
Скрытые марковские модели (Hidden Markov Models) с давних времен используются в распознавании речи. Благодаря мел-кепстральным коэффициентам (MFCC), появилась возможность откинуть несущественные для распознавания компоненты сигнала, значительно снижая размерность признаков. В интернете много простых примеров использования HMM с MFCC для распознавания простых слов.
После знакомства с этими возможностями появилось желание опробовать этот алгоритм распознавания в музыке. Так родилась идея задачи классификации музыкальных композиций по исполнителям. О попытках, какой-то магии и результатах будет рассказано в этом посте.
Мотивация
Желание познакомиться на практике со скрытыми марковскими моделями зародилось давно, и в прошлом году мне удалось привязать их практическое использование с курсовым проектом в магистратуре.
В течение предпроектного гугления была найдена интересная статья, повествующая об использовании HMM для классификации фолк музыки Ирландии, Германии и Франции. Используя большой архив песен (тысячи песен), авторы статьи пытаются выявить существование статистической разницы между композициями разных народов.
Во время изучения библиотек с HMM наткнулся на код из книги Python ML Cookbook, где на примере распознавания нескольких простых слов, использовалась библиотека hmmlearn, которую и решено было опробовать.
Постановка задачи
В наличии песни нескольких музыкальных исполнителей. Задача состоит в обучении классификатора, основанного на HMM, правильному распознаванию авторов поступающих в него песен.
Песни представлены в формате ".wav". Количество песен для разных групп разное. Качество, длительность композиций тоже различаются.
Теория
Для понимания работы алгоритма (какие параметры в каком обучении участвуют) необходимо хотя бы поверхностно ознакомиться с теорией мел-кепстральных коэффициентов и скрытых марковских моделей. Более детальную информацию можно получить в статьях по MFCC и HMM.
MFCC — это представление сигнала, грубо говоря, в виде особого спектра, из которого с помощью различных фильтраций и преобразований удалены незначительные для человеческого слуха компоненты. Спектр носит кратковременный характер, то есть изначально сигнал делится на пересекающиеся отрезки по 20-40 мс. Предполагается, что на таких отрезках частоты сигнала не меняются слишком сильно. И уже на этих отрезках и считаются волшебные коэффициенты.
Есть сигнал

Из него берутся отрезки по 25 мс

И для каждого из них рассчитываются мел-кепстральные коэффициенты

Преимущество этого представления в том, что для распознавания речи достаточно брать около 16 коэффициентов на каждый фрейм вместо сотен или тысяч, в случае обычного преобразования Фурье. Экспериментальным путем выяснено, что для выделения этих коэффициентов в песнях лучше брать по 30-40 компонент.
Для общего понимания работы скрытых марковских моделей можно посмотреть и описание на вики.
Смысл их в том, что есть неизвестный набор скрытых состояний , проявление которых в какой-то последовательности, определяемой вероятностями , с некоторыми вероятностями приводит к набору наблюдаемых результатов .
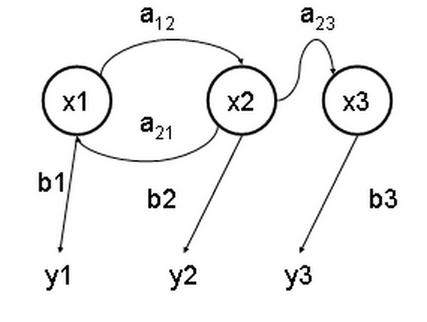
В качестве наблюдаемых результатов в нашем случае выступают mfcc для каждого фрейма.
Алгоритм Баума-Велша (частный случай более известного EM-алгоритма) используется для нахождения неизвестных параметров HMM. Именно он и занимается обучением модели.
Реализация
Приступим, наконец, к коду. Полная версия доступна здесь.
Для расчета MFCC была выбрана библиотека librosa. Также можно использовать библиотеку python_speech_features, в которой в отличие от librosa реализованы только функции, необходимые для расчета мел-кепстральных коэффициентов.
Песни будем принимать в формате ".wav". Ниже представлен функция для расчета MFCC, принимающая на вход имя ".wav" файла.
def getFeaturesFromWAV(self, filename):
audio, sampling_freq = librosa.load(
filename, sr=None, res_type=self._res_type)
features = librosa.feature.mfcc(
audio, sampling_freq, n_mfcc=self._nmfcc, n_fft=self._nfft, hop_length=self._hop_length)
if self._scale:
features = sklearn.preprocessing.scale(features)
return features.T
На первой строке проходит обычная загрузка ".wav" файла. Стерео файл приводится к одноканальному формату. librosa позволяет проводить разный ресемплинг, я остановился на
res_type=’scipy’. На расчет признаков я посчитал нужным указать три основных параметра:
n_mfcc — количество мел-кепстральных коэффициентов, n_fft — число точек для быстрого преобразования Фурье, hop_length — число сэмплов для фреймов (к примеру, 512 сэмплов для 22кГ и выдаст примерно 23мс).Масштабирование — шаг необязательный, но с ним мне удалось сделать классификатор более устойчивым.
Перейдем к классификатору. hmmlearn оказалась неустойчивой библиотекой, в которой с каждым обновлением что-то ломается. Тем не менее, ее совместимость с scikit не может не радовать. На данный момент (0.2.1), Hidden Markov Models with Gaussian emissions — наиболее рабочая модель.
Отдельно хочется отметить следующие параметры модели.
self._hmm = hmm.GaussianHMM(n_components=hmmParams.n_components,
covariance_type=hmmParams.cov_type, n_iter=hmmParams.n_iter, tol=hmmParams.tol)
Параметр
n_components — определяет число скрытых состояний. Относительно неплохие модели можно строить, используя 6-8 скрытых состояний. Обучаются они довольно быстро: 10 песен занимает порядка 7 минут на моем Core i5-7300HQ 2.50GHz. Но для получения более интересных моделей я предпочел использовать около 20 скрытых состояний. Пробовал больше, но на моих тестах результаты несильно менялись, а время обучения увеличилось до нескольких дней при том же количестве песен.Остальные параметры отвечают за сходимость EM-алгоритма, ограничивая число итераций, точность и определяя тип ковариационных параметров состояний.
hmmlearn используется для обучения без учителя. Поэтому процесс обучения строится следующим образом. Для каждого класса обучается своя модель. Далее тестовый сигнал прогоняется через каждую модель, где по нему рассчитывается логарифмическая вероятность
score каждой модели. Класс, которому соответствует модель, выдавшая наибольшую вероятность, и является владельцем этого тестового сигнала.Обучение в коде одной модели выглядит так:
featureMatrix = np.array([])
for filename in [x for x in os.listdir(subfolder) if x.endswith('.wav')]:
filepath = os.path.join(subfolder, filename)
features = self.getFeaturesFromWAV(filepath)
featureMatrix = np.append(featureMatrix, features, axis=0) if len(
featureMatrix) != 0 else features
hmm_trainer = HMMTrainer(hmmParams=self._hmmParams)
hmm_trainer.train(featureMatrix)
Код бегает по папке
subfolder находит все ".wav" файлы, и для каждой из них считает MFCC, которые в последствии просто добавляет в матрицу признаков. В матрице признаков строка соответствует фрейму, столбец соответствует номеру коэффициента из MFCC.После заполнения матрицы создается скрытая марковская модель для этого класса, и признаки передаются в EM-алгоритм для обучения.
Классификация выглядит так.
features = self.getFeaturesFromWAV(filepath)
#label is the name of class corresponding to model
scores = {}
for hmm_model, label in self._models:
score = hmm_model.get_score(features)
scores[label] = score
similarity = sorted(scores.items(), key=lambda t: t[1], reverse=True)
Бродим по всем моделям и считаем логарифмические вероятности. Получаем сортированный по вероятностям набор классов. Первый элемент и покажет, кто наиболее вероятный исполнитель данной песни.
Результаты и улучшения
В обучающую выборку были выбраны песни семи исполнителей: Anathema, Hollywood Undead, Metallica, Motorhead, Nirvana, Pink Floyd, The XX. Количество песен для каждой из них, как и сами песни, выбирались из соображений, какие именно тесты хочется провести.
К примеру, стиль группы Anathema сильно менялся в течение их карьеры, начиная с тяжелого дум-метала и заканчивая спокойным прогрессивным роком. Решено было композиции из первого альбома отправить в тестовую выборку, а более в обучение — более мягкие песни.
Deep
Pressure
Untouchable Part 1
Lost Control
Underworld
One Last Goodbye
Panic
A Fine Day To Exit
Judgement
Hollywood Undead:
Been To Hell
S.C.A.V.A
We Are
Undead
Glory
Young
Coming Back Down
Metallica:
Enter Sandman
Nothing Else Matters
Sad But True
Of Wolf And Man
The Unforgiven
The God That Failed
Wherever I May Room
My Friend Of Misery
Don't Tread On Me
The Struggle Within
Through The Never
Motorhead:
Victory Or Die
The Devil.mp3
Thunder & Lightning
Electricity
Fire Storm Hotel
Evil Eye
Shoot Out All Of Your Lights
Nirvana:
Sappy
About A Girl
Something In The Way
Come As You Are
Endless Nameless
Heart Shaped Box
Lithium
Pink Floyd:
Another Brick In The Wall pt 1
Comfortably Numb
The Dogs Of War
Empty Spaces
Time
Wish You Were Here
Money
On The Turning Away
The XX:
Angels
Fiction
Basic Space
Crystalised
Fantasy
Unfold
Тесты выдавали относительно неплохой результат (из 16 тестов 4 ошибки). Проблемы появились при попытке распознать исполнителя по вырезанной части песни.
Внезапно оказалось, что когда сама композиция классифицируется правильно, ее часть может выдавать диаметрально противоположный результат. Притом, если этот кусок композиции содержит начало песни, то модель выдает правильный результат. Но если он все же начинается с другой части композиции, то модель целиком и полностью уверена, что эта песня никак не относится к нужному исполнителю.
Master Of Puppets (Cut 00:00 — 00:35) to Metallica (True)
Master Of Puppets (Cut 00:20 — 00:55) to Anathema (False, Metallica)
The Unforgiven (Cut 01:10 — 01:35) to Anathema (False, Metallica)
Heart Shaped Box to Nirvana (True)
Heart Shaped Box (Cut 01:00 — 01:40) to Hollywood Undead (False, Nirvana)
Решение искалось долго. Предпринимались попытки обучения на 50 и больше скрытых состояниях (почти трое суток обучений), количество MFCC увеличивалось до сотен. Но ничто из этого не решало проблему.
Проблема решилась весьма суровой, но на каком-то уровне подсознания понятной идеей. Она заключалась в том, чтобы случайным образом перемешивать (shuffle) строки в матрице признаков перед обучением. Результат оправдал себя, ненамного увеличив время обучения, но выдав более устойчивый алгоритм.
featureMatrix = np.array([])
for filename in [x for x in os.listdir(subfolder) if x.endswith('.wav')]:
filepath = os.path.join(subfolder, filename)
features = self.getFeaturesFromWAV(filepath)
featureMatrix = np.append(featureMatrix, features, axis=0) if len(
featureMatrix) != 0 else features
hmm_trainer = HMMTrainer(hmmParams=self._hmmParams)
np.random.shuffle(featureMatrix) #shuffle it
hmm_trainer.train(featureMatrix)
Ниже представлены результаты теста модели с параметрами: 20 скрытых состояний, 40 MFCC, с маcштабированием компонент и shuffle.
We Are Motorhead to Motorhead (True)
Master Of Puppets to Metallica (True)
Empty to Anathema (True)
Keep Talking to Pink Floyd (True)
Tell Me Who To Kill to Motorhead (True)
Smells Like Teen Spirit to Nirvana (True)
Orion (Instrumental) to Metallica (True)
The Silent Enigma to Anathema (True)
Nirvana — School to Nirvana (True)
A Natural Disaster to Anathema (True)
Islands to The XX (True)
High Hopes to Pink Floyd (True)
Have A Cigar to Pink Floyd (True)
Lovelorn Rhapsody to Pink Floyd (False, Anathema)
Holier Than Thou to Metallica (True)
Результат: 2 ошибки из 16 песен. В целом неплохо, хоть и ошибки пугают (Pink Floyd явно не такой тяжелый).
Тесты с вырезками из песен уверенно проходятся.
Master Of Puppets (Cut 00:00 — 00:35) to Metallica (True)
Master Of Puppets (Cut 00:20 — 00:55) to Metallica (True)
The Unforgiven (Cut 01:10 — 01:35) to Metallica (True)
Heart Shaped Box to Nirvana (True)
Heart Shaped Box (Cut 01:00 — 01:40) to Nirvana (True)
Заключение
Построенный классификатор на основе скрытых марковских моделей показывает удовлетворительные результаты, правильно определяя исполнителей для большинства композиций.
Весь код доступен здесь. Кому интересно, может сам попробовать обучить модели на своих композициях. По результатам можно также попытаться выявить общее в музыке разных групп.
Для быстрого теста на обученных композициях, можно посмотреть на крутящийся на Heroku сайт (принимает на вход небольшие ".wav" файлы). Список композиций, на которых обучалась модель с сайта, представлен выше в пункте выше под спойлером.
Комментарии (20)

kolyan
20.03.2018 01:45мне видятся следующие проблемы:
— вы не достаточно заботитесь о том что модель должна не только определять исполнителя, но и отличать от других. Собственно определение уникальных отличительных черт — самый сложный кусок.
— ну блин нельзя полагаться на магию библиотек. я перемешал и оно заработало — в жизни должны быть очень веские доказательства чтоб так делать. Я не математик, но Марковские цепи в моем понимание учат последовательности. Научите рандому — рандом и будут прогнозировать
— разубедите меня, но я не видел рабочей системы распознавания аудио на mfcc и марковских цепях. Туча академических статей, а прикладных правдоподобных решений — просто нет.
Искренне желаю не унывать и останавливать себя если начинаете «перебирать и пробовать» — это не научно)
aslepov78
20.03.2018 10:22— ну блин нельзя полагаться на магию библиотек. я перемешал и оно заработало — в жизни должны быть очень веские доказательства чтоб так делать
Весь ML как раз на том и стоит чтобы чтото там намешать и опа заработало. А почему работает понять невозможно. Если удается найти решение — победителя не судят. А если нет — ну да, вы будете похожи на некудышного повара который кидает в суп все подряд в надежде получить вкусное блюдо.
Sklert Автор
20.03.2018 10:28Спасибо за критику! Про магию библиотек не совсем понял. Копаться внутри тех же hmmlearn, python_speech_features/librosa пришлось долго и неприятно. Насчет shuffle, да, я не решился пока написать полноценное теоретическое обоснование этого выбора. В остальном, к сожалению, согласен. Статей много — приложений мало. Унывать не будем, тема интересная, и идей еще много)
roryorangepants
Для классификации музыки вроде бы хорошо заходят CNN, обученные поверх спектральных фич. Было бы интересно попробовать на том же датасете и сравнить точность.
aslepov78
Ваши CNN уже куда только не заходят. Неужели так трудно принять что нет универсальных серебряных пуль, на роль которой постоянно предлагают нейро-чтототам. Методы которые происходят из предметной области всегда будут эффективнее. HMM как раз такой.
roryorangepants
Это утверждение, основанное на каком-то серьезном paper-е, где кто-то сравнивал современные CNN и HMM на задаче классификации музыки, или так, чисто вбросить на вентилятор?
Потому что в последние пару лет сети уже обогнали всякие GMM-HMM-based модели на крупных бенчмарковых датасетах в других задачах, связанных со звуком, и я не вижу причин, почему в классификации музыки это было бы иначе.
aslepov78
Обогнали в чем, в каких задачах? FFT — это тоже модель, модель сигнала основаная на спектрах, используется в неимоверном кол-ве задач. Следуя вашему наивному высказыванию тоже надо сеточку прикручивать? Так вот и HHM — это модель дважды случайного сигнала. Логично же что сигнал с музыкой таковым является в каком то приближении. Методы предметной области всегда будут давать результаты лучше.
roryorangepants
Во-первых, причём здесь FFT вообще? Я не давал никаких общих утверждений. Я даже не говорил, что CNN будут работать лучше HMM. Просто высказал гипотезу, что на данной конкретной задаче сети будут работать лучше (и сейчас, погуглив, я уже уверен в этом).
Во-вторых, если вам интересно, в каких задачах сети обогнали более старые методы, вот стандартные примеры: speech recognition и speaker recognition. Также достаточно мощные результаты сети показывают в задачах voice activity detection, trigger word detection, sound classification.
Есть только один метод для того, чтобы определить state-of-the-art-метод — сравнить на реальных задачах. А «логично, что...» — это не доказательство.
aslepov78
fft — модель данных, не лучше не хуже GMM-HMM-based. Общее утверждение вы высказали:
— снова наивное утверждение «из гугла». В частности, в speech recognition, используется целая комбинация различных методов. Там и HMM, и FFT и чего только нет. Да, там есть и нейро сети. Но говорить что нейросети лучше HMM — это как сравнивать трактор с формулой 1. А вы это заявляли:
roryorangepants
Мне кажется, вы видите то, что хотите, а не то, что я реально написал. Давайте продолжим цитату, которую вы привели уже дважды:
Я не говорю, что «нейронные сети в целом лучше HMM». Я говорю, что на конкретных задачах и датасетах сейчас сети являются state-of-the-art.
FFT — не модель данных, а алгоритм преобразования сигнала, и к предмету спора он не имеет ни малейшего отношения.
Сударь, но если вы посмотрите на топовые решения последних нескольких лет, то увидите, что там уже не классические GMM-HMM-модели, а как раз таки deep learning (местами в комбинации с HMM, действительно, а местами, как в статье с SotA-результатами по ссылке, и сам по себе).
Зачем отрицать факт того, что это работает лучше при наличии достаточного объема данных и вычислительных мощностей (но в 2018 году этого вдоволь)?
aslepov78
Ну неконкретные задачи я надеюсь мы не будем обсуждать. state-of-the-art — под этот красивый слоган любой процесс поиска решания можно подогнать.
Я хочу конкретики, а вы уклоняетесь от нее. Вы сказали слова «сети уже обогнали». Я задал вопрос — в чем? Ответа нет.
Сударь, вот тут вы правы. Заменим FFT на просто ряд Фурье, надеюсь это уже будет моделью. Но так как эта модель есть результат FFT — то это уже имеет отношения к предмету диалога.
А это уже смешно. Да при наличии достаточного времени ( а это и есть выч ресурс) и памяти — я вообще любую задачу решу, тупо перебором. И мне нейросети не нужны при этом. Проблема в том что этих ресурсов всегда мало. И если есть более точный и быстрый метод — то он лучше. И все его ищут. Но некоторые совершенно не хотят копать предметную область, они уверовали в серебряные пули, большие объемы данных, как бы симуляцию мозга нейросетями. Я понял вашу веру, удачи вам.
roryorangepants
Это шутка? Я привёл конкретный список задач на два комментария выше. Я привёл конкретную статью с SotA speech recognition в комментарии, на который вы прямо сейчас отвечаете. Вы точно читаете, что я вам пишу?
Нет, потому что в сообщении, к которому вы придрались, я просто предложил сравнить представленный в статье метод с сетями. Причём здесь FFT, который так или иначе используется при работе со звуком для feature extraction, а не для самого моделирования — ума не приложу.
Самое вкусное подсветил жирным. Если это действительно так, то почему на том же ImageNet последние пять лет побеждают сети? С учётом абсурдности конкретно данного утверждения обсуждать следующую часть комментария смысла вроде нет.
aslepov78
Уважаемый, вам надо в ответ статьи по успешным применениям HMM? И т.о. мы нанем соревнование по гуглению? Конечно я не собираюсь читать что вы там нагуглили. Точка зрения — это сумма опыта. Ваш мне понятен.
Вы сказали при наличии достаточного кол-ва ресурсов. Что считать достаточноым будем? На ImageNet сети соревнуются с сетями, как намекает само название. Попробуйте посоревнуйтесь с алгоритмами поиска лица в фотокамерах одними только сетями вашими.
roryorangepants
Ну и как с вами тогда общаться?
У меня такое чувство, что вы впервые слышите про ImageNet и в целом не особо интересуетесь темой компьютерного зрения в частности. Иначе бы вы такого не писали, конечно.
aslepov78
Никак, я не настаивал. Читать спам который вы считаете высшим знанием — извините нет. По любым методам тонны статей. Отвечать ссылками можно только когда вас просят, иначе считаю это отсутствием аргументации.
Да будет вам известно что CV — это не синоним нейросетей или машинленинга. ImageNet — слышал, интереса не имею.
Прикольная логика )
Sklert Автор
На самом деле, после долгой работы с CNN в сегментации изображений, Вы открыли мне, что они еще и со звуком хорошо заходят. Я думал, к звуку больше рекуррентные относят. Но гугл меня и вправду обеспечил чтивом на несколько выходных вперед)
Не уверен, что CNN стоит проверять на том же столь малом датасете, где меньше сотни песен. Насколько мне известно, CNN выигрывает на гигантских датасетах, уступая на мелких сетах тем же SVM и деревьям.
В любом случае, проверить это можно лишь на практике)
roryorangepants
Да, на таком маленьком датасете сеть ничему не научится, но в принципе для этой задачи не особо сложно скомпилировать большой датасет, просто выкачав дискографии нескольких групп.
aslepov78
Вот вам еще открытие — звук можно представить в виде картинок. А картинку — наоборот в виде сигнала. Ну конечно можно что угодно применить к чему угодно. И HMM можно применить к картинкам, причем в этом будет вполне рациональный смысл. Конкретная область где это делают — классификация текстур.
Sklert Автор
Печально, что после прочтения поста, вы решили, что это для меня "открытие". Применить можно все ко всему, как вы и сказали. Хоть прямо на битах все обучай. Интересно то, какие результаты подобные методы выдают, насколько требовательны к датасету, сколько времени тратится на обучение.
aslepov78
Рад что вы это понимаете. Тогда вы должны понять, что высказывание «нейро-мега-магик сеть А хорошо работает на звуке» — на столько же глупо на сколько «трактор лучше формулы 1».
Звуки разные, их природа разная, они имеют каскадно сложную модель, от семантики языка (если это речь), до акустики и спектров. И тут раз какая то магик сеть решает все задачи разом? Ну правда бред.