Мы уже рассмотрели механизм индексирования PostgreSQL, интерфейс методов доступа и все основные методы доступа, как то: хеш-индексы, B-деревья, GiST, SP-GiST и GIN. А в этой части посмотрим на превращение джина в ром.
RUM
Хоть авторы и утверждают, что джин — могущественный дух, но тема напитков все-таки победила: GIN следующего поколения назвали RUM.
Этот метод доступа развивает идею, заложенную в GIN, и позволяет выполнять полнотекстовый поиск еще быстрее. Это единственный метод в этой серии статей, который не входит в стандартную поставку PostgreSQL и является сторонним расширением. Есть несколько вариантов его установки:
- Взять пакет yum или apt из репозитория PGDG. Например, если вы ставили PostgreSQL из пакета postgresql-10, то поставьте еще postgresql-10-rum.
- Самостоятельно собрать и установить из исходных кодов на github (инструкция там же).
- Пользоваться в составе Postgres Pro Enterprise (или хотя бы читать оттуда документацию).
Ограничения GIN
Какие ограничения индекса GIN позволяет преодолеть RUM?
Во-первых, тип данных tsvector, помимо самих лексем, содержит информацию об их позициях внутри документа. В GIN-индексе, как мы видели в прошлый раз, эта информация не сохраняются. Из-за этого операции фразового поиска, появившиеся в версии 9.6, обслуживается GIN-индексом неэффективно и вынуждены обращаться к исходным данным для перепроверки.
Во-вторых, поисковые системы обычно возвращают результаты в порядке релевантности (что бы это ни означало). Для этого можно пользоваться функциями ранжирования ts_rank и ts_rank_cd, но их приходится вычислять для каждой строки результата, что, конечно, медленно.
Метод доступа RUM в первом приближении можно рассматривать как GIN, в который добавлена позиционная информация, и который поддерживает выдачу результата в нужном порядке (аналогично тому, как GiST умеет выдавать ближайших соседей). Пойдем по порядку.
Фразовый поиск
Запрос в полнотекстовом поиске может содержать специальные конструкции, которые учитывают расстояние между лексемами. Например, можно найти документы, в которых бабку от дедки отделяет еще одно слово:
postgres=# select to_tsvector('Бабка за дедку, дедка за репку...') @@
to_tsquery('бабка <2> дедка');
?column?
----------
t
(1 row)
Или указать, что слова должны стоять друг за другом:
postgres=# select to_tsvector('Бабка за дедку, дедка за репку...') @@
to_tsquery('дедка <-> дедка');
?column?
----------
t
(1 row)
Обычный индекс GIN может выдать документы, в которых есть обе лексемы, но проверить расстояние между ними можно, только заглянув в tsvector:
postgres=# select to_tsvector('Бабка за дедку, дедка за репку...');
to_tsvector
------------------------------
'бабк':1 'дедк':3,4 'репк':6
(1 row)
В индексе RUM каждая лексема не просто ссылается на строки таблицы: вместе с каждым TID-м лежит и список позиций, в которых лексема встречается в документе. Вот как можно представить себе индекс, созданный на уже хорошо знакомой нам таблице с белой березой (по умолчанию для tsvector используется класс операторов rum_tsvector_ops):
postgres=# create extension rum;
CREATE EXTENSION
postgres=# create index on ts using rum(doc_tsv);
CREATE INDEX
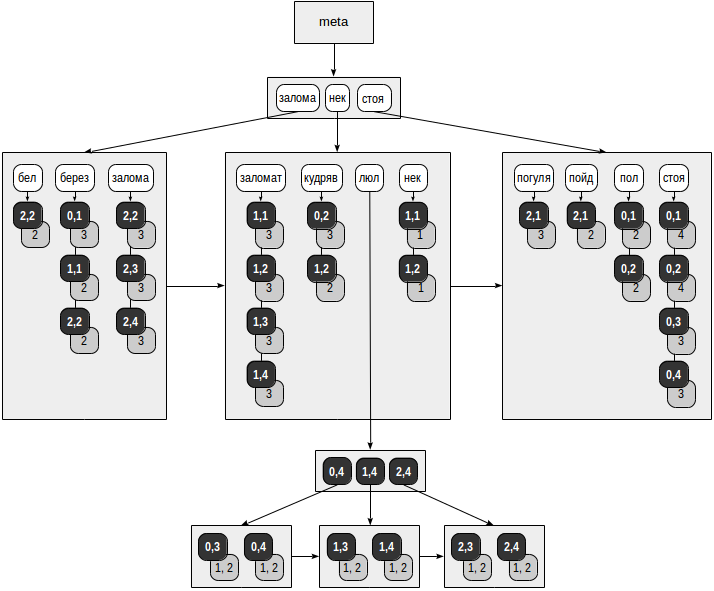
Серые квадраты на рисунке — добавленная позиционная информация:
postgres=# select ctid, doc, doc_tsv from ts;
ctid | doc | doc_tsv
--------+-------------------------+--------------------------------
(0,1) | Во поле береза стояла | 'берез':3 'пол':2 'стоя':4
(0,2) | Во поле кудрявая стояла | 'кудряв':3 'пол':2 'стоя':4
(0,3) | Люли, люли, стояла | 'люл':1,2 'стоя':3
(0,4) | Люли, люли, стояла | 'люл':1,2 'стоя':3
(1,1) | Некому березу заломати | 'берез':2 'заломат':3 'нек':1
(1,2) | Некому кудряву заломати | 'заломат':3 'кудряв':2 'нек':1
(1,3) | Люли, люли, заломати | 'заломат':3 'люл':1,2
(1,4) | Люли, люли, заломати | 'заломат':3 'люл':1,2
(2,1) | Я пойду погуляю | 'погуля':3 'пойд':2
(2,2) | Белую березу заломаю | 'бел':1 'берез':2 'залома':3
(2,3) | Люли, люли, заломаю | 'залома':3 'люл':1,2
(2,4) | Люли, люли, заломаю | 'залома':3 'люл':1,2
(12 rows)
В GIN еще есть отложенная вставка при указании параметра fastupdate; в RUM эта функциональность убрана.
Чтобы посмотреть, как индекс работает на реальных данных, воспользуемся известным нам архивом рассылки pgsql-hackers.
fts=# alter table mail_messages add column tsv tsvector;
ALTER TABLE
fts=# set default_text_search_config = default;
SET
fts=# update mail_messages
set tsv = to_tsvector(body_plain);
...
UPDATE 356125
Вот как выполняется запрос, использующий фразовый поиск, с индексом GIN:
fts=# create index tsv_gin on mail_messages using gin(tsv);
CREATE INDEX
fts=# explain (costs off, analyze)
select * from mail_messages where tsv @@ to_tsquery('hello <-> hackers');
QUERY PLAN
---------------------------------------------------------------------------------
Bitmap Heap Scan on mail_messages (actual time=2.490..18.088 rows=259 loops=1)
Recheck Cond: (tsv @@ to_tsquery('hello <-> hackers'::text))
Rows Removed by Index Recheck: 1517
Heap Blocks: exact=1503
-> Bitmap Index Scan on tsv_gin (actual time=2.204..2.204 rows=1776 loops=1)
Index Cond: (tsv @@ to_tsquery('hello <-> hackers'::text))
Planning time: 0.266 ms
Execution time: 18.151 ms
(8 rows)
Как видно из плана, GIN-индекс используется, но возвращает 1776 потенциальных совпадений, из которых остается 259, а 1517 отбрасываются на этапе перепроверки.
Удалим теперь GIN-индекс и построим RUM.
fts=# drop index tsv_gin;
DROP INDEX
fts=# create index tsv_rum on mail_messages using rum(tsv);
CREATE INDEX
Теперь в индексе есть вся необходимая информация и поиск выполняется точно:
fts=# explain (costs off, analyze)
select * from mail_messages
where tsv @@ to_tsquery('hello <-> hackers');
QUERY PLAN
--------------------------------------------------------------------------------
Bitmap Heap Scan on mail_messages (actual time=2.798..3.015 rows=259 loops=1)
Recheck Cond: (tsv @@ to_tsquery('hello <-> hackers'::text))
Heap Blocks: exact=250
-> Bitmap Index Scan on tsv_rum (actual time=2.768..2.768 rows=259 loops=1)
Index Cond: (tsv @@ to_tsquery('hello <-> hackers'::text))
Planning time: 0.245 ms
Execution time: 3.053 ms
(7 rows)
Сортировка по релевантности
Для того, чтобы выдавать документы сразу в нужном порядке, индекс RUM поддерживает упорядочивающие операторы, о которых у нас шла речь в части про GiST. Расширение rum определяет такой оператор
<=>, возвращающий некое расстояние между документом (tsvector) и запросом (tsquery). Например:fts=# select to_tsvector('Бабка за дедку, дедка за репку...') <=> to_tsquery('репка');
?column?
----------
16.4493
(1 row)
fts=# select to_tsvector('Бабка за дедку, дедка за репку...') <=> to_tsquery('дедка');
?column?
----------
13.1595
(1 row)
Документ оказался более релевантен первому запросу, чем второму: чем чаще в документе встречается слово, тем менее оно «ценно».
Снова попробуем сравнить GIN и RUM на относительно большом объеме данных: выберем десять наиболее релевантных документов, содержащих «hello» и «hackers».
fts=# explain (costs off, analyze)
select * from mail_messages
where tsv @@ to_tsquery('hello & hackers')
order by ts_rank(tsv,to_tsquery('hello & hackers'))
limit 10;
QUERY PLAN
---------------------------------------------------------------------------------------------
Limit (actual time=27.076..27.078 rows=10 loops=1)
-> Sort (actual time=27.075..27.076 rows=10 loops=1)
Sort Key: (ts_rank(tsv, to_tsquery('hello & hackers'::text)))
Sort Method: top-N heapsort Memory: 29kB
-> Bitmap Heap Scan on mail_messages (actual ... rows=1776 loops=1)
Recheck Cond: (tsv @@ to_tsquery('hello & hackers'::text))
Heap Blocks: exact=1503
-> Bitmap Index Scan on tsv_gin (actual ... rows=1776 loops=1)
Index Cond: (tsv @@ to_tsquery('hello & hackers'::text))
Planning time: 0.276 ms
Execution time: 27.121 ms
(11 rows)
GIN-индекс возвращает 1776 совпадений, которые затем отдельно сортируются для выборки десяти наиболее подходящих.
С индексом RUM запрос выполняется простым индексным сканированием: никакие лишние документы не просматриваются, никакой отдельной сортировки не требуется:
fts=# explain (costs off, analyze)
select * from mail_messages
where tsv @@ to_tsquery('hello & hackers')
order by tsv <=> to_tsquery('hello & hackers')
limit 10;
QUERY PLAN
--------------------------------------------------------------------------------------------
Limit (actual time=5.083..5.171 rows=10 loops=1)
-> Index Scan using tsv_rum on mail_messages (actual ... rows=10 loops=1)
Index Cond: (tsv @@ to_tsquery('hello & hackers'::text))
Order By: (tsv <=> to_tsquery('hello & hackers'::text))
Planning time: 0.244 ms
Execution time: 5.207 ms
(6 rows)
Дополнительная информация
Индекс RUM, как и GIN, можно построить по нескольким полям. Но если в GIN лексемы разных столбцов хранятся независимо друг от друга, то RUM позволяет «связать» основное поле (tsvector в нашем случае) с дополнительным. Для этого надо воспользоваться специальным классом операторов rum_tsvector_addon_ops:
fts=# create index on mail_messages using rum(tsv rum_tsvector_addon_ops, sent)
with (attach='sent', to='tsv');
CREATE INDEX
Такой индекс можно использовать, чтобы выдавать результаты в порядке сортировки по дополнительному полю:
fts=# select id, sent, sent <=> '2017-01-01 15:00:00'
from mail_messages
where tsv @@ to_tsquery('hello')
order by sent <=> '2017-01-01 15:00:00'
limit 10;
id | sent | ?column?
---------+---------------------+----------
2298548 | 2017-01-01 15:03:22 | 202
2298547 | 2017-01-01 14:53:13 | 407
2298545 | 2017-01-01 13:28:12 | 5508
2298554 | 2017-01-01 18:30:45 | 12645
2298530 | 2016-12-31 20:28:48 | 66672
2298587 | 2017-01-02 12:39:26 | 77966
2298588 | 2017-01-02 12:43:22 | 78202
2298597 | 2017-01-02 13:48:02 | 82082
2298606 | 2017-01-02 15:50:50 | 89450
2298628 | 2017-01-02 18:55:49 | 100549
(10 rows)
Здесь мы ищем подходящие строки, расположенные как можно ближе к указанной дате, не важно, раньше или позже. Чтобы получить результаты, строго предшествующие дате (или следующие за ней), надо воспользоваться операцией
<=| (или |=>).Запрос, как мы и ожидаем, выполняется простым индексным сканированием:
ts=# explain (costs off)
select id, sent, sent <=> '2017-01-01 15:00:00'
from mail_messages
where tsv @@ to_tsquery('hello')
order by sent <=> '2017-01-01 15:00:00'
limit 10;
QUERY PLAN
---------------------------------------------------------------------------------
Limit
-> Index Scan using mail_messages_tsv_sent_idx on mail_messages
Index Cond: (tsv @@ to_tsquery('hello'::text))
Order By: (sent <=> '2017-01-01 15:00:00'::timestamp without time zone)
(4 rows)
Если бы мы создали индекс без дополнительной информации о связи полей, то для аналогичного запроса пришлось бы выполнять сортировку всех полученных от индекса результатов.
Конечно, кроме даты в RUM-индекс можно добавить поля и других типов данных — поддерживаются практически все базовые типы. Например, интернет-магазин может быстро показывать товары по новизне (дата), цене (numeric), популярности или размеру скидки (целое или плавающая точка).
Другие классы операторов
Для полноты картины стоит сказать и про другие доступные классы операторов.
Начнем с rum_tsvector_hash_ops и rum_tsvector_hash_addon_ops. Они во всем аналогичны уже рассмотренным выше rum_tsvector_ops и rum_tsvector_addon_ops, но в индексе сохраняется не сама лексема, а ее хеш-код. Это может уменьшить размер индекса, но, разумеется, делает поиск менее точным и требующим перепроверки. Кроме того, индекс перестает поддерживать поиск частичных совпадений.
Любопытен класс операторов rum_tsquery_ops. Он позволяет решать «обратную» задачу: находить запросы, которые соответствуют документу. Зачем это может понадобиться? Например, подписать пользователя на новые товары по его фильтру. Или автоматически классифицировать новые документы. Вот простой пример:
fts=# create table categories(query tsquery, category text);
CREATE TABLE
fts=# insert into categories values
(to_tsquery('vacuum | autovacuum | freeze'), 'vacuum'),
(to_tsquery('xmin | xmax | snapshot | isolation'), 'mvcc'),
(to_tsquery('wal | (write & ahead & log) | durability'), 'wal');
INSERT 0 3
fts=# create index on categories using rum(query);
CREATE INDEX
fts=# select array_agg(category)
from categories
where to_tsvector(
'Hello hackers, the attached patch greatly improves performance of tuple
freezing and also reduces size of generated write-ahead logs.'
) @@ query;
array_agg
--------------
{vacuum,wal}
(1 row)
Остаются классы операторов rum_anyarray_ops и rum_anyarray_addon_ops — они предназначены для работы не с tsvector, а с массивами. Для GIN это уже рассматривалось в прошлый раз, так что нет резона повторяться.
Размер индекса и журнала предзаписи
Понятно, что, раз RUM содержит больше информации, чем GIN, то и места он будет занимать больше. В прошлый раз мы сравнивали размеры разных индексов; добавим в эту таблицу и RUM:
rum | gin | gist | btree
--------+--------+--------+--------
457 MB | 179 MB | 125 MB | 546 MB
Как видно, объем вырос довольно существенно — такова плата за быстрый поиск.
Еще один неочевидный момент, на который стоит обратить внимание, связан с тем, что RUM является расширением, то есть его можно устанавливать, не внося никаких изменений в ядро системы. Это стало возможным в версии 9.6 благодаря патчу, который сделал Александр Коротков. Одна из задач, которые при этом пришлось решить — генерация журнальных записей. Механизм журналирования обязан быть абсолютно надежным, поэтому расширение нельзя пускать в эту кухню. Вместо того, чтобы позволять расширению создавать свои собственные типы журнальных записей, сделано так: код расширения сообщает о намерении изменить страницу, вносит в нее любые изменения и сигнализирует о завершении, а уже ядро системы сравнивает старую и новую версии страницы и само генерирует необходимые унифицированные журнальные записи.
Текущий алгоритм генерации сравнивает страницы побайтово, находит измененные фрагменты и записывает в журнал каждый такой фрагмент вместе со смещением от начала страницы. Это работает хорошо и при изменении всего нескольких байтов, и когда страница поменялась полностью. Но если внутрь страницы добавить какой-то фрагмент, сдвинув остальное содержимое вниз (или, наоборот, убрать фрагмент, сдвинув содержимое вверх), формально изменится значительно больше байтов, чем реально было добавлено или удалено.
Из-за этого активно изменяющийся RUM-индекс может генерировать журнальные записи существенно большего размера, чем GIN (который, будучи не расширением, а частью ядра, управляет журналом сам). Степень этого неприятного эффекта сильно зависит от реальной нагрузки, но, чтобы как-то почувствовать проблему, давайте попробуем несколько раз удалить и добавить некоторое количество строк, перемежая эти действия очисткой (vacuum). Оценить размер журнальных записей можно так: в начале и в конце запомнить позицию в журнале функцией pg_current_wal_location (до десятой верcии — pg_current_xlog_location) и затем посмотреть на их разность.
Тут, конечно, надо иметь в виду много факторов. Нужно убедиться, что в системе работает только один пользователь, иначе в расчет попадут «лишние» записи. Даже в этом случае мы учитываем не только RUM, но и изменения самой таблицы и индекса, поддерживающего первичный ключ. Влияют и значения конфигурационных параметров (здесь использовался уровень журнала replica, без сжатия). Но все же попробуем.
fts=# select pg_current_wal_location() as start_lsn \gset
fts=# insert into mail_messages(parent_id, sent, subject, author, body_plain, tsv)
select parent_id, sent, subject, author, body_plain, tsv
from mail_messages where id % 100 = 0;
INSERT 0 3576
fts=# delete from mail_messages where id % 100 = 99;
DELETE 3590
fts=# vacuum mail_messages;
VACUUM
fts=# insert into mail_messages(parent_id, sent, subject, author, body_plain, tsv)
select parent_id, sent, subject, author, body_plain, tsv
from mail_messages where id % 100 = 1;
INSERT 0 3605
fts=# delete from mail_messages where id % 100 = 98;
DELETE 3637
fts=# vacuum mail_messages;
VACUUM
fts=# insert into mail_messages(parent_id, sent, subject, author, body_plain, tsv)
select parent_id, sent, subject, author, body_plain, tsv from mail_messages
where id % 100 = 2;
INSERT 0 3625
fts=# delete from mail_messages where id % 100 = 97;
DELETE 3668
fts=# vacuum mail_messages;
VACUUM
fts=# select pg_current_wal_location() as end_lsn \gset
fts=# select pg_size_pretty(:'end_lsn'::pg_lsn - :'start_lsn'::pg_lsn);
pg_size_pretty
----------------
3114 MB
(1 row)
Итак, получилось около 3 ГБ. А если тот же эксперимент повторить с индексом GIN, будет всего около 700 МБ.
Поэтому хотелось бы иметь другой алгоритм, находящий минимальное количество операций вставки и удаления, с помощью которых одно состояние страницы можно привести к другому — аналогично тому, как работает утилита diff. Такой алгоритм уже реализовал Олег Иванов, его патч обсуждается. В приведенном примере этот патч, ценой небольшого замедления, позволяет сократить объем журнальных записей в полтора раза, до 1900 МБ.
Свойства
Традиционно посмотрим на свойства метода доступа rum (запросы приводились ранее), обратив внимание на отличия от gin.
Свойства метода:
amname | name | pg_indexam_has_property
--------+---------------+-------------------------
rum | can_order | f
rum | can_unique | f
rum | can_multi_col | t
rum | can_exclude | t -- f для gin
Свойства индекса:
name | pg_index_has_property
---------------+-----------------------
clusterable | f
index_scan | t -- f для gin
bitmap_scan | t
backward_scan | f
Отметим, что RUM, в отличие от GIN, поддерживает индексное сканирование — иначе нельзя было бы получить ровно необходимое количество результатов в запросах с фразой limit. Соответственно, нет необходимости и в аналоге параметра gin_fuzzy_search_limit. Ну и, как следствие, индекс может использоваться для поддержки ограничений исключения.
Свойства уровня столбца:
name | pg_index_column_has_property
--------------------+------------------------------
asc | f
desc | f
nulls_first | f
nulls_last | f
orderable | f
distance_orderable | t -- f для gin
returnable | f
search_array | f
search_nulls | f
Здесь отличие в том, что RUM поддерживает упорядочивающие операторы. Хотя и не для всех классов операторов: например, для tsquery_ops будет false.
Продолжение следует.
Комментарии (18)

linuxover
05.12.2017 09:01еще вопрос: по администрированию: RUM пересобираем отдельно — ок.
но вот например надо смигрировать с Pg 9.5.5 на 9.5.6, RUM пересобирать надо или нет?
erogov Автор
05.12.2017 13:55Версии, отличающиеся только последней цифрой, всегда совместимы, так что при переходе с 9.5.5 и 9.5.6 точно ничего не надо. Вот если с 9.5 на 9.6, то скорее всего придется пересобрать.
linuxover
а вот если не tsvector, а свои функции?
например у нас есть некие массивы txt (например — облако меток для постов блога), допустим столбик
"column" TEXT[]кладем их в GIN
далее GIN позволяет индекс использовать в запросах:
но при этом выдача несортирована.
Вопрос: а как с GIN или RUM сортировать выборку например "начиная от тех кто еще имеет 'd' в списке"?
Я чет попытался понять про приоритеты и GIN но не понял можно ли и как правильно индексировать своё.
linuxover
сорри скобки недописал
erogov Автор
RUM позволяет использовать для сортировки другой столбец таблицы. Сделать напрямую, чтобы сортировка была по какому-то свойству проиндексированного массива, не получится.
Но если очень нужно, то всегда можно пойти в обход.
Вот у нас таблица и какие-то строчки в ней:
Фактически мы хотим получить вот такой результат (только с помощью индекса):
Ок, создаем дополнительный столбец под нужное для сортировки свойство и триггер. Столбец делаем целочисленным, потому что с boolean RUM не научили работать.
Можно обновить столбец, заодно проверим, что триггер отрабатывает корректно:
Ну а теперь уже индекс:
Результат правильный, и в плане — индексный доступ:
Оно?
linuxover
Оно, спасибо за подробный пример, попробую обязательно!
PS: а байду с триггером можно ли не разводить?
Если свять IMMUTABLE has_d функцию:
то можно ли поправить WITH секцию на фукнциональный стайл?:
но в любом случае, можно или нельзя функцию использовать — огромное спасибо за развернутый пример :)
erogov Автор
Увы, сейчас в параметре attach ожидается имя столбца таблицы, ничего другого туда не подсунуть. Но я поговорю с разработчиками, возможно это получится изменить.
linuxover
> Но я поговорю с разработчиками, возможно это получится изменить.
если имя функции передавать (принимающей весь рекорд таблицы), то наверно можно будет полностью функциональный индекс построить.
иногда ведь и массива то может не быть, его аналог функций *tsvector может строить налету.
linuxover
круто. а если has_d было бы числом 0..N, то можно ли было бы по нему отсортировать?
я правильно понимаю что если has_d у каждого будет свой, то оператор
выдаст близкие, то есть сперва те у кого has_d = 27, потом те у кого has_d = 26 и 28? так?
или потом только те у кого has_d = 26, а 28 нет?
linuxover
все, сам понял, да 26 и 28
PS: опечатка WHERE/ORDER BY в вопросе :)
сорри с телефона писал
erogov Автор
Да, так и есть. Но есть еще операторы
|=>и<=|. Например,has_d <=| 27выдаст 27, 26, 25, ..., 0, 28, 29, ...select_artur
linuxover, если я правильно понял вопрос, то можно поступить чуть проще.
При этом способе сортировка также выполняется в индексе:
erogov Автор
А ведь точно! В этом конкретном случае так, конечно, значительно проще и правильней.
Артур, раз уж ты сюда пришел (: расскажи, реально ли для attach/to запилить поддержку выражений, а не только столбцов таблицы? Чтобы можно было функциональные индексы делать.
select_artur
Такую поддержку реально сделать ) Но ее пока нет.
linuxover
не не правильно, на выходе нужны только
<@ {a,b,c}, а только сортировка по порядку "начиная от тех кто еще иdимеет".то есть имеем облако меток например на хабре. Представим что некий анализатор статистики добавляет метки по мере просмотров "популярное", "сверхпопулярное" итп
и когда пользователь ищет по меткам — ему выдавать выдачу "сперва очень популярное, потом просто популярное, а потом все остальное". То есть
a,b,c— метки выданные пользователем, аd,e,f— добавленные движком. Поэтому в фильтре они не участвуют, а только вORDER BY.Как-то так.
Ну и в общем виде — решение erogov — обобщенное. Ему б еще функциндекс можно было б прикрутить — ваще круто бы было :D
erogov Автор
На свежую голову — и у меня, и у Артура на самом деле должно быть условие
where tags && '{a,b,c}', а неwhere tags <@ '{a,b,c,d}'.linuxover
то есть в WHERE может быть одно а в order by другое и будет из индекса нормально выбирать?
надо будет попробовать. Разгребусь с текучкой — покопаюсь, спасибо :)
erogov Автор
Ну да, лишь бы условие в WHERE поддерживалось индексом, а в ORDER BY был бы
<=>.