
В начале моего приключения в роли программиста мой код зачастую напоминал вермишель. В любых условных выражениях я только и делал, что сразу переходил к описанию верного исхода, оставляя на конец остальное. «Это работает, вот и все», — говорил я себе, а код продолжал расти, как на дрожжах. Тысячи написанных методов в итоге заставили меня задуматься, а не стоит ли поменять их внутреннюю логику, возвращая отрицательные результаты как можно раннее. Таким образом, я пришел к тому, что теперь называю правилом «неотложного провала».
Очевидно, что существует несколько подходов написания одной и той же функции. Например, как можно начать выполнение основной части сразу после положительного исхода условного оператора, так и можно сначала пробежаться по всем отрицательным исходам, возвращая ошибки из функции, а уже только потом перейти к основной логике. Иными словами, я открыл для себя разные стили написания условных конструкций.
Два подхода проверки требований
Наиболее базовый подход заключается в том, что если данные соответствуют каким-либо условиям, то программа непосредственно переходит к исполнению основного кода функции. Например, можно отправить сообщение только в том случае, когда переменная
$email является валидным адресом, а $message не является пустой строкой. В противном случае будет возвращена ошибка.function sendEmail(string $email, string $message)
{
if (filter_var($email, FILTER_VALIDATE_EMAIL)) {
if ($message !== '') {
return Mailer::send($email, $message);
} else {
throw new InvalidArgumentException('Cannot send an empty message.');
}
} else {
throw new InvalidArgumentException('Email is not valid.');
}
}Предыдущий отрывок кода является именно тем, что было описано раннее. Работает ли это? Абсолютно. Читаемо ли? Не совсем.
В чем проблема написания требований в самом коде?
Существует две стилистические проблемы в написанной функции
sendMail():- Присутствует более одного уровня отступов в теле функции;
- Невозможно сразу определить путь успешности функции без ее полного изучения;
Так как первый пункт касается понятия «чистого кода», позвольте мне сфокусироваться на втором. Наша функция имеет несколько ветвей, а оператор
return недостаточно хорошо обозреваем. Конечно, приведенный пример очень прост и короток, но на практике в функции может наблюдаться огромное множество условий и возвратов значений. В этот момент и вступает в дело герой-спаситель «обратное условие».function sendEmail(string $email, string $message)
{
if (! filter_var($email, FILTER_VALIDATE_EMAIL)) {
throw new InvalidArgumentException('Email is not valid.');
}
if ($message === '') {
throw new InvalidArgumentException('Cannot send an empty message.');
}
return Mailer::send($email, $message);
}Я понимаю, что избавился от одного
else после второго условного оператора, но, субъективно говоря, новый образец кода выглядит заметно чище и эстетичней. Явно, что «обратное условие» заслужило печеньку за помощь (прим. переводчика, тоже печеньку ему).Чего я достигну, используя «обратные условия»?
Во первых, максимальный уровень отступов в основном теле функции уменьшился до одного, а также мы избавились от вложенных условий. Код становится более читаемым и легким для понимания, а финальная инструкция в конце метода – доступней.
Наверное, сейчас вы недоумеваете, а что именно я назвал подходом «неотложного провала». К сожалению, Jim Shore и Martin Fowler дали определение этому термину еще задолго до моего “Hello world”. Конечно, хотя и цели обоих подходов одинаковые, я решил переименовать мое видение в «ранний возврат». Термин описывает сам себя, так что я закрепил это название «на вывеске».
Концепт «раннего возврата»
Для начала требуется формально определить данный термин.
«Ранний возврат» — это концепт написания функций таким образом, что ожидаемый положительный результат возвращается в конце, когда остальной код в случае расхождения с целью функции должен завершить ее выполнение настолько раньше, насколько возможно.Вы не поверите, насколько долго я думал над данным определением, но в любом случае концепт является обобщенным. Что такое «ожидаемый положительный результат», «завершение выполнения» и «цель функции»? Постараюсь описать это в дальнейшем.
Следуйте «пути к счастью»
«Горшочек с золотом в конце радуги», помните ли вы эту историю? А может вы уже нашли такой горшок? Это именно то, чем можно описать подход «раннего возврата». Ожидаемый приз, успех нашей функции находится именно в конце пути. Глядя на новую версию
sendMail, можно уверенно сказать, что целью функции была отправка сообщения на указанный почтовый адрес. Это и есть «ожидаемый положительный результат», иными словами «путь к счастью».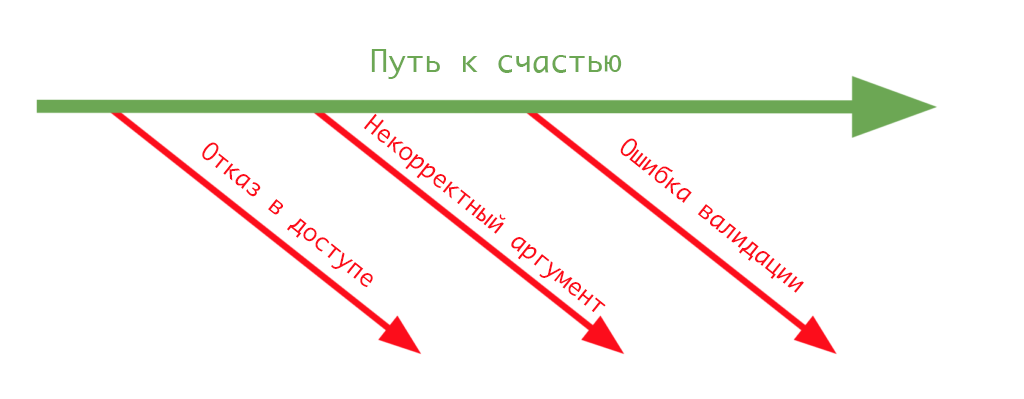
Основной путь в функции четко обозреваем
Расположив финальную операцию в самом конце, мы четко понимаем как выглядит путь к финальной цели. Один взгляд на код, и все становится на свои места.
Избавьтесь от отрицательных случаев как можно ранее
Не всегда исполнение функции приводит к ожидаемому результату. Порой пользователь может ввести неверный email адрес в нашем примере, а порой и пустую строку в качестве сообщения. В обоих случаях требуется завершить работу функции немедленно. Завершением функции может быть или возврат отрицательного значение, или возврат ошибки. Данный выбор индивидуален. Некоторых людей может смутить использование нескольких операторов возврата, но это вполне нормальная практика. К тому же данный подход зачастую делает функцию более понятной для человеческого взора.
«Шаблон вышибалы» — это раннее описанная методология, которая завершает выполнение функции в случаях ее неверного состояния. Взгляните на следующий пример:
function matrixAdd(array $mA, array $mB)
{
if (! isMatrix($mA)) {
throw new InvalidArgumentException("First argument is not a valid matrix.");
}
if (! isMatrix($mB)) {
throw new InvalidArgumentException("Second argument is not a valid matrix.");
}
if (! hasSameSize($mA, $mB)) {
throw new InvalidArgumentException("Arrays have not equal size.");
}
return array_map(function ($cA, $cB) {
return array_map(function ($vA, $vB) {
return $vA + $vB;
}, $cA, $cB);
}, $mA, $mB);
}Данный код просто старается удостовериться, что ход выполнения функции может продолжаться, когда внутренние конструкции возврата значения включают в себя всю основную логику.
Возвращайте пораньше из действий контроллеров
Действия контроллеров – это идеальный кандидат для использования вышеописанного подхода. Действия зачастую включают в себя огромное количество проверок прежде, чем они вернут ожидаемый результат. Давайте рассмотрим пример с
updatePostAction в контроллере PostController:/* PostController.php */
public function updatePostAction(Request $request, $postId)
{
$error = false;
if ($this->isGranded('POST_EDIT')) {
$post = $this->repository->get($postId);
if ($post) {
$form = $this->createPostUpdateForm();
$form->handleRequest($post, $request);
if ($form->isValid()) {
$this->manager->persist($post);
$this->manager->flush();
$message = "Post has been updated.";
} else {
$message = "Post validation error.";
$error = true;
}
} else {
$message = "Post doesn't exist.";
$error = true;
}
} else {
$message = "Insufficient permissions.";
$error = true;
}
$this->addFlash($message);
if ($error) {
$response = new Response("post.update", ['id' => $postId]);
} else {
$response = new RedirectResponse("post.index");
}
return $response;
}Можно заметить, что кусок кода является достаточно объемным, включая множество вложенных условий. Этот же отрывок можно переписать, использую метод «раннего возврата».
/* PostController.php */
public function updatePostAction(Request $request, $postId)
{
$failResponse = new Response("post.update", ['id' => $postId]);
if (! $this->isGranded('POST_EDIT')) {
$this->addFlash("Insufficient permissions.");
return $failResponse;
}
$post = $this->repository->get($postId);
if (! $post) {
$this->addFlash("Post doesn't exist.");
return $failResponse;
}
$form = $this->createPostUpdateForm();
$form->handleRequest($post, $request);
if (! $form->isValid()) {
$this->addFlash("Post validation error.");
return $failResponse;
}
$this->manager->persist($post);
$this->manager->flush();
return new RedirectResponse("post.index");
}Теперь же любой программист может четко увидеть «путь к счастью». Все очень просто: ожидаете, что что-то может пойти не так, — проверьте это и верните отрицательный результат пораньше. Вышеуказанный код также имеет один уровень отступов и присущую большинству подобных функций читаемость. Опять-таки, больше не нужно использовать
else условия.Возвращайте пораньше из рекурсивных функций
Рекурсивные функции также должны прерываться как можно ранее.
function reverse($string, $acc = '')
{
if (! $string) {
return $acc;
}
return reverse(substr($string, 1), $string[0] . $acc);
}Недостатки подхода «раннего возврата»
Возникает вопрос, а является ли описанный концепт панацеей? В чем же заключены недостатки?
Проблема 1. Стилистика кода – понятие субъективное
Мы, программисты, зачастую тратим больше времени на чтение кода, нежели его написание. Это довольно-таки известная правда. Таким образом, требуется написание как можно более простого и изящного кода, насколько возможно. Я настаиваю на следовании концепта «раннего возврата» именно потому, что основной механизм функции заключен именно в ее конце.
Вот только выбор стилистики кода подвержен субъективному мнению. Кому-то удобней единое использование оператора возврата, а кому-то нет. Выбор, в конечном итоге, остается за каждым программистом.

Если представить две абстрактные функции, какая из них будет казаться проще для чтения и понимания?
Проблема 2. Иногда «ранний возврат» — лишнее усложнение
Можно привести множество примеров, когда «ранний возврат» негативно влияет на конечный код. Типичным примером можно привести функции-сеттеры, в которых параметры зачастую отличаются от
false:public function setUrl($url)
{
if (! $url) {
return;
}
$this->url = $url;
}Это не самое значительное улучшение читабельности кода. Ситуативность использования подхода остается заботой самого программиста, ведь, используя стандартный подход, можно добиться лучшего результата:
public function setUrl($url)
{
if ($url) {
$this->url = $url;
}
}Проблема 3. Все это выглядит как оператор break
Так как в функции может быть расположено большое количество операторов
return, не всегда удобно понять, откуда был получен результат. Но до тех пор, пока вы используете данный подход для завершения некорректных состояний функции, все будет в порядке. Ах, да, пишете ли вы тесты?Проблема 4. Иногда лучше использовать одну переменную вместо множества return операторов
Существуют структуры кода, в которых подход «раннего возврата» ничего не изменяет. Только взгляните на следующие примеры кода:
function nextState($currentState, $neighbours)
{
$nextState = 0;
if ($currentState === 0 && $neighbours === 3) {
$nextState = 1;
} elseif ($currentState === 1 && $neighbours >= 2 && $neighbours <= 3) {
$nextState = 1;
}
return $nextState;
}Эта же функция с вышеуказанным концептом выглядит так:
function nextState($currentState, $neighbours)
{
if ($currentState === 0 && $neighbours === 3) {
return 1;
}
if ($currentState === 1 && $neighbours >= 2 && $neighbours <= 3) {
return 1;
}
return 0;
}Очевидно, что больших преимуществ у второго примера над первым нет.
Заключение
То, как каждый из программистов пишет свой код, зачастую зависит от привычек и традиций. Невозможно определить, что лучше, а что хуже, когда финальный исход является таким же. Как говорится, в программировании многие вещи субъективны.
Концепт «раннего возврата» вводит некоторые правила, необязательные для исполнения в 100% случаев, но которые зачастую помогают делать код чище и читабельней. Очень важно сохранять дисциплину при написании кода, ведь следование единой стилистике кода важней, чем ее выбор.
Лично я использую метод «раннего возврата» настолько часто, насколько возможно, особенно когда неотложное завершение функций с некорректными состояниями улучшает эстетику кода. Я привык, что успешное завершение всегда находится в конце функций, ведь недаром одна из мантр гласит:
Следуйте пути к успеху и реагируйте в случае ошибок.
Оригинал статьи
Заметка: переводчик оставляет за собой право стилистически менять фразы из источника.
Комментарии (131)

XopHeT
01.02.2018 13:53Код ниже
if Ошибка1 {
// Обработка ошибки 1
result = 1;
} elsif Ошибка2 {
// Обработка ошибки 2
result = 2;
} elsif Ошибка3 {
// Обработка ошибки 3
result = 3;
} else {
// Все ок, работаем дальше.
result = 4;
}
return result;
лишен недостатков 1, 3 и соответствует идее, переданной в статье.
Личное мнение по недостатку 4 — ВСЕГДА лучше использовать промежуточную переменную вместо множества RETURN операторов.
В некоторых ЯП для этих целей даже неявно переменная объявляется.
PaulMaly
01.02.2018 14:11Ага, проблема только в том, что проверочные условия могут выходить за рамки одной иерархии if-else. А также в том случае, когда возвращаемый результат не единообразен, как в случае с контроллером из статьи.

Neikist
01.02.2018 14:14Если выходят за рамки одного уровня иерархии возможно стоит рассмотреть возможность вынести в отдельные функции?
PaulMaly
01.02.2018 15:23Вы проверку каждого входного параметра будете в отдельную функцию выносить или что?
Neikist
01.02.2018 15:36Если у вас вложенные иерархии if-else — то это уже явно не проверка одного параметра, а проверка каких то комбинаций условий. Которые лучше в отдельные функции вынести для снижения цикломатической сложности конкретной функции, имхо.

t1gor
01.02.2018 14:20как в случае с контроллером из статьи.
Мне кажется пример с контроллером вообще не очень удачен в современном мире. Все, что в нем происходит можно "разбить" на более мелкие части и вынести в дргуие метса. Мне, например, очень нравиться как это реализовано в Laravel — валидация происходит вне контроллера, равно как и обработка ее ошибок и ACL.

dom1n1k
01.02.2018 14:40+2И чем же это хорошо? Оператор return сразу однозначно дает понять, что обработка этой ветви завершена. Присваивание result оставляет туман неизвестности — а что если дальше с этим результатом будет что-то происходить? Получается что-то типа switch с неполным набором брейков — иногда это может быть полезно, но в общем случае практика плохая.
XopHeT
01.02.2018 14:47Return может затеряться (визуально) в куче кода и человек, который сопровождает код будет искренне удивлен, почему выполнение не доходит до конца метода (функции).
Чтобы все-таки понять почему — ему придется заходить в отладчике во все if'ы и проверять «а не в этом ли условии программа выходит на уровень вверх?».
В случае с if-elsif-elsif-else достаточно поставить точку останова на 1м if-e и увидеть куда зайдет программа в процессе выполнения.
Cerberuser
01.02.2018 17:35Честно говоря, не очень понял аргумент с точкой останова. Ясно же, что и в случае с return-ами вариант «встать на первое условие внутри функции и проследить выполнение до момента выхода» тоже сработает. А если функция такая громоздкая, что проходить её пошагово сначала — нерациональная трата времени, так и в случае с цепочкой elseif-ов результат будет ровно такой же (не говоря уж о вопросе, рационально ли её делать в этом случае одной функцией).
XopHeT
01.02.2018 14:52Т.е. if-elsif-elsif-else сразу дает человеку понять, что есть ситуации, когда не весь код выполнится.
А глядя на конструкции
if Условие1 {
return;
}
if Условие2 {
return;
}
if Условие3 {
return;
}
// все ок, работаем.
создается ложное впечатление, что строка «все ок, работаем» выполняется всегда.Cerberuser
01.02.2018 18:32… которое, опять же, разбивается за один проход отладчика. Который нужен, по Вашим же собственным словам, и в первом случае, если по каким-то причинам оказалось неясно, какая именно из веток в данных условиях отрабатывает. Я не спорю с тезисом (что код с if-elseif выглядит читабельнее), я пытаюсь понять обоснованность аргумента.
XopHeT
01.02.2018 18:46В данном случае, может быть, выглядит не убедительно т.к. внутри каждого условия просто стоит return.
Выше писали, что внутри этого условия могут быть еще условия.
Во вложенных условиях еще условия.
Тогда чтобы понять тут ли выходит программа мне нужно по всей этой лесенке пройтись. Потом по следующей лесенке. Потом по третьей по счету.
Да, можно вынести лесенку в отдельный метод.
И вариант оформления if-elseif с единственным return в конце принуждает это делать.
Иначе не написать так, чтобы вложенных условий не было.
Durimar123
02.02.2018 14:34Добавь в начале
bool ok = true;
а после всех проверок
if (ok)
{
}
Иногда так даже удобней, но обычно можно и проще
// If vse Ok
{
}

wsf
01.02.2018 14:38Даже с таким подходом корректная логика и некорректная начинают смешиваться. По моему, по возможности, проще валидации выделять в отдельные функции, а после всех проверок исполнять уже непосредственно основную логику.
boblenin
02.02.2018 21:37Выделять в отдельные функции стоит если эти проверки делаются более одного раза.
morsic
01.02.2018 15:144 пример
Очевидное преимущество второго способа — не надо поднимать глаза и искать что за там $nextState объявлен, код четко разбит на 3 случая, читать проще будет.
Sinatr
01.02.2018 15:21+6Не знал, что Капитана Очевидность зовут Szymon Krajewski.
Неужели для кого-то это что-то новое? Удивляет, что такую мелочь можно раздуть до размеров статьи, которую начинают переводить и репостить.
Кстати, ни слова про декларативный, императивный, контрактный и т.д. подходы, когда часть таких проверок вообще выносится из тела метода.Daniyar94
01.02.2018 17:03Хотя эти вещи кажутся очевидными, в реальном мире, я не раз сталкивался с таким вот if/else hellом. А иногда и вообще без какой либо валидации.

smple
01.02.2018 15:47-1если честно подобный подход считаю очевидным, пришел к следующему правилам для себя:
- Только один return (не считая исключений), можно использовать переменную.
- return это последняя строка
- Исключения только для исключительных ситуаций.
- Не более одного уровня отступов, не считая отступов функции => рефакторить в приватный метод.
все остальное это следствие из этих правил.
MikailBag
01.02.2018 17:21Не более одного уровня отступов, не считая отступов функции => рефакторить в приватный метод.
И как алгоритм Флойда должен выглядеть?))
smple
01.02.2018 18:31-1так как php используется в вебе то такое решение вполне сойдет
<?php class Floid { private $w; public function __construct(array $w, int $n) { // если нужно проверяем данные $this->w = $w; $this->n = $n; } public function getResult() { for ($k = 1; $k <= $this->n; $k++) { $this->forByI($k); } return $this->w; } private function forByI($k) { for ($i = 1; $i <= $this->n; $i++) { $this->calc($k, $i); } } private function calc($k, $i) { for ($j = 1; $j <= $this->n; $j++) { $this->w[$i][$j] = min( $this->w[$i][$j], $this->w[$i][$k] + $this->w[$k][$j] ); } } }
если мы будем говорить об оптимизации производительности, потребление памяти, скорости и тд первое что стоит начать делать это взять компилируемый язык чтобы не терять время интерпретации, причем я ничего против пхп не имею в свое нише он дает достаточную производительность.
ах да по поводу отсутуов внутри min забыл упомянуть что такое в функциях можно делать но в меру, могу убрать но не вижу смысла зачем от этого избавляться
MikailBag
01.02.2018 18:48+2Вам не кажется, что исходный вариант (4 строки) выглядит проще?
Ну т.е. понятно, что можно разбивать код до уровня "любая инструкция в отдельной ф-ции", а в С++ это еще и работать быстро будет. Но по-моему не имеет смысл резать на отдельные функции что-то цельное, например алгоритмы.smple
01.02.2018 19:38исходный вариант 4 строки которые в примере это на самом деле, + 1 строка на функцию + 2 строки на скобки этой функции(в psr открывающая с новой строки) + 1 строка закрывающая скобка для каждого цикла (итого 3) + 1 строка на return
итого получаем 4 полезных строки размазанные по еще 7 строкам получаем 11 входных строк.
но даже учитывая 11 строк можно считать что он выглядит не сложно, но это не значит что так как я написал делать нельзя.
Но работа программиста это не писать максимально короткие программы, а писать софт который потом можно поддерживать потому что имея 11 строк я могу довольно много чего придумать так чтобы потом это было читать и понимать тяжело, поэтому мы не строками меримся, а пишем софт который потом поддерживать и большая часть времени читать.
Для примера цитата про "алгоритм установки gentoo" http://bash.im/quote/394695 если вам нравиться подобное в коде, то у всех свои вкусы и каждый вправе иметь свои взгляды.
по поводу разбивать на части то что цельное, вы когда запрос к бд посылаете вы ручками создаете сокет, подключаетесь к бд и посылаете запрос или все таки разделяете на уровень по работе с бд и потому что генерирует запросы?
ото алгоритм работы с бд можно назвать и это:
- Создать подключение
- Аутедентификация + авторизация
- выбрать бд
- цикл по запросам для бд
как бы тоже 4 строки, не надо все под одну гребенку нести.
а то что я разбил исходный текст на 3 метода это потому что у алгоритма 3 уровня отступов
VolCh
01.02.2018 20:18При использовании готовых алгоритмов при таком подходе есть шанс усложнить поддержку. В одной функции алгоритм может быть узнаваем, а при разбитии на части — нет.
smple
01.02.2018 21:06давайте я возьму очень популярный алгоритм которым большинство присутствующих пользуется и не задумывается (реализацию специально на пыхе найду) https://github.com/phpseclib/phpseclib/blob/master/phpseclib/Crypt/RSA.php
вот сразу как открываешь подобный файл и видишь родные $i, $j, $n прям сразу ясно становиться что за алгоритм
прям каждый день сниться когда все это в одной функции будет не разделено на вспомогательные вещи, прям сразу ясно что это RSA, а не DSA
теперь запишите его как вы говорили все в одну функцию, да да да decrypt, encrypt, sign, verify, createkey пусть там на входе массив будет и сказан тип операции что надо сделать и разные ключи с параметрами
я вам даже начну
<?php function rsa(array $params) { return ;/* тут надо его просто расчитать в зависимости от параметров и да я специально все в одну строку пишу, чтобы строки сэкономить это же так важно */}
и теперь ответьте честно будет выглядеть проще?
есть GodObject, но похоже можно еще создавать GodFunction или GodMethod, не знал о последних двух, спасибо что помогли их понять еще раз.
VolCh
02.02.2018 15:37Ну, если я буду писать алгоритм RSA по описанию, то, скорее всего, выделю так как выделено в оригинальном описании, чтобы тот, кто знает это описание сразу его определил.
P.S. А экономия строк тут непричём, дело в разрыве знакомого многим процесса на выбранные из моей головы куски с придуманными мною названиями.
smple
04.02.2018 00:26-1только что вот считать оригинальным описанием?
то что написано в rfc? RFC 2313, RFC 2437, RFC 3447 в каком именно?
или первая его оригинальная публикация в научных журналах ?
только вот в этих документах нет ничего конкретного по реализации (кроме математических формул) потому что парадигм программирования очень много:
- Императивное программирование
1.1. ООП
1.2. Процедурное и тд - Декларативное программироваине
2.1. Функциональное и тд
Вы будете искать rfc описывающее rsa в рамках ООП или ФП? таких нет, потому что rfc это описание и оно не привязано к реализации (парадигме или языку программирования), а как вы будете делать реализацию и в рамках какой парадигмы, зависит от вас и возможно от языка программирования что будете использовать (глупо например используя java писать в фп парадигме или использовать haskell и писать в ооп)
Даже если вы выберете ООП то тут есть еще куча вопрос:
- mutable или immutable ?
- stateless или statefull ?
То о чем вы говорите (о разрыве знакомого многим и лишними абстракциями) называется "связанность", что код должен отражать предметную область с которой он работает.
Только вот проблема в том что на вики выложен пример реализации в виде псевдо кода или какой нибудь наиболее наглядный пример на популярном языке, например в ФП не принято использовать циклы и вместо циклов бы тут использовали array map и реализация была бы совсем другой (в вики нет примера алгоритма флойда в рамках ФП).
Поэтому я согласен с тем что код должен быть сильно связан с предметной областью с которой он работает, но я не согласен с тем что есть одна и только одна каноническая реализация алгоритма, как минимум один и тот же алгоритм может выглядеть по разному в разных парадигмах программирования, также могут применяться разные оптимизации для повышения производительности и тд,
VolCh
05.02.2018 09:32Я не силён в данной предметной области, чтобы аргументированно ответить на большинство ваших вопросов. Но в целом и не утверждаю, что есть одна и только одна каноническая реализация алгоритма. С другой стороны, чем меньше разбираешься в предметной области, тем меньше надо вносить отсебятины, особенно в такой области как криптография, где даже лишние вызовы функций могут быть использованы в качестве информации для взлома.
- Императивное программирование
smple
01.02.2018 21:29а как по вашему должен выглядеть алгоритм rsa со всеми основными вещами (decrypt, encrypt, sign, verify, createkey причем не разбивая на отдельные функции)
а также работу с BigInt тоже не выносить отдельно это же цельное, там ниже задал вопрос, но не вам к сожалению, поэтому и тут продублировал, а и еще постарайтесь сделать поменьше строк, "это очень важно".michael_vostrikov
02.02.2018 17:09Вы путаете выделение отдельных действий и разбивание одного цельного действия на части. Изображение вам наверно проще целиком смотреть, чем по отдельному пикселю прокручивать.
smple
03.02.2018 23:35так вопрос разделения действий очень относительный.
вот например взять тот же алгоритм флойда и пхп, там есть операция +, если я выйду за пределы int во время этой операции?
Для работы с большими числами есть bc math или gmp, но это же алгоритм флойда надо ли их использовать, мне кажется да (если можно за пределы int уйти) но вы говорите что алгоритм флойда это то неделимое и надо смотреть на всю картину в целом, давайте тогда и работу с большими числами реализуем внутри циклов, как тогда будет выглядеть алгоритм без вспомогательных функций (методов) для работы с большими числами ?
по поводу изображений пример не корректен, если было так как вы говорите то в редакторах не было бы zoom (ведь удобней смотреть на все изображение без приближений вы так написали), поэтому пример с изображениями как раз и говорит что иногда один элемент (изображение) состоит из множества разных элементов (пикселей и векторов, ведь внезапно бывает еще и векторная графика), но мы не задумываемся о этих деталях когда смотрим на изображение пока нет в этом необходимости.
к сожалению я так и не вижу реализацию rsa от вас
michael_vostrikov
04.02.2018 00:47Сложение двух больших чисел — это одно отдельное действие. Если два вложенных цикла по одному массиву нужны для получения результата и без любого из них промежуточный результат не существует или не имеет смысла — это тоже одно отдельное действие.
Отдельные действия можно вынести в функции и использовать во многих других действиях, причем основываясь на интерфейсе и описании смысла результата. Части действий, вынесенные в функции, без знакомства с реализацией использовать нельзя.
не было бы zoom (ведь удобней смотреть на все изображение без приближений вы так написали)
Нет, я не писал, что приближения не нужны. Я писал, что в режиме большого приближения изображение целиком сложно воспринять. Так же как и воспринять реализацию алгоритма, наблюдая зависящие друг от друга куски реализации по отдельности на одном уровне.
к сожалению я так и не вижу реализацию rsa от вас
Реализация, разбитая на независимые отдельные действия меня устраивает. И писали про нее вы не мне.
И да, не вижу ни одной причины из обсуждения в этой ветке, почему кто-то должен всё объединять в одну функцию, так же как и почему кто-то должен разбивать логику на миллион функций, причем руководствуясь числом отступов, а не результатом анализа этой логики.smple
04.02.2018 01:19Я писал, что в режиме большого приближения изображение целиком сложно воспринять.
Понятие приближения зависит от изображения и от того что вы хотите увидеть, но обратите внимание вы сами начали говорить о
не имеет смысл резать на отдельные функции что-то цельное, например алгоритмы
Вы сами начали говорить о приватных методах, вместо того чтобы смотреть на картину, вы начали упоминать о пикселях из которых она состоит (приватных методов).
И я вам показал пример алгоритма где имеет смысл делить на отдельные методы, это rsa.
И да, не вижу ни одной причины из обсуждения в этой ветке, почему кто-то должен всё объединять в одну функцию
Вот я это уже цитировал выше повторю "не имеет смысл резать на отдельные функции что-то цельное, например алгоритмы"
теперь по поводу работы с большими числами это тоже алгоритмы, а значит исходя из ваших же слов не имеет смысла резать на отдельные функции, да алгоритм сложения больших чисел один, но есть куча алгоритмов умножения например.
michael_vostrikov
04.02.2018 09:32и от того что вы хотите увидеть
Правильно. В данном случае речь о том, чтобы увидеть алгоритм целиком.
Вы сами начали говорить о приватных методах, вместо того чтобы смотреть на картину, вы начали упоминать о пикселях из которых она состоит (приватных методов).
Во-первых, это не я говорил.
Во-вторых, о том и речь, что нет места, где есть картина, есть только куча отдельных пикселей. В вашем примере нет места с двумя вложенными циклами, зато есть 3 места с одним циклом. Причем у одного из них название завязано на реализацию. А если мы for на foreach поменяем, или на map?
И я вам показал пример алгоритма где имеет смысл делить на отдельные методы, это rsa.
В этой ветке никто не говорил что делить на методы вообще не надо.
Вот я это уже цитировал выше повторю
В таком случае и я повторю: вы общались с другим человеком, обратите внимание на ники.
а значит исходя из ваших же слов не имеет смысла резать на отдельные функции
Исходя из моих слов (а именно "Отдельные действия можно вынести в функции и использовать во многих других действиях") это никак не следует. Потому что написано прямо противоположное. Сложение можно вынести в функцию и использовать в умножении. Отдельные независимые части, из которых состоит сложение тоже можно вынести в функции и использовать в сложении.
Вы подменяете понятия. Речь идет не о том, разбивать на функции или нет. Разбивать надо, это и так все знают. Речь о том, насколько подробно разбивать, и по каким границам. Если кто-то говорит, что не надо разбивать по отступам, это никак не означает, что разбивать не надо вообще. Потому что есть больше двух возможных вариантов.
MikailBag
02.02.2018 17:17Мой тезис — сложность восприятия кода нелинейно зависит от кол-ва функций. Например, в случае с алгоритмом Флойда, знающему его человеку ориентироваться будет проще, чем в длинном. Естественно это не значит, что все алгоритмы должны быть реализованы в одной функции.
smple
04.02.2018 00:43Сложность зависит только от кол-ва функций? complexity(functionCount) или есть еще другие параметры ?
Например, в случае с алгоритмом Флойда, знающему его человеку ориентироваться будет проще, чем в длинном.
каким образом знание или незнание алгоритма зависит от его длинны? если я перепишу алгоритм флойда в одну строку вам будет проще в нем ориентироваться и он станет вам более знакомым?
кто вам сказал что псевдо код выложенный на сайте вики это единственная реализация?
вы слышали о различных парадигмах программирования и что в рамках этих парадигм также может применяться алгоритмы и иметь разные реализации которые визуально будут не очень похожи друг на друга, но при этом возвращать одинаковые результаты.
попробуйте реализовать алгоритм флойда в рамках фп и посмотрите понадобится ли вам вспомогательные функции (в том числе и анонимные).
labone
01.02.2018 16:30Рад, что появляются такие статьи. Часто чиню чужие вермишели с помощью переписывания на ранний возврат.
Для меня главное, что значительно повышается скорость сопровождения кода, и сразу видны проблемы в чужой логике, которые люди не учли, когда вкладывали ифы.
При правильной органиизации кода return не теряется, наоборот, обработчики ошибок сразу видны в том месте где она происходит, а не после основного рабочего кода.
Igor_Shumilov
01.02.2018 16:37Хм. Всегда так писал. Всегда это казалось очевидным. Сначала проверить входные данные, а только потом их обрабатывать.
Не верить же на слово тому, кто вызывает функцию.DaylightIsBurning
02.02.2018 17:19проверки стоят тактов процессора/памяти.
Igor_Shumilov
02.02.2018 17:26Некорректные данные на входе функции стоят часов отладки.
DaylightIsBurning
02.02.2018 19:17assert()

AllexIn
04.02.2018 11:16Ассерт на тестах помогает. А в продакшене нет. И почему-то именно в продакшене не корректные данные и приплывают в самых неожиданных местах.
VolCh
01.02.2018 16:56Во втором варианте контроллера уже намечается ситуация, из-за которой я иногда избегаю ранних возвратов — сложная логика в той же ветви, что и возврат. Тут ещё относительно легко сделать что-то вроде this->createWrongResponseWithFlash($mesaage) один раз и юзать его при фейлах. Если же логика разная, то часто не хватает условного return, типа return? value; которая возвращает если value приводится к fa
VolCh
01.02.2018 16:58возвращает value, если приводится к fslse и игнорится, если к true. На C можно макрос написать, ав других есть языках подобное или я хочу чего-то странного?

RomanVPro
01.02.2018 17:38-2Рекомендую прочитать книгу «Elegant Objects» Егора Бугаенко — там приведен прекрасный пример отделения валидации от бизнес-логики. Если вкратце, то вот как это выглядит.
Необходимо выделить интерфейс из вашего класса (который в текущей версии содержит и валидацию, и бизнес-логику).
У интерфейса следует сделать две реализации: первая реализует бизнес-логику без какой-либо валидации входных параметров, вторая — содержит всю необходимую валидацию входных параметров. При этом вторая реализация инкапсулирует экземпляр исходного интерфейса.
После всех манипуляций вы можете использовать либо экземпляр первой реализации — при этом у вас не будет валидации (иногда бывает необходимо для тестов) — или же можете завернуть этот экземпляр в инстанс второй реализации — в этом случае добавляется валидация.
В общем, используйте декораторы :)timazhum Автор
01.02.2018 17:44Звучит, конечно, круто. К сожалению, не всегда удобно. В том же Perl сей подход вызовет больше сложностей в связи с корявостью ООП
Pilat
02.02.2018 00:20Вот именно в Perl такой подход проблем не вызовет из-за нормальной реализации ООП. Другой вопрос, что на валидации входных параметров свет клином не сошёлся.
boblenin
02.02.2018 21:42Видел такое доведенное до идиотизма. Все из себя представляет комманды, вызывающие другие комманды (Command Pattern) и так 5 уровней вложенности для того, чтобы сделать выборку по ID из базы данных.

anonim007
01.02.2018 17:45+1Используем одну переменную и один return. И потом надеемся, что компилятор скомпилирует так, что не заставит программу пробегать по всей цепочке условий, а выполнит безусловный переход на return… иначе пользователь бежит и покупает новый процессор т.к. этот тормозить чего-то начал :)
XopHeT
01.02.2018 18:22А есть сведения о компиляторах, которые заставят проверять все ветки условия if-elsif-elsif-elsif-else если первое условие истинно?

a-tk
02.02.2018 13:47В Паскале это была неявная переменная Result, а вместо возврата — псевдофункция Exit.
Не сказал бы, что писать в таком стиле доставляло удовольствие.
Mabu
01.02.2018 19:14Если на вход функции данные поступают чаще правильные, чем неправильные, то в инструкциях для процессора эта концепция выглядит так.
Проверить условие > прыгнуть дальше > проверить условие > прыгнуть дальше > проверить условие > прыгнуть на выполнение полезного действия.
Вложенные условия избавляют от прыжков, теперь цепочка инструкций будет: проверить условие > проверить условие > проверить условие > выполнить полезное действие.
Что лучше: одноуровневые условия и лишние прыжки или вложенные условия и отсутствие прыжков? Умеет ли компилятор оптимизировать лишние прыжки?VolCh
01.02.2018 20:20Даже если не умеет (особенно если речь об интерпретаторе, а не компиляторе), то по умолчанию приоритет у читаемости кода, а не у скорости его работы или потребляемой памяти.

ZakharS
02.02.2018 09:09Сейчас не найду точных цифр, но, помнится, что ошибочная ветка в if вместо else добавляет пару десятков тактов из-за предсказания ветвлений. Процессор идет по ветке обработки ошибки и потом, когда оказывается, что данные верны, вынужден откатиться назад. Хотя, когда все поставят патчи для Meltdown, эта проблема перестанет быть актуальной :)

16tomatotonns
01.02.2018 20:24Низкая вложенность — это очень удобно. Только желательно логировать выходы из функций, в таком случае будет понятно где обрубается, по типу такого:


xFFFF
01.02.2018 21:40Давно пишу в таком стиле. Как-то сам пришел к нему.
Jumper_In
02.02.2018 13:22Вот в первые полгода работы, пока набирался опыта, писал в духе if else, потом это перестало нравиться, стал делать ранние выходы, аргументируя себе это тем, что функция раньше закончится, а, следовательно, выполнение программы быстрее выйдет.
А сейчас больше претензий к читаемости, конечно, для ранних выходов чётко видно, когда и что произойдёт этапами. Хотя где-то встречалось мнение, что для некоторых программ или приложений должен быть строго 1 оператор return, поэтому сомнения иногда закрадываются.boblenin
02.02.2018 21:45Вот мнение это встречалось, но непонятно на чем основано. Может быть какая-то оптимизация для компиляторов времен DOS. Или что-нибудь связанное с функциональщиной и доказуемостью алгоритма. Помню только, что что-то древнее.

F0iL
02.02.2018 06:56Звучит разумно и выглядит красиво, но, к примеру, в стандарте написания высоконадежного кода MISRA C (используемого, к примеру, при разработке встраиваемого ПО для автомобилей) прямым текстом сказано:
Rule 14.7 :(required) «A function shall have a single point of exit at the end of the function».
Аналогичные пункты есть и в других подобных стандартах.
TimsTims
02.02.2018 10:17Стандарты пишут люди. Люди могут ошибаться.
F0iL
02.02.2018 10:33Стандарты пишут люди далеко не глупые и с экспертизой в своей сфере, основываясь на логике и реальном опыте. Иными словами, если что-то написано, то скорее всего не просто так.
А ещё стандарты развиваются, исправляются и дополняются. Иными словами, если какой-то пункт стандарта пережил уже множество редакций (учитывая, что его отмена никак не влияет на обратную совместимость), то он там тем более не просто так :)TimsTims
02.02.2018 14:16А ещё стандарты развиваются, исправляются и дополняются
Именно это я и хотел сказать. То, что это стандарт, и «так принято», еще не означает, что больше не существует других более выгодных вариантов написания кода.
boblenin
02.02.2018 21:47Неглупые люди приняли рекоммендации по валидации паролей. Все эти перемешивания заглавных и строчных букв, цифр и спецсимволов.
F0iL
02.02.2018 23:42Стандарт генерации паролей и стандарт написания кода, от корректности которого зависят жизни сотни людей — это какбэ немного разные вещи.
Плюс я именно об этом говорил в предыдущем комментарии, те же NIST'овские рекомендации про пароли перевыпустили, а в стандартах написания высоконадежного кода обсуждаемый тезис используется уже не один десяток лет и пережил множество переизданий в разных формах, и ничего, самолёты не падают, АЭС не взрываются.boblenin
03.02.2018 17:33Вообще-то от програмных ошибок и ракеты взрывались. Но вот теперь уже — машины врезаются.
И те же АЭС взрываются и самолеты падают — хотя у меня нет статистики по тому, какая часть из проблем связана с плохим кодом.
Мне ваша аргументация кажется очень слабой.F0iL
04.02.2018 00:03Я вообще немного не о том.
В авиации есть такое расхожее выражение: «правила безопасности пишутся кровью».
Как минимум, при разработке стандартов, при добавлении тезисов или выборе из альтернативных сущностей, выводы делаются не только на голой теории, но и с учетом анализа обнаруженных дефектов в уже существующих и существовавших изделиях и процессах, с учетом последствий, к которым они привели. Это к тому, что если что-то написано, то оно написано не «с потолка».
Касательно «пережил много изданий» и «самолеты не падают, АЭС не взрываются». Когда появляются какие-то новые данные или доводы, или происходит какой-то случай, который оказывается не покрытым правилами или же доказывает их ошибочность, стандарты оперативно обновляются и перевыпускаются. Иными словами, касательно конкретно обсуждаемого пункта, если пункт по прежнему присутствует в списке правил, значит за десятки лет не нашлось ни одного события или существенного аргумента, обоснованно говорящих о его некорректности.boblenin
04.02.2018 02:29> выводы делаются не только на голой теории, но и с учетом анализа
> обнаруженных дефектов в уже существующих и существовавших изделиях
Вы уверенны, что это имеет отношение к статье?
> Это к тому, что если что-то написано, то оно написано не «с потолка».
Мой пример с паролями — опровергает ваше утверждение.
> стандарты оперативно обновляются и перевыпускаются.
Вы в общем может быть правы, если исключить «оперативно».
> значит за десятки лет не нашлось ни одного события или существенного
> аргумента, обоснованно говорящих о его некорректности.
Утверждение никак не связано логически с тем, что вы написали до него. И в целом ложно.F0iL
04.02.2018 11:46Вы уверенны, что это имеет отношение к статье?
А что конкретно вас смущает?
В статье предлагается идея, противоречащая утвержденной и выверенной практике в отраслях, критичных к безопасности и корректности ПО.
Если вам не нравится терминология, то можете учесть, что «софт» является неотъемлемой частью «изделия», а термин «дефекты в ПО» так вообще довольно распротраненный с сфере безопасности и оценки качества программ.
Мой пример с паролями — опровергает ваше утверждение.
Я специально выше отметил, что это совершенно разные сферы с совершенно разными методами. Вероятность катастрофы с человеческими жертвами из-за слабого пароля на много порядков меньше чем из-за ошибки в программе управления двигателями авиалайнера. Следовательно, отличаются и сами процессы подготовки документов и требования к ним.
Тот же NIST'овский стандарт писался даже не комитетом экспертов, а одним-единственным рядовым менеджером базируясь на голой теории (причем еще ошибочно примененной) без анализа известных «неудачных случаев». В авиации и энергетике такое в принципе невозможно. Поэтому как пример его приводить бессмысленно.
И самое главное: когда появились обоснованные доводы ошибочности его пунктов, стандарт все-таки пересмотрели и перевыпустили.
Вы в общем может быть правы, если исключить «оперативно».
Не скажу про атомную энергетику, но в авиации — весьма оперативно.
Утверждение никак не связано логически с тем, что вы написали до него. И в целом ложно.
Обоснуйте.
Есть два тезиса:
1. «При обнаружении реальных фактов о некорректности пунктов стандарта, в стандарт должны вноситься (и по факту вносятся) изменения и он перевыпускается».
2. «За несколько десятков лет существования стандарта и нескольких переизданий его, обсуждаемый пункт не был убран или изменен».
Вывод очевиден: «за все это время не нашлось ни одного события или аргумента, весомо и объективно говорящего о его неправильности».boblenin
05.02.2018 03:01> В статье предлагается идея, противоречащая утвержденной и
> выверенной практике в отраслях, критичных к безопасности и
> корректности ПО.
Это факт или мнение?
> Я специально выше отметил, что это совершенно разные сферы с
> совершенно разными методами.
Безопасность и безопасность — это разные сферы. А безопасность и кодирование — это одно и то же. Я правильно вас не понимаю?
> В авиации и энергетике такое в принципе невозможно.
Это факт или мнение?
> И самое главное: когда появились обоснованные доводы
> ошибочности его пунктов, стандарт все-таки пересмотрели и
> перевыпустили.
И более ошибочные рекоммендации не используются, я так понимаю?
> Вывод очевиден: «за все это время не нашлось ни одного события
> или аргумента, весомо и объективно говорящего о его
> неправильности».
Вывод очевиден. Формальную логику в школах отменили зря.VolCh
05.02.2018 09:54+1Безопасность и безопасность — это разные сферы.
Да )) Безопасность в области "постить котиков", личных и корпоративных финансов, медицины и АЭС — это разные безопасности, разная цена ошибки, следовательно разные ресурсы выделяются на их предотвращение.
Безопасность (в контексте безошибочности) и удобство обычно противоречат друг другу, и в отраслях, где цена ошибки относительно низка удобство побеждает. Вон, посмотрите в топике про malloc какие дебаты пошли из-за одного if, причём большинство (субъективно) склоняется к мнению, что можно доверять исторически сложившемуся поведению некоторых компиляторов и некоторых реализаций ОС с некоторыми настройками. Что какие-то частные случаи не стоят вставки if после каждого malloc для проверки на NULL, поскольку на подавляющем большинстве систем реальных пользователей проверка не гарантирует реального выделения памяти, а фактически сложившиеся традиции в реализации дадут аналогичный самой простой проверке результат. Что это неопределенное поведение, в любой момент могущее измениться, никого не парит.
F0iL
05.02.2018 12:27Это факт или мнение?
Факт.
Безопасность и безопасность — это разные сферы. А безопасность и кодирование — это одно и то же. Я правильно вас не понимаю?
В соседнем комменте уже совершенно ответили за меня, причем совершенно правильно ответили.
Это факт или мнение?
Факт.
И более ошибочные рекоммендации не используются, я так понимаю?
В целом верно. Зависит от конкретной ситуации. В некоторых случаях стандарт вступает в силу непосредственно в момент его опубликования, в некоторых случаях — для новых проектов и производных документов.
Вывод очевиден. Формальную логику в школах отменили зря.
То есть обосновать вы не можете. Понятно.

johnfound
02.02.2018 11:24А производительность??? Правильные данные случаются намного чаще, чем неправильные. А при этом подходе, код будет выполнятся медленней всего именно когда данные правильные.
То есть, вред конкретный и вещественный, а польза несколько виртуальная…
a-tk
02.02.2018 11:35Это точно не преждевременная оптимизация некритичных фрагментов кода?
johnfound
02.02.2018 11:45Нет, не думаю. Это преждевременная, сознательная пессимизация всего кода. А когда придет время оптимизировать (ведь, "преждевременно" не значит "никогда") такой код придется переписывать начисто.
Оптимизировать раньше срока, конечно плохо. Но надо писать optimization-friendly код.
Neikist
02.02.2018 11:51В 95% прикладных задач основной затык на I/O (ожидание выполнения запроса на СУБД, ответа какого нибудь http api, чтение/запись файлов и т.д.), а уж никак не там где вы пишете. Это важно на вычислительных задачах, сложных алгоритмах, в системном ПО.
johnfound
02.02.2018 12:00В 95% прикладных задач основной затык на I/O (ожидание выполнения запроса на СУБД, ответа какого нибудь http api, чтение/запись файлов и т.д.), а уж никак не там где вы пишете. Это важно на вычислительных задачах, сложных алгоритмах, в системном ПО.
Так это же религиозная мантра. Мой опыт говорит наоборот – если пишешь оптимальный код, то программы получаются быстрые. Если всегда думаешь "преждевременная оптимизация зло!", то получаются медленные монстры, которые только убить можно, но никак не исправить. :)
Вот статья, человек просто сделал код на 20000% (sic!) быстрее, просто думая о оптимальности кода, а не написанием оптимального код:
Neikist
02.02.2018 12:16От задач зависит все же. Например в моей области примерно 80-90% времени выполнения по данным профилировщика — как раз работа с базой (это при том что все естественно стараются запросы и их количество оптимизировать). Ну, конечно если совсем очевидных ляпов не допускать. Недавно мобильное приложение делал — тоже основной проблемой было оптимизировать загрузку по сети больших объемов данных.
johnfound
02.02.2018 12:29От задач зависит все же.
А кто спорит? Но если человек сознательно начинает писать суб-оптимальный код, то он его будет писать всегда. Те же запросы к БД можно и нужно оптимизировать. И скорость реально повышается в десятки раз. Я писал форум на ассемблере и SQLite. Все говорят что SQLite медленная. Но нет, оказывается что SQLite очень даже быстрая, просто готовит запросы правильно надо. И теперь у меня есть самый быстрый форум в мире, на "самой медленной" БД.
michael_vostrikov
02.02.2018 23:26Ага, только вы писали его месяц, хотя там работы на пару дней)
А поскольку ожидание ввода-вывода от языка не зависит, то на PHP тот же функционал будет работать ну может на несколько процентов медленнее.johnfound
03.02.2018 14:48Ага, только вы писали его месяц, хотя там работы на пару дней
Ну, ну, а разработчики например myBB, SMF или Flarum тоже так считают?
Neikist
03.02.2018 01:42Да, читал статью вашу, очень круто конечно, но для реальных задач бизнеса имеет мало смысла, имхо. Но например в моем случае вообще весь код процентов на 50 из запросов состоит. И запросы на 1к+ строк из за сложности бизнес логики, особенно в отчетах, но не только, вполне нормальное явление. И поверьте, за ту четверть секунды что выполняется такой запрос — выхода отработают даже на том языке что я пишу десятки тысяч раз. Понятно что не стоит пихать экспоненциальную сложность алгоритмов там где можно реализовать что то с линейной или другой низкой сложностью, но экономить на тактах в таких системах не приходится, все же гораздо важнее читабельность.

tema_sun
02.02.2018 11:54Точно. Буквально год-полтора назад на Хабре была статья, что лучше писать if-elif-else, чем if-if-if, именно по причине, что во втором случае все условия будут проверется всегда.
timazhum Автор
02.02.2018 13:24В данном случае оба подхода идентичны, так как после любого верного
ifидет возврат из функции (то, что после уже не проверяется)
boblenin
02.02.2018 21:48> Правильные данные случаются намного чаще, чем неправильные.
А не наоборот?VolCh
05.02.2018 10:00В целом именно правильные случаются чаще хоть в публичных, хоть в закрытых контурах, если ваша система не является целью постоянных атак хакеров, причём брутфорсных. Ну или ваша система сугубо одноразовая, пользователи пользуются ею один раз в жизни. При многократном использовании пользователи, пускай и с разной скоростью, но учатся вводить корректные данные для достижения своих целей. Причём корректные именно с точки зрения системы, а не документации на неё и(или) здравого смысла. Пускай на уровне "это невозможно понять, это нужно запомнить", но учатся.

Goodkat
02.02.2018 12:43Всегда так делаю, но просто потому что лень писать все эти вложенные if else if.
miooim
02.02.2018 13:25Я этот подход уже давно использую, и вот читая статью я подумал, ведь это пессимистичный подход. С точки зрения производительности этот код видимо хуже того который сразу переходит к решению задачи. Ведь если подумать, то пессимистичный подход нужен только во время написания кода, а потом после отладки когда все работает, весь этот проверочный хлам будет мешать работе программы и влиять на производительность.

vanxant
04.02.2018 01:26Да нет там пенальти по производительности. Проверку все равно делать, условный переход все равно делать. Зато компилятору удобнее оптимизировать при инлайнинге (если он видит, что в конкретном месте условия заведомо ложны, он может их спокойно выкинуть)
gt8one
02.02.2018 13:25Ещё можно через "… do {… } while (false);" сделать:
// setup int status = 0; do { // preconditions status = doSomething(); if (status) break; status = doSomethingElse(); if (status) break; // computation status = doWhatYouWantedToInTheFirstPlace(); } while (false); // cleanup return status;a-tk
02.02.2018 13:51Можно, но когда Вы увидите такой код в чужом проекте повсеместно, Вы вряд ли сильно обрадуетесь.

php7
02.02.2018 13:25Тут как с музыкой.
Кто-то может играть на гитаре только по написанным аккордам и написанному бою (типа вверх-вниз-глушим).
А кто-то может сам понять на слух, какой аккорд взять и как бить по струнам в конкретной песне.
5oclock
04.02.2018 00:08Только такой подход надо сочетать с принципом RAII.
А то со всеми этими return'ами можно ресурсы растерять.a-tk
04.02.2018 10:58Не во всех языках есть концепции, близкие к RAII, хотя где-то есть поддержка на уровне синтаксического сахара.
5oclock
04.02.2018 11:16Не во всех.
Но принцип «раннего возврата» — более-менее универсальный.
Потому там где есть RAII — нелишним будет ранний возврат сочетать с RAII.
А то будут всякие утечки памяти, незакрытые файлы и навечно заблокированные мьютексы.
Да и код самой функции с «ранним возвратом» будет более стройным.
А то по мере углубления в функцию — возвраты становятся всё более хлопотными:
на первом if — просто выход (ничего ещё не делали);
на втором if — перед выходом надо файл закрыть, который открыли после первого if;
на третьем if — перед выходом надо и файл закрыть и память освободить;
на четвертом if — всё то же самое, плюс не забыть освободить мьютекс
И т.д.
Можно конечно возразить, мол надо сначала проверить все условия, а потом делать работу, в т.ч. выделять и захватывать ресурсы.
Но, во-первых, не всегда это возможно. От алгоритма зависит.
А во-вторых, принцип «раннего возврата» — более универсален, чем просто «проверка условий перед тем как засучить рукава». Необходимость возврата может возникнуть уже «в глубине» функции, а не в «проверочном заголовке». И легко можно что-то забыть освободить/закрыть.a-tk
04.02.2018 17:48Если акцент на то, что если язык поддерживает RAII, то он очень полезен в связке с ранним возвратом — то я полностью согласен.
Но надо только понимать, когда сначала стоит проверить проверить предусловия, а потом уже выделять ресурсы и отдавать их под контроль Раи. Перемешивать проверку и выделение ресурсов может быть весьма неэффективным.VolCh
05.02.2018 10:02Вот, наверное, да, хороший принцип — ранний возврат в блоке проверки предусловий, а дальше уже вложенные проверки или try/catch/finally, когд аначинается реальная работа.
sgrey
04.02.2018 02:01Очень много сталкивался с таким кодом, как у студентов, так и у опытных программистов, где имеется вложеный в три-пять условий возврат или положительное выполнение, при этом вся функция представляет собой одно условие. Всегда предпочитаю такое переписывать и проверять на негативные варианты сначала. Во-первых таким образом уменьшается количество возможных ветвей исполнения. Во-вторых код намного удобнее читать и модифицировать. Стараюсь по возможности своих студентов учить такому же

amakhrov
04.02.2018 07:47Фаулер описал этот прием 20 лет назад в книге "Рефакторинг".
sgrey
04.02.2018 20:57Да вобщем-то довольно легко до него додуматься, даже без книг. Вобщем не удивительно что вещь известная и давняя
Neikist
Хм, могу ошибаться но дядюшка Боб как раз из за проблем 1 и 3 рекомендует делать только один возврат в конце.
Timmmm
Найдете ссылку на рекомендацию?
Neikist
Постараюсь вечером найти, если не забуду.
Neikist
Timmmm Хм, не нашел, хотя казалось бы точно читал. При этом у Макконела, книга которого мне как то больше понравилась, есть раздел «множественные возвраты и функции» в котором ранний выход при проверке условий как раз поощряется.
Timmmm
Спасибо, что не забыл.
«поощряется»? На мой взгляд это единственно верное выполнение функции. Все перечисленные проблемы, это же смех, притянуты за уши. Хочется добраться до реальных проблем, если таковые есть.
a-tk
Там всё хитро. Надеюсь, изложу близко к тому, что написано у Макконнелла, но, возможно, на моё изложение наложились и собственные деформации и опыт.
Тезис: функция должна соблюдать инварианты.
Сначала надо выполнить проверки входных данных и не приступать к работе, если они не соблюдены.
Дальше выполняется код, который должен иметь одну точку выхода.
Neikist
Да, я примерно так же этот раздел понял. Но все таки странно что у меня в памяти это в другом виде отложилось… Ведь и сам в основном писал сначала проверки с возвратом, далее основной код, и в конце еще один возврат.
DaylightIsBurning
А что делать, если проверка входных данных — дорогостоящая операция? Обычно такое бывает когда проверка входных данных делается где-то в вызывающем коде один раз, а не каждый раз при вызове «вложенной функции».
Пример:
Получается, что будет 2 лишних проверки, которые в реальном коде компилятор не сможет соптимизировать, если проверка не тривиальна.
MikailBag
Можно делать булевый параметр с значением по умолчанию — нужно ли делать дорогие проверки.
Если упороться в край, можно сделать его шаблонным. Тогда проверки будут вырезаны еще на этапе компиляции))
DaylightIsBurning
Это уже есть, называется assert, проблемы не решает.
MikailBag
А почему, кстати?
DaylightIsBurning
Потому, что всё равно бывает необходимо отлавливать ошибки в рантайме (в production) и отлавливать их на нижнем уровне вложенности (assert) — медленно, а на верхнем — ненадёжно (легко ошибиться, пропустив недопустимое значение параметра дальше по стеку вызова).
Assert — это только для дебага, когда скорость не важна.
Тут возникает идея Design by contract.