
Привет, Хабр. Мы недавно перевели на арабский язык 2ГИС Онлайн, и хотим поделиться своим опытом адаптации интерфейса под RTL (right-to-left). Это будет актуально и для иврита, и для персидского языка.
Я разделю этот опыт на две статьи — теоретическую и практическую. Сегодня — больше про теорию. Я расскажу, зачем нам понадобилось переворачивать весь интерфейс, что для разработчика интерфейсов значит фраза «сделать арабскую версию» и как справиться с арабским языком, смешанным с английским. Особое внимание уделю алгоритму, по которому строится отображение текста смешанной направленности — unicode bidirectional algorithm.
Зачем это всё?
Кажется, ценность в адаптации интерфейса под «справа налево» такая же, как у адаптации на любой другой популярный язык, но это не совсем так.
Различие между английской и русской версией небольшое — чаще всего, это просто переведёный текст. Пользовательский опыт, за исключением редких мелочей, в целом не отличается. Различие же между арабской и английской версией огромное.
Всего 0.6% интернет-ресурсов в мире содержат арабский контент. Однако, на арабском говорит больше 5% пользователей интернета, и эта доля стремительно растёт. Привычное направление чтения для них — справа налево. Какие ощущения у них от современного веба? Точно такие же, как у носителя русского языка при пользовании RTL–интерфейсом. Выбери себе метафору сам — может, это как садиться за руль праворульной машины, когда постоянно водишь леворульную. Или как зайти однажды в 2ГИС и увидеть, что карточки и поиск — справа:

Если мы хотим, чтобы наш сервис был максимально удобным для всех пользователей, адаптировать его под RTL нужно обязательно.
В чём состоит задача?
С первого взгляда она мне показалась необъятной — нужно переделать весь интерфейс под требования, которые никто не сможет нормально объяснить.
Посмотрев несколько примеров арабских сайтов, я понимаю, что сделать арабскую версию — это:
- Перевести данные на арабский язык. Эта часть понятнее всего, но легче не становится — это огромные объёмы данных;
- Перевести интерфейс на арабский язык. Для нас это не так просто, потому что до этого мы переводили только с русского, а переводчиков с русского на арабский у нас нет. Придётся сначала переводить строки и комментарии на английский, а потом — с английского на арабский;
- Адаптировать весь интерфейс под «справа налево». Это вроде просто «перевернуть всё в другую сторону». Надо разобраться, как это происходит. И для этого точно есть какие-то готовые решения.
С переводами вроде всё понятно. С переворачиванием интерфейса — ничего не понятно. Остановимся на этом подробнее.
Первым делом я добавил тегу html атрибут dir="rtl":
<html dir="rtl">Всё изменилось, но не совсем так, как я ожидал. Я осознал, что совсем не понимаю, что происходит. По какому принципу выстраиваются элементы друг за другом?
Базовое направление (base direction)
Рассмотрим один и тот же простой кусок вёрстки в LTR и RTL. Он не очень осмысленный, но наглядный:
<table>
<tr>
<td>
Hello world
</td>
<td>
<button>Hello</button> <button>world</button>
</td>
</tr>
</table>
Как видно на скриншоте, атрибут dir (как и css-свойство direction) задаёт:
- Выравнивание контента (
text-align); - Направление потока — в какую сторону друг за другом располагаются
inline-blockэлементы; - Порядок элементов в таблице, флексах, гридах.
Элементы поменяли порядок, но символы в словах всё равно расположены как обычно. Потому что порядок символов в строке определяется другим алгоритмом.
Последовательность символов внутри строки
Физически в строке символы расположены последовательно, но за итоговое отображение этой последовательности на экране отвечает unicode bidirectional algorithm.
Вкратце:
- Для каждого символа в строке вычисляется направленность;
- Строка бьётся на блоки одинаковой направленности;
- Блоки выстраиваются в порядке, заданном базовым направлением.
На направленность каждого символа влияет его тип и направленность соседних символов.
Три типа символов
1) Сильно направленные (или строго типизированные, strongly typed) — например, буквы. Их направленность заранее определена — для большинства символов это LTR, для арабских и иврита — RTL.
Слова на картинке целиком строго типизированы:

2) Нейтральные — например, знаки пунктуации или пробелы. Их направленность не задана явно, они направлены так же, как соседние сильно направленные символы.
Запятая между направленными слева направо «o» и «w» в строке «Hello, world» принимает их направленность и при базовом LTR, и при RTL:

Но что, если нейтрально направленный символ попадает между двумя сильно направленными символами разной направленности? Такой символ принимает базовую направленность.
Вот тут расположение «++» в одном случае между однонаправленными «C» и «a», а в другом — между разнонаправленными «C» и арабским «?», приводит к разному результату:

То же самое случается с нейтральными символами в конце строки:

3) Слабо направленные (или слабо типизированные, weakly typed) — например, числа. Они имеют свою направленность, но никак не влияют на окружающие символы.
Непрерывные слова из цифр выстраиваются слева направо, но два числа подряд, разделённые нейтральным символом, будут идти друг за другом справа налево, если задана базовая RTL–направленность:

Ещё более наглядный случай — число, в котором разряды разделены пробелом:
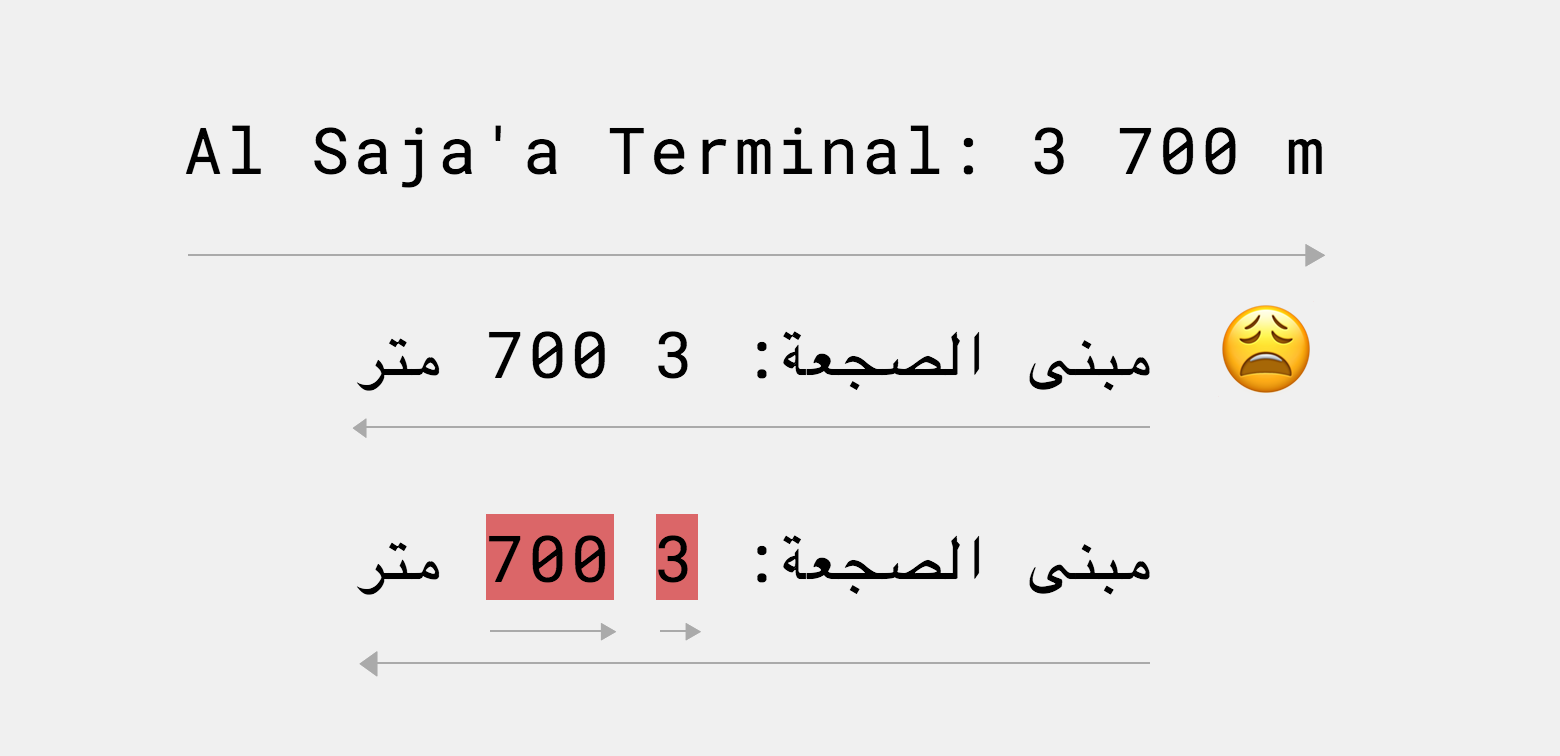
При этом допускается разделять числа точкой, запятой, двоеточием — эти разделители тоже слабо направлены (подробнее можно посмотреть в спецификации):

Направленные блоки (directional run)
Последовательные символы одинаковой направленности объединяются в блоки (directional run). Эти блоки выстраиваются друг за другом в порядке, определённым базовым направлением:

Слабо направленные числа, несмотря на то, что имеют свою направленность, не влияют на формирование блоков, что может приводить к такому результату — они продолжают предыдущий направленный блок:

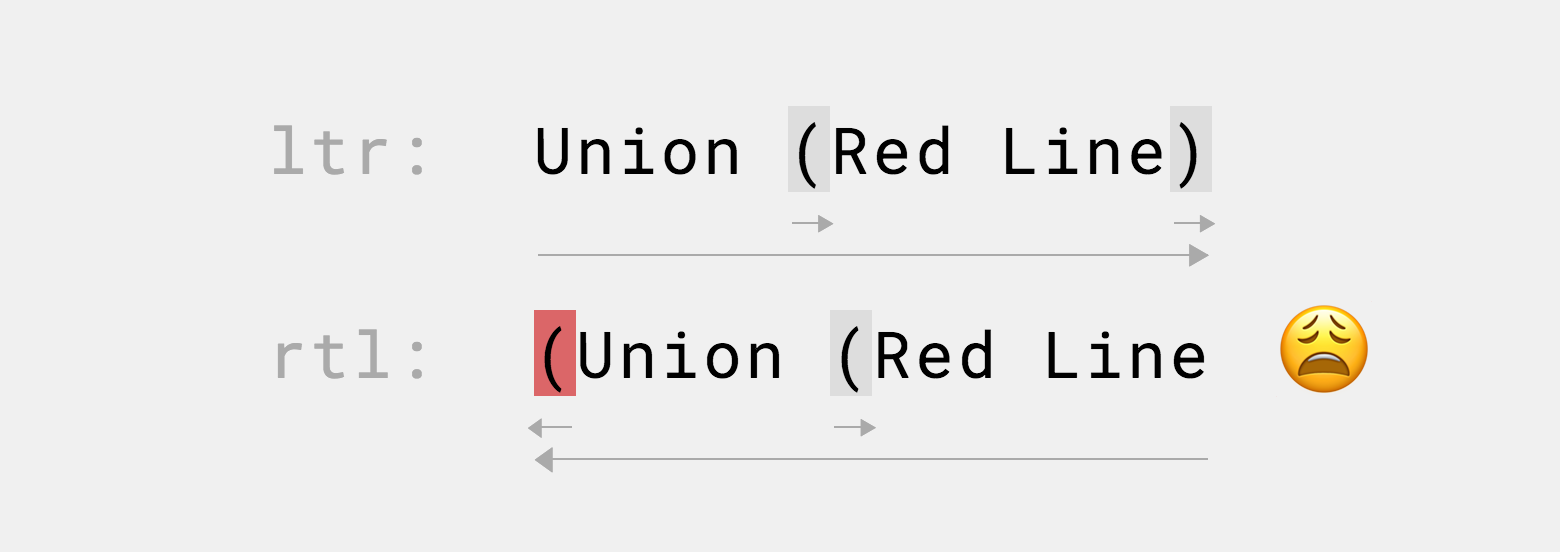
Зеркальные символы
Некоторые символы в разных контекстах имеют разную форму — например, открывающая скобка в RTL будет выглядеть как закрывающая в LTR (что логично, ведь контент в скобках будет идти после — то есть, слева от неё).
В большинстве случаев это не создаёт проблем, но если скобки случайно окажутся разной направленности, визуально они будут смотреть в одну сторону. Например, если скобка висит в конце строки:
Берём порядок под контроль
Как мы увидели выше, часто текст по этим правилам форматируется не так, как нам хотелось бы.
В этом случае нам пригодятся инструменты для встраивания желаемого направления в существующий контекст или переопределения направлений конкретных символов.
Изоляция (isolate)
С заданием базового направления мы уже познакомились выше: это делает атрибут dir. Это глобальный атрибут, он применим к любому элементу.
dir создаёт новый уровень встраивания (embedding level) и изолирует содержимое от внешнего контекста. Контент внутри направлен согласно значению атрибута, а внешняя направленность самого контейнера становится нейтральной.
Явная установка атрибута dir позволяет избежать почти всех проблем форматирования смешанного текста:
??? ??? <span dir="ltr">C++</span> ? Java
Если направленность контента неизвестна заранее, можно указать auto в качестве значения атрибута dir. Тогда направление содержимого определится с помощью «некоторой эвристики» — оно просто возьмётся у первого попавшегося строго типизированного символа.
<p dir="auto">{comment}</p>Аналогично работает тег <bdi> и css-правило unicode-bidi: isolate:
<span>Landmark: <bdi>{name}</bdi> — {distance}</span>
Встраивание (embed)
Можно открыть новый уровень встраивания без изоляции — правило unicode-bidi: embed в комбинации с нужным значением правила direction определяют и направление внутри элемента, и его направленность снаружи. Но это на практике не нужно почти никогда.
Переопределение (override)
<bdo dir="rtl"> или unicode-bidi: bidi-override; direction: rtl. Переопределяет направление каждого символа внутри элемента. Нужно использовать крайне редко (например, если нужно поменять местами два конкретных символа) и не забывать изолировать дочерние элементы.
<bdo dir="rtl">Hello, world!</bdo>
При этом снаружи элемент трактуется как сильно направленный. Чтобы он вёл себя как isolate снаружи, но как bidi-override внутри, нужно использовать unicode-bidi: isolate-override.
Управляющие символы (marks)
Вставка управляющих символов — неприятный способ, но он полезен, когда у нас нет доступа к разметке, но есть доступ к контенту. Например, это могут быть просто невидимые сильно направленные символы, ‎ и ‏ (‎/‏ или \u200e/\u200f). Они помогают задать нужное направление нейтральному символу.
Например, в этом случае, чтобы восклицательный знак в конце строки принял направление LTR, нужно, чтобы он находился между двумя LTR символами:
<span dir="rtl">Hello, world!‎</span>Также любая описанная выше логика реализуется через управляющие символы. Для изоляции — LRI/RLI, для переопределения — LRO/RLO, и т.д. — смотри подробное руководство по управляющим символам.
Поддержка браузерами
К сожалению, в IE тег <bdi>, dir="auto" и соответствующие им правила CSS не поддерживаются. Кроме того, спецификация этих правил всё ещё на стадии Editor's Draft.
Если нужен аналог dir="auto", работающий в любом браузере, можно парсить контент регуляркой и выставлять атрибут dir самостоятельно. Но лучше, конечно, так не делать.
HTML или CSS?
Однозначно, управлять направлением текста по возможности нужно через HTML–атрибут dir и тег <bdi>, а не через правила CSS. Направление текста — это не стилизация, это часть контента. Страница может быть вставлена через какой-нибудь instant view или быть прочитана через RSS–reader.
Перед заключением: немного боли
Мы познакомились с теорией. Но знание теории не освобождает от необходимости страдать.
Главная проблема, с которой я столкнулся на первых же минутах разработки под RTL–язык, это его чужеродность. Мы пишем код слева направо. Моя система, браузер и редактор работают слева направо, все наши внутренние продукты — слева направо. Поэтому, как только в это пространство попадает арабский язык, всё плохо и больно:
Манипуляции с текстом
Если символы на экране расположены не в том порядке, в каком они на самом деле располагаются в строке, что будет, если попытаться редактировать двунаправленный текст? Или хотя бы выделить и скопировать его часть?
Ничего хорошего. Попробуйте сами:
Landmarks: ??? ?????? ??? — 600 m, ????? ???????? — 1.2 km
a?z?b?y?c?x?d?w?e?v?f?u?g?t?h?s?i?r?j?q?k?p?l?o?m?n?

Манипуляции с кодом
И то же самое при правке кода в редакторе и код-ревью — боль.
Даже в порядке элементов в массиве нельзя быть уверенным:

Или того хуже, код вообще не выглядит валидным:

Можно довести до абсурда:

Снова берём всё под контроль
В любой ситуации есть только один источник правды — логическое расположение символов в строке. Символы могут быть расположены визуально правильно в редакторе или в почтовом клиенте, но на итоговой странице правильно их расположить не получится, потому что логический порядок нарушен.
Посмотреть, как изначально расположены символы в строке и почему они визуально расположились именно так, позволяет инструмент на сайте Юникода: http://unicode.org/cldr/utility/bidi.jsp

Итого
Мы познакомились с правилами, по которым определяется порядок элементов и порядок символов в строке, и узнали, как можно на него влиять.
Что нужно обязательно помнить:
dir="rtl"задаёт направление потока, выравнивает текст какtext-align: right, меняет порядок ячеек таблицы, флексов и гридов. За последовательность символов в строке отвечает unicode bidirectional algorithm;- Каждый символ имеет тип направленности — строго типизированные (буквы), слабо типизированные (цифры) и нейтральные (знаки пунктуации и пробелы);
- Проблемы возникают чаще всего на границе между разными типами символов.
На практике вся эта теория выливается в одно простое правило:
При смешанной направленности нужно явно изолировать уровни встраивания с помощью атрибутаdir, а если контент неопределённой направленности — использовать<bdi>иdir="auto".
Также нужно готовиться к тому, что в редакторе текст может выглядеть не совсем так, как будет выглядеть в браузере. И это обязательно причинит тебе боль.
Что дальше?
В следующей статье я расскажу о нашем практическом опыте. Как быстро сделать прототип RTL-версии и какие выбрать решения для продакшна. Как быть заранее готовым, но какие моменты невозможно предусмотреть.
Комментарии (44)

TheShock
10.05.2018 08:15+5Ваша статья в очередной раз доказала, насколько повезло большинству разработчиков, которые никогда не работают с rtl
Leopotam
10.05.2018 10:08Особенно если не было необходимости реализовывать это в приложениях, не поддерживающих это никаким образом, например, в игровом движке Unity. :) Там вообще нет даже базовой поддержки rtl и основная боль была как раз на смешанных данных + их стилизации через теги (цвет, жирность и т.п).
forcam
10.05.2018 09:23Жаль что Gis не сделал хотя бы для столиц стран СНГ карты, отличная система, но так мало городов вне России, для стран СНГ :(
AllexIn
10.05.2018 12:32Вроде бы не сами Гисовцы делают отдельные города, а «желающие» на местах.
forcam
10.05.2018 15:36-1Ну Беларусь отсутствует вообще в любом формате(
А что в Яндекс картах, что в Гугл картах, если не работает GPS на телефоне, все, никуда не попасть (я про браузерные версии), раньше можно было написать откуда и куда хочешь попасть, теперь нужно тыкать на карте, что как по мне полнейший бред, ну по крайней мере для меня. Если я не знаю где находится улица на карте большого города, то как мне в нее «тыкнуть»?) Ну как по мне маразм. Надеюсь 2Гис хотя бы такой же ерундой страдать не будет. И да, почему Минска нет хотя бы? Неужели вы его так не любите в 2Гисе? :)
«желающие» на местах
на сколько я знаю, желающие на местах только добавляют штрихи, т.е. инфу корректируют, хотя может я и ошибаюсь, нигде не встречал информации по этому поводу. Думаю, если бы простые люди на местах делали эти карты, каким-то образом, то городов было бы на несколько порядков больше) 2Gis крайне удобен, я бы сказал, безальтернативно удобен в использовании. Но то что городов крайне мало в других странах, а теперь еще и на арабский рынок полезли, это конечно печалит, очень.AllexIn
10.05.2018 15:43«Простые» люди и не могут.
Нужно обладать ресурсами, чтобы на месте сформировать начальную базу 2гис. А это дохрена работы.
Подробности тут:
info.2gis.ru/company/franchiseforcam
10.05.2018 19:52Теперь все становится понятнее, мде. Неужели просто нельзя собрать данные по городу? Ну не знаю, из открытых источников, привязать их к адресам установить данный режим как Бета, на подтвержденных сделать пометку что подтверждены все организации в здании, т.е. их отдельно обзвонили, ну и по телефону перепроверить корректность, во всех организациях есть телефоны. И не придется искать Франчайзов.
AllexIn
10.05.2018 20:10+1Я не имею никакого отношения к 2ГИС, но уверен что «просто» — нельзя.
2ГИС это брэнд, который ассоциируется с очень качественным картографическим сервисом.
Именно поэтому он умудряется существовать в мире, где есть OpenStreetMap.
Вы предлагаете сделать клон OSM — не понятно зачем, OSM и так уже есть. А для 2ГИС это означает создать негативное впечатление о брэнде.forcam
10.05.2018 22:07Ну значит сделать отдельный лоукост-брэнд, дочернюю компанию, где не будет 99,9% точности, многим достаточно по инфе того, что им выдал бы гугл или яндекс и поднимать качество более автоматизированными средствами. OSM если я правильно понимаю это просто карта, без наполнения, кроме того, что бы добраться из пункта А в пункт Б она, видимо ничего не может. Если просто адрес найти, то да, а если найти и посмотреть, что там?)
AllexIn
11.05.2018 00:14Всё там есть. И поиск пути, и информация о компаниях, и достопримечательности.
Как раз примерно на том уровне, который вы хотите увидеть в лоукост 2ГИС.
Телефонов нет. Но нагуглить телефон по адресу, я полагаю не такая уж проблема.shoorick
11.05.2018 14:18Телефонов есть. OSM в теории позволяет хранить что угодно, да и на практике, судя по пресетам JOSM, можно и телефон указать, и сайт, и мыло, и часы работы, и принимают ли карточки, и какие конкретно, и октановое число бензина (если это заправка), и ширину дверного проёма на входе, и доступность для инвалидов, и цвет крыши здания, и материал его стен и т. д., и т. п. Другой вопрос, как это показать.
AllexIn
11.05.2018 14:20Верно. И тот же maps.me вполне себе показывает телефоны.
Я ошибся в изначальном сообщении.
shoorick
11.05.2018 14:13OSM — это набор геоданных. А уж что с этим набором делать — другой вопрос. Можно отображать как карту, можно строить маршруты, можно устраивать адресный поиск в обе стороны — куча всяких разных способов есть.
lastwish Автор
11.05.2018 06:18Да, 2ГИС — это про точность данных, многое заботливо собирается и выверяется руками. Если это убрать, у такого сервиса с 2ГИС общей будет только графическая оболочка — никаких конкурентных преимуществ в плане точности, никакой любви пользователей, рекламодателей и т.д. Это сильно заметно, когда у нас в каком-нибудь регионе появляются проблемы с актуальностью информации — сервис остаётся приятным и привычным, но без 100% доверия к данным это ну совсем не то.
newartix
10.05.2018 09:49Интересно было бы почитать про экономическую целесообразность такого перевода. Насчёт 5% пользователей интернета написали, но конкретно для 2Гис это настолько приоритетный рынок?
Мы переводили простейшее ПО на арабский язык, это просто ад. В принципе, вполне очевидный. Стоит ли овчинка выделки?
Насколько я понимаю, даже Гугл интерфейс своих карт толком не адаптировал, отделались только переводом.
Проще всего кажется создать цельный отдел разработки, для которого арабский (другой RTL язык) является родным, и пусть они «переводят», а по сути адаптируют все нюансы. Тексты, дизайн, картинки, устойчивые культурные шаблоны (символы алкогольных напитков, например в большинстве случаев будут неуместны). Почему в вашей компании не пошли по этому пути?lastwish Автор
10.05.2018 10:11Экономическая целесообразность тут у каждого своя. В случае 2ГИС это вклад даже не столько в увеличение активной аудитории, сколько в узнаваемость бренда среди пользователей и потенциальных партнёров, т.к. качественных арабских сервисов почти нет. Можно назвать это персональным подходом. И на данный момент о затраченных усилиях ничуть не жалеем.
Вот специальный отдел разработки арабской версии создавать для нас было бы точно слишком сложно и дорого. Это же я тут только проблемы с фронтендом описываю, а за ним стоят ещё десятки команд. Плюс к этому, огромную работу провёл именно наш дубайский офис, все вместе переводили и помогали адаптировать. Без них бы вряд ли что-то хорошее смогло выйти.
Зато после единовременной адаптации все новые фичи достаются всем локальным версиям условно бесплатно — перевёл, вёрстку проверил, зарелизил.newartix
10.05.2018 10:26Понятно, то есть поддержка носителей языка внутри компании всё-таки есть. Под отделом разработки я и имел ввиду именно людей занимающихся интерфейсом/фронтендом. В бэке тоже столкнулись с какими-то проблемами?
Просто у нас проблемы возникли как раз в плане организации работы. Так как в команде никто не знает даже близко арабского, мы даже не представляем как ПО в итоге выглядит, то ли верно, то ли бред, где какие контексты могут иметь значение. Это постоянная переписка с переводчиком, постоянные тестовые билды и ожидание обратной связи. Благо, как я уже сказал, ПО относительно простое.lastwish Автор
10.05.2018 11:01+1Да, почти всех зацепило — до этого у нас не было проектов с мультиязычностью данных. Внутренние продукты, хранилища данных, почти все API, поиск проезда, рендеринг тайлов карты, и т.д. Получился такой крутой повод сделать наконец большой шаг к настоящей мультиязычности.
В плане организации работы — как обычная, просто очень большая, задача с нечёткими требованиями. Что-то улучшили, слили (так чтобы эти изменения не ломали английскую версию), отдали арабским коллегам на ревью, получили фидбек. И так несколько месяцев. Проблема «то ли верно, то ли бред» — да, от этого больнее всего было. Особенно искать, на чьей стороне проблема, когда например в почтовом клиенте (LTR) текст выглядит не так, как в итоге на сайте (RTL), но оба варианта на первый взгляд — почти одинаковые закорючки.
RomeroMsk
10.05.2018 10:24Еще очень «весело» разрабатывать всевозможные компоненты с учетом RTL. Например, datepicker, где направление дней недели, дат, месяцев, годов — тоже «обратное». Нажимаешь на кнопку пролистывания месяца вправо, а отображается предыдущий месяц:

paperfrog
10.05.2018 19:27+1Это тут еще календарь григорианский. Особая магия начинается, когда нужно Hijri.
forcam
10.05.2018 17:58-1Ребят, объясните, почему так мало городов? Ну если проблема с масштабируемостью, сделайте вы платную версию, ну хоть по подписке, хоть как, что бы только больше городов было, у вас какой-то точечный выбор городов и это очень странно. Качество 100 из 100, распространненность 10 из 100, я не знаю, но как по мне не правильно это. Ну хотя бы всё СНГ бы запилили, хотя бы города численностью 100 тыс+. Жаль, такое качество, а пользоваться нельзя, Беларуси нет вообще в любом виде :( Жил в России горя с вами не знал, а переехал на родину, заезжаешь в Минск, так хоть волком вой)
AllexIn
10.05.2018 20:11так хоть волком вой
OSM отменили чтоли?forcam
11.05.2018 00:37OsmAnd? Или о каком речь?
AllexIn
11.05.2018 00:41Тысячи их.
Я лично, если еду в город где нету 2GIS — использую maps.me
Вот я сейчас сделал запрос на тему «кафе» в Минске:
ru.maps.me/catalog/food/amenity-cafe/country-belarus/city-minsk-26162465
Не 2ГИС, но близко
agmt
10.05.2018 18:57+1Интересно, что будет раньше: верстальщики и стандарты дойдут до уровня хорошей поддержки или перейдут на латиницу?
vindy123
10.05.2018 19:27+1Привет из Саудовской Аравии) С интересом прочитал, как оно должно быть на самом деле. По собственному опыту — большинство местных понятия не имеет о таких тонкостях. Смешанные тексты и числа пишутся как Аллах на душу положит (или как логика конкретного текстового редактора дает писать). Особая боль — ходьба курсором по смешанному тексту и его выделение, когда внезапно нажатие стрелки вправо начинает работать как стрелка влево на отдельном куске. Идея перехода всем миром на эсперанто мне уже не кажется такой нелепой в последние три года)
AIxray
10.05.2018 20:01-3Компания 2Gis, а скажите пожалуйста: вы таким образом обучили алгоритм корректно переводить на арабский? К сути вопроса, имеется у вас быстрый способ обучения арабскому?
Считается что, русский+арабский это словно развитие левого и правого полушария чел. мозга.
Bhudh
11.05.2018 05:38Также нужно готовиться к тому, что в редакторе текст может выглядеть не совсем так, как будет выглядеть в браузере. И это обязательно причинит тебе боль.
Для таких вещей и существуют экранирующие последовательности. Чистый LTR, ну а что текста в 6 раз больше визуально и ни черта не понятно — так Вы ведь и арабский не понимаете.lastwish Автор
11.05.2018 06:33Да, это решит проблему с выделением текста и навигацией по коду. Но кажется будет ещё сложнее сопоставить код и его реальное отображение в браузере.
И это не избавит от писем вроде «ребята, в этом адресе [арабский_текст_с_цифрой_слева] номер дома должен идти в конце строки». А он вроде и так в конце, строка же читается справа налево. А оказывается, что в LTR почтовом клиенте цифра в начале (слева) потому что она реально в начале строки, и в RTL контексте она окажется тоже в начале (справа). Брр!
rednaxi
Не вполне понятно по поводу чисел. Если арабы читают справа налево то и число 600 для них должно выглядеть как 006 разве нет?
tyomitch
Нет. Они их читают от единиц к сотням. Это европейцы, позаимствовав арабские числа, стали их читать «задом наперёд».
paluke
Little-endian процессоры придумали арабы?
Goodkat
Надеюсь, они их хотя бы последовательно читают.
Европейцы в числах всё перемешали: числа до 20 мы тоже читаем справа налево: 17 — «семь-на-дцать», а после 20 слева направо: 57 — «пятьдесят семь», достигнув сотни читаем сперва сотню, потом единицы: 112 — «сто две-на-дцать», но после 120 всё число читается слева направо. Какое-нибудь 12717 начинаем читать от середины налево до начала, потом прыгаем в середину, читаем одну цифру и её разряд, потом прыгаем в самый конец и дочитываем налево к середине. Немцы чуть более последовательны, все двузначные числа читают справа налево, но от сотен та же чехарда, что и у нас. Про французов лучше промолчу.
MishaRash
Арабского я не знаю, но, скорее всего, в этом он похож на иврит, так как языки близки.
В иврите в целом система чтения чисел похожа на русский (в основном порядок от старших разрядов к младшим с исключением для 11-17) с добавлением специальных парных слов.
tyomitch
Это в современном иврите так, под влиянием европейских языков; а на библейском иврите писали «девять и шестьдесят лет и девять сот лет».
MishaRash
Вы уверены? Для меня это кажется сомнительным, потому что в традиционных еврейских числах старшие разряды справа. Скорее уж это связано с тем, что цифры на самом деле придумали индийцы, а арабы были лишь посредниками.
tyomitch
Основное преимущество позиционных систем счисления (вроде арабских цифр) перед непозиционными (вроде традиционных еврейских) — возможность выполнения поразрядных операций («столбиком»). Все эти операции выполняются от младших разрядов к старшим. Вам никогда не казалось странным, что столбиком считают «задом наперёд»?
Индийцы тоже считали от младших разрядов к старшим:
При этом индийцы писали слева направо, т.е. древнеиндийский порядок цифр был обратный современному.