 Я думаю многие задавались вопросом как отключить триггеры в zabbix на время прогнозируемой нагрузки, например на момент выполнения бэкапов. И я думаю многие легко решили этот вопрос, ну а те, кто ещё не придумал как это реализовать, добро пожаловать под кат!
Я думаю многие задавались вопросом как отключить триггеры в zabbix на время прогнозируемой нагрузки, например на момент выполнения бэкапов. И я думаю многие легко решили этот вопрос, ну а те, кто ещё не придумал как это реализовать, добро пожаловать под кат!Совсем недавно я познакомился с zabbix и спешу поделиться с сообществом своими наработками. Наработок пока две, эта и вторая про низкоуровневое обнаружение сервисов, таких как zabbix, mysql, postgress и вообще любых сервисов, там будет работа с API zabbix, скрипт на Python и немного Bash.
Я конечно и раньше с ним был знаком, но не так близко.
А теперь по делу:
Вся хитрость заключается в добавлении в выражении триггера дополнительного условия которое будет сверять время срабатывания триггера с временем заданным с бездействием триггера.
{выполнилось условие срабатывания триггера}
И
(
{текущее время} МЕНЬШЕ {начального времени отключения триггера}
ИЛИ
{текущее время} БОЛЬШЕ {конечного времени отключения триггера
)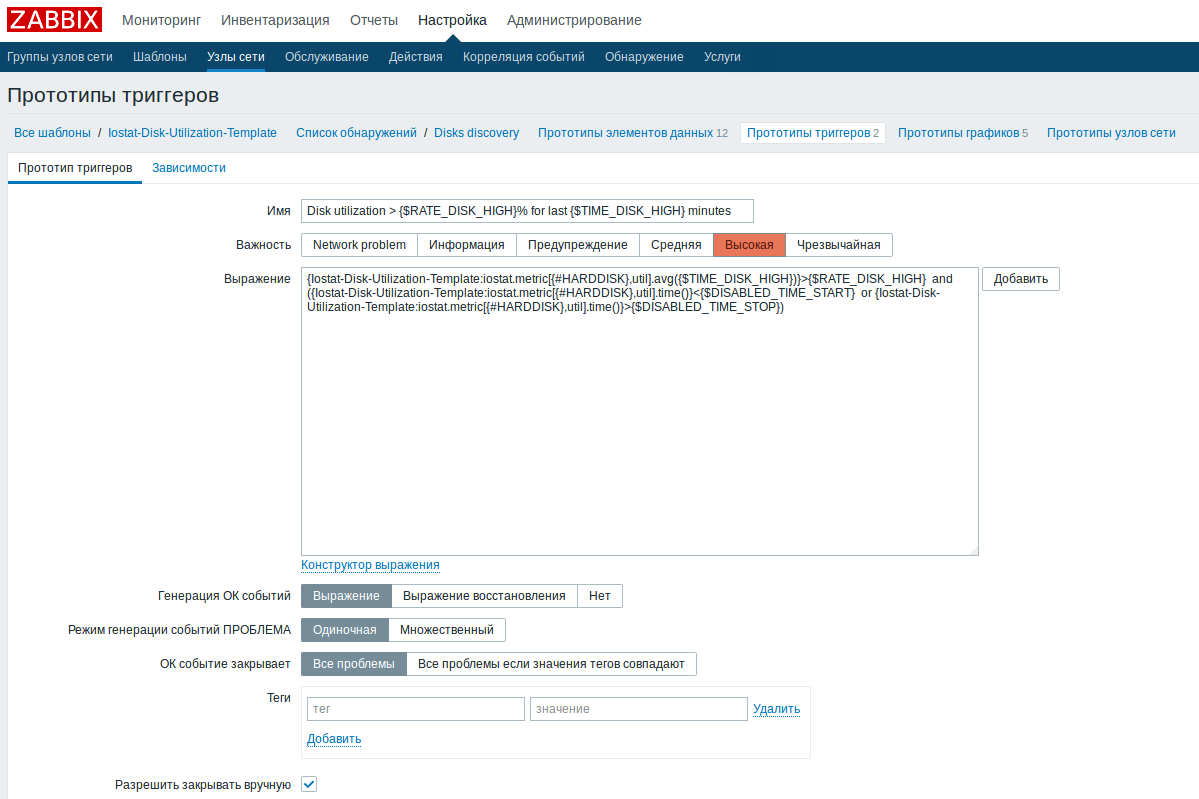
{Iostat-Disk-Utilization-Template:iostat.metric[{#HARDDISK},util].avg({$TIME_DISK_HIGH})}>{$RATE_DISK_HIGH} and ({Iostat-Disk-Utilization-Template:iostat.metric[{#HARDDISK},util].time()}<{$DISABLED_TIME_START} or {Iostat-Disk-Utilization-Template:iostat.metric[{#HARDDISK},util].time()}>{$DISABLED_TIME_STOP})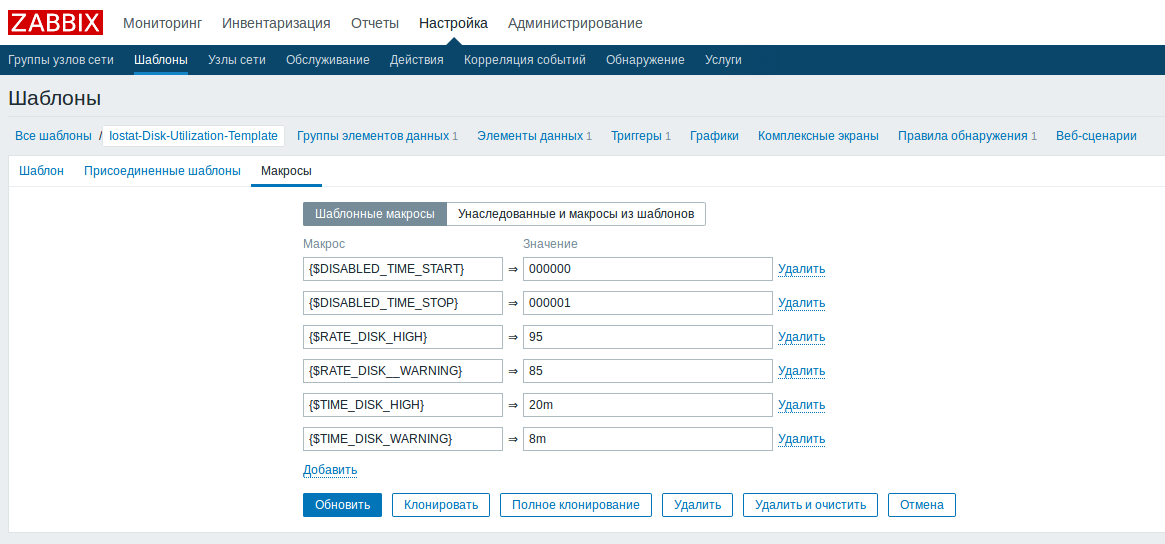
Для гибкой настройки параметров срабатывания триггеров утилизации дисков я добавил четыре макроса:
{$TIME_DISK_HIGH} - максимальная продолжительность нагрузки диска для алерта "Высокая нагрузка"
{$RATE_DISK_HIGH} - максимальный процент нагрузки диска для алерта "Высокая нагрузка"
{$RATE_DISK__WARNING} - максимальный процент нагрузки диска для алерта "Средняя нагрузка"
{$TIME_DISK_WARNING} - максимальная продолжительность нагрузки диска для алерта "Средняя нагрузка"И два макроса для отключения триггера:
{$DISABLED_TIME_START} - Начальное время бездействия триггера
{$DISABLED_TIME_STOP} - Конечное время бездействия триггераВ шаблоне, в макросах, необходимо задать параметры высокой и средней нагрузки на диски, а так-же начальное и конечное время бездействия триггера по умолчанию.
«Макросы узла сети и унаследованные» и напротив нужного макроса нажать кнопку изменить, после изменения макрос появится на вкладке «Макросы узла сети».

По умолчанию время начала бездействия триггера задано как 000000 и конечное время как 000001. То есть триггер будет бездействовать ровно одну секунду с 00 часов, 00 минут и 00 секунд до 00 часов, 00 минут и 01 секунд.
Оригинальный шаблон для переделок
И готовый шаблон
P.S.
В ходе экспериментов выяснилось, что если пытаться каким-то образом сократить время бездействия триггера, например в выражении триггера использовать <= и >= или указывать время равным началу и концу, то триггер либо не срабатывает вообще или не работает время отключения.
Комментарии (9)

MasMaX
26.01.2018 12:18Если мешают лишние уведомления, то лучше всё-таки выключать оповещения (Actions), а не триггеры. У меня так сделано. Менеджерам не приходят ночные уведомления, так как там постоянная нагрузка из-за расчетов, а мне как админу уведомления идут 24 часа в сутки. Если менеджер захочет ночью посмотреть нагрузку то он это делает через веб-интерфейс. А выключать триггеры я считаю немного опасно, можно пропустить реальную проблему.
Вот так это сделано у меня:


Archon
26.01.2018 16:59Это совершенно разные функции для совершенно разных целей. Отключение экшенов нужно для группировки по различным видам ответственности (неайтишный сотрудник, дежурный сисадмин, программист, дневной сисадмин, и т.п.), на каждом из которых нужны различные группы оповещений в различные интервалы времени. Т.е. мы задаём что-то типа: «то, что между сервером А и Б в 2 часа ночи попёрло 600 мегабит трафика — это не нормально и возможно сигнализирует об аварии, но дневному менеджеру от этого можно и не просыпаться, пусть спит дальше».
А автор рассказывает именно о настройке, задающей «то, что между сервером А и Б в 2 часа ночи каждую среду прёт 600 мегабит трафика — это совершенно нормально, прогнозируемо, и никакой аварии в этом заключаться не может, потому что это льются бекапы». Такое можно реализовать либо мейнтенансом (если все пошатывания более-менее сгруппированы по времени), либо задачей дополнительных условий в самих триггерах.

Gyzes
26.01.2018 13:06Настраивал так еще давно и при такой же настройке возникла проблема, когда выражение тригера переходит в состояние «ОК» из-за того, что не выполняется условие по времени. Хотя проблема остается. Решается изменением выражения восстановления, где нужно просто убрать привязку ко времени.
throttle
26.01.2018 20:33Меня, честно говоря, удивляет способность людей написать статью на ровном месте.
Ни в коем случае не в укор автору, скорее укор себе. Я бы эту статью уложил в фразу «В Zabbix есть „Периоды обслуживания.“ :)
Я прочел, что не про maintenance, но тем не менее.
Я еще отлично помню статью про то, что в OpenVPN есть опция multihome.

AlexGluck
27.01.2018 00:26Есть дефолтные шаблоны, в которых действительно удобно вставлять макросами какие то не уникальные для хоста данные, но вот время бекапов таким же способом делать увы не получается. Слишком много работы по настройке получается.
Если у нас собственный бекап сервер, то у него есть определённое количество ресурсов и запускать бекапы одновременно всего вы физически не сможете так как исчерпаете их(скорость сети и дисков). Поэтому для триггеров на статусы слейвов при бекапе в одно время на одном сервере, в другое на другом и вы никак это не автоматизируете без кода который по апи из бекап сервиса забирает данные и помещает их по апи в заббикс. А такой код будет жёстко завязан на конкретные продукты и расширить его или опубликовать будет не целесообразно.
У нас старт бекапов бд делаются не в конкретное время, а в некотором диапазоне когда освободятся ресурсы и длительность их зависит от типа бекапа, инкремент или полный. Соответственно макросы должны меняться динамически и для каждого триггера должны быть уникальны, что без автоматизации напрочь убивает все инсинуации аналогичные вашим. И это верно не только для текущей компании в которой я работаю.
Fess
Есть штатный механизм отключения оповещения: Maintenance
С его помощью не получится отключить конкретный триггер, но это, за частую, и не нужно.
scarab
Мне кажется, автор некорректно сформулировал название заголовка и тем самым породил неверное восприятие.
Maintenance нужен для полного отключения триггеров, но не на период бэкапа или иных штатных действий, а на период отключения сервисов, т.е. нештатных (хотя и запланированных) работ.
Для бэкапов же правильнее было бы сделать отдельные триггеры (или задавать значения через макросы), которые будут работать только во время бэкапа.
MagicEx
Maintenance позволяет оставить триггеры и сбор данных, но убрать ненужные оповещения в действиях. У нас например в период обновлений вин серверов триггеры работают только в Jabber. SMS и Телеграм отключаются установкой галки «Приостановить операции в режиме обслуживания»
Froggy_0
Только им и пользуюсь. Проще в настройке.