
В этой статье я расскажу, какие технологии мы стали использовать для сбора и агрегации данных в новом проекте.
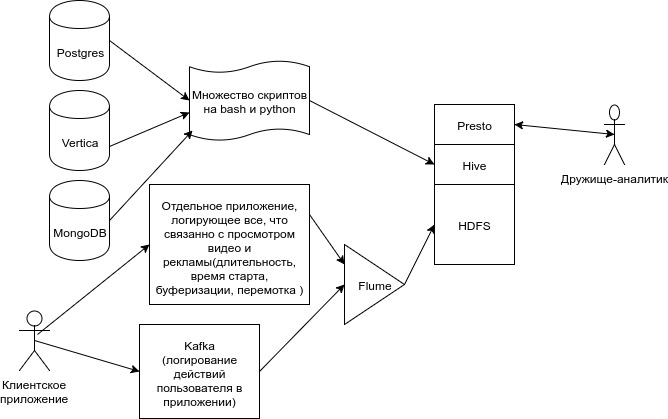
Так выглядела наша старая схема движения данных.
Множество данных от наших микросервисов, переливались скриптами в Hive.
Flume грузил клиентские данные из Kafka в ещё несколько таблиц, плюсом Flume грузил информацию о просмотрах из файловой системы одного из сервисов. Кроме этого были десятки скриптов в cron и oozie.
В какой-то момент мы поняли, что так жить нельзя. Такую систему загрузки данных практически невозможно тестировать. Каждая выгрузка сопровождается молитвами. Каждый новый тикет на доработку — тихим скрежетом сердца и зубов. Сделать так, чтобы система была полностью толерантна к падениям какого-либо её компонента стало очень сложно.
Подумав о том, каким мы хотим видеть новый ETL и примерив технологии и молитвы, мы получили следующую схему:

- Все данные поступают по http. От всех сервисов. Данные в json.
- Храним сырые(не обработанные) данные в kafka 5 дней. Кроме ETL, данные из kafka также используют и другие backend-сервисы.
- Вся логика обработки данных находится в одном месте. Для нас это стал java-код для фреймворка Apache Flink. Про этот чудо-фреймворк чуть позже.
- Для хранения промежуточных расчётов используем redis. У Flink есть своё state-хранилище, оно толератно к падениям и делает чекпоинты, но его проблема в том, что из него нельзя восстановиться при изменении кода.
- Складируем всё в Clickhouse. Подключаем внешними словарями все таблицы, данные из которых микросервисы не отправляют нам событиями по http.
Если про самописный http-сервис, складирующий данные в kafka, и про сам сервис kafka писать нет смысла, то вот про то, как мы используем Flink и ClickHouse, я хочу остановится подробнее.
Apache Flink
Apache Flink — это платформа обработки потоков с открытым исходным кодом для распределенных приложений с высокой степенью отказоустойчивости и толерантностью к падениям.
Когда данные для анализа нужны быстрее и необходима быстрая агрегация большого потока данных для оперативной реакции на определенные события — стандартный, батчевый подход к ETL уже не работает. Тут-то нам и поможет streaming-processing.
Прелесть такого подхода не только в быстроте доставки данных, но и в том что вся обработка находится в одном месте. Можно обвесить всё тестами, вместо набора скриптов и sql-запросов это становится похоже на проект который можно поддерживать.
package ivi.ru.groot;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
import org.apache.flink.util.Collector;
import org.json.JSONException;
import org.json.JSONObject;
import java.util.Properties;
public class Test {
public static void main(String[] args) throws Exception {
// Инициализация окружения flink-приложения
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Настройки для консюмера kafka
Properties kafkaProps = new Properties();
kafkaProps.setProperty("bootstrap.servers", "kafka.host.org.ru:9092");
kafkaProps.setProperty("zookeeper.connect", "zoo.host.org.ru:9092");
kafkaProps.setProperty("group.id", "group_id_for_reading");
FlinkKafkaConsumer010 eventsConsumer =
new FlinkKafkaConsumer010<>("topic_name",
new SimpleStringSchema(),
kafkaProps);
// Вот теперь у нас есть поток данных(DataStreamApi) над которым можно делать всё что угодно
DataStream<String> eventStreamString = env.addSource(eventsConsumer).name("Event Consumer");
// Для начала решим очень простую задачу. Отфильтруем те записи в которых есть слово Hello
eventStreamString = eventStreamString.filter(x -> x.contains("Hello"));
// А теперь оставим те которые можно преобразовать в json и прокинем далее в поток JSONObject
DataStream<JSONObject> jsonEventStream = eventStreamString.flatMap(new FlatMapFunction<String, JSONObject>() {
@Override
public void flatMap(String value, Collector<JSONObject> out) throws Exception {
try{
//прокидываем в поток записи которые можно преобразовать в json
out.collect(new JSONObject(value));
}
catch (JSONException e){}
}
});
// выведем в stout эти json-объекты.
jsonEventStream.print();
// Запустим наш граф
env.execute();
}
}
Про то как быстро создать maven-проект c зависимостями flink и небольшими примерами.
Вот здесь подробное описание DataStream API, с помощью которого можно производить практически любые преобразования с потоком данных.
Кластер flink можно запустить в yarn, mesos или при помощи отдельных(встроенных в пакет flink) task- и job-manager's.
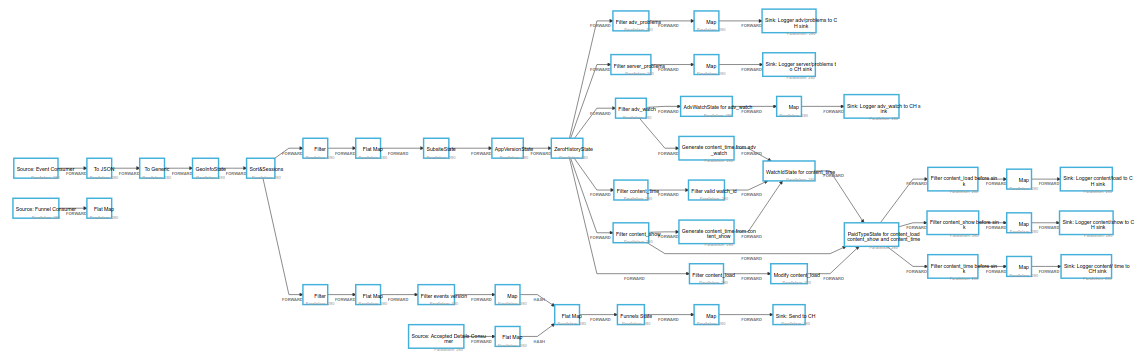
Кроме очевидной задачи складирования данных в нужном формате, мы с помощью Flink написали код, решающий следующие задачи:
- Генерация сессий для событий. Сессия становится единой для всех событий одного user_id. Вне зависимости, какой был источник сообщения.
- Проставляем гео-информацию для каждого события (город, область, страну, широту и долготу).
- Вычисляем “продуктовые воронки”. Наши аналитики описывают определенную последовательность событий. Мы ищем для пользователя внутри одной клиентской сессии эту последовательность и маркируем попавшие в воронку события.
- Комбинация данных из разных источников. Чтобы не делать лишние join’ы — можно заранее понять, что столбец из таблицы A может понадобиться в будущем в таблице B. Можно сделать это на этапе процессинга.
Для быстрой работы всей этой машинерии пришлось сделать пару нехитрых приёмов:
- Все данные партиционируем по user_id на этапе заливки в kafka.
- Используем redis как state-хранилище. Redis — это просто, надёжно и супер быстро, когда мы говорим про key-value хранилище.
- Избавиться от всех оконных функций. Нет всем задержкам!
ClickHouse
Clickhouse выглядел на момент проектирования просто идеальным вариантом для наших задач хранения и аналитических расчётов. Колоночное хранилище со сжатием (по структуре похожее на parquet), распределенная обработка запросов, шардирование, репликация, семплирование запросов, вложенные таблицы, внешние словари из mysql и любого ODBC подключения, дедупликация данных(хоть и отложенная) и многие другие плюшки…
Мы начали тестировать ClickHouse уже через неделю после релиза, и сказать, что всё сразу было радужно — это соврать.
Нет вменяемой схемы распределения прав доступа. Пользователи заводятся через xml файл. Нельзя настроить пользователю readOnly доступ на одну базу и полный доступ до другой базы. Либо полный, либо только чтение.
Нет нормального join. Если правая часть от join не помещается в память — извини. Нет оконных функций. Но мы решили это построив в Flink механизм “воронок”, который позволяет отслеживать последовательности событий и помечать их. Минус наших “воронок” в том, что мы не можем их смотреть задним числом до добавления аналитиком. Или нужно репроцессить данные.
Долгое время не было нормального ODBC-драйвера. Это огромный барьер для того, чтобы внедрять базу, ибо многие BI (Tableau в частности) имеют именно этот интерфейс. Сейчас с этим проблем нет.
Побывав на последней конференции по CH (12 декабря 2017 года), разработчики базы обнадежили меня. Большинство из тех проблем которые меня волнуют, должны быть решены в первом квартале 2018 года.
Многие ругают ClickHouse за синтаксис, но мне он нравится. Как выразился один мой многоуважаемый коллега, Clickhouse — это “база данных для программистов”. И в этом есть немного правды. Можно сильно упрощать запросы если использовать крутейший и уникальный функционал. Например, функции высшего порядка. Lambda-вычисления на массивах прямо в sql. Не чудо ли это??? Или то, что мне очень понравилось — комбинаторы агрегатных функций.
Данный функционал позволяет к функциям приставлять набор суффиксов (-if, -merge, -array), модифицируя работу этой функции. Крайне интересные наработки.
Наше решение на Clickhouse основывается на табличном движке ReplicatedReplacingMergeTree.
Схема распределения данных по кластеру выглядит примерно так:
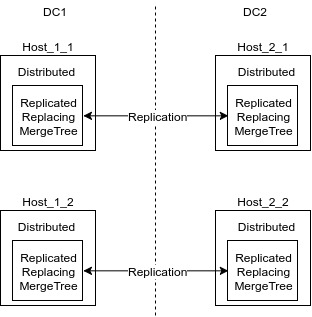
Distributed таблица — это обёртка над локальной таблицей (ReplicatedReplacingMergeTree), в которую идут все insert и select. Эти таблицы занимаются шардированием данных при вставке. Запросы к этим таблицам будут распределёнными. Данные, по возможности, распределённо обрабатываются на удалённых серверах.
ReplicatedReplacingMergeTree — это движок, который реплицирует данные и при этом, при каждом мёрже схлопывает дубликаты по определённым ключам. Ключи для дедупликации указываются при создании таблицы.
Резюме
Такая схема ETL, позволила нам иметь хранилище толерантное к дубликатам. При ошибке в коде мы всегда можем откатить consumer offset в kafka и обработать часть данных снова, не прилагая никаких особых усилий для движения данных.
Комментарии (12)

Closer
24.01.2018 12:21У Flink-а есть ряд проблем. Я не пользовался им кажется с версии 1.1 и возможно что-то уже изменилось, но тем не менее:
- Flink очень нестабильный. Например он может работать неделю обрабатывая тысячи сообщений в секунду, потом неожиданно повиснуть так что приходится перезапускать все ноды. Самое плохое что эта нестабильность только увеличивается при выходе новых минорных версий.
- Чуствителен к сетевым проблемам. Например если пропала связанность между нодами, то кластер может развалится и потом уже не собраться автоматически. Приходится лезь в логи, разбираться что сломалось, перезагружать ноды и flow.
- Очень прожорлив до CPU. Переписав flow на пару приложений на Java удалось снизить использование CPU процентов на 50 если не больше. Думаю эта особенность может стать bottleneck-ом при частых пиковых нагрузках, либо потребуется больше серверов.
- Flink не умеет динамически масштабироваться при изменений кластера. Например если одна нода упала, то он перезапускал flow на оставшихся (если мог конечно), а когда нода восстанавливалась, то она оставалась простаивать. Приходилось отслеживать это и вручную перезапускать flow.
- При запуске flow Flink не умеет подстраивать его под размер кластера (возможно сейчас уже может т.к. эта фича была в планах). Например если нужно запускать вычисление на всех 4-х нодах кластера, то в flow нужно явно указать это. Появляется/удаляется нода — нужно менять код во flow.
- Отвратительный API для деплоя flow. Если вы хотите задеплоить новую flow, то вам самим нужно сделать savepoint, самим сделать cancel flow (повезёт если он сработает), залить JAR c новым flow и надеятся что изменения которые в нем сделаны подхватстся из сделанного ранее savepoint-а. Мне пришлось написать ужасный скрипт для Gradle который всё это делал.
- Для сохранения checkpoint-ов и savepoint-ов (если вы подняли кластер Apache Flink) используется HDFS протокол. Заставить работать его требует титанических усилий т.к. части адаптеров (например S3) нет в Flink и он берёт их из инсталяции Hadoop которая должна быть где-то рядом и совместима с Flink. S3 адаптер который используется в этом Hadoop старый и содержит ошибки которые при возникновении выносят весь кластер Apache Flink. Настроить его тоже не просто. Ещё сложнее сделать это если вы живете не в AWS т.к. S3 интерфейс есть только у Riak CS или Minio (с которым адаптер из Hadoop не совместим из-за некоторых особенностей реализации Minio). Всё это выглядит как полный пиздец т.к. по факту вам всего лишь нужно положить файлик куда-то и скачать его. Я бы сделал это сам, но Flink не дает сделать это в обход HDFS.
- Очень похоже что есть мемори лики при сохранений checkpoint т.к. его размер стабильно рос и с нескольких сотен килобайт за пару недель он дорастал до сотен мегабайт. Мой flow был не очень большой и я излазил его вдоль и поперёк так что скорее всего ошибка где-то в Apache Flink.
Думаю этого достаточно, хотя это не все проблемы с которыми пришлось столкнуться при использовании Apache Flink.
В целом у меня сложилось следующее впечатление от Apache Flink: идея хорошая и правильная, но реализация — говно. Так же возникло ощущение что с каждым новым релизом ситуация ухудщается.

akonyaev Автор
24.01.2018 12:55Ну про checkpoint's я согласен. Мне этот механизм не очень нравится. И дело не в том, что он где-то течёт. Это всё недоказано, а может быть и пофикшено. Дело в том, что восстанавливаться из них сложно, когда меняешь граф.
Чуствителен к сетевым проблемам. Если у Вас распределённый движок для вычислений, происходит общение между нодами и тут бац, сети нет — ну я даже не знаю, что Вы ещё хотите? Все таймауты можно настраивать в akka.
Про то что неудобно деплоить. Тут я не соглашусь. Мы используем в качестве среды запуска YARN. Мы написали для Cloudera Manager своё расширение и следим за flink из него. Очень удобно. Залили новый JAR, новый конфиг, нажали restart в CM и поехали считать дальше с новым графом.
Сейчас мы используем версию 1.4.0, но и в начале когда был 1.1.4 было вполне стабильно.

rzykov
24.01.2018 18:17А сколько записей в день приходит?
akonyaev Автор
24.01.2018 21:56Около 1.5 миллиардов сообщений
rzykov
25.01.2018 15:01в день? так много?
akonyaev Автор
25.01.2018 22:19Да. Это около 1ТБ данных.
Мы собираем на новой платформе аналитики практически все возможные события.
Показы всех секций интерфейса, всех элементов, любые взаимодействия с клиентом, очень много событий от плеера, масса событий от бекенда.
С учётом того, что на новую платформу мы перевели только двух клиентов, данных будет ещё больше.
omgloki
24.01.2018 20:01Интересная статья, возникли несколько вопросов:
1) Почему воронки считаются не в CH, а на уровне Flink? Медленно?
(Кажется, что у аналитиков может возникнуть желание посмотреть разные воронки в разной ретроспективе.)
Смотрели ли / пробовали ли функции такого рода?
2) Какой тип persistence у redis? Скорости достаточно? Используете ли redis-cluster?akonyaev Автор
24.01.2018 22:141) Вполне резонный вопрос. sequenceMatch мы пробовали. Но нужно было чтобы от одного шага воронки, до другого было определённое колличество сообщений.
Я потом увидел доклад от Yandex (https://www.youtube.com/watch?v=YpurT78U2qA), где ребята решают это на основе массивов. В ближайшее время буду изучать этот вариант. Возможно, что надобность в предрасчитанных воронках отпадёт, если аналитикам понравится считать их прямо в базе.
2) Честно говоря, я не знаю как именно в redis у нас настроены снепшоты. Скорости вполне хватает. Мы используем redis-cluster, 4 шарда, каждый реплицированный.

ElMaxo
Разрешите два вопроса:
1. Используется ли Flink CEP в вашем проекте для определения паттернов в потоке событий?
2. Каким именно образом используется Redis в качестве хранилища стейтов в Flink? Дописывали поддержку в качестве state backend или через AsyncIO?
akonyaev Автор
1) Flink CEP — никогда не использовали. Посмотрел, и даже не знаю где у нас применить.
2) Мы не стали делать свою реализацию state backend, так как для этого нужно научить её всему API что есть в Flink (savepoint, checkpoint, восстановление из них и многое прочее). Мы просто во всех наших RichFlatMapFunction используем Cache на основе JedisCluster. Это позволяет избавится от ненужных keyBy перед flatMap и не парится о всех контрольных точках.
Если мы упали, то весь кеш гарантировано на месте.