
Data Management Platform
Задача, для решения которой нам понадобились инструменты работы с большими данными, – сегментация пользователей. Класс систем, которые решают задачу сегментации пользователей во всём мире принято называть Data Management Platform или сокращённо DMP. На вход DMP поступают данные о действиях пользователей (в первую очередь, это факты посещений тех или иных страниц в интернете), на выходе DMP выдает «профиль пользователя» — его пол, возраст, интересы, намерения и так далее. Этот профиль в дальнейшем используется для таргетирования рекламы, персональных рекомендаций и для персонализации контента в целом. Продробнее о DMP можно почитать тут: http://digitalmarketing-glossary.com/What-is-DMP-definition.
Поскольку DMP работает с данными большого количества пользователей, объёмы данных, которые нужно обрабатывать, могут достигать очень внушительных размеров. Например, наша DMP Facetz.DCA обрабатывает данные 600 миллионов браузеров, ежедневно обрабатывая почти полпетабайта данных.
Архитектура DMP Facetz.DCA
Для того, чтобы обрабатывать такие объёмы данных необходима хорошая масштабируемая архитектура. Изначально мы построили систему на основе стека hadoop. Подробное описание архитектуры вполне заслуживает отдельной статьи, в этом же материале я ограничусь кратким описанием:
- Логи действий пользователя складываются на HDFS – распределённую файловую систему, являющуюся одной из базовых компонент экосистемы hadoop
- Из HDFS данные складываются в хранилище сырых данных, реализованное на основе Apache HBase – распределенной масштабируемой базы данных, построенной на основе идей Big Table. По сути, HBase – очень удобная для массовой обработки key-value база данных. Все данные пользователей хранятся в одной большой таблице facts. Данные одного пользователя соответствуют одной строке HBase, что позволяет очень быстро и удобно получить всю необходимую информацию о нём.
- Один раз в сутки запускается Analytic Engine – большой MapReduce job, который, собственно, и выполняет сегментацию пользователей. По сути, Analytic Engine – контейнер для правил сегментации, которые отдельно готовятся аналитиками. Например, один скрипт может размечать пол пользователя, другой — его интересы и так далее.
- Готовые сегменты пользователей складываются в Aerospike – key-value базу данных, которая очень хорошо заточена на быструю отдачу – 99% запросов на чтение отрабатывают менее чем за 1 мс даже при больших нагрузках в десятки тысяч запросов в секунду.
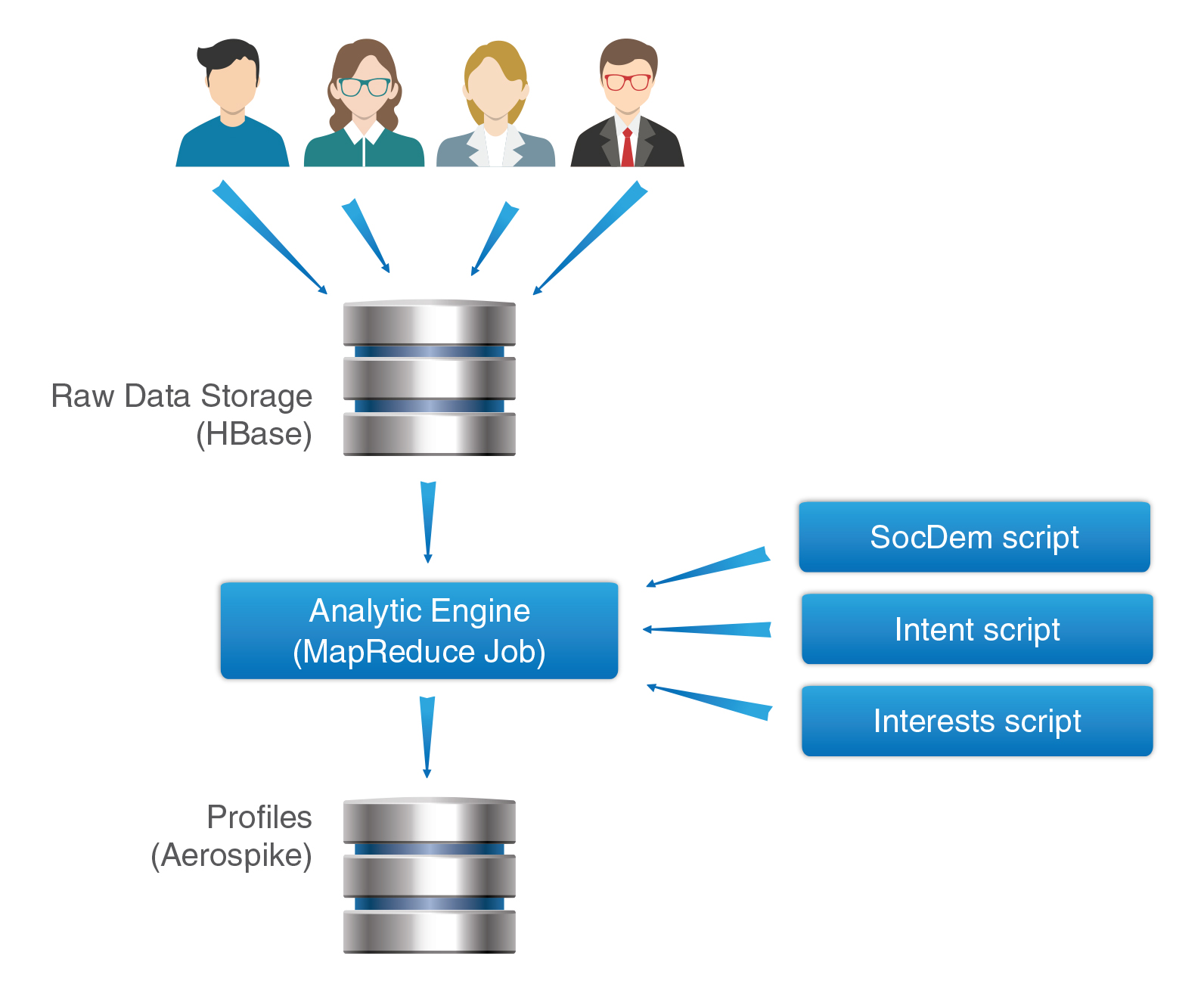
Архитектура Facetz.DCA
Проблемы MapReduce
Разработанная архитектура показала себя хорошо – позволила быстро смасштабироваться до обработки профилей пользователей всего Рунета и размечать их при помощи сотен скриптов (каждый может размечать пользователя по нескольким сегментам). Однако она оказалась не лишённой недостатков. Основная проблема – отсутствие интерактивности при обработке. MapReduce, по своей природе, – парадигма offline–обработки данных. Так, например, если пользователь посмотрел билеты на футбол сегодня, в сегмент «Интересуется футболом» он может попасть только завтра. В некоторых случаях такая задержка является критичной. Типичный пример – ретаргетинг – реклама пользователю товаров, которые он уже посмотрел. На графике приведена вероятность совершения покупки пользователем после просмотра товара по прошествии времени:

График вероятности конверсии после просмотра товара. При отстутсвии real-time движка для нас доступна только зеленая часть, в то время как максимальная вероятность приходится на первые часы.
Видно, что самая большая вероятность покупки – в течение нескольких первых часов. При таком подходе система узнала бы, что пользователь хочет купить товар, только по прошествии суток – когда вероятность покупки практически вышла на плато.
Очевидно, что необходим механизм потоковой real-time обработки данных, который сводит к минимуму задержку. При этом хочется сохранить универсальность обработки – возможность строить сколь угодно сложные правила сегментации пользователей.
Модель Акторов
Поразмыслив, мы пришли к выводу, что лучше всего для решения задачи нам подходит парадигма реактивного программирования и модель акторов. Актор – это примитив параллельного программирования, который умеет:
- Принимать сообщения
- Посылать сообщения
- Создавать новых актор’ов
- Устанавливать реакцию на сообщения
Модель акторов зародилась в erlang-сообществе, сейчас реализации этой модели существуют для многих языков программирования.
Для языка scala, на котором написана наша DMP, очень хорошим тулкитом является akka. Она лежит в основе нескольких популярных фреймворков, хорошо задокументированна. Кроме того, на Coursera есть прекрасный курс принципы реактивного программирования, в котором эти самые принципы рассказываются как раз на примере akka. Отдельно стоит упомянуть модуль akka cluster, который позволяет масштабировать решения (базирующиеся на акторах) на несколько серверов.
Архитектура Real-Time DMP
Итоговая архитектура выглядит следующим образом:

Поставщик данных складывает информацию о действиях пользователей в RabbitMQ.
- Из RabbitMQ сообщения о действиях пользователя вычитывает Dispatcher. Dispatcher-ов может быть несколько, они работают независимо.
- Для каждого онлайн-пользователя в системе заводится актор. Dispatcher отправляет сообщение о новом событии (вычитанном из RabbitMQ) соответствующему актору (или заводит новый актор, если это первое действие пользователя и для него ещё нет актора).
- Актор, соответствующий пользователю, добавляет информацию о действии в список пользовательских действий и запускает скрипты сегментации (те же, что запускают Analytic Engine при MapReduce-обработке).
- Данные о размеченных сегментах складываются в Aerospike. Также данные о сегментах и действиях пользователях доступны по API, подключенным напрямую к акторам.
- Если о пользователе не поступало данных в течение часа, сессия считается законченной и актор уничтожается.
Шардированием акторов по кластеру, их жизнью и уничтожением управляет akka, что существенно упростило разработку.
Текущие результаты:
- Akka-кластер из 6 нод;
- Поток данных 3000 событий в секунду;
- 4-6 миллионов пользователей онлайн (в зависимости от дня недели);
- Среднее время выполнения одного скрипта сегментации пользователей меньше пяти миллисекунд;
- Среднее время между событием и сегментацией на основе этого события – одна секунда.

Дальнейшее развитие
Наш Real-Time Engine показал себя хорошо и мы планируем развивать его дальше. Список шагов, которые мы планируем предпринять:
- Персистентность – сейчас Real-Time Engine сегментирует пользователей только на основе последней сессии. Мы планируем добавить подтягивание более старой информации из HBase при появлении нового пользователя.
- На текущий момент только часть наших данных переведена на realtime-обработку. Мы планируем постепенно перевести все наши источники данных на потоковую обработку, после этого поток обрабатываемых данных возрастёт до 30000 событий в секунду.
- После завершения перевода на Realtime мы сможем отказаться от ежедневного расчёта MapReduce, что позволит сэкономить на серверах за счёт того, что обрабатываться будут только те пользователи, которые реально сегодня проявили активность в интернете.
Ссылки на похожие решения
В конце хотелось бы привести несколько ссылок на некоторые фреймворки, на основе которых также можно строить потоковую обработку данных:
– Apache Storm
– Spark Streaming
– Apache Samza
Спасибо за внимание, готовы ответить на ваши вопросы.
Комментарии (48)
gurinderu
25.06.2015 19:21а зачем на каждого юзера создаётся по актору?

asash Автор
28.06.2015 09:46+1Актор на каждого юзера создается для того чтобы инкапсулировать в себя всю информацию про этого юзера, чтобы вся нужная информация нужная для обработки была доступна локально.
gurinderu
28.06.2015 20:02Хм, а почему бы всю необходимое информацию не сохранить в message и иметь 1 актор на всех юзеров?

Ivanhoe
28.06.2015 20:56+2Да в общем зачем, если акторы достаточно легковесны? Размазывать по кластеру, опять же, можно.
gurinderu
29.06.2015 10:06Размазывать то, можно но стоит ли. Это опять же лишние затраты на общение между нодами.
Kane
29.06.2015 11:33Наоборот, цель такого подхода — сократить взаимодействие между нодами в системе, которая на одной ноде работать не может. Актор содержит весь необходимый стейт и в состоянии сам выдать необходимую информацию о себе.
Doggy
28.06.2015 23:05+2На заметку: модель Акторов зародилась не в сообществе эрланга.
Модели акторов 40 лет!Kane
28.06.2015 23:16В документации по Akka постоянно встречаются отсылки к Erlang-реализации
Doggy
28.06.2015 23:19Это не означает, что акторы зародились в сообществе эрланга.
HDDimon
29.06.2015 09:46+1Акторы зародились не в сообществе Erlang, но как раз в Erlang появилась одна из первых реализаций модели акторов, которую можно использовать в реальных системах на больших нагрузках. В целом же, почему в доках по акка идет постоянная отсылка к Erlang? Ответ очень прост, авторы акка в первых версиях пытались просто портировать модель Erlang на Scala. Позже же появились некоторые улучшения, которых нет в Erlang.
Doggy
29.06.2015 09:54Все эти доводы не являются достаточным оправданием для подмены понятия «первая реализация используемая в реальных системах» на «зародились в сообществе».
Я просто оставил ссылку, чтобы пытливые умы могли более детально посмотреть историю акторов при желании. В интернетах порой бывает трудно найти первоисточник и выяснить истинное положение вещей. Мне кажется надо придерживаться фактов и стараться избегать искажения информация при повествовании.
ilnarb
А сколько серверов понадобилось бы на 1 млрд юзеров и 20 млрд событий в сутки (примерно 500к/с в пике)?
asash Автор
Сложно сказать. На таком потоке вероятно вылезут какие-то дополнительные ограничения, которые не видно сейчас. Например у меня серьезные подозрения что RabbitMQ пришлось бы заменить на что-то другое.