Перевод статьи Create a scalable REST API with Falcon and RHSCL автора Shane Boulden.
В этой статье мы создадим REST API на основе фреймворка Python Falcon, потестируем производительность и попробуем его масштабировать, чтобы справиться с нагрузками.
Для реализации и тестирования нашего API нам понадобятся следующие компоненты:
Falcon — это минималистичный веб-фреймворк для построения веб API, согласно сайту Falcon он до 10 раз быстрее чем Flask. Falcon быстрый!
Я предполагаю, что у вас уже установлен PostgreSQL (куда же мы без него). Нам необходимо создать БД orgdb и пользователя orguser.
Этому пользователю необходимо в настройках PostgreSQL в файле pg_hba.conf прописать доступ по паролю к только что созданной БД и выдать все права.
Конфигурирование базы данных завершено. Перейдем к созданию нашего Falcon приложения.
Для нашего приложения будем использовать Python3.5.
Создадим virtualenv и установим необходимые библиотеки:
Создадим файл ‘app.py’:
Теперь опишем модели в файле ‘models.py’:
Мы создали два вспомогательных метода для настройки приложения ‘init_tables’ и ‘generate_users’. Запустим их для инициализации приложения:
Если вы зайдете в БД orgdb, то в таблице orguser увидите созданных пользователей.
Теперь вы можете протестировать API:
Оценим производительность нашего API с помощью Taurus. По возможности необходимо развернуть Taurus на отдельной машине.
Устанавливаем Taurus в нашем виртуальном окружении:
Теперь мы можем создать сценарий для нашего теста. Создаем файл bzt-config.yml следующего содержания (не забудьте указать верный IP адрес):
Этот тест будет симулировать веб трафик от 100 пользователей, с нарастанием их числа в течение минуты, и держать нагрузку 2 минуты 30 секунд.
Запустим API с одним воркером:
Теперь мы можем запустить Taurus. При первом запуске он скачает нужные зависимости:
После установки зависимостей отобразится наша консоль с ходом исполнения теста:
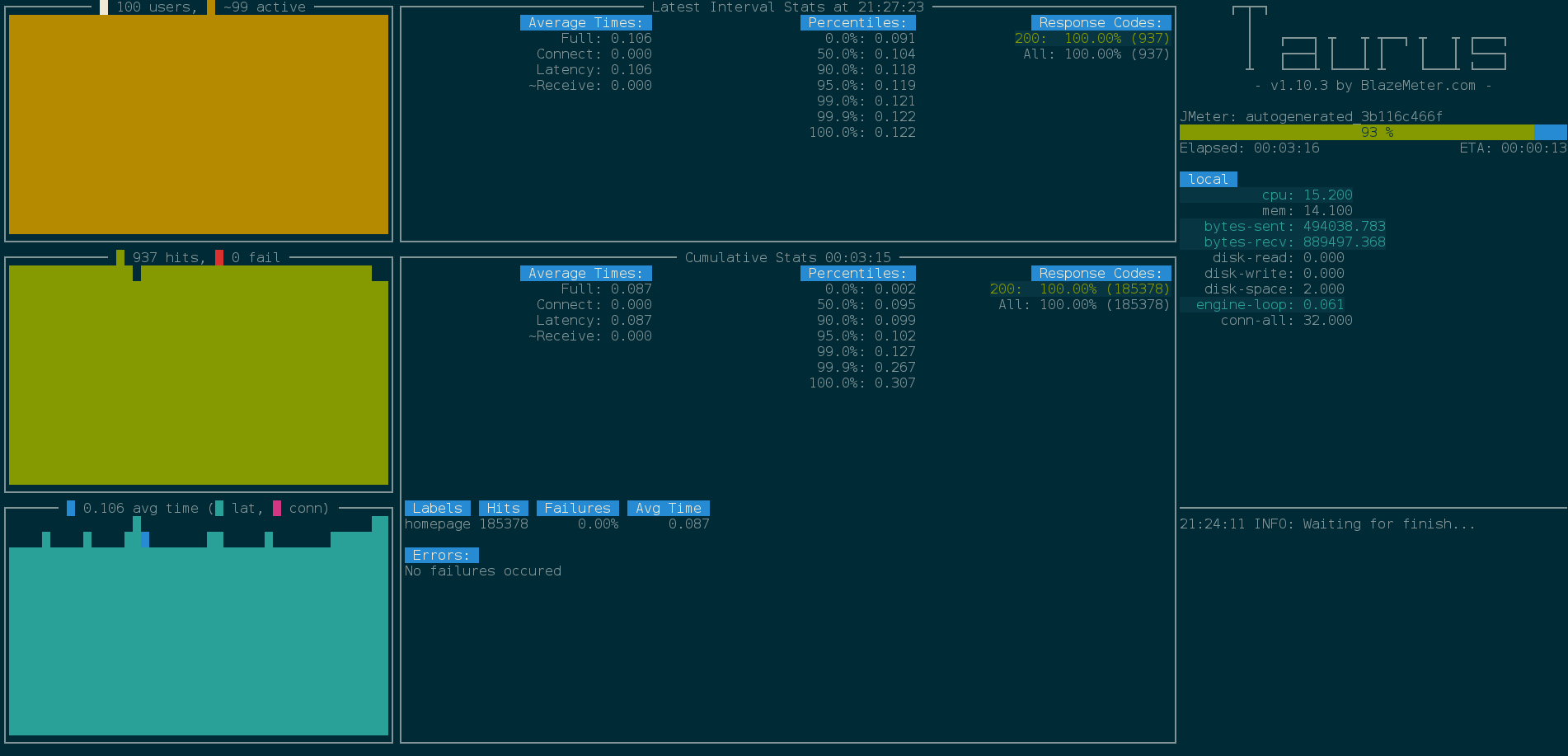
Опцию -report мы используем для загрузки результатов в BlazeMeter и генерации веб-отчета.
Наше API отлично справляется со 100 пользователями. Мы достигли пропускной способности в ~1000 запросов/секунду, без ошибок и со средним временем ответом 0.1с.
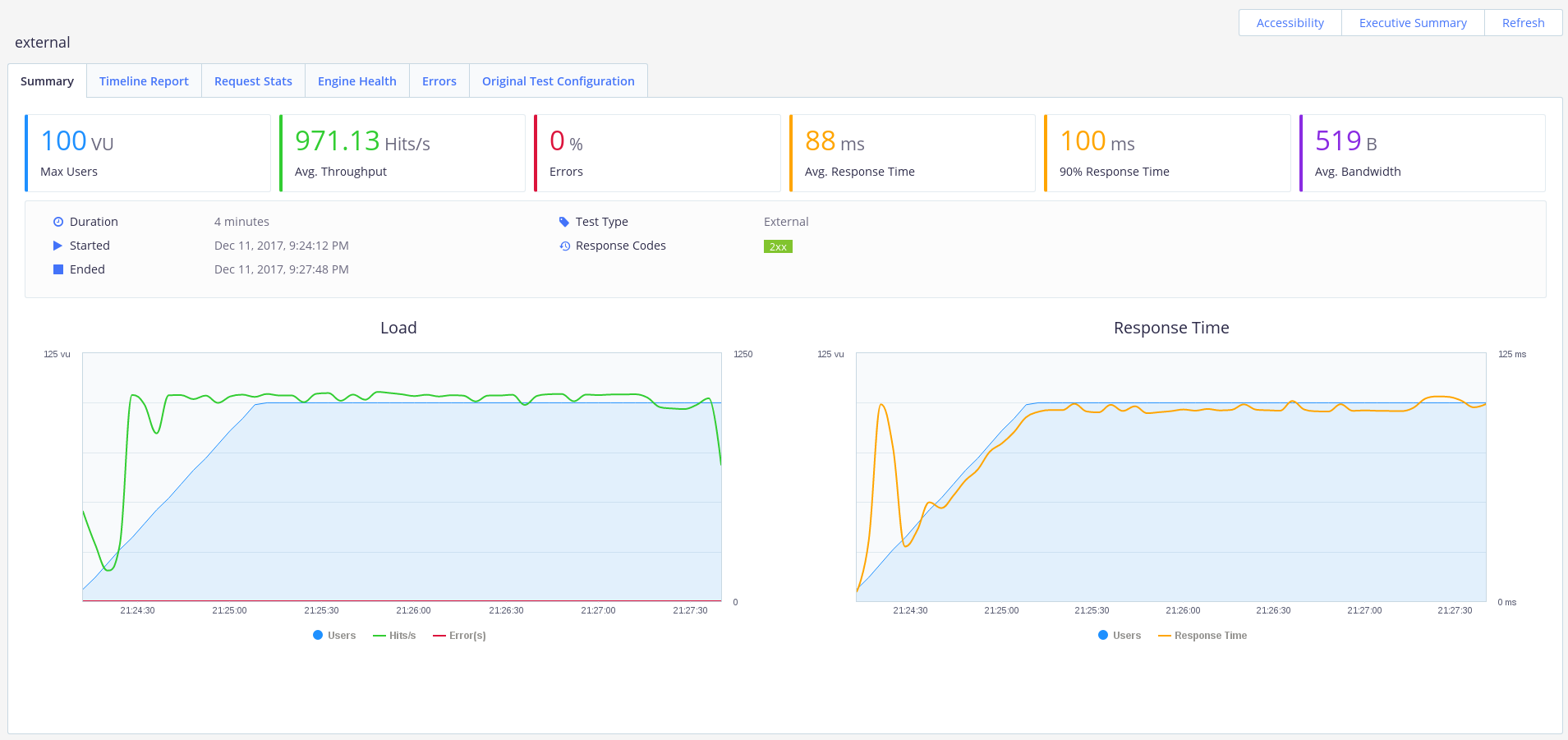
Отлично, а что если пользователей будет 500? Изменим параметр concurrency на 500 в нашем файле bzt-config.yml и снова запустим Taurus.
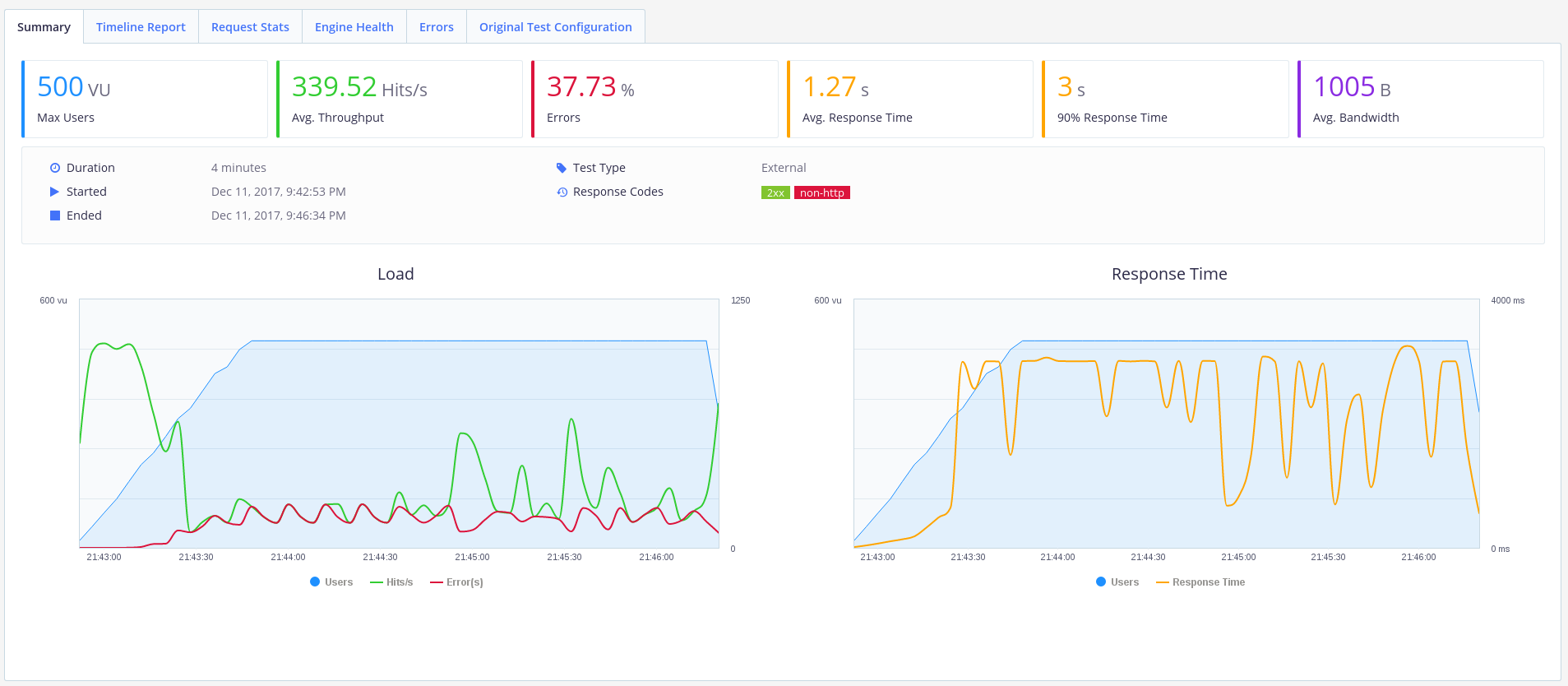
Хм. Похоже наш одинокий воркер не справился с нагрузкой. 40% ошибок — это не дело.
Попробуем увеличить количество воркеров.
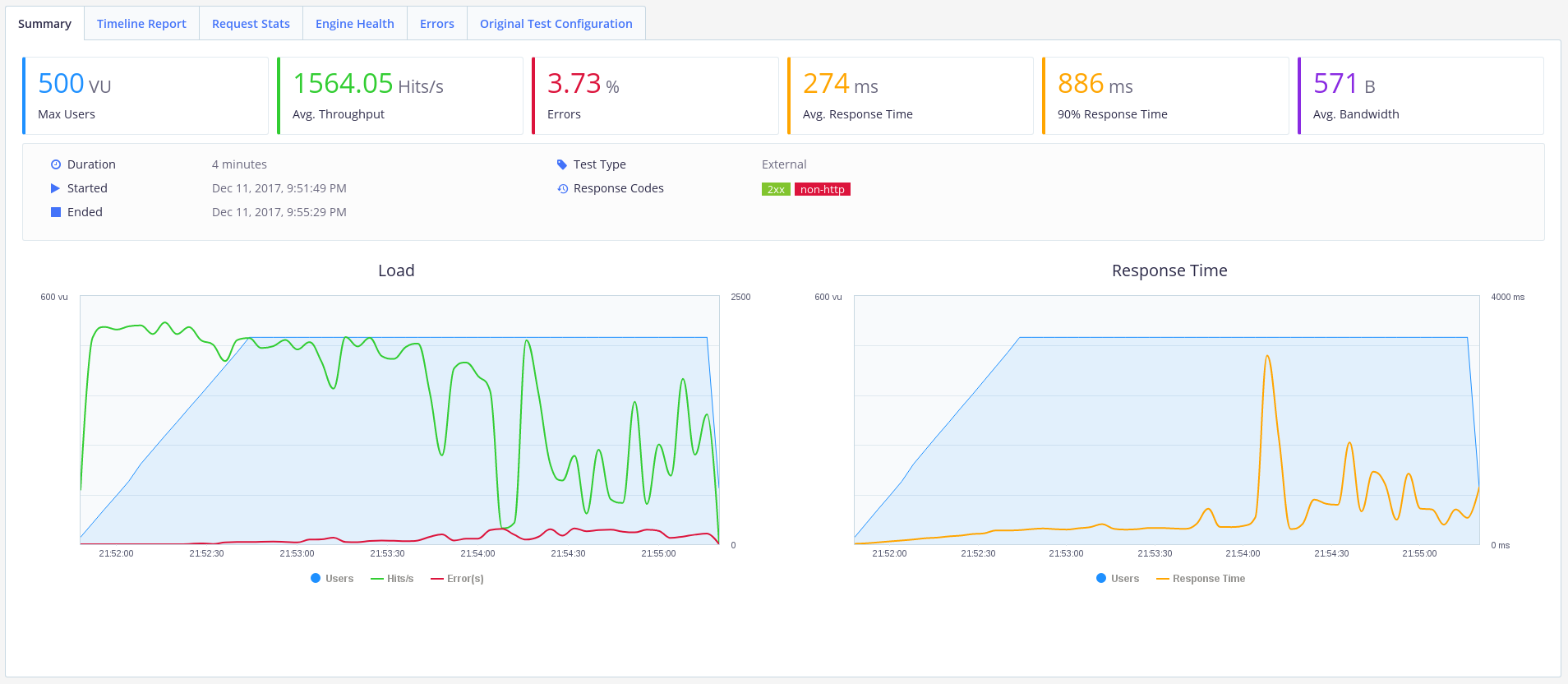
Выглядит лучше. Ошибки еще есть, но пропускная способность увеличилась до ~1500 запросов/секунду, и среднее время отклика уменьшилось до ~270 мс. Такое API уже можно использовать.
Можно настроить PostgreSQL под железо с помощью PgTune.
На сегодня все. Спасибо, что читали!
В этой статье мы создадим REST API на основе фреймворка Python Falcon, потестируем производительность и попробуем его масштабировать, чтобы справиться с нагрузками.
Для реализации и тестирования нашего API нам понадобятся следующие компоненты:
Почему Falcon?
Falcon — это минималистичный веб-фреймворк для построения веб API, согласно сайту Falcon он до 10 раз быстрее чем Flask. Falcon быстрый!
Начало
Я предполагаю, что у вас уже установлен PostgreSQL (куда же мы без него). Нам необходимо создать БД orgdb и пользователя orguser.
Этому пользователю необходимо в настройках PostgreSQL в файле pg_hba.conf прописать доступ по паролю к только что созданной БД и выдать все права.
Конфигурирование базы данных завершено. Перейдем к созданию нашего Falcon приложения.
Создание API
Для нашего приложения будем использовать Python3.5.
Создадим virtualenv и установим необходимые библиотеки:
$ virtualenv ~/falconenv
$ source ~/falconenv/bin/activate
$ pip install peewee falcon gunicorn
Создадим файл ‘app.py’:
import falcon
from models import *
from playhouse.shortcuts import model_to_dict
import json
class UserIdResource():
def on_get(self, req, resp, user_id):
try:
user = OrgUser.get(OrgUser.id == user_id)
resp.body = json.dumps(model_to_dict(user))
except OrgUser.DoesNotExist:
resp.status = falcon.HTTP_404
class UserResource():
def on_get(self, req, resp):
users = OrgUser.select().order_by(OrgUser.id)
resp.body = json.dumps([model_to_dict(u) for u in users])
api = falcon.API()
users = UserResource()
users_id = UserIdResource()
api.add_route('/users/', users)
api.add_route('/users/{user_id}', users_id)
Теперь опишем модели в файле ‘models.py’:
from peewee import *
import uuid
psql_db = PostgresqlDatabase(
'orgdb',
user='orguser',
password='123456',
host='127.0.0.1')
def init_tables():
psql_db.create_tables([OrgUser], safe=True)
def generate_users(num_users):
for i in range(num_users):
user_name = str(uuid.uuid4())[0:8]
OrgUser(username=user_name).save()
class BaseModel(Model):
class Meta:
database = psql_db
class OrgUser(BaseModel):
username = CharField(unique=True)
Мы создали два вспомогательных метода для настройки приложения ‘init_tables’ и ‘generate_users’. Запустим их для инициализации приложения:
$ python
Python 3.5.1 (default, Sep 15 2016, 08:30:32)
Type "help", "copyright", "credits" or "license" for more information.
>>> from app import *
>>> init_tables()
>>> generate_users(20)
Если вы зайдете в БД orgdb, то в таблице orguser увидите созданных пользователей.
Теперь вы можете протестировать API:
$ gunicorn app:api -b 0.0.0.0:8000
[2017-12-11 23:19:40 +1100] [23493] [INFO] Starting gunicorn 19.7.1
[2017-12-11 23:19:40 +1100] [23493] [INFO] Listening at: http://0.0.0.0:8000 (23493)
[2017-12-11 23:19:40 +1100] [23493] [INFO] Using worker: sync
[2017-12-11 23:19:40 +1100] [23496] [INFO] Booting worker with pid: 23496
$ curl http://localhost:8000/users
[{"username": "e60202a4", "id": 1}, {"username": "e780bdd4", "id": 2}, {"username": "cb29132d", "id": 3}, {"username": "4016c71b", "id": 4}, {"username": "e0d5deba", "id": 5}, {"username": "e835ae28", "id": 6}, {"username": "952ba94f", "id": 7}, {"username": "8b03499e", "id": 8}, {"username": "b72a0e55", "id": 9}, {"username": "ad782bb8", "id": 10}, {"username": "ec832c5f", "id": 11}, {"username": "f59f2dec", "id": 12}, {"username": "82d7149d", "id": 13}, {"username": "870f486d", "id": 14}, {"username": "6cdb6651", "id": 15}, {"username": "45a09079", "id": 16}, {"username": "612397f6", "id": 17}, {"username": "901c2ab6", "id": 18}, {"username": "59d86f87", "id": 19}, {"username": "1bbbae00", "id": 20}]
Тестируем API
Оценим производительность нашего API с помощью Taurus. По возможности необходимо развернуть Taurus на отдельной машине.
Устанавливаем Taurus в нашем виртуальном окружении:
$ pip install bzt
Теперь мы можем создать сценарий для нашего теста. Создаем файл bzt-config.yml следующего содержания (не забудьте указать верный IP адрес):
execution:
concurrency: 100
hold-for: 2m30s
ramp-up: 1m
scenario:
requests:
- url: http://ip-addr:8000/users/
method: GET
label: api
timeout: 3sЭтот тест будет симулировать веб трафик от 100 пользователей, с нарастанием их числа в течение минуты, и держать нагрузку 2 минуты 30 секунд.
Запустим API с одним воркером:
$ gunicorn --workers 1 app:api -b 0.0.0.0:8000Теперь мы можем запустить Taurus. При первом запуске он скачает нужные зависимости:
$ bzt bzt-config.yml -reportПосле установки зависимостей отобразится наша консоль с ходом исполнения теста:
Опцию -report мы используем для загрузки результатов в BlazeMeter и генерации веб-отчета.
Наше API отлично справляется со 100 пользователями. Мы достигли пропускной способности в ~1000 запросов/секунду, без ошибок и со средним временем ответом 0.1с.
Отлично, а что если пользователей будет 500? Изменим параметр concurrency на 500 в нашем файле bzt-config.yml и снова запустим Taurus.
Хм. Похоже наш одинокий воркер не справился с нагрузкой. 40% ошибок — это не дело.
Попробуем увеличить количество воркеров.
gunicorn --workers 20 app:api -b 0.0.0.0:8000Выглядит лучше. Ошибки еще есть, но пропускная способность увеличилась до ~1500 запросов/секунду, и среднее время отклика уменьшилось до ~270 мс. Такое API уже можно использовать.
Дальнейшая оптимизация производительности
Можно настроить PostgreSQL под железо с помощью PgTune.
На сегодня все. Спасибо, что читали!
Комментарии (12)

neopug
19.01.2018 19:30Подскажите, это перевод или авторская статья? Скриншоты и листинги уж больно смахивают на developers.redhat.com/blog/2017/12/29/create-scalable-rest-api-falcon-rhscl

artnest
22.01.2018 15:15В первом предложении данной статьи говорится о том, что это перевод статьи, ссылку на которую вы привели.
floyer
19.01.2018 21:56Пытался перейти на Falcon с Flask, но документация просто отвратительная, в следствии чего так и не смог разобраться в данном фреймворке.
pythonprogrammer
19.01.2018 22:10Один-единственный человек пилит — вряд ли там что-то дельное может быть…
ebt
20.01.2018 02:19Аргумент про 10x ускорение в сравнении с Flask совершенно нерелевантен. Этот слой никогда не бывает узким местом.
aavezel
фреймворк работающий через gunicorn в 2018? вы серьезно?
foxin
Поделитесь, пожалуйста, стабильными решениями.
floyer
а чем gunicorn не угодил? хорошее решение для многих ситуаций.
aavezel
хорошее. но синхронное. т. е. если в логике будет определенное количество подвисаний, то производительность будет проседать. те запросы которые не используют залокированное поведение будут висеть в ожидании. Конечно gunicorn кикнет воркер и запустит новый, но, не факт что этот новый воркер не залочится на следующим запросе.
запустить гринлеты или еще лучше обращение к базе через asyncio — проблемно, так как тот не опускает эвентлупы из себя. тем самым сведя работу с гринлетами к нулю.
vassabi
не подскажете, через что по-вашему должен работать фреймворк в 2018 году?
mozzzg
Что, собственно, не так? Довольно часто встречаю gunicorn в продакшене.