REST становится общим подходом для представления сервисов окружающему миру. Причина его популярности заключается в его простоте, легкости использования, доступе через HTTP и другие. Существует неправильное представление о том, что все данные, доступные через сеть, считаются REST, но это не так. В этой статье я собираюсь объяснить вам некоторые best practices, которые вы должны всегда помнить при реализации собственного REST приложения. Я бы хотел услышать ваш опыт в REST приложениях, поэтому если вы знаете best practies, которые не упомянуты в этой статье, пожалуйста, поделитесь с нами в комментариях.
Disclamer: все best practies основаны на моем личном опыте. Если вы имеете другое мнение, не стесняйтесь отправлять его мне на email, и мы обсудим его.
Здесь представлен список best practices, которые будут обсуждаться в этой статье:
1. Конечные точки в URL – имя существительное, не глагол
2. Множественное число
3. Документация
4. Версия вашего приложения
5. Пагинация
6. Использование SSL
7. HTTP методы
8. Эффективное использование кодов ответов HTTP
1. Конечные точки в URL – имя существительное, не глагол
Одна из самых распространённых ошибок, которую делают разработчики REST приложений, — использование глаголов при именовании конечных точек. Однако, это не лучшая практика. Вы должны всегда использовать существительные вместо глаголов.
Пример сценария:
Мы имеем заказ на разработку REST веб сервисов, которые предоставляют информацию об Индийских фермерах. Сервис также должен реализовывать функционал, предоставляющий такую информацию как доход фермера, названия культур, адреса ферм и другую информацию, относящуюся к каждому фермеру. Каждый фермер имеет уникальный id.
Таким же образом должны быть реализованы сервисы, предоставляющие информацию о культурах и какой фермер владеет ими.
Best Practice:
Имеем единственную конечную точку, которая отвечает за все действия. В примере ниже представлена только одна конечная точка /farmers для всех операций таких как добавление, обновление, удаление. Базовые реализации имеют различные HTTP методы, которые правильно маршрутизируются для разных операций.
• /farmers
• /crops
Не рекомендуется:
Постарайтесь избегать использования глаголов. Рекомендуется представлять операции внутри таких форматах как JSON, XML, RAML или использовать HTTP методы. Не используйте представленные ниже обозначения:
• /getFarmers
• /updateFarmers
• /deleteFarmers
• /getCrops
• /updateCrops
• /deleteCrops
2. Множественное число
Используйте множественное число для названия своих REST сервисов. Это еще одна горячая тема для обсуждений среди REST дизайнеров – выбор между единственными или множественными формами существительных для обозначения сервисов.
Best Practice:
• /farmers
• /farmers/{farmer_id}
• /crops
• /crops/{crop_id}
Не рекомендуется:
• /farmer
• /farmer/{farmer_id}
Примечание:
Хотя я упоминаю, что использование множественного числа является best practice, по какой-то причине, если вы придерживаетесь единственного числа, то придерживайтесь этого во всех своих сервисах. Не смешивайте использование множественного и единственного чисел. Поэтому я и не говорю здесь про bad practice, а просто говорю, что это не рекомендуется. Пожалуйста, решайте сами, что лучше подходит для вашего приложения.
3. Документация
Документирование программного обеспечения является общей практикой для всех разработчиков. Этой практики стоит придерживаться и при реализации REST приложений. Если писать полезную документацию, то она поможет другим разработчикам понять ваш код.
Наиболее распространенным способом документирования REST приложений – это документация с перечисленными в ней конечными точками, и описывающая список операций для каждой из них. Есть множество инструментов, которые позволяют сделать это автоматически.
Ниже представлены приложения, которые помогают документировать REST сервисы:
• DRF Docs
• Swagger
• Apiary
Пожалуйста, поделитесь своим опытом документирования ваших приложений в комментариях.
4. Версия вашего приложения
Любое программное обеспечение развивается с течением времени. Это может потребовать различных версий для всех существенных изменений в приложении. Когда дело доходит до версии REST приложения, то оно становится одной из самых обсуждаемых тем среди сообщества разработчиков REST.
Существует два общих способа для управления версиями REST приложений:
1. URI версии.
2. Мультимедиа версии.
URI версии:
Простой пример как выглядит URI версия:
host/v2/farmers
host/v1/farmers
Ниже приведены основные недостатки способа создания версий с использованием URI:
- Разбиваются существующие URIs, все клиенты должны обновить до нового URI.
- Увеличивается количество URI версий для управления, что в свою очередь увеличивает размер HTTP кэша для хранения нескольких версий URI. Добавление большого числа дубликатов URI может повлиять на количество обращений к кэшу и тем самым может снизить производительность вашего приложения.
- Он крайне негибкий, мы не можем просто изменить ресурс или небольшой их набор.
Мультимедийный способ управления версиями:
Этот подход отправляет информацию о версии в заголовке каждого запроса. Когда мы изменим тип и язык мультимедиа URI, мы перейдем к рассмотрению контента на основе заголовка. Этот способ является наиболее предпочтительным вариантом для управления версиями REST приложений.
Пример информации в заголовке:
GET /account/5555 HTTP/1.1
Accept: application/vnd.farmers.v1+json
HTTP/1.1 200 OK
Content-Type: application/vnd.farmers.v1+json
В мультимедийном подходе управления версиями клиент имеет возможность выбрать, какую версию запрашивать с сервера. Этот способ выглядит предпочтительней, чем подход с URI, но сложность возникает при кэшировании запросов с различными версиями, которые передаются через заголовок. Говоря простыми словами, когда клиент кэширует на основе URI, это просто, но, кэширование с ключом в качестве мультимедийного типа добавляет сложности.
5. Пагинация
Отправка большого объема данных через HTTP не очень хорошая идея. Безусловно, возникнут проблемы с производительностью, поскольку сериализация больших объектов JSON станет дорогостоящей. Best practice является разбиение результатов на части, а не отправка всех записей сразу. Предоставьте возможность разбивать результаты на странице с помощью предыдущих или следующих ссылок.
Если вы используете пагинацию в вашем приложении, одним из хороших способов указать ссылку на пагинацию является использование опции Link HTTP заголовка.
Следующая ссылка будет полезной для вас.
6. Использование SSL
SSL должен быть! Вы всегда должны применять SSL для своего REST приложения. Доступ к вашему приложения будет осуществляется из любой точки мира, и нет никакой гарантии, что к нему будет обеспечен безопасный доступ. С ростом числа инцидентов с киберпреступностью мы обязательно должны обеспечить безопасность своему приложению.
Стандартные протоколы проверки аутентификации облегчают работу по защите вашего приложения. Не используйте базовый механизм аутентификации. Используйте Oauth1.Oa или Oaurh2 для лучшей безопасности ваших сервисов. Я бы рекомендовал Oauth2 лично из-за его новейших функций.
7. HTTP методы
Проектирование операций на HTTP методы становится легче, когда вы знаете характеристики всех методов HTTP. В одном из предыдущих разделов этой статьи я настаивал на использовании HTTP методов для операций вместо написания различных наименований сервисов для каждой операции. В этом разделе в основном рассматривается поведение каждого HTTP метода.
Ниже представлены две характеристики, которые должны быть определены перед использованием HTTP метода:
- Безопасность: HTTP метод считается безопасным, когда вызов этого метода не изменяет состояние данных. Например, когда вы извлекаете данные с помощью метода GET, это безопасно, потому что этот метод не обновляет данные на стороне сервера.
- Идемпотентность: когда вы получаете один и тот же ответ, сколько раз вы вызываете один и тот же ресурс, он известен как идемпотентный. Например, когда вы пытаетесь обновить одни и те же данные на сервере, ответ будет таким же для каждого запроса, сделанного с одинаковыми данными.
Не все методы являются безопасными и идемпотентными. Ниже представлен список методов, которые используются в REST приложениях и показаны их свойства:
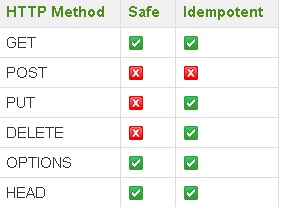
REST HTTP методы
Ниже приведен краткий обзор каждого метода и рекомендации по их использованию:
- GET: этот метод является безопасным и идемпотентным. Обычно используется для извлечения информации и не имеет побочных эффектов.
- POST: этот метод не является ни безопасным, ни идемпотентным. Этот метод наиболее широко используется для создания ресурсов.
- PUT: этот метод является идемпотентным. Вот почему лучше использовать этот метод вместо POST для обновления ресурсов. Избегайте использования POST для обновления ресурсов.
- DELETE: как следует из названия, этот метод используется для удаления ресурсов. Но этот метод не является идемпотентным для всех запросов.
- OPTIONS: этот метод не используется для каких-либо манипуляций с ресурсами. Но он полезен, когда клиент не знает других методов, поддерживаемых для ресурса, и используя этот метод, клиент может получить различное представление ресурса.
- HEAD: этот метод используется для запроса ресурса c сервера. Он очень похож на метод GET, но HEAD должен отправлять запрос и получать ответ только в заголовке. Согласно спецификации HTTP, этот метод не должен использовать тело для запроса и ответа.
8. Эффективное использование кодов ответов HTTP
HTTP определяет различные коды ответов для указания клиенту различной информации об операциях. Ваше REST приложение могло бы эффективно использовать все доступные HTTP-коды, чтобы помочь клиенту правильно настроить ответ. Далее представлен список кодов ответов HTTP:
- 200 OK — это ответ на успешные GET, PUT, PATCH или DELETE. Этот код также используется для POST, который не приводит к созданию.
- 201 Created — этот код состояния является ответом на POST, который приводит к созданию.
- 204 Нет содержимого. Это ответ на успешный запрос, который не будет возвращать тело (например, запрос DELETE)
- 304 Not Modified — используйте этот код состояния, когда заголовки HTTP-кеширования находятся в работе
- 400 Bad Request — этот код состояния указывает, что запрос искажен, например, если тело не может быть проанализировано
- 401 Unauthorized — Если не указаны или недействительны данные аутентификации. Также полезно активировать всплывающее окно auth, если приложение используется из браузера
- 403 Forbidden — когда аутентификация прошла успешно, но аутентифицированный пользователь не имеет доступа к ресурсу
- 404 Not found — если запрашивается несуществующий ресурс
- 405 Method Not Allowed — когда запрашивается HTTP-метод, который не разрешен для аутентифицированного пользователя
- 410 Gone — этот код состояния указывает, что ресурс в этой конечной точке больше не доступен. Полезно в качестве защитного ответа для старых версий API
- 415 Unsupported Media Type. Если в качестве части запроса был указан неправильный тип содержимого
- 422 Unprocessable Entity — используется для проверки ошибок
- 429 Too Many Requests — когда запрос отклоняется из-за ограничения скорости
Резюме
Надеюсь, эта статья будет полезна для понимания того, как создать свой REST API. Здесь представлены best practices, собранные на основе моего опыта и обсуждения с друзьями, которые работали над приложениями веб-служб REST.
Если вы много работали над дизайном REST API, и, если вы чувствуете, что эта статья не имеет для вас никакого смысла, я рад услышать ваши отзывы. Я хотел бы продолжить обновление этого обсуждения с помощью более проверенных методов разработки лучшего API для вашего приложения.
Хорошего прочтения. Спасибо за посещение моего блога.
Комментарии (183)

1goblin
23.03.2018 18:18Для telecom-а есть есть такая организация, как TM Forum, которая определяет некоторые стандарты.
В том числе и на REST API
По этой ссылке — рекомендации да дизайн API.
www.tmforum.org/resources/standard/tmf630-api-design-guidelines-3-0-r17-5-0
Придется зарегистрироваться.

titulusdesiderio
23.03.2018 19:26+28) забыли про 500х коды. И вообще про коды тут пункт ниочём. список HTTP статусов можно и на википедии посмотреть.
Мой бестпрактис касательно кодов: В самой первой версии апи сделайте поддержку 4х статусов
- 200 — ок
- 400 — неправильный запрос
- 404 — не найдено результатов
- 500 — внутренняя ошибка сервера
Этого достаточно на первое время, а если у вас есть бюджет вы всегда сможете расширить этот список. Главное — поддержать хотя бы их.
5) пагинация через link — имхо это даже бэд практис в некоторых случаях. Если мы предоставляем
limit/offset(skip/size и т.п.) — то этого более чем достаточно для пагинации, и создание линков усложняет код, не привнося никакого дополнительного функционала (ведь пагинация и так есть). А вот отказываться отlimit/offsetв пользу линков — плохая идея. мы заведомо ограничиваем возможности клиента, не привнося ничего взамен.
7) А что за путаница у него в методах и их индепендности? и счего бы вдруг GET был индепендным? запросив одну и ту же книгу с разницей в несколько секунд, у неё может измениться статус или рейтинг. Но это уже мелочь
mayorovp
23.03.2018 19:29-1Если уж делать совсем-совсем REST, то пагинацию надо делать через Range :-)

powerman
24.03.2018 00:05+17) А что за путаница у него в методах и их индепендности?
Идемпотентности, а не индепендности. А путаница вызвана тем, что в статье дано некорректное определение:
Идемпотентность: когда вы получаете один и тот же ответ, сколько раз вы вызываете один и тот же ресурс, он известен как идемпотентный.
Корректное можно найти в википедии, и оно совсем про другое:
Идемпотентная операция в информатике — действие, многократное повторение которого эквивалентно однократному.
Примером такой операции могут служить GET-запросы в протоколе HTTP. По спецификации, сервер должен возвращать одни и те же ответы на идентичные запросы (при условии, что ресурс не изменился между ними по иным причинам). Такая особенность позволяет кэшировать ответы, снижая нагрузку на сеть.Между выделенными жирным определениями есть принципиальная разница. При повторе запроса ответы могут отличаться. Один пример: упомянутое в википедии изменение (не из-за выполнения самого GET) запрашиваемого GET-ом ресурса между запросами. Другой пример: выполнение DELETE объекта с неким id — первый запрос может вернуть 204 No Content а последующие 404 Not Found, но при этом многократное удаление не отличается от однократного в том смысле, что в обоих случаях результат одинаковый — объект с этим id более не существует.
По сути, идемпотентные запросы полезны тем, что их можно безопасно автоматически повторять при необходимости (напр. из-за сетевых ошибок).
titulusdesiderio
24.03.2018 09:57ого. большое спасибо! Ваш комментарий был для меня на порядок полезнее статьи (:

YemSalat
25.03.2018 03:11Идемпотентность: когда вы получаете один и тот же ответ, сколько раз вы вызываете один и тот же ресурс
Идемпотентная операция в информатике — действие, многократное повторение которого эквивалентно однократному.
Четное слово, не понимаю разницу между этими двумя определениями в контексте REST, можете пожалуйста объяснить?
[EDIT]
Перечитал ваш комментарий, вопрос снимается.

evgenyk
23.03.2018 19:38+1Насчет кодов. А что уважаемые господа думают о следующей схеме:
Например для GET — если сам запрос прошел удачно, но оибку в бизнес логике, возврещается HTTP код 200 и документ с полем ошибка, описанием ошибки и кодом ошибки (код ошибки не HTTP, а самой системы).
Иначе получается путаница транспортного уровня (HTTP) и уровня бизнес логики.titulusdesiderio
23.03.2018 20:13ошибки бизнесс-логики — это 500 ошибки.
evgenyk
24.03.2018 01:05Из русской вики:
Коды 5xx выделены под случаи неудачного выполнения операции по вине сервера.titulusdesiderio
24.03.2018 09:59+2Ошибка бизнесс-логики — это ошибка сервера. То что вы её аккуратно отлавливаете — не значит что она не происходила.

lair
23.03.2018 21:01… и клиенту нужно каждый раз парсить содержимое поле "ошибка". Спасибо, нет.
dmitry_dvm
24.03.2018 00:57+3Лучше проверять Errors!=null, чем заворачивать условный HttpClient в трайкэтчи и проверять все варианты ошибок, расписывать на каждую свое действие и так же парсить поле «ошибка»плюс принудительно отключать эксепшены на неуспешные ответы и каждый раз проверять IsSuccess. Вы просто с одной стороны баррикады рассматриваете, видимо. Со стороны клиента во много раз удобнее получать всегда один и тот же ответ и просто проверять в нем одно поле.
lair
24.03.2018 01:02+2чем заворачивать условный HttpClient в трайкэтчи
А зачем это делать, если не секрет?
Со стороны клиента во много раз удобнее получать всегда один и тот же ответ и просто проверять в нем одно поле.
Знаете, я регулярно пишу и SOAP и REST-клиенты. Так что нет, лично мне намного удобнее, когда бросят эксепшн при неудачном логине, чем если я забуду проверить, что логин удачный, и получу ошибку уже потом, при запросе.

flancer
24.03.2018 09:02+1А зачем это делать, если не секрет?
Не секрет — "проверять все варианты ошибок"
лично мне намного удобнее, когда бросят эксепшн при неудачном логине
Только если вам нет нужды объяснять user'у перед экраном, что же, собственно, произошло нехорошего на той стороне интернета, из-за чего самый важный и срочный запрос в его жизни не проходит. Причем в максимально удобной и понятной для него форме, чтобы он самостоятельно вырулил из сложившейся ситуации и по-возможности минимально вынес мозг call-центру. А так — да, для разговоров "server-to-server" достаточно в лог скинуть сообщение и стектрейс.
lair
24.03.2018 12:21Не секрет — "проверять все варианты ошибок"
Так для этого
try..catchне нужен, достаточно обработать код возврата.
Только если вам нет нужды объяснять user'у перед экраном [...] А так — да, для разговоров "server-to-server" достаточно в лог скинуть сообщение и стектрейс.
Ну так я и пишу преимущественно unattended-клиенты, и планирую сервера для таких. Другое дело, что использование HTTP-статусов для ошибок позволяет мне выбирать из этих двух способов.
flancer
24.03.2018 15:09Так для этого try..catch не нужен, достаточно обработать код возврата.
© lair
… и клиенту нужно каждый раз парсить содержимое поле "ошибка". Спасибо, нет.
© lairНадеюсь, что "код возврата" это не "содержимое поля 'ошибка'" ;)
lair
24.03.2018 15:20Правильно надеетесь. Я про HTTP Status. В том же .net у вас есть три варианта:
HttpResponseMessage response; // 1 response.EnsureSuccessStatusCode(); //2 if (response.IsSuccessStatusCode()) //3 switch (response.StatusCode)
Выбор между ними зависит от стратегии клиента.
flancer
24.03.2018 16:55Т.е., "код возврата" — это HTTP Status, в котором не предусмотрены ошибки бизнес-логики. Я правильно понимаю, что вы, как клиент, предпочитаете в случае ошибки на уровне бизнес-логики (например, "клиент с таким ИНН уже есть") получить ответ от сервера со статусом 200?
lair
24.03.2018 18:04+2Нет, неправильно. Я предпочитаю получить от сервера релевантный HTTP Status (в зависимости от того, что именно пошло не так), а дополнительную информацию — в теле ответа. Соответственно, ошибка "вы шлете нам невалидный ИНН" будет выражаться либо в 400, либо в 422 (в зависимости от нашего занудства), а уже в теле будет написано "дублирующийся ИНН", или
INN: "duplicate", или в меру нашего извращения.flancer
24.03.2018 20:15-3и клиенту нужно каждый раз парсить содержимое поле "ошибка". Спасибо, нет.
© liar
а уже в теле будет написано "дублирующийся ИНН", или INN: "duplicate", или в меру нашего извращения.
© liarулыбнуло.
lair
24.03.2018 20:23+3… а что вас "улыбнуло"-то? В этой схеме для того, чтобы понять, что запрос невалиден, не надо парсить тело ответа.
flancer
24.03.2018 21:53-1А тело ответа — оно зачем в таком случае? Либо его тоже нужно парсить, и тогда ваше "Спасибо, нет" неуместно, либо его парсить не нужно и тогда, согласно старику Оккаму, неуместно само тело. Вот это и улыбнуло.
lair
24.03.2018 23:25А тело ответа — оно зачем в таком случае?
Для тех ситуаций, когда нам нужна дополнительная информация об ошибке (а не только сам факт, что она произошла).
flancer
25.03.2018 11:10но оибку в бизнес логике, возврещается HTTP код 200 и документ с полем ошибка, описанием ошибки и кодом ошибки (код ошибки не HTTP, а самой системы).
Вот за то коллега evgenyk и говорил. Если ошибка бизнес-логики, значит пользователь что-то сделал не так, как предусматривалось разработчиками, и ему нужна дополнительная информация, чтобы он сам мог разрулить ситуацию (если она разруливаемая), которая через состояния HTTP-статуса не передается. Очень редко, когда пользователь остается доволен, видя на экране надпись "Ошибка 500. Обратитесь в службу поддержки".
Я понимаю, откуда ноги растут у вашего "и клиенту нужно каждый раз парсить содержимое поле "ошибка". Спасибо, нет." — вы серверный разработчик с соответствующим взглядом на разработку.
lair
25.03.2018 11:14Если ошибка бизнес-логики, значит пользователь что-то сделал не так,
Совершенно не обязательно. Собственно, у вас вообще может не быть человеческого пользователя.
ему нужна дополнительная информация, чтобы он сам мог разрулить ситуацию (если она разруливаемая), которая через состояния HTTP-статуса не передается
Ничего не мешает передавать дополнительную информацию вместе с кодом 500 — таким образом мы получим API, который удобнее для неинтерактивных клиентов, но ничем не хуже для интерактивных.
flancer
25.03.2018 14:01+1С точки зрения backend-разработчика человеческого пользователя нет всегда. Но это ограниченная точка зрения.
С точки зрения forntend-разработчика (в частности, разработчика SPA) человеческий пользователь есть слишком часто, чтобы его игнорировать. Разделение ошибок на 500-е (т.е., любые ошибки, не предусмотренные логикой операции, которые произошли в момент выполнения зпроса на сервере) и на ошибки бизнес-логики, зависящие от конкретной запрошенной операции (200-е с необходимостью анализа содержимого поля "ошибка") позволяют запускать на клиенте сценарии решения ошибочной с точки зрения бизнес-логики ситуации с использованием полученных с сервера данных.
Другими словами, 500-я ошибка — это всегда тупиковая ошибка. Ее обработка и на неинтерактивном клиенте и на интерактивном одинакова — логируем / показываем пользователю сообщение, что все плохо. Код ошибки в 200-м ответе сигнализирует, что выполнение запрошенной операции на сервере пошло по одному из предусмотренных разработчиками сценариев, не обеспечивающих успешного завершения в силу каких-то условий. В этом случае пользователь (интерактивный) или программа (неинтерактивный) может выполнить некоторые дополнительные действия, после чего повторить операцию.
То есть, если сценарий выполнения операции предусматривает возможность дублирования ИНН и имеются рекомендации для пользователя, что нужно сделать в данном случае — это ошибка бизнес-логики (код 200). Если на сервере при добавлении записи в БД произошла ошибка из-за того, что в таблице на поле ИНН повешен ключ уникальности, а записывались данные с повторяющимся значением ИНН, которая перехватилась и обернулась в типовое сообщение об ошибке на уровне REST framework'а, потому что разраб сервиса даже не предполагал такого варианта — это 500-я ошибка.
Почему не передавать все ошибки через 500-й код? Потому что в таком случае смешивают обычные ошибки (как правило выполнение операции невозможно по независящим от клиента обстоятельствам) и ошибки бизнес-логики (зачастую операция возможна при внесении некоторых изменений в данные или предварительном выполнении других операций), очень сильно привязанные к контексту текущих выполняемых действий (т.е. к тому же контексту, в котором на клиенте происходит дальнейшая обработка данных, полученных с сервера в результате успешного завершения операции с кодом 200).
Есть мнение, что ошибки валидации входных данных не являются ошибками, как таковыми — это предусмотренный сценарий взаимодействия. Эту точку зрения можно распростанить и на ошибки бизнес-логики, предусмотренные разработчиками сервисов. Все остальное — настоящие ошибки, 500-й код, окончательный тупик.
lair
25.03.2018 14:12С точки зрения backend-разработчика человеческого пользователя нет всегда. Но это ограниченная точка зрения.
Это, очевидно, неправда — это я вам говорю как backend-разработчик.
Есть мнение, что ошибки валидации входных данных не являются ошибками, как таковыми — это предусмотренный сценарий взаимодействия.
Они являются ошибками, но не являются исключениями. Я выше уже приводил пример: если во входящем сообщении нет необходимого поля — это какая ошибка (или исключение)?
Разделение ошибок на 500-е (т.е., любые ошибки, не предусмотренные логикой операции, которые произошли в момент выполнения зпроса на сервере) и на ошибки бизнес-логики, зависящие от конкретной запрошенной операции (200-е с необходимостью анализа содержимого поля "ошибка") позволяют запускать на клиенте сценарии решения ошибочной с точки зрения бизнес-логики ситуации с использованием полученных с сервера данных.
Зато теперь все промежуточные системы потеряли возможность логировать "ошибки бизнес-логики", потому что они не знают, как их выделить из успешных ответов.
Знаете, у меня вот есть маленький проект, который интегрировался с тремя системами. Все они возвращали сообщения об ошибках с соответствующими кодами HTTP (4xx и 5xx). Когда мне понадобилась диагностика, я поставил стандартный модуль, который делает автотрассировку HTTP-вызовов, и сразу увидел статистику успешных и неуспешных вызовов (а для неуспешных — еще и тела ответов). А потом я добавил туда интеграцию со Slack, который возвращает ошибки в теле ответа с кодом 200. Мне пришлось пойти и дописать специальную обработку такого тела в диагностическую мидлварь (и теперь я вынужден, униформности ради, парсить тело дважды, тоже мило).
flancer
25.03.2018 14:33А универсального решения, устраивающего всех, нет. Если работаешь в разнородной среде то ради униформности чего только не приходится делать. Это вы ещё на фронт не залазили.
lair
25.03.2018 14:35Если работаешь в разнородной среде то ради униформности чего только не приходится делать.
Так вот, один из критериев, упомянутых Филдингом — это униформный интерфейс. Возврат 2xx в случае, если произошла ошибка — нарушение униформности.
VolCh
25.03.2018 15:04-1возврат 4xx в случае отправки клиентом корректного запроса, который сервер не может обработать из-за каких-то внутренних бизнес-правил точно нарушение униформности.
lair
25.03.2018 15:06+1Во-первых, как вы определяете "корректный" запрос?
Во-вторых:
The 422 (Unprocessable Entity) status code means the server understands the content type of the request entity (hence a 415(Unsupported Media Type) status code is inappropriate), and the syntax of the request entity is correct (thus a 400 (Bad Request) status code is inappropriate) but was unable to process the contained instructions. For example, this error condition may occur if an XML request body contains well-formed (i.e., syntactically correct), but semantically erroneous, XML instructions.
VolCh
25.03.2018 20:05Корректный — соответствующий ожидаемой схеме, json schema, xml dtd, xml schema, просто какая-то чистая функция от http-запроса. Максимум из проверки состояния (читай обращения к базе) сервера — проверка прав, и то подвопросом в случае с jwt или аналогов с правами в запросе.
lair
25.03.2018 20:53Иными словами, вы не признаете приведенное выше определение 422 кода?
VolCh
25.03.2018 21:24именно, что признаю. 422 для велл-формед xml, но не соответствующего dtd/schema, 400 для недесериализуемого json, 422 для десериализуемого, но не соответствующего схеме. 200 со телом типа {status: «domain-error», message: «tax identifier already exists»}
lair
25.03.2018 21:26422 для велл-формед xml, но не соответствующего dtd/schema,
Противоречит моей цитате. Несоответствие схеме — это не семантическая ошибка. Там не зря написано "unable to process the contained instructions". Я вам более того скажу, хороший современный модел-биндер вход, не соответствующий схеме, сразу завернет обратно с 400 просто чтобы избежать атаки.
VolCh
25.03.2018 19:53Вот, для меня HTTP ошибка — это исключение уровня контроллера в MVC. Контроллер не смог преобразовать http запрос в вызов метод(ов) модели.
lair
25.03.2018 20:52Ну то есть то, будет возвращено 4хх или 2хх, зависит исключительно от того, насколько умной вы сможете сделать валидацию до контроллера?

velvetcat
24.03.2018 10:55Плюс к экзепшенам, правильно разделенных по типам. Они позволяют строить действительно структурированный код. Если ошибка при вызове метода API была на уровне транспорта (а в случае REST API это еще надо разобраться, ха-ха) — бросаем исключение технического типа и не обрабатываем его на уровне бизнес-логики.

mexahuk61
24.03.2018 02:40+2Если у вас клиент кидает исключение, при ответе сервера статусом 500, то смените клиент или свое представление о работе http протокола
titulusdesiderio
24.03.2018 10:19+1Я фулстек разработчик, с даже бОльшим опытом во фронте. так что я рассматриваю с двух сторон баррикады.
на клиенте нам важно знать получилось ли выполнить операцию или не получилось. получилось — только для статусов 200
всё остальное (и не важно, пропала сеть, неправльный урл, ошибка сервера, ошибка БЛ, да хоть апокалипсис) — это не получилось, тобишь ошибка.
Вы же предлагаете примешать некоторые ошибки к неошибкам что бы вместо одной проверки удалось/неудалось делать их кучу даже в том коде который должен выполняться когда «удалось».
вы заведомо пытаетесь усложнить код. усложнить состояние приложение. ввести ситуации когда у нас есть не только fail/success а ещё и «какбы success, но немножко fail»velvetcat
24.03.2018 11:05+1всё остальное (и не важно, пропала сеть, неправльный урл, ошибка сервера, ошибка БЛ, да хоть апокалипсис) — это не получилось, тобишь ошибка.
Крайне, крайне ограниченный подход. Вам, как минимум, надо знать, произошла ли ошибка по вине сервера (и можно попробовать позже) или клиента (повторять такой же запрос бессмысленно).
titulusdesiderio
24.03.2018 11:16-1так это отлично 400х 500х кодами решается
например на условный
POST: /users/123/im {text: 'hello'}
500{ok: false, message: 'SMTP relay fail: code 1234', trace: ['/path/to','/bla/bla','/lib/smtp',...]}— ошибка кода. когда возник необработанные ексепшн
или 500:
{ok: false, message: 'user is not activated yet'}— ошибка бизнесс-логики, когда произошла нештатная ситуация (отправлено сообщение пользователю, но он ещё не активирован)
или 404
{ok: false, message: 'user not found'}— ошибка запроса. пользователя с таким ID нету.
на клиенте все эти ошибки можно обработать адекватно. а можно и не обрабатывать но знать хотя бы что сообщение не доставлено.
а если мы на 2 и 3 случай будем отдавать 200, то клиент будет думать — а, всё ок сообщение доставлено. он даже не узнает об ошибке, если мы отдельно не пропишем обработку псевдо-успешных запросов
dmitry_dvm
24.03.2018 11:26+2Нет, клиент проверяет поле Errors в ответе и если оно не пустое, значит произошла ошибка. Но главное, что он теперь точно знает, что ошибка это не системная и не транспортная. Получается, что неуспешный ответ может прийти только во время отладки (под контролем разработчика) или если всё сломалось. По моему опыту это значительно удобнее.
И да, на бэке это делать геморройнее, чем просто отдавать ошибки хттп, я заморачиваюсь с этим ради удобства клиентов.titulusdesiderio
24.03.2018 11:47+1можно в тело ответа вставлять поле
errorsи при это отдавать правильный статус
а можно отдавать ошибку, но "как будто не ошибку" и на клиенте обрабатывать не только успешные и провалившиеся запросы к серверу, а ещё и "немножко успешные, но чуть-чуть провалившиеся"
Кстати нет, на беке проще отдавать всегда 200 и не париться. HTTP коды вводят для улучшения удобства работы с api
YemSalat
25.03.2018 00:24Нет, клиент проверяет поле Errors в ответе и если оно не пустое, значит произошла ошибка. Но главное, что он теперь точно знает, что ошибка это не системная и не транспортная. Получается, что неуспешный ответ может прийти только во время отладки (под контролем разработчика) или если всё сломалось. По моему опыту это значительно удобнее.
To есть то что клиент теперь не может разбираться в разных категориях ошибок — это по-вашему хорошо? «Удобнее» — возможно (хотя тоже спорно)
Если код < 400 значит ОК, если нет — то ошибка — по-моему еще более простой в реализации на клиенте подход.
Еще такой момент, объясните пожалуйста что вы понимаете под «системная» ошибка, а то создается впечатление что вы с ветряными мельницами боретесь.
И да, на бэке это делать геморройнее, чем просто отдавать ошибки хттп, я заморачиваюсь с этим ради удобства клиентов.
На бэке послать 200 и кастомную ошибку обычно наоборот проще чем нормально настроить RESТ.
У вас похоже сложилось ложное впечатление что вам предлагают использовать статус коды ВМЕСТО поля errors. Это не так, их надо использовать СОВМЕСТНО.VolCh
25.03.2018 01:02системная ошибка — не ожидаемая реакция системы, например, запрос апи по не существующему ендпоинту или отправка неверного шэйпа тела. То есть где-то рассогласования кода или клиента, или ошибка сети, или место на диске кончилось. Такие ошибки обычно обрабатываются глобально в клиенте с сообщениями пользователю типа " обратитесь в саппорт или повторители позже ". А, например, непройденная валидация в модели на сервере — ошибка пользователя, их обычно обрабатывают локально, например подсвечивая поле формы красным.
YemSalat
25.03.2018 01:34Я попросил dmitry_dvm объяснить этот термин потому-что он разделяет понятия «транспортная» и «системная» ошибка.
В вашем же примере — в чем разница между «отправка неверного шэйпа тела» и «непройденная валидация в модели — ошибка пользователя»?lair
25.03.2018 02:11В вашем же примере — в чем разница между «отправка неверного шэйпа тела» и «непройденная валидация в модели — ошибка пользователя»?
Вот как бы да. Вот мы смотрим на тело
{first_name: "John"}— как нам понять, в немlast_nameнет потому, что его не ввели, или потому, что клиентское приложение его не отправило?VolCh
25.03.2018 08:38Не ввели — пустая строка или null
lair
25.03.2018 10:37Во-первых, дефолтный сериализатор в .net из коробки это не различает: на запись вам надо будет выставить флаг, чтобы он так делал, а на чтение вам придется руками разбирать
JObject, чтобы понять, было там значение, или нет. Что хуже, во-вторых, вам придется заставить сделать то же самое каждого вашего клиента — и они не скажут вам за это спасибо. В-третьих, вы только что на пустом месте увеличили накладные расходы: теперь я должен всегда передавать все свойства, даже если заполнено только одно, а представьте, что дело происходит с мобильника.
(и это еще не считая тех, гм, интересных разработчиков, которые решили, что
property: null— это "запишите в свойство null`, а нет свойства — это "не трогайте свойство")VolCh
25.03.2018 12:31-1Не знаю про клиенты .net, но как по мне он должен формировать запрос в соответствии с объявленным сервером API. Если там заявлено, что last-name required & (string|null), а клиент не предоставил, то это 400/422 до, как говорят юристы, рассмотрения дела по существу. Это ошибка клиента, несоблюдение им протокола, аналог попытки вызова метода с неверной сигнатурой, а не недопустимое в данной ситуации действие пользователя. А если не объявлено обязательным, то это уже не ошибка клиента и места 4xx ошибкам нет, ответ должен быть 2xx с результатом или линком на него, а результат вполне может быть типа {status: «error», message: «last-name required in create user command» }.
lair
25.03.2018 12:39Не знаю про клиенты .net, но как по мне он должен формировать запрос в соответствии с объявленным сервером API.
С этим никто не спорит. Но объявленное вами API сложно в реализации.
А если не объявлено обязательным, то это уже не ошибка клиента и места 4xx ошибкам нет, ответ должен быть 2xx
… а где, бишь, это написано, и как с этим соотносится код 422?
Более того, речь как раз о том, что оно объявлено обязательным и непустым, и это значит, что сервер не может различить ситуацию "клиент не передал" от ситуации "пользователь не ввел" — и, как следствие, всегда должен возвращать 400/422.
VolCh
25.03.2018 09:08Если разделять, то транспортная — отсутствие сети, прежде всего.
Отправка неверного шэйпа — например, несоответствие тела json schema — это 400 или 422. Валидация модели — с успешно пройденной валидацией на схему несоответствие каким-то бизнес-правилам, глобальным или для конкретного кейса, требующего, как правило, анализ не только тела запроса, но и текущего стейта приложения. Чёткой грани в общем случае нет, но по дефолту в моих реализациях 400 или 422 это невозможность собрать в контроллере объект типа Command или Query, или просто определить параметры для вызова метода модели. Это в архитектуре, где у контроллера основная функция служить тупым адаптером к слою приложения, преобразовывать http-сообщения.YemSalat
25.03.2018 11:56+1Отправка неверного шэйпа — например, несоответствие тела json schema — это 400 или 422.
Из вашего же примера:
...«поле ОКПО обязательно для типа клиента „юрлицо“» должны приходить с 200 кодом.
На каком уровне будет эта проверка? У вас будет возможность «собрать в контроллере объект типа Command или Query» и пустить его в модель обрабатывать бизнес логику, или он сразу отвалится на уровне валидации, сказав что без нужного поля в теле запроса он не пройдет?VolCh
25.03.2018 12:48Это зависит от APIs и http-ендпоинта, и домена, решение времени проектирования APIs. Как правило, валидация в ендпоинте не зависит от состояния домена, с одной стороны, с другой, часто ограничена инструментами и стандартами типа OpenAPI и JSON Schema. Общее правило наверное такое для 4xx — выдавать их в ситуациях когда программный клиент (его разработчик) может проверить валидность запроса на своей стороне, но по каким-то то причинам или не проверял, или проверил, но неправильно. То, что он может проверить, если и будет отдавать ошибку http, то 5xx
YemSalat
25.03.2018 14:11Общее правило наверное такое для 4xx — выдавать их в ситуациях когда программный клиент (его разработчик) может проверить валидность запроса на своей стороне, но по каким-то то причинам или не проверял, или проверил, но неправильно.
Снова возвращаясь к вашему примеру: «поле ОКПО обязательно для типа клиента „юрлицо“» — по сути это же тот случай когда клиент не проверил на своей стороне что отправляет. И получается приходим к проблеме выбора какие ошибки отдавать для каждого поля — http или свои.
Опять же, как вы сказали, валидация скорее всего будет обрабатываться стандартными инструментами и отсекать «неправильные» запросы до начала их «полноценной» обработки.
В результате получим апи в котором часть эндпоинтов возвращает ошибки с 200 кодом, а часть с кодами хттп, и правила по которым эти ошибки различаются могут быть совершенно не очевидны тем, кто будет использовать или поддерживать это апи.
Еще можете пожалуйста объяснить почему на клиенте может быть полезно различать между 4хх и 200 ошибками в том подходе, который вы предлагаете.VolCh
25.03.2018 17:304xx ошибки в этом подходе свидетельствуют о несогласованности кода клиента и сервера, клиент отправил запрос, который контроллер сервера технически не готов передать в модель для обработки, если говорить в терминах MVC при тонком контроллере. Это ошибки, сигнализирующие о том, что код клиента и сервера рассинхронизированы, они не предполагают реакции от пользователя кроме обращения в поддержку, «чистки кеша» и т. п.
VolCh
25.03.2018 20:13Тут вариант, когда у клиента нет полной информации о том, каким должен быть запрос, например обязательность ОКПО для юрлица выставлена в конфиге/админке, не участвующих в документировании апи.
velvetcat
24.03.2018 11:54+2По-вашему получается, что 200-е нельзя разделить между собой, а 500-е — можно.
Но это все ни о чем. Смысл заключается в фиксированных классах ошибок — чтобы клиент мог правильно обработать любую, в т.ч. новую, ошибку. В общем, если честно, Ваш пример настолько корявый, что обсуждать даже не хочется. Уберите статус коды, и увидите, что они просто лишние.
А сама проблема лежит глубже — REST смешивает транспортный и прикладной уровень, и подход "200 на все" эту проблему решает (правда, делая REST не нужным вообще).
titulusdesiderio
24.03.2018 12:11А сама проблема лежит глубже — REST смешивает транспортный и прикладной уровень, и подход "200 на все" эту проблему решает (правда, делая REST не нужным вообще).
а к чему это тогда? используйте RPC или что вам ближе. Топик всё-же про REST. и выбирая его как протокол взаимодействия всё же стоит придерживаться рекомендаций этого стандарта.
А так да, вас никто не держит за руки. Кто-то пилит псевдо-REST через одни POST запросы, передавая
{type: GET|POST|UPDATE|etc}в теле. Кто-то отдаёт 200 на всё, даже ошибки. Кто-то делает 1 ендпоинт а все параметры переносит в query аляGET: /api/users/:id/books/->/api?model=users&id=:id&field=books. Каждый строчит как он хочет
Но когда я начинаю работать над уже существующим проектом, я молюсь чтобы авторы легаси использовали стандарты а не своё "видение". Ибо "видение" очень часто в итоге превращается в боль
VolCh
24.03.2018 13:31+2REST — архитектура, как и RPC. HTTP — протокол прикладного уровня очень сильно по спецификации близкий к принципам REST. Но это не мешает использовать его лишь как транспортный, в рамках любой архитектуры. В этом случае ошибки HTTP должны свидетельствовать лишь об ошибках транспортного уровня.
dmitry_dvm
24.03.2018 18:46Вы пишите апи для себя или для клиента? Пробовали хоть раз на клиенте работать с тем, что сами предлагаете? Этот «стандарт» апи просто неудобен в использовании.
titulusdesiderio
24.03.2018 19:23пробовал. и перенял этот подход, когда начал писать сам REST-сервера. ибо это удобно
YemSalat
25.03.2018 21:32Смысл заключается в фиксированных классах ошибок — чтобы клиент мог правильно обработать любую, в т.ч. новую, ошибку.
Можете привести пример где ваш подход делает «чтобы клиент мог правильно обработать любую, в т.ч. новую, ошибку», а стандартный REST подход — нет.
velvetcat
26.03.2018 15:11Сначала объясните, пожалуйста, что Вы понимаете под стандартным REST-подходом. Чувствую, имеет место недопонимание. На всякий случай напоминаю, я отвечал на коммент, где предлагалось делать так:
500 {ok: false, message: 'SMTP relay fail: code 1234', trace: ['/path/to','/bla/bla','/lib/smtp',...]} — ошибка кода. когда возник необработанные ексепшн
500: {ok: false, message: 'user is not activated yet'} — ошибка бизнесс-логики
VolCh
24.03.2018 13:25+1При использовании http в качестве транспорта 4xx и 5xx коды должны приходить в идеале только в случае ошибок работы клиента или сервера, ошибки бизнес-логики типа «договор закрыт», " клиент с таким ИНН уже есть", «поле ОКПО обязательно для типа клиента „юрлицо“ обязательно» должны приходить с 200 кодом.
YemSalat
25.03.2018 00:33ошибки бизнес-логики типа «договор закрыт», " клиент с таким ИНН уже есть", «поле ОКПО обязательно для типа клиента „юрлицо“ обязательно» должны приходить с 200 кодом
С каким кодом должна приходить ошибка «клиента с таким ИНН нет»?
Это ошибка бизнес логики, или клиента?
Если у клиента нет каких-то прав на выполнение запроса — это 403 или 200? Бизнес логика или транспорт?VolCh
25.03.2018 01:08С правами, пожалуй, 403, если это не что-то очень локальное типа нет права оставлять поле пустым.
YemSalat
25.03.2018 02:09То есть уже начинаются «детали» — и в определенных случаях нужно таки различать аутентификация, например — это бизнес логика, или транспорт и тому подобные моменты. В итоге получается не «на все ответ 200» — а все-таки разночтения.
Возможно для вашего случая — REST вообще не лучшее решение, и действительно удобнее использовать свою вариацию, но тогда для вас будут закрыты многие инструменты и подходы которые «окружают» эту методологию.
YemSalat
25.03.2018 00:05Лучше проверять Errors!=null, чем заворачивать условный HttpClient в трайкэтчи и проверять все варианты ошибок, расписывать на каждую свое действие и так же парсить поле «ошибка»плюс принудительно отключать эксепшены на неуспешные ответы и каждый раз проверять IsSuccess
Вы о чем вообще? Проверить что статус код < 400, a потом уже точно так же обрабатывать поле error — религия не позволяет?
А с вашим подходом недолго скатиться в идиотизм в стиле `200 OK User not found`lair
25.03.2018 00:31А с вашим подходом недолго скатиться в идиотизм в стиле
200 OK User not foundЧто, заметим, лично мной виденное поведение у как минимум одного API: ты, значит, шлешь запрос на логин, а тебе в ответ 200 OK, в котором
{code: "Invalid login/password"}. Сколько раз я все проклинал при отладке.
php7
25.03.2018 11:45А я проклинаю ваши коды в заголовках.
И что?
Использование разных методов для запросов.
Это усложняет.
Но такие как Вы видимо этого не осознают.
Вам лишь бы код клепать.
Читай документацию по API и не будешь проклинать.lair
25.03.2018 11:51Использование разных методов для запросов. Это усложняет.
Да, усложняет. Но взамен мы получаем более читаемые запросы (и более простую работу на промежуточных узлах). Каждый выбирает для себя.
Читай документацию по API и не будешь проклинать.
Вот в этом и проблема, которую некоторые пытаются решить: минимизировать количество документации, чтение которой необходимо для работы с API. Опять-таки, всех разработчиков мидлвари не заставишь читать документации на все API, они бы что-нибудь униформное предпочли.
hippoage
23.03.2018 23:00Так некоторые делают. И не обязательно мелкие конторы.
Основная проблема — ошибок в http мало, в любом случае свои структуры придумывать для более детальной информации. Но все же лучше совмещать оба подхода: использовать примерно 10 кодов ошибок, и в теле дополнительно больше информации давать.
Если же про различие ошибок бизнес-логики и транспортных, то выделите разные коды. Например, 422 — ошибки валидации (бизнес-логики), а 502 — ошибки бекенда, 504 — транспортные.evgenyk
24.03.2018 01:00+2У меня в голове такая логика. HTTP — транспорт, ошибки должны быть транспортного уровня. Если запрос обработан правильно, то ИМХО на транспортном уровне должен быть код 200.
А тело ответа может быть таким (пвсеводокод):
<error_code>5238<error_code/>Красных надувных шариков нет на складе.
dmitry_dvm
24.03.2018 00:44+4Я делаю всегда ответ 200 и ошибки в поле ошибок. Потому что раньше я писал мобильные приложения и знаю как неудобен подход с кодами. Если отдать в ответ 404, то как на клиенте понять в магазине нет соли или нет магазина?
Когда я отдаю всегда 200 это значит, что все остальные ответы относятся к сетевым или фатальным проблемам и их можно фильтровать одной пачкой, типа повторите позже. Грубо говоря все остальные коды не могут появиться в жизни, если не отвалилась сеть или не легли какие-то из сервисов.
И у меня всегда одинаковый ответ состоящий из
, чтобы в типизированных языках на клиенте не пришлось под каждый ответ пилить отдельную модель.Data<T> и Errors[]lair
24.03.2018 01:00-1Если отдать в ответ 404, то как на клиенте понять в магазине нет соли или нет магазина?
А не надо в ответ на запрос "есть ли соль" отдавать 404, если ее нету — если, конечно, у вас правильно сформулирован запрос.
Но вообще, конечно, просто надо сначала прийти на корень магазина, и если там нет 404, то магазин есть. А соли — нет.
Когда я отдаю всегда 200 это значит, что все остальные ответы относятся к сетевым или фатальным проблемам и их можно фильтровать одной пачкой, типа повторите позже
… и вы, конечно, не учитываете тот факт, что запросы, на которые пришли ответы из 400-ой группы, так просто повторять нельзя?

amakhrov
24.03.2018 09:44+1надо сначала прийти на корень магазина, и если там нет 404, то магазин есть
Может, задеплоили не ту версию магазина. В котором эндпойнт "отсыпьте-соли" отсутствует.
И вот мне в ответ на запрос "отсыпьте-соли/2кг" возвращается 404. Если это значит "соль не завезли" — ну бог с ним, бывает. А если "эндпойнт не существует" — то надо бить в набат админу и слать ошибки в логи.
Чтобы по-разному обработать ошибку транспорта и отсутствие данных в базе (ошибка приложения), придется использовать код 200 для ошибки приложения.
titulusdesiderio
24.03.2018 10:26-2если ендпоинт отсутствует — нефиг отдавать по нему 404
mayorovp
24.03.2018 10:42+3А какой еще код можно отдать на запрос по несуществующему эндпоинту?
titulusdesiderio
24.03.2018 11:05Это я уже запутался. Вы правы, 404 тут как раз и должен возвращаться. Можете 418 попробовать (;
А на практике у меня обычно
404{ok: false, message: 'not found'}для отсутствия ендпоинта
и 404{ok: false, result: null}для отсутствия соли
это меня натолкнуло на мысль что стоит подумать над отсутствием соли. вероятно я измению этот ответ в ближайшем будущем.
к слову, для правильного запроса, по которому должен возвращаться массив. например корзина. в случае отсутствия элементов у меня
200{ok: true, result: []}dmitry_dvm
24.03.2018 11:30+2В вашем случае 404й ответ надо проверять дважды. А с моим подходом — единожды.
titulusdesiderio
24.03.2018 11:47согласен. я думаю что мой подход стоит пересмотреть.
но ваш подход вносит гораздо больше неопределённости и излишнего усложнения, по причинам которые я расписал выше.
lair
24.03.2018 12:30-1Может, задеплоили не ту версию магазина. В котором эндпойнт "отсыпьте-соли" отсутствует.
А вы по приходу на корень магазина не проверяете доступные эндпойнты? Ну так горе вам.
И вот мне в ответ на запрос "отсыпьте-соли/2кг" возвращается 404. Если это значит "соль не завезли" — ну бог с ним, бывает.
Так у вас две семантических ошибки. "2 кг" — это не идентификатор ресурса, ему нечего делать в пути; поэтому и отсутствие соли — это не "404 не найден".
Чтобы по-разному обработать ошибку транспорта и отсутствие данных в базе (ошибка приложения), придется использовать код 200 для ошибки приложения.
Что мешает использовать код 500 для ошибки приложения?
amakhrov
24.03.2018 20:29А вы по приходу на корень магазина не проверяете доступные эндпойнты
Расскажите, как вы это делаете? Я не слышал о таком подходе.
"2 кг" — это не идентификатор ресурса
Так и знал, что пример с солью меня подведет.
Ну, замените на GET /project/123 — что изменится?
Аналогично, две ситуации:
- эндпойнт /project/ не создан в коде приложения (транспортная проблема — очень серьезно)
- проект 123 отсутствует в базе (ошибка приложения).
Что мешает использовать код 500 для ошибки приложения?
Например, семантичность :).
Даже если забыть про семантику — у нас остаются все те же 2 ситуации:
- База упала, ну или там out of memory — ошибка 500 на транспортном уровне, надо сообщать админу
- Проект 123 не найден — обычно ничего делать не надо.
powerman
24.03.2018 21:35+1А зачем вы вообще пытаетесь на клиенте определить критичность ошибки для сервера?
На клиенте важно только то, удаётся выполнить запрос или нет. Причина неудачи интересна не более, чем в разрезе временная ли она и стоит ли пытаться автоматически повторить идемпотентный запрос.
Проблемы сервера, потенциальные — вроде запросов к несуществующим ресурсам, или реальные — вроде out of memory или невозможности подключиться к БД, гораздо удобнее определять на стороне сервера, и там же реализовать их мониторинг и рассылку алертов. Клиент о таких вещах думать не должен от слова совсем.
VolCh
25.03.2018 13:45Причина неудачи интересна для клиента прежде по делению на три категории: проблемы с сервером/каналом, проблемы с соблюдением протокола, проблемы с пользовательскими действиями.
powerman
25.03.2018 15:36-1Проблемы с соблюдением протокола клиенту интересны только в одном, достаточно редком кейсе: когда клиент свой, он всего один, и общается со сторонним сервером, который нередко без предупреждения меняет API. В остальных случаях клиенту это не нужно (если сервер свой, то проблемы с протоколом удобнее ловить на стороне сервера, если клиентов много то получать от каждого отчёт что сервер не то вернул очень неудобно, если API сервера стабильно то реализовывать в клиенте дополнительный контроль API избыточная паранойя).
VolCh
25.03.2018 21:514xx ошибка — сигнал для клиента, что протокол он не соблюдает. Сторонний клиент для публичного api может, например, инициировать отправку сообщения о такой ошибке своему вендору.
lair
24.03.2018 23:23Расскажите, как вы это делаете? Я не слышал о таком подходе.
По ссылкам. Пришли на
/, запросили ссылки, по типу нашли отвечающую за выдачу соли, перешли туда, запросили доступные действия. HATEOAS, одна из частей имплементации REST.
Ну, замените на GET /project/123 — что изменится?
Да ничего. Надо было сначала идти на
project, а потом на123, если вам так важно знать, где проблема.
Аналогично, две ситуации: [...] очень серьезно [...] ошибка приложения
Вот вопрос только, для кого эти две ситуации реально отличаются. То бишь, с чьей стороны мы смотрим на API.
Например, семантичность
Семантически все верно: "The 500 (Internal Server Error) status code indicates that the server encountered an unexpected condition that prevented it from fulfilling the request."
База упала, ну или там out of memory — ошибка 500 на транспортном уровне, надо сообщать админу
Не надо сообщать админу, админ сам все мониторит. А вы получили свой 503 — и ждите. И, заметим, никакого 500.
amakhrov
25.03.2018 00:26Да, если использовать 500 вместо 404, проблема решается.
Про семантику кода 500 не согласен, но спорить не буду.
lair
25.03.2018 00:29Да, если использовать 500 вместо 404, проблема решается.
Не надо использовать 500 вместо 404, надо использовать тот код, который наилучшим образом подходит к ситуации.
dmitry_dvm
24.03.2018 11:35По дефолту на пост запросе валидация модели вернет 400 и описание. Но ошибки валидации должны быть только во время отладки, потом на клиенте сделают свою валидацию и до юзера эта 400 никогда не дойдет (если не будет попыток обойти клиентскую валидацию). Так зачем писать логику разбора и обхождения этой ошибки на клиенте, если ее никогда не будет при моем подходе?
undestroyer
24.03.2018 11:57Не соглашусь по двум пунктам:
- 400 — BadRequest, указывает на то что сервер не смог понять запрос. Используется когда в эндпоинт нужен строго определенный входной параметр, а вместо него присылают что-то другое. Если сервер смог понять что ему прислали и это по структуре совпадает с тем что должно быть, то 400 быть не должно. На ошибки валидации есть код 422 — Unprocessable Entity, который как раз и означает что переданная сущность не может быть обработана (из-за ошибок)
- Ошибки валидации должны быть всегда, а не только во время отладки. Например, после выпуска приложения вы обновили API и ранее необязательное поле сделали обязательным (не лучший пример, но возможен). Нормальное приложение сможет это обработать и показать пользователю ошибку валидации, которую нашел сервер. Если сервер не будет присылать ошибки, то пользователь не узнает что именно произошло не так и может не выполнить свою задачу
dmitry_dvm
24.03.2018 18:551. Это придумал не я. BadRequest — стандартный дотнетовский (работаю с ним) ответ на неудачную валидацию модели.
2. Так в моем случае как раз приходят ошибки которые можно напрямую отдавать юзеру, потому что они осмысленные. При изменившейся валидации я верну 200, но поле Errors будет содержать новые требования, который юзер сразу увидит. А если возвращать 400, то это уже эксепшн на клиенте, который неизвестно как предвосхитить.lair
24.03.2018 19:07+1При изменившейся валидации я верну 200, но поле Errors будет содержать новые требования, который юзер сразу увидит.
Ну то есть вы все-таки пишете логику обработку ошибок на клиенте, даже если их не может быть.
А если возвращать 400, то это уже эксепшн на клиенте, который неизвестно как предвосхитить.
Эмм, это проблема вашего клиента, выкиньте его и возьмите нормальный. Стандартный дотнетовский
HttpClientтак себя не ведет.dmitry_dvm
24.03.2018 23:17Ну то есть вы все-таки пишете логику обработку ошибок на клиенте, даже если их не может быть.
Я предлагаю на клиенте засунуть запрос в трайкэтч и в кэтче предлагать юзеру трайэгэйн, потому что проблема точно не на клиенте. А если ответ успешен и Errors!=null то показывать его содержимое.
дотнетовский HttpClient так себя не ведет
Как это не ведет? При .EnsureSuccess… Он именно так себя и ведет. Да и на остальных, типа рестшарпа, надо вручную отключать выброс эксепшнов на неуспешных ответах.
Хорошо. Я вижу в вашем подходе на клиенте мешанину из транспортных и программных ошибок, у которых надо сортировать не только коды, но и описания. Какие плюсы у вашего подхода, кроме псевдостандартности?lair
24.03.2018 23:28Как это не ведет? При .EnsureSuccess… Он именно так себя и ведет.
А кто вас заставляет делать
EnsureSuccessStatusCode?
Какие плюсы у вашего подхода, кроме псевдостандартности?
То, что я знаю, что если сервер вернул мне 200 — тело можно парсить, и там то, что я запрашивал. И если меня интересует happy path, я могу просто проверять на ответы 200-ой группы, и считать все остальное фейлами, не тратя ресурсы на парсинг ответа. И еще то, что системы мониторинга тоже не надо парсить тело, чтобы определять статус происходящего.
VolCh
25.03.2018 21:53Вашей системе серверного мониторинга интересны случаи, когда пользователь не заполнил обязательное поле?
lair
25.03.2018 21:58Моей системе серверного мониторинга интересны случаи, когда запрос не был успешно выполнен. Почему — дело пятнадцатое.
VolCh
25.03.2018 23:36Как по мне, то ситуации, когда малоквалифицированный пользователь не заполнил обязательное поле серверному мониторингу не интересна, по сути это ложноположительное срабатывание серверного мониторинга, направленного на обеспечение работоспособности сервера. Она может быть интересна только разработчикам (владельцам) клиента для анализа того, как так получилось, что клиент решил отправить запрос с незаполненным обязательным полем.
lair
25.03.2018 23:39Еще раз, меня волнует число неуспешных запросов, потому что они определяют успешность интеграции. Если это число (или доля, не суть) внезапно выросла, это повод пойти и постучать по голове тем, кто делает интеграцию. А уж люди у них это вводят или машина криво шлет — пусть сами разбираются.
lair
25.03.2018 00:42(пропустил почему-то)
Я предлагаю на клиенте засунуть запрос в трайкэтч и в кэтче предлагать юзеру трайэгэйн, потому что проблема точно не на клиенте.
Откуда вы знаете, что она не на клиенте? Какой смысл делать еще одну попытку, если сервер вам сказал "not authorized" или, того веселее, "invalid media type"? А разделять между "мы не достучались до сервера" и "сервер сказал, что мы слишком много запросов делаем" тоже не надо?
А если ответ успешен и Errors!=null то показывать его содержимое.
… а там, значит, написано "У вас нет прав на эту операцию". И что пользователю дальше делать?
dmitry_dvm
25.03.2018 17:59А кто вас заставляет делать EnsureSuccessStatusCode?
Никто не заставляет. Так просто удобнее отсеять сразу все транспортные проблемы.
invalid media type
Оно не может вылезти во время эксплуатации. А если вылезло, то все настолько плохо, что все равно надо дебажить.
not authorized
Это в любом случае должно обрабатываться отдельно, особенно учитывая всякие акцес и рефреш токены и что, например в OpenID Connect эта ошибка описывается вообще в хэдерах, а не в теле ответа.
Откуда вы знаете, что она не на клиенте?
Потому что все ошибки такого плана должны отлавливаться при разработке клиента и в эксплуатации не возникать.
мы слишком много запросов делаем
Это вообще идеальный пример правильности моего подхрда. Такую ошибку как раз надо юзеру показывать. Даже гугл в брауезере не стесняется это делать. А как вы ее через обработку кодов обработаете?
считать все остальное фейлами, не тратя ресурсы на парсинг ответа.
В том-то и проблема, что не только тратя, но тратя в 2 раза больше, чем можно тратить, используя подход REST over HTTP.
Я же не просто так это пишу, а по собственному опыту использования множества разных апи.lair
25.03.2018 18:08Никто не заставляет. Так просто удобнее отсеять сразу все транспортные проблемы.
Если у вас случились транспортные проблемы, вы не получите ответа вообще (кроме случаев с прокси и их специфическими ошибками).
Оно не может вылезти во время эксплуатации. А если вылезло, то все настолько плохо, что все равно надо дебажить.
Ну то есть ретраить-то бесполезно.
Это в любом случае должно обрабатываться отдельно
То есть тоже ретраить бесполезно.
Потому что все ошибки такого плана должны отлавливаться при разработке клиента и в эксплуатации не возникать.
В реальности так не бывает, и между сервером и клиентом постоянно случаются расхождения.
Такую ошибку [мы слишком много запросов делаем] как раз надо юзеру показывать.
То есть опять нельзя ретраить. Не многовато ли получается исключений из вашего правила "Я предлагаю на клиенте засунуть запрос в трайкэтч и в кэтче предлагать юзеру трайэгэйн".
А как вы ее через обработку кодов обработаете?
Ну так тривиально же: ловим 429, дальше блокируем все запросы до истечения
Retry-After, если он есть.
В том-то и проблема, что не только тратя, но тратя в 2 раза больше, чем можно тратить, используя подход REST over HTTP.
… и где я их трачу в два раза больше, покажите, пожалуйста?
Я же не просто так это пишу, а по собственному опыту использования множества разных апи.
Likewise.
dmitry_dvm
26.03.2018 11:52В реальности так не бывает, и между сервером и клиентом постоянно случаются расхождения.
В этом-то и проблема ваших суждений. Когда я писал мобильных клиентов, они никогда не расходились с апи, т.к. это во-первых странно, а во-вторых бессмысленно.mayorovp
26.03.2018 12:29Отлично. Теперь вы больше никогда не сможете изменить API, так как это приведет к расхождению со старыми мобильными клиентами, что странно и бессмысленно.
lair
26.03.2018 13:06Когда я писал мобильных клиентов, они никогда не расходились с апи
Завидую вам. В моей реальности клиент расходится с сервером даже когда их пишет одна команда (потому что есть k версий серверов и n версий клиентов); а как только за клиент и сервер начинают отвечать разные команды (что уж говорить про разные компании?) — там даже в рамках одной версии есть недопонимания.
Иными словами, если клиенты никогда не расходятся с API, откуда все эти некорректные запросы в моих логах?
lair
24.03.2018 12:32Так зачем писать логику разбора и обхождения этой ошибки на клиенте, если ее никогда не будет при моем подходе?
Чтобы в ситуации, когда на сервере валидацию поменяют, а на клиенте — нет, вам было понятно, что происходит. А если вам на эту ситуацию положить, то вы говорите "все незнакомые статус — в эксепшн", и больше ничего не делаете.
YemSalat
25.03.2018 00:58Если отдать в ответ 404, то как на клиенте понять в магазине нет соли или нет магазина
Если у вас нет магазина — то у вас должен быть зафэйленный деплой бэкенда с кучей логов и алертами. А клиент о том что магазин не задеплоился знать вообще не должен.
Когда я отдаю всегда 200 это значит, что все остальные ответы относятся к сетевым или фатальным проблемам и их можно фильтровать одной пачкой, типа повторите позже
POST потом тоже будете «повторять позже»?dmitry_dvm
25.03.2018 18:02POST потом тоже будете «повторять позже»?
Именно! Потому что раз произошла транспортная ошибка, то я данные вообще не получил и можно их отправить еще раз. В этом и есть главный плюс разделения ошибок.lair
25.03.2018 18:11Потому что раз произошла транспортная ошибка, то я данные вообще не получил и можно их отправить еще раз.
Или нельзя, если вы получили 400, 405, 413, 415 и еще некоторые. Потому что ошибки группы 4xx — это не "транспортные ошибки".
VolCh
24.03.2018 09:49+4Просто надо различать HTTP REST API и REST API over HTTP. В первом случае мы связаны по рукам и ногам спецификациями HTTP, мы решаем описать доменную модель в терминах HTTP, в частности мы должны проецировать ошибки домена на ошибки HTTP. Мы можем вводить дополнительные коды в теле ответа, но ошибки должны возвращаться со статусом 400 или 500 как минимум.
Если же мы делаем REST API over HTTP, то просто используем HTTP как транспортный протокол (в целом это скорее прикладной протокол) и руководствуемся исключительно практическими соображениями, в пределе дав клиентам один урл типа /api с методом POST и возвращая 200 в случае если запрос вообще дошёл до приложения и принят им для обработки, начат анализ тела запроса.
На практике чаще всего смешивают оба подхода, или вообще говорят о REST HTTP API, на деле не соблюдая принципов REST вообще.powerman
24.03.2018 16:25+1Это всё абсолютно верно, только я не понимаю, в чём вообще смысл использовать REST API over HTTP. Как по мне, в момент принятия решения использовать HTTP исключительно в качестве транспорта REST теряет большую часть своей привлекательности и выбор какого-нибудь RPC протокола over HTTP становится более разумным.
VolCh
24.03.2018 18:29В REST архитектуру заложены определённые принципы, облегчающие создание распределённых систем. Есть и другие, но эти тоже работают.
powerman
24.03.2018 19:53Безусловно, только сколько пользы остаётся от этих принципов после того, как мы потеряли возможность использовать громадное количество существующих инструментов, поддерживающих эти принципы? Пока REST использует соответствующие методы HTTP все эти инструменты могут перехватывать запросы, модифицировать их, кешировать, автоматически повторять идемпотентные… но как только мы сделали "over HTTP" и для всего теперь используем POST — все эти инструменты стали неприменимы.
Теперь для использования заложенных в REST принципов нам нужно писать собственные инструменты. А если всё-равно писать собственное, то не проще ли это делать уже не ограничивая себя REST-ом, если только он не подходит действительно идеально для текущего проекта (и я лично таких проектов не встречал — всегда что-нибудь да "выпирает" из "чистого RESTful")?
VolCh
24.03.2018 23:02Скорее всего именно поэтому на практике комбинируют оба подхода: используют идентификаторы в виде урл, для RUD используют GET, PUT, DELETE и т. п. Но при конфликте домена и семантики HTTP предпочтение отдают домену.




Falseclock
23.03.2018 23:06ODATA — лучшее решение для REST API.
Во-первых, стандарт.
Во-вторых, не надо писать документацию.
В-третьих, легкая и быстрая интеграция: скормил метадату «клиенту» и тот знает что от куда брать и как с чем связано.
Pilat
24.03.2018 03:16+3Такое ощущение, что при придумывании REST интерфейса основное время уходит на проверку следования рекомендациям и, при смене авторитета, изменениям в реализации.
Может быть, RPC подход не так уж и плох? Или SOAP.lair
24.03.2018 12:33-1И RPC, и SOAP действительно не так уж плохи. Но если вы думаете, что там нет проблемы продумывания интерфейса, то вы глубоко ошибаетесь. Один только спор "как в соапе возвращать ошибки" чего стоит.

Dreyk
24.03.2018 04:46+1304 Not Modified — используйте этот код состояния, когда заголовки HTTP-кеширования находятся в работе
когда имеете дело с HTTP-кешированием (или когда работаете с HTTP-кеширвоанием)
до этого момента в тексте не замечал, что это перевод, а после — сразу видно, как будто немного лень стало переводить
undestroyer
24.03.2018 05:05+3В пункте 8:
200 OK — это ответ на успешные GET, PUT, PATCH или DELETE.
Хотя до этого, в списке методов PATCH вообще не упоминался.
Касательно предмета разговора, считаю использование методов кроме GET и POST избыточным, по ответам использую в основном 200, 400, 401, 404, 413, 422, 500.
В академическом смысле REST направлен на управление ресурсом, а под ресурсом, как правило, пониматься документ не имеющий бизнес-логики, которая создаст сайд-эффекты.
Базовый пример: изменить статус заказа на «Отгружен»
REST: говорим серверу изменить статус заказа с любого на 2
PUT /order/1 HTTP/1.0 { "status": 2, "seller_id": 101, "client_name": "Mr. Holmes", "client_address": "Baker st, 221b" // ... }
Реальный мир: перевод заказа в какой-то статус имеет действия бизнес-логики (управление остатком товара на складе, уведомления клиенту и менеджеру, отправка данных в API транспортной компании и тд), поэтому в своих проектах задача «перевести заказ в статус Отгружено» решаю POST запросом с объектом:
POST /order/ship HTTP/1.0 { "order_id": 1 }
При реализации по REST сервер должен сам сделать diff текущего состояния ресурса с измененным, решить что там за операция бизнес-логики и выполнить ее. Мне такой подход не нравится, поэтому на бизес-операции делаю отдельные точки входа, из соображений 1 запрос = 1 бизнес-действие. Так удобнее поддерживать, тестировать и разрабатывать.Ares_ekb
24.03.2018 08:18А если так?
PUT /order/1/status HTTP/1.0 { "value": 2 }VolCh
24.03.2018 09:52Или даже без value, просто 2.
undestroyer
24.03.2018 11:44+1Не очевидно. API делается для внешних разработчиков, поэтому преимущества семантического программирования тут показывают себя во всей красе. После прочтения какого из методов проще понять что происходит при его вызове:
/order/1/status/2или/order/1/ship? Мне больше нравится второй вариант
VolCh
24.03.2018 09:58Изменить статус заказа академически скорее будет PUT /order/1/status 2 или PATCH /order/1 status=2 или POST /order/1/ship.
undestroyer
24.03.2018 11:35Не встречал ранее практики управления свойствами ресурса через /resourse/id/property. Для меня ресурс уже является атомарным и дальнейшее его деление никогда не пробовал. Надо более подробно изучить что это дает и какие проблемы имеет, хотя бы в академическом смасле
mayorovp
24.03.2018 10:46А почему не
POST /order/1/ship HTTP/1.0?undestroyer
24.03.2018 11:39В классических подходах современных MVC фреймворках роутинг строится по принципу
/{Controller}/{Method}. Реализовать/order/shipпроще чем/order/1/ship. Предложенный вариант тоже хорош, на первый взгляд мне нравится, но реализация требует дополнительных усилий по конфигурации проекта, а мне этого делать обычно лень. Кастомный конфиг роутинга может стать запутанным и поддержка будет сложнее.mayorovp
24.03.2018 13:06+1Мне почему-то всегда казалось что /{Controller}/{Method} — это не принцип построения роутинга, а всего-то маршрут по умолчанию…
undestroyer
24.03.2018 12:02-1А кто-нибудь может объяснить откуда ажиотаж (вроде уже немного спал) вокруг GraphQL? Никаких преимуществ против нормально документированного REST-like я не вижу

Virviil
24.03.2018 12:56GraphQL это следующий шаг в REST API. Со своими плюсами и минусами.
Плюсы связаны в основном с развитием технологий — непример в GraphQL можно интегрировать real-time за счёт вебсокетов, и это всё ещё находится в рамках GraphQL (в отличие от рест, где сокеты — это что-то отдельное).
Самодокументирования, типизация, строгая объектная модель — это всё про GraphQL.
Минусы в основном сосредоточены в проблемах реализации адекватной ACL модели, и необходимостью продумывать ограничения тяжести запросов на предмет DDoS сервера. Впрочем, в REST эти проблемы тоже есть.
Основное "из жизни" преимущество GraphQL — в половине случаев не надо менять бэк, если немного изменилась конфигурация необходимых фронту параметров.

nsinreal
24.03.2018 13:41Итоговая производительность у graphql-клиента будет выше за счёт объединения запросов
VolCh
25.03.2018 14:04Основное преимущество, имхо, возможность по умолчанию делать запросы, в ответе на которые будут скомбинированы разные типы «ресурсов». В REST технически вы можете сделать ендпоинт, который позволит неограниченно разворачивать в глубину разные типы связанных ресурсов типа пользователей и их групп, но это будет нарушением идеологии в общем случае — ресурсы должны содержать ссылки на другие ресурсы, а не включать их представление в себя. Грубо, при подготовке ответов в REST сервер не должен делать join с таблицами, содержащими данные разных типов ресурсов, а в GraphQL он обязан их делать по запросу пользователя. «Джойны» в нём чуть ли не главная фича из коробки, их специально нужно ограничивать, если не хочешь дать возможность клиенту разворачивать неограниченно всю модель. А в HTTP REST нужно вводить дополнения, нарушающие его идеологию, если хочешь, например, вытащить одним запросом пользователя, его группы, их пользователей их из группы.
php7
24.03.2018 12:17-1Что я скажу.
Существует неправильное представление о том, что все данные, доступные через сеть, считаются REST, но это не так.
Нет, это существует мейнстримовое представление, что только REST API по этим гребаным лучшим практикам — REST, а все остальное непойми что.
Мне не очень нравятся занятия любовью с выбором метода запроса или чтения кодов ответов. Почему метод должен обязательно быть в строке адреса?
Дайте мне просто метод, который нужно дернуть.
Мне вот нравится ВК API.
Оно что, не REST?
Еще как REST.
Что мне это напоминает?
Да любую мейнстримовую истерию.
Да хоть на счет того же Agile.
Это хомякам кто-то оплачивает эти статьи?
Или они сами выбрали течь в чужих сомнительных парадигмах?lair
24.03.2018 12:34-1Мне вот нравится ВК API. Оно что, не REST? Еще как REST.
По какому формальному определению?
php7
24.03.2018 15:27-1Да сходи хотя бы на википедию:
ru.wikipedia.org/wiki/RESTlair
24.03.2018 15:36-1То есть вы утверждаете, ВК API (какой конкретно, кстати?) выполняет пять из шести ограничений по Филдингу?
php7
24.03.2018 16:31-11. ВК API может как отвечать всем требованиям, так и не отвечать.
Я не ВК.
Я смотрю на сам «протокол».
2. Я считаю да.
Да и некоторые ограничие какие-то тупорылые и непонятные.
Вы считаете нет, что он нарушает?
Какой API? Да тот, который в документации освещен по умолчанию.lair
24.03.2018 16:51ВК API может как отвечать всем требованиям, так и не отвечать.
Если он не отвечает требованиям этого определения, то он не REST в рамках этого определения.
Да и некоторые ограничие какие-то тупорылые и непонятные.
А это не важно, они все равно часть определения. Если они вам не нравятся — значит, это определение вам не подходит. Ок, дайте другое.
Какой API? Да тот, который в документации освещен по умолчанию.
Ссылку дайте, пожалуйста, на конкретное описание. Я сходу нашел кучу разных, непонятно, о чем именно речь идет.
php7
24.03.2018 21:24Мы видимо пошли чуток не туда.
Меня интересует, как делать запросы и получать ответы.
Да, документация по API немного запутанная. Не сразу поймешь куда попадешь.
Вот это vk.com/dev/methodslair
24.03.2018 23:33Меня интересует, как делать запросы и получать ответы.
Оно и видно. Вас не интересует, REST ли это, вас интересует, как делать запросы и ответы. Ну и прекрасно. Просто оставьте REST в покое и пользуйтесь теми API, которые вам удобны.
Вот это vk.com/dev/methods
Выглядит как типичный RPC.
php7
25.03.2018 10:30-1Ну да, это не может не быть RPC.
Потому что RPC — это просто констатация межпроцессного взаимодействия.
Это не конкретный протокол.
А REST — это RPC по HTTP.
Многие под REST и RPC почему-то понимают конкретный протокол.
Но это заблуждение.lair
25.03.2018 10:41+1Потому что RPC — это просто констатация межпроцессного взаимодействия.
Конечно, нет. RPC — это remote procedure call, вполне конкретный стиль межпроцессного взаимодействия. Скажем, если вы в SOA кидаетесь документными событиями, у вас будет межсистемное взаимодействие, но не будет RPC.
А REST — это RPC по HTTP.
Просто нет. Во-первых, вы не найдете определения, где это было бы сказано, во-вторых, вот: https://www.quora.com/What-is-the-difference-between-REST-and-RPC
php7
25.03.2018 13:02-11. Почитай что такое RPC на википедии.
Это не только HTTP.
2. Иногда просто нужно думать головой и уметь складывать цельную картину.
3. Из статьи о REST на вики:
В сети Интернет вызов удалённой процедуры может представлять собой обычный HTTP-запрос (обычно «GET» или «POST»; такой запрос называют «REST-запрос»), а необходимые данные передаются в качестве параметров запроса[2][3].
вызов удалённой процедуры — ссылка на RPC.
4. Да потому что интернеты захватили упоротыши.
Вон еще один статью накалякал с бредом.
Это как форсед мем.
5. По ссылке — это все ерунда.
Если мой ответ не пробъет Вашу броню, то можете не отвечать мне.lair
25.03.2018 13:12+1Почитай что такое RPC на википедии. Это не только HTTP.
Я где-то утверждал, что RPC — это только HTTP? Вроде нет.
Из статьи о REST на вики:
Если подниметесь буквально на строчку выше вашей цитаты, там написано буквально: "REST является альтернативой RPC" (выделение мое)
Да потому что интернеты захватили упоротыши. [...] По ссылке — это все ерунда.
Конечно, один вы знаете, как правильно определяется REST. Было бы здорово, конечно, увидеть-таки ссылку на признанное формальное определение.
r1000ru
24.03.2018 13:48+1Везде где могу — использую или реализую JsonRPC 2.0 (http://www.jsonrpc.org/specification). Больше нет неоднозначностей с объектами, нет ограничений в методах, нет необходимости определять — ошибка на уровне протокола хттп или бизнес-логики. Да и вообще без разницы, отправка идет по чистому хттп или через веб-сокеты. А еще нет смешения свойств объекта ответа с информацией о результате выполнения. Все просто и прозрачно. А такое в энтерпрайз не берут.

jakobz
24.03.2018 14:55+1Я у себя на энтерпрайзе не использую REST. В последнее время — GraphQL, до этого — JSON over HTTP, в RPC-стиле.
Мне искренне непонятно как вообще на REST можно построить API для типичных страниц приложения — где надо показать 10 наиболее релевантных зайчиков, статистику по белочкам, детали по первому зайчику, и вот это всё. Если делать в стиле REST — это надо будет на каждой странице в 20 эндпоинтов ходить.
Да, есть случаи когда REST неплохо подойдет. Скажем, как API какого-нибудь популярного приложения типа Trello или Gmail-а. Там это API нужно, в основном, чтобы быстро разобраться, зацепиться, и сделать какую-нибудь простую штуку типа «письмо пришло — создали таску».
При этому, можно легко убедиться, что тот же Gmail, имея публичное REST API, в веб-приложении пользуется совсем другими внутренними API, которые ни разу не REST. И так — делают все нормальные люди. Потому что REST не подходит для построения API для веб- или мобильного приложения. GraphQL — подходит, JSON RPC — подходит, а REST — нет.
Яростная пропаганда REST, как лучшего похода для API — это очень вредная штука. Я лично видел как из-за этого факапят проекты в человеко-годы.
devalone
24.03.2018 18:10Какие-то уж совсем очевидные вещи. Можно было бы затронуть хотя б опции для фильтрации и сортировки ресурсов, а тут может быть много вариантов.
— как в django rest framework:
site.com/books?author=George Orwell&year__lte=1945&ordering=price
— исползьуя POST(некоторые и так делают):
POST site.com/filters/books
BODY: {
«filter»: ...,
«ordering»: ...,
}
— используя urlencode (лично мне этот метод нравится, т.к. не нужно запоминать извращённую djangoвскую нотацию и можно кешировать, также нет конфликтов полей книги и служебных слов(ordering), но минус — читабельность)
site.com/books?filter=author%3DGeorge%20Orwell%26year%3C%3D1945&order_by=price
— создавать фильтр POST'ом, записывая в базу и делать дальнейший запрос как-то так:
site.com/filters/1234
ИМХО, самый извращённый вариант, зачем хранить ненужный мусор в БД?
И тыщи других вариантов.
PashaNedved
24.03.2018 18:571. Конечные точки в URL – имя существительное, не глагол
Можно ли сделать из этого вывод, что нужно использовать
https://my-site.com/subscribtions/{subscribe_id}?unsubscribe
вместо
https://my-site.com/subscribtions/{subscribe_id}/unsubscribe
?lair
24.03.2018 19:08+2Совсем по уму, уж если у вас есть множество
subscriptionsс отдельными элементами, достаточно делатьDELETEна этом элементе.PashaNedved
24.03.2018 19:25Я имею ввиду не удалить ресурс, а пропатчить, сохранив семантическую ценность запроса.
lair
24.03.2018 19:34Даже если не обсуждать, надо ли здесь удалять или патчить (потому что это весьма спорный вопрос), ваша фраза уже содержит ответ: просто вызовите
PATCH.
Lachrimae
Странная все же у автора манера. Он говорит — делай так, а не вот так. Ни объяснения, ни доводов. Ничего.
Alesh
lair
Это не объяснение, это "верьте мне". Объяснение — это "мы пробовали сделать вот так, и получилось вот такое" или "мы не делали по этой практике, и получилось вот такое".
Alesh
Ну с REST тут, такое. Никто не мешает и в единственном числе и с глаголами, работать будет, но большинство все таки склоняется что это не по понятиям) Поэтому объяснения только два, так нравится и все так делают. От манеры автора тут вряд ли что зависело.
lair
Ни "мне так нравится", ни "все так делают" — не критерий best practice.
Alesh
Ну если вы найдете аналогичную статью, где есть объективные объяснения таких моментов по REST, поделитесь ссылкой. Прочту с интересом.
o_nix
https://habrahabr.ru/company/mailru/blog/345184/