 Еще 4 года назад использование контейнеров в production было экзотикой, но сейчас это уже норма как для маленьких компаний, так и для больших корпораций. Давайте попробуем посмотреть на всю эту историю с devops/контейнерами/микросервисами ретроспективно, взглянуть еще раз свежим взглядом на то, какие задачи мы изначально пытались решить, какие решения у нас есть сейчас и чего не хватает для полного счастья?
Еще 4 года назад использование контейнеров в production было экзотикой, но сейчас это уже норма как для маленьких компаний, так и для больших корпораций. Давайте попробуем посмотреть на всю эту историю с devops/контейнерами/микросервисами ретроспективно, взглянуть еще раз свежим взглядом на то, какие задачи мы изначально пытались решить, какие решения у нас есть сейчас и чего не хватает для полного счастья?
Я буду в большей степени рассуждать про production окружение, так как основную массу нерешенных проблем я вижу именно там.
Раньше production окружение выглядело примерно так:
- монолитное приложение, работающее в гордом одиночестве на сервере или виртуалке
- БД на отдельных серверах
- фронтенды
- вспомогательные инфраструктурные сервисы (кэши, брокеры очередей итд)
В какой-то момент бизнес начал сильно смещаться в IT (к цифровому продукту, как модно сейчас говорить), это повлекло за собой необходимость наращивать как объемы разработки, так и скорость. Методология разработки изменилась, чтобы соответствовать новым требованиям, а это в свою очередь вызвало появления ряда проблем на стыке разработки и эксплуатации:
- монолитное приложения сложно разрабатывать толпой разработчиков
- сложно управлять зависимостями
- сложно релизить
- сложно разбираться с проблемами/ошибками в большом приложении
В качестве решения этих проблем мы получили сначала микросервисы, которые перенесли сложность из области кода в интеграционное поле.
Ежели где-то что-то убыло, то где-то что-то прибыть должно непременно. М. Ломоносов
В общем случае ни один вменяемый админ, отвечающий за доступность инфраструктуры в целом, не согласился бы на подобные изменения. Чтобы это как-то компенсировать, у нас появилось нечто под названием DevOps. Я даже не буду пытаться рассуждать о том, что же такое devops, лучше посмотрим, какие результаты мы получили в результате участия разработчиков в эксплутационных вопросах:
- docker — удобный способ упаковки софта для разворачивания в различных окружениях (да, я реально считаю, что докер это всего лишь пакет:)
- infrastructure as a code — у нас сильно усложнилась инфраструктура и теперь мы просто обязаны где-то зафиксировать способ восстанавливать ее с нуля (раньше это было опционально)
- оркестрация — раньше мы могли себе позволить наливать виртуалки/железные серверы руками под каждое приложение, сейчас их стало много и нам хочется иметь какое-то "облако", которому мы просто говорим "запусти сервис в трех копиях на разных железках"
- огромное количество tooling'а для управления всем этим хозяйством
Побочным эффектом этих новых технологий и подходов стало то, что окончательно исчезли барьеры в порождении микросервисов.
Когда начинающий админ или разработчик-романтик смотрит на новую картину мира, он думает, что инфраструктура теперь является "облаком" поверх какого-то количества серверов, которое легко масштабируется добавлением серверов в случае необходимости. Мы как бы построили над нашей инфраструктурой абстракцию, и нас теперь не интересует, что происходит внутри.
Эта иллюзия разбивается вдребезги сразу после того, как у нас появляется нагрузка и мы начинаем трепетно относиться к времени ответа наших сервисов. Например:
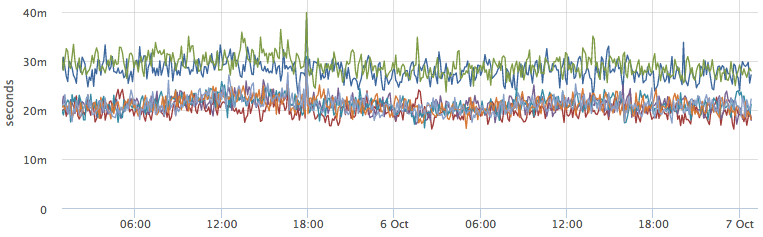
Почему некоторые инстансы сервиса работают медленнее остальных? Сразу после этого, начинаются вопросы такого вида:
- может там серверы слабее?
- может кто-то ресурсы съел?
- нужно найти, на каких серверах работают инстансы:
dc1d9748-30b6-4acb-9a5f-d5054cfb29bd
7a1c47cb-6388-4016-bef0-4876c240ccd6
и посмотреть там на соседние контейнеры и потребление ресурсов
То есть, мы начали разрушать нашу абстракцию: теперь мы хотим знать топологию нашего "облака", а следующим шагом захотим ей управлять.
В итоге типичная "облачная" инфраструктура на текущий момент выглядит примерно так (плюсуй, если узнал свою:)
- есть серверы docker-, kube- на каждом из них 20-50 контейнеров
- базы работают на отдельных железках и как правило общие
- resource-intensive сервисы на отдельных железках, чтобы никому не мешать
- latency-sensitive сервисы на отдельных железках, чтобы им никто не мешал
Я решил попробовать собрать воедино (из давно известных компонентов) и немного потестировать подход, который смог бы сохранить "облако" черным ящиком для пользователя.
Начнем конечно с постановки задачи:
- у нас есть наши серверные ресурсы и какое-то количество сервисов (приложений), между которыми их нужно разделить
- нагрузка на соседние сервисы не должна влиять на целевой сервис
- возможность доутилизировать простаивающие ресурсы
- хотим понимать, сколько ресурсов осталось и когда пора добавлять мощности
Я попробовал подсмотреть решение или подход у существующих оркестраторов, точнее их облачные комерческие инсталяции Google Сontainer Engine, Amazon EC2 Container Service. Как оказалось, это просто отдельная инсталяция kubernetes поверх арендованных вами виртуалок. То есть, они не пытаются решать задачу распределения ресурсов виртуалок на ваши сервисы.
Потом я вспомнил про свой давний опыт работы с Google App Engine (самое true облако на мой взгляд). В случае с GAE ты действительно ничего не знаешь про низлежащую инфраструктуру, а просто заливаешь туда код, он работает и автоматически масштабируется. Платим мы за каждый час работы каждого инстанса выбранного класса (CPU Mhz + Memory), облако само регулирует количество таких инстансов в зависимости от текущей нагрузки на приложение. Отдельно отмечу, что частота процессора в данном случае, показывает лишь то, какую часть процессорного времени выделят вашему инстансу. То есть, если у нас есть проц 2.4Ghz, и мы выделяем 600Mhz, значит мы отдаем 1/4 времени одного ядра.
Этот подход мы и возьмем за основу. С технической стороны в этом нет ничего сложного, в linux с 2008 года есть cgroups (на хабре есть подробное описание). Сосредоточимся на открытых вопросах:
- как выбрать ограничения? Если спросить у любого разработчика, сколько памяти нужно его сервису, с вероятностью 99% он ответит: "ну дай 4Gb, наверное влезет". Тот же вопрос про CPU точно останется без ответа:)
- насколько лимиты ресурсов вообще работают на практике?
Cgroups:CPU
- shares: пропорции выделения процессорного времени
- quota: жесткое ограничение количества процессорного времени в единицу реального времени
- cpusets: привязка процессов к конкретным cpu (+NUMA)
Для теста я написал http сервис, который половину времени запроса молотит cpu и половину времени просто спит. Будем запускать его на сервере 8 ядер/32Gb (hyper-threading выключен для простоты). Подадим на него нагрузку через yandex.tank с соседней машины (по быстрой сети) сначала только на него, а через какое-то время на соседний сервис. Время ответа будем отслеживать по гистограмме с бакетами от 20ms до 100ms с шагом 10ms.
Отправная точка:
docker run -d --name service1 --net host -e HTTP_PORT=8080 httpservice
docker run -d --name service2 --net host -e HTTP_PORT=8081 httpserviceГистограмма
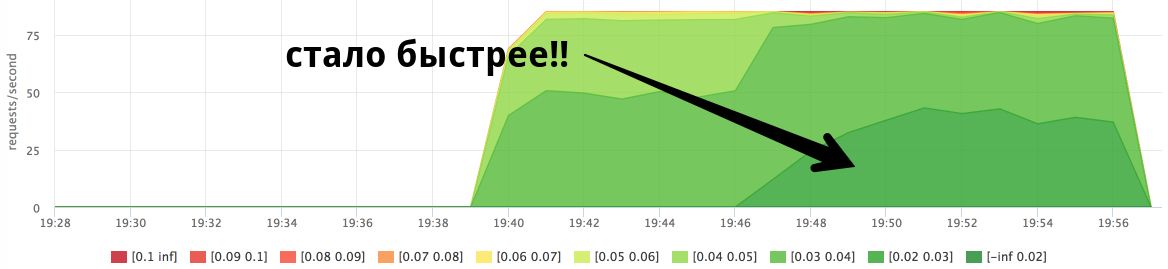
Потребление cpu в разрезе контейнеров:
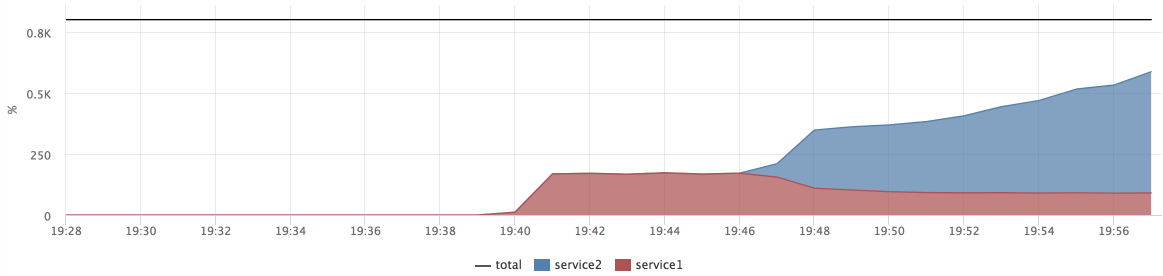
Мы видим, что в момент подачи нагрузки на service2 время ответа service1 улучшилось. У меня было достаточно много гипотез, почему это могло происходить, но ответ я случайно увидел в perf:
perf stat -p <pid> sleep 10 Медленно (без нагрузки на соседа):
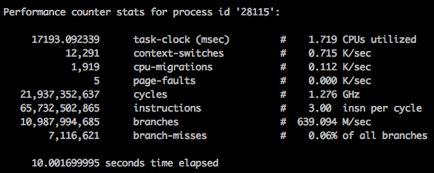
Быстро (с нагрузкой на соседа):
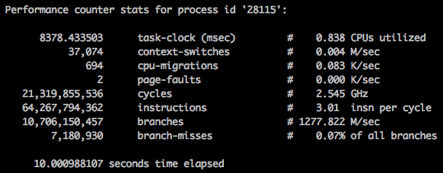
На картинках видно, что мы тратим одинаковое количество процессорных циклов за 10 секунд в обоих случаях, но скорость их "траты" разная (1.2Ghz vs 2.5Ghz). Конечно же это оказался "лучший друг производительности" — режим энергосбережения.
Чиним:
for i in `seq 0 7`
do
echo “performance” > /sys/devices/system/cpu/cpu$i/cpufreq/scaling_governor
doneЗапускаем снова тот же тест:

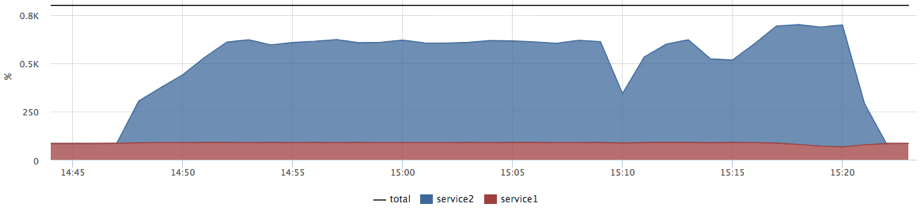
Теперь, мы видим как сервис2 начинает ожидаемо мешать сервису1. На самоме деле, когда никакие ограничения/приоритеты не заданы, мы имеем распределение долей процессорного времени поровну (cpu shares 1024:1024). При этом пока нет конкуренции за ресурсы, процесс может утилизировать все имеющиеся ресурсы. Если мы хотим предсказуемого времени ответа, нам нужно ориентироваться на худший случай.
Попробуем зажать сервис1 квотами, но сначала быстро разберемся, как настраиваются квоты на cpu:
- period – реальное время
- quota – сколько процессорного времени можно потратить за period
- если хотим отрезать 2 ядра: quota = 2 * period
- если процесс потратил quota, процессорное время ему не выделяется (throttling), пока не кончится текущий period
Выделим сервису1 два ядра (2ms cpu за 1ms) и подадим возрастающую нагрузку:
docker run -d --name service1 --cpu-period=1000 --cpu-quota=2000 …Гистограмма:

Фактическое потребление cpu:

Throttled time:
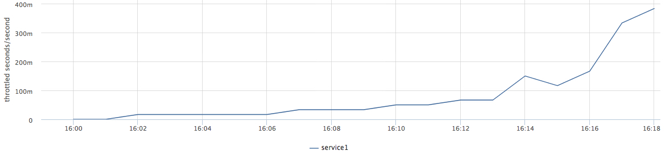
В результате этого теста мы нашли предел производительности сервиса без деградации времени ответа при текущей квоте.
- мы знаем, сколько в пределе можно подать запросов с балансировщика на такой инстанс
- можем посчитать в % утилизацию cpu сервисом
Факт: /sys/fs/cgroup/cpu/docker/id/cpuacct.usage
Лимит: period/quota
Триггер: [service1] cpu usage > 90% (как на каждой машине кластера, так и по кластеру в целом)
Распределяем ресурсы:
- делим машину на ”слоты” без overselling для latency-sensitive сервисов (quota)
- если готовимся к повышению нагрузки – запускаем каждого сервиса столько, чтобы потребление было < N %
- если есть умный оркестратор и желание – делаем это динамически
- количество свободных слотов – наш запас, держим его на комфортном уровне

Чтобы "добить" машину фоновой нагрузкой попробуем поставить максимальный cpu-shares нашим слотам с квотами, а "фоновым" задачам поставим минимальный приоритет.
docker run --name service1 --cpu-shares=262144 --cpu-period=1000 --cpu-quota=2000 ...
docker run --name=stress1 --rm -it --cpu-shares=2
progrium/stress --cpu 12 --timeout 300s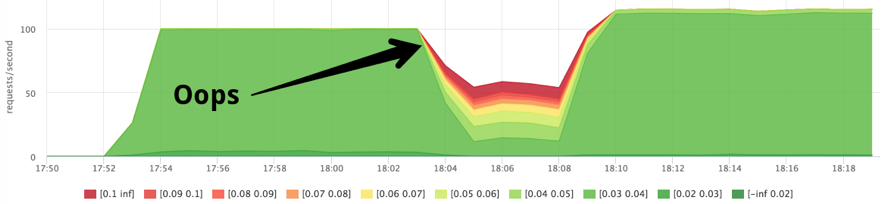
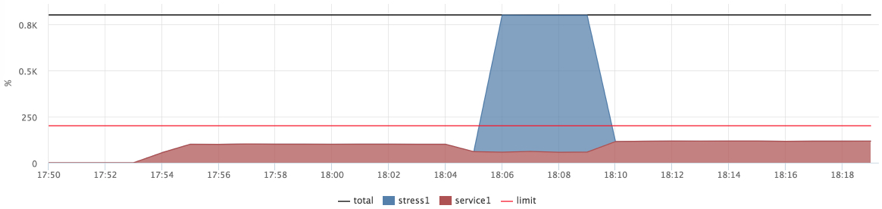
После этого теста я на 2-3 дня залип на упражнения с различными настройками планировщика (CFS) и изучением его внутреннего устройства. Выводы без подробностей такие:
- время выделяется слотами (slices)
- можно крутить ручки sysctl –a |grep kernel.sched_ уменьшая погрешность планирования, но для моего теста значимого эффекта я не получил
- я поставил квоту 2ms/1ms, это оказался достаточно маленький слот
- в результате я решил попробовать квоту 20ms/10ms (те же 2 ядра)
- 200ms/100ms на 8 ядрах можно "спалить" за 200/8 = wall 50ms, то есть throttling в пределе будет 50ms, это ощутимо на фоне времени ответа моего тестового сервиса
Пробуем 20ms/10ms:
docker run --name service1 --cpu-shares=262144 --cpu-period=10000 --cpu-quota=20000 ...
docker run --name=stress1 --rm -it --cpu-shares=2
progrium/stress --cpu 12 --timeout 300s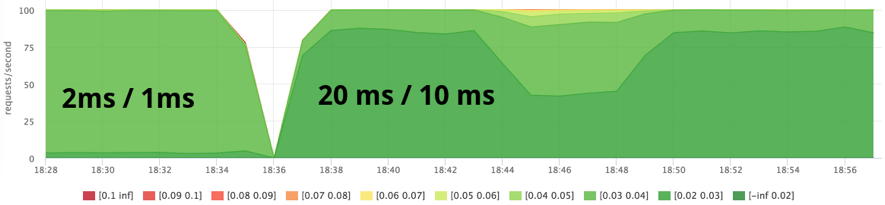
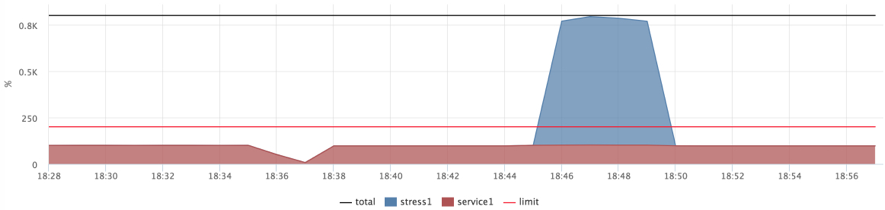
Такие показатели я посчитал приемлемыми и решил закончить с CPU:
- мы догрузили машину до 100% cpu usage, но время ответа сервиса осталось на приемлемом уровне
- нужно тестировать и подбирать параметры
- “слоты” + фоновая нагрузка – рабочая модель распределения ресурсов
Cgroups:memory
История с памятью более очевидная, но я хотел бы все равно мельком остановиться на паре примеров. Зачем нам вообще может понадобиться ограничивать память сервисам:
- cервис с утечкой может съесть всю память, а OOM killer может прибить не его, а соседа
- cервис с утечкой или активно читающий с диска может "вымыть" page cache, который очень нужен соседнему сервису
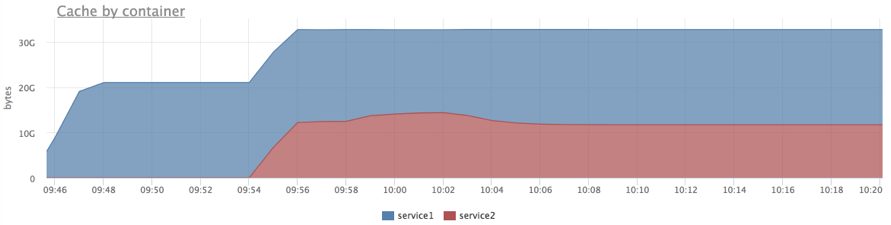
Более того, при использовании cgroups мы получаем расширенную статистику потребления памяти различными группами процессов. Например, можно понять, какой из сервисов сколько page cache использует.
Я решил протестировать следующий сценарий: наш сервис активно работает с диском (читает кусок из файла 20Gb со случайного offset на каждый запрос), объем данных целиком влезает в память (предварительно прогреем кэш), рядом запустим сервис, который прочитает соседний огромный файл (как будто кто-то логи пришел читать).
dd if=/dev/zero of=datafile count=20024 bs=1048576 # создаем файл 20GB
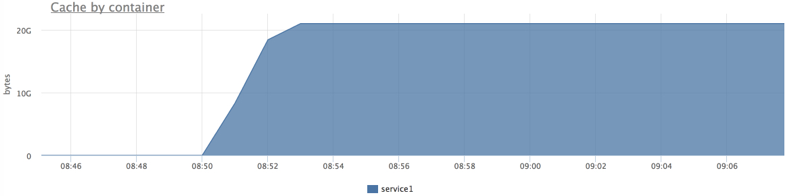
docker run -d --name service1 .. DATAFILE_PATH=/datadir/datafile …Прогреваем кэш от cgroup сервиса:
cgexec -g memory:docker/<id> cat datafile > /dev/nullПроверяем, что файл в кэше:
pcstat /datadir/datafile
Проверяем, что кэш засчитался нашему сервису:
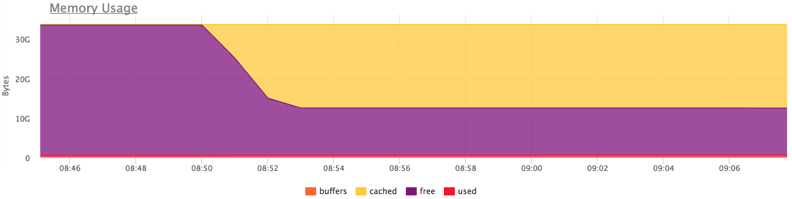
Запускаем нагрузку и пробуем "вымыть" кэш:
docker run --rm -ti --name service2 ubuntu cat datafile1 > /dev/null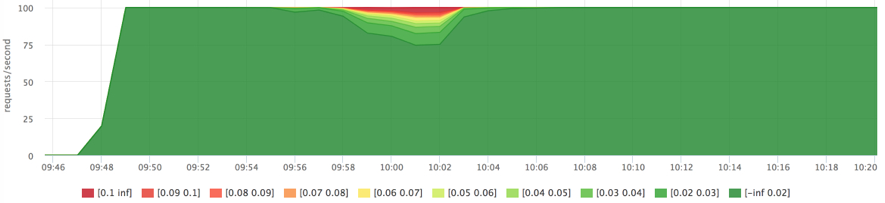
Как только мы немного "вымыли" кэш сервису1, это сразу сказалось на времени ответа.
Проделаем тоже самое, но ограничим сервис2 1Gb (лимит распространяется и на RSS и на page cache):
docker run --rm -ti --memory=1G --name service2 ubuntu cat datafile1 > /dev/null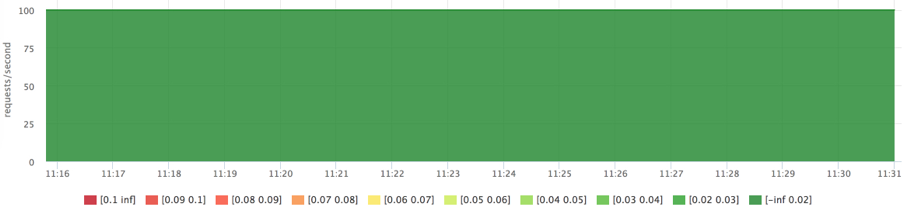
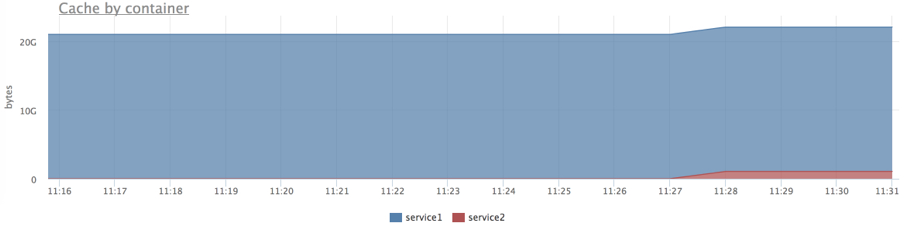
Теперь видим, что лимит работает.
Cgroups:blkio (disk i/o)
- все по аналогии с CPU
- есть возможность задать вес (приоритет)
- лимиты по iops/traffic на чтение/запись
- можно настроить для конкретных дисков
Поступим так же, как с CPU: отрежем квоту iops критичным сервисам, но поставим максимальный приоритет, фоновым задачам поставим минимальный приоритет. В отличие от CPU здесь не очень понятен предел (нет никаких 100%).
Сначала выясним предел нашего конкретного SATA диска при нашем профиле нагрузки. Cервис из предыдущего теста: 20Gb файл и случайное чтение по 1Mb на запрос, но в этот раз мы зажали наш сервис по памяти, чтобы исключить использование page cache.
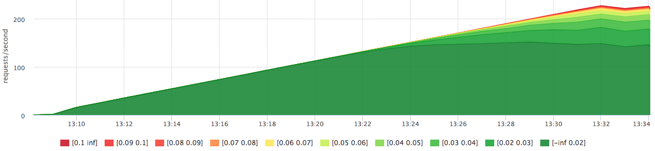
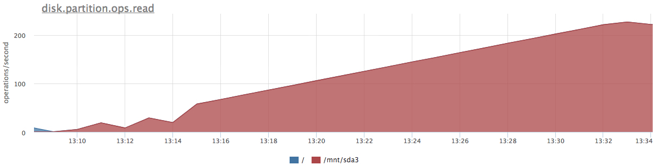
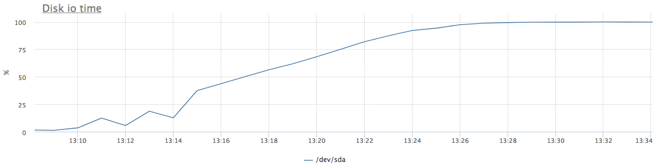
Получили чуть больше 200 iops, попробуем зажать сервис на 100 iops на чтение:
docker run -d --name service1 -m 10M --device-read-iops /dev/sda:100 …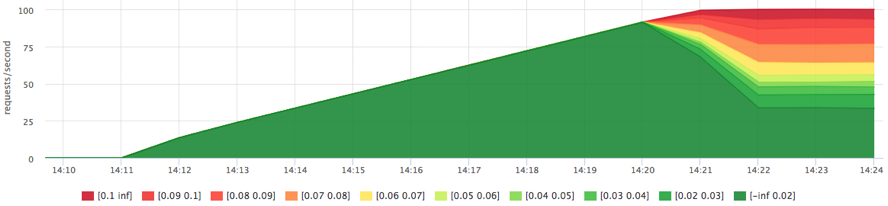
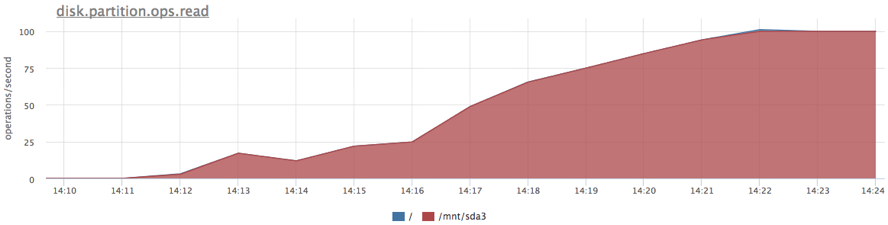
Лимит работает, нам не дали прочитать больше 100 iops. Помимо ограничения теперь у нас есть расширенная статистика по утилизации диска конкретными группами процессов. Например, можно узнать фактическое количество операций чтения/записи по каждому диску (/sys/fs/cgroup/blkio/[id]/blkio.throttle.io_serviced), причем это только те запросы, которые реально долетели до диска.
Попробуем догрузить диск фоновой задачей (пока без лимитов/приоритетов):
docker run -d --name service1 -m 10M …
docker run -d --name service2 -m 10M ubuntu cat datafile1 > /dev/null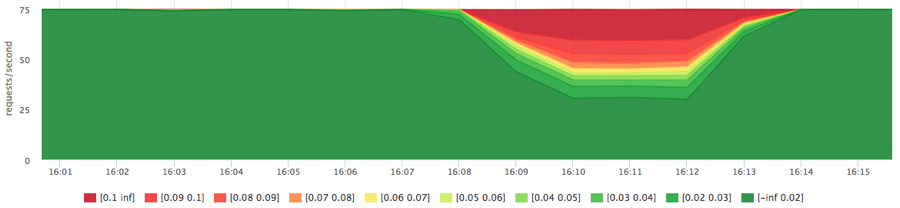
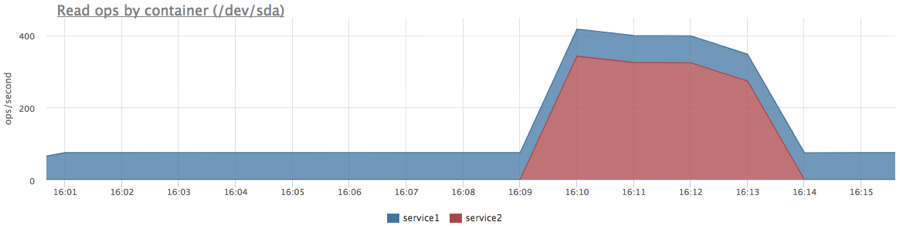
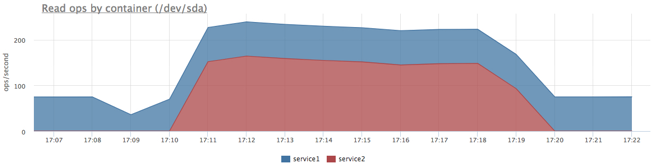
Получили вполне ожидаемую картину, но так как сервис2 читал последовательно, в сумме мы получили больше iops.
Теперь настроим приоритеты:
docker run -d --name service1 -m 10M --blkio-weight 1000
docker run -d --name service2 -m 10M --blkio-weight 10 ubuntu cat datafile1 > /dev/null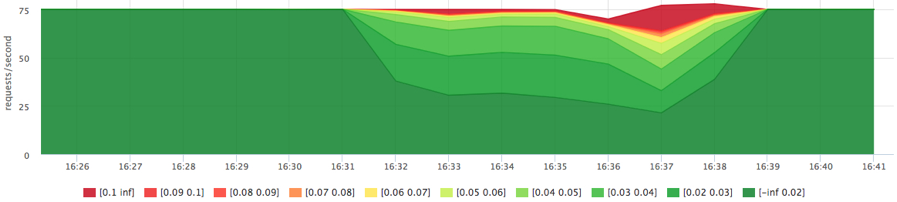

Я уже привык к тому, что из коробки ничего сразу не работает:) После пары дней упражнений с IO планировщиками linux (напоминаю, у меня был обычный шпиндельный SATA диск):
- cfq у меня настроить не получилось, но там есть, что покрутить
- лучший результат на данном тесте дал планировщик deadline с такими настройками:
echo deadline > /sys/block/sda/queue/scheduler echo 1 > /sys/block/sda/queue/iosched/fifo_batch echo 250 > /sys/block/sda/queue/iosched/read_expire
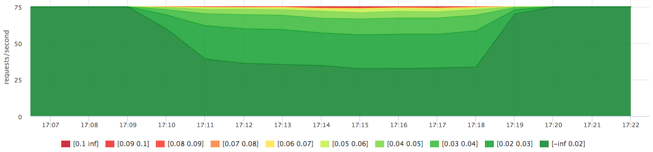
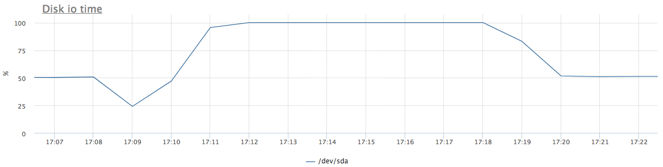
Эти результаты я посчитал приемлемыми и дальше тему не исследовал.
Итого
- если очень захотеть, настроить и все хорошенько протестировать, можно запустить hadoop рядом с боевой БД в prime time :)
- до "true" облака нам всем ещё очень далеко и есть вагон нерешенных вопросов
- нужно смотреть на правильные метрики, это очень дисциплинирует и заставляет разобраться с каждой аномалией, как на production, так и во время подобных тестов
Реклама: все интересные метрики, которые я нашел в ходе данного тестирования, мы добавили в наш агент (сейчас они в beta тестировании, скоро будут доступны всем). У нас есть 2х недельный триал, но если вы хотите посмотреть именно на метрики cgroups, напишите нам, мы расширим вам триал.
Комментарии (56)
MonkAlex
21.02.2018 21:09Таки что не так с devops? Тему то не раскрыли.

NikolaySivko Автор
21.02.2018 21:12Работы много еще там, многие этого не замечают или не хотят замечать
MonkAlex
21.02.2018 22:32Так девопс — это не серебрянная пуля. Это идея автоматизации всего в округе, чтобы не приходилось админам вручную ручки крутить у разных окружений. Чтобы можно было обновлять\откатывать каждые пару минут и никто не умирал, и не было шансов сделать ошибку.
Оно вообще не о производительности, которую видимо меряли в статье.

Singaporian
22.02.2018 10:09Работы много по усложнению жизни жизни админов разработчиками? Или что? :-)

YetAnotherSlava
22.02.2018 16:45А когда благодаря автоматизации у devops работы снова станет мало, их припрягут к разгрузке фур и охране склада сутки через трое.

Angerslave
21.02.2018 21:23-1Проблема не в монолите, в скорости изменений. Можно ли монолит релизить несколько раз в день? Гипотетически да, но зачем так жить?
Второй момент — стоимость железа. Гектар оперативы стоит копейки и довольно часто баланс между скоростью разработки и стоимостью поддержки в деньгах чаще выражается в большей эффективности быстрой разработки.
Конечно, в отдельных отраслях это неразумно, но, я надеюсь, в них люди на хайп не байтятся.
Sannis
22.02.2018 10:38Монолит можно релизить несколько раз в день, и выкативаться монолитом на стейджинг десятки сотен раз в день тоже можно.
И даже если монолит разбить на N "микросервисов", это не значит что вы сможете релизиться в N раз чаще, накладные расходы на тестирование, синхронизацию и обучение людей писать в соответствии с таким подходом никто не отменял.Angerslave
22.02.2018 10:45Верно, разбиение не даст возможность релизиться чаще. Даже наоборот, каждый отдельный микросервис будет релизиться реже (вплоть до N раз в идеальном случае), что как раз снижает накладные расходы.

Fesor
22.02.2018 12:22Не могу понять логическую цепочку. Почему накладные расходы снижаются? Они как раз таки увеличиваются. Да и идея не в частоте релизов, а в том что бы релиз отдельной части системы не влиял на остальные. И нужно это очень малому проценту проектов.
Angerslave
22.02.2018 13:02-1Потому, что вместо релиза, скажем, Windows, происходит релиз только отдельного компонента и соответственно тестировать нужно меньше. И это можно сделать умнее, чем просто «тестим всё» при релизе монолита. Кроме того, если над каждым микросервисом работает отдельная команда, то одни могут релизиться каждую среду, другие — каждый четверг и т.д. В случае зависимости микросервисов релиз также будет завязан друг на друга, но в монолите по факту такое происходит каждый раз.
Опять же, зависит от количества команд. Чем больше, тем сложнее релизить монолит часто.khanid
22.02.2018 20:10вместо релиза, скажем, Windows, происходит релиз только отдельного компонента и соответственно тестировать нужно меньше
Это очень спорное заявление.
Я отлично помню ситуацию, когда на win2k8 устанавливался языковой пакет для NetFramework35. Даже при отсутствующем установленном NetFramework35. Это приводило, в свою очередь, к тому, что ломалась вещь, никак с этим не связанная — консоли mmc, т.е. все оснастки становились недоступными. Ситуацию усугубляло то, что это только на неанглийских версиях системы было. Вещи вроде бы несвязанные, но к чему привело — я описал.Angerslave
23.02.2018 09:56В Longhorn им пришлось выкинуть в мусорку несколько человеко-лет работы потому, что они хотели зарелизить всё и сразу и некоторые компоненты (WinFS в частности) оказались ненужны на момент релиза.
Fesor
22.02.2018 22:09происходит релиз только отдельного компонента и соответственно тестировать нужно меньше.
Если тестировать нужно меньше, значит вы как-то изолировали влияние компонента на другие части системы. То есть у нас низкая связанность. Что вам мешает делать монолиты с низкой связанностью?
Кроме того, если над каждым микросервисом работает отдельная команда, то одни могут релизиться каждую среду, другие — каждый четверг и т.д.
а третьи могут релизить монолит целиком и полностью 10 раз в день. И что?
В случае зависимости микросервисов релиз также будет завязан друг на друга, но в монолите по факту такое происходит каждый раз.
Это управление зависимостями и в случае и микросервисов и монолитов все примерно одинаково. Другое дело, что скажем релиз одного компонента безболезненно происходит, а при изменениях другого надо проходить сертификацию к примеру. И тут выгодно разделить эти компоненты так, что бы у них был независимый цикл релизов.
Микросервисы сами по себе вообще ничего не дают. В сферическом вакууме уж точно. Это не благодать а вынужденная мера. Как думаете что будет с проектом на микросервисах, которые пилит команда, не в состоянии добиться низкой связанности компонентов в монолитном варианте?
Angerslave
23.02.2018 10:01Если тестировать нужно меньше, значит вы как-то изолировали влияние компонента на другие части системы. То есть у нас низкая связанность. Что вам мешает делать монолиты с низкой связанностью?
Верно, я не озвучил очевидное для меня допущение — релиз монолитного приложения по процессу занимает от часа до недели. В случае, если релиз приложения можно выкатить за минуту (и откатить за секунду), то, конечно, делить его смысла нет.Fesor
23.02.2018 12:37очевидное для меня допущение — релиз монолитного приложения по процессу занимает от часа до недели.
а можете пояснить, на основании чего было сделано подобное допущение? То есть мы говорим о проектах без адекватного уровня автоматизации доставки, а ни как не про монолит vs мифические микросервисы?
GreedyIvan
23.02.2018 13:41То есть мы говорим о проектах без адекватного уровня автоматизации доставки
Монолит за несколько лет своей эксплуатации вырос до размеров, что основная операционная база занимает несколько терабайт. И деплой изменений, затрагивающий миграции в основных таблицах, растягивается на недели, так как альтернатива связана с остановкой бд, деплоем бизнес-кода с новой логикой и поднятие бд. Практически без шансов на откат в случае, если что-то пошло не так. Поэтому маленькими шагами (т.е. с диким оверхедом к основным изменениям), чтобы максимально минимизировать даунтаймы и последствия от возможных неудач.
После этого понимание, что так быть не должно и надо что-то менять, приходит само.VolCh
23.02.2018 14:16Тут не микросервисы нужны, а более адекватный подход к миграциям чем "связана с остановкой бд, деплоем бизнес-кода с новой логикой и поднятие бд". Если это у вас основная таблица, то от переноса её в микросервис ничего не поменяется.
Angerslave
23.02.2018 13:55Комментарий GreedyIvan примерно описывает что я понимаю под монолитом и его проблемами, с которыми в концепции DevOps разработчики борятся. ИМХО, адекватный уровень автоматизации доставки гораздо ближе к сферическим микросервисам в вакууме — при большой базе (кода и данных) приходится грамотно разделять компоненты и деплоить их по-одному или несколько (но не обязательно все сразу).
Fesor
23.02.2018 15:56адекватный уровень автоматизации доставки гораздо ближе к сферическим микросервисам в вакууме
это подмена понятий и искажение терминологии. Причем очень грубое. Настолько грубое что невилирует какой либо смысл в термине "микросервис", уж слишком сильно его извратить успели.
при большой базе (кода и данных) приходится грамотно разделять компоненты и деплоить их по-одному или несколько (но не обязательно все сразу).
Грамотно разделять на компоненты — это всегда важно, зависимости, связанность и все такое. Но почему если у меня приложение жирное, и данных в базе много, это как-то влияет на деплоймент? Например, у меня есть миграция которая добавляет одно поле в табличку. Оно аффектит только одну табличку, добавляю я это поле безопасно (то есть никаких диких локов нет), обратная совместимость сохранена. В чем проблема релизить такие монолиты?
Или еще нюанс. Допустим мы добавили поле в табличку. И допустим миграция, заполняющая это поле будет отрабатывать пару часов. Как мне тут помогут микросервисы? Это же табличка принадлежащая конкретному компоненту. И в силу обратной совместимости я могу сделать эту миграцию независимо от деплоя.
Ну то есть тут больше вопрос архитектуры и процессов, нежели "микросервисы это ответ".
Angerslave
23.02.2018 16:32Да, в нашем случае табличка весит пару сотен гигабайт и изменений схемы занимает 2 дня. Вы верно отметили, что тут про процессы, а не про микросервисы. Я даже скорее про релиз говорю, и про скорость изменений.
Мы действительно о несколько разных вещах говорим.

roller
21.02.2018 22:01-1> теперь мы просто обязаны где-то зафиксировать способ восстанавливать ее с нуля
Наконец та жизнь начала реально давать админам по рукам и «доналить еще один сервер» стало быстро и просто, и событие типа «перезагрузили сервер и чо-то не заработало» теоретически должны уйти в прошлое, не будет «забытых» настроек и runtime костылей
hippoage
21.02.2018 22:27Немного вступлюсь за Kubernetes: там есть request и limit на cpu и память. Реквесты используются для размещения pod на нодах. Лимит по cpu — ограничение через cgroups. Лимит по памяти — прилетает OOM killer.
При этом не помню про blkio. Скорее всего нет. Но это из-за идеологии отсутствия локальных хранилищ.
Ещё интересны ограничения на трафик. Что-то на эту тему так же есть в k8s.
Если говорить про настройки хоста/ядра, то это тоже можно делать. Но это уже никакой не чёрный ящик.NikolaySivko Автор
21.02.2018 22:31kubernetes естественно прокидываем лимиты в cgroups (в linux просто ничего другого нет), вот если бы он навязывал задавать лимиты (не давал запускать deployment без органичений на каждый под) — было бы совсем хорошо.
theairkit
22.02.2018 00:15kubernetes умеет делать это с помощью limitRange, раздельно для cpu и memory:
kubernetes.io/docs/tasks/administer-cluster/memory-default-namespace
kubernetes.io/docs/tasks/administer-cluster/cpu-default-namespace
А если требуется более комлексная проверка k8s-спецификаций — то можно/нужно писать linter под свои нужды.theairkit
22.02.2018 00:28И ещё можно/нужно задавать опции для kubelet'а, чтобы он знал о том, сколько доступно ресурсов ноды для нужд кластера, например:
kubelet --help 2>&1 | grep limit ... --eviction-hard string A set of eviction thresholds (e.g. memory.available<1Gi) that if met would trigger a pod eviction. (default "memory.available<100Mi,nodefs.available<10%,nodefs.inodesFree<5%") ... --system-reserved mapStringString A set of ResourceName=ResourceQuantity (e.g. cpu=200m,memory=500Mi) pairs that describe resources reserved for non-kubernetes components. Currently only cpu and memory are supported. See http://kubernetes.io/docs/user-guide/compute-resources for more detail. [default=none] ... $ cat /proc/${kubelet_pid}/cmdline # мой тестовый стенд ... --system-reserved=cpu=100m,memory=100Mi --eviction-hard=imagefs.available<5%,memory.available<5%,nodefs.available<5%,nodefs.inodesFree<5 ...
akrymets
21.02.2018 23:25+1Как по мне статья годная. Как минимум интересная. Но по-моему автор упускает один момент: когда современный среднестатистический разработчик-мечтатель в своем кубернетисе или ECS столкнется с падением производительности системы, он действительно просто добавит под капот ресурсов и скорее всего не будет разбираться что там у него под капотом происходит и что там мешает его счастливой жизни. Даже если получит какой-то перебор по затратам. Но в подавляющем большинстве случаев это все равно дешевле, чем делать и поддерживать это все руками.
Вся история эволюции подходов и методов разработки и администрирования это история переходов на более высокие уровни абстракций ценой появления слишком уж большой сложности копания под капотом. Каждый следующий уровень абстракции позволяет нам решать проблему на уровне, который еще ближе к самОй проблемной области, а не заниматься дорогим и скучным низкоуровневым мазохизмом. Эта цена эволюции, и это все равно в перспективе дешевле в большинстве случаев.
P.S. AWS ECS не построен на кубернетисе в отличе от GCE. Это отдельная амазоновская система оркестрации контейнеров, которая из плюсов имеет только то, что она полностью управляется самим амазоном, и вы можете сразу начать с ней работать. Все остальное в ней по сравнению с K8s это боль имхо
Atorian
21.02.2018 23:56Верно подмечено.
Хотелось бы еще добавить, что контейнеры это классно, но сейчас все стремятся в AWS Lambda / Google Functions. И с ними вся головная боль контейнеров — на совести провайдеров. И с затратами все норм. Ну а если без контейнеров никак, то у амазона, например есть сервис Fargate, который позволяет арендовать контейнер, а не ес2 инстанс, напрямую. Т.е. ECS без головной боли.
Так что все движется в правильном направлении.

Suvitruf
21.02.2018 23:27Так и не понял, какие выводы из статьи. И да, DevOps — это не про производительность.
Singaporian
22.02.2018 10:11Про производительность. Только не серверов, а разработчиков/админов.
Но автор статьи так не считает.
arheops
22.02.2018 05:53+1Выводы из статьи — высокооплачиваемый девопс легко может залипнуть на пару дней — неделю и получить выгоду… ну может 50баксов в месяц.
Где расчеты эффективности вашего залипания? Что в результате получила компания?
А вообще докер это класно, а потом упираемся в производительность чегото еще класного(типа rabbitmq) и приходится убирать докер, чтоб получить нужные 10-20% разницы на немаштабируемых участках(которые с завидной периодичностью почемуто появляются).
Та же база в докере на nvme — работает отвратительно.NikolaySivko Автор
22.02.2018 08:13+3Высокооплачиваемый девопс может делать в рабочее время что угодно, если он при этом сможет обеспечить бизнесу работу сервиса с нужным SLA. У многих компаний это стабильно-низкое время ответа, например <100ms на запрос. Вот для таких случаев нужно очень хорошо ориентироваться в самом низком уровне.
VulvarisMagistralis
22.02.2018 08:20+1Высокооплачиваемый девопс может делать в рабочее время что угодно, если он при этом сможет обеспечить бизнесу работу сервиса с нужным SLA.
Ох уж эти мне профессиональные мечты, мечты…
Высокооплачиваемый сотрудник слишком дорого обходится фирме, чтобы не объяснять руководству чем он занят.

akamensky
22.02.2018 07:55Дочитал до тюнинга «scaling_governor» как решения и бросил. Не уверен как остальным читателям, но мне вот именно этот момент и показал проблему DevOps. ОС на сервере настроена как для desktop/laptop, и вы пытаетесь на этом показать производительность production? Смешно. Вот этот как раз и есть настоящая беда, когда люди рвутся везде использовать новейшие buzzword'ы, но при этом не знают как еще настроить сервер для production.
NikolaySivko Автор
22.02.2018 08:09+3Не соглашусь с вами. "scaling_governor" в этом случае был не тюнинг, а объяснение конкретной аномалии на гистограмме. Не менее важно, что проблема была обнаружена по конкретным показателям (perf), после чего сразу было понятно, что и как нужно исправить. Поверьте, я достаточно много собеседовал админов и наслушался, как правильно настраивать серверы в production:) При этом человек естественно не понимал, что он крутит и зачем.
akamensky
22.02.2018 10:51Это я к тому что при нормальной установке Linux на сервер соответствующие пакеты которые бы добавили соответствующие модули ядра (cpufrequtils на Debian, например) не установлены по-умолчанию, а это означает что ваши тесты были проведены, мягко говоря, не в совсем корректном окружении. Я так же собеседовал и собеседую людей на различные роли. И все рвутся мне рассказать как же правильно настроить kubernetes, хотя когда их спрашиваешь банальные вещи (как работает swap, разница между статической и динамической линковкой, для чего используется strace и мой любимый — как работает OOM) смотрят на меня «глазами полными ужаса»
Singaporian
22.02.2018 10:03+1Вся эта статья отталкивается от неоспоримой базы, что DevOps — это микро-сервисы. С какого фаллоса?
Я, конечно, восхищаюсь трудолюбием автора — написать такую объемную и аккуратную статью стоило ему труда. Но может было бы рациональнее пустить эти ресурсы на изучение термина DevOps и его смысловой нагрузки?VulvarisMagistralis
22.02.2018 10:17-1Ну раз ты такой умный — мы с удовольствием послушаем твое объяснение
Singaporian
22.02.2018 10:32- Я не говорил, что я умный
- Я не считаю уместным обсуждать здесь мою или чью-бы то ни было личность и интеллектуальные способности
- Чтобы я ни думал о DevOps, это не меняет факта того, что это не микро-сервисы
- Статья на Wiki содержит вполне исчерпывающую информацию на эту тему, чтобы осознать примитивность определения «DevOps=microservices»
AlexPu
22.02.2018 10:21-1>>DevOps придумали разработчики, чтобы админы больше работали
А я почему-то думал диаметрально противоположным образом — что это хитрый план админов по перекладыванию части своей работы на разработчиков. При том, что разработчики как-бы и не против ибо добиться от админов какой-то помощи (или вообще какой-то реакции кроме «отстань дебил») с первого раза просто не реальноVulvarisMagistralis
22.02.2018 11:07А я почему-то думал диаметрально противоположным образом — что это хитрый план админов по перекладыванию части своей работы на разработчиков.
Вы оба не правы.
Админы со знанием DevOpv автоматически могут рассчитывать на зарплату в 1.5-3 раза больше, чем обычные админы.
Потому совершенно очевидно чей именно это хитрый план и с какими целями.AlexPu
22.02.2018 12:21Разработчики со знанием DevOpv автоматически могут рассчитывать на зарплату в 1.5-3 раза больше, чем обычные разработчики… так кого мы обманываем?
VulvarisMagistralis
22.02.2018 12:39У вас так:
Разработчики со знанием DevOpv...
У меня так:
Админы со знанием DevOpv…
Для разработчиков знание технологии DevOps — уже скоро будет считаться базовым навыком, посему для разработчиков нет такого высокого коэффициента к зарплате.
А вот для админа — это знание означает переход на другую квалификационную ступеньку.AlexPu
22.02.2018 15:30>>Для разработчиков знание технологии DevOps — уже скоро будет считаться базовым навыком, посему для разработчиков нет такого высокого коэффициента к зарплате.
Это откуда у вас такие сведения? У меня например сведения совсем-совсем другие… Полностью ортогональные вашим. Хотя будущее я конечно не пргнощирую — я чисто текущую ситуацию описываю.
Что касается того, где это будет являться базовым навыком… лично я считаю, что базовым навыком это должно являться именно у всевозможных администраторов. Особенно тех, которые нынче именуются Infrastructure EngineerVulvarisMagistralis
22.02.2018 15:31У меня например сведения совсем-совсем другие… Полностью ортогональные вашим.
Яснее пожалуйста.AlexPu
23.02.2018 16:29Ну если хотите яснее — извольте:
По моему личному опыту, а также опыту моих коллег работающих как на должностях разработчиков, менеджеров разного уровня, infrastructure engineer, сетевых администраторов, security администраторов итп, известно следующее:
— разработчики с глубоким опытом работы с docker и связанными с ним технологиями на вес золота. Размер вознаграждения таких разработчиков в среднем на 50% выше стандартных (но в случаях где этот навык ключевой, зарплаты находятся на максимальном уровне определяемом экономической целесообразностью). Сразу поясню, что речь не идет о воображаемых вами «минимальных навыках» — никого эти самые минимальные навыки не интересуют вообще. Речь идет о способности построить приложение состоящее из десятков и сотен (а то и тысяч) независимых сервисов включая инфраструктурные сервисы. Это в частности и мой личный опыт — я на собеседования хожу сейчас как на работу, при том, что работа мне новая не требуется
— сотрудники работающие на должностях infrastructure engineer имеют зарплаты ощутимо ниже разработчиков — это единственная причина по которой я не могу перейти работать на такую должность. В моем возрасте довольно трудно уже оставаться разработчиком, хотелось бы на старости лет чего нибудь поспокойнее… Но никто даже слышать не хочет, чтобы платить зарплату хотя-бы равную той, что у меня есть сейчас. Основная масса infrastructure engineer это бывшие тестеры (процентов 60) и молодые разработчики с опытом работы менее 5-ти лет. Надеюсь ситуация в этой области исправится
— все виды администраторов однозначно заявляют, что владение технологиями связанными с Docker у них рассматривается как почти обязательный навык, при этом никто никогда не слышал о том, чтобы за это предлагали какие-то доп. деньги (вообще это пожалуй единственная профессия ИТ в ЕС где предложение превышает спрос). При этом речь не идет о каких-то глубоких познаниях Docker — тут как раз стоит говорить как раз именно о базовых знаниях… ну как… базовых… уровень администратора в общем…
Все вышеперечисленное это именно то как оно есть а не то как оно должно быть. Хотя это конечно не означает истину в последней инстанции. Ну и для справки — компания в которой я работаю сейчас имеет штат примерно 350 человек (на весну прошлого года), в составе этого штата есть и отдел администраторов (все виды оных) и отдел который мы именуем operations (он же ops department или просто ops) — последний занимается тем, что принято именовать DevOps… создан он примерно год назад… и мне точно известно кого туда нанимали и нанимают, каким опытом и навыками они обладают и какую именно работу они выполняют.
VulvarisMagistralis
22.02.2018 17:06Что касается того, где это будет являться базовым навыком… лично я считаю, что базовым навыком это должно являться именно у всевозможных администраторов.
От разработчиков требуются минимальные навыки.
Умение пушить корректно в git (иногда с тегами и т.п.)
Умение написать Dockerfile под свое приложение да работать с docker-compose.
Умение нормальный vendoring использовать.
И т.п. мелочи.
Это все шире и шире используют и при разработке «в одного»
У админов разделение все же шире.
Хорошо описано чем отличаются админы тут по соседству:
habrahabr.ru/company/okmeter/blog/349610/#comment_10683060
И если в предыдущей парадигме «старый добрый админ» является специалистом по настройке железа и сервисного ПО, а разработчик выдает код, который должен работать в этом конкретном окружении, то в новой парадигме, где разработчик отдаёт «код и описание окружения для его работы», потребовались «другие специалисты», которые будут принимать и обслуживать эти «контейнеры». Совершенно другие навыки, совершенно другой набор инструментов.
DevOps принципиально меняет мир с точки зрения администрирования.
Но слабо с точки зрения разработчиков — ну, среда отладки приближена к среде production. Это же хорошо, меньше багов.
VulvarisMagistralis
22.02.2018 17:36От разработчиков требуются минимальные навыки.
Так как разработчики в системе DevOps являются, хоть квалифицированными, но именно что пользователями.
А админы — должны настроить для пользователей-разработчиков и поддерживать хозяйство.
Другое дело, что таких админов нужно меньше чем разработчиков.
Но мы же говорим о зарплате на 1 человека, а не об фонде оплаты труда (зарплата на 1 человека * количество потребных людей).
GreedyIvan
22.02.2018 14:51+2Раньше production окружение выглядело примерно так
монолитное приложение, работающее в гордом одиночестве на сервере или виртуалке
До появления более-менее приемлемой контейнерезации, которую можно применять в продакшн, перед разработчиками часто стояла непреодолимая стена в виде уже используемых технологий в монолите. И чем объемнее был монолит, тем более железобенной была эта стена.
Использование даже просто обновленной версии какой-либо библиотеки натыкалось на то, что нужно адское количество ресурсов (особенно в железе) затратить на то, чтобы поднять обновленный продакшен без даунтайма. А иметь равноценную продакшену тестовую среду — это была очень большая роскошь.
Микросервисы, но главным образом контейнеризация приложений, решила эту проблему. Разработчик теперь отдаёт приложение с готовым описанием окружения, в котором это приложение как разрабатывается, так и эксплуатируется. А раз разработчик стал давать другой продукт на выходе, то потребовались «другие люди» для работы с этим другим продуктом.
И если в предыдущей парадигме «старый добрый админ» является специалистом по настройке железа и сервисного ПО, а разработчик выдает код, который должен работать в этом конкретном окружении, то в новой парадигме, где разработчик отдаёт «код и описание окружения для его работы», потребовались «другие специалисты», которые будут принимать и обслуживать эти «контейнеры». Совершенно другие навыки, совершенно другой набор инструментов.
И попробовав раз, понимаешь, что мир ИТ эволюционировал. И прошлым мастадонтам уготован лишь очень небольшой и чисто функциональный кусок по поднятию общей облачной инфраструктуры. А на сцене начинают доминировать совершенно другие технологии и навыки. На сцене, для которой вопрос о том, какую выбрать ос для сервера (порождавшем ожесточенные споры), выглядить далеко не первостепенным, если не вообще существенным.VulvarisMagistralis
22.02.2018 15:12На сцене, для которой вопрос о том, какую выбрать ос для сервера (порождавшем ожесточенные споры), выглядить далеко не первостепенным, если не вообще существенным.
Когда же ОС вообще умрут?
Контейнеры все же используют ядро ОС. А вот когда совсем…

samizdam
23.02.2018 12:38На КДПВ чернокожие товарищи не поддерживают контейнер — они держаться за него. Что как бы намекает, что и заголовок статьи спорный.
alek0585
В чем поинт статьи?
VulvarisMagistralis
Присоединяюсь: а о чем вообще статья то.
Введение и основная часть — вообще про разные стороны жизни рассказывают.
Может, автор 2 статьи написать хотел разных, но спутал абзацы.
Singaporian
Поинт статьи в чем угодно, но только не в ее заголовке.
fukkit
какая-то беспоинтовая