
Нейронные сети глубокого обучения достигли больших успехов в распознавании образов. В тоже время текстовые капчи до сих пор используются в некоторых известных сервисах бесплатной электронной почты. Интересно смогут ли нейронные сети глубоко обучения справится с задачей распознавания текстовой капчи? Если да то как?
Что такое текстовая капча?
Капча (англ. “CAPTCHA”) — это тест на “человечность”. То есть задача, которую легко решает человек, в то время как для машины эта задача должна быть сложной. Зачастую используется текст со слипшимися буквами, пример на картинке ниже, также картинку дополнительно подвергают оптическим искажениям.

Капча, как правило, используется на странице регистрации для защиты от ботов рассылающих спам.
Полносверточная нейронная сеть
Если буквы “слиплись”, то их обычно очень трудно разделить эвристическими алгоритмами. Следовательно, нужно искать каждую букву в каждом месте картинки. С этой задачей справится полносверточная нейронная сеть. Полносверточная сеть — сверточная сеть без полносвязного слоя. На вход такой сети подается изображение, на выходе она выдает тоже изображение или несколько изображений (карты центров).

Количество карт центров равно длине алфавита символов использованных в определенной капче. На картах центров отмечаются центры букв. Масштабное преобразование, которое в сети происходит из-за наличия пуллинг слоев, учитывается. Ниже показан пример карты символа для символа “D”
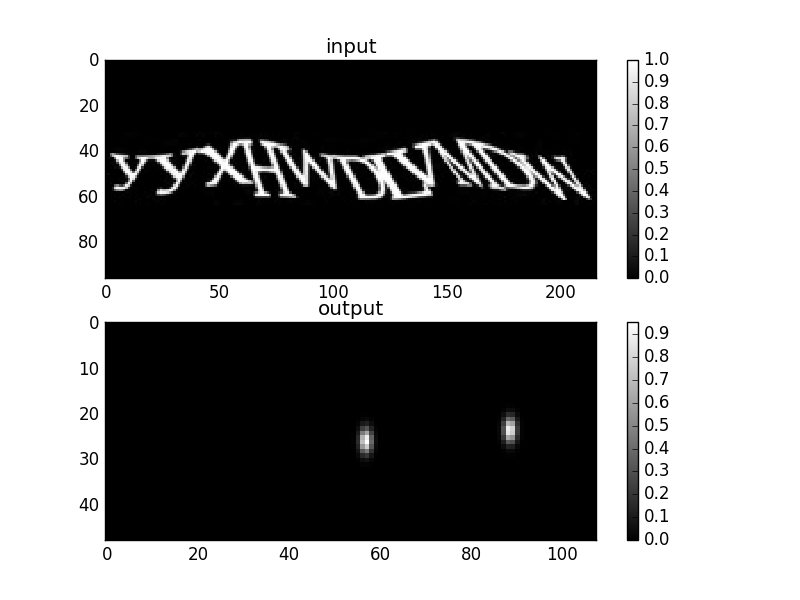
В данном случае используются сверточные слои с паддингом так, чтобы размер изображений на выходе сверточного слоя равнялся размеру изображений на входном слое. Профиль пятна на карте символа задается двумерной гауссовой функцией с ширинами 1.3 и 2.6 пикселей.
Первоначально полносверточная сеть была проверена на символе “R”:
Для проверки применялась небольшая сеть с 2мя пуллингами, натреннированная на CPU. Убедившись, что идея хоть как то работает, я приобрел б/у видеокарту Nvidia GTX 760, 2GB. Это дало мне возможность тренировать более крупные сети для всех символов алфавита, а также ускорило обучение (примерно в 10 раз). Для тренировки сети использовалась библиотека Theano, на текущий момент уже не поддерживаемая.
Тренировка на генераторе
Разметить большой датасет вручную казалось делом долгим и трудозатратным, поэтому было решено генерировать капчи специальным скриптом. При этом карты центров генерируются автоматически. Мною был подобран шрифт, используемый в капче для сервиса Hotmail, сгенерированная капча визуально была похожа по стилю на реальные капчи:

Финальная точность тренировки на сгенерированных капчах, как оказалось, в 2 раза ниже, по сравнению с тренировкой на реальных капчах. Вероятно, такие нюансы как степень пересечения символов, масштаб, толщина линий символов, параметры искажения и т. п., важны, и в генераторе эти нюансы воспроизвести не удалось. Сеть тренированная на сгенерированных капчах давала точность на реальных капчах около 10%, точность — какой процент капч распознался правильно. Капча считается распознанной, если все символы в ней распознаны правильно. В любом случае этот эксперимент показал, что метод рабочий, и требуется повысить точность распознавания.
Тренировка на реальном датасете
Для ручной разметки датасета реальных капч был написан скрипт на Matlab с графическим интерфейсом:

Здесь кружочки можно расставлять и двигать мышкой. Кружочком отмечается центр символа. Ручная разметка занимала 5-15 часов, однако есть сервисы, где за не большую плату размечают вручную датасеты. Однако, как оказалось, сервис Amazon Mechanical Turk не работает с российскими заказчиками. Разместил заказ на разметку датасета на известном сайте фриланса. К сожалению, качество разметки было не идеальным, поправлял разметку самостоятельно. Кроме того, поиск исполнителя занимает время (1 неделя) и также это показалось дорого: 30 долларов за 560 размеченных капч. От данного способа отказался, в итоге пришел к использованию сайтов ручного распознавания капч, где самая низкая стоимость 1 доллар за 2000 капч. Но полученный ответ там — это строка. Таким образом, ручной расстановки центров избежать не удалось. Более того, исполнители в таких сервисах допускают ошибки или вовсе действуют недобросовестно, печатая произвольную строку в ответе. В итоге приходилось проверять и исправлять ошибки.
Более глубокая сеть
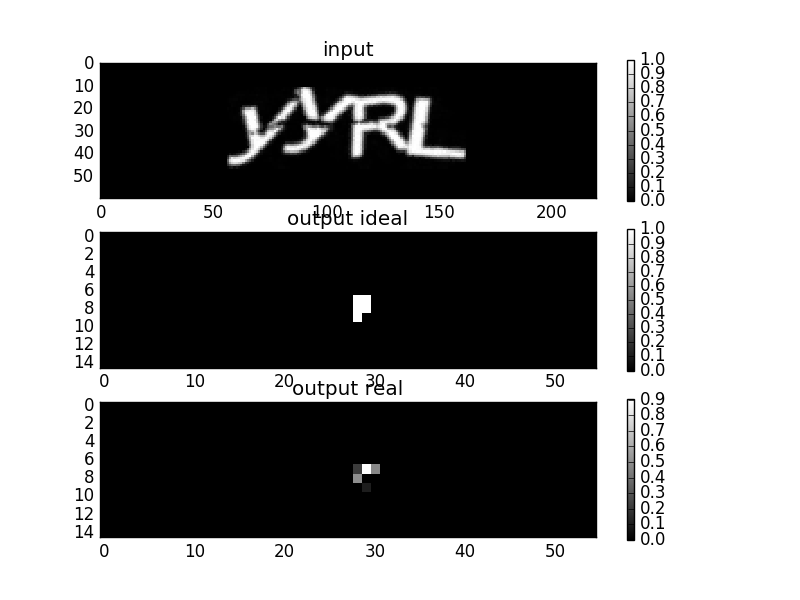
Очевидно точность распознавания была недостаточна, поэтому возник вопрос подбора архитектуры. Меня интересовал вопрос “видит” ли один пиксель на выходном изображении весь символ на входном изображении:

Таким образом, мы рассматриваем один пиксель на выходном изображении, и есть вопрос: значения каких пикселей на входном изображении влияют на значения этого пикселя? Я рассуждал так: если пиксель видит не весь символ, то используется не вся информация о символе и точность хуже. Для определения размера этой области видимости (будем называть ее так), я провел следующий эксперимент: установил все веса сверточных слоев равным 0.01, а смещения равным 0, на вход сети подается изображение, в котором значения всех пикселей равны 0 кроме центрального. В результате на выходе сети получается пятно:

Форма данного пятна близка к форме гауссовой функции. Форма получившегося пятна вызывает вопрос, почему пятно круглое, тогда как ядра сверток в сверточных слоях квадратные? (В сети использовались ядра сверток 3x3 и 5x5). Мое объяснение такое: это похоже на центральную предельную теорему. В ней, как и здесь, присутствует стремление к гауссовому распределению. Центральная предельная теорема утверждает, что для случайных величин, даже с разными распределениями, распределение их суммы равно свертке распределений. Таким образом, если мы сворачиваем любой сигнал сам с собой много раз, то по центральной предельной теореме результат стремится к гауссовой функции, а ширина гауссовской функции растет как корень из количества сверток (слоев). Если для такой же сети с константными весами посмотреть, где в выходном изображении значения пикселей больше нуля, то получается все таки квадратная область (см. рисунок ниже), размер этой области пропорционален сумме размеров сверток в сверточных слоях сети.

Раньше думал, что из-за ассоциативного свойства свертки две последовательные свертки 3x3 эквивалентны свертке 5x5 и потому, если свернуть 2 ядра 3x3 получится одно ядро 5x5. Однако, потом пришел к выводу, что это не эквивалентно хотя бы потому, что у двух сверток 3x3 9*2=18 параметров, а у одной 5x5 25 параметров, таким образом, у свертки 5x5 больше степеней свободы. В итоге, на выходе сети получается гауссова функция с шириной меньше суммы размеров сверток в слоях. Здесь ответил на вопрос какие пиксели на выходе подвержены влиянию одного пикселя на входе. Хотя изначально вопрос ставился обратный. Но оба вопросы эквивалентны, что можно понять из рисунка:

На рисунке можно представить, что это вид на изображения с боку или, что у нас высота изображений равна 1. Каждый из пикселей A и B имеет свою зону влияния на выходном изображении (обозначены синим цветом): для А это D-C, для B это C-E, на значения пикселя C влияют значения пикселей A и B и значения всех пикселей между A и B. Расстояния равны: AB = DC = CE (с учетом масштабирования: в сети присутствуют пуллинг слои, поэтому входное и выходное изображения имеют разные разрешения). В итоге, получается следующий алгоритм нахождения размера области видимости:
- задаем константные веса в сверточных слоях, весам-смещениям задаем значения 0
- на вход подаем изображения с одним ненулевым пикселем
- получаем размер пятна на выходе
- умножаем этот размер на коэффициент учитывающий разное разрешение входного и выходного слоя (например, если у нас 2 пулинга в сети, то разрешение на выходе в 4 раза меньше, чем на входе, значит этот размер надо умножать на 4).
Чтобы посмотреть какие признаки сеть использует, провел следующий эксперимент: в тренированную сеть подаем изображение капчи, на выходе получаем изображения с отмеченными центрами символов, из них выбираем какой-нибудь задетектированный символ, на изображениях-картах центров оставляем ненулевой только ту карту, которая соответствует рассматриваемому символу. Такой выход сети запоминаем как
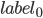 , затем градиентным спуском минимизируем функцию:
, затем градиентным спуском минимизируем функцию: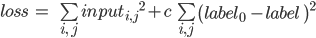
Здесь
 — входное изображение сети,
— входное изображение сети, 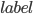 — выходные изображения сети,
— выходные изображения сети,  — некоторая константа, которая подбирается экспериментально (
— некоторая константа, которая подбирается экспериментально ( ). При такой минимизации вход и выход сети считаются переменными, а веса сети константами. Начальное значение переменной это изображение капчи, является начальной точкой оптимизации алгоритма градиентного спуска. При такой минимизации мы уменьшаем значения пикселей на входе изображения, при этом сдерживаем значения пикселей на выходном изображении, в результате оптимизации на входном изображении остаются только те пиксели, которые сеть использует в распознавании символа.
). При такой минимизации вход и выход сети считаются переменными, а веса сети константами. Начальное значение переменной это изображение капчи, является начальной точкой оптимизации алгоритма градиентного спуска. При такой минимизации мы уменьшаем значения пикселей на входе изображения, при этом сдерживаем значения пикселей на выходном изображении, в результате оптимизации на входном изображении остаются только те пиксели, которые сеть использует в распознавании символа. Что получилось:
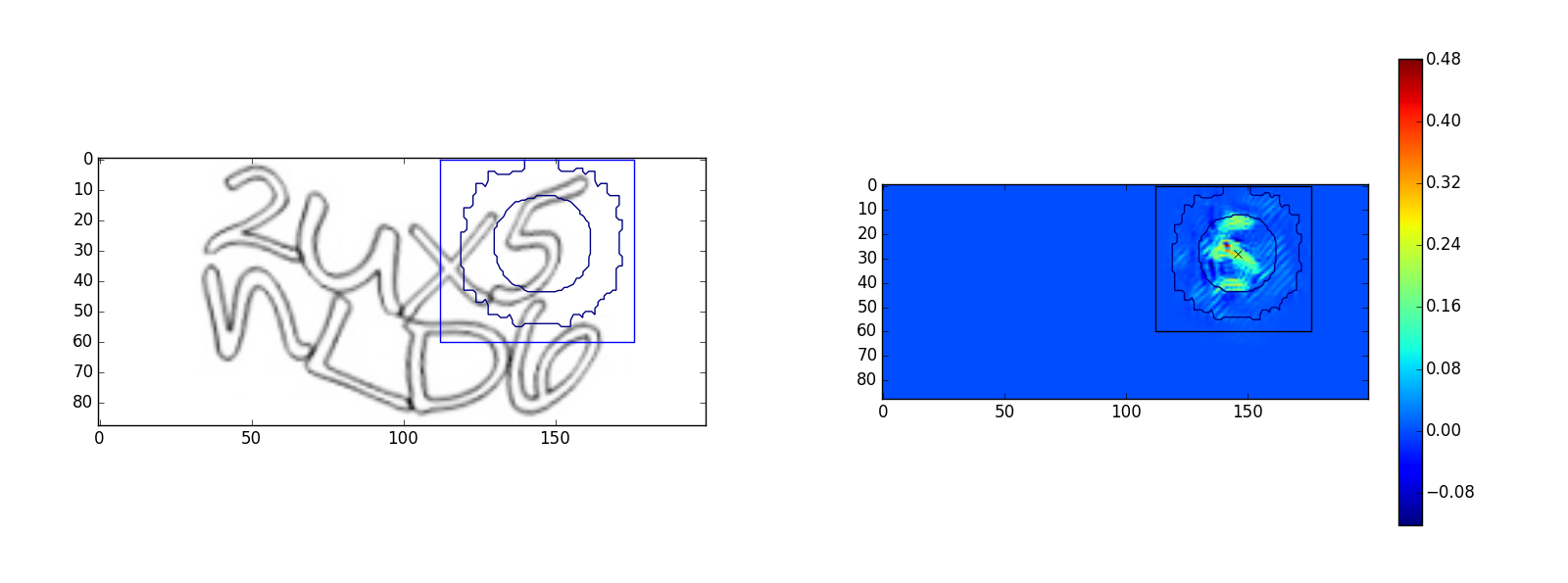
Для символа “2”:

Для символа “5”:
Для символа “L”:

Для символа “u”:
Изображения слева — исходные изображения капч, изображения справа — это оптимизированное изображение
. Квадратом на изображениях обозначена область видимости output>0, окружности на рисунке — это линии уровня Гауссовой функции области видимости. Малая окружность — уровень 35% от максимального значения, большая окружность — уровень 3%. Примеры показывают, что сеть видит в пределах своей области видимости. Однако, у символа “u” наблюдается выход за область видимости, возможно это частичное ложное срабатывание на символ “n”. Было проведено много экспериментов с архитектурой сети, чем более глубокая и широкая сеть, тем более сложные капчи она может распознавать, самой универсальной архитектурой оказалась следующая:
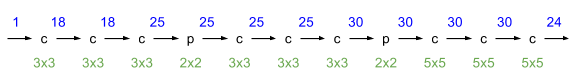
Синим цветом, поверх стрелок, показано количество изображений (feature maps). c- сверточный слой, p — max-pooling слой, зеленым цветом внизу показаны размеры ядер. В сверточных слоях используются ядра 3x3 и 5x5 без strade, пуллинг слой имеет патч 2x2. После каждого сверточного слоя есть ReLU слой (на рисунке не показан). На вход подается одно изображение, на выходе получется 24 (количество символов в алфавите). В сверточных слоях паддинг подобран таким образом, чтобы на выходе слоя размер изображения был таким же как и на входе. Паддинг добавляет нули, однако это никак не влияет на работу сети, потому что значение фонового пикселя капчи — 0, так как всегда берется негативное изображение (белые буквы по черному фону). Паддинг лишь незначительно замедляет работу сети. Так как в сети 2 пуллинг слоя, то разрешение изображения на выходе в 4 раза меньше разрешения изображения на входе, таким образом каждый пуллинг уменьшает разрешение в 2 раза, например, если на входе у нас капча размером 216x96 то на выходе будет 24 изображения размером 54x24.
Улучшения
Переход от решателя SGD к решателю ADAM дал заметное ускорение обучения, и финальное качество стало лучше. Решатель ADAM импортировал из модуля lasagne и использовал внутри theano-кода, параметр learning rate ставил 0.0005, регуляризация L2 была добавлена через градиент. Было замечено, что от тренировки к тренировке результат получается разный. Объясняю это так: алгоритм градиентного спуска застревает в недостаточно оптимальном локальном минимуме. Частично поборол это следующим образом: запускал тренировку несколько раз и выбирал несколько самых лучших результатов, затем продолжал их тренировать еще несколько эпох, после из них выбирал один лучший результат и уже этот единственный лучший результат долго тренировал. Таким образом удалось избежать застревания в недостаточно оптимальных локальных минимумах и финальное значение функции ошибок (loss) получалась достаточно малым. На рисунке показан график — эволюция значения функции ошибок:
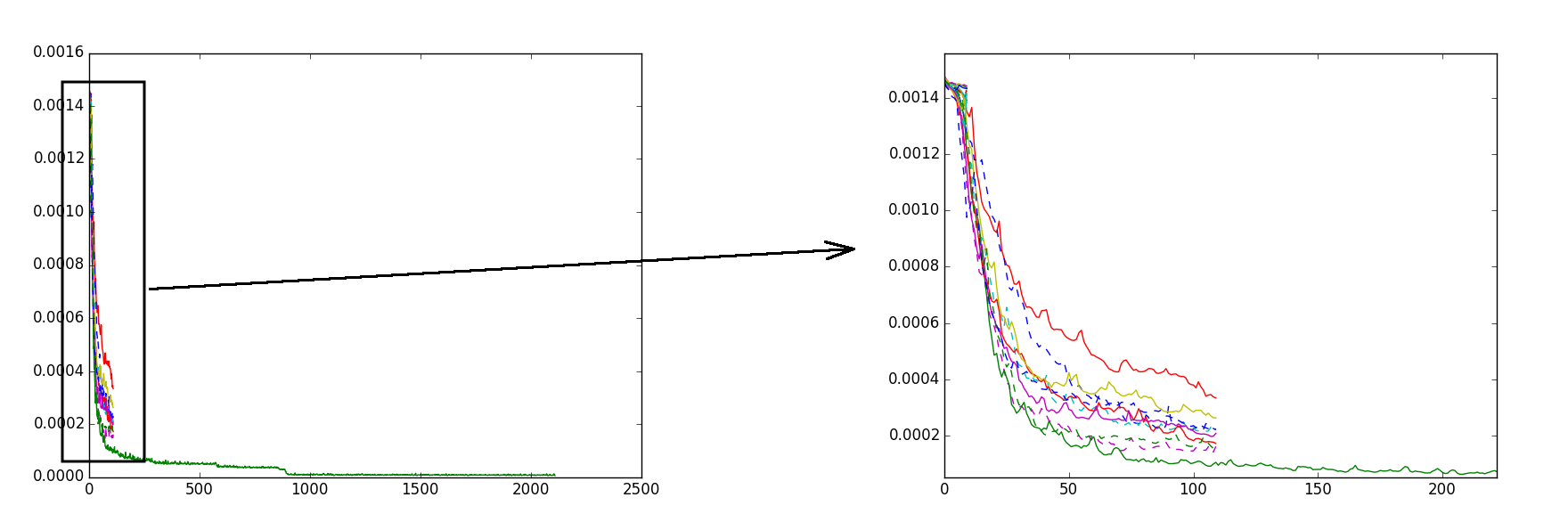
По оси x — число эпох, по оси y — значение функции ошибок. Разными цветами показаны разные тренировки. Порядок обучения примерно такой:
1) запускаем 20 тренировок по 10 эпох
2) выбираем 10 лучших результатов (по наименьшему значению loss) и тренируем их еще 100 эпох
3) выбираем один лучший результат и продолжаем тренировать его еще 1500 эпох.
Это занимает около 12 часов. Конечно, для экономии памяти, данные тренировки проводились последовательно, например, в пункте 2) 10 тренировок проводились последовательно одна за другой, для этого провел модификацию решателя ADAM от Lasagne, чтобы иметь возможность сохранять и загружать состояние решателя в переменные.
Разбиение датасета на 3 части позволяло отслеживать переобучение сети:
1 часть: тренировочный датасет — исходный, на котором сеть обучается
2 часть: тестовый датасет, на котором сеть проверяется в процессе тренировки
3 часть: отложенный датасет, на нем проверяется качество обучения после тренировки
Датасеты 2 и 3 небольшие, в моем случае было по 160 капч в каждом, также по датасету 2 определяется оптимальный порог срабатывания, порог который устанавливается на выходное изображение. Если значение пикселя превышает порог, то в данном месте обнаружен соответствующий символ. Обычно оптимальное значение порога срабатывания находится в диапазоне 0.3 — 0.5. Если точность на тестовом датасете значительно ниже, чем точность на тренировочном датасете — это значит что произошло переобучение и тренировочный датасет необходимо увеличить. В случае, если эти точности примерно одинаковы, но не высокие, то архитектуру нейронной сети нужно усложнять, а тренировочный датасет увеличивать. Усложнять архитектуру сети можно двумя путями: увеличивать глубину или увеличивать ширину.
Предварительная обработка изображений также повышала точность распознавания. Пример предобработки:
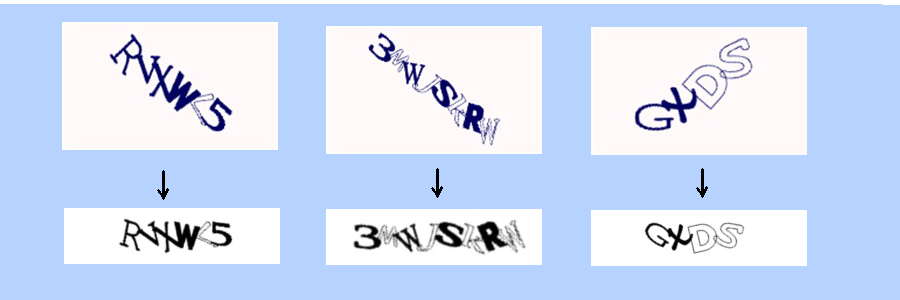
В данном случае методом наименьших квадратов найдена средняя линия повернутой строки, производится поворот и масштабирование, масштабирование проводится по средней высоте строки. Сервис Hotmail часто делает разнообразные искажения:



Эти искажения необходимо компенсировать.
Неудачные идеи
Всегда интересно почитать про чужие неудачи, опишу их здесь.
Существовала проблема малого датасета: для качественного распознавания требовался большой датасет, который требовалось разметить вручную (1000 капч). Мной предпринимались различные попытки каким-то образом обучить сеть качественно на малом датасете. Делал попытку обучать сеть на результатах распознавания другой сети. при этом выбирал только те капчи и те места изображений, в которых сеть была уверена. Уверенность определял по значению пикселя на выходном изображении. Таким образом можно увеличить датасет. Однако идея не сработала, после нескольких итераций обучения качество распознавания сильно ухудшилось: сеть не распознавала некоторые символы, путала их, то есть ошибки распознавания накапливались.
Другая попытка обучиться на малом датасете — использовать сиамские сети, сиамская сеть на входе требует пару капч, если у нас датасет из N капч, то пар будет N2, получаем гораздо больше обучающих примеров. Cеть преобразует капчу в карту векторов. В качестве метрики сходства векторов выбрал скалярное произведение. Предполагалось что сиамская сеть будет работать следующим образом. Сеть сравнивает часть изображения на капче с некоторым эталонным изображением символа, если сеть видит, что символ тот же с учетом искажения, то считается, что в данном месте качи есть соответствующий символ. Сиамская сеть тренировалась с трудом, часто застревала в неоптимальном локальном минимуме, точность была заметно ниже точности обычной сети. Возможно проблема была в неправильном выборе метрики сходства векторов.
Также была идея использовать автоэнкодер для предварительного обучения нижней части сети (та, что ближе к входу), чтобы ускорить обучение. Автоэнкодер — это сеть, которая обучается выдавать на выходном изображении то же что и подается на вход, при этом в архитектуре автоэнкодера организуют узкий участок. Тренеровка автоэнкодера есть обучение без учителя.
Пример работы автоэкодера:
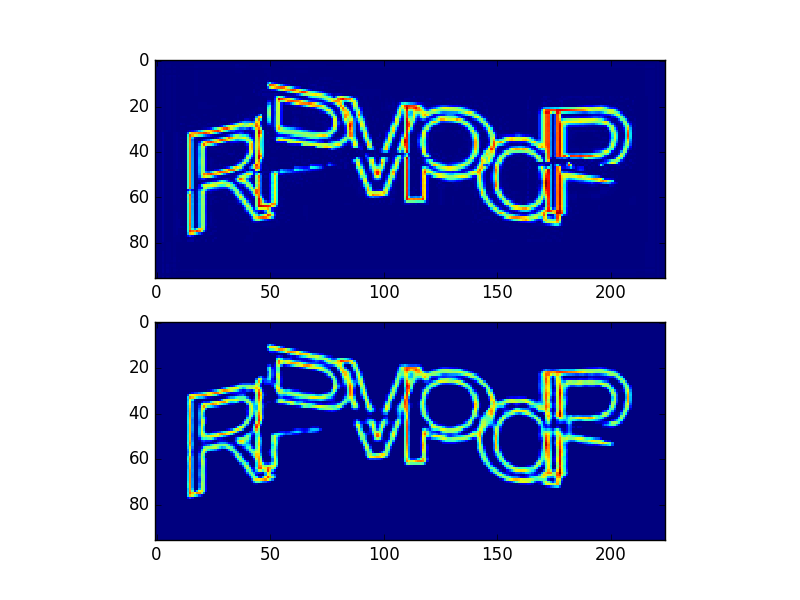
Первое изображение — входное, второе — выходное.
У обученного автоэнкодера берут нижнюю часть сети, добавляют новых необученных слоев, все это дотренировывают на требуемую задачу. В моем случае применение автоэнкодера никак не ускоряло обучение сети.
Также был пример капчи, которая использовала цвет:


На данной капче описанный метод с полносверточной нейронной сетью не давал результата, он не появился даже после различных предобработок изображения повышающих контрастность. Предполагаю что, полносверточные сети плохо справляются с неконтрастными изображениями. Тем не менее, данную капчу удалось распознать обычной сверточной сетью с полносвязным слоем, получена точность около 50%, определение координат символов осуществлялось специальным эвристическим алгоритмом.
Результат
| Примеры | Точность | Коментарий |
|---|---|---|
  |
42 % | Капча Микрософт , jpg |
 |
61 % | |
 |
63 % | |
 |
93 % | капча mail.ru, 500x200, jpg |
 |
87 % | капча mail.ru, 300x100, jpg |
 |
65 % | Капча Яндекс, русские слова, gif |
 |
70 % | капча Steam, png |
 |
82 % | капча World Of Tanks, цифры, png |
Что еще можно было бы улучшить
Можно было бы сделать автоматическую разметку центров символов. Сервисы ручного распознавания капч выдают лишь распознанные строки, поэтому автоматическая разметка центров помогла бы полностью автоматизировать разметку тренировочного датасета. Идея такова: выбрать только те капчи, в которых каждый символ встречается один раз, на каждый символ натренировать отдельную обычную сверточную сеть, такая сеть будет отвечать лишь на вопрос: есть ли в данной капче символ или нет? Затем посмотреть какие признаки использует сеть, используя метод минимизация значений пикселей входной картинки (описано выше). Полученные признаки позволят локализовать символ, далее тренируем полносверточную сеть на полученных центрах символов.
Выводы
Текстовые капчи распознаются полносверточной нейронной сетью в большинстве случаев. Вероятно, уже настало время отказываться от текстовых капч. Google давно не использует текстовую капчу, вместо текста предлагаются картинки с различными предметами, которые нужно распознать человеку:
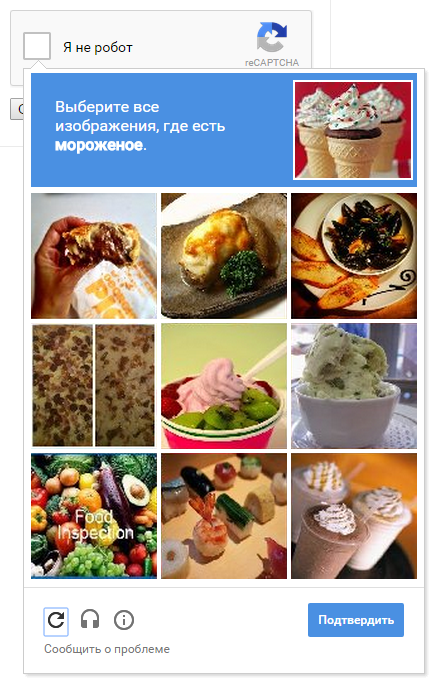
Однако и такая задача кажется решаемой для сверточной сети. Можно предположить, что в будущем возникнут центры регистрации людей, например, человека по скайпу интервьюирует живой человек, проверяет сканы паспортов и тому подобное, затем человеку выдается цифровая подпись, с которой он может автоматически регистрироваться на любом сайте.
© Максим Веденев
Комментарии (100)

KiloLeo
26.11.2017 16:59-1Работа проделана качественная, профессиональная и значительная. Жаль, что всё это ради вреда. А ведь много полезных применений — ЭКГ расшифромывать, томограммы, ставить диагнозы… «Эту бы энергию, да в мирных целях...» (с) Не жалко своего времени и сил на негодные дела?
Gray12
26.11.2017 17:04Это всего лишь готовые задачки. На основе этих алгоритмов можно комп и машины научить водить и найти телефон Сары Коннор в справочнике.
KiloLeo
26.11.2017 17:24+1Это вполне конкретная задача. И мы все понимаем как это будет использоваться. А кто хочет машины учить водить — тот учит машины.

sumanai
26.11.2017 18:08И мы все понимаем как это будет использоваться.
Где скачать плагин к Хрумеру? Правильно, нигде, авторы не выкладывают код, да и в хрумере есть более отработанные алгоритмы. Так что хуже, чем сейчас, эта работа не сделает.KiloLeo
26.11.2017 18:42Несколько месяцев плотной работы потрачены просто так, поиграться? не так интересно как именно это будет монетизировано. Важно, что в любом случае эта отмычка попадёт в руки тех, для кого предназначена. А то, что у кого-то есть более качественные отмычки сути дела не меняет. Эта тоже вполне справится со своей задачей.
Но работа отличная — статью, прям в учебник вставляй.khim
26.11.2017 20:54Важно, что в любом случае эта отмычка попадёт в руки тех, для кого предназначена.
Совершенно не факт. Люди, делающие отмычки «для тех, для кого предназначены» редко публикуют статьи на Хабре. Ибо им это не нужно: каждая такая статья бьёт по их карману, так как цена отмычек падает.
Публикацией статей обычно грешат люди «с другой стороны баррикад» — те, кто делают замки. Им же тоже нужно оценивать качество своей работы. Ну и деньжат на улучшение «замков», если получится, срубить…

stychos
27.11.2017 11:21Может тогда эти, которые антиподы тех, для кого предназначена отмычка, наконец поменяют замки и уберут эти капчи?
commanderxo
26.11.2017 20:37А кто хочет машины учить водить — тот учит машины.
А ещё лучше - совмещать

Dark_Daiver
26.11.2017 17:56Если честно, то не вижу трагедии. Разве распознавание капчи это чудесная задачка чтобы отточить свои навыки работы с CNN (легко генерировать выборку любого размера и любой сложности).
Всякая медицина же, требует определенного бэкграунда.
kalininmr
26.11.2017 23:40я участвовал в проекте автоматизированной расшифровки ЭКГ кучу лет назад(больше 10 точно).
и уже тогда их было достаточно.
vedenev Автор
27.11.2017 11:12Я понимаю что это вредная вещь, но не смог удержаться. Уж очень интересная задача. Хотя статья может быть и полезна: разработчики капч посмотрят эту статью и начнут думать в сторону улучшения своих капч или вообще отказа от них.
stychos
27.11.2017 11:42Правильно, пусть разработчики капч научат всякие нейронки распознавать человека без капч.

AlexanderG
27.11.2017 22:17Очень часто встречается капча из одной галочки «Я не робот». Полагаю, как-то анализируется пользовательское поведение на странице или история.
stychos
27.11.2017 22:42Осталось мaленький шажочек сделать — убрать её вовсе!

andreymal
28.11.2017 00:18И он уже давно сделан! Только пользователи об этом зачастую не в курсе по очевидным причинам :)
vedenev Автор
28.11.2017 04:12С января cooming soon так и висит:
www.google.com/recaptcha/intro/comingsoon/invisible.html

vedenin1980
27.11.2017 12:18Жаль, что всё это ради вреда. А ведь много полезных применений
Все не так однозначно,
во-первых, задача разгадывания капчи это та же задача распознавания текста (иногда бывает, что рукописный, плохо сохранившийся машиный текст та еще капча), а она очень полезна. Например, я участвовал в хакатроне, где задачей было распознавать текст с почтовых посылок, там бы нам бы очень пригодились алгоритмы из статьи.
во-вторых, бывают задачи когда требуется обходить капчи и парсить сайты для вполне легальных и моральных целей, когда я работал на фрилансе несколько раз обращались с задачами вида автоматизировать труд человека, который просматривал сайты бесплатных объявлений для поиска определенных важных заказчику объявлений (он бы их в любом случае просматривал, только скрипт экономил ему полчаса-час рабочего времени ежедневно), либо с когда посреднику нужно было получать каталог и цены от оптовика, оптовик был в принципе не против (посредник же продавал его товары), но не готов был оплачивать разработку api или доработку своего сайта.
Это всего лишь инструмент, его можно по-разному использовать, так же как всякое ПО для хакерских проникновений.

khdavid
27.11.2017 14:57Вы абсолютно не правы. Если существует знание о взломе любой защиты, то чем раньше это знание будет опубликовано, тем лучше. Это поможет разработать средства защиты. Иначе защищающимся будет сложнее подготовиться к атакам.

xFFFF
26.11.2017 17:01Интересная работа) Сам сейчас начинаю работать с нейросетями, но успехов пока мало)
Gray12
26.11.2017 17:03Не просто капчи, а уже а вторая рекапча, программеры Хрумера далеко продвинулсь в этом.

abrwalk
26.11.2017 17:19Ненавижу рекапчу, чувствую себя как на личном досмотре в аэропорту, и плевать я хотел на вашу борьбу со ботами, это не мои проблемы.
algotrader2013
27.11.2017 01:36поддерживаю. Новая версия с картинками еще и часто нелогична для человека. К примеру, спрашивают все картинки, где есть автомобиль. Показывают картинку, где в левом верхнем краю картинки виднеется маленький кусочек колеса (где-то четверть). Что делать?
Или фото всех магазинов, и виден дом с большими фасадными окнами, а место, где вывеска может быть (или не быть), заслонено деревом и хз, это магазин, или жилой дом.dmitryredkin
27.11.2017 18:35Разве вы еще не поняли, что в рекапче главное — не столько правильно угадать, сколько продемонстрировать типичное для человека поведение(траектория мышки, раздумья над сложным случаем и быстрые отметки в простом и т.п.)?

lightman
27.11.2017 11:17+сто. Давно уже пора понять и принять что человек и компьютер усиленно стремятся к точке неотличимости друг от друга. Пора отказаться от капчастылей и перейти на систему оценки контента по личному доверию.
Aquahawk
27.11.2017 14:14Компьютер ни куда не стремится, люди которые делают ботов стремятся к неотличимости ботов от людей.
TheYellingChives
28.11.2017 04:04Со всеми включенными куками, залогиненый в сервисах гугла я просто ставлю галочку и мне не предлагает даже её проходить.
sumanai
28.11.2017 15:23И прощай приватность, гугл знает каждый ваш шаг в сети.
TheYellingChives
28.11.2017 16:18И пусть, чем это мне мешает? Слишком хорошая выдача поиска будет? Реклама которая будет пробиваться сквозь блокировщики будет адекватной? Я не вижу минусов от того, что какой-то ИИ следит за мной.
sumanai
28.11.2017 17:20Вам не мешает, а вот мне мешает.
Выдача будет не хорошей, а персонализированной, то есть легко попасть в информационный пузырь. Адекватная реклама может ударить в мои уязвимые точки и заставить купить вещь, которая мне в действительности не нужна, в отличие от ванг и средств от грибка, которые фильтруются и без блокировщиков. И т.д.
Ваш выбор конечно, но дискриминация любителе анонимности не есть хорошо, по крайней мере с моей точки зрения.
Rumlin
26.11.2017 18:51С паспортами наверное ещё хуже. В году 2015-м попадались публикация о взломе аккаунтов playstation.Суть сводилась к тому, что взломщик, вроде ситуация была в Бельгии, звонил в службу техподлержки и легко выдавал себя за настоящего пользователя, ему сбрасывали пароль и он вводил аккаунт. Немного позже я поговорил с сотрудником российской техподлержки Сони, с его слов когда они просят прислать скан или фото страницы паспорта с фото, это просто психологический трюк, чтобы вспугнуть потенциального злоумышленника. В реальности если им пришлют фотошоп или сгенерированный скан паспорта — они не поймут что это фальшивка т.к. главное чтобы совпали ФИО пользователя.

mejedi
26.11.2017 23:53В Германии широко применяется. Можно завести счет в банке, и верифицировать паспорт удаленно. Есть сервис верификации от Deutsche Post, некоторые банки используют собственное решение.
Реализовано это как приложение для телефона с видеочатом; оператор достаточно заморочен и просит показать паспорт в разных ракурсах и двигать им чтобы проступили защитные элементы, которые видны под определенным углом.
tbp2k5
27.11.2017 11:15Не думаю что у них «просьба прислать скан» работает только как «психологический трюк». В нашей организации такая проблема тоже стоит и мы тоже просим прислать «сканы». Не знаю как в российском законодательстве, а здесь (франция) за изготовление использование фальшивого документа можно получить до 3-5 лет тюрьмы или до 45 000 € / 75 000 € штрафа (в зависимости от типа документа и контекста).
Можете себе гуглом перевести: www.service-public.fr/particuliers/vosdroits/F31612Rumlin
28.11.2017 16:21Юридический аспект — это другая сторона. И в случае завладения аккаунтом, это не самое большое и не основное преступление. Фактически скан паспорта — это единственное, что стоит на пути злоумышленника. Остальное просто, и после скана, техподдержка уже ничего не проверяет. Пользуясь случаем предупреждаю владельцев аккаунтов PS — не привязывайте к аккаунту настоящие банковские карты, и тем более зарплатные, где есть деньги. Списываются они в один момент, вернуть обратно (почти) невозможно по пользовательскому соглашению после покупки и загрузки игры в угнанном аккаунте. Списываются они и официально по не знанию или не внимательному прочтению каких-то соглашений и условий подписок, акций. Вот эти деньги точно вернуть нельзя.
К слову юристы у Sony самые злые — у них так четко описаны условия использования, покупок, что пользователь везде им должен. И в случае спора у Сони есть куда ткнуть чтобы показать с чем пользователь соглашался.
alsii
26.11.2017 22:05Можно предположить, что в будущем возникнут центры регистрации людей, например, человека по скайпу интервьюирует живой человек, проверяет сканы паспортов и тому подобное
Будущее наступило. В Германии, чтобы активировать купленную в магазине SIM-карту нужно или пройти верификацию в отделении Deutsche Post, или воспользоватся сайтом/программой Postident, где нужно пройти интервью с живым оператором и продемонстрировать ему документ. Причем с ноутбука мне это сделать не удалось: "К сожалению Ваша камера не позволяет получить достаточно качественное изображение". Пришлось скачивать приложение на мобильник.
khim
26.11.2017 22:11Ну дык это почти во всех почти странах так… если все делать как в законе написано. И всегда было так. Просто в Германии несколько более аккуратно закон соблюдают…
Причём тут CAPTCHA и Gmail???alsii
27.11.2017 13:00Три с половиной года назад такого не было. Покупаешь симку в магазине, заходишь на страничку оператора, регистрируешься, жмешь кнопку "активировать", вводишь нимер и код активации с карточки и все работает. Для тарифов с подключенными кслугами нужно было указывать номер счета, но для простых "9 центов за минуту/СМС" это было не обязательно. Пополнять счет можно было покупая в магазитах карты пополнения. Если платить наличкой, то получалось вполне анонимно. А вот прошлым летом столкнулся со всей этой процедурой.
khim
27.11.2017 17:06Возможно. Законы требовали обязательного предьявления ID всегда, а после череды терактов за этим стали более тщательно следить. Думаю в России тоже про них скоро вспомнят…

kafeman
27.11.2017 05:17Не так давно покупал prepaid sim на заправке в Германии, для регистрации было достаточно ввести свое имя и адрес на сайте. Потом ее, конечно, заблокировали, но обещали разблокировать, если я таки пришлю им свой настоящий адрес.

VitaZheltyakov
26.11.2017 22:54Что-то у нейронной сети результаты не намного лучше, чем у аналитических алгоритмов…
Ну а если поделу — на данный момент ни одна нейронная сеть, ни аналитика не может разгадать капчи с пересечением букв (пример, на первом изображении статьи «низо» и «кожа»).
Учитывая это, я слабо понимаю смысл создавать нейронные сети, если аналитические алгоритмы дают примерно такие же результаты (?)vedenin1980
27.11.2017 02:50на данный момент ни одна нейронная сеть, ни аналитика не может разгадать капчи с пересечением букв
Скорее ни одна из общедоступных, задача не кажется не решаемой (например, бы я попробовал в случае слипшихся букв убирать некоторые линии и смотреть не получается ли без них буква с высокой достоверностью, либо расчитывать ожидаемую ширину буквы и пытаться разделить слипшихся). ИМХО, такие алгоритмы скорее всего существуют, просто стоят дорого и доступны не всем.

qwert_ukg
27.11.2017 11:19на данный момент ни одна нейронная сеть, ни аналитика не может разгадать капчи с пересечением
я и сам не всегда могу их разгадать
vedenev Автор
27.11.2017 11:22Может может. Для полносверточной сети не обязательно чтобы символы были разделены, она ищет в каждом месте картинке каждый символ.

bro-dev
26.11.2017 23:10Ну пока что выглядит все равно полуавтоматически, то есть просто отточенный алгоритм с базой, вот когда будет уровня суем любую каптчу и она без обучения решает как человек, тогда уже можно будет волноваться.
vedenev Автор
27.11.2017 11:25Уже пора волноваться. В статье описана идея как можно автоматизировать разметку (Что еще можно было бы улучшить). Хотя hotmail выбрал интересную тактику: меняют капчу каждые 2 недели. Это сильное усложнение — нужно все время обучать сеть заново.
bro-dev
27.11.2017 15:43Суть в том что ей все равно нужна еще тренировка, то есть есть нужна база в которой уже будет прорешенно 1к каптчей, человек же вообще любую каптчу может решить с первого раза даже которую вчера придумали на другом конце света.
old_bear
27.11.2017 19:41человек же вообще любую каптчу может решить с первого раза даже которую вчера придумали на другом конце света
Т.е. вы думаете, что рядом с капчами совершенно зря делают кнопочку «другой вариант»?
sumanai
27.11.2017 20:38человек же вообще любую каптчу может решить с первого раза
Решайте. Или вы не человек? Её придумали весьма давно если что.

ankh1989
27.11.2017 08:25Классификация картинок это классическая задача в которой соревнуются авторы работ по нейросетям. Называется ImageNet. Есть подозрение, что Гугл берёт картинки прямо оттуда. Вроде как сейчас наилучший результат это 73%, но исследования в этой области ведутся так быстро, что возможно уже через неделю этот результат будет устаревшим.

cepera_ang
27.11.2017 17:14Это результат не классификации, а детектирования объектов и это не совсем «проценты». В классификации на том же конкурсе результат топ-5 97+% и топ-1 81+%

horevivan
27.11.2017 11:26Уважаемый автор. Как вы оцениваете устойчивость данного вида капчи?
- Сейчас, когда процент 'похожести' рисунка пользователя определяется с помощью НН?
- Что если попытки взлома с помощью НН будут использоватся для обучения НН которая отсеивает взломы?
losse_narmo
27.11.2017 11:44Я бы сказал она устойчива против людей :)
Была забракована 1/3 моих попыток. При этом регулярно говорила «ок» на недорисованное изображение
vedenev Автор
27.11.2017 11:46Возможно такую капчу можно взломать генеративными сетями (GAN). arxiv.org/pdf/1406.2661.pdf такая сеть может генерировать картинки. Может и векторную графику тоже сможет адекватную сгенерировать
andreymal
27.11.2017 12:03Это точно капча, а не генератор случайного процента?
EvilFox
28.11.2017 02:04А кружок с галкой не принимает уже с десяток попыток даже достаточно удачных забраковала…

iShkval
27.11.2017 11:27Очень интересно что будет при таком прогрессе через годик-два. Очень надеюсь что каптчам найдут замену, а то местами они уже конкретно подбешивать начинают и превращаются в защиту от людей а не роботов.
sumanai
27.11.2017 16:55В итоге везде будут гуглокапчи, которые вводить ещё дольше и сложнее, чем буквы.
Zetc
27.11.2017 11:27Не хватает списка литературы. Про карту центров сами придумали или есть исследования? Вроде бы на Coursera, Andrew Ng приводил пример с капчей, где алгоритм последовательно обрабатывал часть картинки (квадратное окно, движущееся слева направо) без разделения на символы, результаты с выхода классификатора объединялись какой-то эвристикой. Не пробовали что-нибудь подобное?
vedenev Автор
27.11.2017 11:32А зачем окно? В сверточной сети ядра сверток уже и так бегают по картинкам. Делаем полносверточную сеть и все. Карту центров сам придумал. Но может быть изобрел велосипед. Позже видел в статьях то же самое делали (статья была про поиск ключевых точек тела: локти колени и т п). Окно изначально не пробывал т к в этой задаче важна еще и скорость. Показалось что окно будет слишком медленным
AW-Valera
27.11.2017 11:29>Вероятно, уже настало время отказываться от текстовых капч.
Не совсем, на мой взгляд. Сейчас уже есть решения, позволяющие автоматизированно решать ту же ReCaptcha от гугла и у гугла особо нет инструментов для борьбы с этими решениями и единственное что они сейчас делают — это лимитируют количество вводов с одного IP и блокируют подозрительные IP-адреса (плюс проводят большую работу по выявлению бот\не бот на основе кук)
Что же касается текстовой капчи, так в ней ещё большой запас для адекватного усложнения для нейросети с сохранением «человечности» при которой у человека не возникнет проблем с её распознанием.
К примеру вот образцы капчи с формы авторизации сервиса антикапчи rucaptcha.com:



vedenev Автор
27.11.2017 11:40Думаю полносверточная сеть здесь сможет достичь около 30 %. Да есть еще методы борьбы: постоянно менять капчу, блокировать по IP, анализировать активность зарегестрирванного почтового ящика (кстати это все опять же можно делать машинным обучением). Кстати спамеры арендуют много IP чтобы регестировать аккаунты.
anizotrop
27.11.2017 11:32Спасибо за статью!
1. Интересно было бы увидеть процент распознавания или error rate для всех сетов для каждой из протестированных архитектур.
2. Результат с тренировкой на сгенерированых одним алгоритмом капчами предсказуем т.к. распределение тренировочного датасета отличается от тестировочного.
3. Почему Вы изначально решили работать с полносверточной сетью без FC слоёв?
4. Касательно неконтрастных изображений — думаю увеличение размеров фильтров помогло бы.
5. Интересно было бы почитать о сравнении результатов, если решите попробовать capsnet для той же задачи.vedenev Автор
27.11.2017 11:361. Я почти все результаты выложил. Есть еще некоторый капчи hotmail другого типа но там тоже примерно 40% — 50%. Дело в том что критерием распознанной капчи я считал точность не ниже 50%. Если точность была ниже то я делал сеть больше и датасет больше и точность достигала 50%
2. Это не было очевидно. На глаз генерированая капча и реальная капча ничем не отличается.
3. Для скорости + полносверточная сеть не требует сегментации букв.
4. Может быть, я не проверял.
5. Капчи уже надоели. Сейчас занимаюсь поиском людей на изображении.
Sky550
27.11.2017 11:37Решая рекапчу мы помогаем нейросетям тренироваться. Если будут сливы бд рекапчи то мороженки и машины тоже будут искажать. Как вариант появиться капча вроде Саймон говорит — три раза потянуть точку в левый нижний угол квадрата и тому подобное, и все это капчевым шрифтом.

lumaxy
27.11.2017 11:47Вспомнил кейс, где эта разработка была бы направлена исключительно в мирное русло. У страховой компании «Согласие» при покупке полиса ОСАГО онлайн на нескольких этапах оформления есть ввод капчи, причем по отзывам на форумах, последняя капча для «нежелательных» клиентов уже непосредственно перед оплатой специально сделана нерешаемой путем использования вперемешку русских/латинских букв одинакового начертания. То есть формально тебе в заключении договора не отказывают, но ты тупо не можешь ввести капчу, чтобы заплатить за полис :) Их техподдержка предлагает пробовать другой браузер, почистить кэш, и т.д., пока ты не сдашься и не отстанешь от них. Было бы интересно узнать, можно ли победить такую капчу — там количество попыток ввода неограниченно.
ITurchenko
27.11.2017 14:58А где гарантии, что сервер не возвращает «неверно» на любой вариант ответа?
lumaxy
27.11.2017 18:48Ну Вы уже совсем потеряли веру в человечество :) Хотя такой вариант тоже вполне возможен…

Frankenstine
27.11.2017 13:50Я думаю капчи надо делать на основе «специфики» зрения человека, например использовать оптические иллюзии. Так же, в борьбе с такими вот нейронными сетями хорошо должно помочь примешивание к изображению частей символов, в качестве шума. Сеть не отличит часть символа от символа, у которого «повреждена» часть (но присутствует), так как сеть не ищет «недостающее» для распознания символа. Например, берём букву В и стираем часть вертикальной палки — человек увидит что символ неполный и проигнорирует, а сеть даст ложное распознание буквы В.
vedenev Автор
27.11.2017 14:57Если левую палку у B стереть то получится 3 тут и человек может спутать. Нейронная сеть и человек видят по разному. Генеративные сети показали что сеть плохо справляется с подсчетом особенностей (она может сгенерировать изображение собаки с 6тю лапами). Значит нужно слеплять символы так чтобы было трудно понять какие символы не посчитав некоторые палочки. Например последовательности из p и q причем некоторые p и q совмещены так что их кружочки совпадают. Тогда чтобы понять что за последовательность нужно посмотреть как палочки расположены, посчитать их. Тут надо специальный алгоритм генерирования капчи делать чтобы совмещать кружочки. Также нужен специальный шрифт в котором нет никаких завиточков дополнительных у p и q, иначе сеть может зацепится за завиточки и распознать. Но и такие неоднозначности кажутся решаемыми моделью CNN+LSTM
Frankenstine
27.11.2017 20:28Стирать нужно так, чтобы не получалось другого символа, т.е. часть палки/дуги. Получится не символ, лишь похоже. Человек видит что часть символа отсутствует, программа этого нюанса не может увидеть, так как она определяет символ по проценту совпадения с оригиналом.
vedenev Автор
28.11.2017 04:06Если в обучающем датасете поставить символы с затертой палочкой то сеть обучится находить и такие символы
Frankenstine
28.11.2017 09:41Если стирать скажем не более 20% длины символа, в случайном месте, то сколько вариантов «несимвола» получится? Не слишком ли большой алфавит распознавания выйдет для нейронной сети?
vedenev Автор
28.11.2017 14:04Там не нужно чтобы в датасете были все возможные способы затирания части символа т к сеть смотрит несколько признаков символа в разных местах если некоторые из них (не обязательно все) найдены то символ распознается.
Frankenstine
28.11.2017 14:42Вот именно про это я и говорю. Программа не может отличить намеренный дефект от искажения. Человек может. Псевдосимвол распознается программой, а человек видит что это не символ, лишь его бОльшая часть.
vedenin1980
28.11.2017 15:07Да ровно так же может оказаться, что такие намеренные дефекты будут слишком сложными для человека, но распознаваться программой. Проблема капчи в том, чтобы она не превратилась в дикий ребус, который для разгадывания требует кучу сил и времени, иначе ваши пользователи/клиенты просто уйдут.
Если говорить о текстовых капчах, то наверное самая простая защита это показывать очень разные капчи в каждой сессии, тогда есть большой шанс что сеть не сможет научится проходит вашу капчу (точнее слишком дорого ее будет учить на бесконечное кол-во вариантов).
forall
27.11.2017 19:13http://docs.google.com/spreadsheets/d/1W1EdvNhu34vAxWAjmIBZY8hsZWoNj3poChIHYVQCHAo/edit#gid=0
Софт известен)vedenev Автор
28.11.2017 04:10На сколько я знаю у них другой метод: сначала ищут центральную линию строки эвристическими алгоритмами. Затем нарезаются окна так что центр окна на ходится на линии центра строки, получают много гипотез и затем отсеивают лишние (это все только догадка, свой метод они не раскрывают)





begemot_sun
Любую капчу можно взломать при соответсвующем бюджете.
ozonar
При соответствующем бюджете можно вообще все что угодно взломать, не только капчу