К достоинствам LizardFS:
Очень быстрая работа в режиме чтения маленьких файлов. Многие кто использовал GlusterFS встречались с проблемой чересчур медленной работы, если кластерная ФС используется под отдачу данных сайтов.
Скорость чтения больших файлов на очень хорошем уровне.
Скорость записи больших файлов мало чем отличается от нативных файловых систем, особенно если снизу SSD диски и между серверами в кластере 1-10 Gbit связь.
Операции chown / ls -la — медленнее, чем в случае нативной ФС, но не настолько медленно
как в случае GlusterFS.
Операции рекурсивного удаления — очень быстро.
Очень гибкие опции подключения в утилите mfsmount.
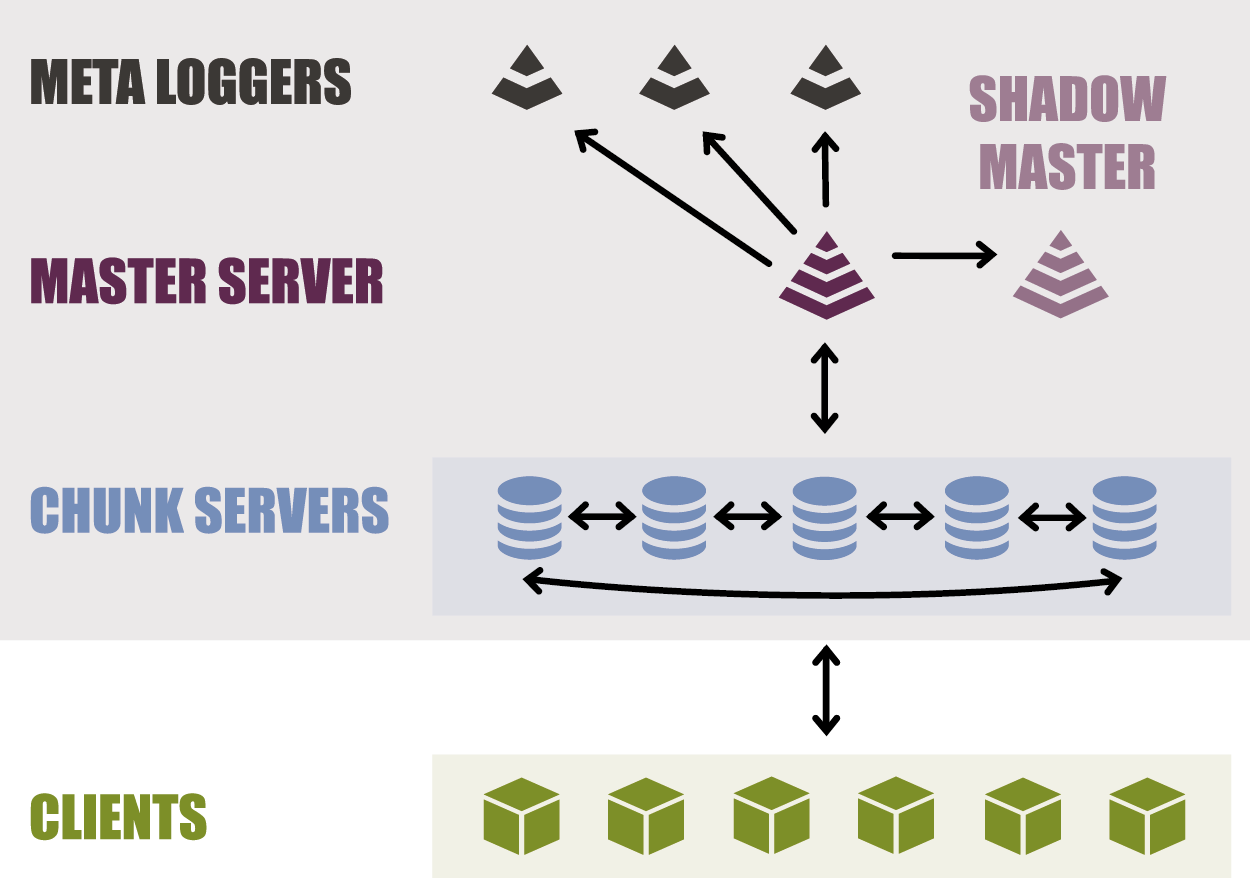
Дублирование мета данных настраивается легко и просто, можно одновременно иметь несколько страховочных shadow мастер серверов и metalogger серверов.
Мета данные хранятся в оперативной памяти.
Очень здорово, что LizardFS может предпочитать брать данные с локального сервера. На примере 2-х реплик для ускорения чтения, LizardFS клиент будет автоматически брать файлы с локального сервера, а не тянуть по сети со 2-го сервера.
Возможность на под.папки устанавливать любые goal(количество реплик), то есть можно указать LizardFS /var/lizardfs/important делать 3 реплики, а /var/lizardfs/not_important вообще без реплик и всё в рамках одной ФС. Все зависит от количества chunk серверов и выполнения требуемых задач, можно даже использовать несколько раздельных дисков под каждый chunk сервер.
Поддерживает различные режимы репликации данных, в том числе EC — Erasure Coding.
Скорость чтения в таком режиме не на много меньше.
Все работает в LXC контейнерах, кроме монтирования клиентом самой файловой системы. Решается монтированием на хостовой машине и пробросом mount point в LXC контейнер.
Можно потренироваться.
Автоматический ребаланс при добавлении новых нод.
Довольно простое удаление выпавших или ненужных нод.
К недостаткам LizardFS:
Скорость записи большого потока маленьких файлов очень низкая. Rsync хорошо это показывает.
В случае с движками сайтов, которые генерируют большое количество кеш файлов на ФС,
кеш надо выносить за пределы кластерной файловой системы. Для движков, в которых это сделать проблемно, то можно поверх примонтированной LizardFS замонтировать в ее под.папки локальные папки, или же использовать символические ссылки.
Пример:
mount --bind /data/nativefs/cache /var/lizardfs/cacheРабочий мастер сервер мета данных может одновременно работать только 1, но параллельно может работать дублер или даже несколько в режиме shadow. High Availability можно реализовать как с помощью платного компонента LizardFS, так и с помощью своих скриптов + uCarp/keepalived/PaceMaker и тому подобного ПО. В нашем случае нам это не требуется, достаточно ручного управления.
К сожалению всё автоматически, как в GlusterFS из коробки, такого тут нет. Плюсы и гибкость перевешивают минусы.
Немного требовательна к оперативной памяти. Но например на небольших проектах где данных примерно 10-20GB и всего 2 реплики это не критично:
root@172.24.1.1:/# df -h |grep "mfs\|Size"
Filesystem Size Used Avail Use% Mounted on
mfs#mfsmaster:9421 1.8T 41G 1.8T 3% /var/www (объем 2-х реплик)
root@172.24.1.1:/# find /var/www -type f -print0 | wc -l --files0-from=- |grep total
185818 total (количество файлов)
root@172.24.1.1:/# smem -u -t -k |grep "mfs\|RSS"
User Count Swap USS PSS RSS
mfs 3 0 170.0M 170.9M 180.9M (3 процесса - master/metalogger/chunkserver)
На среднем проекте проверю потребление RAM позже, еще не внедрили пока, но уже готовимся.
Настройка:
Предоставлю кратенький мануал, как быстро запустить LizardFS на Debian 9.
Предположим у нас есть 4 сервера с установленным Debian 9, 8-ой по умолчанию не содержит готовых пакетов lizardfs.
Выставим лимиты:
В /etc/security/limits.conf надо проставить:
* hard nofile 20000
* soft nofile 20000
Можно прописать и раздельно для root, mfs/lizardfs пользователей. У кого итак лимиты задраны уже, делать этого не требуется. По минимуму нужно 10000.
Распределим роли:
172.24.1.1 (master metadata / chunk) — master мета данных / chunk хранилище
172.24.1.2 (shadow metadata / chunk) — shadow master мета данных / chunk хранилище
172.24.1.3 (metalogger / chunk) — бэкап мета данных / chunk хранилище
172.24.1.4 (metalogger / chunk) — бэкап мета данных / chunk хранилище
Строго говоря, metalogger может работать и на master и shadow параллельно, тем более ресурсы там копеечные требуются. Это фактически отложенный бекап мета данных, точно таких же как и на master / shadow серверах. И любой metalogger, в случае, если на основных серверах побились мета данные можно превратить в master сервер.
То есть например такой вариант у меня используется тоже:
172.24.1.1 (master metadata / metalogger / chunk)
172.24.1.2 (shadow metadata / metalogger / chunk)
Продолжим далее в статье в варианте из 4-х серверов.
Пункты 1-3 — выполняются на всех 4-х серверах.
1. Устанавливаем на всех серверах полный набор из всех сервисов, кроме клиента если у Вас LXC контейнеры. Ставим все сервисы, потому что они все равно отключены в Debian в автозагрузке в /etc/default/… А если вдруг придется metalogger превратить в master, то все уже будет установлено заранее.
apt-get -y install lizardfs-common lizardfs-master lizardfs-chunkserver lizardfs-metalogger lizardfs-client
cp /etc/lizardfs/mfsmaster.cfg.dist /etc/lizardfs/mfsmaster.cfg
cp /etc/lizardfs/mfsmetalogger.cfg.dist /etc/lizardfs/mfsmetalogger.cfg
cp /etc/lizardfs/mfsgoals.cfg.dist /etc/lizardfs/mfsgoals.cfg
cp /etc/lizardfs/mfschunkserver.cfg.dist /etc/lizardfs/mfschunkserver.cfg
cp /etc/lizardfs/mfshdd.cfg.dist /etc/lizardfs/mfshdd.cfgИли, так как в Debian в родных пакетах приводится вариант выше, то если установить из исходников или собрать свои пакеты, то директория будет другой:
cp /etc/mfs/mfsmaster.cfg.dist /etc/mfs/mfsmaster.cfg
cp /etc/mfs/mfsmetalogger.cfg.dist /etc/mfs/mfsmetalogger.cfg
cp /etc/mfs/mfsgoals.cfg.dist /etc/mfs/mfsgoals.cfg
cp /etc/mfs/mfschunkserver.cfg.dist /etc/mfs/mfschunkserver.cfg
cp /etc/mfs/mfshdd.cfg.dist /etc/mfs/mfshdd.cfgВ том числе названия утилит в зависимости от пакетов тоже могут меняться — mfs* / lizardfs <действие> и так далее.
В некоторых случаях, если не поставить пакет master сервера, а поставить только metalogger и chunkserver, то по умолчанию не выставляются права юзера и группы mfs / lizardfs на папку /var/lib/mfs или /var/lib/lizardfs.
2. Добавляем в /etc/hosts дефолтную запись для LizardFS.
echo "172.24.1.1 mfsmaster" >> /etc/hosts3. Выбираем для хранения данных папку или отдельный раздел даже или хоть 2 раздела и больше. Рассмотрим просто 1 папку в текущей ФС на каждом сервере: /data/lizardfs-chunk
mkdir -p /var/www (сюда будем монтировать наш кластер)
mkdir -p /data/lizardfs-chunk (сюда LizardFS будет класть данные в своем формате)
echo "/data/lizardfs-chunk" > /etc/lizardfs/mfshdd.cfg
echo "172.24.1.0/24 / rw,alldirs,maproot=0" > /etc/lizardfs/mfsexports.cfg
Или
echo "/data/lizardfs-chunk" > /etc/mfs/mfshdd.cfg
echo "172.24.1.0/24 / rw,alldirs,maproot=0" > /etc/mfs/mfsexports.cfg
Расшаривание корня / имеется ввиду все пространство самой LizardFS, а не корня нативной ФС системы.
4. Указываем, кто будет master, а кто shadow
На 172.24.1.1 укажем PERSONALITY=master в конфиге mfsmaster.cfg
На 172.24.1.2 укажем PERSONALITY=shadow в конфиге mfsmaster.cfg
5. Включаем нужные сервисы:
172.24.1.1:
echo "LIZARDFSMASTER_ENABLE=true" > /etc/default/lizardfs-master
echo "LIZARDFSCHUNKSERVER_ENABLE=true" > /etc/default/lizardfs-chunkserver
systemctl start lizardfs-master
systemctl start lizardfs-chunkserver
172.24.1.2:
echo "LIZARDFSMASTER_ENABLE=true" > /etc/default/lizardfs-master
echo "LIZARDFSCHUNKSERVER_ENABLE=true" > /etc/default/lizardfs-chunkserver
systemctl start lizardfs-master
systemctl start lizardfs-chunkserver
172.24.1.3:
echo "LIZARDFSCHUNKSERVER_ENABLE=true" > /etc/default/lizardfs-chunkserver
echo "LIZARDFSMETALOGGER_ENABLE=true" > /etc/default/lizardfs-metalogger
systemctl start lizardfs-metalogger
systemctl start lizardfs-chunkserver
172.24.1.4:
echo "LIZARDFSCHUNKSERVER_ENABLE=true" > /etc/default/lizardfs-chunkserver
echo "LIZARDFSMETALOGGER_ENABLE=true" > /etc/default/lizardfs-metalogger
systemctl start lizardfs-metalogger
systemctl start lizardfs-chunkserverДалее монтируем клиентом, есть разные варианты, опций очень много:
ФС на chunkserver`ах:
Если у Вас нативная ФС XFS, необходимо добавить -o mfssugidclearmode=XFS
Если у Вас на BSD собрано, необходимо добавить -o mfssugidclearmode=BSD
Если у Вас на MAC OSX собрано :), необходимо добавить -o mfssugidclearmode=OSX
Понятно, что смешивать разные ФС под chunkserver`ами в рамках кластера не рекомендуется, а если хочется, то требуется использовать -o mfssugidclearmode=ALWAYS
По умолчанию используется EXT для btrfs,ext2,ext3,ext4,hfs[+],jfs,ntfs и reiserfs.
Я не думаю что кому-то в голову придет использовать ntfs под Linux для chunkserver`а.
mfsmount -o big_writes,nosuid,nodev,noatime,allow_other /var/www
mfsmount -o big_writes,nosuid,nodev,noatime,allow_other -o cacheexpirationtime=500 -o readaheadmaxwindowsize=4096 /var/wwwПоддерживаемые опции зависят от версии LizardFS, во втором варианте скорость чтения заметно выше. mfsmount по умолчанию берет IP мастера из /etc/hosts, но подключается ко всем chunk серверам параллельно. Опция big_writes считается устаревшей в новых FUSE клиентах и включена по умолчанию, для старых систем желательно указывать.
Доступные варианты реплик прописываются в mfsgoals.cfg
Затем указываем, сколько реплик данных нам надо:
mfssetgoal -r 2 /var/www
mfsgetgoal /var/wwwНу, а потом начинаем пользоваться в /var/www
Так же еще раз подчеркну гибкость в репликации конкретных директорий или файлов на примере:
root@172.24.1.1:/# mfssetgoal -r 1 /var/www/test/
/var/www/test/:
inodes with goal changed: 1
inodes with goal not changed: 0
inodes with permission denied: 0
root@172.24.1.1:/# mfsgetgoal /var/www
/var/www: 2
root@172.24.1.1:/# mfsgetgoal /var/www/test
/var/www/test: 1
То есть можно прямо на директориях указывать сколько реплик директорий и их поддиректорий
делать. Ребалансинг производится автоматически. Тип доступных для утилиты mfssetgoal реплик указывается в mfsgoals.cfg
Для тех же кому нужна параллельная запись более например 1 гигабайта в секунду, нам это просто не требуется, но эта ФС может и это если погуглить, то следует сконфигурировать goal для использования erasure coding в mfsgoals.cfg и назначить этот тип репликации с помощью mfssetgoal на нужную папку. В этом режиме клиент пишет данные параллельно, при условии что сеть у клиента 10 гигабит как минимум. У серверов предполагается, что тоже не меньше.
> Подробнее о режимах репликации
Важно: не стоит делать killall -9 mfsmaster без надобности.
Этим вы можете как минимум потерять часть данных, которые еще находятся в оперативной памяти и как максимум побить файл метаданных и его придется или чинить с помощью mfsfilerepair утилиты или вообще заменять с металоггера на более старый, естественно куcок данных будет потерян. Отчасти зависит от настроек мастера.
Я не стал записывать это в минусы, так как кластерную ФС надо делать все-таки не на серверах со свалки. Тем более желательно, чтобы у серверов было аварийное электропитание.
Для больших систем может быть важно включить настройку:
root@172.24.1.1:/# cat /etc/mfs/mfschunkserver.cfg |grep -B3 FACTOR
## If enabled, chunkserver will send periodical reports of its I/O load to master,
## which will be taken into consideration when picking chunkservers for I/O operations.
## (Default : 0)
# ENABLE_LOAD_FACTOR = 0
Для быстрой работы в режиме подключения нескольких клиентов параллельно и параллельной записи и чтении, не забываем о таких параметрах по умолчанию:
root@172.24.1.1:/# cat /etc/mfs/mfschunkserver.cfg |grep WORKERS
# NR_OF_NETWORK_WORKERS = 1
# NR_OF_HDD_WORKERS_PER_NETWORK_WORKER = 2
# NR_OF_NETWORK_WORKERS = 1
# NR_OF_HDD_WORKERS_PER_NETWORK_WORKER = 20
И про опции в mfsmount:
-o mfswritecachesize=<N>
specify write cache size in MiB (in range: 16..2048 - default: 128)
-o mfswriteworkers=’N’
define number of write workers (default: 10)
-o mfswritewindowsize=’N’
define write window size (in blocks) for each chunk (default: 15)
В общем-то мне хватило и 1-го полного дня, чтобы достаточно разобраться с этой кластерной ФС. Да оно немного сложнее GlusterFS, но плюсы перевешивают. Быстрое чтение кучи маленьких файлов — это прекрасно.
> Документация
Комментарии (3)

13alex
28.11.2017 01:03Несколько лет назад тестировал MooseFS, форком которой является собственно Lizardfs. Сути раскола и форка не помню уже. Нужно попробовать ещё разок и одну, и вторую.
Тесты проводились для использования собственного CDN, так как понравилась архитектура и настройки наследования древовидного, другие кластерные FS так не умеют.
Спасибо за статью!
DaylightIsBurning
28.11.2017 17:40Там шла разработка очень классной фишки: eventually-consistent гео-репликации. И вроде как эту фишку уже в релиз включили. Суть такая, что можно иметь несколько датацентров с большой latency между ними и настроить что бы как минимум одна(две...) реплики были не в том датацентре, где первая. При этом запись идёт сначала на ближайшую ноду, а затем с неё уже реплицируется в другой город/страну/континент. При этом все реплики как бы равноправные, клиент в «дальнем» ДЦ сможет её сразу читать, как она будет готова. Такая репликация должна сильно повышать скорость записи т.к. запись идёт на ближайшую ноду и сразу даёт acknowledgement.
Meklon
Спасибо большое) обязательно попробую на тестовых серверах.