
Прочитав данную заметку вы узнаете, через что пришлось пройти после неожиданно возникшей утечки памяти серверного приложения в ОС FreeBSD. Какие современные средства обнаружения подобных проблем существуют в данной среде и почему самое мощное из них может оказаться совершенно бесполезным
В один прекрасный полдень четверга, на 5 из 50 серверов Zabbix прислал уведомления о заканчивающемся месте на swap-разделе. График на КПДВ (свободная память) наглядно демонстрирует масштаб проблемы (холмики справа — высвобождение памяти за счет вытеснения в swap). Благо, впереди пятница, и можно спокойно все исправить за выходные. В тот момент еще никто не предполагал, что на поиски и устранение причины уйдет больше 6 суток.
О серверах. Типичные сервера поколения десятых-одиннадцатых годов с 8Гб памяти (практически полностью идентичны и даже одного бренда). Сервера поделены на группы для обслуживания разных наборов пользовательских аккаунтов.
О приложении. Ad-server, HTTP (libh2o) с логикой на C\С++, кучей сторонних библиотек и велосипедов вроде стандартных C++ контейнеров в shared memory и т.п. Принимает входящий запрос, перенаправляет на несколько вышестоящих серверов, проводит аукцион по ответам и возвращает ответ клиенту. Все крутится на FreeBSD 11.0\11.1.
Кто виноват?
Последние изменения в кодовой базе были около десяти дней назад, все эти дни с памятью не происходило ничего примечательного. Беглый анализ давал такой список наиболее вероятных причин:
- изменились качественные либо количественные характеристики входящих\исходящих запросов, что привело к ошибкам при выделении\освобождении памяти;
- велосипеды с контейнерами в shared memory. Они всегда вызывают подозрение, если что-то идет не так;
- никакой утечки нет, просто стало больше данных и они теперь перестали влазить;
- результат обновления ядра ОС \ библиотек. Но никаких авто-обновлений по умолчанию нет, это не какая-нибудь Windows которая, прости Господи, может накатить обновлений, когда вздумается и, вдобавок, перезагрузить машину. Пару месяцев назад так обвалилось много сервисов на соседнем проекте.
- кто-то проводит целенаправленную сетевую атаку, вызывающую переполнение;
- Meltdown\Spectre. Да! Ну конечно же. Не помню, чтобы мы накатывали какие-либо обновления, боясь замедления, но такой пункт сегодня просто обязан иметь место быть в любой нештатной ситуации;
Но характеристики запросов\ответов не изменились (по крайней мере, по всем собираемым метрикам). Данных больше не стало, с сетью порядок, куча свободных ресурсов, сервер отвечает быстро… Неужели изменилась внешняя среда?
Что делать?
Пару лет назад всплывало нечто подобное, но успели забыться практически все инструменты, которые помогли решить проблему тогда. Хотелось просто поскорее избавиться от всего за пару часов, поэтому первая наивная попытка — найти ответ на StackOverflow… В основном народ рекомендует Valgrind и какие-то неизвестные поделки (видимо, сами же авторы), либо плагины к VisualStudio (неактуально). Поделки падали практически все, даже не начав толком работать (memleax, ElectricFence и т.п.), останавливаться на них подробно не будем.
Попутно вспоминаем все недавно выпущенные фичи, благо, изменений за последний месяц было немного, из основных — прикручивание баз GeoIP, и так, по-мелочи…
Пытаемся поочередно отключать клиентов и вышестоящие сервера (данный метод был опробован одним из первых, но почему-то не дал никакого результата, утечка проявлялась во всех комбинациях с разной степенью интенсивности, наблюдалась лишь линейная зависимость от входящих запросов).
Тут же были предприняты попытки отката на старые версии, вплоть до ревизии двухмесячной давности. Память продолжала утекать и там. Откат на еще более ранние версии не представлялся возможным по причине несовместимости с остальными компонентами.
Главный вопрос — почему именно эти 5 серверов? Все машины практически идентичны (кроме разницы в версии ОС 11\11.1). Проблема возникает только на определенной группе аккаунтов. На остальных нет и намека на такое поведение, значит, должно быть, точно зависимость от входящих запросов…
Лирическое отступление
Неоднократно сталкиваясь с утечками в разных проектах, довелось наслушаться жутких историй про самый популярный и действенный способ лечения — периодически перезагружать ущербное приложение. Да да, оказывается, такое работает годами в весьма уважаемых компаниях. Мне это всегда казалось полной дичью, и что я никогда в жизни не опущусь до этого, какого бы масштаба не возникла проблема. Однако, уже на вторые сутки пришлось прописать позорный рестарт в cron-е, т.к. перезагружать приложение раз в несколько часов оказалось довольно утомительным занятием (особенно по ночам).
Зачем-то захотелось сделать все красиво, а именно найти место утечки универсальными средствами. Наверно, это была одна из основных ошибок, допущенных на ранней стадии.
Итак, какие же универсальные средства решения описанной проблемы существуют сегодня? В основе своей, это сторонние библиотеки, оборачивающие вызовы к malloc\free и следящие за всеми операциями с памятью.
valgrind
Прекрасное средство обнаружения проблем. Действительно, ловит практически все виды (двойное освобождение, выход за границы, утечки и т.п.). Тут бы вся эта история и закончилась, не начавшись. Но с valgrind есть одна проблема — практически полная бесполезность для высоко-нагруженных приложений. Выглядит это примерно так: программа стартует в 20-50 раз дольше обычного, потом так же работает, при этом большинство запросов, естественно, не успевают отработать и заканчиваются по таймаутам. Ядра CPU загружаются на 100%, при этом никаких полезных действий приложение не производит, тратя все ресурсы на виртуальную машину valgrind-а. В логах вы обнаружите жалкие доли процента от всех запросов, которые проходят в штатном режиме. После нажатия Ctrl+C, если повезет, через несколько минут появится лог, либо же все упадет (у меня было чаще второе, либо практически пустой лог). В общем, не взлетело.
tcmalloc
Библиотека доступна из порта google-perftools. По заявлением разработчиков:
This is the heap profiler we use at Google.Как и большинство подобных средств, подключается либо с помощью переменной окружения (LD_PRELOAD) либо вкомпиливанием самой библиотеки (-ltcmalloc). Ни тот ни другой способ не сработал. В процессе обнаружился еще один способ — вызов статического метода HeapLeakChecker::NoGlobalLeaks() из кода. Но он почему-то не экспортировался ни в одной из версий библиотеки. В последствии выяснится:
[on FreeBSD] libtcmalloc.so successfully builds, and the «advanced» tcmalloc functionality all works except for the leak-checker, which has Linux-specific code.:( Поехали дальше.
libumem
Доступна из порта umem. Шикарный способ обнаружения проблем с памятью. Особенно в сочетании с MDB. К сожалению, доступно все это только в ОС Solaris, а на FreeBSD MDB было бы неплохо портировать. Запустить с ним приложение не удалось. При старте, до вызова main, происходит вызов calloc из libthr.so, который уже перехвачен libumem-ом. В свою очередь, libumem пытается инициализировать работу с потоками у себя в коде. Рекурсия-с. В общем стек еще задолго до вызова main выглядит примерно так:
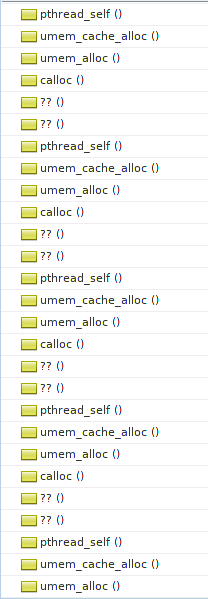
Типичная проблема яйца и курицы, которую непонятно как обойти. Идею выпилить много-поточность (благо, у нас она используется только где-то в boost-зависимостях и в обертке над getaddrinfo) было решено отложить на самый крайний случай. Ну что ж, отпишем разработчикам (если остались еще живые) в открытый кем-то похожий тикет и поедем дальше.
dmalloc
Доступна из одноименного порта. Обладает неплохой документацией. Стек при запуске удивительно напоминает предыдущий случай:
(gdb) bt
#0 0x0000000802c8783e in dmalloc_malloc ()
from /usr/local/lib/libdmallocthcxx.so.1
#1 0x0000000802c88623 in calloc () from /usr/local/lib/libdmallocthcxx.so.1
#2 0x00000008038a8594 in ?? () from /lib/libthr.so.3
#3 0x00000008038a98d4 in ?? () from /lib/libthr.so.3
#4 0x00000008038a58fa in pthread_mutex_lock () from /lib/libthr.so.3
#5 0x0000000802c87641 in ?? () from /usr/local/lib/libdmallocthcxx.so.1
#6 0x0000000802c87bb3 in ?? () from /usr/local/lib/libdmallocthcxx.so.1
#7 0x0000000802c8787a in dmalloc_malloc ()
from /usr/local/lib/libdmallocthcxx.so.1
#8 0x0000000802c88623 in calloc () from /usr/local/lib/libdmallocthcxx.so.1
#9 0x00000008038a8594 in ?? () from /lib/libthr.so.3
#10 0x00000008038a98d4 in ?? () from /lib/libthr.so.3
#11 0x00000008038a58fa in pthread_mutex_lock () from /lib/libthr.so.3
#12 0x0000000802c87641 in ?? () from /usr/local/lib/libdmallocthcxx.so.1
#13 0x0000000802c87bb3 in ?? () from /usr/local/lib/libdmallocthcxx.so.1
#14 0x0000000802c8787a in dmalloc_malloc ()
Но здесь автор в курсе проблемы и предусмотрел оригинальный способ обхода: при старте задавать параметром кол-во вызовов malloc-ов, которые нужно игнорировать (дабы избежать рекурсии):
You know its too low if your program immediately core dumps and too high if the dmalloc library says its gone recursive although with low values, you might get either problem.Мило. Подбирая заветное число, пометавшись между core-dump-ами и рекурсией всю эту затею было решено предать анафеме.
Тем временем, память на серверах стала заканчиваться еще быстрее. Если раньше было 5-6 часов до полного выедания, то сейчас память уходила за час полностью. Пришлось подкручивать cron :( К тому же, набор серверов, подверженных проблеме, стал расти. Правда, на новом наборе серверов память заканчивалась в течении суток. При этом, на большинстве машин до сих пор не было вообще никаких видимых проблем с памятью.
Параллельно, у инженеров в ДЦ запросили дополнительной памяти на один из серверов, чтобы проверить теорию о том, что «это данных стало больше» (последняя, отчаянная попытка убедиться, что это не утечка). ДЦ весьма оперативно предоставил дополнительные 8Гб, которые были благополучно выедены за ночь. Больше в наличии утечки никто не сомневался.
dtrace
В процессе беспощадного гуглежа все больше стали попадаться загадочные скрипты на не менее загадочном языке D. Оказалось, что все они предназначены для невероятно крутой системной утилиты — dtrace, эдакий IDDQD в анализе и отладке практически любого кода. Много про него слышал, но не доводилось использовать в бою.
Т.е. вы можете попросить сохранять все обращения к определенным функциям libc, например, malloc\free, поставив на них датчики (probes), попутно собирая общую статистику, и даже строить диаграммы распределения, и все это в несколько строк кода! Например, вот так:
sudo dtrace -n 'pid$target::malloc:entry { @ = quantize(arg0); }' -p 15034— вы можете узнать распределение выделяемых блоков в любом запущенном процессе (в примере — pid=15034). Вот как выглядит распределение в нашем приложении за несколько секунд мониторинга:
value ------------- Distribution ------------- count
2 | 0
4 | 1407
8 | 455
16 |@@ 35592
32 |@@@@@@@@@@@@@@@@ 239205
64 |@@@@@@@ 112358
128 |@@@@ 55813
256 |@@@@@@ 91368
512 |@ 17204
1024 |@ 19751
2048 |@@ 33310
4096 | 2082
8192 | 554
16384 | 15
32768 | 0
65536 | 3960
131072 | 0
Круто, правда? Все это на лету, без перекомпиляции! Мы, должно быть, где-то очень близко к разгадке всех тайн.
Также вы можете собирать любую статистику по любой функции, экспортируемой из вашего приложения! Правда, с опциями компиляции -O1 и выше большинство интересных функций может попросту пропасть из экспорта, компилятор «заинлайнит» их в код и вам не на чем будет ставить «пробы».
Брендан Грег (Brendan Gregg), апологет dtrace, стал учителем и наставником на все эти безумные дни:
In some cases, this [dtrace] isn’t a better tool – it’s the only tool.— заявлял он.
Вот здесь нечто похожее на то, что нам нужно, однако Брендан оставил комментарий:
FreeBSD: DTrace can be used as with Solaris. I'll share examples when I get a chance.До сегодняшнего дня случай ему, к сожалению, так и не выпал. Но по-сути там все то же самое, что и в Solaris, только вместо sbrk вызывается mmap\munmap.
Пришлось вникать в премудрости языка D. Многие области, например, приведение типов, особенно агрегированных значений, так и не удалось победить.
Вначале я решил испробовать немного переделанный скрипт отсюда:
Код
#!/usr/sbin/dtrace -s
/*#pragma D option quiet*/
/*#pragma D option cleanrate=5000hz*/
pid$1::mmap:entry
{
self->addr = arg0;
self->size = arg1;
}
pid$1::mmap:return
/self->size/
{
addresses_mmap[arg1] = 1;
printf("<__%i,%Y,mmap(0x%lx,%d)->0x%lx\n", i++, walltimestamp, self->addr, self->size, arg1);
/*ustack(2);*/
printf("__>\n\n");
@mem_mmap[arg1] = sum(1);
self->size=0;
}
pid$1::munmap:entry
/addresses_mmap[arg0]/
{
@mem_mmap[arg0] = sum(-1);
printf("<__%i,%Y,munmap(0x%lx,%d)__>\n", i++, walltimestamp, arg0, arg1);
}
pid$1::malloc:entry
{
self->size = arg0;
}
pid$1::malloc:return
/self->size > 0/
{
addresses_malloc[arg1] = 1;
/*
printf("<__%i,%Y,malloc(%d)->0x%lx\n", i++, walltimestamp, self->size, arg1);
ustack(2);
printf("__>\n\n");
*/
@mem_malloc[arg1] = sum(1);
self->size=0;
}
pid$1::free:entry
/addresses_malloc[arg0]/
{
@mem_malloc[arg0] = sum(-1);
/*printf("<__%i,%Y,free(0x%lx)__>\n", i++, walltimestamp, arg0);*/
}
END
{
printf("== REPORT ==\n\n");
printf("== MMAP ==\n\n");
printa("0x%x => %@u\n",@mem_mmap);
printf("== MALLOC ==\n\n");
printa("0x%x => %@u\n",@mem_malloc);
}
Выглядит достаточно просто: сохраняем все вызовы malloc\free, а также места их вызовов. На malloc — увеличиваем счетчик у адреса, на free — уменьшаем. Затем изучаем полученный лог и находим утечку (адреса с счетчиками > 0). Вся проблема заключается в том, что при ~150К malloc-ов в секунду, функция ustack() (сохраняющая стек, т.е. место вызова) начинает буквально хоронить весь процесс своим весом (похоже на случай с valgrind-ом). Я попытался убрать стек из вывода и просто собирать адреса и счетчики к ним, в итоге почему-то многие счетчики были глубоко в минусах (неужели испорченная куча и двойные освобождения?), а адресов с положительными значениями счетчиков практически не было… При этом dtrace часто плевался ошибками вида:
dtrace: 3507 dynamic variable drops with non-empty dirty list
dtrace: 2133 dynamic variable drops
dtrace: 120 dynamic variable drops with non-empty dirty list
dtrace: 993 dynamic variable drops
dtrace: 176 dynamic variable drops with non-empty dirty list
dtrace: 1617 dynamic variable drops
dtrace: 539 dynamic variable drops with non-empty dirty list
dtrace: 10252 dynamic variable drops
dtrace: 3830 dynamic variable drops with non-empty dirty list
dtrace: 17048 dynamic variable drops
dtrace: 39483 dynamic variable drops
dtrace: 1121 dynamic variable drops with non-empty dirty list
dtrace: 35067 dynamic variable drops
dtrace: 32592 dynamic variable drops
dtrace: 10081 dynamic variable drops with non-empty dirty list
Также часто мелькали сообщения о битых адресах в стеке.
Это наталкивало на мысль, что он просто не успевает правильно обрабатывать все события, поэтому счетчики уходят в минуса… Либо же это проблемы с кучей\стеком. Кроме того, вызовов free накручивалось в 1.5 раза больше, чем malloc-ов (значит, все-таки, двойные освобождения?)
Решил попросить помощи у участников почтовой рассылки dtrace.

Судя по архиву, некогда оживленная рассылка переживала не лучшие времена. К большому изумлению, ответ последовал в первые же минуты, хотя отреагировали всего два участника. Один посоветовал использовать аргумент, задающий кол-во кадров стека для сохранения: ustack(nframes). Это не помогло, даже ustack(1) убивал весь процесс. Еще посоветовали использовать libumem (полагая, вероятно, что я приполз с Solaris-а).
Дальше пошли бессистемные попытки, как то: сбор статистики по размерам, выделяемым malloc-ами, и попытка отфильтровать только определенные размеры, ну чтоб хоть как-то уменьшить частоту срабатывания датчиков. Безрезультатно, такое чувство, что ustack() задуман для самых минимальных нагрузок, скажем, до 100 вызовов в секунду. Или же нужно уметь его правильно готовить, сохраняя результат в какой-то бесконечный внутренний буфер, без раскручивания стека на каждом запросе. Но до этого, к сожалению, так и не дошло.
Попытался подойти к задаче с другой стороны — начать подсчет вызовов конструкторов и деструкторов всех объектов в коде, тогда мне фактически не нужно сохранить стек. Результатов это тоже не дало. Никаких расхождений выявлено не было, хотя, конечно же, я поленился «опробировать» все объекты в коде, а ограничился только лишь вызывающими подозрения.
О demangle
Для установки датчиков в вызовы своих функций, требуется произвести т.н. demangle имен. Тут, как на зло, FreeBSD подкинула очередной сюрприз. Простой:
обрушивает утилиту. Баг до сих пор не исправлен в 11.1. Пришлось запускать demangle-инг на одном из серверов с версией 11.0.
echo _ZZN7simlib318SIMLIB_create_nameEPKczE1s | /usr/bin/c++filtобрушивает утилиту. Баг до сих пор не исправлен в 11.1. Пришлось запускать demangle-инг на одном из серверов с версией 11.0.
Все стало походить на борьбу с ветряными мельницами.
Вообще, вывод dtrace уверял, что это не утечка, а испорченная куча \ двойное освобождение. Если это правда, то все очень плохо, без спец. библиотеки тут не обойтись.
Но все это оказалось полной ерундой и лишь увело от цели в сторону на несколько дней.
jemalloc
Примечательно, что в самой FreeBSD используется очень крутой и продвинутый менеджер памяти, еще аж с лохматой 7-ой версии. Вернее, я просто совершенно забыл про это… По количеству настроек и опций все остальные библиотеки-обертки даже рядом не валялись. Повозившись с доками, удалось запустить приложение с опцией:
setenv MALLOC_CONF utrace:trueПосле чего, следуя инструкции отсюда собрать (ktrace) и сгенерить (kdump) лог всех операций с памятью. В их числе оказались и realloc-и, которые в скрипте из статьи не работали, а вторая версия скрипта из комментариев (корректно обрабатывающая realloc-и) вела на несуществующую страницу (и даже «Wayback Machine» ничего не смог найти). Пришлось дописать поддержку realloc-ов, но по сути это дало лишь кучу указателей, где, возможно, происходит утечка, без какого-либо намека на то, где и кем они были выделены.
By skimming through nearby trace output, we may be able to understand a bit more about the location of the leak in the source too :-)— шутил автор статьи.
Чтобы заработали другие опции jemalloc-а (как-то: обнаружение двойных освобождений, выход за пределы массивов, расширенная статистика по обращению к памяти и т.п.), требовалась либо перекомпилляция всего ядра с доп. опциями, либо CURRENT сборка ОС (то, что удалось понять из man-а). Однако, шли шестые сутки поиска и дальнейшее копание в jemalloc было решено приостановить, хотя тема весьма интересна и я надеюсь к ней еще вернуться (надеюсь, не в похожих обстоятельствах).
Что в итоге помогло найти утечку
Поочередное отключение каждого модуля и подсистемы приложения и их комбинаций. Пойди я этим путем в самом начале — и проблема была бы решена в течении суток, но ведь сколько всего нового и интересного пришлось бы пропустить!
В каждой грустной истории должны найтись и положительные стороны.
Нотки позитива
- в процессе поиска иголки было исправлено некоторое количетсво мелких (и не очень) багов, в основном, выделения памяти, там где можно обойтись без оных;
- убран ARC ZFS (зачем он нужен на HTTP сервере, который ничего не пишет на диск, только память жрет, причем весьма существенно);
- проштудированы статьи на тему виртуальных деструкторов и прочих хитрых штук из мира C++;
- написан с десяток скриптов на D, просмотрено несчетное кол-во туториалов (по dtrace);
- погружение в разные реализации malloc\free, знакомство с понятиями arenas и slabs;
- изучены все изветсные баги, связанные с памятью во всех сторонних либах, использованных в проекте;
- узнал историю и драму, развернувшаяся вокруг ОС Solaris в последние годы ее существования;
- прокачаны \ восстановлены навыки работы с GDB.
Безумства, в которые не стоит впадать даже в моменты полного отчаяния
- послать все подальше и переехать на Linux. Думаю, эта мысль не раз посетила любого ярого приверженца FreeBSD, вызвана будь-то отсутствием полноценного Google Chrome, Skype, либо крутых самописных системных утилит. Не поддавайтесь панике, рано или поздно все проблемы решаться и вы вновь вернетесь к любимой ОС;
- попытки пролезть hex-view-ером в раздел со свопом (зачем? посмотреть что вытесняется из памяти и попробовать догадаться где утечка, хаха);
- выпилить всю многопоточность из приложения, чтобы большинство средств выше заработало;
- нанять фрилансера-профессионала, который все быстро починит.
Выводы
- Тщательное протоколирование всех изменений в релизах. Практически во всех случаях, утечка будет связана с одним из самых последних коммитов. Если вы крайне невезучи — то с коммитом за последние пару-тройку месяцев. Пробуйте откатывать все изменения, по одному и в комбинациях, перепроверяйте все по несколько раз. Малейшая оплошность — и вас унесет на несколько дней\недель не тем течением;
- Если вам дорого время — не пытайтесь использовать универсальные средства обнаружения утечек, особенно в high-load проектах;
- Не хватило виртуозности владения dtrace и можно было бы ухитриться обрабатывать только небольшой процент всех запросов. Но тут в post-mortem обработке нужно правильно отфильтровать ложные срабатывания и т.п. На освоение такого подхода, к сожалению, не хватило сил и времени.
Считаю финал этой истории крупным везением. Повезло, что утечка стабильно воспроизводилась на всем протяжении поиска. Что была возможность сколько угодно раз перезапускать заново собранное приложение на одном из релизных серверов без особого вреда пользователям. Что от релиза бага до возникновения проблемы прошло всего несколько дней, а не пол-года, когда шансы найти проблему стали бы исчезающе малы…
Вопросы и ответы
Так в чем же, все-таки, была причина утечки?
Как упоминалось выше, сервер проводит аукцион среди ответов вышестоящих серверов. Если ответов приходит больше максимального значения, то они «обрезаются» (берется top N results).
Топ хранится в std::list, где элементы — это указатели на объекты-биды. Один из коммитов привнес такой чудесный код для обрезания топа: list.resize(max_results). Как вы уже догадались, list.resize не вызывает delete на элементы-указатели. Нужно пройтись и ручками освободить память всех лишних указателей до вызова resize.
Почему такое продолжительное время после релиза версии с багом утечка не давала о себе знать?
Ответы серверов всегда влазили в top N results и ничего не обрезалось. Просто у определенных пользователей в какой-то момент ответов стало больше и они перестали влазить в топ.
Почему откат на предыдущие версии не помог сразу выявить проблему?
Здесь сыграл человеческий фактор. Дело в том, что на старте приложение начинает весьма активно отъедать память, замедляя интенсивность в течении несколько часов. Вероятно, в угаре поиска, это было воспринято как продолжающаяся утечка, и проблемное место выявить не удалось.
Почему проблема всплыла лишь на определенной части серверов?
Из-за обслуживаемых на данной группе серверов аккаунтов. У каких-то из них в аукционе стало возвращаться огромное количество бидов, не влазящих в топ. У остальных аккаунтов, обслуживаемых другими серверами, в топ аукциона попадали все ответы, либо редко превышали макс. размер списка.
Расскажите свои истории борьбы с утечками, особенно на ЯВУ. Действительно ли способ «рестартуем приложение каждые N минут» настолько популярен в качестве универсального решения? Так ли же все печально в среде ОС Linux или «tcmalloc и co.» действительно сходу помогают «найти и обезвредить»?
UPD1: Пока готовил этот текст, случайно наткнулся на возможность выявления утечек средствами clang, интересно было бы попробовать…
Спасибо всем, кто дочитал до конца!
eao197
Думаю, в статье следовало бы сделать ремарку о том, что в DTrace используется свой D-язык, который не имеет ничего общего с другим языком D.
У вас что, реально был list в котором лежали просто голые указатели? Даже не list unique_ptr-ов?И еще вот это:
atd
Вообще, сам по себе лист (или массив) голых указателей — не преступление.
Проблема наступает когда не учитывается ownership объектов, куда они указывают (тут можно порекламировать Rust, но не будем). Нужно решить кто является овнером (на всё время жизни) и воткнуть туда unique_ptr, но если вообще ничего не понятно, и указатели прилетают то слева то справа, то можно обложить всё shared_ptr-ами, хотя тогда становится не ясен профит от использования плюсов, в таких случаях лучше уползти на java/c# ))
tangro
Преступление-преступление. Если этот лист — единственный, кто хранит эти указатели, то это должно быть явно выражено в коде — использованием unique_ptr. Если есть и другие пользователи этих указателей — shared_ptr. И профит по сравнению с java/c# всё-же есть, поскольку shared_ptr гарантирует немедленное удаление объекта при освобождении указателя всеми владельцами, а java/c# ничего не гарантируют.
А лист голых указателей значит — «я тут написал код, который понимаю только я и только сейчас, модель владения объектами есть только у меня в голове и никому я её не расскажу».
atd
> И профит по сравнению с java/c# всё-же есть, поскольку shared_ptr гарантирует немедленное удаление объекта при освобождении указателя всеми владельцами, а java/c# ничего не гарантируют.
В этом у манагед-языков как раз и профит. На плюсах мы будем постоянно ковырять общую кучу, что не так быстро. (либо придётся озаботиться арена-аллокаторами), а ГЦ потом просто соберёт весь этот хлам скопом, что обычно шустрее.
eao197
DarkWanderer
Расскажите, пожалуйста, о новых? По моему опыту, к сожалению, C#/Java гораздо адекватнее работают с памятью — несмотря на детерминированность. Было бы интересно послушать, что же нового придумали в native
eao197
Это вам нужно поинтересоваться тем, как работают jemalloc (например) или tcmalloc (например).
eao197
maksqwe
Кстати, недавно в boost добавили полезную либу — Boost PolyCollection. Предназначена для хранения полиморфных объектов, хранящий в себе указатели на объекты базового класса. По тестам более эффективный нежели vector<unique_ptr>.
Подробности тут:
bannalia.blogspot.com/2014/05/fast-polymorphic-collections.html
www.boost.org/doc/libs/1_67_0/doc/html/poly_collection.html
robert_ayrapetyan Автор
Использование std::list в этом месте месте обусловлено, в первую очередь, необходимостью вызова sort. Поделитесь более эффективным способом отсортировать большой массив структур более 10К раз в секунду?
eao197
Так у вас list голых указателей на структуры или list структур, внутри которых есть указатели?
robert_ayrapetyan Автор
Конечно list голых указателей. Иначе бы на resize вызывались деструкторы структур и утечки бы не было. Но это непозволительная роскошь, двигать структуры при сортировке.
eao197
Ну и насколько, по вашим замерам, сортировка list-а голых указателей эффективнее сортировки vector-а или deque голых указателей?
robert_ayrapetyan Автор
Согласен, list примерно на 20% медленнее vector-а на сортировках, а у нас там много чего еще (например, операций удаления из середины некоторых бидов), поэтому по совокупности list выигрывает в нашей задаче.
eao197
В вашем бенчмарке еще очень не хватает reserve для vector-а перед заполнением. Ну а как себя показывает deque в сравнении с list-ом в совокупности (на сортировке он же выигрывает)?
robert_ayrapetyan Автор
reserve накинул еще пару процентов разрыва:
Run on (1 X 3491.99 MHz CPU )
2018-04-27 11:49:10
— Benchmark Time CPU Iterations
— BM_list_smart 14538337425 ns 14505242000 ns 1
BM_vector_smart 11492866976 ns 11462727000 ns 1
BM_deque_smart 12638374021 ns 12605011000 ns 1
Дек не пробовал. Вообще стоит, конечно, пересмотреть все используемые структуры, коду 7 лет в обед…
cebka
Сортировка много раз в секунду? Эм, heap на векторе же. Хотя стандартный priority_queue, конечно, совершенно никчемный (как обычно) и не позволяет динамически менять вес элементов. Но сама структура данных позволяет это делать за O(log N), что явно быстрее полной сортировки.
robert_ayrapetyan Автор
Ну вот тесты выше показали, что std::sort на векторе\списке — 20% потерь на списках. Но в совокупности с удалениями из середины (которых, в принципе можно вообще избежать, перестроив логику). В общем вопрос открытый.
cebka
Вектор обычно быстрее даже с учетом удаления из середины. Причем, быстрее на порядки. А вот необходимость сортировки, да еще и такой частой — как раз вопрос к структуре данных.
robert_ayrapetyan Автор
Вектор в сравнении со списком выигрывает лишь в одной операции — обращение к произвольному элементу, а проигрывает в двух: удалении\вставке произвольного элемента. В остальном они абсолютно идентичны (кроме ~20% в сортировках из-за оверхеда на указателях, используемых в реализации самого списка). Поэтому «быстрее на порядки» — не корректное заявление.
Сортировка необходима в аукционе, ответы приходят в произвольном порядке (каждый ответ содержит набор разных цен), и нужно либо сортировать при вставке (дорого), либо один раз в конце (наш вариант).
cebka
Я не хочу спорить с вашими "проигрывает", которые моими тестами не подтверждаются. Сортировать при вставке ничего не надо, если это вставка в heap (или изменение веса в нем же). Собственно, тут тоже спорить не о чем, если вы не понимаете, как и для чего работает heap, или же я не понял ваших задач.
robert_ayrapetyan Автор
Покажете код?
robert_ayrapetyan Автор
Перечитал и понял, что вы скорее всего, недопоняли про «Сортировку много раз в секунду». Здесь имеется ввиду что на входящие 10К запросов происходит 10К независимых аукционов, в каждом из них сортировка (в списке) происходит один раз, в конце. Я в курсе что при вставке в кучу сортировка происходит автоматически, только это дороже чем сортировка один раз в конце.
khim
А сколько вы потом отрезаете? С кучей есть один прикол, про который не стоит забывать: эта структура просто-таки создана для того, чтобы все префетчеры перестали работать. Так что если ваша куча влазит в L1 — то она реально очень быстрая и клёвая. А вот если нет — тогда вдруг происходит кратное замедление.
10K запросов в кучу пихать не нужно, а вот если вы возьмёте priority_queue и будет хранть 100 лучших результатов, которые вам реально нужны — результат будет совсем другой.
mayorovp
(комментарий был удален)
mayorovp
Только надо не забыть что при хранении 100 лучших результатов в пирамиде эту самую пирамиду нужно затачивать на поиск худшего результата, а не лучшего. Это совсем не очевидно…
khim
Ну это же классическая задача для собеседования… Я думал об этом уж все точно знают…
0xd34df00d
Перед тем, как вставить/удалить произвольный элемент, его неплохо бы найти. А для того, чтобы его найти, надо к прочим произвольным элементам эффективно адресоваться. А ещё если у вас вектор тупых элементов, то вставить элемент в середину при условии невыхода за capacity — это тупо memmove элементов справа от него. А memmove — это быстро.
Другое дело, что у вас и так скорее всего уже pointer chasing, и львиную долю профита от кеша оно убивает, поэтому вектор у вас выигрывает всего на 20%, а не, скажем, в 10 раз.
Третье дело, что элементы можно и не удалять из середины, а помечать как неиспользуемые, а удалить как-нибудь одним махом в конце. Ну, это если вам правда скорость важна.
В любом случае, вектор — разумный выбор по умолчанию, если только вам не нужны гарантии на инвалидацию итераторов, о чём уже упомянул eao197.
Antervis
list T* плох не потому что list, а потому что list T* вместо list T. Это, конечно, если по большому O и замерам он действительно обходит vertor.
Самый эффективный способ — не сортировать вовсе: попробуйте set/multiset. Можете также попробовать priority_queue
robert_ayrapetyan Автор
На абстрактном тесте на вставку\сортировку получается примерно так:
Run on (1 X 3491.99 MHz CPU )
2018-04-27 21:01:45
— Benchmark Time CPU Iterations
— BM_list_smart 14358524911 ns 14249840000 ns 1
BM_vector_smart 11455311425 ns 11442017000 ns 1
BM_set_smart 15602568549 ns 15579649000 ns 1
BM_pqueue_smart 12102934676 ns 12087128000 ns 1
Код — collabedit.com/4ex6s. Но, опять же, раньше там были вставки\удаления из произвольных позиций, с тех пор много чего поменялось, а «список» остался. Не знаю почему все кинулись оптимизировать этот код, было бы интереснее послушать про истории утечек в ЯВУ.
Antervis
опять list unique_ptr'ов…
удаление из произвольной позиции list'а — O(N) поиск элемента и O(1) удаление. Удаление из произвольной позиции vector — O(1) поиск и O(N) удаление. У set поиск+удаление O(log(N)).
robert_ayrapetyan Автор
На голых вставках «вектор» быстрее «списка»:
BM_vector_smart_ins_rm 15327045208 ns 15315396000 ns 1
BM_list_smart_ins_rm 21855116654 ns 21838877000 ns 1
Но с циклом рандомных вставок\удалений уже начинает отставать:
BM_vector_smart_ins_rm 30417423216 ns 30374146000 ns 1
BM_list_smart_ins_rm 29354732199 ns 29316292000 ns 1
В итоге к финишу они приходят одновременно.
Если честно, я потерял нить спора. Кто кому что пытается доказать?
Antervis
Я пытаюсь не доказать, а объяснить. ideone — тут наглядно видна разница между list указателей и list значений. Я, конечно, удивлен сильным отставанием set, но попробовать всё равно стоило. Тест вставок/удалений из случайных позиций для set не имеет смысла. А еще priority_queue уходит вперед vector/list/deque.
Antervis
upd: проглядел, что вместо сравнения объектов по значению, тест в половине случаев сравнивает указатели на них. В итоге с корректным компаратором list T* резко проседает, а priority_queue сильнее вырывается вперед
0xd34df00d
В каком смысле рандомных?
0xd34df00d
Разница между двумя указателями и одним сильно меньше, чем между одним указателем и нулём указателей.
Почему это не сортировать вовсе? Просто сортировка размазывается по всем вставкам, и последовательный доступ очень неэффективный (с точки зрения кеша, например).
Надо смотреть на все случаи использования конкретной структуры данных и профилировать, иначе это тычки пальцем в небо.
Antervis
сложно было без замеров сказать, будет ли там быстрее vector/set/priority_queue, а вот замена list T* на list T дает гарантированный прирост
Так я ж сразу писал: «попробуйте то, попробуйте это...». В теории set должен был быть выгоднее, но там кеш миссы подкосили.
да не совсем. Вставка N элементов в сет — N log(N). Сортировка — тоже, но сортировка (судя по всему) там проводится периодически, через каждые M вставок/удалений где M << N. Плюс у автора, как я понял, структуры данных побольше и эффективно не мувятся.
robert_ayrapetyan Автор
Согласен, почему-то всегда считал, что все умные указатели дают значительный оверхед, на тестах это сейчас не подтвердилось. Буду переделывать. Но и за 7 лет проекта это первая проблема такого масштаба.
0xd34df00d
Судя по тому, что виртуальные деструкторы там оказываются хитрыми штуками из мира С++, совсем неудивительно.
robert_ayrapetyan Автор
Ну, как правило, для чего конкретно нужны виртуальные деструкторы, вам вряд ли кто-то расскажет уже через неделю после пройденного собеседования. Да, я искренне считаю удаление класса-наследника через указатель на базовый класс «хитрой» штукой. Если не это, то что?
0xd34df00d
Сочувствую вашему пулу кандидатов.
Упомянутые ниже expression templates. Написание правильно работающего кода с move-семантикой (да и то не то что хитро, просто пока непривычно). Любимая мной наркомания на темплейтах. Ну, к слову о темплейтах, попробуйте поиграться с Boost.MPL/Boost.Hana. Или Spirit x3, например.
tangro
Ну блин, как так можно? Плюнули на последние 10 лет прогресса С++ в плане управления памятью — вот вам и проблемы. Умные указатели вам в помощь.
ZaMaZaN4iK
Согласен с комментаторами выше — std::list без умных указателей — варварство какое-то (но вполне возможно, что у Вас просто не C++11. Тогда могли бы из того же Boost использовать).
Меня волнует другой вопрос — КАК у Вас получилось решать проблему утечку памяти не натолкнуться за эти 6 дней на санитайзеры? У меня по первой ссылке в поиске на SO есть реакомендация ASAN.
robert_ayrapetyan Автор
Честно говоря, термин «санитайзер» впервые встретил перед публикацией, случайно поискав тему утечек на хабре (clang-овский кто-то упоминал в комментах к какой-то статье). А гугловский нашел только что.
Расскажите насколько замедляется приложение при его использовании и какие есть подводные камни. Спасибо!
0xd34df00d
Замедляется в пару-тройку раз. Подводные камни в том, что требуется сильно больше вирутальной памяти, что в моей практике иногда больно, когда приходится отлаживать жрущую по паре сот гигов (в нормальном режиме) бигдату.
Ну и перекомпилировать с ним надо, и чем больше проблем вы хотите находить, тем больше зависимостей.
apro
Вообще-то они все гугловские. Просто команда из google их реализовала для gcc и clang в свое время.
prospero78su
Что только люди не сделают, лишь бы не пользоваться языками с автоматическим управлением памятью.
Dima_Sharihin
В C++ есть автоматическое управление памятью
prospero78su
Не сомневаюсь. А она в рантайме, как часть языка, или её надо прикручивать, и поэтому её лень прикручивать?))
Dima_Sharihin
Она явная, появляется, когда вы решите, что она вам нужна.
Как пример: std::shared_ptr/std::uniqure_ptr, placement new и move semantics
prospero78su
«когда решите, что она вам нужна» — ключевая фраза. Это означает — лень, и её не будет.
В прикладнухе (* не на контроллере а-ля stm32 *) — автоматическое управление памятью надо в любом случае. Сначала все над Виртом смеялись с его Обероном, потом внезапно нарисовалась Ява, за ним Сисярп, и наконец — сам Роб Пайк, любитель всяких Си — сделал golang, и внезапно — то же с garbage collector!!!
Но нет. В С++ программист всё ещё решает, нужно ли автоматическое управление память или нет. (* хотя существуют исследования, доказывающие, что автоматическое управление памятью даже в плане производительности бывает заметно лучше, чем ручное управление *)
А потом рождаются вот такие героические посты.
Dima_Sharihin
Ну, стандартные типы STL все довольно-таки безопасны. "Плоские" указатели в С++ — это не стандартная фича языка, а необходимое условие для совместимости с чистым Си.
C++ — язык для всего (в отличие от жабаскрипта, сисярпа, и жабы), поэтому навязывать прикладные подходы от настольного программирования не совсем правильно. К тому же С++ используется там, где традиционные подходы оказались непроизводительными и там действительно уже нужно явно контроллировать узкие места.
А вот про std::resize поверх std::list<T*> — это явный прокол, объясняющийся банальным непониманием работы стандартной библиотеки. Такие косяки допускаются в совершенно любом языке и их причина — не дизайн языка, а банальная невнимательность
prospero78su
И всё-таки я отнесу этот прокол и ещё массу подобных (* недавно была прекрасная статья про оптимизацию выполненную компилятором *) — на необозримость языка, а значит его неуправляемость. Как плохой дизайн.
Про golang не скажу (* там явно кривоватый дизайн *), а тот же родоначальник их всех (Ява/Сисярп/Голанг) — Оберон в инкарнации Оберон-07 (для stm32) или Компонентный Паскаль (для прикладнухи, по сути — брат-близнец) прекрасно работают там, где заявляется приоритет С++.
Они не позволяют делать опасные вещи, а если позволяют — то позволяют это явно, и всё-равно — на тех, кто такие вещи себе позволяет смотрят ооочень криво.
Оберон-подход и Си-синтаксис, в-целом — победил. Я понимаю, что наработаны мегатонны либ в С++, но я правда не понимаю, что за такая странная любовь у мышей к пожиранию кактусов?
Dima_Sharihin
Это скорее стремление не городить велосипеды. C++ позволяет нативно сливаться в экстазе с Си, на котором написаны ядра операционных систем, системные библиотеки и прочие непотребности.
Писать любую обертку для "безопасного языка" — долго, сложно и неблагодарно. Кто хоть раз писал тысячу [DllImport] в дотнете, знает, как хочется просто за#includ'ить заголовочный файл нативной библиотеки
prospero78su
Вот честно слово, никогда не считал использование сборок с define DEBUG велосипедом. Ну вот прям везде есть этап испытаний и опытной эксплуатации. Это неизбежно, это необходимо. Это ладно, если софтина ими же самописная, а если она передаётся клиенту? Это откровенный технический долг, за который платит клиент.
Долго, сложно и благодарно.
Зная, что твой инструмент не позволяет выстрелить тебе в ногу — поиск жучков сводится к вопросу: «Что можно сделать ЗДЕСЬ, чтобы исправить баг ТАМ?».
По личному опыту: софтина работает уже почти 3 года без остановки, за этот период ни одного сбоя. Безопасный язык и его приятный привкус.
Dima_Sharihin
И С++ тут ни при чем, опять же. Утечку памяти можно сделать и в C#
Использование умного или намеренно тупого языка не освобождает от отвественности тестировать свой код
Касаемо С++ стоит различать язык "до C++11" и после. То, что было раньше — треш и угар, хорошо, что тот "цэпэпэ" от нас почти ушел.
Современный C++11/14/17 по удобству очень похож на C#, разве что Linq нет и рефлексии (но рефлексией и в дотнете не так часто пользуются)
prospero78su
В статье С++ (если я правильно понял) — как раз при чём.
Да, в C# можно сделать утечку. Делал сам, проверял. Но это надо сделать специально.
Наверное да. Но не в этот раз. И видимо — не во многие следующие.
Dima_Sharihin
Указанный в статье способ — тоже специально.
PsyHaSTe
Не хочется. Тем более, что почти всегда в нугете есть подходящий враппер, накрайняк pinvoke.net в помощь.
Ну в более новых языках типа раста есть вполне себе удобный bindgen. Кто-то там по-моему целый MySQL перегенерировал на расте. Не сказать, что безопасности написанного кода прибавилось, но вот работать уже с ним можно без извратов с «экстазом».
0xd34df00d
Эта любовь позволяет писать весьма высокопроизводительный код (хотя плюсы таки для этого приходится, увы, немножко знать). Я не слышал про хайлоад-серверы или хардкорные матричные библиотеки (привет, кстати, expression templates) на обероне.
eao197
Именно это и делает C++ до сих пор востребованным.
Эти же исследования доказывают, что для достижения сравнимой производительности нужно иметь в четыре раза больше RAM, чем для такой же программы, но написанной на языке с ручным управлением памятью.
prospero78su
Не сомневаюсь. Limbo широко использовался? Там что-то было принципиальное?
Когда ко мне (в мою контору) приходят люди со знанием С++ они искренне недоумевают, почему мне такие специалисты не нужны. Даже с учётом прекрасных навыков и большого опыта.
Да. И речь идёт про 250к+ памяти.
Ну не смейтесь пожалуйста. Сейчас после gcc меньше 600к+ «hello, world» не бывает.
Dima_Sharihin
У меня на GCC в 400 килобайт поместилась полностью прошивка железки, в которой есть веб-сервер, telnet-консоль, драйверы периферии, поддержка файловых систем и вебморда с картинками (которая занимает половину из всего объема прошивки).
Так что про Hello World это громко.
Да, поддержка стандартной библиотеки неплохо раздувает код, но не настолько, как впиливание garbage collector в memory constrained платформу
prospero78su
У меня на Оберон-07 для stm32 — прошивка уместилась в 4,3к (* Так, милый пустячок любимой даме *). Игрушечка умеет терминал, расписание, уход часов с автокорректировкой и всё такое. GC там нет (просто не предусмотрен), но лазить грязными руками в память даже stm32 на Оберон-07 — фу, не камильфо. А по другому там течь просто не может от слова «совсем».
Ах да. 32к рамы.
eao197
Чтобы говорить конкретно про вашу контору, нужно знать, что это за контора, чем она занимается и насколько успешно. Но здесь речь не об этом, а о том, что не смотря на то, что в большинстве случаев языки с GC успешно справляются, все равно есть ряд областей, где от GC больше вреда, чем пользы. И вот в таких областях чтобы отказаться от C++ и выбрать какую-нибудь Java, нужно иметь очень веские доводы (ну или альтернативный способ мышления). Насколько я слышал, он-лайн аукционы рекламы — как раз относятся к таким областям.
Это вы не смейтесь, речь про приложения, в которых потребление памяти измерялась сотнями мегабайт, а сейчас уже и десятками гигабайт.
prospero78su
Поинтересуйтесь на досуге, на чём были написаны до недавнего времени множество версий golang.
Java? В таких областях используют Оберон. Например БПЛА, боевые самолёты, атомная станция, сельскохозяйственные комплексы и суровая энергетика. Там нет GC (как правило), но и память не течёт.
Очевидно Вы не в теме. Эти исследования проводились, когда типичная память машин была 4-8 МБ с интенсивным выделением и освобождением памяти.
0xd34df00d
У меня есть софт, который жрёт много десятков, если не сотен, гигабайт памяти. Ну там просто десятки миллиардов флоатов, что с них взять.
Если бы язык требовал бы в четыре раза памяти больше на GC, это было бы неприятненько.
prospero78su
GC не требует в четыре раза больше памяти, чем через руками. Это кусок рантайма. +2..5 МБ. А если ещё вспомнить про поколения, да переиспользование памяти, да количество дублирования ручного выделения/освобождения… Так оно ещё и по скорости +30% будет. Подсчёт ссылок — это ровно одно слово на переменную/структуру. Тесты на дебиане, конечно сильно синтетические, но всё же С++ голангу проигрывает по памяти в половине случаев. А уж Ява/питон енд компани…
eao197
Quantifying the Performance of Garbage Collection vs. Explicit Memory Management, 2005-й год:
Тут говорится, что приложение с GC будет показывать такую же или даже лучшую производительность, но ценой расхода дополнительной памяти. В частности, для достижения такой же производительности требуется в пять раз больше памяти.
На что ссылаетесь вы — хз. Впрочем, ереси вы здесь и так уже наговорили порядком.
prospero78su
Я не знаю, где взяли эту геббельсовскую пропаганду, вот вам на русском языке вполне авторитетный сайт:
Читать здесь
Тут говорится — прямо противоположное.
eao197
Результаты бенчмарков по вашей ссылке где?
prospero78su
Я так понимаю, вас так забанили, что и прокси не помогают?))
3 раза С++, 1 раз голанг. В остальных случаях вровень. По скорости явная преимущество у С++ 2 раза в конце. И то, алгоритм, реализованный на Го, имхо, не оптимален.
eao197
Полагаю, что для человека, который предпочитает не писать тесты, нормально давать ссылку сперва на MSDN, где никаких замеров нет. А потом ссылку на Benchmark Game (за упоминание которого в приличном обществе с человеком уже давно перестают разговаривать). Только меня это все больше убеждает в том, что у вас уж очень альтернативный стиль мышления.
Но вот что видно по расходу памяти по вашей же ссылке на Benchmark Game: Go потребляет меньше памяти в бенчмарках reverse-complement, fannkuch-redux, n-body, k-nucleotide. Все. Четыре случая из десяти.
На игрушечных примерах. Если ваши познания о накладных расходах на GC и ручное управление памятью базируются только на примерах из Benchmark Game, тогда ой. Спорить с вами невозможно.
prospero78su
1. Человек не предлагает не писать тесты. Человек предлагает втыкать всюду проверки, где только можно. Эффективность оборонительного стиля в обнаружении недопустимых результатов в ряде случаев выше, а временные и контекстные затраты — на порядки меньше. Контрактное программирование и инварианты прекрасная альтернатива тестам.
2. Если вы считаете, что те люди, которые делали в МС сборщик мусора с поколениями — не делали никаких тестов и там держат школоту — ну тогда больше разговаривать не о чем.
3. Вы просили ссылку — я вам дал. И обратите внимание на мою оговорку:
И после этого вы мне предъявляете, что я не читаю комментарии??)))
То вам ссылку подай, то ссылка не такая, то в МС лохи сидят и творят непонятно что… Вы уж определитесь))
Разницу в 1-20 МБ вы правда считаете серьёзной? С преимуществом с автоматическим управлением памяти? Вопросов больше нет))
Вы просили ссылку — я вам привёл ссылку. Где ваши ссылки? Пока что от вас я слышу только бла-бла-бла.
eao197
Сможете дать точную цитату где я что-то подобное вам «предъявлял»?
Актитесь, любезный, я вам дал ссылку на серьезное исследование, а не на маркетинговый булшит.
prospero78su
Проверки заменяют тест. Более того, тесты не проверяют логику. Тестер напишет тест так, как ему объяснил программист. И таким образом тест повторит кривую логику программиста. Тест проверяет на допустимость входных данных, и допустимость выходных данных. Зачем это делать, если пре-, ин- и постулсовия делают тоже самое и постоянно? И если где-то в другом месте данные приготовлены не верно, они из этого места даже не выйдут, а если выйдут — значит кто-то схалтурил и получит по башке. В любом случае, даже интеграционные тесты — вообще ничего не доказывают. И программист, когда пишет код — владеет контекстом более широким, чем тестер. Уж наверняка программист точнее определит граничные условия.
Видимо, вы не писали с соблюдением контрактов. Моя программа уже 3 года на подстанции 110 кВ работает и ни одного падения. Но прежде чем программа была принята в практическую эксплуатацию, у неё было 2 месяца опытной эксплуатации, и даже тогда — никаких падений не было. Да, были доработки по пожеланиям, но не более.
Пожалуйста:
Т.е. если вдруг окажется, что решение без сборщика мусора на C# будет работать быстрее, чем со сборщиком мусора на C#, ссылка на указанную статью от МС не будет поводом засудить их в суде?))
eao197
Не могу понять логику того, кто написал сей шедевр.
Во-первых, не «тестер», а «тестировщик». Во-вторых, если у вас тестировщик пишет тесты со слов программиста, то с тестированием у вас такие же проблемы, как и с логикой.
Да куда уж нам.
Аргумент, да.
Да уж, если это пример для «И после этого вы мне предъявляете, что я не читаю комментарии?», то мне остается только поинтересоваться «А с головой у вас все нормально?»
prospero78su
Вот объясните мне. Программист неправильно понял поставленную задачу. Был невнимателен, забыл, заболел и пришёл другой, криво написанное задание манагером, некорректно описана спецификация оборудования. И сделал код, который проходит все тесты, даже интеграционные, но результат управления оборудования печальный. как тестирование здесь поможет? Если у меня есть контракт, то я знаю, что быть должно, и чего быть не может. И если заслонка шибера не открывается на 100% при заданных условиях, я знаю фамилию конкретного программиста, который поленился написать инварианты для своего куска кода (да, у меня весь код подписан персонально). И если какой-то компонент оказался сбоку припёка, потому что кто-то не выполнил проверку на возвращаемые значения, на их количество, на их значения — я и в этом случае могу точно сказать кто, почему и где. Зачем мне тесты там, где они не нужны? Во всех остальных случаях, существуют программы комплексных испытаний, аварийные тренировки и периодические проверки?
Покажите мне, где я написал «со слов программиста»? Я по личному опыту, могу вам сказать, что писать тест со слов программиста — это куда лучший вариант, чем писать тест по документации. Делаю выводу, что серьёзным тестированием и его организаций вы толком не занимались.
Да, это аргумент. 35 тыс. человек квартал на востоке Калининграда. Объекты электроснабжения первой и второй категории, социально-значимые объекты. Да, это аргумент.
А вы доктор?)) Я вам по существу ответил, а вы сразу на личности. Фу, как не красиво.
eao197
Я не доктор, но общаться с не совсем нормальными людьми, не умеющими в обычную логику, при этом считающими себя программистами, доводилось. И, боюсь, сейчас тот же самый случай. Поэтому не хочу лишний раз ходить по тем же граблям.
Вот ваши слова: «Тестер напишет тест так, как ему объяснил программист.» Дословно «со слов программиста» в вашей фразе нет, но я ее понял именно так.Вы, например, делаете допуск, что программист может получить неправильную спецификацию, может неправильно ее понять, могут быть неправильно написаны тесты. Но при этом вы не допускаете мысли о том, что с контрактами может быть все то же самое.
Это, в купе с другими вашими высказываниями, приводит меня к выводу, что конструктивного общения не получится из-за вашего альтернативного мышления. За сим прощаюсь. Жалею, что в очередной раз ввязался в разговор с вами.
Да, чтобы не оставлять повисших вопросов:
prospero78su
Я правильно понимаю, что вы себя считаете умеющим логику, и вы вполне нормальный?))
Я не программист. Пишу уже в который раз. И нигде не писал, что я программист, откуда вы это берёте?)) Вы уверены, что вы умеете логику?))
С контрактами — такое быть не может. Потому что контракт — это ограничение и требование внешнее, а логика — требование внутреннее. Почувствуйте разницу.
)) Не стоит. Именно поэтому я директор своей фирмы, а у вас мышление как у всех, что даёт некоторые основания полагать, что вы и дальше будете заниматься тестированием))
Ааа… Ну, если вы привыкли додумывать за собеседников, тогда это многое объясняет)) Думаю, вы уже поняли, что способов объяснить в эпоху, когда каждый человек умеет читать/писать (а тем более в такой области, как программирование) — как минимум на один больше, чем рассказать словами)) И уж если словами программист не смог объяснить логику тестеру, то такой программист или тестер работает точно не у меня)) (в зависимости от результатов разбирательства)
Antervis
важно не то, как работает сборка мусора, а как работает аллокатор в языках с GC. И если бы вы это знали, вы бы прекрасно понимали почему GC требует больше памяти. Это во-первых. Во-вторых, прикрутить (скажем) джавовский аллокатор вместо стандартного в плюсах можно. И если б он давал столь существенный прирост производительности, его б использовали повсеместно. В-третьих, обычно тесты c++ vs java/c# либо синтетические, либо откровенно плохо написаны. «std::list vs java array» — такое я уже видел.
prospero78su
Не важно от слова совсем. Распределение памяти работает, уборка работает, голова не болит. И Вы ошибаетесь, когда так самоуверенно заявляете, что я не знаю, как это работает. Распределение памяти со сборщиком мусора можно настроить и на оптимизацию объёма памяти, и на быстродействие. Такую же стратегию с ручным управлением реализовать невозможно.
Вы меня не слушаете. Плевать я хотел, что там и где можно прикрутить. Я хочу, чтобы программист работал меньше, а выдавал больше, а программы не текли и не падали. Потому что я ему — плачу зарплату.
В С++ есть автоматические указатели. Но как видите, не то что, сборщик мусора, даже автоматические указатели народ не пользует. По хорошему, программисты за такие решения и упущенное время — должны пропорционально возвращать зарплату тому, кто выдавал заказ на софтинку)
Какой существенный прирост производительности? В потерянной выгоде? В уроненном авторитете фирмы и небрежно поставленном назад? Может быть, клиенты довольны? Это, молодой человек, называется «технический долг», за который платят потребители труда программистов, которые плохо выполнили свою работу.
Ну прям в точку! Именно что, синтетические тесты не отражают истинной картины. И это прямо противоречит Вашему высказыванию сверху, о «столь существенном приросте производительности». Если бы это было так, никто бы не писал на питоне, Яве и т.п.
Ну так если скорость на практике не так важна, зачем Вы ссылаетесь на скорость?))
Цену имеет — только труд программиста. За труд и за качество кода, а не за скорость исполнения платит клиент)
0xd34df00d
Конечно, не требует. Извиняюсь за упущенное дополнительное предположение: «если бы язык требовал в четыре раза больше памяти на GC для обеспечения более-менее той же скорости работы».
Ну и можно сравнить производительность compactifying GC с производительностью copying GC, а затем сравнить их требования к потреблению памяти.
Ага, помещающаяся в L1/L2/L3 nursing area — это очень приятно, и если вы в иммутабельном языке вроде хаскеля генерируете много короткоживущего мусора, то это будет почти так же эффективно, как двигать вершину стека, да. Но как только у вас начинаются всякие долгоживущие данные, которые переживают первое поколение, начинается цирк с конями (на стр. 9 прикольные графики, кстати, рекомендую). А там и до ручного управления памятью недалеко.
Чего-чего?
В любом случае, на плюсах вам никто не мешает выделять на аренах нужного размера с нужным скоупом ручками, и реюзать/прибивать, когда нужно, и когда вы в своём алгоритме явно об этом попросите. Оно тогда будет сильно быстрее вообще всего.
Да, придётся писать довольно низкоуровневый скучный код руками. Но его хотя бы можно написать.
Иногда этого много.
prospero78su
Это уже не важно. Приобретаемые выгоды — перевешивают затраты. Ну, и не надо забывать, что стратегию GC можно настроить либо на оптимизацию памяти, либо на оптимизацию скорости, либо выдержать баланс. Сделайте это руками.
Я не сомневаюсь, что в Хаскеле начинаются интересные графики, но я сомневаюсь, что Хаскель вообще хорошо сделан в плане GC. У меня есть другие примеры других языков где весь рантайм влазит в L1 и работает это чудо на атомной станции, и все перекрестились после старого софта.
Не будет. Будет ровно также, как и с GC, который ровно так же выделяет память гигабайтами, если настроить. А отпускает сам, а не руками. И здесь я вижу преимущество.
Когда есть риск подвешивания за яйца — в 95% случаев — не много. А если много — возьмём на один сервер больше.
0xd34df00d
Ещё как важно. Не забывайте, что у всех разные задачи, и если вы пишете что-то для подстанций на три года, кто-то другой может писать что-то, что едва влезает в оперативную память, и что надо рассчитать так быстро, как только можно (и со всеми оптимизациями на полном датасете оно будет считаться на кластере из 20 сорокаядерных машин, скажем, две недели).
Впрочем, высоконадёжные системы без жёстких требований к производительности я бы не писал ни на плюсах, ни на джаве, ни на обероне.
Ну оно там джаву обгоняет, например. ghc'шный GC вполне неплох, кстати, просто там дефолты совершенно уродские, приходится руками дописывать всякое
+RTS -A8Mи тому подобные вещи.Проблема в том, что у меня как у автора (ну или хотя бы кодера) алгоритма априори больше знаний о том, что и когда мне понадобится, чем у GC (при некоторых дополнительных предположениях, конечно, но они почти всегда выполняются).
prospero78su
Я вроде как нигде и не утверждал, что мол а давайте плоскогубцами суп есть. Вы как-то странно обобщаете. Мы сейчас обсуждаем статью. Её текст сверху, ознакомьтесь на досуге.
Да, и такое бывает. Например, на stm32 всего 32к рамы. Вот я пишу на Обероне. Никакого ковыряния руками в памяти, памяти хватает за глаза.
В статье есть что-то про 20 сорокоядерных машин?)) Две недели обсчёт был?))
Вы берёте какие-то странные случаи. Ну, ладно. Пусть будет экстремальный случай: 20 сорокоядерных машин. И что, скорость, которая вся кривая и течёт — это хороший выбор? Вы серьёзно?))
«Обгоняет» — для практики — это не показатель. Для практики показатель — «начинаются интересные графики». Иначе бы вместо Явы все использовали Скалу.
Проблема в том, что Вы — живой человек. И априори где-нибудь, когда-нибудь допустите косяк о котором даже близко мысль не колыхнётся. У GC — не бывает такого. И это, там где есть серьёзные риски человек vs. машина — решает всё.
0xd34df00d
Так там и на подстанции три года непрерывно работать не нужно, и даже от периодических рестартов по крону никто не умер (кроме эстетического чувства автора).
Я под attiny13, что ли, с менее чем килобайтом рамы писал управлятор для установки для лазерной абляции чего-то там, ещё когда был школьником и С++11 ещё назывался C++0x и до его выхода было несколько лет. И тоже ничего не текло (кроме жидкости в сосуде для абляции), и в памяти ковыряться руками не приходилось.
Не хороший, отчасти потому, что это ложный выбор. Зачем им обязательно быть кривыми и течь?
А вы их посмотрели? Там интересность графиков в том, что обгоняет.
Конечно. Правда, тут есть несколько замечаний:
1. Я и не говорил, что всем надо резко писать на языках без GC. Для некоторых приложений я с удовольствием выберу языки с GC.
2. GC избавляет от очень мелкого класса проблем, которые, более того, почти всегда не влияют на корректность. Я бы предпочёл пользоваться программой, которая течёт и которую надо ребутать раз в час, но которая выдаёт заведомо корректные данные, чем той, что выдаёт лажу, но зато не течёт.
3. При соблюдении определённых очень простых правил можно писать вполне безопасный код на плюсах (ну там, никаких голых new и delete, только смартпоинтеры, только хардкор).
4. При соблюдении тех же правил и инвестиции малой доли времени проекта можно реализовать небезопасную, но единожды вычитанную реализацию арен-пулов-етц конкретно под вашу задачу и дальше радоваться жизни. Ну, это если скорость нужна.
prospero78su
А я нигде не писал «давайте всё бросим и будем писать на питоне».
А я, как работодатель не хочу, чтобы мне каждый час звонили заказчики и говорили: «Пришлите нам мальчика, пусть ребутнёт сервер, а то вот прога всю память сожрала. А ещё ваш счётчик моточасов вдруг минусы стал считать. А если вы ничего не сделаете до конца месяца — мы будем обращаться в суд».
Да нет. Вы заблуждаетесь. По каждому факту потери связи с вышестоящей организацией нужно писать объяснительную. И если вышестоящая организация посчитает, что потеря связи происходит слишком часто — вместо того, чтобы решать свои вопросы я буду вынужден тратить время (деньги) на чей-то косяк. Меня такое положение дел не устраивает.
Какой бы опытный программист не был, как бы аккуратно он не писал код — фактор кирпича, отпуск, болезнь, неурядицы дома — этого достаточно. Человек всегда допускает ошибки. И это решает.
Нет такой необходимости в скорости (ну по крайней мере в моей практике), ради которой можно пожертвовать качеством. Был бы у меня штат как у Майкрософт — да и наплевать, что угодно могу делать. Но нет. У меня каждая копейка на счету, каждому надо заплатить зарплату, каждому надо накормить семью. Я предпочту более туповатый, более медленный язык, но чтобы человек мог его освоить за пару месяцев до деталей, и глупую ошибку в нём было сделать невозможно.
eao197
Из статьи видно два откровенных косяка в управлении разработкой: во-первых, не было должного тестирования софта перед его отправкой «в бой» (если бы было, то ситуация, когда в топ бидов попадает только часть всех найденых бидов, была бы проверена еще на тестах). Во-вторых, когда утечка памяти обнаружилась, люди вместо того, чтобы отследить после каких изменений она началась, вернуться на нормальную версию и далее в спокойной обстановке искать утечку, бросились изучать инструменты, с которыми никогда дела не имели.
Это наводит на мысли о не сильно высоком уровне квалификации. В таких условиях люди и на языке с GC наломают дров.
prospero78su
Да, там явно определённые проблемы с культурой разработки. Лично я не вижу смысла писать тесты. Мне проще понавтыкать мягких ассертов с условной компиляцией и логированием подобных варнингов. Тесты в сильнотипизированных языках, с контролем указателей — не имеют особого смысла. Если логика поломатая, то едва ли это тест выяснит. Он только покажет, что поломатая логика правильно отрабатывает свою поломатую логику.
Собственно, да. Вместо метания по кусачкам и плоскогубцам — надо было с самого начала иметь свои кусачки и плоскогубцы (те самые, мягкие ассерты). Ну, и, простите, какие могут быть обновления на боевых серверах без опытной эксплуатации?
Но описанная проблема именно относится к ковырянию памяти руками. Судя по тому, что написано — там и другие ошибки обнаружены, и golang не стал бы волшебной палочкой. Но вот такую глупость — удалось бы отследить, имхо.
eao197
каминг аутстоль откровенное признание. Пожалуй, на этом общение с вами можно завершить.prospero78su
В договоре клиент хочет — за его деньги нет проблем. Если я гарантирую правильность работы — значит софт работает правильно, но
не писать != не вижу смысла писатьКак скажете.
Добрый совет: читайте внимательней текст.
0xd34df00d
Я тоже не вижу смысла писать тесты.
prospero78su
Имхо, тесты придуманы были для языков с высоким динамизмом а-ля питон.
Ты думаешь, что у тебя целое, а у тебя давно уж словарь. И в каком месте проскок — вообще не понятно.
И даже в питоне использование на входе
решает 99,5% проблем связанных с высокой динамической типизацией.
Оставшиеся 0,5% проблем вылезут на других уровнях. Например, периодический контроль входных параметров раз в 4 часа и по включению оборудования.
Элементы контрактного программирования + пре-, ин- и постусловия (инварианты) творят чудеса. Вспомните уроки физики и математики: при получении результата всегда делайте самопроверку и выводите размерность полученной физической величины. Провера результата — это допустимость диапазона, размерность — это та самая типизация.
Что все так в эти тесты вцепились-то?))
PsyHaSTe
С типизацией тестов надо меньше, но типы это не панацея. По крайней мере в распространенных языках нет типа «простое число меньше 10000», хотя это может быть важной частью алгоритма, в частности в дотнетовской BCL это важная конатнта для реализации хэшсета.
Пред и постусловия это прекрасно, но они тоже не все ловят. Эмерджентность во все поля, то, что каждый компонент работает правильно не гарантирует совместной корректной работы.
prospero78su
Вы так пишите, как буд-то я написал, что типизация — это 100% гарантия от ошибок. Я вообще не про типизацию писал. Я писал про инварианты, в ходе вычислений. Это немножко рядом.
Если вы не читали всё обсуждение, я напишу ещё раз: С++ допустил утечку памяти. И не важно: были тесты, не было их… С++ допускает утечку памяти, а значит — память будет течь неизбежно. А тесты — либо написаны не были, либо тесты отработали кривую логику, кривого алгоритма.
И продолжаться это будет до тех пор (априори), пока люди будут пользоваться такими инструментами.
Тесты нужны. Но не в трёх строках кода, и не на проверку выхода за границы массива. Все эти детские болезни должны решаться силами языка и обязательными требованиями к конкретному компилятору языка.
А чтобы (в вашем примере), простые чиселки правильно выдавались кодом — для этого достаточно реализовать небольшой тест на этапе прикидки «а как это вообще будет выглядеть», но не как тест, который нужно гонять каждые сутки, а как тест идеи. После чего кусок кода фиксируется, считается контрольная сумма и тест (регрессионный) — ему совсем не надо.
PsyHaSTe
«Простые чиселки» — это пример. Смысл писать полноценный тест на какой-нибудь контроллер веб-интерфейса просто чтобы показать что от них бывает польза я не вижу.
Что касается этой аргументации:
Это из разряда «сгорел сарай — гори и хата» и «чего мыться — все равно через неделю испачкаюсь».
prospero78su
Да, я это понял. Конкретный пример. Я ответил: тест идеи, а не тест того же самого кода каждые сутки.
Именно про это я и говорил выше.
Если используются инварианты напрополую — пожар остановится на уровне наименьшей области контроля. Обращаю Ваше внимание: не в области видимости, а в области контроля! Т.е. либо на входе в процедуру, либо внутри её, либо на её выходе.
Самозатухающий пожар) Пользуйтесь.
mayorovp
Покажите язык в котором невозможно организовать утечку памяти.
prospero78su
При чём тут
Я Вам совсем про другое говорю: С++ — сам по себе изначально порочен. В нём заложена сама идея утечки памяти. А если эта идея заложена — так и будет.
В питоне, голанге, Компонентном Паскале — заложена идея автоматического управления.
Речь не про то, где это невозможно, а про то, где это труднее. Вы разницу ощущаете?
А если Вы целенаправленно пожелаете выстрелить себе в ногу — тогда я Вам советую взять С++. В нём это сделать — на два порядка легче.
mayorovp
У вас был аргумент «допускает утечку памяти, а значит — память будет течь неизбежно». Так вот — он применим к любому языку кроме тех которыми никто не пользуется.
Изначальную порочность С++ вы еще не доказали.
prospero78su
У меня этот аргумент и остаётся. Если Вы считаете, что питоном никто не пользуется, а Компонентный Паскаль, который используется в ядерной физике, биотехнологиях, истребителях, банковском деле, на атомной станции — в расчёт можно не брать — ну тогда дискуссию можно закончить.
Ссылки можно испортить? Забыть отпустить память? Можно. Значит, порочен. Точка.
mayorovp
А в Компонентном Паскале есть указатели или хотя бы динамические массивы? Если есть — значит, утечка там тоже возможна.
prospero78su
В Компонентном Паскале — не бывает указателей, у которых можно свернуть башку. Или нечаянно — изменить тип. Или забыть разыменовать. Динамических массивов в Компонентном Паскале нет, именно по этой причине.
Память в нём — не течёт. Вообще. Никак. Никогда.
Если только Вы сами не полезете в псевдомодуль SYSTEM (* если в конкретной реализации он вообще есть *)
0xd34df00d
Поэтому я и написал там под спойлером что-то про зависимые типы.
Другое дело, что писать на таких языках сложно и требует определённого склада ума и математической культуры.
0xd34df00d
Тесты — это по-хорошему не только про строки и числа.
Мощная система типов позволяет вам выразить в коде размерности. Мощная система типов позволяет вам выразить те же контракты (вплоть до описания модели межсетевого взаимодействия и соответствующих стейтмашин) в виде типов, которые компилятор проверить на этапе компиляции и даст вам по пальцам, если
ваше доказательствоваш код расходится свашей теоремойвашими контрактами (привет, Карри-Говард).Короче, допустимость диапазона тоже может быть типизацией.
robert_ayrapetyan Автор
По поводу тестов — в топ и должна попадать только часть бидов. Тесты, способные сымитировать похожую нагрузку и ответы (и при этом еще и за памятью правильно следить) требуют минимум х2 в инфраструктуру серверов и разработку (и то никаких гарантий обнаружения подобных утечек). Это неоправданно дорого для нас. Потери времени и ресурсов от поисков подобных багов за несколько лет — ничтожны по сравнению с вложениями в тестовую среду уровня, о котором вы говорите.
По поводу отката на старые версии — вся первая часть статьи посвящена этому вопросу, а почему не обнаружили — в конце.
pdima
полезно и юнит тесты прогнать под valgrind, с таким багом valgrind показал бы лик на юнит тесте который проверяет обработку большего количества результатов чем max_results
eao197
olegator99
Посмотрите на современные инструменты. Например, мы для автотестов C++ кода используем набор из Gitlab CI + ASAN + TSAN + gcov + gtest + gbenchmark.
Если проект большой и давно живет, а автотестов в нем нет совсем, то дешевле всего его обмазать внешними, тестами — они позволяют приложив минимум усилий, дать максимум уверенности, что все работает так как надо. (следующий шаг это unit тесты c gtest/gbenchmark, они дадут более информативную диагностику, но их внедрить сильно дороже)
Объем инфраструктуры который требуется:
Для небольших команд ~10 человек — вся эта инфраструктура спокойно влезет на 2 виртуалки работающие на 1-м физическом сервере.
Общий подход примерно такой:
Конечно, шаги 2) и 3) потребуют вложить заметное количество усилий, но они себя очень быстро окупят.
Что имеем на выходе:
1) проверка что, ничего не утекло (после выхода бинарь инструментировнный ASAN выдаст список того, что утекло)
2) убедимся, что не было рейсов (TSAN сборка в этом поможет)
3) сможем посмотреть глазами, какой процент кода оказался покрыт нашими тестами (gcov инструментарий даст общий % покрытия и подробный репорт, и покажет в какие строчки попадало управление, а в какие нет). На основании этой информации расширяете покрытие тестами.
И это все работает в весьма скромной аппаратной инфраструктуре.
robert_ayrapetyan Автор
Может, опубликуете статью, как весь этот зоопарк поднять и настроить?
olegator99
А вот были таки мысли. Время только найти бы на это
dendron
Поражает обилие комментаторов желающих щегольнуть своими познаниями не по делу. Задним умом все умные. Человек пришёл поделится опытом и историей, его закидали какахами. Такое чувство что токсичность и высокомерие особенно присущи сообществу C++.
Автору спасибо за познавательный обзор отладочных инструментов.
robert_ayrapetyan Автор
Спасибо! По unique_ptr комменты, считаю, по делу, остальное — все больше по оптимизации, интересно подискутировать.
0xd34df00d
Это очень хреновый обзор, потому что вводит в заблуждение, одного разбора tcmalloc достаточно. HEAPPROFILE указывает, куда дампать снимки памяти, линковка с tcmalloc, собственно, переопределяет malloc/free, можно и не линковаться, но тогда надо LD_PRELOAD (и аналог на freebsd). Если автор пытался просто засунуть путь в HEAPPROFILE без прелоада/линковки, а потом отдельно линковался, и у него тоже ниработало — это какое-то фундаментальное нежелание задавать вопросы уровня «а как оно, блин, вообще должно работать из первых принципов?»
robert_ayrapetyan Автор
Что вам конкретно не понравилось в разделе tcmalloc? Что не описан LD_PRELOAD? Я писал про линковку (ltcmalloc), а почему оно не работает — внимательно дочитайте этот раздел до конца. И поостынте, уже 10 комментов налепили в такой хреновый пост )
0xd34df00d
Описывать попытки использования инструментов, которые заведомо не будут работать на вашей системе, это тоже очень круто, я это даже комментировать не стал.
Пост-то как раз шикарный. А так-то просто плюсы — мой самый любимый императивный язык.
robert_ayrapetyan Автор
Откуда мне было знать, что оно заведомо не будет работать? Есть полноценный порт, а сноску про недопиленный heap-check в FreeBSD нужно очень постараться, чтоб найти. Цель статьи как раз уберечь других от попыток туда соваться.
По поводу HEAPPROFILE — понятно что не будет работать только с ним, «либо\либо» — это оговорка в статье.
0xd34df00d
А это, на самом деле, очень печально, потому что tcmalloc вместе с возможностью делать снепшоты хипа в разные моменты и сравнивать их не раз меня спасал. Причём, спасал не только в случаях вроде того, что у вас появился (забыли сделать delete), но и когда были, например, циклические зависимости у шаред_поинтеров, или когда была логическая утечка, и в какой-нибудь мапе данные оставались дольше, чем они там были нужны. Причём в последнем случае при завершении приложения мапа очищается, поэтому valgrind/asan/etc ничего не покажут.
robert_ayrapetyan Автор
А, ну и еще многих, наверно, зацепило про презрительное отношение к «рестартуем приложение каждые N минут» :)
prospero78su
Автору спасибо за познавательный обзор.
Отсутствие результата, боль, головняк и всё такое — это ценный опыт.
И косвенное подтверждение, что 15 минут славы С++ всё-таки прошли)
eao197
Вообще-то C++ — это язык, который очень больно бъет по рукам за любой просчет и невнимательность. Особенно когда люди сознательно нарушают давным-давно известные рекомендации. Вот, скажем, про то, что не следует работать с владеющими голыми указателями, говорят с 1990-х годов. Тем не менее, люди во времена C++11 хранят голые владеющие указатели в контейнере и закономерно отгребают проблем. Что здесь остается сказать? Разве что: поделом.
Опять же, вокруг C++ много мифов. Которые, зачастую, рождаются в результате вот таких вот случаев. Одни «профи» отказались от помощи со стороны языка (RAII, unique_ptr) и выбрали для своих задач откровенно неэффективные структуры данных (все-таки std::list для хранения всего лишь указателей — это жуткий перерасход памяти + добавление лишнего уровня косвенности при обращении к элементам, тут уж если нужны были именно свойства list-а, то следовало бы смотреть в сторону интрузивного двухсвязного списка). А потом, когда жопа таки случается, не знают за что хвататься. Другие «профи» прочитают такой отчет о закономерно полученных проблемах и делают для себя вывод о том, что C++ — это отстой
, что только Оберон спасет индустрию.olegator99
По существу, про C++ все так и есть. По форме — имхо стоит быть терпимее к просчетам других людей.
eao197
Когда, скажем, в авиации случается катастрофа, то ее результаты предают огласке и там, почему-то не считают зазорным скрывать факторы, приведшие к катастрофе. В том числе и человеческие. А затем, по результатам, вносят изменения в регламенты, инструкции и уставы для того, чтобы устранить или минимизировать влияние этих факторов.
В разработке ПО же когда случается какая-то беда, почему-то начинаются разговоры про «токсичность и высокомерие» или «стоит быть терпимее к просчетам других людей». Вся обсуждаемая здесь статья — это яркий пример того, как делать не нужно. О чем и следует говорить.
avandy
Доля истины в ваших словах есть. Но идеальных людей нет. Нет и идеальных специалистов. С++ — язык который я пронес через 20 лет, это мой первый серьёзный язык, который я учил. Поэтому я мыслил как С++ когда писал программы. Прошли годы и я изучил несколько других концепций в языках программирования. Сейчас, на сегодняшнем уровне своего развития я пришел к пониманию того, что для того чтобы писать код на с++, нужно хорошо выспаться, сделать зарядку, помедитировать, настроится и сконцентрироваться, потом в том состоянии познания дзен быстро кодить, пока вдохновение не ушло. Вовремя остановиться. Рано лечь спать. С++ очень крут, но требует предельной концентрации и всеобъемлющего понимания кода. Сегодня для своих нужд я пришел к языку Ada (не реклама). Я для себя понял, что я точно не робот кодить без ошибок. Компилятор должен облегчать жизнь программистам, ВЕЗДЕ где возможно. Везде идет процесс унификации. Супер спецов всегда будет не хватать, а потребность в софте будет расти. Поэтому инструменты разработки будут развиваться таким путем, чтобы даже средний по уровню специалист писал приемлемый код. Я врач, за последние 20 лет хирургия превратилась из искусства в ремесло (и это нормально). То что раньше мог делать отдельный одаренный Кулибин, сегодня при помощи нового инструмента делает почти любой (Да, Кулибиных в медицине тоже мало). У C++ концептуально с этим трудности. Но ему придется измениться! В первую очередь наверное отказаться от совместимости с С.
eao197
Извините, но то, что вы пишете — это оффтоп. Сейчас под любую задачу есть выбор из нескольких языков программирования и инструментов к ним. Никто не заставляет выбирать именно C++. Но если C++ выбран, то имеет смысл придерживаться «уставов, которые были написаны кровью», иначе отстрел конечностей — это лишь вопрос времени. Как у авторов статьи — 7 лет все было хорошо, но закономерный итог их все равно настиг.
avandy
Просматривается максимализм. В конкретной моменте с std::list и сырыми указателями, я с вами конечно согласен. Результат закономерен. Как выбирался инструмент программирования, мы не знаем. Может заставляли, может нет. Может автор на тот момент только С++ знал. Использовал то, что знал. Тех задание часто меняется по ходу дела, если оно вообще было. Автор поделился честным опытом, за что ему спасибо. А бывают ситуации, когда тебя ставят перед фактом для тебя мало изученной темы и требуют результат. А так, типа- "Эй… эй… Пацаны. Да вы здесь неочень...", выглядит не солидно. Вот вы тоже пишите статьи и многие благодарны вам за это, и я в их числе, хороший стиль, с удовольствием читаю.
eao197
Это обычный человек увидя последствия ДТП, когда пешеход в нарушение правил ППД выбежал на дорогу и попал под машину, может охать, ахать и причитать «да как же так, да кто же мог подумать». А немолодой сотрудник ГАИ или врач скорой с многолетним опытом отнесется к произошедшему, думаю, совсем иначе. Собственно, у меня такая же профдеформация.
Да, автор поделился. За это ему спасибо. Но написанное в итоге следует воспринимать как горький урок. И ценность статьи, как мне кажется, вовсе не в перечне инструментов, с которыми автору довелось познакомиться. А именно в том, что здесь идет наглядная демонстрация: нарушил правила — отгреб по полной программе.
Поэтому я не понимаю комментариев вот такого вида. Из-за чего эта подветка обсуждения и появилась.
avandy
Ладно. Мы поняли друг друга. Но тем не менее добрее надо быть. Все в одной лодке, а нам еще другие миры покорять))) Работы непочатый край)))
Antervis
Кто виноват в том, что абстрактная программа работает некорректно — её автор или ЯП, на котором она написана?
olegator99
Про tcmalloc:
В комплекте с pprof это очень мощный инструмент, который позволяет прямо в RUNTIME в любой момент следить за всей памятью выделенной приложением, даже tcmalloc на вашем хосте не умеет leak detection.
Выглядит как то так:
Что бы это работало, в свое приложение надо добавить весьма тривиальную обработку вызова нескольких http методов для pprof
robert_ayrapetyan Автор
Спасибо! Какой оверхед за использование всех этих доп. обвесов?
olegator99
По памяти — минимальный, практически не виден на приборах. По скорости работы зависит от хоста, примерно так:
На Linux включение профайлинга кучи в tcmalloc снижает скорость работы приложения в среднем раз в 5-10.
На OSX (и возможно на BSD) — снижение скорости в 1.5 — 2 раза.
olegator99
deleted