
А ведь могло быть по-другому. Вам приходит смс от системы мониторинга, что произошел сбой на одном из серверов. Но СУБД продолжает работать, поскольку отказоустойчивый кластер PostgreSQL отработал потерю одного узла и продолжает функционировать. Нет надобности срочно ехать на работу и восстанавливать сервер БД. Выяснение причин сбоя и работы по восстановлению спокойно переносятся на рабочий понедельник.
Как бы то ни было, стоит подумать о технологиях отказоустойчивы кластеров с СУБД PostgreSQL. Мы расскажем о построении отказоустойчивого кластера СУБД PostgreSQL с помощью программного обеспечения Pacemaker&Corosync.
Отказоустойчивый кластер СУБД PostgreSQL на основе Pacemaker
Сегодня в ИТ-системах уровня «business critical» спрос на широкую функциональность отходит на второй план. На первое место выходит спрос на надежность ИТ-систем. Для отказоустойчивости приходится вводить избыточность компонентов системы. Ими управляет специальное программное обеспечение.
Примером такого программного обеспечения является Pacemaker – решение компании ClusterLabs, позволяющее организовать отказоустойчивый кластер (ОУК). Работает Pacemaker под управлением широкого спектра операционных Unix-систем – RHEL, CentOS, Debian, Ubuntu.
Это программное обеспечение не создавали специально для работы с PostgreSQL или других СУБД. Сфера применения Pacemaker&Corosync значительно шире. Есть специализированные решения, заточенные под PostgreSQL, например multimaster, входящий в состав Postgres Pro Enterprise (компания Postgres Professional), или Patroni (компания Zalando). Но рассматриваемый в статье кластер PostgreSQL на основе Pacemaker/Corosync, достаточно популярен и подходит по соотношению простоты и надежности к стоимости владения для немалого числа ситуаций. Все зависит от конкретных задач. Сравнение решений не входит в задачи этой статьи.
Итак: Pacemaker — мозг и по совместительству менеджер ресурсов кластера. Его главная задача — достижение максимальной доступности ресурсов, которыми он управляет, и защита их от сбоев.
Во время работы кластера происходят различные события – сбой, присоединение узлов, ресурсов, переход узлов в сервисный режим и другие. Pacemaker реагирует на эти события в кластере, выполняя действия, на которые он запрограммирован., например, остановку ресурсов, перенос ресурсов и другие.
Для того, чтобы стало понятно, как устроен и работает Pacemaker, давайте рассмотрим, что у него внутри и из чего он состоит.
Итак, перейдем к сущностям Pacemaker.
Рисунок 1. Сущности pacemaker – узлы кластера
Первая и самая важная сущность – это узлы кластера. Узел (нода,
node) кластера представляет собой физический сервер или виртуальную машину с установленным Pacemaker.Узлы, предназначенные для предоставления одинаковых сервисов, должны иметь одинаковую конфигурацию софта. То есть, если ресурс postgresql предполагается запускать на узлах
node1, node2, и он расположен в нестандартных путях установки, то на этих узлах должны быть одинаковые конфигурационные файлы, пути установки PostgreSQL, и конечно же, одинаковая версия PostgreSQL.Следующая важная группа сущностей Pacemaker – ресурсы кластера. Вообще для Pacemaker ресурс — это скрипт, написанный на любом языке. Обычно эти скрипты пишутся на
bash, но ничто не мешает писать их на Perl, Python, C или даже на PHP. Скрипт управляет сервисами в операционной системе. Главное требование к скриптам — уметь выполнять 3 действия: start, stop, monitor и делиться некоторой метаинформацией.Правда в нашем случае — кластера PostgreSQL — к этим действиям добавляются promote, demote и другие специфичные для PostgreSQL команды.
Примеры ресурсов:
- IP адрес;
- сервис, запускаемый в операционной системе;
- блочное устройство
- файловая система;
- другие.
Ресурсы имеют множество атрибутов, которые хранятся в конфигурационном XML-файле Pacemaker'а. Наиболее интересные из них: priority, resource-stickiness, migration-threshold, failure-timeout, multiple-active.
Рассмотрим их более подробно.
Атрибут priority — приоритет ресурса, который учитывается, если узел исчерпал лимит по количеству активных ресурсов (по умолчанию 0). Если узлы кластера не одинаковы по производительности или доступности, то можно увеличить приоритет одного из узлов, чтобы он был активным всегда, когда работает.
Атрибут resource-stickiness — липкость ресурса (по умолчанию 0). Липкость (stickiness) указывает на то, насколько ресурс «хочет» оставаться там, где он есть сейчас. Например, после сбоя узла его ресурсы переходят на другие узлы (точнее — стартуют на других узлах), а после восстановления работоспособности сбойного узла, ресурсы могут вернуться к нему или не вернуться, и это поведение как раз и описывается параметром липкость.
Другими словами, липкость показывает, насколько желательно или не желательно, чтобы ресурс вернулся на восстановленный после сбоя узел.
Поскольку по умолчанию липкость всех ресурсов 0, то Pacemaker сам располагает ресурсы на узлах «оптимально» на свое усмотрение.
Но это не всегда может быть оптимально с точки зрения администратора. Например, в случае, когда в отказоустойчивом кластере узлы имеют неодинаковую производительность, администратор захочет запускать сервисы на узле с большей производительностью.
Также Pacemaker позволяет задавать разную липкость ресурса в зависимости от времени суток и дня недели, что позволяет, например, обеспечить переход ресурса на исходный узел в нерабочее время.
Атрибут migration-threshold — сколько отказов должно произойти, чтобы Pacemaker решил, что узел непригоден для данного ресурса и перенёс (мигрировал) его на другой узел. По умолчанию также этот параметр равен 0, т. е. при любом количестве отказов автоматического переноса ресурсов не будет происходить.
Но, с точки зрения отказоустойчивости, правильно выставить этот параметр в 1, чтобы при первом же сбое Pacemaker перемещал ресурс на другой узел.
Атрибут failure-timeout — количество секунд после сбоя, до истечения которых Pacemaker считает, что отказа не произошло, и не предпринимает ничего, в частности, не перемещает ресурсы. По умолчанию, равен 0.
Атрибут multiple-active – дает указание Pacemaker, что делать с ресурсом, если он оказался запущен более чем на одном узле. Может принимать следующие значения:
- block — установить опцию unmanaged, то есть деактивировать
- stop_only — остановить на всех узлах
- stop_start — остановить на всех узлах и запустить только на одном (значение по-умолчанию).
По умолчанию, кластер не следит после запуска, жив ли ресурс. Чтобы включить отслеживание ресурса, нужно при создании ресурса добавить операцию
monitor, тогда кластер будет следить за состоянием ресурса. Параметр interval этой операции – интервал, с каким делать проверку.При возникновении отказа на основном узле, Pacemaker «перемещает» ресурсы на другой узел (на самом деле, Pacemaker останавливает ресурсы на сбойнувшем узле и запускает ресурсы на другом). Процесс «перемещения» ресурсов на другой узел происходит быстро и незаметно для конечного клиента.
Группы ресурсов
Ресурсы можно объединять в группы — списки ресурсов, которые должны запускаться в определенном порядке, останавливаться в обратном порядке и исполняться на одном узле.Все ресурсы группы запускаются на одном узле и запускаются последовательно, согласно порядку в группе. Но нужно учитывать, что при сбое одного из ресурсов группы, вся группа переместится на другой узел.
При выключении какого-либо ресурса группы, все последующие ресурсы группы тоже выключатся. Например, ресурс PostgreSQL, имеющий тип pgsql, и ресурс Virtual-IP, имеющий тип IPaddr2, могут быть объединены в группу.
Последовательность запуска в этой группе такая – сначала запускается PostgreSQL, и при его успешном запуске вслед за ним запускается ресурс Virtual-IP.
Кворум (quorum)
Что такое кворум? Говорят, что кластер имеет кворум при достаточном количестве «живых» узлов кластера. Достаточность количества «живых» узлов определяется по формуле ниже.
n > N/2, где n – количество живых узлов, N – общее количество узлов в кластере.
Как видно из простой формулы, кластер с кворумом – это когда количество «живых» узлов, больше половины общего количества узлов в кластере.
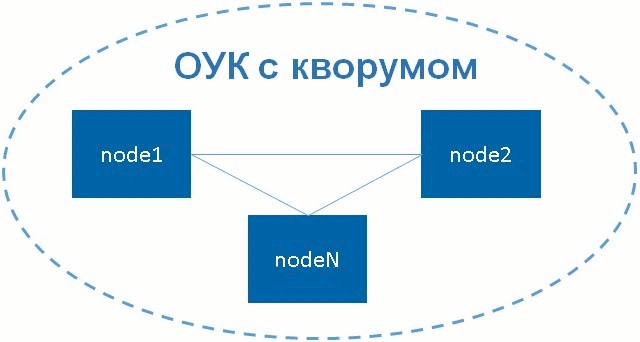
Рисунок 2 – Отказоустойчивый кластер с кворумом
Как вы, наверное, понимаете, в кластере, состоящем из двух узлов, при сбое на одном из 2-х узлов не будет кворума. По умолчанию, если нет кворума, Pacemaker останавливает ресурсы.
Чтобы этого избежать, нужно при настройке Pacemaker указать ему, чтобы наличие или отсутствие кворума не учитывалось. Делается это с помощью опции no-quorum-policy=ignore.
Архитектура Pacemaker
Архитектура Pacemaker представляет собой три уровня:

Рисунок 3 – Уровни Pacemaker
- Кластеронезависимый уровень – ресурсы и агенты. На этом уровне располагаются сами ресурсы и их скрипты. На рисунке обозначен зеленым цветом.
- Менеджер ресурсов (Pacemaker), это «мозг» кластера. Он реагирует на события, происходящие в кластере: отказ или присоединение узлов, ресурсов, переход узлов в сервисный режим и другие административные действия. На рисунке обозначен синим цветом.
- Информационный уровень (Corosync) — на этом уровне осуществляется сетевое взаимодействие узлов, т.е. передача сервисных команд (запуск/остановка ресурсов, узлов и т.д.), обмен информацией о полноте состава кластера (
quorum) и т.д. На рисунке он обозначен красным.
Что нужно для работы Pacemaker?
Для правильного функционирования отказоустойчивого кластера необходимо, чтобы выполнялись следующие требования:
- Синхронизация времени между узлами в кластере
- Разрешение имен узлов в кластере
- Стабильность сетевых подключений
- Наличие у узлов кластера функции управления питанием/перезагрузкой с помощью IPMI(ILO) для организации «фенсинга» (fencing – изоляция) узла.
- Разрешение прохождения трафика по протоколам и портам
Рассмотрим эти требования подробнее.
Синхронизация времени – нужно, чтобы все узлы имели одно и то же время, обычно это реализуется установкой в локальной сети сервера времени (
ntpd).Разрешение имен – реализуется установкой в локальной сети сервера DNS. Если нет возможности установить сервер DNS, нужно на всех узлах кластера внести записи в файл /etc/hosts с именами хостов и IP-адресами.
Стабильность сетевых соединений. Необходимо избавиться от ложных срабатываний. Представьте, что у вас нестабильная локальная сеть, в которой каждые 5-10 секунд происходит потеря линка между узлами кластера и коммутатором. В таком случае, Pacemaker будет считать сбоем пропадание линка более, чем на 5 секунд. Пропал линк, ваши ресурсы «переехали». Потом линк восстановился. Но Pacemaker уже считает узел в кластере «сбойнувшим», он уже «перенес» ресурсы на другой узел. При следующем сбое, Pacemaker «перенесет» ресурсы на следующий узел, и так далее, пока не закончатся все узлы, и возникнет отказ в обслуживании. Таким образом, из-за ложных срабатываний весь кластер может перестать функционировать.
Наличие у узлов кластера функции управления питанием/перезагрузкой с помощью IPMI (ILO) для организации «фенсинга». Необходимо для того, чтобы при сбое узла изолировать его от остальных узлов. «Фенсинг» исключает ситуацию возникновения split-brain (когда появляются одновременно два узла, выполняющих роль Мастера СУБД PostgreSQL).
Разрешение прохождения трафика по протоколам и портам. Это важное требование, потому что в различных организациях службы безопасности часто устанавливают ограничения на прохождение трафика между подсетями или ограничения на уровне коммутаторов.
В таблице ниже приведен перечень протоколов и портов, которые необходимы для функционирования отказоустойчивого кластера.
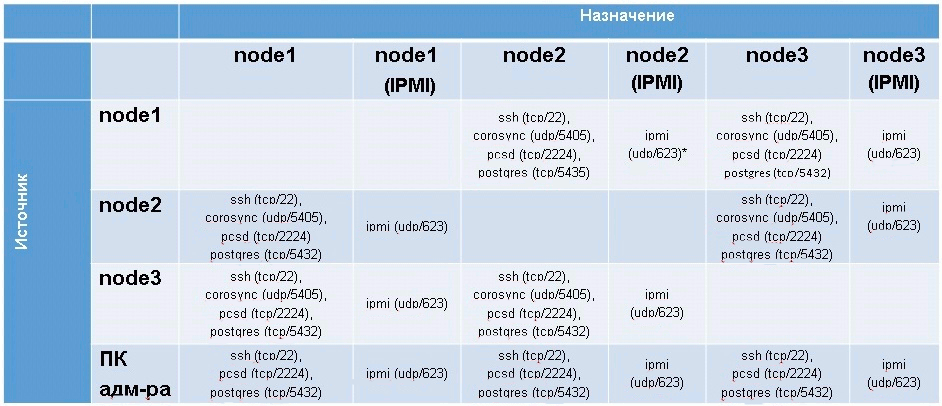
Таблица 1 – Перечень протоколов и портов, необходимых для функционирования ОУК
В таблице приведены данные для случая отказоустойчивого кластера из 3-х узлов –
node1, node2, node3. Также подразумевается, что узлы кластера и интерфейсы управления питанием узлов (IPMI) находятся в разных подсетях.Как видно из таблицы, необходимо обеспечить не только доступность соседних узлов в локальной сети, но и доступность узлов в сети IPMI.
Особенности использования виртуальных машин для ОУК
При использовании виртуальных машин для построения отказоустойчивых кластеров следует учитывать следующие особенности.
- fsync. Отказоустойчивость СУБД PostgreSQL очень сильно завязана на возможность синхронизировать запись в постоянное хранилище (диск) и корректное функционирование этого механизма. Разные гипервизоры по-разному реализуют кеширование дисковых операций, некоторые не обеспечивают своевременного сброса данных из кеша в систему хранения.
- realtime corosync. Процесс corosync в ОУК на основе Pacemaker отвечает за обнаружение сбоев узлов кластера. Для того, чтобы он корректно функционировал, нужно, чтобы ОС гарантированно планировала его исполнение на процессоре (ОС выделяет процессорное время). В связи с этим этот процесс имеет приоритет RT (
realtime). В виртуализированной ОС нет возможности гарантировать такое планирование процессов, что приводит к ложным срабатываниям кластерного ПО. - фенсинг. В виртуализированной среде механизм фенсинга (
fencing) усложняется и становится многоуровневым: на первом уровне нужно реализовать выключение виртуальной машины через гипервизор, а на втором — выключение всего гипервизора (второй уровень срабатывает, когда на первом уровне фенсинга корректно не отработал). К сожалению, у некоторых гипервизоров нет возможности фенсинга. Рекомендуем не использовать виртуальные машины при построении ОУК.
Особенности использования PostgreSQL для ОУК
При использовании PostgreSQL в отказоустойчивых кластерах следует учитывать следующие особенности:
- Pacemaker при запуске кластера с PostgreSQL размещает файл блокировки LOCK.PSQL на узле с мастером СУБД. Обычно этот файл размещается в директории
/var/lib/pgsql/tmp. Это делается с той целью, чтобы при сбое на Мастере запретить в дальнейшем автоматический запуск PostgreSQL. Таким образом, после сбоя на Мастере всегда требуется вмешательство администратора БД для устранения причин сбоя. - Поскольку в ОУК используется стандартная схема PostgreSQL Master-Slave, то при определенных сбоях возможна ситуация возникновения двух Мастеров – т.н. split-brain. Например, сбой Потеря сетевой связности между каким-либо из узлов и остальными узлами (о всех видах сбоев см. далее). Во избежание этой ситуации необходимо выполнение двух важных условий при построении отказоустойчивых кластеров:
- наличие кворума в ОУК. Это означает, что в кластере должно быть не менее 3-х узлов. Причем, необязательно все три узла должны быть с СУБД, достаточно на двух узлах иметь Мастер и Реплику, а третий узел выступает в роли «голосующего».
- Наличие устройств фенсинга на узлах с СУБД. При возникновении сбоя устройства «фенсинга» изолируют сбойнувший узел – посылают команду на выключение питания или перезагрузку (
poweroffилиhard-reset).
- Архивы WAL-ов рекомендуется размещать на общих (
shared) устройствах хранения, доступных как Мастеру, так и Реплике. Это позволит упростить процесс восстановления Мастера после сбоя и перевода его в режимSlave.
Команды управления Pacemaker
Приведем некоторые интересные команды управления Pacemaker (все команды требуют права суперпользователя ОС).Основная утилита управления кластером — pcs. Перед настройкой и первым запуском кластера необходимо один раз произвести авторизацию узлов в кластере.
- sudo pcs cluster auth node1 node2 node3 -u hacluster -p 'пароль‘
- Запуск кластера на всех узлах
- sudo pcs cluster start --all
Запуск/останов на одном узле:
- sudo pcs cluster start
- sudo pcs cluster stop
Просмотр состояния кластера с помощью монитора Corosync:
- sudo crm_mon -Afr
Очистка счетчиков сбоев:
- sudo pcs resource cleanup
Мониторинг состояния кластера с помощью crm_mon
У Pacemaker есть встроенная утилита мониторинга состояния кластера. Системный администратор может с помощью нее видеть, что происходит в кластере, какие ресурсы на каких узлах расположены в настоящее время.
С помощью команды crm_mon можно контролировать состояние ОУК.
- sudo crm_mon –Afr
На скриншоте отчет о состоянии кластера.
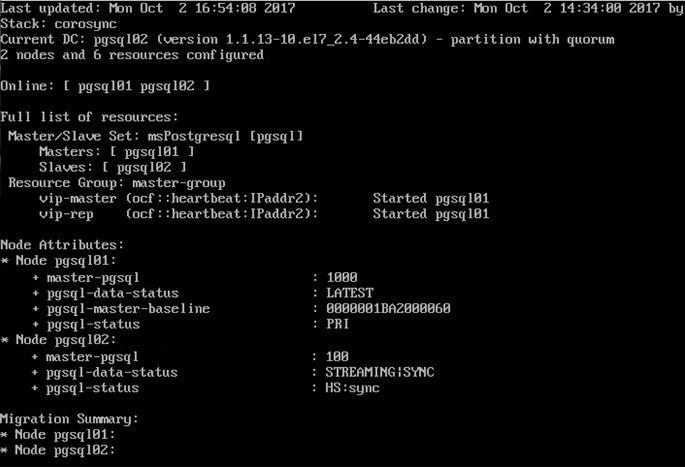
Рисунок 4 – Мониторинг состояния кластера с помощью команды crm_mon
pgsql-status
PRI – состояние мастераHS:sync – синхронная репликаHS:async – асинхронная репликаHS:alone – реплика не может подключится к мастеруSTOP – PostgreSQL остановленpgsql-data-status
LATEST – состояние, присущее мастеру. Данный узел является мастером.STREAMING:SYNC/ASYNC – показывает состояние репликации и тип репликации (SYNC/ASYNC)DISCONNECT – реплика не может подключиться к мастеру. Обычно такое бывает, когда нет соединения от реплики к мастеру.pgsql-master-baselineПоказывает линию времени. Линия времени меняется каждый раз после выполнения команды promote на узле-реплике. После этого СУБД начинает новый отсчет времени.Виды сбоев на узлах кластера
От каких видов сбоев защищает отказоустойчивый кластер на базе Pacemaker?
- Сбой по питанию на текущем мастере или на реплике. Сбой питания, когда пропадает питание и сервер выключается. Это может быть как Мастер, так и одна из Реплик.
- Сбой процесса PostgreSQL. Сбой основного процесса PostgreSQL – система может завершить аварийно процесс postgres по разным причинам, например, нехватка памяти, либо недостаточное количество файловых дескрипторов, либо превышено максимальное число открытых файлов.
- Потеря сетевой связности между каким-либо из узлов и остальными узлами. Это сетевая недоступность какого-либо узла. Например, её причиной может быть выход из строя сетевой карты, либо порта коммутатора.
- Сбой процесса Pacemaker/Corosync. Сбой процесса Corosync/pacemaker аналогично сбою процесса PostgreSQL.
Виды планового обслуживания ОУК
Для проведения регламентных работ необходимо периодически выводить из состава кластера отдельные узлы:
- Выведение из эксплуатации Мастера или Реплики для плановых работ нужно в следующих случаях:
- замена вышедшего из строя оборудования (не приведшего к сбою);
- апгрейд оборудования;
- обновление софта;
- другие случаи.
- Смена ролей Мастера и Реплики. Это нужно в случае, когда, серверы Мастера и Реплики отличаются по ресурсам. Например, у нас в составе ОУК есть мощный сервер, выполняющий роль Мастера СУБД PostgreSQL, и слабый сервер, выполняющий роль Реплики. После сбоя более мощного сервера Мастера его функции переходят к более слабой Реплике. Логично предположить, что после устранения причин сбоя на бывшем Мастере администратору захочется вернуть роль Мастера обратно на мощный сервер.
Важно! Прежде чем производить смену ролей или вывод Мастера из эксплуатации, необходимо с помощью команды #crm_mon –Afr убедиться, что в кластере присутствует синхронная реплика. И роль Мастера назначается всегда синхронной реплике.
Поскольку цель этой и так не короткой статьи – познакомить вас с одним из решений по отказоустойчивости СУБД PostgreSQL, вопросы установки, настройки и команды конфигурирования отказоустойчивого кластера не рассматриваются.
Автор статьи — Игорь Косенков, инженер Postgres Professional.
Рисунок — Наталья Лёвшина.
Комментарии (21)

dotfinal
24.05.2018 14:41Опцию no-quorum-policy=ignore лучшего вообще не показывать, а если показывать, то писать про split-brain сразу после, а не через еще полстатьи. Найдутся же люди, мол, «пфф, что за глупость, конечно же, выключу» :D
F0iL
25.05.2018 13:11Когда нет кворума, т.к. всего два сервера, или когда нельзя по какой-то причине сделать фенсинг, можно сами сервера, если они стоят рядом в одной серверной, сцепить напрямую друг с другом еще одним сетевым кабелем (в конфигурации pacemaker я не видел опции, чтобы он использовал для синхронизации еще один интерфейс, но можно вручную прописать это в конфиг corosync), и после этого добавить ресурс ocf:pacemaker:ping с пингом на какой-нибудь вышестоящий узел (например, маршрутизатор/шлюз или сервер приложений), и тогда в случае проблем с сетью или железом, сервера об этом сами поймут и договорятся между собой о том, чтобы не допустить сплит-брейна и переместить ресурсы на ту машину, что не потеряла связность.
Andronas
24.05.2018 16:15+1… Произошел сбой на сервере СУБД, база данных с текущего момента недоступна. На решение проблемы отводится короткое время.
В нормальной компании на такой случай должен быть дежурный администратор, иначе никакой кластер не спасет.F0iL
25.05.2018 13:26Это вы еше с комплексами на промышленных и транспортных объектах не работали.
Дежурный есть только техник, который скорее электрик, чем айтишник, ответственный администратор тоже есть, но по ночам он не работает, у него целый зоопарк этих систем, и их он знает только по тому, что написано в документации от разработчиков системы, сами разработчики в другом городе, по выходным не работают, приехать смогут дня через три, удаленные подключения и Интернет запрещает СБ.
При этом требования по отказоустойчивости системы возведены в абсолют — вплоть до того, что с любым программным глюком система должна разбираться сама и полностью автоматически, с аппаратным — с минимальным вмешательством (если посыпался диск, то узнали об этом в системе мониторинга, диск заменили по инструкции, все само синхронилизировалось и восстановилось; заглючило железо — заменили сервер целиком по инструкции на такой же со склада, все автоматически настроилось, синхронизировалось и восстановилось без единого диалогового окна или запроса к пользователю), и работать все это должно без потери сервиса ни на минуту.
Иными словами, по ТЗ случаи вида «над этим думает и разбирается администратор» в принципе недопустимы.
Мы в подобном проекте как раз использовали PostgreSQL и Pacemaker/Corosync. Веселья была масса.
ildarz
24.05.2018 16:40В виртуализированной среде механизм фенсинга (fencing) усложняется и становится многоуровневым: на первом уровне нужно реализовать выключение виртуальной машины через гипервизор, а на втором — выключение всего гипервизора (второй уровень срабатывает, когда на первом уровне фенсинга корректно не отработал). К сожалению, у некоторых гипервизоров нет возможности фенсинга. Рекомендуем не использовать виртуальные машины при построении ОУК
Вот этого абзаца я вообще не понял.
Во-первых, что это за таинственные "некоторые" гипервизоры, у которых нет функции выключения VM?
Во-вторых, из-за сбоя в одной VM гасить весь хост, серьезно?!
В-третьих, финальное "рекомендуем не использовать VM" — а вы на календарь смотрели? Сейчас не 2008 год, а 2018.
Понятно, что многие вещи при виртуализации усложняются (начиная от понимания того, что, собственно случилось, заканчивая механизмами реакции). Но это попросту заслуживает отдельного рассмотрения, а не рекомендаций вида "не используйте виртуалки, там надо".
Merlyel
24.05.2018 17:08Во-первых, что это за таинственные «некоторые» гипервизоры, у которых нет функции выключения VM?
Имхо, тут вопрос не в «нет функции выключения», а то, что корректный фенсинг — это жесткое отключение из розетки (если проводить аналогию с железками), а не милая просьба «выключись, пожалуйста». И вот если хост не смог выключить быстро VM (ну зависли там процессы напрочь и система не хочет выключиться), то в зависимости от критичности кластеризованного сервиса может быть придется и весь хост погасить.ildarz
24.05.2018 17:35что корректный фенсинг — это жесткое отключение из розетки
Тогда это надо делать через управляемый PDU, а не IPMI, с которым тоже фокусы могут быть. ;) А выключение через IPMI концептуально мало чем отличается от выключения через гипервизор.
в зависимости от критичности кластеризованного сервиса может быть придется и весь хост погасить.
Может быть. Только управляться это должно не на уровне кластера PostgreSQL, а на уровне кластера виртуализации. Я про то и пишу, что в виртуализованной среде нужно дополнительное планирование, а советы "выключите хост" или "не используйте виртуализацию" не слишком полезны в общем случае. Хотя, конечно, вполне могут быть кейсы, где виртуализация просто не нужна.
Biggo
24.05.2018 20:11Или можно просто начать использовать CockroachDB, который с самого начала multimaster. Понятно, что по функционалу не сравнить, но ребята энергично работают.
DonAlPAtino
25.05.2018 11:02А такой кластер можно растянуть на пару датацентров или лучше не надо?
Igor_Le Автор
25.05.2018 13:54[ответ автора статьи, Игоря Косенкова]
Есть положительный опыт построения 3-х нодового кластера, «растянутого» на 3 дата-центра — каждая нода живет в своем дата-центре.
В таком кластере есть свои нюансы, которые необходимо учитывать.
Первый — невозможность обеспечить надежный управляющий линк между нодами, поскольку нельзя гарантировать надежный канал между дата-центрами. Линк между нодами (считай, между дата-центрами) может периодически пропадать. В ОУК с дефолтными настройками такое пропадание линка будет считаться сбоем и Pacemaker на это среагирует — переместит ресурсы на «живую» ноду.
Поэтому встает задача выставить оптимальные таймауты на время реагирования Pacemaker'ом.
Выставить большие таймауты — значит будет большее время переключения роли Мастера между нодами.
Выставить короткий таймаут — значит будут ложные срабатывания Pacemaker'ом.
Оптимальные таймауты можно подобрать только эмпирическим путем.
Второй — необходимо организовать единое адресное пространство между дата-центрами. Это дополнительное оборудование, расходы, и с точки зрения надежности — включение дополнительных элементов (VPN-устройств) необходимо также резервировать.
Третий — ввиду того, что задержка между дата-центрами может составлять большее время, чем в локальной сети, то придется отказаться от синхронной реплики при построении ОУК. А это влечет небольшую потерю данных — реплика от мастера будет отставать, и при переключении роли мастера на асинхронную реплику небольшая часть данных будет потеряна.
trider
25.05.2018 11:33Вопрос, как и ко всем этим хреновым инструментариям, которые не решают проблему. Пришёл на master долгоиграющий ALTER TABLE, который успешно просочился в бинарных логах на слейвы, в этот момент у нас факап на мастере и неважно что руки/patroni/Pacemaker и т.д. один из слейвов переключает в режим master'а, который из бинлога разгребает долгоиграющий ALTER TABLE. Как Pacemaker узнает о долгоиграющем ALTER TABLE и поймёт когда SLAVE его разгребёт, чтобы сделать его мастером?
Andronas
25.05.2018 23:31Если например две ноды, есть общее хранилище то с помощью Pacemaker можно сделать failover кластер где постгрес живёт на одной ноде а на второй поднимается при сбое на первой?
vesper-bot
Ага, только переезд постгрес-мастера по скрипту pacemaker тоже провалился, и весь кластер рассыпался вдребезги. Такое тоже бывает ;)
Вообще, имхо corosync/pacemaker — самый рульный кластерный стек на линуксах, во всяком случае, я с ним почти без проблем сумел разобраться и даже что-то на нем поднять, что стоит и не падает.