
Вся информация по проектам реплицируется в отчетную базу из HP Project and Portfolio Management. Для того чтобы наша нейросеть на Tensorflow могла обучаться и делать прогнозы, нужно превратить данные по проектам в нечто понятное для этого API — в векторы.
Подготовка векторов для Tensorflow
Начинаем с импорта данных из отчетной базы. Данные по закрытым проектам используются для обучения нейросети, данные по активным проектам нужны для построения прогнозов. Сначала один раз выгрузили данные по всем проектам, после этого по таймеру выгружаются только изменения. Формат выгрузки — *.csv.
В обобщенном виде мы получаем вот такую таблицу:

На следующем шаге все это загружается в MongoDB. Из обработки исключаются проекты, не имеющие достаточного объема данных или не подходящие для анализа по другим причинам.
Далее идентифицируем задачи проектов, сопоставляя их со списком типовых задач. Задачи в проектах не сводятся к единой формулировке, названия схожих задач могут различаться. Поэтому для распознавания мы составили словарный справочник с синонимами. Одинаковые задачи в разных проектах получают уникальный идентификатор. Распознавание работает пока только на русском языке. Исключаем проекты, где удалось распознать менее 20% задач, и проекты, по какой-либо причине не имеющие задачи закрытия.
На этом этапе становится понятно, в какую нейросеть пойдет тот или иной проект. У нас две нейросети: одна предсказывает оценку проекта при закрытии, другая — дату закрытия проекта. Для обучения первой используются проекты, закрытые с оценкой, для второй – все закрытые проекты.
На основе колонок «Уровень вехи», «Тип контрольной точки» и «Событие» создаем справочники событий. Затем события привязываем к шкале времени для восстановления истории изменений с шагом в один день. Первая строчка содержит события за один день. Каждая новая строчка содержит предыдущие события + события нового дня.
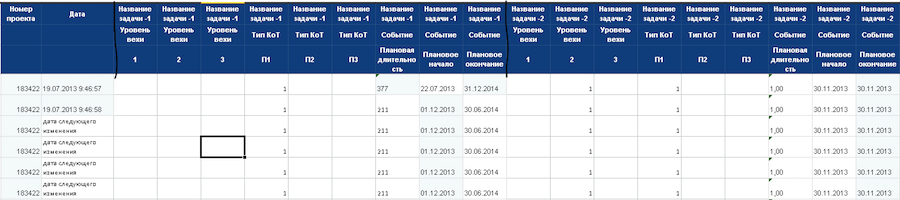
Переводим значения в диапазон от 0 до 1. Временные шкалы для проектов создаются по одинаковым идентифицированным событиям, такой подход позволяет сравнивать проекты разной длительности.
В качестве конечной точки мы не берем плановую дату окончания проекта — мы рассчитываем с запасом. Например, если проект идет год, то шкала для него будет на пять лет. Это сделано для того, чтобы предсказывать события, выходящие за временные рамки проекта.

Теперь все данные имеют нужный формат. Можно подготовить входящие векторы для нейросети. Каждая колонка в таблице — это нейрон, комбинация из трех элементов: задача проекта, события и значения события. Сейчас у нас насчитывается примерно 25 тысяч нейронов.
Синтетические данные для обучения
Для увеличения количества данных, используемых в обучении, мы генерируем синтетические данные с разными искажениями:
- Восстановление соседних задач. В случае отсутствия соседней задачи в нее копируются значения текущей задачи со смещением от 0% до 0,005%.
- Размытие. От значений нейронов текущей задачи вычитается от 0% до 0,005%. Это значение делится пополам и добавляется в нейроны соседней задачи.
- Шумы. Значения нейронов текущей задачи корректируются в диапазоне 0,005%.
- Зануление. Значения нейронов текущей задачи зануляются, то есть предполагаем, что такая задача может отсутствовать в другом проекте.
- Смешение. Используется комбинация предыдущих искажений.
Работа Tensorflow
Чтобы научить нашу нейронную сеть, мы используем набор контрольных векторов, которые позволяют ей сопоставить данные о проекте с конечным результатом. Первая сеть учится прогнозировать оценки проекта, вторая предсказывает дату закрытия проекта.
Ниже представлены примеры контрольных векторов для каждой из сетей.
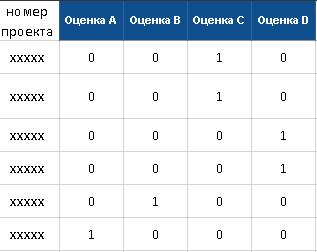
Контрольный вектор для нейросети, прогнозирующей оценку проекта
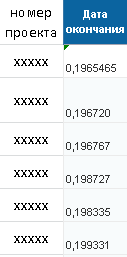
Контрольный вектор для нейросети, прогнозирующей дату окончания проекта
После загрузки начинается обучение стандартными средствами Tensorflow. На вход подаются обучающие векторы, на выходе результаты сравниваются с контрольными векторами. Результат сравнения отправляется обратно в нейронную сеть для корректировки обучения. За процессом можно наблюдать через графический интерфейс. После того как сеть обучена, на вход подаются вектора проектов, по которым нужно построить прогноз. Прогноз имеет формат контрольного вектора, на основе которого формируется отчет по всем актуальным проектам.
Что дальше?
Сейчас мы завершаем работы по автоматизации всех этапов подготовки данных и процесса обучения нейронной сети с помощью Jenkins. Обычно он используется для сборок, но здесь мы расширили сферу применения. Создали задачи по импорту данных, подготовке обучающих векторов и обучению нейронной сети. Сделали возможность настройки задач по построению прогноза.
У этой системы есть два основных направления развития. Мы работаем над подключением новых источников данных — это различные учетные системы Сбербанка, связанные с проектным управлением. А также разрабатываем алгоритм для выдачи рекомендаций по улучшению ведения проблемных проектов. Чтобы нейросеть могла, например, посоветовать, каких специалистов надо подключить к проекту, чтобы завершить его вовремя. Здесь появляется огромное количество разных идей, поскольку нейросеть должна пояснить, почему нужно делать именно так, как она рекомендует. Это называется объяснимый искусственный интеллект, Explainable Artificial Intelligence (XAI).
Кроме нас, в Сбербанке и Сбертехе есть еще несколько команд, которые ведут стартапы по Machine Learning для предсказаний количества ошибок в релизах, инцидентов на основе отзывов пользователей и данных из систем мониторинга. Коллеги обязательно поделятся своими кейсами.
Комментарии (13)

Apatic
27.03.2018 00:18+1Я не совсем понял, а что в итоге предсказывается то?
Было бы неплохо привести пример прогноза по какому-то проекту. С картинками, так сказать
yurybaramykov Автор
27.03.2018 15:53+1По проектам предсказывается:
— оценка при закрытии
— дата закрытия проекта
Пример:
ID проекта — 123456
Название проекта — Проект
Прогноз оценки — C
Прогноз закрытия — 21.06.2018
Apatic
29.03.2018 12:01Про точность пока сложно говорить, насколько я понимаю?
Кому раскрываются/будут раскрываться (я так и не понял пошло это уже в продакшн или нет) данные прогноза?

mad_nazgul
27.03.2018 05:40Как не пытались менеджеры избавиться от программистов, но похоже программисты начинают избавляться от менеджеров. :-)
ser0t0nin
27.03.2018 14:41Каждая колонка в таблице — это нейрон, комбинация из трех элементов: задача проекта, события и значения события. Сейчас у нас насчитывается примерно 25 тысяч нейронов.
Вот совсем не понял, нейрон — функция логистической регрессии, а не колонка. Вообще можно ли на архитектуру сети взглянуть? или там просто персептрон?yurybaramykov Автор
27.03.2018 15:33+1Архитектура следующая: 25 тысяч во входном слое, всего 4 слоя, 2 скрытых.
Выше был описан принцип формирования данных для использования во входном слое, данные из колонок подаются в нейроны на вход.ser0t0nin
27.03.2018 16:25Спасибо! Получается вы можете любой проект представить в виде вектора в пространстве размерности 25к? какой примерно объем обучающей выборки у вас?
Tiendil
Какая точность прогнозов получилась?
Какого рода проекты анализировались?
Сколько проектов попало в выборки?
Можете перечислить другие причины?
Можете поделиться списком типов?
Без количественных данных сложно оцени проделанную работу :-)
yurybaramykov Автор
Спасибо большое за вопросы :)
Ответы на некоторые из них являются темой для отдельного поста.
Анализировались ИТ проекты, более 100. Типовые задачи — подготовка документации, анализ, кодирование, формирование релиза, тестирование, внедрение и т.д.
Sberbank
Ждем следующий пост :)
Kaiser
Некоторые моменты звучат очень странно, хотелось бы получить ответы в комментах.
— Нет ничего о метрике качества и чего удалось добиться на отложенной выборке.
— Я правильно понял, что есть 25k фичей и обучающая выборка объемом 100 строк?
yurybaramykov Автор
Спасибо за вопрос.
Качество данных очень важный вопрос, но о нем не получилось рассказать в этом посте. У нас есть много фильтров на разных этапах, если данных мало — проект не используется.
1 проект представляется в виде вектора (таблица 25к колонок — 700-800 строк)
Количество строк в векторе 1 проекта зависит от длительности проекта и частоты внесения данных. Строка — это все события за 1 день.