Искусственный интеллект (далее ИИ) всегда привлекал не только ученых-фантастов и писателей, но и обычных обывателей. Роботы, наделенные разумом, дразнят наше любопытство и настораживают наши первобытные страхи, становятся персонажами книг и кинолент. Однако ИИ может быть и неосязаемый, не наделенный оболочкой из металла или пластика. Совокупность программ и алгоритмов, способная самостоятельно принимать решения и изменять те или иные переменные для получения заданной цели — это тоже ИИ. В наше время, когда будущее по мнению многих фантастов уже настало, многие компании с огромным интересом и энтузиазмом смотрят в сторону использования искусственного интеллекта с целью модернизации процесса производства и предоставления товаров и услуг. Кто же, как не дата центры, должны стоять у истоков этого, возможно, революционного прорыва.

Одним из самых крупных, во многих пониманиях, фанатом ИИ является корпорация Google. Все мы знаем об автомобиле, который способен передвигаться по оживленной дороге без прямого участия человека, о приложениях для смартфонов, способных распознавать речь и коммуницировать с человеком, о поисковых сервисах, способных мгновенно распознавать цифровые изображения. Все эти фантастические вещи разрабатываются не только Google. Многие компании, такие как Facebook, Microsoft и IBM тоже не пасут задних. Это является ярким показателем их чрезвычайно большого интереса к внедрению ИИ в нашу с вами повседневную жизнь.

Google Car
Многие революционные проекты основаны на использовании ИИ в том или ином виде. Среди них авто Google, IBM Watson (суперкомпьютер, оборудованный вопросной-ответной системой ИИ). Это довольно громкие и публичные проекты. Однако не единственные, и далеко не самые главные. Большинство компаний уделяют значительно больше времени и ресурсов на развитие так называемой системы искусственного интеллекта «глубинное обучение».
 IBM Watson (суперкомпьютер, оборудованный вопросной-ответной системой ИИ)
IBM Watson (суперкомпьютер, оборудованный вопросной-ответной системой ИИ)
Именно эту систему Google и развивает в своих дата центрах. За всеми сервисами Google скрывается огромное множество данных, которые требуют обработки и анализа. Соответственно компания владеет своими огромными дата центрами, что вообщем то и не секрет. В настоящий момент в ЦОД-ах корпорации начали применять искусственные нейронные сети, задачей которых является анализ работы самого ЦОДа. В дальнейшем, полученные данные используются для улучшения работы структуры хранения и обработки данных. По сути эти нейронные сети представляют собой компьютерные алгоритмы, которые могут распознать паттерны и принять определенное решение, основываясь на полученных данных. Эта сеть не может сравниться с человеческим интеллектом, однако многие задачи она может выполнять значительно быстрее и эффективнее. Именно по этой причине Google применяет данные алгоритмы в работе своих дата центров, именно там, где скорость значит многое.
Творцом ИИ для ЦОДа Google стал молодой инженер Джим Гао (Jim Gao), которого многие из команды называют «юным гением». В свое время он прошел курс онлайн лекций профессора Стэндфордского университета Эндрю Ына (Andrew Ng). Профессор является ведущим специалистов в области изучения ИИ.

Профессор Ын
Джим Гао использовал свои «20% времени»* для изучения работы искусственных нейронных сетей и способов их применения в работе ЦОДов компании.
Каждые несколько секунд Google собирает огромное количество всевозможных данных: показатели потребляемой энергии, объемы использованной в системе охлаждения воды, температура снаружи ЦОДа и т.д. Джим Гао создал систему ИИ, которая бы собрала эту информацию, обрабатывала ее и предсказывала уровень эффективности работы дата центра. Спустя 12 месяцев модель была скорректирована, ввиду получения еще более новых данных. В результате точность предсказаний составила 99,6%.
Данная система ИИ является своего рода превентивной мерой во время решения той или иной проблемы. На данный момент ИИ занимается работой основных систем обеспечения ЦОДа (энергообеспечение, охлаждение и т.д.). К примеру, система ИИ может «предложить» замену теплообменника, что улучшит работу системы охлаждения. Пару месяцев назад ЦОДу пришлось отключить некоторое число серверов, что обычно влияет на энергоэффективность, однако благодаря ИИ Джима Гао, которая регулирует систему охлаждения, технические работы прошли спокойно, а уровень энергоэффективности оставался высоким в течении всего времени. ИИ, по словам представителей Google, может замечать те мелкие детали, которые не видны человеку, что и делает ее такой эффективной.
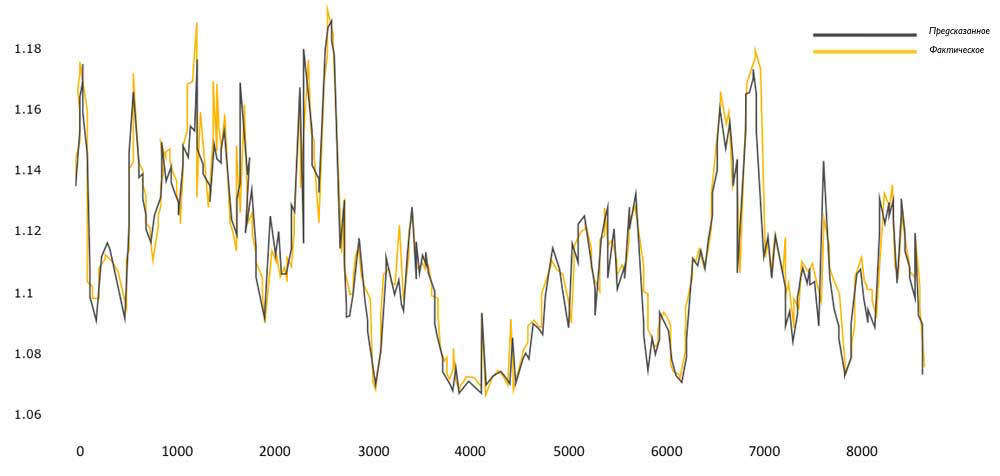
Данный график показывает соотношение предсказаний ИИ системы и фактических показателей PUE (Power usage effectiveness) эффективности энергопотребления
Конечно же, нас не может не радовать такой успех Google, однако все же интересно как работает эта система.
Прежде всего была поставлена задача в определении именно тех факторов, которые имеют самое большое влияние на уровень энергоэффективности (PUE). Джим Гао сократил список до 19 факторов (переменных). После была сформирована искусственная нейронная сеть. Эта система должна была анализировать (или обрабатывать, кому как удобнее) огромное количество данных и искать в них закономерности.
Сложность заключается в количестве, как это не забавно, всего. Точнее выражаясь, в количестве переменных. Количество оборудования, их комбинаций, соединений, факторов влияния, таких как погодные условия.
Более подробно эту проблему и методы ее решения в контексте использования ИИ в работе дата центра Джим Гао описывает в своей работе «машинное обучение в оптимизации центров обработки данных».
Вот, что говорит сам Джим Гао во вступительной части своей работы:
Реализация модели
Входная переменная x — (m x n) — массив данных, где m — количество обучающих примеров, а n — количество особенностей, к которым относится и IT нагрузка и погодные условия, число работающих куллеров и градирен, количество устанавливаемого оборудования и т.д.
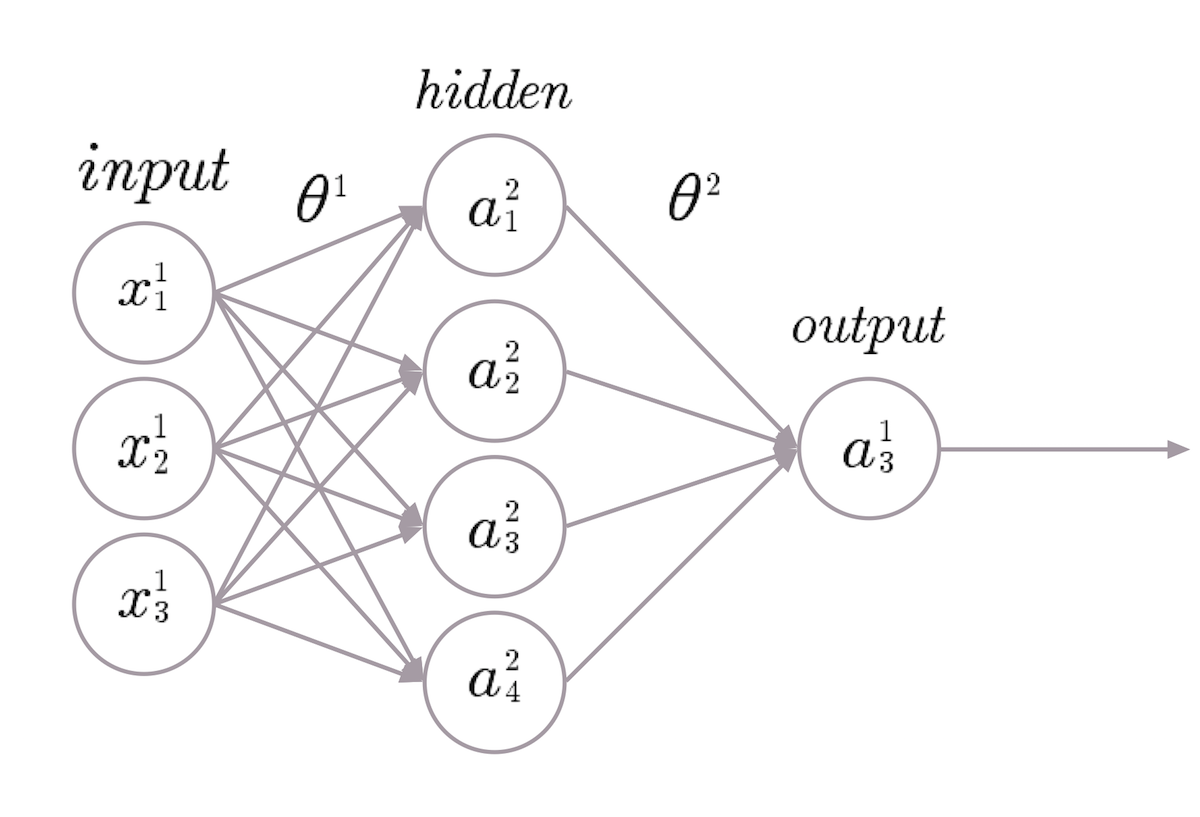
Обыкновенная трехслойная нейронная сеть
Входная матрица х умножается на параметры модели матрицы ?1 для получения скрытого состояния матрицы. На практике, а действует в качестве промежуточного участка, который взаимодействует со вторым параметром матрицы ?2 для вычисления исходных данных h?(x). Размер и количество скрытых слоев напрямую зависит от сложности моделируемой системы. При этом h?(x) представляет собой вариативность выходных данных, представленных в виде некоего диапазона показателей, которые и необходимо оптимизировать. Уровень энергоэффективности используется в формировании данной системы как показатель работоспособности ЦОДа. Диапазон показателей — коэффициент, не отображающий общего потребления энергии дата центром. Другие исходные данные включают в себя данные об утилизации серверов для максимализации продуктивности, или же данные о сбоях оборудования для понимания того, как инфраструктура ЦОДа влияет на его надежность. Нейронная сеть ищет взаимосвязь между различными данными показателей, дабы сформировать математическую модель, калькулирующую исходные данные h?(x). Понимая основные математические принципы h?(x), можно их контролировать и оптимизировать.
Несмотря на то, что линейная независимость показателей необязательна, ее использование значительно сокращает время обучения системы и снижает количество процессов переобучения. К тому же данная линейная система показателей упрощает модель ограничивая число вводных данных исключительно теми показателями, которые являются самыми фундаментальными для работы ЦОДа. К примеру температура в проемах системы охлаждения не является важным показателем для формирования уровня энергоэффективности, так как является следствием работы других систем (работы градирен, температуры водного конденсата и точки ввода охлажденной воды), показатели которых и есть фундаментальны.
Процесс обучения нейронной сети можно разделить на четыре основных этапа (+ пятый этап, повторяющий пункты 2-4):
1. Произвольная инициализация параметров (паттернов) модели;
2. Реализация алгоритма дальнейшего разветвления;
3. Вычисление функции затрат J(?);
4. Реализация алгоритма обратного разветвления;
5. Повторение пунктов 2, 3 и 4 для достижения максимальной конвергенции или же достижения необходимого числа попыток.
1. Произвольная инициализация
Произвольная инициализация — процесс произвольного назначения величины ? между [-1, 1] непосредственно перед началом обучения модели. Для понимания того зачем это необходимо, рассмотрим сценарий, где все параметры модели будут равны 0. Входящие данные в каждом последующие слое нейронной сети будут одинаковы, так как они умножаются на ? (равное 0). Кроме того эта ошибка будет распространяться и в обратном направлении, посредством скрытых слоев, что приведет к тому, что любые изменения параметров модели также будут абсолютно идентичны. Именно по этой причине значение ? произвольно варьируется в диапазоне [-1, 1], дабы избежать формирования дисбаланса.
2. Дальнейшее разветвление
Дальнейшее разветвление относится к процессу калькуляции каждого следующего слоя, так как значение каждого из них зависит от параметров модели и от слоев, предшествующих им. Исходные данные модели вычисляются путем алгоритма дальнейшего разветвления, где alj отображает активацию узла l в слое j, а ?l — матрица данных (параметры модели) преображающая слой l в слой l+1.
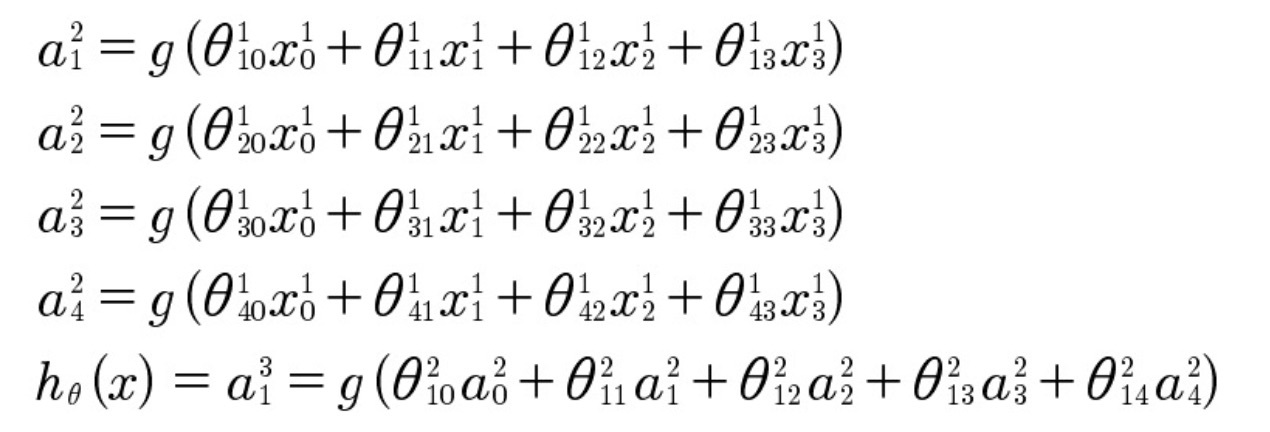
Базовые параметры (узлы со значением 1) прибавляются к каждому несходному слою для представления цифрового выражения в каждом слое.
В приведенных выше уравнениях ?110 редставляет собой значение между прибавленным базовым параметром x10 и элементом скрытого слоя a21.
Целью функции активации x(z) является имитирование работы биологических нейронных сетей, путем наложение входных данных на исходные в пределах диапазона (0, 1). Она задается сигмовидной логистической функцией g(z)=1/(1+e-z)
Следует отметить, что приведенные выше уравнения могут быть выражены более компактно в матричной форме:
a2=g(?1x)
h?(x)=a3=g(?2a2)
3. Функция затрат
Данная функция является параметром, который должен снижаться с каждой интеграцией в процессе обучения системы. Формула данного параметра выглядит так:
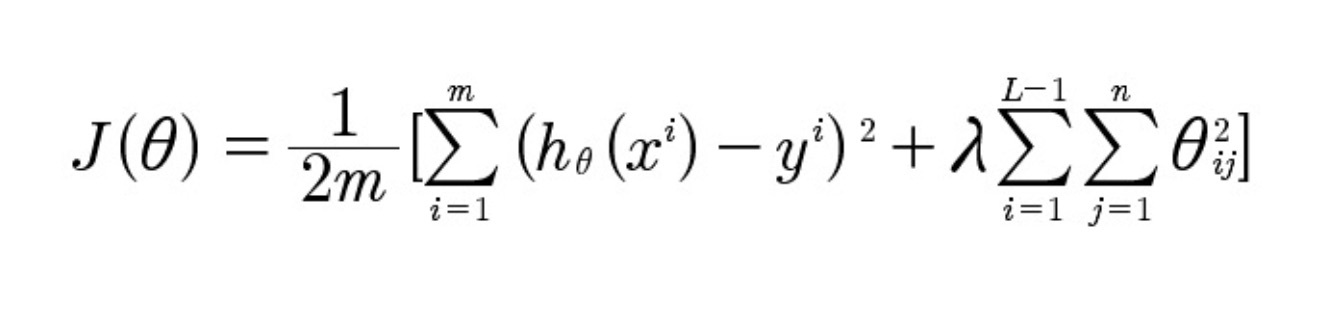
Где:
h?(x) это предсказанные вычисляемые данные;
y — фактические данные соответствующие выходным данным;
m — число обучающих примеров на показатель;
L — число слоев;
n — число узлов;
? — регулирующий параметр, отвечающий за балансировку между точностью системы и количество процессов ее переобучения.
В данном случае h?(x) — это вычисляемый уровень энергоэффективности, а y — фактический уровень энергоэффективности.
4. Обратное разветвление
После вычисления функции затрат индикатор ошибок ? распространяется по всем слоям в обратном порядке для ликвидации значения 0. Погрешность в выходном слое определяется как разница между вычисляемыми выходными данными h?(x) и фактическими y.
Для трехслойной нейронной схемы ошибка, связанная с выходными и скрытыми слоями, выражается так:
?3=a3 — y
?2=(?2)T.*g'(z2)=(?2)T?3.*[a2.*(1-a2)]
Где:
g’(z) представляет собой производную функции активации. Данное выражение можно упростить до такого вида: a.*(1-a).
Погрешности нет исключительно в первом слое, так как он является совокупностью вводимых данных. Для каждого слоя погрешность вычисляется по ниже приведенным формулам:
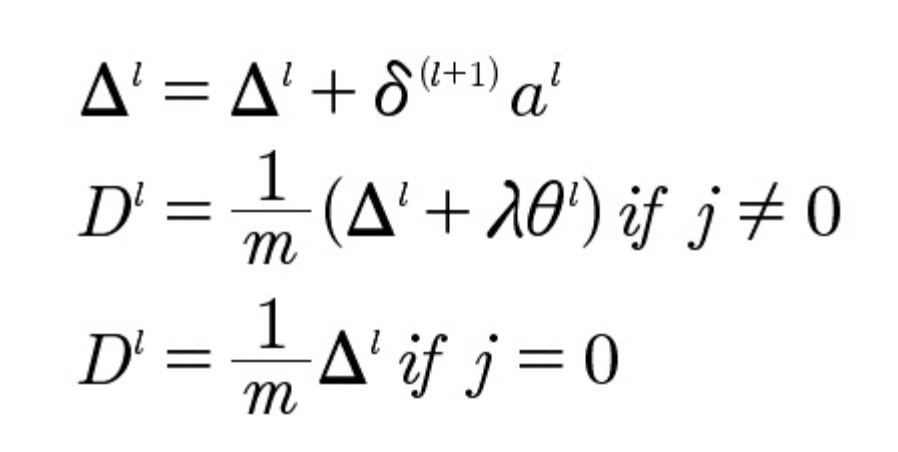
Где: ?l инициализируется, как вектор нулей. Dl добавляется для проведения апдейта модели каждого слоя перед повторным проведением пунктов 2-4. Соединив все алгоритмы обучения, данный процесс может дать множество (точнее сказать, сотни тысяч) итераций, прежде чем будет достигнута конвергенция, процесс достижения которой ускоряется за счет формулы затрат.
Реализация
Данная искусственная нейронная сеть использует 5 скрытых слоев, по 50 узлов в каждом слое, и параметр регуляризации = 0,001. Для проведения расчетов используется 19 параметров. В результате получаем один параметр — уровень энергоэффективности ЦОДа. Каждый из этих параметров включает в себя 184435 примера по 5 минут каждый (данные о работе той или иной системы в ЦОДе в течении 5 минут, собранные множество раз для проведения анализа и расчетов). Это составляет примерно 2 года данных (во временном эквиваленте). 70% данных используется для обучения системы, остальные 30% — для перекрестной проверки и тестирования. Хронологическая последовательность в сборе и анализе данных была умышленно нарушена для достижения более точных результатов.
Данные нормализации были использованы в виду большого числа сырых параметров работы систем ЦОДа. Значение вектора z, определяются в диапазоне [-1, 1]:
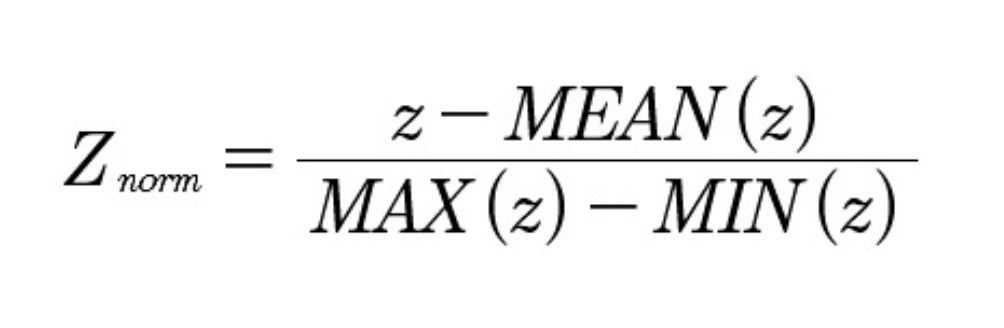
Как уже говорилось ранее для более оптимальных и точных подсчетов, проводимых нейронной схемой, было использовано 19 параметров. Вот их полный перечень:
Столь положительные результаты работающей системы, способной довольно точно анализировать данные, все же, были достигнуты Гао без использования «глубинного обучения». Работа ИИ, в случае использования данной системы, может значительно улучшиться и расшириться в своих полномочиях. Сейчас Google использует свой ИИ исключительно для улучшения работы определенных систем в своих ЦОДах. В будущем ИИ будут использоваться также и для анализа/обработки данных. Возможно ИИ станет управлять всем интернетом, как собственной структурой, улучшая его, делая более отзывчивым к пользователям. Искусственный интеллект способен изменить мир, это факт.
Но сколько еще нам, людям, прийдется узнать, сколько понять и осознать, прежде чем мы дадим ИИ больше власти, чем имеем сами. Может мы можем создать полноценный искусственный разум, но просто не хотим этого. Ибо все мы знаем поговорку «ученик превзошел своего учителя». Не получится ли так, что наше творение превзойдет нас. Ответы на эти вопросы мы пока не знаем, но это лишь пока.
Одним из самых крупных, во многих пониманиях, фанатом ИИ является корпорация Google. Все мы знаем об автомобиле, который способен передвигаться по оживленной дороге без прямого участия человека, о приложениях для смартфонов, способных распознавать речь и коммуницировать с человеком, о поисковых сервисах, способных мгновенно распознавать цифровые изображения. Все эти фантастические вещи разрабатываются не только Google. Многие компании, такие как Facebook, Microsoft и IBM тоже не пасут задних. Это является ярким показателем их чрезвычайно большого интереса к внедрению ИИ в нашу с вами повседневную жизнь.
Google Car
Многие революционные проекты основаны на использовании ИИ в том или ином виде. Среди них авто Google, IBM Watson (суперкомпьютер, оборудованный вопросной-ответной системой ИИ). Это довольно громкие и публичные проекты. Однако не единственные, и далеко не самые главные. Большинство компаний уделяют значительно больше времени и ресурсов на развитие так называемой системы искусственного интеллекта «глубинное обучение».
IBM Watson (суперкомпьютер, оборудованный вопросной-ответной системой ИИ)Именно эту систему Google и развивает в своих дата центрах. За всеми сервисами Google скрывается огромное множество данных, которые требуют обработки и анализа. Соответственно компания владеет своими огромными дата центрами, что вообщем то и не секрет. В настоящий момент в ЦОД-ах корпорации начали применять искусственные нейронные сети, задачей которых является анализ работы самого ЦОДа. В дальнейшем, полученные данные используются для улучшения работы структуры хранения и обработки данных. По сути эти нейронные сети представляют собой компьютерные алгоритмы, которые могут распознать паттерны и принять определенное решение, основываясь на полученных данных. Эта сеть не может сравниться с человеческим интеллектом, однако многие задачи она может выполнять значительно быстрее и эффективнее. Именно по этой причине Google применяет данные алгоритмы в работе своих дата центров, именно там, где скорость значит многое.
Творцом ИИ для ЦОДа Google стал молодой инженер Джим Гао (Jim Gao), которого многие из команды называют «юным гением». В свое время он прошел курс онлайн лекций профессора Стэндфордского университета Эндрю Ына (Andrew Ng). Профессор является ведущим специалистов в области изучения ИИ.
Профессор Ын
Джим Гао использовал свои «20% времени»* для изучения работы искусственных нейронных сетей и способов их применения в работе ЦОДов компании.
* «20% времени» — нововведение компании Google, направленное на улучшение работы своих сотрудников. По сути это официальное разрешение от руководства использовать 20% рабочего времени на исследование и разработку собственных идей, которые в дальнейшем могут пригодится компании.
Каждые несколько секунд Google собирает огромное количество всевозможных данных: показатели потребляемой энергии, объемы использованной в системе охлаждения воды, температура снаружи ЦОДа и т.д. Джим Гао создал систему ИИ, которая бы собрала эту информацию, обрабатывала ее и предсказывала уровень эффективности работы дата центра. Спустя 12 месяцев модель была скорректирована, ввиду получения еще более новых данных. В результате точность предсказаний составила 99,6%.
Данная система ИИ является своего рода превентивной мерой во время решения той или иной проблемы. На данный момент ИИ занимается работой основных систем обеспечения ЦОДа (энергообеспечение, охлаждение и т.д.). К примеру, система ИИ может «предложить» замену теплообменника, что улучшит работу системы охлаждения. Пару месяцев назад ЦОДу пришлось отключить некоторое число серверов, что обычно влияет на энергоэффективность, однако благодаря ИИ Джима Гао, которая регулирует систему охлаждения, технические работы прошли спокойно, а уровень энергоэффективности оставался высоким в течении всего времени. ИИ, по словам представителей Google, может замечать те мелкие детали, которые не видны человеку, что и делает ее такой эффективной.
Данный график показывает соотношение предсказаний ИИ системы и фактических показателей PUE (Power usage effectiveness) эффективности энергопотребления
Конечно же, нас не может не радовать такой успех Google, однако все же интересно как работает эта система.
Прежде всего была поставлена задача в определении именно тех факторов, которые имеют самое большое влияние на уровень энергоэффективности (PUE). Джим Гао сократил список до 19 факторов (переменных). После была сформирована искусственная нейронная сеть. Эта система должна была анализировать (или обрабатывать, кому как удобнее) огромное количество данных и искать в них закономерности.
Сложность заключается в количестве, как это не забавно, всего. Точнее выражаясь, в количестве переменных. Количество оборудования, их комбинаций, соединений, факторов влияния, таких как погодные условия.
Более подробно эту проблему и методы ее решения в контексте использования ИИ в работе дата центра Джим Гао описывает в своей работе «машинное обучение в оптимизации центров обработки данных».
Вот, что говорит сам Джим Гао во вступительной части своей работы:
«Современный дата центр (ДЦ) это сложная совокупность множества механических, электрических систем и систем управления. Огромное число возможных конфигураций операционных и нелинейных соединений усложняет понимание и оптимизацию энергоэффективности. Мы разработали структуру нейронных соединений, которая посредством анализа фактических операционных данных, обучается моделированию плана действий и предвидению уровня энергоэффективности PUE, с погрешностью в рамках 0,004 +/- 0,005, или же погрешностью в 0,4% от PUE 1,1. Модель была серьезно испытана в ЦОДах Google. Результаты продемонстрировали, что машинное обучение — эффективный способ использования уже имеющихся сенсорных данных для моделирования работы ЦОДа и повышения энергоэффективности».
Реализация модели
Входная переменная x — (m x n) — массив данных, где m — количество обучающих примеров, а n — количество особенностей, к которым относится и IT нагрузка и погодные условия, число работающих куллеров и градирен, количество устанавливаемого оборудования и т.д.
Обыкновенная трехслойная нейронная сеть
Входная матрица х умножается на параметры модели матрицы ?1 для получения скрытого состояния матрицы. На практике, а действует в качестве промежуточного участка, который взаимодействует со вторым параметром матрицы ?2 для вычисления исходных данных h?(x). Размер и количество скрытых слоев напрямую зависит от сложности моделируемой системы. При этом h?(x) представляет собой вариативность выходных данных, представленных в виде некоего диапазона показателей, которые и необходимо оптимизировать. Уровень энергоэффективности используется в формировании данной системы как показатель работоспособности ЦОДа. Диапазон показателей — коэффициент, не отображающий общего потребления энергии дата центром. Другие исходные данные включают в себя данные об утилизации серверов для максимализации продуктивности, или же данные о сбоях оборудования для понимания того, как инфраструктура ЦОДа влияет на его надежность. Нейронная сеть ищет взаимосвязь между различными данными показателей, дабы сформировать математическую модель, калькулирующую исходные данные h?(x). Понимая основные математические принципы h?(x), можно их контролировать и оптимизировать.
Несмотря на то, что линейная независимость показателей необязательна, ее использование значительно сокращает время обучения системы и снижает количество процессов переобучения. К тому же данная линейная система показателей упрощает модель ограничивая число вводных данных исключительно теми показателями, которые являются самыми фундаментальными для работы ЦОДа. К примеру температура в проемах системы охлаждения не является важным показателем для формирования уровня энергоэффективности, так как является следствием работы других систем (работы градирен, температуры водного конденсата и точки ввода охлажденной воды), показатели которых и есть фундаментальны.
Процесс обучения нейронной сети можно разделить на четыре основных этапа (+ пятый этап, повторяющий пункты 2-4):
1. Произвольная инициализация параметров (паттернов) модели;
2. Реализация алгоритма дальнейшего разветвления;
3. Вычисление функции затрат J(?);
4. Реализация алгоритма обратного разветвления;
5. Повторение пунктов 2, 3 и 4 для достижения максимальной конвергенции или же достижения необходимого числа попыток.
1. Произвольная инициализация
Произвольная инициализация — процесс произвольного назначения величины ? между [-1, 1] непосредственно перед началом обучения модели. Для понимания того зачем это необходимо, рассмотрим сценарий, где все параметры модели будут равны 0. Входящие данные в каждом последующие слое нейронной сети будут одинаковы, так как они умножаются на ? (равное 0). Кроме того эта ошибка будет распространяться и в обратном направлении, посредством скрытых слоев, что приведет к тому, что любые изменения параметров модели также будут абсолютно идентичны. Именно по этой причине значение ? произвольно варьируется в диапазоне [-1, 1], дабы избежать формирования дисбаланса.
2. Дальнейшее разветвление
Дальнейшее разветвление относится к процессу калькуляции каждого следующего слоя, так как значение каждого из них зависит от параметров модели и от слоев, предшествующих им. Исходные данные модели вычисляются путем алгоритма дальнейшего разветвления, где alj отображает активацию узла l в слое j, а ?l — матрица данных (параметры модели) преображающая слой l в слой l+1.
Базовые параметры (узлы со значением 1) прибавляются к каждому несходному слою для представления цифрового выражения в каждом слое.
В приведенных выше уравнениях ?110 редставляет собой значение между прибавленным базовым параметром x10 и элементом скрытого слоя a21.
Целью функции активации x(z) является имитирование работы биологических нейронных сетей, путем наложение входных данных на исходные в пределах диапазона (0, 1). Она задается сигмовидной логистической функцией g(z)=1/(1+e-z)
Следует отметить, что приведенные выше уравнения могут быть выражены более компактно в матричной форме:
a2=g(?1x)
h?(x)=a3=g(?2a2)
3. Функция затрат
Данная функция является параметром, который должен снижаться с каждой интеграцией в процессе обучения системы. Формула данного параметра выглядит так:
Где:
h?(x) это предсказанные вычисляемые данные;
y — фактические данные соответствующие выходным данным;
m — число обучающих примеров на показатель;
L — число слоев;
n — число узлов;
? — регулирующий параметр, отвечающий за балансировку между точностью системы и количество процессов ее переобучения.
В данном случае h?(x) — это вычисляемый уровень энергоэффективности, а y — фактический уровень энергоэффективности.
4. Обратное разветвление
После вычисления функции затрат индикатор ошибок ? распространяется по всем слоям в обратном порядке для ликвидации значения 0. Погрешность в выходном слое определяется как разница между вычисляемыми выходными данными h?(x) и фактическими y.
Для трехслойной нейронной схемы ошибка, связанная с выходными и скрытыми слоями, выражается так:
?3=a3 — y
?2=(?2)T.*g'(z2)=(?2)T?3.*[a2.*(1-a2)]
Где:
g’(z) представляет собой производную функции активации. Данное выражение можно упростить до такого вида: a.*(1-a).
Погрешности нет исключительно в первом слое, так как он является совокупностью вводимых данных. Для каждого слоя погрешность вычисляется по ниже приведенным формулам:
Где: ?l инициализируется, как вектор нулей. Dl добавляется для проведения апдейта модели каждого слоя перед повторным проведением пунктов 2-4. Соединив все алгоритмы обучения, данный процесс может дать множество (точнее сказать, сотни тысяч) итераций, прежде чем будет достигнута конвергенция, процесс достижения которой ускоряется за счет формулы затрат.
Реализация
Данная искусственная нейронная сеть использует 5 скрытых слоев, по 50 узлов в каждом слое, и параметр регуляризации = 0,001. Для проведения расчетов используется 19 параметров. В результате получаем один параметр — уровень энергоэффективности ЦОДа. Каждый из этих параметров включает в себя 184435 примера по 5 минут каждый (данные о работе той или иной системы в ЦОДе в течении 5 минут, собранные множество раз для проведения анализа и расчетов). Это составляет примерно 2 года данных (во временном эквиваленте). 70% данных используется для обучения системы, остальные 30% — для перекрестной проверки и тестирования. Хронологическая последовательность в сборе и анализе данных была умышленно нарушена для достижения более точных результатов.
Данные нормализации были использованы в виду большого числа сырых параметров работы систем ЦОДа. Значение вектора z, определяются в диапазоне [-1, 1]:
Как уже говорилось ранее для более оптимальных и точных подсчетов, проводимых нейронной схемой, было использовано 19 параметров. Вот их полный перечень:
- IT нагрузка
- Нагрузка на базовые сети всего помещения
- Общее число работающих водных насосов
- Среднее скорость частотно-регулируемого привода водных насосов
- Общее число работающих насосов конденсата
- Среднее скорость частотно-регулируемого привода насосов конденсата
- Общее количество работающих градирен
- Средняя температура охлаждающей воды
- Общее число работающих чиллеры
- Общее число работающих сухих охладителей
- Общее число насосов ввода охлаждающей воды
- Средняя температура воды в насосах ввода
- Средняя температура теплообменника
- Наружная температура мокрого термометра
- Наружная температура сухого термометра
- Теплосодержание наружного воздуха
- Относительная влажность наружного воздуха
- Скорость ветра
- Направление ветра
Столь положительные результаты работающей системы, способной довольно точно анализировать данные, все же, были достигнуты Гао без использования «глубинного обучения». Работа ИИ, в случае использования данной системы, может значительно улучшиться и расшириться в своих полномочиях. Сейчас Google использует свой ИИ исключительно для улучшения работы определенных систем в своих ЦОДах. В будущем ИИ будут использоваться также и для анализа/обработки данных. Возможно ИИ станет управлять всем интернетом, как собственной структурой, улучшая его, делая более отзывчивым к пользователям. Искусственный интеллект способен изменить мир, это факт.
Но сколько еще нам, людям, прийдется узнать, сколько понять и осознать, прежде чем мы дадим ИИ больше власти, чем имеем сами. Может мы можем создать полноценный искусственный разум, но просто не хотим этого. Ибо все мы знаем поговорку «ученик превзошел своего учителя». Не получится ли так, что наше творение превзойдет нас. Ответы на эти вопросы мы пока не знаем, но это лишь пока.
Комментарии (6)



MaxxxZ
25.06.2015 07:54+3Это не ИИ. Это обычная математическая модель. Гугл очень любит термин ИИ прикручивать к количественному развитию алгоритмов взаимодействия с человеком, в то время, как ИИ требует качественного скачка.
Zenitchik
Формулы для слепых?
IvanGalavachov
Это ж как слепой их прочитает?
HostingManager
Я думаю, что тут имеет место недоработка кода хабра, когда картинки чрезмерно растягиваются по ширине.