а коль на пользователей надежды нет, то придется брать дело в свои руки. Для начала мы знаем, что все исключительные ситуации в своих программах мы можем обработать. Например, в .NET мы можем повесить глобальный обработчик всех эксепшенов. Самое простое, что можно сделать дальше, это писать в лог все эксепшены, которые нам прилетают в этот обработчик. Это уже хоть что-то.
Однако, просто лог сам себя не отошлет, и нам приходится ждать сообщения от пользователя, чтобы узнать о проблеме и попросить его этот лог отправить, а это лишняя трата времени, да и вообще, пользователь может и вовсе не написать. Как вариант, мы можем отправлять наш лог сами по электронной почте, но страшно представить, во что превратится наш почтовый ящик, если нам придет достаточно большое количество оповещений. А это достаточно реально на крупных проектах. Да и вообще, разбирать, что там написано в текстовом лог файле на 100500 строк, не совсем приятное занятие.
В результате мы приходим к тому, что самое адекватное решение — это сервис, который будет крутиться в облаке и принимать информацию о произошедших ошибках, обрабатывать ее, структурировать и показывать нам через web интерфейс в удобном виде. Ну и почему бы нам для себя подобный сервис не написать?
Изначально мы сделали простейший сборщик падений в наших демках, чтобы получать данные об этих падениях, и на их основании исправлять проблемы в наших компонентах, тем самым улучшая их качество. Это были всего лишь кол-стек и имя модуля демки, однако, мы быстро поняли, что этих данных недостаточно, и стали их расширять. В результате в данный момент мы собираем очень подробную информацию об окружении, где произошла ошибка, начиная со списка загруженных библиотек и версии студии и фреймворка, и заканчивая версией ОС и текущей установленной культурой. При этом, если нам надо, мы всегда можем добавить любую дополнительную информацию через механизм CustomData. Для примера, можно посмотреть на тестовый репорт.
Когда информации для нахождения проблемных мест стало достаточно, мы столкнулись с тем, что порой репортов приходит очень много. Ведь, если проблема достаточно тривиальна, то велика вероятность, что много пользователей на нее наткнется. А в такой ситуации мы получаем по репорту от каждого из них. В результате мы имеем кучу репортов, которые если не идентичны, то крайне похожи:
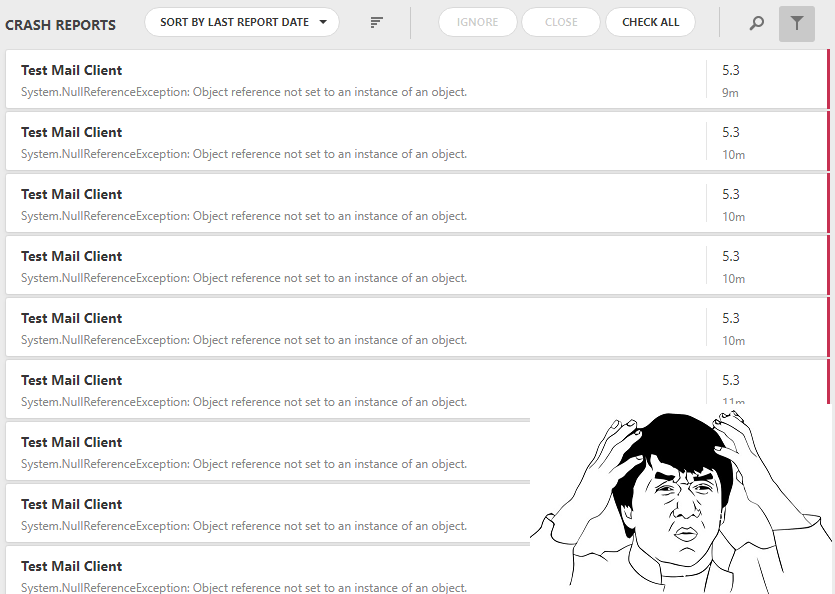
Понятное дело, что работать со всем этим, мягко говоря, затруднительно, плюс, среди всех этих одинаковых репортов могут потеряться и уникальные, оповещающие о других проблемах. Чтобы избавиться от этого, мы реализовали поиск дубликатов по определенному набору ключевых полей и схлопывание их в один репорт:
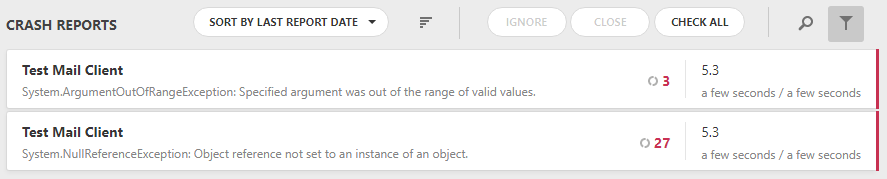
Да, так уже гораздо лучше.
Однако, помимо дубликатов, во входящих оказывалось достаточно много репортов, которые нам просто не интересны, например, это могут быть репорты об уже пофикшеных проблемах. Это подтолкнуло нас к задаче реализации автоматического игнорирования входящих репортов по каким-либо условиям, а условий нам дали уйму: и чтобы по версии можно было игнорировать, и чтобы по ключевым словам в колстеке, и чтобы по определенным строкам колстека, и чтобы ошибка без наших компонентов в колстеке нам не приходили и т.д и т.п. В результате мы выделили 4 основных вида правил игнора, и это покрыло все наши задачи. Вообще, данная тема заслуживает отдельной статьи, поэтому здесь я приведу ссылку на документацию, чтобы можно было составить общее впечатление об этом механизме: Ignoring Filters
В процессе работы с сервисом мы нашли ему еще одно необычное применение: он отлично может помогать отделу поддержки. Нередко пользователи пишут, что у них произошла какая-то проблема, но она воспроизводится только на машине их пользователя, и подебажить или получить какую-то подробную информацию о самой ошибке возможности нет. Или, например, ошибки происходят на программах, которые ограничены в правах и не могут записать лог файл. Во всех этих ситуациях нам успешно помогает Logify, ибо сбор данных о падениях на развернутых приложениях и есть его основная задача.
В результате Logify был внедрен во множество наших продуктов, и сейчас приносит ощутимую пользу. В процессе развития Logify уже явно перестал быть просто проектом для внутреннего пользования, и мы решили выпустить его как отдельный сервис. Он был причесан и представлен публике с переделанным UI сначала в виде бета тестирования, и в данный момент он уже полноценно запущен в продакшен. Так что кому интересно, приглашаю попробовать: Logify. Клиенты доступны на GitHub.
Комментарии (21)

Andrey2008
20.11.2017 17:25Учишь, учишь PVS-Studio использовать. Так ведь нет… :)
void KeyDown(object sender, KeyEventArgs e) { FrameworkElement source = sender as FrameworkElement; if(!IsActive || (sender == null)) return; Dictionary<string, string> properties = CollectCommonProperties(source, e); LogKeyboard(properties, e, false, CheckPasswordElement(e.OriginalSource as UIElement)); }
V3019 Possibly an incorrect variable is compared to null after type conversion using 'as' keyword. Check variables 'sender', 'source'. BreadcrumbsRecorder.cs 86
Видимо следует проверять на null ссылку source, а не sender.
Аналогично:- V3019 Possibly an incorrect variable is compared to null after type conversion using 'as' keyword. Check variables 'sender', 'source'. BreadcrumbsRecorder.cs 94
- V3019 Possibly an incorrect variable is compared to null after type conversion using 'as' keyword. Check variables 'sender', 'source'. BreadcrumbsRecorder.cs 102
- V3019 Possibly an incorrect variable is compared to null after type conversion using 'as' keyword. Check variables 'sender', 'source'. BreadcrumbsRecorder.cs 110
- V3019 Possibly an incorrect variable is compared to null after type conversion using 'as' keyword. Check variables 'sender', 'source'. BreadcrumbsRecorder.cs 118
- V3019 Possibly an incorrect variable is compared to null after type conversion using 'as' keyword. Check variables 'sender', 'source'. BreadcrumbsRecorder.cs 126

mviorno
20.11.2017 17:49Спасибо, поправили (кроме лока на тип — оно так надёжнее будет, чем на статическую переменную полагаться в многопоточной среде).
Andrey2008
20.11.2017 19:22<зануда on> Хочу напомнить всем присутствующим, что продуктивнее не разово что-то проверить и поправить, а использовать статически анализ регулярно. Тогда многие ошибки можно было выявить не в процессе внутреннего тестирования (и последующему фидбека от пользователей), а сразу в ходе написания кода. <зануда off>
Andrey2008
20.11.2017 20:30А что по поводу V3083? Например, здесь:
public bool CopyHandler(int bytesCopied) { .... if (NotifyProgress != null) NotifyProgress(this, EventArgs.Empty); return !isStopped; }
V3083 Unsafe invocation of event 'NotifyProgress', NullReferenceException is possible. Consider assigning event to a local variable before invoking it. Zip.cs 1035
Или:
protected override bool RaiseConfirmationDialogShowing(ReportConfirmationModel model) { if(ConfirmationDialogShowing != null) { ConfirmationDialogModel actualModel = model as ConfirmationDialogModel; if(actualModel == null) return false; ConfirmationDialogEventArgs args = new ConfirmationDialogEventArgs(actualModel); ConfirmationDialogShowing(this, args); return args.Handled; } return false; }
V3083 Unsafe invocation of event, NullReferenceException is possible. Consider assigning event to a local variable before invoking it. LogifyClient.cs 169
Здесь больше шанс возникновения NullReferenceException, так как проверка и использование разнесены дальше.
Далее- V3083 Unsafe invocation of event, NullReferenceException is possible. Consider assigning event to a local variable before invoking it. LogifyClient.cs 156
- V3083 Unsafe invocation of event 'FocusChanged', NullReferenceException is possible. Consider assigning event to a local variable before invoking it. BreadcrumbsRecorder.cs 391
- V3083 Unsafe invocation of event 'PropertyChanged', NullReferenceException is possible. Consider assigning event to a local variable before invoking it. ReportConfirmationModel.cs 55
- V3083 Unsafe invocation of event, NullReferenceException is possible. Consider assigning event to a local variable before invoking it. LogifyClientBase.cs 171
- V3083 Unsafe invocation of event, NullReferenceException is possible. Consider assigning event to a local variable before invoking it. LogifyClientBase.cs 183
- V3083 Unsafe invocation of event, NullReferenceException is possible. Consider assigning event to a local variable before invoking it. LogifyClientBase.cs 192
mviorno
20.11.2017 23:18Андрей, ИМХО, подобная проверка уже на грани абсурда. Следующий шаг — запретить напрямую обращаться к свойствам объекта, а разрешить только брать значения в локальную переменную — вдруг свойство из соседней нитки кто-нить занулит между обращениями. Принцип разумной достаточности никто не отменял.
mayorovp
21.11.2017 14:31+1Тут прикол в том, что из коробки любые события потокобезопасны если их правильно вызывать, и кто-то может рассчитывать на это их свойство — а тут гонка. Обычные же поля класса таких гарантий из коробки не имеют.
artangeline
20.11.2017 20:10А в дальнейшем планируется расширение функционала или будет работать узкопрофильно?
Mirimon Автор
20.11.2017 20:11Да, конечно планируется. Продукт активно развивается. А какой функционал требуется?
alexey_prokopyev
21.11.2017 09:49Не планируете сделать оффлайн версию, для использования в интранетах?
Mirimon Автор
21.11.2017 10:05В ближайших планах нет, но мы эту задачу в голове держим, так как иногда запросы приходят.
worldnomad
21.11.2017 10:07Пишу как простой пользователь.
Дело не в отсутствии какой-то обратной связи. Дело в том, что разработчикам наплевать, я так думаю. Не было бы наплевать — просто делали бы простые и понятные формы обратной связи. Потом автоматический отсев, потом, полуавтоматический. И уже отсеянное читали бы живые люди. И исправляли.
Я не верю, что разработчиков по-настоящему интересуют проблемы пользователей. Да и собственные программы тоже. Ну, перестанут покупать эту говно-программу, напишем другую, поскольку мы всё равно знаем лучше, что ИМ (презрительно) нужно. Яркий пример отношение мозиллы к своему браузеру. Как до них не доходит, что в эти маленькие крестики, закрывающие вкладки просто трудно попасть мышкой — я не понимаю. Почему они не дают пользователю изменить размеры значков, шрифт интерфейса — я не понимаю.
Самое плодотворное общение у меня было с разработчиком mkvtoolnix. Вменяемый человек, что тут скажешь.
Почему media player classic не могут научить понимать, что если человек делает скриншот в плеере, и скриншот этот приходится на ту же секунду, что и предыдущий, то не загружай тупые окошки и не задавай тупых вопросов о перезаписи уже существующего файла, а просто присвой новый номер (через дефис, например), если уж не понимаешь, что есть десятые и сотые и тысячные доли секунды.
Акронис. Если уж человека угораздило один раз сделать копию в другую папку, на другой диск, то не надо всякий раз ее опять там создавать в случае, если ты создаешь новую копию после восстановления предыдущей.
O&O Defrag. Ваша программа не умеет дефрагментировать MFT. Не умеет! И никогда не умела. Хотя вы годами заявляете обратное.
Privazer. Где ты хранишь настройки, чтобы не ставить всякий раз нужные галки??
RegOrganizer. Почему ты спрашиваешь дважды после завершения очистки реестра закрыть это окно или нет? У меня, что есть варианты? Они там что, вообще ещё какие-то возможны, другие варианты?
и т.д.Sky3d
21.11.2017 10:50Яркий пример отношение мозиллы к своему браузеру. Как до них не доходит, что в эти маленькие крестики, закрывающие вкладки просто трудно попасть мышкой — я не понимаю.
Между прочим в новом Firefox Quantum с крестиками все нормально, да и еще много чего
DRVTiny
21.11.2017 11:13Согласен. Отсутствие позитивной обратной связи с пользователями приводит к тому, что разработчики игнорируют гораздо более критичные ошибки, нежели просто падения приложения. После падения программу действительно несложно запустить снова — и если в ней в момент падения не редактировалось что-то важное, а само падение было результатом стечения маловероятных обстоятельств, а не какого-то серьёзного бага, который почему-то просочился через тестировщиков — пользователь забудет об этом досадном инциденте и будет продолжать пользоваться приложением дальше. А вот если функционал приложения реализован неудобно, нелогично, поведение приложения попросту раздражает/бесит пользователя систематически — вы ничего не получите своим Logify, но если для приложения отсутствует удобная система обратной связи, позволяющая пользователю понять, что его обращение действительно важно для разработчиков (а не ушло в /dev/null), то вы должны быть как минимум Microsoft'ом, чтобы иметь полное моральное право просто «забить на тупых хомячков» и сосредоточиться исключительно на эксплуатации оных в качестве бесплатных бета-тестеров с использованием Logify…
Mirimon Автор
21.11.2017 11:21Так никто же и не спорит, мы тут тоже за все хорошее и против всего плохого. Только работать надо в комплексе. И стабильность важна и юзабилити важно. Очень удобная, но постаянно глючащая программа тоже мало радости приносит. И если повлиять на UI и обратную связь у сторонних приложений мы никак не можем, то предоставить инструмент, позволяющий улучшить стабильность уже в наших силах.
SirEdvin
Зачем, если есть sentry? Всмысле, есть ли у него существенные отличия?
Mirimon Автор
Настолько мощный механизм автоматических игноров, который я описывал в статье, есть только у нас. Без него нам бы пришлось не сладко, ибо очень легко потонуть в потоке ненужных репортов. Это из крупного, далее уже по мелочам.
SirEdvin
В случае sentry это делается грамотными сообщениями об ошибке и типами ошибок, что на самом деле, довольно гибко.
Mirimon Автор
У нас внутри были ситуации, когда такое не помогло бы. Мало того, я так понимаю, они их обрабатывают, т.е. они влияют на месячное ограничение количества репортов. Наши же фильтры репорты отбрасывают и они не выедают лимит.
Mirimon Автор
Ну а если смотреть на мелочи, то это и кастомизация темплейтов нотификаций, это CustomFields, это возможность объединить в отдельном блоке самую важную информацию: Favorites. У Sentry нет своего .NET клиента (мелочь, а неприятно), нет автоматической подписки на необработанные эксепшены (написал один раз StartExceptionsHandling и забыл).
Ну и, чисто субъективно, нам наша деталька кажется более удобной :)
SirEdvin
Кастомные теги в sentry — есть.
Опять же таки, не уверен, насколько нужна эта фича при походе sentry, потому что у вас просто много тегов, в sentry дополнительные теги нужно добавлять.
Таки есть.
Опять же, есть.
:)
Mirimon Автор
Это у нас называется CustomData у клиентов. CustomFields это чисто серверная фича, которая позволяет настроить ссылку на абсолютно любое свойство в репорте.
Так просто удобнее просматривать репорт, если требуется прежде всего обращать внимание на строго определенные поля, а все остальные уже смотрятся после.
Это клиент от community, а не от Sentry.
В .NET?