
Все же знают, что такое Рамблер/топ-100? На всякий случай — это сервис веб-аналитики. Наши пользователи ставят себе на сайты счетчик, ну а мы в свою очередь готовим всю необходимую статистику посещений в виде набора стандартных отчетов. Под катом рассказ Виталия Самигуллина, руководителя группы разработки технологий Рамблер/топ-100, о том, как мы разрабатывали API ClickHouse на Python и зачем вообще всё это затевали.
Переход с batch на stream processing потребовал нового хранилища и нового API
Собственно, с чего бы вдруг нам понадобилось разрабатывать API Clickhouse? Во-первых, у нас произошли определенные изменения в процессе обработки данных. Общая схема сервиса в настоящее время выглядит следующим образом.
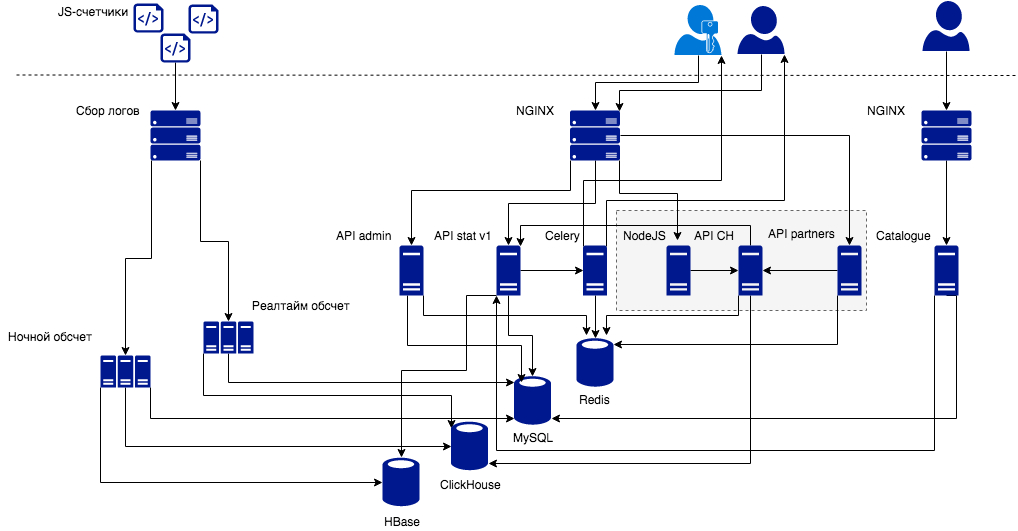
В левом верхнем углу вы видите счетчики, которые шлют нам события. Логи этих событий мы парсим и обрабатываем определенным образом. Как это происходит сейчас: у нас есть кластер ночного батч-обсчета, который обсчитывает логи за вчерашний день. Для пользователя Топ-100 это не очень удобно, потому что свежая статистика появляется в личном кабинете спустя сутки.
Всем очень хотелось, чтобы сервис работал «как в лучших домах ЛондОна», а статистика по текущему дню прилетала пользователю как можно скорее. Поэтому мы решили перейти на так называемую стримовую обработку данных (near real-time data processing или микро-батчи). Задержка в отображении данных в 5-10 минут — сущий пустяк в сравнении со схемой, когда данные приходят на следующие сутки.
Если раньше результаты ночного обсчета заливались в open-source аналог BigTable от Google, то для real-time нам потребовалась новая база данных. Мы выбрали ClickHouse (подробнее об этом в нашей статье на Хабре). Далее начали разработку API ClickHouse для работы с этой базой данных. Надо заметить, что API достаточно низкоуровневая. Пользователи взаимодействуют с ней через различные прослойки: партнерские API, API пользовательского приложения.
Что такое Clickhouse?
Clickhouse – это система управления базами данных. ClickHouse является столбцовой базой данных. Это значит, что данные хранятся, организованные в столбцы, а не в строчки. Это предусматривает возможность работать с десятками и даже сотнями столбцов. Второе важное свойство этой БД — она очень быстрая как раз таки потому, что она организована в столбцы (при запросе мы вычитываем только необходимые столбцы), использует сжатие данных, умеет распараллеливать обработку запросов на несколько процессорных ядер, а также поддерживает распределенную обработку запроса на кластере из многих серверов.
Еще один важный аспект — SQL-like синтаксис языка запросов, расширенный большим количеством полезных функций агрегации и трансформации. Это позволяет вынести часть логики из приложения в запрос. То есть, если у вас приложение на Python, вынос логики в Clickhouse, написанный на С++, не только будет удобным, но и обеспечит прирост скорости.
Аналитические запросы
Аналитические запросы — это паттерн, обладающий набором характеристик. Например, аналитические запросы предусматривают преимущественно чтение. В аналитических запросах нам не нужны транзакции — данные читаются и почти никогда не изменяются. А если изменения требуются, это делается через удаление партиций и запись новой партиции. Кроме того, запись происходит большими пачками с real-time кластера. В аналитических запросах часто предусматривается вычитывание данных отдельных столбцов из широкой многостолбцовой таблицы.
В отличие от ночного обсчета, результаты микробатчей записываются в ClickHouse в неагрегированном виде. И когда данных очень-очень много, запросы могут быть медленными. Для аналитики допустимы запросы на основе части данных с некоторым приближенным результатом. ClickHouse позволяет это делать с помощью механизма сэмплирования.
Продуктовый challenge
Раньше с данными ночного обсчета мы делали стандартные отчеты для пользователей — это примерно 30 стандартных отчетов, например, отчеты по аудиторным или поведенческим показателям, технологиям, источникам трафика, содержанию страниц. Со стороны API требовалось по две ручки на каждый отчет: одна для табличных данных, вторая для графика.
Теперь перед нами стоял продуктовый вызов — помимо ускорения обсчета до почти реального времени и сохранения уже существующих отчетов со статистикой, нам предстояло реализовать конструктор отчетов. Конструктор отчетов должен позволить пользователю создавать полностью кастомные отчеты под свои нужды. Что это означает для API?
Это означает, что мы уже не можем сделать по стандартному шаблону с SQL-запросом на каждый стандартный отчет из нашей статистики. Нужно уметь генерировать запросы для кастомных отчетов. То есть API берет на себя функции почти-ORM. Почему почти, потому что мы не решали какую-то универсальную задачку генерации SQL запросов для ClickHouse. Мы решали задачу для нашей схемы данных, для наших таблиц.
Понятно, что в случае API, который будет использоваться для конструктора отчетов, нам достаточно некой единой точки входа, одной ручки: ручка получает на вход набор параметров для запроса в БД, генерирует запрос, отправляет его в ClickHouse, неким образом форматирует и возвращает ответ. Для того, чтобы генерировать этот запрос, мы ввели такое понятие, как кубики.
Кубики — это сущности для генерации SQL-запросов. По своему типу кубики делятся на две категории:
Размерности — отвечают на вопрос ЧТО?
Метрики – отвечают на вопрос СКОЛЬКО?
Лучше всего структуру кубика можно увидеть на примере нашего стандартного отчета «География». В таблице мы видим разбивку по странам. Очевидно, что страна отвечает на вопрос «ЧТО?» и относится к размерности. У каждой страны есть какие-то количественные представления: посетители, отказы, глубина просмотра и так далее. Это метрики.

Теперь давайте представим, что пользователь вдохновился отчетом с разбивкой по странам и в качестве размерностей решил добавить регионы и города, чтобы провести более сложную аналитику и узнать, на каких страницах заканчивают просмотр его сайта жители Москвы, Киева и Минска. А потом пользователь захочет посмотреть, как эти показатели изменяются с течением времени и добавит в конструкторе отчетов кубик «День».
От запроса к API к SQL-запросу
Как мог бы выглядеть запрос к API? Какой запрос к БД он будет генерировать? Как генерируется SQL-запрос? И как реализованы кубики в Python-коде.
В качестве примера возьмем самый простой отчет «Технологии/Операционные системы».
JSON-запрос в API
{"dimensions": [
{"name": "counter",
"filters": [{"op": "eq", "val": 123}]},
{"name": "os",
"filters": [{"op": "nlike", "val": "Windows%"}]},
{"name": "day",
"filters": [{"op": "eq", "val": "2017-03-22"}]}
],
"metrics": [
{"name": "visitors",
"filters": [{"op": "gt", "val": 100}]}
],
"sort": [
{"name": "visitors", "order": "desc"},
{"name": "os", "order": "asc"}
],
"offset": 0,
"limit": 20,
"sample": 1.0}
Очевидно, что в API мы будем слать какой-то JSON, который состоит из списка метрик, размерностей, сортировок, лимитов, офсетов и сэмпла (если мы хотим строить запрос только по части дата-сета).
Каждый кубик — и метрики, и размерности — описывается каким-то ключевым словом и включает в себя фильтры. В приведенном выше случае видно, что у нас есть размерность «Счетчик», «Номер проекта» и он равен некоему ID. У нас есть кубик «Операционные системы», и мы в этом запросе хотим сделать разбивку по всем ОС, кроме Windows. У нас есть кубик «День», и мы хотим посмотреть данные только за сегодня.
То же самое с метриками. У нас есть «Посетители», мы хотим посмотреть все ОС, где посетителей было больше ста. Ну и отсортировать это все в убывающем порядке по посетителям и возрастающем порядке по названиям ОС.
От SQL-запроса к кубикам
SELECT
os_name AS os,
uniqCombined(user_id) AS visitors
FROM hits
SAMPLE 1
WHERE
(counter_id = 123) AND
(dt = toDate('2018-03-22')) AND
(os NOT LIKE 'Windows%')
GROUP BY
os
HAVING
visitors > 100
ORDER BY
visitors DESC,
os ASC
LIMIT 0, 20
Мы хотим, чтобы API на основе входящего JSON сгенерировал SQL-запрос для ClickHouse. В приведенном выше запросе мы видим все описанные в JSON размерности и метрики. У нас есть секция SELECT, в ней мы выбираем названия операционных систем. Есть и агрегация по посетителям. Все фильтры отправляются в секции WHERE и HAVING. После группировки мы хотим отсеять все ОС, где у нас 100 пользователей и меньше, и так далее.
Свойства кубиков
У каждого кубика есть определённые свойства, которые его определяют:
- Колонка в БД
- Alias
- Признак видимости
- Фильтры
- Сортировка
- Выражения для всех необходимых секций SQL-запроса (SELECT, WHERE, ...)
Например, для кубика «Операционные системы» колонка в БД, как мы видим из запроса — это os_name. Alias позволяет удобно работать с фильтрами, группировками и сортировками. Признак видимости заключается вот в чем: в приведенном выше примере ясно, что размерность, «Счетчик» и «День» невидимые. Мы их используем только для сортировки, но в секции SELECT они не участвуют. В то же время кубики «Операционные системы» и «Посетители» явно видимы. То же самое и с сортировкой — какие-то кубики у нас участвуют в сортировке, какие-то нет. Есть определенные порядки для сортировки. И естественно, что в финальном запросе мы хотим получить кусочки для каждой секции запроса, для каждого ключевого слова: SELECT, WHERE, и прочих. Каждый кубик будет предоставлять нам эти кусочки через соответствующие выражения.
Реализация кубиков в Python
API написана на Python. Рассмотрим реализацию кубиков на этом языке программирования.
class Selectable(object):
column = not_implemented
alias = not_implemented
def __init__(self, visible: bool=True, sortable: bool=False) -> None:
self.visible = visible
self.sortable = sortable
self.filters = []
...
def filter(self, operator: str, value: Any) -> None:
...
def sort(self, ascending: bool=False, ?priority: int=0) -> None:
...
@property
def select(self) -> Optional[str]:
...
Очевидно, что метрики и размерности имеют много общего. Поэтому общие для этих сущностей свойства мы опишем в базовом, родительском классе. Он имеет переменные класса: колонку, alias. При инициализации мы задаем свойства видимости и сортируемости. У нас есть метод для добавления фильтров, который будет добавлять оператор и значение. И очевидно, что фильтров может быть много, поэтому все эти фильтры будут добавляться в список. Например, у нас может быть диапазон дат в запросе «от и до». Соответственно, добавляются два фильтра.
То же самое с сортировкой: мы можем указать порядок сортировки по убыванию или возрастанию. Дальше мы хотим иметь атрибуты по каждой секции запроса, которые будут возвращать строчки. Из этих строчек и будет склеиваться большой финальный запрос.
Ниже упрощенный пример реализации кубиков «Операционные системы» и «Посетители» на Python.
class OSName(StringDimension):
column = 'os_name'
alias = 'os'
functions = []
...
class Visitors(IntegerMetric):
column = 'user_id'
alias = 'visitors'
functions = [uniqCombined]
...Мы просто наследуемся от родительского класса, задаем названия колонки в БД, alias, список функций трансформации или агрегации. Например, как мы видели в запросе, для подсчета примерного количества посетителей нам нужна агрегирующая функция uniqCombined.
Все наши кубики можно упорядочить в некую иерархию классов.
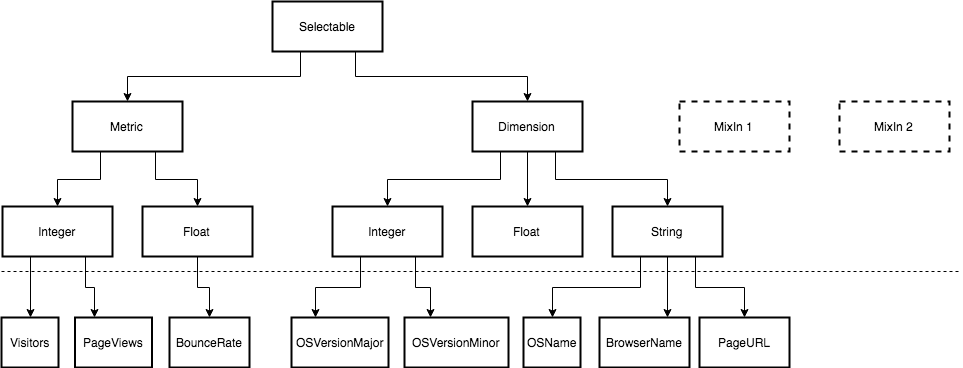
Как уже говорилось ранее, и у метрик, и у размерностей очень много общего. Поэтому основная логика вынесена в основной родительский класс Selectable.
Тем не менее, между ними есть и различия. Например, мы всегда группируем по размерностям, а секция HAVING у нас бывает только для метрик. Соответственно, они будут в этом различаться. Аналогично с сэмплированием. Когда мы указываем, например, сэмпл 1/10, нам нужно умножить метрики на обратное число (на 10), чтобы получить примерное значение для этих метрик. Поэтому мы выделяем два класса Metric и Dimension.
На следующем уровне иерархии логично создать классы, которые как-то завязаны на тип хранимых и выдаваемых данных. Метрики могут быть целочисленные, такие как «Посетители» или «Просмотры страниц». Это могут быть метрики с плавающей запятой, как например «Показатель отказов».
Аналогично с размерностями, но там в основном строчки: «Название браузера», «Операционные системы», URL и прочее. На схеме вы также видите Mixin-классы. Это такие вспомогательные классы, которые мы можем подмешивать при определении конкретных кубиков, например, чтобы реализовать более сложную логику, скажем, в работе с функциями трансформации или агрегации. В самом простейшем случае, который нам в большинстве случаев подходит, это некая цепочка функций, применяемая к колонке. Иногда бывают сложные функции, для которых требуются аргументы, зависимости с другими кубиками и другое. Mixin в этом случае хорошо подходят.
Генератор SQL-запросов
Итак, у нас есть кубики. Из набора кубиков нужно собрать строчку запроса. Это делает класс SQLGenerator — генератор инициализируется некими свойствами запроса в целом, которые применимы для всех-всех кубиков, которые участвуют в генерации финального SQL-запроса. Очевидно, что таким общим свойством может быть название таблицы, например, «hits». Это сэмпл — понятно, что не может быть разный сэмпл для разных кубиков. Ну и лимиты, офсеты.
Дальше в этот генератор мы должны передать список объектов, которые уже инициализированы, у которых задана видимость, заданы фильтры, сортировка. В результате класс генератора должен сохранить в некотором словаре списки строчек. Ключами словаря будут названия секций запроса (SELECT, WHERE, …), а значениями будут эти самые списки кубиков, у которых мы обращаемся к атрибутам, соответствующим секции запроса. Атрибуты — это просто строки, кусочки соответствующей секции.
generator = SQLGenerator(table="hits", sample=0.01, limit=[offset, limit])
generator.add([sel1, sel2, ...])
...
{
'SELECT': [sel1.select, sel2.select],
'FROM': 'hits',
'SAMPLE': 1,
'WHERE': [sel1.where, sel2.where],
'GROUP BY': [sel1.groupby, sel2.groupby],
'HAVING': [sel1.having, sel2.having],
'ORDER BY': [sel1.orderby, sel2.orderby],
'LIMIT': [0, 20],
}Наконец, чтобы получить полностью сформированную строку для каждой секции, мы должны эти кусочки склеить по какому-то правилу. Очевидно, что у нас будет словарь соответствий секции и правила склейки, сепаратора. Например, в SELECT мы все кусочки соединим через запятую. А в WHERE или HAVING кусочки будут склеиваться через AND.
Внутреннее устройство API
Как это выглядит всё вместе? Рассмотрим схему ниже.
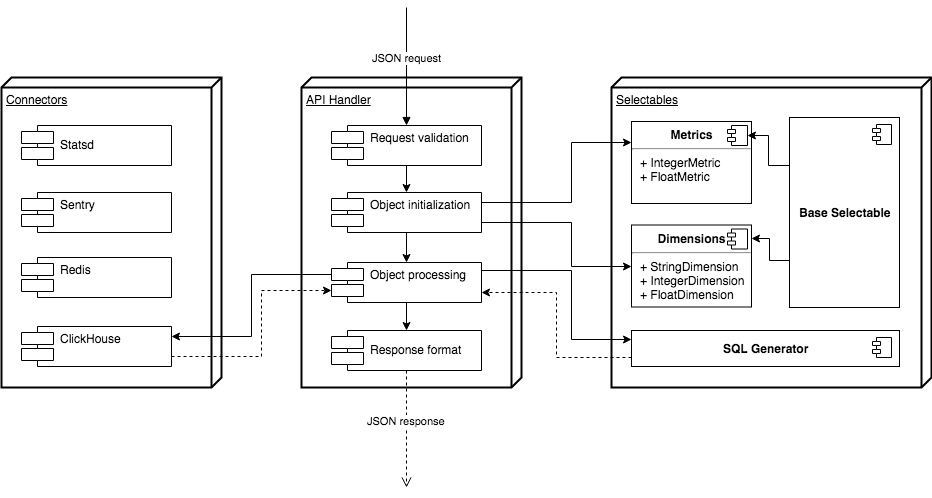
Как и в любом API, нам нужна валидация входящих запросов, в нашем случае POST-запроса с JSON-нагрузкой. Дальше мы должны посмотреть соответствие названий кубиков названиям классов на Python, инициализировать соответствующие классы, задать фильтры, сортировку. Далее нам нужно подсунуть объекты классов в генератор для того, чтобы он склеил нам строчку SQL-запроса. Затем через специальный коннектор, в который вынесена вся логика работы с ClickHouse, запрос отправится исполняться в ClickHouse. Мы должны получить ответ от БД, отформатировать его и отдать пользователю.
Выводы
Проект разрабатывается на CPython 3.6.4. Нам очень нравятся f-string. Если вы их не используете, считайте, что жизнь проходит мимо вас. Не менее важны упорядоченные словари, где пока де-факто гарантируется порядок вставки ключей, а начиная с Python 3.7 такая гарантия будет официальной — тоже очень удобно, с учетом использования словарей, где ключами являются названия секций запроса SQL, которые должны следовать в определенном порядке. Это существенно повысило скорость разработки. Ну и поскольку в эту API входят разные клиенты, и на API планируется относительно высокая нагрузка, мы решили попробовать asyncio и фреймворк aiohttp. В итоге мы получили довольно быструю API.
Нам также понравилась штука под названием mypy. Отличный инструмент, способный повысить качество кода, заставляющий программиста в каких-то случаях лучше декомпозировать функции и, конечно, отлавливать часть ошибок до запуска программы. Если у вас раньше был опыт работы с mypy и он был негативным, определенно стоит попробовать еще раз — за последнее время mypy стабилизировалась, были поправлены некоторые неприятные баги.
Поскольку в нашей архитектуре компонент API ClickHouse является критически важным, для нас важно поддерживать качество кода. Мы пишем много юнит-тестов с большим процентом покрытия кода, и в этом нам очень помогает pytest. Особенно удобна возможность писать параметризованные тесты. Мы используем это, чтобы сравнивать SQL-запросы, которые создает генератор, по различным входным JSON-запросам с соответствующими эталонными SQL-запросами.
P.S. Вы также можете посмотреть видео с презентации Виталия Самигуллина (aka pilosus).
Комментарии (7)

SyCraft
18.05.2018 15:43Админил я когда то, старую Топ-100 :) те еще были времена.
pilosus
18.05.2018 19:16+1Мы вспоминаем те славные времена, поглядывая в git blame! А если серьёзно, то от старого топ-100 осталось чуть более чем ничего — все легаси спилено, новый стек и инфраструктура не имеют ничего общего со старой версией проекта.
Для админов у нас сейчас тоже есть разные интересные задачки. Если кому-то интересно, можем попробовать рассказать про CI/CD, заезд в Kubernetes, вот это все.
igor_suhorukov
Вы сравнивали Clickhouse и Apache kylin ,pinot, druid с вашими паттернами доступа?
pilosus
Из перечисленного сравнивали с Druid. Еще в сравнении были Vertica и Kudu + Impala.
Вот тут подробнее про это написано habr.com/company/rambler-co/blog/332202
igor_suhorukov
Спасибо! Почитал с интересом и особенно понравилось что описали сложности для каждого компонента.
Вы при работе отправляете pull requestы? Было бы замечательно, если каждый проект не велосипедом на базовых фичах!
pilosus
мы шлем пулл-реквесты в те опен-сорс проекты, на которые у нас есть ресурсы — время и люди, которые знают стек технологий, на котором написан опен-сорс проект. К примеру, на момент написания той статьи в команде не было людей, хорошо знакомых с Java, чтобы что-то коммитить в Kafka. А вот в ClickHouse мы поправили некоторые баги и добавили нужные нам (и, надеюсь, другим) фичи.
igor_suhorukov
Молодцы! Вполне прагматичный подход.