Код на Си, занимающий 156 байт
int main(void) {
int testArray[5U] = {-1,20,-3,0,4};
int lowest = INT_MAX;
for (int i = 0; i < 5; i++) {
lowest = ((lowest < testArray[i]) ? lowest : testArray[i]);
};
return 0;И его ассемблерное представление
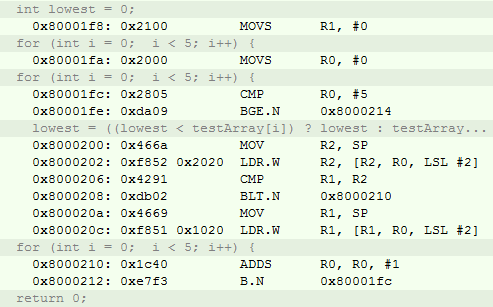
И код на С++, занимающий 152 байт
int main() {
int testArray[5U] = {-1, 20, -3, 0, 4};
int lowest = INT_MAX;
for (auto it: testArray) {
lowest = ((lowest < it) ? lowest : it);
};
return 0;И его ассемблерное представление
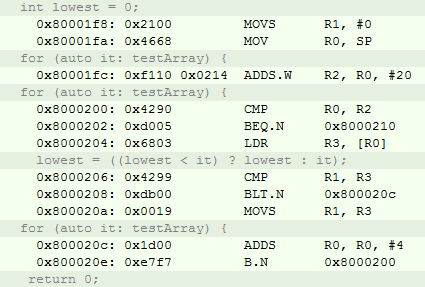
Как можно увидеть сгенерированный компилятором код на С++ на 4 байт меньше, а скорость работы на 12 тактов быстрее. Все это достигается за счет новых возможностей С++14. Конечно, можно заметить, что для обоих компиляторов была отключена оптимизация, что это очень синтетический тест который не имеет ничего общего с реальной реализацией, но все же можно сказать, что не все так однозначно.
Нужно учитывать особенности программирования для микроконтроллеров, ведь требования к небольшому объему памяти программ 32,64..512 кБ, еще меньшему объему ОЗУ и низкой частоты микропроцессоров (особенно при использовании для низкопотребляющих датчиков), накладывают свои ограничения. И с уверенностью можно сказать, что не все фишки С++ полезны. Например, использование стандартной библиотки шаблонов может отнять значительное количество ресурсов, а такие важные в большом мире С++ вещи как исключениия можно с уверенностью выкинуть из проектов для небольших микроконтроллеров, поскольку они требуют значительного увеличения размера стека и кода для хранения информации об обработчике исключения и дальнейшем его поиске. Поэтому я попытаюсь рассказать как можно использовать С++ и его новые особенности для небольших проектов и постараюсь показать, что без зазрения совести С++ можно использовать вместо Си.
Первым делом надо определиться с задачей. Она должна быть достаточно простой, но и достаточно показательной, чтобы увидеть как можно, например, полностью отказаться от макросов, по-возможности уйти от указателей, уменьшить риски глупых ошибок и так далее…
Выбор, как обычно пал на светодиды.
Для того, чтобы читатель понимал что мы хотим сделать, я приведу конечный вариант задачи, которую необходимо реализовать на микроконтроллере:
- Используемая плата XNUCLEO-F411RE
- ПО должно работать на микропроцессоре STMF411R, работающего от внешней частоты 16 Мгц.
- ПО должно поддерживать управление 4 светодиодами на плате, подключенных к портам (Светодиод 1 – GPIOA.5, Светодиод 2 – GPIOC.9, Светодиод 3 – GPIOC.8, Светодиод 4 – GPIOC.5).
- ПО должно поддерживать 3 режима управления светодиодами (Елочка – все светодиоды загораются поочерёдно, потом в таком же порядке поочередно потухают. Шахматы – вначале загораются четные светодиоды и гаснут нечетные, затем наоборот. Режим Все – все светодиоды загораются и затем гаснут ). Время смены состояния светодиодов – 1 секунда.
- ПО должно поддерживать смену режима управления светодиодами с помощью кнопки, подключенной к порту GPIOC.13 в кольцевом порядке в последовательности Елочка-Шахматы-Все.
Так выглядит конечное требование от заказчика. Но как это обычно бывает на практике, сначала заказчик пришел с идеей попроще, он решил, что для полного счастья ему не хватает яркой индикации, а именно моргания зеленым светодиодом раз в 1 секунду. Эту задачу и бросился реализовать программист с именем Снежинка.

Итак, на нашей плате есть 4 светодиода: LED1, LED2, LED3 и LED4. Они подключены к портам GPIOA.5, GPIOC.5, GPIOC.8, GPIOC.9 соответственно. Пока давайте будем работать с LED1, который находится на GPIOA.5.
Для начала программист Снежинка написал вот такой вот простой код на Си, который будет переключать светодиод. Выглядит это так:
int main() {
GPIOC->ODR ^= GPIO_ODR_OD5; //переключаем состояние светодиода LED1 на противоположное
Delay(1000U);
GPIOC->ODR ^= GPIO_ODR_OD5; //еще раз, чтобы моргнуть светодиодом
return 0;
}
Код работает хорошо и правильно, Снежинка остался доволен своей работой и пошел отдыхать. Но для непосвящённого в тонкости разводки платы и булевые операции пользователя, этот код не совсем понятен, поэтому Снежинке пришлось дописывать комментарии, которые поясняют, что на порте GPIOA.5 находится светодиод и собственно мы хотим его переключить.
Давай подумаем, как должен выглядеть такой код на человеческом языке. Может быть так:
Toggle Led1 then
Delay 1000ms then
Toggle Led1
Как мы можем увидеть, здесь уже не нужны комментарии и назначение такого кода интуитивно понятно. Самое замечательно то, что этот псевдокод практически полностью соответствует коду на С++. Посмотрите, единственное отличие — мы должны вначале создать светодиод, указав на каком порту он находится.
int main() {
Led Led1(*GPIOA, 5U);
Led1.Toggle();
Delay(1000U);
Led1.Toggle();
return 0;
}
#pragma language = extended
#pragma segment = "CSTACK"
extern "C" void __iar_program_start( void );
class DummyModule {
public:
static void handler();
};
typedef void( *intfunc )( void );
//cstat !MISRAC++2008-9-5-1
typedef union { intfunc __fun; void * __ptr; } intvec_elem;
#pragma location = ".intvec"
//cstat !MISRAC++2008-0-1-4_b !MISRAC++2008-9-5-1
extern "C" const intvec_elem __vector_table[] =
{
{ .__ptr = __sfe( "CSTACK" ) },
__iar_program_start,
DummyModule::handler,
DummyModule::handler,
DummyModule::handler,
DummyModule::handler,
DummyModule::handler,
0,
0,
0,
0,
DummyModule::handler,
DummyModule::handler,
0,
DummyModule::handler,
DummyModule::handler,
//External Interrupts
DummyModule::handler, //Window Watchdog
DummyModule::handler, //PVD through EXTI Line detect/EXTI16
DummyModule::handler, //Tamper and Time Stamp/EXTI21
DummyModule::handler, //RTC Wakeup/EXTI22
DummyModule::handler, //FLASH
DummyModule::handler, //RCC
DummyModule::handler, //EXTI Line 0
DummyModule::handler, //EXTI Line 1
DummyModule::handler, //EXTI Line 2
DummyModule::handler, //EXTI Line 3
DummyModule::handler, //EXTI Line 4
DummyModule::handler, //DMA1 Stream 0
DummyModule::handler, //DMA1 Stream 1
DummyModule::handler, //DMA1 Stream 2
DummyModule::handler, //DMA1 Stream 3
DummyModule::handler, //DMA1 Stream 4
DummyModule::handler, //DMA1 Stream 5
DummyModule::handler, //DMA1 Stream 6
DummyModule::handler, //ADC1
0, //USB High Priority
0, //USB Low Priority
0, //DAC
0, //COMP through EXTI Line
DummyModule::handler, //EXTI Line 9..5
DummyModule::handler, //TIM9/TIM1 Break interrupt
DummyModule::handler, //TIM10/TIM1 Update interrupt
DummyModule::handler, //TIM11/TIM1 Trigger/Commutation interrupts
DummyModule::handler, //TIM1 Capture Compare interrupt
DummyModule::handler, //TIM2
DummyModule::handler, //TIM3
DummyModule::handler, //TIM4
DummyModule::handler, //I2C1 Event
DummyModule::handler, //I2C1 Error
DummyModule::handler, //I2C2 Event
DummyModule::handler, //I2C2 Error
DummyModule::handler, //SPI1
DummyModule::handler, //SPI2
DummyModule::handler, //USART1
DummyModule::handler, //USART2
0,
DummyModule::handler, //EXTI Line 15..10
DummyModule::handler, //EXTI Line 17 interrupt / RTC Alarms (A and B) through EXTI line interrupt
DummyModule::handler, //EXTI Line 18 interrupt / USB On-The-Go FS Wakeup through EXTI line interrupt
0, //TIM6
0, //TIM7 f0
0,
0,
DummyModule::handler, //DMA1 Stream 7 global interrupt fc
0,
DummyModule::handler, //SDIO global interrupt
DummyModule::handler, //TIM5 global interrupt
DummyModule::handler, //SPI3 global interrupt
0, // 110
0,
0,
0,
DummyModule::handler, //DMA2 Stream0 global interrupt 120
DummyModule::handler, //DMA2 Stream1 global interrupt
DummyModule::handler, //DMA2 Stream2 global interrupt
DummyModule::handler, //DMA2 Stream3 global interrupt
DummyModule::handler, //DMA2 Stream4 global interrupt 130
0,
0,
0,
0,
0,
0,
DummyModule::handler, //USB On The Go FS global interrupt, 14C
DummyModule::handler, //DMA2 Stream5 global interrupt
DummyModule::handler, //DMA2 Stream6 global interrupt
DummyModule::handler, //DMA2 Stream7 global interrupt
DummyModule::handler, //USART6 15C
DummyModule::handler, //I2C3 Event
DummyModule::handler, //I2C3 Error 164
0,
0,
0,
0,
0,
0,
0,
DummyModule::handler, //FPU 184
0,
0,
DummyModule::handler, //SPI 4 global interrupt
DummyModule::handler //SPI 5 global interrupt
};
__weak void DummyModule::handler() { for(;;) {} };
extern "C" void __cmain( void );
extern "C" __weak void __iar_init_core( void );
extern "C" __weak void __iar_init_vfp( void );
#pragma required=__vector_table
void __iar_program_start( void )
{
__iar_init_core();
__iar_init_vfp();
__cmain();
}
#ifndef UTILS_H
#define UTILS_H
#include <cassert>
namespace utils {
template<typename T, typename T1>
inline void setBit(T &value, T1 bit) {
assert((sizeof(T) * 8U) > bit);
value |= static_cast<T>(static_cast<T>(1) << static_cast<T>(bit));
};
template<typename T, typename T1>
inline void clearBit(T &value, T1 bit) {
assert((sizeof(T) * 8U) > bit);
value &= ~static_cast<T>(static_cast<T>(1) << static_cast<T>(bit));
};
template<typename T, typename T1>
inline void toggleBit(T &value, T1 bit) {
assert((sizeof(T) * 8U) > bit);
value ^= static_cast<T>(static_cast<T>(1) << static_cast<T>(bit));
};
template<typename T, typename T1>
inline bool checkBit(const T &value, T1 bit) {
assert((sizeof(T) * 8U) > bit);
return !((value & (static_cast<T>(1) << static_cast<T>(bit))) == static_cast<T>(0U));
};
};
#endif
#ifndef LED_H
#define LED_H
#include "utils.hpp"
class Led
{
public:
Led(GPIO_TypeDef &portName, unsigned int pinNum) : port(portName),
pin(pinNum) {};
inline void Toggle() const { utils::toggleBit(port.ODR, pin); }
inline void SwitchOn() const { utils::setBit(port.ODR, pin); }
inline void SwitchOff() const { utils::clearBit(port.ODR, pin); }
private:
GPIO_TypeDef &port;
unsigned int pin;
};
#endif
#include <stm32f411xe.h>
#include "led.hpp"
extern "C" {
int __low_level_init(void) {
//Включение внешнего генератора на 16 МГц
RCC->CR |= RCC_CR_HSION;
while ((RCC->CR & RCC_CR_HSIRDY) != RCC_CR_HSIRDY) {
}
//Переключаем системную частоту на внешний генератор
RCC->CFGR |= RCC_CFGR_SW_HSI;
while ((RCC->CFGR & RCC_CFGR_SWS) != RCC_CFGR_SWS_HSI) {
}
//Подаем тактирование на порты С и А
RCC->AHB1ENR |= (RCC_AHB1ENR_GPIOAEN);
//LED1 на PortA.5, устанавливаем PortA.5 как выход
GPIOA->MODER |= GPIO_MODER_MODE5_0;
return 1;
}
//Задержка, для простоты реализована в виде цикла
inline void Delay(unsigned int mSec) {
for (unsigned int i = 0U; i < mSec * 3000U; i++) {
__NOP();
};
}
}
int main() {
Led Led1(*GPIOA, 5U);
Led1.Toggle();
Delay(1000U);
Led1.Toggle();
return 0;
}
Программисты минималисты могут сказать, что да код понятнее, но ведь он избыточен, создается объект, идет вызов конструктора, методов, сколько же ОЗУ и дополнительного кода генерируется. Но если вы взглянете листинг на ассемблере, то приятно удивитесь, размер кода на С++ при включенной опции inline functions для обоих компиляторов, будет такой же как и для Си программы, а из-за особенностей вызова функции main, общий код на С++ даже на одну инструкцию меньше.
Ассемблерный код из Си исходников

Ассемблерный код из С++ исходников

Это еще раз подтверждает тот факт, что современные компиляторы делают свою работу по превращению вашего замечательного и понятного кода на языке С++ в оптимальный ассемблерный код. И совсем не каждый программист на ассемблере может достичь такого уровня оптимизации.
Конечно, при отключенной оптимизации код на С++ не будет таким компактным по размеру стека и быстродействию. Для сравнения приведу неоптимизированный вариант с вызовом конструктора и методов.

Для меня нет дилеммы между держанием в голове множество ненужных деталей чтобы написать микропрограмму датчика (какие элементы на какие порты подключены, в каком текущем состоянии находится сейчас порт или тот или иной модуль и так далее) и простотой и понятностью кода. Ведь в конце концов, нам нужно описать логику работы устройства, интерфейс взаимодействия с пользователем, реализовать расчеты, а не запомнить, что для того чтобы считать данные с АЦП, нужно вначале его выбрать с помощью сигнала CS, находящегося на порту GPIOA.3 и установить его в единицу. Пусть этим занимается разработчик модуля АЦП.
Первоначально может показаться, что необходимо писать много дополнительного кода, но уверяю вас, это с лихвой окупится, когда приложение станет немного сложнее, чем просто моргнуть светодиодом.
Вернемся к нашему заданию. Не успел Снежинка показать результат своей работы заказчику, как заказчик, ощутив прелесть моргания светодиода в ночи, решил, что хорошо бы иметь моргающие в режиме “Елочка” четыре светодиода, тем более что на носу Китайский Новый год и будет много потенциальных покупателей.
Наш программист Снежинка, одновременно выполняющий несколько проектов, решил сэкономить время и сделать все в лоб самым, как он считает надежным и понятным способом:
#define TOGGLE_BIT(A,B) ((A) ^= (1U << ((B) & 31UL)))
#define SET_BIT(A,B) ((A) |= (1U << ((B) & 31UL)))
int main(void) {
//Зажигаем все светодиоды
SET_BIT(GPIOC->ODR, 5U);
SET_BIT(GPIOC->ODR, 8U);
SET_BIT(GPIOC->ODR, 9U);
SET_BIT(GPIOA->ODR, 5U);
//Переключаем по очереди все светодиоды
for (;;) {
Delay(1000U);
TOGGLE_BIT(GPIOC->ODR, 5U);
Delay(1000U);
TOGGLE_BIT(GPIOC->ODR, 8U);
Delay(1000U);
TOGGLE_BIT(GPIOC->ODR, 9U);
Delay(1000U);
TOGGLE_BIT(GPIOС->ODR, 5U); //ошибка: должно быть TOGGLE_BIT(GPIOA->ODR, 5U
}
return 0;
}
Код работает, но обратите внимание, на последнюю запись TOGGLE_BIT(GPIOС->ODR, 5U). Светодиоды 1 и 4 находятся на ножке номер 5, но на разных портах. Используя Ctrl С-Ctrl V, Снежинка скопировал первую запись, и забыл поменять порт. Это типичная ошибка, которую допускают программисты, работающие под давлением менеджмента, устанавливающих срок “вчера”. Проблема заключается в том, что для поставленной задачи надо было быстро написать код, и у Снежинки не было времени подумать над дизайном ПО, он просто сел и написал то что надо было, при этом допустив небольшую помарку, которую он конечно же найдет при первой же прошивке в устройство. Однако, нужно понимать, что на это он потратит какое-то время. Кроме того, Снежинка добавил два ужасных макроса, которые по его мнению облегчают ему работу. В предыдущем примере на С++ мы добавили довольно много кода, в том числе для того, чтобы заменить эти макросы на замечательные встроенные функции. Зачем?
Давайте рассмотрим очень популярный макрос установки бита. С помощью него можно устанавливать бит в любом целочисленном типе.
#define SET_BIT(A,B) (A |= (1 << B))
int main() {
unsigned char value = 0U;
SET_BIT(value, 10);
return 0;
}
Все выглядит очень красиво, за исключением одного – в данном коде ошибка и нужный бит не установится. С помощью макроса SET_BIT устанавливается 10 бит в переменной value, которая имеет размер 8 бит. Интересно сколько программист будет искать такую ошибку, если объявление переменной будет не так близко к вызову макроса? Единственное преимущество данного подхода – это несомненный факт того, что код будет занимать наименьший размер.
Чтобы избежать потенциальной ошибки, давайте заменим этот макрос на шаблонную функцию
template<typename T, typename T1>
inline void setBit(T &value, T1 bit) {
assert((sizeof(T) * 8U) > bit);
value |= static_cast<T>(static_cast<T>(1) << static_cast<T>(bit));
};
Здесь встроенная функция setBit принимает ссылку на параметр, в котором нужно установить бит и номер бита. Функция может принимать произвольный тип параметра и номера бита. В данном случае для того, чтобы убедиться, что номер бита не превышает размер типа параметра, другими словами, что бит точно можно установить в параметре такого типа, мы делаем проверку с помощью функции assert. Функция assert проверяет условие во время исполнения и если условие соблюдено, то код продолжает исполняться дальше, а вот если условия не соблюдено, то программа завершится с ошибкой. Описание прототипа функции assert лежит в файле cassert, его и нужно подключить. Такая проверка будет полезна во время разработки, если вдруг кто-то решит передать неверный входной параметр, вы заметите это во время работы, когда он сработает. Понятно, что в продуктовом коде нет смысла использовать проверку входных параметров, так как это занимает место, замедляет работу, да к тому же во время разработки вы уже отлавили все потенциальные возможности передачи неверных параметров, поэтому assert можно отключить, определив NDEBUG символ в исходном файле или определив его для всего проекта.
Обратите внимание на ключевое слово inline. Это ключевое слово указывает компилятору, что хотелось бы, чтобы данная функция рассматривалась как встраиваемая. Т.е. мы предполагаем, что компилятор просто заменит вызов функции на её код, однако на практике такого можно добиться только с установками оптимизации у компилятора. В IAR Workbench это установка флажка напротив опции “Function Inlining” в закладке С/С++ Compiler->Optimization. В таком случае наша функция также быстра и занимает столько же места как и макрос.
Вернемся снова к коду Снежинки, как же тут обстоят дела с расширяемостью?
#define TOGGLE_BIT(A,B) ((A) ^= (1U << ((B) & 31UL)))
#define SET_BIT(A,B) ((A) |= (1U << ((B) & 31UL)))
int main(void) {
//Зажигаем все светодиоды
SET_BIT(GPIOC->ODR, 5U);
SET_BIT(GPIOC->ODR, 8U);
SET_BIT(GPIOC->ODR, 9U);
SET_BIT(GPIOA->ODR, 5U);
//Переключаем по очереди все светодиоды
for (;;) {
Delay(1000U);
TOGGLE_BIT(GPIOC->ODR, 5U);
Delay(1000U);
TOGGLE_BIT(GPIOC->ODR, 8U);
Delay(1000U);
TOGGLE_BIT(GPIOC->ODR, 9U);
Delay(1000U);
TOGGLE_BIT(GPIOС->ODR, 5U); //ошибка: должно быть TOGGLE_BIT(GPIOA->ODR, 5U
}
return 0;
}Ведь судя по всему заказчик не остановится на этом и что произойдет, если светодиодов будет не 4, а 40? Размер кода увеличится линейно в 10 раз. Вероятность ошибки возрастет во столько же раз, а поддержка кода в дальнейшем превратится в рутину.
Более мудрый программист на С мог бы написать код так:
int main(void) {
tLed pLeds[] = {{ GPIOC, 5U },{ GPIOC, 8U },{ GPIOC, 9U },{ GPIOA, 5U }};
SwitchOnAllLed(pLeds, LEDS_COUNT);
for (;;) {
for (int i = 0; i < LEDS_COUNT; i++) {
Delay(1000U);
ToggleLed(&pLeds[i]);
}
}
return 0;
}
Функция main теперь содержит меньше кода и самое главное стала легко расширяемая. При увеличении количества светодиодов, теперь достаточно просто добавить порт к которому подключен светодиод в массив светодиодов pLeds и макрос LEDS_COUNT поменять на количество светодиодов. При этом размер кода вообще не увеличится. Конечно глубина стека при этом вырастет значительно, так как массив светодиодов создается на стеке, а он уже равен 56 байтам.
Между первым решением и вторым всегда есть выбор, что важнее для конкретной вашей реализации: Меньший размер кода, расширяемость, удобочитаемость и лаконичность или меньший размер ОЗУ и скорость. По моему опыту в 90% случаев можно выбрать первое.
Но давайте рассмотрим этот код повнимательнее. Это типичный код на Си с использованием указателей и макросов типа SET_BIT() и TOGGLE_BIT(). И в связи с этим, здесь существуют риски потенциальных проблем, например, функция SwitchOnAllLed(tLed *pLed, int size) принимает указатель и размер массива. Во-первых, нужно понимать, что ничего не запрещает передать в эту функцию нулевой указатель, поэтому нужна проверка, что указатель не равен NULL, а ведь случайно можно вообще передать указатель на другой объект. Во-вторых, в случае, если вдруг программист передаст размер больше чем объявленный размер массива, поведение такой функции будет совершенно непредвиденным. Поэтому конечно, лучше в этой функции проверять размер. Добавление таких проверок приведет к увеличению кода, проверки можно сделать и с использовнием assert, но лучше попробовать написать тоже самое на С++
int main() {
LedsController LedsContr;
LedsContr.SwitchOnAll();
for (;;) {
for (auto &led : LedsContr.Leds) {
Delay(1000U);
led.Toggle();
}
}
return 0;
}
Да этот код занимает уже значительно больше места. Но мы увидим в дальнейшем, как такой дизайн поможет нам сэкономить время, а размер кода будет практически таким же как и на Си, при усложнении программы.
Здесь используется класс LedsController, приведу его код:
#ifndef LEDSCONTROLLER_H
#define LEDSCONTROLLER_H
#include "led.hpp"
#include <array>
constexpr unsigned int LedsCount = 4U;
class LedsController {
public:
LedsController() {};
inline void SwitchOnAll() {
for (auto &led : Leds) {
led.SwitchOn();
}
};
std::array<Led, LedsCount> leds{Led{*GPIOC, 5U},Led{*GPIOC, 8U},Led{*GPIOC, 9U},Led{*GPIOA, 5U}};
};
#endif
Методу SwitchOnAll() теперь не надо передавать указатель на массив, он использует уже существующий массив, сохраненный внутри объекта класса.
Почему же этот код считается надежнее? Во-первых, мы нигде не используем указатели, мы храним массив объектов на все существующие светодиоды в нашем классе и обращаемся непосредственно к объекту, а не к указателю. Во-вторых, мы используем специальный синтаксис для цикла for, который обходит наш массив без необходимости указывания его размера, за нас это делает компилятор. Этот цикл работает с любыми объектами являющиеся итераторами. Массив в С++ по умолчанию является таким объектом.
Единственное место, где можно ошибиться, это задание размера массива с помощью константы LedsCount. Однако, даже из этого небольшого примера, можно увидеть, что С++ предоставляет намного больше средств для написания надежного кода.
Еще один момент, требующий внимания – это то, что мы можем по ошибке создать несколько объектов класса LedsController, что приведет к увеличению размера используемого ОЗУ (стека) и к интересному поведению программы. Защититься от этого может помочь шаблон Одиночка, но делать это стоит только тогда, когда у вас довольно крупный проект, большая команда разработчиков и существует риск, что кто-то забудет о том, что объект вашего контроллера уже создан и нечаянно создаст еще один такой же. В нашем же случае, это явный переизбыток, функция небольшая, и мы четко помним, что объект класса LedsController у нас один.
Но вернемся к разработке, как обычно бывает, в тот момент, когда программист реализовал задачу (елочку в нашем случае), заказчик тут же просит реализовать еще два режима: моргание в шахматном порядке и моргание всеми светодиодами, а режимы должны меняться по нажатию кнопки. В случае со Снежинкой произойдет практически полный провал и если привести код программы в стиле Снежинка, то он будет настолько громоздким, что не влезет на страницу данной статьи, поэтому приводить здесь я его не буду.
Лучше посмотрим что сможет сделать программист на С. Понимая, что от заказчика могут поступить еще новые предложения, он скорее всего сделает нечто вроде этого:
int main(void) {
tPort Leds[] = { { GPIOC, 5U },{ GPIOC, 8U },{ GPIOC, 9U },{ GPIOA, 5U } };
tPort Button = { GPIOC, BUTTON_PIN }; //Кнопка на порте GPIOC.13
tLedMode Mode = LM_Tree;
int currentLed = 0;
SwitchOnAllLed(Leds, LEDS_COUNT);
for (;;) {
//Проверяем нажата ли кнопка. Она подтянута к 1, поэтому проверка на 0
if (!CHECK_BIT(Button.pPort->IDR, BUTTON_PIN)) {
//Устанавливаем следующий режим
Mode = (Mode < LM_End) ? (tLedMode)(Mode + 1U) : LM_Tree;
//Устанавливаем начальное состояние для нового режима
currentLed = 0;
switch (Mode) {
case LM_Tree:
case LM_All:
SwitchOnAllLed(Leds, LEDS_COUNT);
break;
case LM_Chess:
SwitchChessLed(Leds, LEDS_COUNT);
break;
default:
break;
}
}
//Переключаем светодиоды в зависимости от режима
switch (Mode) {
case LM_Tree:
ToggleLed(&Leds[currentLed]);
break;
case LM_All:
case LM_Chess:
ToggleAll(Leds, LEDS_COUNT);
break;
default:
break;
}
currentLed = (currentLed < (LEDS_COUNT – 1)) ? (currentLed + 1) : 0;
Delay(300U);
}
return 0;
}
И хотя, чтобы добавить новый режим, нужно всего лишь добавить новый перечеслитель, добавить установку начального значения для этого режима и обработку работы светодиодов для этого режима, программа все еще требует основательного пояснения и комментариев и уже смотрится громоздкой. Поэтому принимается решение убрать обработку режимов в отдельные методы:
inline void SetLedsBeginState(tLedMode mode, tPort *leds) {
switch (mode) {
case LM_Tree:
case LM_All:
SwitchOnAllLed(leds, LEDS_COUNT);
break;
case LM_Chess:
SwitchChessLed(leds, LEDS_COUNT);
break;
default:
break;
}
}
inline void UpdateLeds(tLedMode mode, tPort *leds, int curLed) {
switch (mode) {
case LM_Tree:
ToggleLed(&leds[curLed]);
break;
case LM_All:
case LM_Chess:
ToggleAll(leds, LEDS_COUNT);
break;
default:
break;
}
}
В таком случае основная программ выглядит намного лучше:
int main(void) {
tPort Leds[] = { {GPIOC, 5U},{GPIOC, 8U},{GPIOC, 9U},{GPIOA, 5U} };
tPort Button = {GPIOC, BUTTON_PIN};
tLedMode Mode = LM_Tree;
int currentLed = 0;
SwitchOnAllLed(Leds, LEDS_COUNT);
for (;;) {
//Проверяем нажата ли кнопка. Она подтянута к 1, поэтому проверка на 0
if (!CHECK_BIT(Button.pPort->IDR, BUTTON_PIN)) {
//Устанавливаем следующий режим
Mode = (Mode < LM_End) ? (tLedMode)(Mode + 1U) : LM_Tree;
currentLed = 0;
//Устанавливаем начальное состояние для нового режима
SetLedsBeginState(Mode, Leds);
}
//Переключаем светодиоды в зависимости от режима
UpdateLeds(Mode, Leds, currentLed);
currentLed = (currentLed < (LEDS_COUNT -1)) ? (currentLed + 1) : 0;
Delay(300U);
}
return 0;
}
Но все же хотелось бы что-то вроде человеческого
If Button is Pressed then
set Next Light Mode
Update Leds
Delay 1000ms
Можно попытаться сделать такое на Си, но тогда придется держать несколько переменных вне функций, например, currentLed, Mode. Эти переменные должны быть глобальными, чтобы функции знали про них. А глобальные переменные, как мы знаем это опять потенциальный риск ошибки. Можно нечаянно поменять значение глобальной переменной в каком-то из модулей, так как вы не можете держать в голове все возможные места, где и как она меняется, а через год уже и не вспомните зачем она вообще нужна.
Можно использовать для хранения этих данных структуры и пытаться использовать ООП на Си, но следует понимать, что в данном случае будет много накладных расходов, придется как минимум хранить указатель на функцию, а код будет выглядеть очень похожим на С++.
Поэтому перейдем сразу к коду на С++
int main() {
LedsController leds;
Button button{ *GPIOC, 13U };
for (;;) {
if (button.IsPressed()) {
leds.NextMode();
} else {
leds.Update();
}
Delay(1sec);
}
return 0;
}
#ifndef UTILS_H
#define UTILS_H
#include <cassert>
namespace utils {
template<typename T, typename T1>
inline void setBit(T &value, T1 bit) {
assert((sizeof(T) * 8U) > bit);
value |= static_cast<T>(static_cast<T>(1) << static_cast<T>(bit));
};
template<typename T, typename T1>
inline void clearBit(T &value, T1 bit) {
assert((sizeof(T) * 8U) > bit);
value &=~ static_cast<T>(static_cast<T>(1) << static_cast<T>(bit));
};
template<typename T,typename T1>
inline void toggleBit(T &value, T1 bit) {
assert((sizeof(T) * 8U) > bit);
value ^= static_cast<T>(static_cast<T>(1) << static_cast<T>(bit));
};
template<typename T, typename T1>
inline bool checkBit(const T &value, T1 bit) {
assert((sizeof(T) * 8U) > bit);
return !((value & (static_cast<T>(1) << static_cast<T>(bit))) == static_cast<T>(0U));
};
};
constexpr unsigned long long operator "" sec(unsigned long long sec) {
return sec * 1000U;
}
#endif#ifndef LED_H
#define LED_H
#include "utils.hpp"
class Led
{
public:
Led(GPIO_TypeDef &portName, unsigned int pinNum): port(portName),
pin(pinNum) {};
inline void Toggle() const { utils::toggleBit(port.ODR, pin); }
inline void SwitchOn() const { utils::setBit(port.ODR, pin); }
inline void SwitchOff() const { utils::clearBit(port.ODR, pin); }
private:
GPIO_TypeDef &port;
unsigned int pin;
};
#endif#ifndef LEDSCONTROLLER_H
#define LEDSCONTROLLER_H
#include "led.hpp"
#include <array>
enum class LedMode : unsigned char {
Tree = 0,
Chess = 1,
All = 2,
End = 2
};
constexpr int LedsCount = 4;
class LedsController {
public:
LedsController() { SwitchOnAll(); };
void SwitchOnAll() {
for (auto &led: leds) {
led.SwitchOn();
}
};
void ToggleAll() {
for (auto &led: leds) {
led.Toggle();
}
};
void NextMode() { mode = (mode < LedMode::End) ?
static_cast<LedMode>(static_cast<unsigned char>(mode) + 1U) : LedMode::Tree;
currentLed = 0;
if (mode == LedMode::Chess){
for(int i = 0; i < LedsCount; i++) {
if ((i % 2) == 0) {
leds[i].SwitchOn();
} else {
leds[i].SwitchOff();
}
}
} else {
SwitchOnAll();
}
};
void Update() {
switch(mode) {
case LedMode::Tree:
leds[currentLed].Toggle();
break;
case LedMode::All:
case LedMode::Chess:
ToggleAll();
break;
default:
break;
}
currentLed = (currentLed < (LedsCount - 1)) ? (currentLed + 1) : 0;
}
private:
LedMode mode = LedMode::Tree;
int currentLed = 0;
std::array<Led, LedsCount> leds{Led{*GPIOC, 5U},Led{*GPIOC, 8U},Led{*GPIOC, 9U},Led{*GPIOA, 5U}};
};
#endif#pragma language = extended
#pragma segment = "CSTACK"
extern "C" void __iar_program_start( void );
class DummyModule {
public:
static void handler();
};
typedef void( *intfunc )( void );
//cstat !MISRAC++2008-9-5-1
typedef union { intfunc __fun; void * __ptr; } intvec_elem;
#pragma location = ".intvec"
//cstat !MISRAC++2008-0-1-4_b !MISRAC++2008-9-5-1
extern "C" const intvec_elem __vector_table[] =
{
{ .__ptr = __sfe( "CSTACK" ) },
__iar_program_start,
DummyModule::handler,
DummyModule::handler,
DummyModule::handler,
DummyModule::handler,
DummyModule::handler,
0,
0,
0,
0,
DummyModule::handler,
DummyModule::handler,
0,
DummyModule::handler,
DummyModule::handler,
//External Interrupts
DummyModule::handler, //Window Watchdog
DummyModule::handler, //PVD through EXTI Line detect/EXTI16
DummyModule::handler, //Tamper and Time Stamp/EXTI21
DummyModule::handler, //RTC Wakeup/EXTI22
DummyModule::handler, //FLASH
DummyModule::handler, //RCC
DummyModule::handler, //EXTI Line 0
DummyModule::handler, //EXTI Line 1
DummyModule::handler, //EXTI Line 2
DummyModule::handler, //EXTI Line 3
DummyModule::handler, //EXTI Line 4
DummyModule::handler, //DMA1 Stream 0
DummyModule::handler, //DMA1 Stream 1
DummyModule::handler, //DMA1 Stream 2
DummyModule::handler, //DMA1 Stream 3
DummyModule::handler, //DMA1 Stream 4
DummyModule::handler, //DMA1 Stream 5
DummyModule::handler, //DMA1 Stream 6
DummyModule::handler, //ADC1
0, //USB High Priority
0, //USB Low Priority
0, //DAC
0, //COMP through EXTI Line
DummyModule::handler, //EXTI Line 9..5
DummyModule::handler, //TIM9/TIM1 Break interrupt
DummyModule::handler, //TIM10/TIM1 Update interrupt
DummyModule::handler, //TIM11/TIM1 Trigger/Commutation interrupts
DummyModule::handler, //TIM1 Capture Compare interrupt
DummyModule::handler, //TIM2
DummyModule::handler, //TIM3
DummyModule::handler, //TIM4
DummyModule::handler, //I2C1 Event
DummyModule::handler, //I2C1 Error
DummyModule::handler, //I2C2 Event
DummyModule::handler, //I2C2 Error
DummyModule::handler, //SPI1
DummyModule::handler, //SPI2
DummyModule::handler, //USART1
DummyModule::handler, //USART2
0,
DummyModule::handler, //EXTI Line 15..10
DummyModule::handler, //EXTI Line 17 interrupt / RTC Alarms (A and B) through EXTI line interrupt
DummyModule::handler, //EXTI Line 18 interrupt / USB On-The-Go FS Wakeup through EXTI line interrupt
0, //TIM6
0, //TIM7 f0
0,
0,
DummyModule::handler, //DMA1 Stream 7 global interrupt fc
0,
DummyModule::handler, //SDIO global interrupt
DummyModule::handler, //TIM5 global interrupt
DummyModule::handler, //SPI3 global interrupt
0, // 110
0,
0,
0,
DummyModule::handler, //DMA2 Stream0 global interrupt 120
DummyModule::handler, //DMA2 Stream1 global interrupt
DummyModule::handler, //DMA2 Stream2 global interrupt
DummyModule::handler, //DMA2 Stream3 global interrupt
DummyModule::handler, //DMA2 Stream4 global interrupt 130
0,
0,
0,
0,
0,
0,
DummyModule::handler, //USB On The Go FS global interrupt, 14C
DummyModule::handler, //DMA2 Stream5 global interrupt
DummyModule::handler, //DMA2 Stream6 global interrupt
DummyModule::handler, //DMA2 Stream7 global interrupt
DummyModule::handler, //USART6 15C
DummyModule::handler, //I2C3 Event
DummyModule::handler, //I2C3 Error 164
0,
0,
0,
0,
0,
0,
0,
DummyModule::handler, //FPU 184
0,
0,
DummyModule::handler, //SPI 4 global interrupt
DummyModule::handler //SPI 5 global interrupt
};
__weak void DummyModule::handler() { for(;;) {} };
extern "C" void __cmain( void );
extern "C" __weak void __iar_init_core( void );
extern "C" __weak void __iar_init_vfp( void );
#pragma required=__vector_table
void __iar_program_start( void )
{
__iar_init_core();
__iar_init_vfp();
__cmain();
}
#include <stm32f411xe.h>
#include "ledscontroller.hpp"
#include "button.hpp"
extern "C" {
int __low_level_init(void) {
//Включение внешнего генератора на 16 МГц
RCC->CR |= RCC_CR_HSION;
while ((RCC->CR & RCC_CR_HSIRDY) != RCC_CR_HSIRDY) {
}
//Переключаем системную частоту на внешний генератор
RCC->CFGR |= RCC_CFGR_SW_HSI;
while ((RCC->CFGR & RCC_CFGR_SWS) != RCC_CFGR_SWS_HSI) {
}
//Подаем тактирование на порты С и А
RCC->AHB1ENR |= (RCC_AHB1ENR_GPIOCEN | RCC_AHB1ENR_GPIOAEN);
//LED1 на PortA.5, ставим PortA.5 на выход
GPIOA->MODER |= GPIO_MODER_MODE5_0;
//LED2 на PortС.9,LED3 на PortC.8,LED4 на PortC.5 ставим PortC.5,8,9 на выход
GPIOC->MODER |= (GPIO_MODER_MODE5_0 | GPIO_MODER_MODE8_0 | GPIO_MODER_MODE9_0);
return 1;
}
}
//Задержка, для простоты реализована в виде цикла
inline void Delay(unsigned int mSec) {
for (unsigned int i = 0U; i < mSec * 3000U; i++) {
__NOP();
};
}
int main() {
LedsController leds;
LedsController leds1;
Button buttonUser{*GPIOC, 13U};
for(;;)
{
if (buttonUser.IsPressed()) {
leds.NextMode();
} else {
leds.Update();
leds1.Update();
}
Delay(1sec);
}
return 0;
}Похоже на то, что нам удалось написать код на С++ практически человеческим языком? Неправда ли очень понятный и простой код. Этот код не требует никаких комментариев, все понятно и так. Мы даже использовали пользовательский литерал «sec», чтобы было понятно что это секунда, которая затем преобразуются в отсчеты для передачи в функцию Delay, с помощью следующей конструкции:
constexpr unsigned long long operator "" sec(unsigned long long sec) {
return sec * 1000U;
}
...
Delay(1sec);Определение пользовательского литерала задается с помощью оператора "" и названия литерала. Ключевое слово constexpr указывает копилятору, что если это возможно значение должно быть посчитано на этапе компиляции и просто подставлено в код. В данном случае все значения известны на входе, мы передаем 1 и на выходе получаем 1000. Поэтому компилятор просто заменит вызов Delay(1sec) на Delay(1000) — очень удобно и читабельно. С помощью этого же ключевого слова можно заменить все макросы типа,
#define MAGIC_NUM 0x5f3759dfна более понятное
constexpr unsigned int MagicNumber = 0x5f3759df;Еще раз повторюсь, мы получили очень расширяемый и понятный код, такой что при добавлении новых режимов моргания светодиодами или изменения количества светодиодов здесь вообще ничего не надо будет менять! Необходимо будет сделать небольшие изменения только в классе LedsController, отвечающий за поведение светодиодов. На лицо преимущество использования такого подхода.
Так сколько же ресурсов теперь стало занимать такое решение? Взглянув на код, практически любой программист скажет, что код на С++ должен быть значительно больше, да что там, я и сам в этом убеждён. Ведь тут и несколько объектов на стеке, вызовы конструкторов и дополнительных методов. Но хватит предположений — перейдем к цифрам и сравним размеры кода на Си и С++ при отключенной оптимизации Код на Си занимает 496 байт и 80 байт максимальная вложенность стека. Код на С++ занимает 606 байт и 112 байт вложенности стека.
Казалось бы, на лицо 20% преимущество по размеру кода и стека в пользу Си. Но дело в том, что по умолчанию IAR компилятор никак не реагирует на ключевое слово inline у функций и поэтому каждый раз вставляет вызовы функций, это в свою очередь приводит к увеличению кода и стека из-за сохранения и восстановления контекстов функций, а также к уменьшению скорости выполнения. Сделано это для того, чтобы можно было нормально провести отладку методов и функций, иначе бы некоторых функций и локальных переменных вообще бы не существовало в результирующем коде.
Если мы включим оптимизацию и поддержку inline функций, то картина будет уже другой. Код на Си занимает 396 байта и 72 байта на стеке.
Код же на С++ занимает 400 байта и 72 байта на стеке. Разница в 4 байта, а ассемблерный код практически идентичен коду на Си при очевидном преимуществе в простоте и лаконичности кода на С++. И кто теперь скажет что на С++ не выгодно писать встроенное ПО?
P.S.:
Пример кода можно взять тут.
Спасибо за найденный недочет vanxant, Mabu, exchg, Antervis, а NightShad0w за хороший пример поиска наименьшего с помощью std библиотеки Код поиска наменьшего с std
С хорошего совета Jef239 для уменьшения размера ОЗУ под массив leds его можно задать как static const, а все методы класса Led сделать константными, тогда массив на этом процессоре будет расположен в памяти программ и стек уменьшится на размер этого массива. Выбор за разработчиком, что важнее…
Комментарии (112)

Dovgaluk
31.01.2018 18:42Какая разница передавать указатель или обращаться к объекту? Имя все равно пишется, параметр все равно передается.
Вот если много вложенных вызовов методов, то в C++ исходник действительно покороче будет.
Кстати, странно, что первый пример на Си не оптимизировался, обычно компиляторы это умеют.lamerok Автор
31.01.2018 19:36Разница в том что указатель изменяемый, его можно забыть про инициализировать, можно нечаянно поменять. Таких примеров предостаточно. Для этого в срр и придуманы были ссылки, и умные указатели, чтобы такие проблемы и закрывать.
segment
31.01.2018 19:29+1Нужен пример из реальных и больших задач/проектов. Сколько помню, всегда приводят в пример миганием светодиодом или обращение к IO пинам — это не показатель.
lamerok Автор
31.01.2018 19:32+2Есть такой, на этой же плате с графическим индикатором и блутузом, но в статью не влезет.

monah_tuk
01.02.2018 01:54Epiphan AV.io, все девайсы в линейке. Epiphan KVM2USB3.0. Правда там ресурсов побольше: Cypress FX3, на код 300 кБ и оперативки около 100кБ. При этом, например, для типобезопасного доступа к регистрам I2C реализована абстракция… которая полностью исчезает в бинарном коде. Т.е. она решает проблему: ударить по рукам пользователю на этапе компиляции, если он пытается запихнуть непихуемое, но обладает нулевой стоимостью в рантайме. Да, шаблоны :) К сожалению, код приводить не могу по понятным причинам. Кодовая база около 50+ тыс строк. Рантайм свой — только необходимое, исключений нет. Код в релизной версии около 230кБ. Компилятор GCC 4.8.4. C++11.

potan
31.01.2018 19:55А почему C++, а не сразу Rust? Переход с C на C++ не сильно проще, а преимуществ дает меньше.
VioletGiraffe
31.01.2018 20:11Потому что С и С++ — промышленный стандарт де-факто для «нативного» программирования?
А ещё Rust некрасивый и неудобный, но это уже моё личное субъективное мнение.DrLivesey
01.02.2018 09:32-4Однако же в Rust уже как минимум с 1.0.0 есть целый набор фич, которые аналогичны тем, что вошли в С++17.
Falstaff
01.02.2018 14:34А у него уже тулчейн для микроконтроллеров в удобоваримом состоянии? Просто когда в последний раз смотрел, они весь embedded официально оставляли "на когда-нибудь потом", и всё что было доступно — это сделанные энтузиастами хаки разной степени допиленности и удобства в использовании. Что-то с тех пор поменялось, интересно?

beeruser
31.01.2018 21:26Как можно увидеть сгенерированный компилятором код на С++ на 4 байт меньше, а скорость работы на 12 тактов быстрее. Все это достигается за счет новых возможностей С++14
Причём тут возможности С++14? Вы о чём?
В первом листинге проблема с оптимизацией (она вообще включена?) — два раза перечитывается значение из массива, к тому же не произведёна оптимизация strength reduction на индексе цикла.
В результате имеем 4 инструкции, 12 байт против 2 инструкций, 4 байта
Т.е. 8 байт потеряно на пустом месте.lamerok Автор
31.01.2018 21:34Оптимизация включена, при включенной код не имеет смысла, все вычисляется на этапе компиляции. Тут показано, что в общем случае for с обходом через итератор преобразуется в более эффективный код.
beeruser
31.01.2018 22:54при включенной код не имеет смысла, все вычисляется на этапе компиляции
Детский сад.
Ну так создайте зависимость чтобы код не превращался в return 0;
godbolt.org/g/NwK3Wp
Пока что получается что ваша статья не имеет смысла, т.к. исходит из неверных предпосылок.
NightShad0w
01.02.2018 08:14+1И добавлю версию с увеличенным количеством С++14, а то чего вручную-то по массиву ходить.
godbolt.org/g/xHMEho

eandr_67
01.02.2018 14:52+1А что мешает использовать в С не индекс а указатель? Насколько эффективна компиляция такого кода?:
for (int *i = testArray + 4; i >= testArray; --i) { lowest = (lowest < *i) ? lowest : *i; }lamerok Автор
01.02.2018 15:42Проверил по коду размер одинаковый стал. Но согласитесь, что код на С++ с новым for лаконичнее.
beeruser
02.02.2018 00:19Этого делать не нужно. Компилятор сам всё делает. Смотрите мой коммент выше.
dev96
31.01.2018 21:48Во второй половине 2017-ого года в ВУЗе был курс по микроконтроллерам. Преподаватель давал задачи решать на С, да и все одногруппники. Но я, человек, привыкший к С++ и ООП поколупавшись в Keil, взял и начал писать на С++. Набросал небольшую библиотеку на классах под CMSIS и понеслась))) Работали мы с STM32F103C8. Писали на Keil 4, где был стандарт С++03, что было для меня дико неудобным. В итоге притащил в универ Keil 5 (в последней версии добавили компилятор ARM Compiler с поддержкой С++14), помудрил с либой CMSIS под наш МК, в итоге скомпилировал проект со своей либой, но на МК не завелось нормально (и не было времени разбираться с этим).
Так вот, к чему я веду, С++ стараются внедрить в область разработки под МК, да и это безусловно удобнее, чем писать на чистом С.
Но вот заинклюдив тот же программа на МК уже не влезала… (На STM32F103C8 64Kb под программу).dev96
31.01.2018 22:25«Но вот заинклюдив vector тот же, программа на МК уже не влезала...»
lamerok Автор
31.01.2018 22:51) конечно, можно было использовать просто массивы или std::array. Vector слишком громоздкий, и юзает динамически выделяемую память. Сразу появляется куча, за которой следить нужно… Лучше динамически создаваемые объекты вообще не использовать.
dev96
31.01.2018 23:12я кучу в своей обёртке использовал (не более 1,5 кб, при доступных 20кб). И std::array мне не был доступен, ибо с компилятором, с поддержкой С++14 я не стал разбираться дальше и продолжил писать на С++03.
iCpu
01.02.2018 06:47+2А ещё можно было застрять на старом WATCOM даже без C++98, и в его контексте жаловаться на неудобства. На том же Болте Богов можно увидеть, что между gcc 4.5 и gcc 7.2 огромная разница, тем более, что для лучшего результата нужно теребонькать ключи компилятора.
dev96
01.02.2018 11:31+1Мне и C++03 неудобный, ибо я начинал программировать сразу на С++11, с использованием большинства нововведений. И код на чистом С мне не приходилось писать вообще никогда.
А под МК я писал только по учебе в универе.

Punk_Joker
01.02.2018 16:42Можно попробовать Embedded Template Library
У самого пока руки недошили ее опробовать
Mabu
31.01.2018 21:48Почему переменная lowest инициализируется нулём, а не первым элементом массива?
Если инициализировать нулём, то среди чисел {2, 1, 3} алгоритм покажет, что наименьшее — это ноль.
Это ошибка.
Инициализируйте lowest первым элементом массива и обходите массив начиная со второго.lamerok Автор
31.01.2018 21:53Я, согласен, что это топорный пример, но я там написал, что это очень синтетический тест, его конечно можно улучшить, но я хотел показать, что если писать в лоб, примерно в одном стиле, то можно получить такой вот результат.


exchg
31.01.2018 21:48Зачем вы сравнили два разных кода с отключенной оптимизацией? В Си версии эквивалентом (без оптимизации) будет что-то типа:
for (int i = 0; i < 5; i++) { int val = testArray[i]; lowest = ((lowest < val) ? lowest : val); };lamerok Автор
31.01.2018 21:58С включенной оптимизацией, все вычислится на этапе компиляции и кода не будет.
exchg
31.01.2018 22:40Да, я это понимаю. И говорю о том, что в таком случае нужно сравнивать хотя бы эквивалентный код. Иначе в чем смысл? Данное сравнение показывает, что код с двумя чтениями из памяти менее оптимальный чем код с одним чтением из памяти.
Ну а в общем не совсем понятно, почему С++ код в Си стиле, должен давать менее оптимальный выхлоп?
ЗЫ Ну и исправьте ошибку с инициализацией, понятно что код демонстрационный, но глаз режет.
Sub_Dia
31.01.2018 21:53Да, я раньше тоже считал, что С++ избыточен для МК.
Потом понял, что просто не знаю языка и вообще боюсь начинать с ООП. Прошло довольно много времени, и я успешно применяю С++ в проектах на микроконтроллерах.segment
31.01.2018 23:42Можете привести пример удачного использования C++ в крупном проекте? Где реализация на Си была бы слишком громоздкой
a1ien_n3t
01.02.2018 01:21github.com/PX4/Firmware вот пример крупного проекта для микроконтроллеров написанного на c++.
*По секрету у нас тоже свой автопилот и тоже на с++ под микроконтроллеры.monah_tuk
01.02.2018 01:59Мой пример: https://habrahabr.ru/post/347980/#comment_10646510, но, извините, без кода.

ncix
01.02.2018 01:12Странно, что никто не вспомнил Arduino — вот вам и МК и С++ и исключительно успешный проект.
monah_tuk
01.02.2018 02:00Я бы не относил это к удачным примерам. То, что я видел — достаточно топорно написано. Но для варианта — быстро что-то набросать, вполне.
ncix
01.02.2018 10:02+1За всё время наверное миллиарды плат Ардуино и клонов произведены и проданы, и это неудачный пример? Фреймворк и многочисленные библиотеки прекрасно справляются с задачами предоставления удобного API к контроллеру на С++ для любителей DIY.
Я предполагаю аргумент, что для промышленного применения это всё не годится. Согласен. Конечно, не годится, это проект не для промышленного применения. Но тем не менее это пример исключительно успешного использования С++ на МК.

h0rr0rr_drag0n
01.02.2018 11:25Мне кажется неправильным сводить успех Ардуины как продукта к используемому в процессе её разработки языку программирования.
Скорее всего, для среднего пользователя Ардуины куда как важнее простота расширения платы при помощи всяких разных модулей, то что в комплекте с платой поставляется готовая среда разработки (с каким-то своим Си-подобным диалектом) и прочие подобные вещи, о которых заранее подумали специально обученные люди.
Не говорю уже об узнаваемом бренде, следующей отсюда явной и не очень рекламе Ардуины среди новичков практически во всех профильных местах и т.д.ncix
01.02.2018 11:33+1готовая среда разработки (с каким-то своим Си-подобным диалектом)
Там самый настоящий С++, компилируется при помощи avr-gcc.
Если бы пользователю пришлось писать на чистом си или ассемблере — возможно и не было бы такого успеха.
h0rr0rr_drag0n
01.02.2018 12:33Хм, из того, что я читал про Ардуино ранее — следует что в тамошнем IDE используется какое-то урезанное в сторону простоты подмножество C++, которое уменьшает порог вхождения для тех, кто раньше особо не программировал.
Вроде бы это подмножество вместе с IDE и прочими утилитами называется Wiring, но это не точно:
Заголовок спойлераWiring and Processing have spawned another project, Arduino, which uses the Processing IDE, with a simplified version of the C++ language, as a way to teach artists and designers how to program microcontrollers. There are now two separate hardware projects, Wiring and Arduino, using the Wiring environment and language.
https://en.wikipedia.org/wiki/Wiring_(development_platform)iCpu
01.02.2018 12:46У них поддержка синтаксиса в самой IDE значительно урезана. Позор-позор, если честно. Но если, например, подключить любой готовый проект с Atmel Studio, всё будет работать как надо.
ncix
01.02.2018 14:15Не совсем понятно что значит "поддержка синтаксиса в IDE"? Автокомплит? Лично писал код с классами, темплейтами и макросами.
PS: Хотя конечно IDE убогая
dev96
01.02.2018 14:23Arduino IDE хотя-бы бесплатная, хоть и похожа больше на примитивнейший текстовый редактор. А Keil uVision IDE продаётся за бешенные деньги (не считая Lite-версии), но при этом дико баганутая и не доработанная.
ncix
01.02.2018 14:31Atmel Studio бесплатная, вполне годная IDE.
но под Ардуино по мне так лучше смириться с убогим редактором, зато получить бесконечно богатый менеджер готовых библиотек. Все равно проекты там физически не могут быть большими. Пара десятков файлов это край, обычно не более 5. Многие вообще в одному модуле всё пишут даже без функций, сплошным текстом (жесть конечно).
iCpu
01.02.2018 17:06Atmel — по сути тупо вижак с помидором. Бесплатно! А, значит,
ДАРОМ!!!
А Arduino IDE, по сути, не поддерживает проекты из нескольких файлов. Подсветка тех же шаблонов не работает. Автокомплит только после добавления собственных символов в keywords.txt
Оно не критично для atmega 168, но уже на 2560 размеры выходят из-под контроля. Да и attiny16 в такой IDE не запрогаешь без боли, но по обратной причине.
Да, менеджер библиотек — это круто, но он обновляется из рук вон плохо, так что некоторые поделки застряли на той же стадии, что и IDE — лагающее, извините мой французский, дерьмо.ncix
01.02.2018 17:33А Arduino IDE, по сути, не поддерживает проекты из нескольких файлов.
Поддерживает. Просто закиньте несколько файлов в одну папку.

darkdaskin
01.02.2018 17:23+1Незачем мириться с убогим редактором. Можно поставить дополнение VisualMicro (работает с Visual Studio или Atmel Studio) и получить мощь нормальной IDE вместе с доступом ко всем библиотекам Arduino. Даже отладка в симуляторе кое-как работает (правда, у меня не завелись точки останова — то ли нужна платная версия, то ли просто что-то недонастроил).
EGregor_IX
01.02.2018 09:16+1Хм. У меня лежат либы под AVRки написанные в 2007 году и на С++. Компилятор IAR генерит отличный компактный код, ничем не уступающий по компактности написанному на чистом C. При написании на плюсах есть хитрости в виде статического экземпляра класса или статические функции например.
А что касается ошибок вида «установка десятого бита в восьмибитной переменной», то у вас неправильно построен процесс разработки. Для любой периферии драйверы пишутся человеком, который очень хорошо знает саму железяку, и этот драйвер имеет функции не «SETBIT(port, pin), а функции вида „errStatus InitDisplay()“. И вот этот набор драйверов передаётся программисту, который пишет алгоритмы, протоколы обмена и прочий матан. Вот тогда всё работает отлично и все довольны.
MUTbKA98
01.02.2018 09:16-2Все описанное — это не C++. Это «Си с использованием элементов современного синтаксиса». Я и сам так пишу.
C++ — это когда с собой тащится stl или boost, море классов с наследованием, вcякие shared_ptr на каждой строчке и ключевое слово virtual повсеместно.
Но тогда, боюсь, все будет не так компактно.lamerok Автор
01.02.2018 09:25+2Наследование, не показал согласен, но оно вообще когда не добавит, если вирутальные функции не использовать. Можно обойтись же без shared_ptr. Я тут старался показать, что код на намного С++ лаконичнее, и размер такой же. и это не просто Си с использование соврменного синтаксиса, так как на Си такое будет занимать больше места, я там написал, что можно структры использовать и указатели на функции, но это сразу + к размеру.
Про std, см комментарий от NightShad0w, при ключенной оптимизации все работает ОК.
habrahabr.ru/post/347980/#comment_10646698. Проверил на IAR, тоже код такой же. Поэтому её использовать можно, но не безздумно. unique_ptr например запросто, он ничего не добавит, а вот shared_ptr нет, он сразу добавит много накладных, хотя все зависит от задачи, если вы на Си будете решать, ту же задачу, что решает во многих случая shared_ptr, то возможно и кода будет больше.
ncix
01.02.2018 09:55+4Неожиданно. С++ это код соответствующий одному из стандартов С++ХХ, вот и всё. Если у кого-то не получается писать на С++ без boost и stl — язык в общем-то тут ни при чём.

Dima_Sharihin
01.02.2018 16:13Ну, между прочим, shared_ptr-подобный интерфейс вполне можно накрутить поверх пулов памяти какой-нибудь RTOS.
Буст и прочие, конечно, хороши, но часто слишком избыточны для задачи.
oam2oam
01.02.2018 09:25+1Удивительно, что такой пример можно сделать и на языке Ада (ниже для stm32f407ve) и… получится несколько другой результат (исходный текст вставлен в дизассемблер):
testArray : array (1..5) of integer := (-1,20,-3,0,4) with volatile;
lowest : Integer := 10000;
procedure q_ada is
84: 4b08 ldr r3, [pc, #32] ; (a8 <pager__q_ada+0x24>)
86: 6898 ldr r0, [r3, #8]
88: b530 push {r4, r5, lr}
begin
for i in 1..5 loop
8a: 2200 movs r2, #0
8c: f06f 4440 mvn.w r4, #3221225472 ; 0xc0000000
90: 3201 adds r2, #1
lowest := (if lowest < testArray(i) then lowest else testArray(i));
92: 1911 adds r1, r2, r4
94: eb03 0181 add.w r1, r3, r1, lsl #2
98: 68cd ldr r5, [r1, #12]
9a: 4285 cmp r5, r0
9c: bfd8 it le
9e: 68c8 ldrle r0, [r1, #12]
a0: 2a05 cmp r2, #5
a2: d1f5 bne.n 90 <pager__q_ada+0xc>
a4: 6098 str r0, [r3, #8]
lowest := (if lowest < testArray(i) then lowest else testArray(i));
end loop;
end q_ada;
a6: bd30 pop {r4, r5, pc}
Пришлось, конечно, постараться, чтобы код давал не 0 байт :), так как, действительно пользы от него совсем нет…

eurol
01.02.2018 09:25Код на Си:
int lowest = INT_MAX;
И его ассемблерное представление:
int lowest = 0;
Что-то не так в датском королевстве. Хотя это и не влияет на сравнение, но все же код неверный.lamerok Автор
01.02.2018 09:26Там ошибка изначально была, я её поправил, ассемблер еще нет — картинку надо делать новую.
AndyKorg
01.02.2018 09:26Т.е. такую важную вещь ООП как исключения нежелательно использовать в проектах для МК?
lamerok Автор
01.02.2018 09:46+2Исключения сразу значительно увеличит размер кода, так как добавится таблица с информацией о том где исключение было поднято и где искать его обработчик и сам механизм поиска обработчика исключения тоже будет в коде. Ну и медленно это все будет… на 1 Мгц то.

Antervis
01.02.2018 09:32+1for (auto led : leds) {
здесь led копируется по значению. Меняя состояние led вы не поменяете состояние *it. Если нужно просто обойти массив, более корректным был бы проход по ссылке:
for (auto &led : leds) {
Вероятно, в этих разыменованиях и есть разница в пару инструкций
IRainman
01.02.2018 11:26+2Не просто можно но и нужно и не только для маленьких, а для больших тоже ибо из-за отсутствия пространств имён в C и шаблонов требуется огромное количество копипасты или макросгенерации, которая не отлаживаема вообще, а также дико длинные префиксы и постоянный геморой со сборкой и линковкой. В C++ этого ужаса и бардака нет. Я уже молчу про STL и нормальные интерфейсы к повседневной алгоритмике.

ganqqwerty
01.02.2018 12:11Что думают в царстве микроконтроллеров о том, что к вам придёт JavaScript и рынок труда сильно поменяется?
lamerok Автор
01.02.2018 13:45+2На 8, — 256 кБайта памяти программ и 4 — 20 кБ ОЗУ, он никогда не придет. Миниатюрным датчикам и низкопотребляющим устройствам это не грозит тоже. А вся промышленность сидит именно на этом. Все упирается в потребление и цену, зачем мне быстрый навороченный микро, который стоит 7 баксов, но с возможностью Джава, если то же само можно сделать на 1 баксовом? При объемах в 30 000 скажем датчиках в год (а к слову, средний объем датчиков температуры у какого-нибудь Элемера) получим 180 000 долларов экономии! А если взять конторы покрупнее, то выгода может быть и под миллион долларов.

Methos
02.02.2018 10:37-1Это сейчас так.
А через 5 лет микроконтроллеры будут иметь память 1 Гбайт спокойно и её просто некуда будет деть, поэтому всё будет написано на js, компилируемым в assembler =)Free_ze
02.02.2018 10:48+1А через 5 лет микроконтроллеры будут иметь память 1 Гбайт спокойно и её просто некуда будет деть
Тогда они просто станут еще дешевле. Микроконтроллеры — это не готовый продукт для потребителя, поэтому маркетинг а-ля «два ядра, три гига» там просто смысла не имеет.
А вот всякого-рода *duino за много денег с кортексом на борту лишь для того, чтобы вращать педали JS-интерпретатора, уже есть. Но индустрия этого не замечает. Серьезные конторы в сфере IoT концентрируются лишь на облачных решениях с JS-интерфейсом, а исполнительные устройства/датчики все так же на C.
Gryphon88
01.02.2018 14:36Извините, а разве в С не принято делать через виртуальный порт, и по нему елозить масками?
lamerok Автор
01.02.2018 14:49не понял вопроса, вы имеете ввиду, что можно, например, сделать включение и выключение всех светодидов маской?
GPIOC->ODR |= ALLLEDS_MASK;
GPIOC->ODR &=~ ALLLEDS_MASK;
Но порты же разные вообще А и С, к ним впринципе одномоментно нельзя маски применить.
Или сделать массив из битов портов, используя битбендинг и по нему лазить, но в чем тогда разница, между обыччным массивом?eurol
01.02.2018 15:45У ARM часто (всегда?) есть возможность указать адрес таким образом, чтобы запись была возможна по маске. То есть берем указатель на байт, в него пишем, скажем, 0xff, а единицы запишутся только в те биты, которые есть в маске. При этом маска указывается неявно, через адрес. Так можно обойтись вообще без масок в программе, заменив их на адреса.
То есть вместо PORTA |= 1<<4 пишем что-то типа *porta_mask_bit4 = 0xff.
Или об этом и было написано, но я не понял?khim
01.02.2018 17:45Я с машинным кодом ARM вожусь по работе последние лет 5 — и такой роскоши не замечал. Подобные CPU в природе бывают, но из-за использования большинством процессоров шины данных шириной более, чем в один быть, они мало распространены.
Не поясните о каких командах идёт речь?eurol
01.02.2018 17:56Речь идет не о командах, а о том, что для некоторых областей памяти сделана возможность доступа к ним побитово через другие области памяти (несомненно, гораздо большего размера).
Вместо того, чтобы писать команды установки некоторых битов и/или сброса других в одном из портов можно написать одну команду записи по определенному адресу, при этом будет выполнена операция, эквивалентная {PORT1&=~maskand;PORT1|=maskor;}. Аналогичная радость есть и при работе с некоторыми участками памяти.
Такая возможность точно есть у процессора LX4F120, который когда-то стоял на первом ланчпаде от TI, и что-то мне подсказывает, что это не TI придумала такую замечательную возможность изменять биты группами, обращаясь к специальной области в адресном пространстве. Впрочем, может, кто-то и разобьет мою уверенность в том, что это ARM-фича.khim
01.02.2018 18:02Вы про BSRR и BRR? Про них уже тут писали…
Ну так в них не будет вместо PORTA |= 1<<4 пишем что-то типа *porta_mask_bit4 = 0xff.
Будет всего лишь PORTA = 1<<4 для установки или PORTA = 1<<(4+16) для сброса.
В адресе никаких масок там нет, не пугайте.eurol
01.02.2018 18:2210.2.1.2 Data Register Operation
To aid in the efficiency of software, the GPIO ports allow for the modification of individual bits in the
GPIO Data (GPIODATA) register (see page 623) by using bits [9:2] of the address bus as a mask.
In this manner, software drivers can modify individual GPIO pins in a single instruction without
affecting the state of the other pins. This method is more efficient than the conventional method of
performing a read-modify-write operation to set or clear an individual GPIO pin. To implement this
feature, the GPIODATA register covers 256 locations in the memory map.
During a write, if the address bit associated with that data bit is set, the value of the GPIODATA
register is altered. If the address bit is cleared, the data bit is left unchanged.
Из даташита на lm4f120h5qr.
Короче говоря, есть базовый адрес регистра, к нему мы можем прибавить маску, правда, умноженную на 4, чтобы получить возможность записывать только в те биты, которые в маске установлены. При этом мы одной операцией записи изменяем только те биты, которые хотим. Кстати, и при чтении такая же фишка есть: биты, которые нам не нужны, при чтении будут сброшены в ноль.dev96
01.02.2018 18:26я себе BSRR и BRR заворачивал в вот такое:
MicroController& controller = MicroController::GetRef(); PortInterface& portA = controller.PortA(); while (true) { portA.Pin(1).High(); Delay(2000); portA.Pin(1).Low(); Delay(2000); }
и это давало возможность писать алгоритмы, принимающие в качестве входных данных структуры, содержащие настройки пинов. Вообщем, удобно и гибко.
Dima_Sharihin
01.02.2018 16:22Главный ключ успешной оптимизации кода — узнать максимальное число ограничений на этапе компиляции. Если из константного указателя мы можем вывести значение, мы можем сэкономить N-тактов процессора, сразу подставив что и куда надо. Если есть возможность развернуть цикл, зная количество итераций, можно ускорить выполнение программы или вообще освободить несколько драгоценных регистров
Суть плюшек современного С++ в том, что compile-time вычисления делать куда проще, нежели делать это в Си (но там это тоже возможно).
UPD: в ARM есть регистры установки, сброса и записи значений GPIO, там операции |= и &= избыточны
dev96
01.02.2018 17:02UPD: в ARM есть регистры установки, сброса и записи значений GPIO, там операции |= и &= избыточны
BSRR и BRR. Причём через BSRR также можно сбрасывать состояние (через старшие разряды). И в мануале советуют работать через эти два регистра (производительнее, ибо ODR там как-то связан с прерыванием, в отличии от этих двух).
Или вы не о том?)Dima_Sharihin
01.02.2018 21:54Да, о них, просто предпочитаю работать через тонкий HAL, и GPIO не из того рода периферии, в которой по ходу службы запоминаешь названия регистров (другое дело eHRPWM от TI, 86 регистров на модуль)
Gryphon88
01.02.2018 15:57Термин bitBending я нашёл только применительно к arm, так что видимо мы разные вещи имеем в виду.
Можно сделать через указатели, неэффективно, но наглядно, как-то так:
typedef struct { volatile uint8_t *port; volatile uint8_t *pin; volatile uint8_t *dir; uint8_t mask; } virt_port; virt_port vport[7] = {{&PORTB,&PINB,&DDRB,(1<<0)}, {&PORTB,&PINB,&DDRB,(1<<1)}, {&PORTB,&PINB,&DDRB,(1<<2)}, {&PORTB,&PINB,&DDRB,(1<<3)}, {&PORTB,&PINB,&DDRB,(1<<4)}, {&PORTB,&PINB,&DDRB,(1<<5)}, {&PORTD,&PIND,&DDRD,(1<<7)}};
Пример взят с avrfreaks
Можно задать «виртуальные пины» таблицей в виде A, 5 (имя реального порта и его номер), а потом размотать через x-macro, тогда можно будет редактировать в одном месте без большой опаски накосорезить.
Другой способ сделать всё на макросах, можно посмотреть пример на chipenable. Там большая портянка, вроде бы для совместимости с С89, поскольку не используется _VA_ARGS_, с которым было бы чуть короче. Аналогичный православный способ — на асме на easyelectronics
Sap_ru
01.02.2018 18:34Исключения на контроллерах практически не работоспособны. Объём кода сразы прыгает за 2 мегабайта для простенькой программы для Cortex.
Кроме того не работоспособна развёртка стека. Это адово долго по меркам контроллера, требует десятки килобайт стека, делает программу непредсказуемой в плане быстродействия.
Но каким обазом C++ связан с исключениями? --no-exption и --no-rtti делают всю магию.
Писать на C++ хорошо, благостно и правильно. Сейчас средненькая программа, это под сотню файлов и мегабайты текста когда.
Неймспейсы, шаблоны, constexpr-выражения (вместо ада из макросов) и даже наследование классов (например, для конечных автоматов) это делает программу проще, понятнее и уменьшает количество ошибок.
Зачем каждый раз клепать циклические буфер, если можно один раз отладить его на шаблонах?
Зачем городить туеву хучу кода в конечных автоматах и потом рыдать над отладкой, если это легко решается наследованием и виртуальными функциями? И никакого оверхеда. Ни байта. Вы бы всё равно писали равно тот же код и использовали те же переменные на чистом C. Местами даже лучше получается, т.к. компилятор может лучше оптимизировать работу с данными.
А уже заменить болто из макросов, которое есть в любом встраиваемом проекте constexpr выражениями, это сам Бог велел! Количество ошибок и время отладки сразу уменьшаются в разы.
Короче, чтобы писать на C++ для контроллеров, нужно очень хорошо понимать, как именно и во что это компилируется. Тогда код увеличивается только на 200 байт плюсового стартапа, всё остальное эквивалентно.Antervis
01.02.2018 19:58Но каким обазом C++ связан с исключениями? --no-exption и --no-rtti делают всю магию.
увы, но в stl есть несколько узких мест, где нет версии api без исключений.
Другой вопрос — а что будет, если повсеместно использовать noexcept, кроме буквально пары мест, где без них никак? Печатать да, много, но всё равно быстрее чем на чистом си.khim
01.02.2018 21:05Тут уже говорилось: любая попытка собрать программу под мироконтроллер с поддержкой исключений немедленно порождает монстра, который никуда не влазит.

Jef239
02.02.2018 01:08stl (на микроконтроллерах) в большинстве случаев — в топку.
a1ien_n3t
02.02.2018 12:16Вы очень категоричны. Есть куча готовых вещей из stl с нулевым оверхедом.
Sap_ru
04.02.2018 14:20К сожалению узнать об нельзя практически никак. Завтра меняете компилятор или его версию, или версию библиотек и с ужасом понимаете, что у программа выросла в пять раз и требует десятки мегабайт ОЗУ. Т.е. теряется совместимость по компиляторам и их версиях.
Да и вообще там поле граблей. Шаг влево, шаг вправо и какая-нибудь сортировка сжирает всю память. И хорошо, если вы это заметите.a1ien_n3t
04.02.2018 18:26Такого быть неможет в принципе. Почти на все алгоритмы есть гарантии. Если вы такое пишете это показывает, что вы незнаете как устроенны библиотека.
Я могу вам перечислить куча вещей из stl которые гарантированно имею 0 оверхед и никогда не изменятся.
Начинаем
Почти весь атомик. Можно в большинстве своем применять, а не использовать ассемблер или Builtins
Все трейтисы, когда вы пишите куча шаблонного кода нету смысла плодить свой велосипед.
std::chrono
Многие вещи из utils.
Некоторые контейнеры, тут с оговорками.
Алгоритмы. Многие вы лучше всеравно не напишите.
Sap_ru
04.02.2018 14:18-1STL не применим для embedded от слова никак. Банально потому, что там активно используется динамическая память и алгоритмы не оптимизированные по расходу памяти.
noexept, как правило, мало. Нужно ещё компилятору ключ передавать, что использует C++ без исключений. Иначе он подключает не только библиотеку развёртки стека, но и, что хуже, невероятное число данных о стеках всех фукций в программе.Falstaff
04.02.2018 15:39+1Как-то вы уж очень безапелляционно. Далеко не весь STL использует динамическое выделение памяти. Что-то просто не стоит использовать, памятуя что оно использует кучу. Что-то можно перевести на собственные аллокаторы с пулами. Для чего-то можно выделить максимальный размер памяти используя .reserve(), тем более что в embedded многое создаётся единожды и живёт пока прошивка работает — выделить память из кучи не страшно, если это делается один раз во время инициализации. Что-то можно разместить на флэше (неизменяемые ассоциативные массивы, например, хорошо ложатся на размещённый во флэше std::map). Без исключений тоже вполне можно жить.
Да, признаю, надо много знать об STL и держать в уме нюансы, но оно везде так, нюансов в любой области полно. Для кого-то овчинка не стоит выделки, для кого-то стоит.
Antervis
04.02.2018 18:52+1большая часть алгоритмов из algorithms library не требует исключений и динамического выделения памяти, не добавляет никакого оверхеда, а объем кода сокращает в разы.
Jef239
02.02.2018 01:06Конечно глубина стека при этом вырастет значительно, так как массив светодиодов создается на стеке, а он уже равен 56 байтам.
Использовать static или создавать массив вне функции религия не позволяет? :-)lamerok Автор
02.02.2018 06:54Ну впринципе вообще глобальная переменная это вред. Static можно, но какая рзаница? ОЗУ все равно отъест, а где не имеет значения в стеке или сегменте данных (адрессное пространстров одно, это же не микрочип 16 где стек аппаратный). Единственное, контроллировать стек надо будет, но линкер выдает его максимальный размер, поэтому с моей точки зрения, вообще без разницы.
Dovgaluk
02.02.2018 12:58Линкер не может знать максимальный размер стека, он же не знает полное дерево вызовов, так как оно зависит от входных данных.
Jef239
02.02.2018 15:51+1Почему в ОЗУ? У нас обычно фон-неймановская архитектура. Соответственно static const улетает в ПЗУ (при настроенном линкер-скрипте). И даже если архитектура строго гарвардская, ОЗУ зачастую состоит из нескольких сегментов. Соответственно можно при помощи прагмы запихать static в другой, более свободный, сегмент.
lamerok Автор
02.02.2018 16:50Да согласен, придется только поменять все методы класса Led на const, что собетвенно и правильно, так как поля класса не меняются и эти 56 байт улетят в ПЗУ, освободив стек. Хорошее замечание.
serdzz
02.02.2018 06:54github.com/andysworkshop/stm32plus — реальный проект на c++11
github.com/istarc/stm32 — тут можно посмотреть на оптимизацию с++ кода и использование STL nanospec
Methos
02.02.2018 10:31Ждём статьи со сравнением C++ и Javascript
khim
02.02.2018 13:20Влажные мечты о Javascript можете отставить. Истина между вами лежит посередине. Ни о каких гигабайтах памяти в микроконтроллерах в ближайшее время и говорить не приходится, конечно, но и четырёхбитные микроконтроллеры с 256 байтами программной памяти и частотой в десятки килогерц индустрия использовать перестала. Перешли на более современные архитектуры с памятью в 8-16K и частотой в мегагерц, что уже позволяет использовать C/C++.
Думаю лет через 20 типичный объём памяти дорастёт уже до мегабайта — там уже и байткод какой-нибудь можно будет замутить. А JavaScript… ну если он до конца столетия не вымрет, то всё может быть, конечно.h0rr0rr_drag0n
02.02.2018 14:47Дополню — как верно подметили выше: если научатся делать микроконтроллеры с гигабайтами памяти, то скорее всего просто существующие на тот момент микроконтроллеры с мегабайтами памяти станут ещё дешевле, если технология позволит получать столько же памяти, но за меньшую цену — это таки выгодно для производства.
Заниматься же уменьшением порога вхождения для embedded-разработчика при помощи JavaScript'а на микроконтроллерах с гигабайтами памяти нет никакого резона, поскольку помимо ЯП embedded-разработчику нужно знать ещё вагон вещей для эффективной разработки и (особенно!) отладки своего ПО и язык С или подмножество С++ становятся меньшей из проблем в таком случае.
Jef239
02.02.2018 16:08Байткод — это средство сжатия программы до невероятно малых размеров. Только, разумеется речь не о javascript, а о форте. Полный размер системы с редактором и драйвером диска — 12килобайт, из них чуть больше половины — исполнительная система.
Типичный пример того, что писали на форте — это карманная игра «Ну погоди». Микропроцессор КБ1013ВК1-2, ОЗУ объёмом 65 4-битных ячеек со страничной организацией 13x5, объём программы — 1830 команд.Antervis
03.02.2018 20:16не путайте байткод и машинный код. Первое еще требует компиляцию или (в случае жс) интерпретацию. Сама-то программа конечно в мк влезет, а вот виртуальная машина — нет.
Jef239
03.02.2018 22:36Не путаю. На форте использовался шитый код. Один из его вариантов (индексный шитый код) как раз и является байткодом. То есть в прямом шитом коде пишутся адреса подпрограмм а в индексном и в байт-коде — индексы в массиве, где сидят адреса подпрограмм. Аргументы (если они не в стеке) идут после адреса (или индекса) подппрограммы.
Размер машинозависимой части виртуальной машины форта — примерно 3 килобайта, размер машинонезависимой части — ещё 5 килобайт. В сумме получается интерпретатор вполне полного форта. Ещё 4 килобайта — на драйвер диска и полноэкранный редактор.
Скорость программ на форте — примерно в 10 раз меньше неоптимизированного С++ (20-30 раз к оптимизированному). Компактность — раза в полтора компактней ассемблера.
Да, компилятор на форте — это одна строка. Точнее то, что в форте называется компилятором: взять текстовую строку и превратить её в шитый код.
P.S. Ну что вы хотите, если язык был создан почти 50 лет назад для контроллеров, управляющих телескопами? :-) Форт и 50 лет назад на мелкие машинки легко ложился.


vanxant
В первых двух листингах у вас UB, хороший компилятор должен сделать прогу 0 байт)
Dovgaluk
Если должен, то это не UB
khim
Клуючевое слово «хороший». Плохой — может что угодно сделать.
tangro
Как-раз UB даёт право делать всё, что угодно. А из всего множества «всего, что угодно» вариант «не делать ничего» являетя оптимальным и по затратам времени и по размеру бинарника :)
lamerok Автор
Он не UB, но при включенной оптимизации, размер действительно 0. Можно сделать ввиде отдельной функции.
vanxant
Насчёт UB я погорячился (не в туда посмотрел), но lowest должен инициализироваться testArray[0] или INT_MAX, а не нулём.
lamerok Автор
Точно, поменял.