Этой весной мне удалось, наконец, реализовать давнюю мечту строителей конструкторов: встроить среди американских патентов четвертьвековой давности очень простое решение всех их проблем. По сути — это эмуляция базы данных приложения, при построении которого вся черновая, рутинная работа программиста вынесена «за скобки».
В снове решения — система хранения данных и способ их обработки, результат — альтернатива существующим ORM. Заявленные преимущества: повышение надёжности базы данных за счёт минимизации ошибок при добавлении новых данных и формировании запросов к ним, а также снижение риска лавинообразной деградации производительности при работе с большими объемами данных (с любыми объемами).
Оно не меняет принципиально структуру физического хранения данных, в нем всё происходит точно так же, как в обычном приложении с базой данных: информация хранится на носителе, она фрагментирована, со временем фрагментация увеличивается. При запросах данных так же происходит множество чтений разрозненных фрагментов информации с диска.
Больше того — это может работать в обычной реляционной БД.
Но есть нюансы.
В целом, сейчас те мечты 90-х уже не так актуальны, есть множество различных ORM, и их проблемы менее заметны на фоне всего остального, что успел породить прогресс. Но иногда так хочется вернуться к истокам… Вернёмся.
Есть два качественных улучшения в управлении данными:
- Программист работает на уровень выше — на уровне конструктора, что позволяет делать на порядок меньше работы для задания структуры и выборки данных
- Администратор работает с предельно простой базой данных, в которой задачи кластеризации, зеркалирования, шардирования и подобные решаются также значительно проще
Сегодня реализованный прототип ядра (пусть далее оно называется так) будущей платформы не предоставляет Администратору никаких готовых средств для решения его задач. Учитывая простоту архитектуры, адаптация этих средств под конкретный проект сопоставима с написанием их с нуля. То же касается переноса между средами, контроля версий и прочего.
Рамки задач ядра: управление структурой, запросы и базовый интерфейс для изменения данных.
Я сделал минимальную обвязку и интерфейс, чтобы можно было пользоваться. Например, не используется механизм транзакций, доступный в СУБД, хотя реализовать его в ядре займет не более часа. Также не используются триггеры и constraints, просто потому что всё это до сих пор не понадобилось нам в прикладной разработке. Подобные вещи делаются поверх ядра (далеко за рамками патентной формулы) и, рискну заявить, делаются достаточно тривиально чтобы любой желающий мог сделать их под себя.
Теперь рассмотрим упомянутые нюансы.
Все данные физически хранятся в одной таблице из 5 полей: ID, родитель (ID), тип (тоже ID), порядок среди равных (число), значение (набор байтов). У неё есть 3 индекса: ID, тип-значение, родитель-тип. Вместо обращения к базе данных, которая найдет таблицу, в ней найдет поле, в котором найдет данные, ядро обращается к единственной таблице, в которой по индексу сразу находит данные нужного типа.
Подход, реализованный в ядре, позволят описать в этой таблице любую структуру данных: в редакторе типов создаем метамодель данных, а сами данные по этой модели доступны для просмотра и изменения в базовом интерфейсе. Объединение данных разных типов в таблицы использует статистику индексов, чтобы всё это работало с оптимальной скоростью — любая РСУБД примерно так же работает с данными на диске.
Это можно представить как устройство хранения, куда можно отправлять данные и запрашивать их, обращаясь к ядру. При этом снаружи, в интерфейсе, данные выглядят как набор обычных таблиц реляционной БД. Далее под таблицами я подразумеваю именно эти смоделированные ядром таблицы.
Индексирование данных
Как видите, есть некоторая избыточность при индексировании, такова цена удобства.
Оптимизатор запросов сделает грязную работу за программиста — устранит неоптимальные сканирования таблиц данных, как если бы администратор проанализировал структуру и построил все нужные индексы вручную. Это рутинная задача, которой обычно занимаются по мере необходимости, тем не менее, если этим всерьез не заниматься, то база данных непродуктивно потребляет ресурсы сервера. Иногда очень непродуктивно.
Разумеется, никакой оптимизатор не заменит человека, особенно, знакомого с предметной областью, поэтому в любом приложении есть место для негрязной, творческой работы программиста.
Далее несколько примеров, когда может потребоваться подойти к решению с умом.
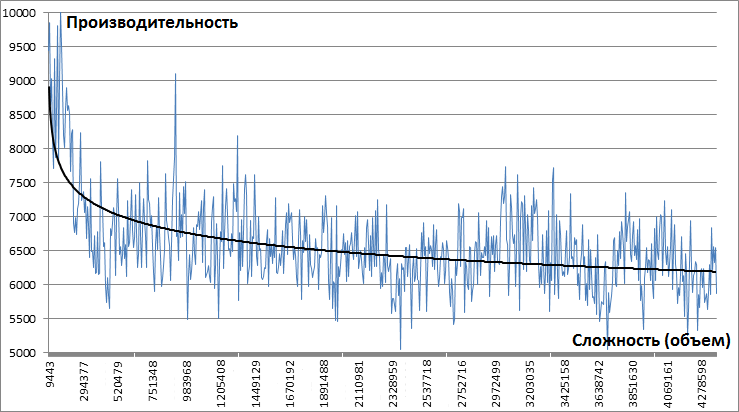
Есть правила, которые нужно помнить и соблюдать, чтобы производительность вашего приложения была оптимальна. Эти правила придумал не я, они относятся к общим приемам эффективной работы с большими объемами данных. Надо заметить, что эти же правила работают в любой реляционной базе данных. Некоторые из них очевидны для опытных разработчиков, однако, не все приходят в разработку сразу опытными.
Невозможность использования индекса
Избегайте использовать критичный к быстродействию фильтр по неиндексируемому значению поля:
- Индекс не применится в случае, когда вы используете некую функцию для преобразования поля, а затем уже к её результату применяете фильтр.
- Также следует учитывать, что индекс строится по значению полей, начиная с их первого символа, поэтому если вы используете в фильтре сравнение с подстрокой, начинающейся не с первого символа, то индекс применен не будет.
Не так часто встречается реальная необходимость применять указанные выше способы отбора данных в больших массивах записей, но если это действительно необходимо, то лучше будет дополнительно хранить заранее вычисленное значение нужной функции.
- Если в номерах банковских счетов вы анализируете код валюты по 6-8 символам, то вместо использования выражения SUBSTRING(Валюта, 6, 3) для отбора валют счетов следует вынести код валюты в отдельное поле в таблице счетов и делать выборку по его значению
- Когда вам требуется быстро найти человека по последним цифрам номера его телефона, то вместо поиска по маске %4567 стоит создать дополнительное поле с инвертированными номерами 89101234567 => 765432 (необязательно номер целиком) и затем также инвертировать условие поиска перед отправкой его в запрос: 7654%
Отсутствие индекса
Если вы планируете использовать для фильтрации данных некий атрибут, который может быть пустым, то его следует сделать обязательным и прописать туда по умолчанию значение, которое будет означать пустоту, например, слово NULL.

В данном случае выполненный заказ имеет заполненное время выполнения, и если не заполнять это поле аналогом пустого значения, то ядро не сохранит и не проиндексирует его. А значит, оптимизатору придется просмотреть все заказы для нахождения невыполненных, что при большом количестве заказов может занять время и является непродуктивной работой.
Если же мы ставим значение «NULL» (текстовое) по умолчанию, то оптимизатор быстро найдет все невыполненные заказы при помощи индекса.
Последовательность выборки связанных сущностей
При создании запроса старайтесь поместить в колонки отчета в первую очередь объекты или реквизиты, выборка которых по заданным условиям может значительно сократить массив связанных данных.
Обычно оптимизатор неплохо справляется со своей задачей, но бывают случаи, когда ему необходима помощь человека.
В выборке несколько таблиц с различным количеством записей, при этом заданы условия отбора, к которым не может быть применен индекс.
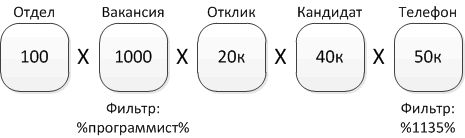
Оптимизатор может начать строить произведение таблиц, начиная с Отдела, прежде чем начнет применять фильтр к телефонам. Это может занять большое время.
Человеку же в этом случае очевидно, что даже без индекса запрос к одной таблице записей отработает быcтрее, вернув несколько записей и подтянув данные остальных таблиц. Поэтому человек поможет оптимизатору, переместив колонку Телефон в начало запроса, и тогда оптимизатор начнет выборку с телефонов.
В общем, это всё что нужно знать о новом ядре, чтобы начать с ним работать, если вам понадобится им овладеть.
Мои предыдущие статьи подвергались критике из-за отсутствия экосистемы вокруг технологического преимущества, данного ядром. Безусловно, это важно — предоставить администратору минимальный набор простых примеров, над чем мы с единомышленниками сейчас работаем, реализовывая самые разные задачи. Эти проекты служат только для подтверждения концепции, они пока не имеют ресурсов для создания Экосистемы для широкого промышленного применения. Тем не менее, там вы можете посмотреть наработки, чтобы мне не быть голословным.
Комментарии (132)

lair
30.05.2018 09:31"Еще одна" EAV. Со всеми недостатками — но более того, совершенно не понятно, как реализуются "заявленные преимущества": например, как же достигается "уменьшение ошибок при вводе", учитывая, что механизм ограничений выкинули. Или почему кластеризация и шардинг проще, хотя теперь критерий шардинга не присутствует в каждой строчке.
UltimaSol Автор
30.05.2018 09:59Это не EAV, поэтому подразумеваемых вами недостатков тут нет.
Постарайтесь без клише обойтись и, если интересно, я расскажу по пунктам, что и как.
Статью старался не перегружать, потому что есть отдельные ссылки, где всё можно посмотреть и потрогать.lair
30.05.2018 10:05+2Все данные физически хранятся в одной таблице из 5 полей: ID, родитель (ID), тип (тоже ID), порядок среди равных (число), значение (набор байтов).
Не EAV, допустим. Тогда что? Ключ-значение с иерархией? Возьмите список недостатков от KV.
Ну и вопросов про ошибки и шардинг это все равно не отменяет.
UltimaSol Автор
30.05.2018 10:24Не KV, опять клише и притянутые автоматом недостатки.
Если бы это укладывалось в существующие приемы, то защитить решение патентом было бы нельзя.
Ошибки сокращаются за счет устранения рисков низкоуровневой работы с данными.
Шардинг проще опять же из-за предельно простой структуры данных.lair
30.05.2018 11:02+2Не KV
Ну так а что тогда, собственно? Понимаете ли, "мы тут придумали такую клевую штуку, которая решает все ваши мечты, но мы вам про нее ничего не расскажем" — это не очень хороший подход для статьи.
Ошибки сокращаются за счет устранения рисков низкоуровневой работы с данными.
Шардинг проще опять же из-за предельно простой структуры данных.Это все, простите, общие слова (которыми, к слову, пестрит маркетинговая документация практически любой СУБД). А конкретику можно какую-нибудь, которая бы их подтверждала?
Вот, возьмем, например, шардинг. Предположим, мне нужно шардить все данные по пользователю (а пользователей, соответственно, мы шардим по стабильному хэшу от гарантированно неизменного идентификатора; непривязанных к пользователю данных не существует). Как конкретно это делается в вашей системе, и почему это проще, чем во всех существующих?
Или возьмем консистентность. Как конкретно в вашей системе гарантируется ссылочная целостность, и почему это проще и лучше, чем в традиционной реляционной БД?
leotsarev
30.05.2018 11:39Предполагаю, что нужно просто в рамках одной транзакции прочитать данные, проверить ссылочную целостность и записать. Это значительно быстрее, чем проверять устаревшими средствами SQL сервера (на самом деле нет).
Ах да, транзакций же тоже нет. Тогда не знаю
lair
30.05.2018 11:05+1Все данные физически хранятся в одной таблице из 5 полей: ID, родитель (ID), тип (тоже ID), порядок среди равных (число), значение (набор байтов).
Предположим, мне нужно сохранить тривиальную структуру: название книги и год ее выпуска. Какие конкретно записи появятся в вашей "одной таблице"?
UltimaSol Автор
30.05.2018 12:33Будет такая структура в Редакторе типов:

Так выглядит добавленный объект:

А так имевшиеся ранее и новые строчки в базе:

lair
30.05.2018 12:46Так, чтобы избежать обсуждения, правильно ли вы смоделировали мою предметную область, давайте просто добавим к "книге" еще один атрибут, "число страниц", и посмотрим, что в хранилище получится после этого.
UltimaSol Автор
30.05.2018 13:09Добавятся строки метаданных (зеленым) и данных (синим)

Сама книга будет выглядеть в редакторе так:

А в Словаре этак:

lair
30.05.2018 13:18UltimaSol Автор
30.05.2018 13:27А при чем здесь этот фрагмент картинки?
Я вам совсем другое показывал, и вот то — не EAV.lair
30.05.2018 13:30При том, что это — EAV, и это нижний уровень. А, значит, вся ваша система как она есть сейчас построена поверх EAV, и (по умолчанию) несет все недостатки этого самого EAV.
UltimaSol Автор
30.05.2018 13:41При том, что это — EAV, и это нижний уровень.
Что «это»?
Вы выдрали кусок данных из контекста и строите неверную теорию.
Я говорю про принципиально иную структуру и иные методы, нежели это сделано в EAV.lair
30.05.2018 13:43Что «это»?
Ваше хранилище.
Я говорю про принципиально иную структуру
То есть данные в вашем хранилище имеют "принципиально иную структуру", нежели показанная вами же в примере выше? Так какую же, расскажите нам.
Hardcoin
30.05.2018 19:40+1Ваше хранилище выглядит как EAV и крякает как EAV. Серьезно, если это не EAV — верю на слово, но в чем разница? Желательно техническими словами, а не маркетинговыми.
UltimaSol Автор
30.05.2018 21:07-2Ваше хранилище выглядит как EAV и крякает как EAV.
Я зачесываю волосы налево. По-вашему, я такой же зверюга, как Гитлер. Я, правда, ещё и рыжий. Ну, наверняка комик, скажете вы. А если я крякну?
Ок, техническими словами EAV как таковой неработоспособен, если пытаться сделать приложение только средствами EAV. EAV — это способ хранить данные для определенных задач, и у него есть свои недостатки, не к каждой задаче он подходит.
Я же утверждаю, что это решение подходит для любых задач прикладной разработки. На небольших проектах подходит как есть, и я могу показать эти проекты. Для нормальных промышленных масштабов требует доработки, как и любая связка Язык программирования — База — Шаблонизатор — Хостинг. Но принципиально тоже подходит для выполнения проекта целиком.Hardcoin
30.05.2018 22:11+1По-вашему, я такой же зверюга, как Гитлер.
Ну какая глупость. Я же говорю, верю на слово, что отличается, но чем? От Гитлера вы, например, отличаетесь тем, что не возглавляете партию (и можно ещё сотню существенных отличий найти).
Ваше решение выглядит как СУБД поверх хранилища EAV. Во всяком случае на первый взгляд.
техническими словами EAV как таковой неработоспособен
Это не "технические слова", извините. Это как раз маркетинговый булшит — "как таковой неработоспособен".
Технический специалист из вашей команды может чуть более техническую статью написать? Математика, бенчмарки, примеры синтаксиса для сложных случаев. Мы же на Хабре всё-таки. Если есть, конечно, желание и время.UltimaSol Автор
30.05.2018 22:19Вот здесь есть тестовый стенд, бенчмарки мордой лица на вас смотрят.
Hardcoin
30.05.2018 22:26Тестовый стенд хороший, а вот бенчмарков с цифрами и графиками не нашел. Если это было предложение самому провести замеры времени, используя ваш тестовый стенд, то это как-то странно.
UltimaSol Автор
31.05.2018 12:35Я сделал выгрузку и анализ журналов одного из сервисов.
Это рекрутерский сервис, интегрированный с HH.RU: оттуда забираются анкеты кандидатов, хранятся вакансии, можно назначать встречи, отправлять СМС и письма.
Вчера там работал 21 пользователь, и они за день сделали чуть больше 10000 запросов на изменение, которые заняли в сумме 2.26 секунды согласно журналу:

Были еще запросы на выборку: построение рабочих форм, отчеты и прочее, которых гораздо больше.
То есть, это небольшая часть нагрузки с замерами.
Вот статистика по запросам (только изменение данных!) за весь день:

Это за самый нагруженный час:

Как видите, средний запрос отрабатывает меньше чем за треть миллисекунды, корреляции среднего времени отработки запроса с пиками нагрузки не наблюдается: за счет быстрой отработки запросов они просто не конфликтуют. Поэтому запас прочности достаточно велик.lair
31.05.2018 13:25и они за день сделали чуть больше 10000 запросов на изменение
… а сколько "запросов на изменение" у вас происходит, когда пользователь обновляет четыре свойства у одного объекта?
UltimaSol Автор
31.05.2018 13:54При создании, удалении и изменении — по 1 запросу на свойство, при удалении объекта — 1 запрос на все.
lair
31.05.2018 13:55… то есть когда пользователь изменяет четыре свойства, вы шлете в четыре раза больше запросов на изменение, чем, гм, традиционные решения?
UltimaSol Автор
31.05.2018 13:59-1Точно.
Это очень простые и быстрые изменения, и любая база также внутри себя кладет изменения не единым действием, а адресно, по отдельным свойствам.lair
31.05.2018 14:14и любая база также внутри себя кладет изменения не единым действием, а адресно, по отдельным свойствам.
Вы правда хотите пообсуждать разницу в стоимости низкоуровневых и высокоуровневых операций?
UltimaSol Автор
31.05.2018 14:43Это быстро работает даже сейчас, при эмуляции всего процесса в базе данных, с громадным оверхэдом. В собственном же откомпилированном движке это тем более будет работать на низком уровне с вполне конкурентноспособными характеристиками.
lair
31.05.2018 14:50Это быстро работает даже сейчас, при эмуляции всего процесса в базе данных, с громадным оверхэдом
"Быстро" — понятие очень относительное.
В собственном же откомпилированном движке это тем более будет работать на низком уровне с вполне конкурентноспособными характеристиками.
Если кто-то сможет его с этими характеристиками написать.
AlexTest
31.05.2018 15:07Если кто-то сможет его с этими характеристиками написать.
UltimaSol переизобрел структуру таблицы для хранения дерева данных объектов произвольной глубины, кстати уже неоднократно описанную во многих учебниках и статьях по БД.
Как я написал тут он просто не понимает насколько эта, на первый взгляд, компактная и простая структура хранения данных будет «дорога» при работе с ней на реальных объектах, для которых она действительно может потребоваться (потому что для большинства случаев она просто не нужна).
roscomtheend
01.06.2018 14:28«любая база также внутри себя кладет изменения не единым действием, а адресно, по отдельным свойствам.» У вас категорически неверные сведения о «любой базе», для вас это пугало типа «обычного стирального порошка» от маркетологов (как и заявление «быстрее, выше, сильнее обычной базы»).
> Это быстро работает даже сейчас, при эмуляции всего процесса в базе данных, с громадным оверхэдом.
Как и говорил в другом месте — это возможно только при кривом проектировании вами «обычной» таблицы.
Hardcoin
31.05.2018 21:21+1Спасибо. Теперь намного понятнее, на какую нишу вы позиционируетесь.
Вообще, создание структуры базы в браузере — это не плохо. Для потоковой разработки — удобно. Хотя преимущества хранения этого в базе в виде дерева, а не в виде кортежей мне непонятны, но почему бы и нет.
lair
30.05.2018 22:28Ок, техническими словами EAV как таковой неработоспособен, если пытаться сделать приложение только средствами EAV
Прекрасно. Осталось объяснить нам, чем конкретно ваше решение отличается от EAV.
Я же утверждаю, что это решение подходит для любых задач прикладной разработки.
Утверждать-то можно что угодно.
m03r
30.05.2018 11:11+1Внимательно прочитал текст, и не могу избавиться от ощущения взаимоисключающих параграфов. Так, в начале читаем: «вся черновая, рутинная работа программиста вынесена “за скобки”». Но при этом далее: «адаптация этих средств под конкретный проект сопоставима с написанием их с нуля».
Ещё: заявлено «повышение надёжности базы данных за счёт минимизации ошибок при добавлении новых данных», но при этом — нельзя задать CONSTRAINT'ы.
Ещё в работе с СУБД «лавинообразное» (читай квадратичное) снижение производительности обычно связано с отсутствием правильных индексов, добавлением которых проблема решается.
В примере с «последовательностью выборки связанных сущностей» планопостроитель любой СУБД построит правильный запрос при нормальной реляционной структуре таблиц, здесь преимущества мне совершенно неочевидны.UltimaSol Автор
30.05.2018 20:47Так, в начале читаем: «вся черновая, рутинная работа программиста вынесена “за скобки”». Но при этом далее: «адаптация этих средств под конкретный проект сопоставима с написанием их с нуля».
Первая часть предложения про программиста, а вторая — про администратора. У них совершенно разные задачи, и этот проект ориентирован больше на программиста, освобождая его от рутины.
В небольших проектах администратор вообще не нужен, что является как раз целью Интеграла (рабочее название этого проекта). Часто в любительской прикладной разработке при 100 тысячах записей в базе уже начинает всё тормозить и нужен админ.
Ещё: заявлено «повышение надёжности базы данных за счёт минимизации ошибок при добавлении новых данных», но при этом — нельзя задать CONSTRAINT'ы.
Речь идет о DDL — вы не можете ошибиться с размерностью данных, ключами и теми же CONSTRAINT'ами, если у вас нет доступа ко всему этому.
Ещё в работе с СУБД «лавинообразное» (читай квадратичное) снижение производительности обычно связано с отсутствием правильных индексов, добавлением которых проблема решается.
Заставьте программиста залезть в базу, найти ВСЕ тонкие места и починить. И починить правильно. Бизнес-пользователю такое удается редко, точнее, почти никогда.
В примере с «последовательностью выборки связанных сущностей» планопостроитель любой СУБД построит правильный запрос при нормальной реляционной структуре таблиц, здесь преимущества мне совершенно неочевидны.
СУБД построит правильный запрос при нормальной реляционной структуре таблиц и наличии нужных индексов. Эту проблему Интеграл и решает (см. предыдущий абзац).lair
30.05.2018 21:06Бизнес-пользователю такое удается редко, точнее, почти никогда.
А вы думаете, бизнес-пользователь способен построить правильную сущностную модель системы? Так нет, не способен. Тогда при чем тут бизнес-пользователь?
UltimaSol Автор
30.05.2018 21:20Как раз тут не про бизнес-пользователя, а про программиста: его не нужно заставлять делать неблагодарную, незаметную, не оплачиваемую отдельно работу, когда Интеграл почти всю её сделал за него.
lair
30.05.2018 22:26Ну так не надо заставлять программиста делать неблагодарную и неоплачиваемую работу — просто заплатите ему.
UltimaSol Автор
30.05.2018 23:41Ага, известно чем это заканчивается. В одной компании, где я работал, шутили так:
Больше thread.sleep'ов ставьте в коде, за скорость отдельно заплатят уроды.
m03r
30.05.2018 21:23Спасибо за разъяснения, но у меня всё равно осталась путаница. Что входит в обязанности администратора, программиста и бизнес-пользователя?
leotsarev
30.05.2018 11:34Выглядит так, что вы поверх SQL сервера сделали свой небольшой SQL сервер, и типа он будет работать быстрее (на самом деле нет).
UltimaSol Автор
30.05.2018 12:43Вы правы, пока у меня нет возможности написать собственный движок или выкинуть всё ненужное для моей задачи из существующего движка с открытым кодом, это работает в обычной РСУБД, неважно какой.
Эта идея про подход, а реализация может быть любая.
Насчет быстрее: я не говорю, что быстрее, чем обычная РСУБД. А говорю, что устраняю непродуктивные накладные расходы и риски за счет добавления некоторой избыточности. Чтобы админу не приходилось искать узкие места и «добавлять индексы» в работающей системе, а сделать эту работу за него (это только одна из задач).lair
30.05.2018 12:47+2А говорю, что устраняю непродуктивные накладные расходы и риски за счет добавления некоторой избыточности
А избыточность, значит, не добавляет накладных расходов?
Hardcoin
30.05.2018 19:42сделать эту работу за него
А кто будет делать эту работу за него? Программист? Или автоматический оптимизатор? Непонятно пока.
UltimaSol Автор
30.05.2018 21:35Ядро сделает работу: создаст структуру и перестроит индексы, а оптимизатор сможет использовать имеющийся набор индексов при построении плана запроса.
Hardcoin
30.05.2018 21:59Т.е. оптимизатор автоматический? Хорошо. В mysql или posrgres так же используются оптимизаторы для построения плана запроса. Какие вы видите преимущества в вашем проекте по сравнению с ними?
Есть ли какие либо сравнительные тесты, например, для связанных таблиц (join) с фильтрацией? По скорости. Интуитивно выглядит, что в вашей схеме, если в таблицах, скажем, по миллиону строк, будет медленнее раз в десять, чем просто положить это в классическую СУБД и повесить индекс.
UltimaSol Автор
30.05.2018 22:39Т.е. оптимизатор автоматический? Хорошо. В mysql или posrgres так же используются оптимизаторы для построения плана запроса. Какие вы видите преимущества в вашем проекте по сравнению с ними?
Мой проект сегодня использует оптимизатор mysql или posgre, т.е. любой базы, на которой развернуто ядро. Даже когда у Интеграла будет свой оптимизатор, то он не будет сильно отличаться от них, а скорее будет просто взят у этих уважаемых коллег. Преимущество не в оптимизаторе, а в системе организации хранения данных и способе представления их пользователю.
Есть ли какие либо сравнительные тесты, например, для связанных таблиц (join) с фильтрацией? По скорости. Интуитивно выглядит, что в вашей схеме, если в таблицах, скажем, по миллиону строк, будет медленнее раз в десять, чем просто положить это в классическую СУБД и повесить индекс.
Пример с пятью миллионами объектов, что составляет 31 872 291 строку в представленной здесь архитектуре.
Можете попробовать сделать аналог в классической СУБД (или найти существующий, коих полно), который будет работать в 10 раз быстрее.Hardcoin
30.05.2018 22:55Вы предлагаете это сделать мне? Повторюсь, это очень странное предложение. Мне интересно посмотреть на сравнительный бенчмарк (если он есть или вы планируете его сделать). Делать бенчмарк для вас мне, конечно, не интересно.
P.S. найти у вас "Селезневская, 10" не вышло, хотя такой адрес явно есть.
UltimaSol Автор
30.05.2018 23:22Вы предлагаете это сделать мне? Повторюсь, это очень странное предложение. Мне интересно посмотреть на сравнительный бенчмарк (если он есть или вы планируете его сделать).
Предлагаю просто посмотреть визуально как это работает. Если у вас на памяти есть подобный сервис, можете на глазок попытаться определить разницу. Нет, так нет.
Я делал сравнение с подобным сервисом в классической СУБД, получалась разница в 2-4 раза по разным оценкам.
P.S. найти у вас «Селезневская, 10» не вышло, хотя такой адрес явно есть.
Там тоже есть P.S.:
P.S. Сервис немного глючноват в плане перебора комбинаций (все таки его суть не в этом), предложения по исправлению с благодарностью принимаются.
lair
30.05.2018 22:30Ядро сделает работу: создаст структуру и перестроит индексы
И где гарантии, что оно построит индексы правильно?
(Вот у MS в Azure для таких оптимизаций прикручено наблюдение за статистикой в очень больших объемах и модель машинного обучения. И то они автооткат сделали.)
UltimaSol Автор
30.05.2018 22:47+1А там всего 3 индекса на всё, сложно сделать неправильно.
Я не первый, кто пытался заставить работать такую архитектуру. Есть эпичные случаи, но у парней не особо получалось. Azure идет путём тех парней, применяятанковые клинья и ковровое бомбометаниенаблюдение в очень больших объемах и модель машинного обучения, я — своим, упрощая всё.lair
30.05.2018 22:51А там всего 3 индекса на всё, сложно сделать неправильно.
Всегда три индекса? А как же write vs read? Покрывающие индексы, разные виды деревьев, пространственные, прочая смешная требуха?
One size doesn't fit all.
UltimaSol Автор
30.05.2018 23:05Если внимательно присмотреться внутрь любой системы, то там вы увидите шину данных, которая последовательно работает со всеми устройствами этой самой системы, которые и сами все с последовательным доступом.
То есть, вся эта «смешная требуха» все равно сериализована и пространственные индексы не более чем виртуальное представление очень сложного, многослойного и неэффективного программного обеспечения, написанного людьми самой разной квалификации. Где происходят мрачные вещи. Ну, не мне вам рассказывать.
Интеграл построен очень просто и имеет только те накладные расходы, о которых я говорю, без «смешной требухи».lair
30.05.2018 23:13Ну то есть вы так незаметно пытаетесь сказать, что вы-то умнее чем отдел-другой программистов, которые решают ту же самую задачу, что и вы, и вы-то сможете построить универсальную прикладную платформу без всех сопутствующих проблем.
roscomtheend
31.05.2018 14:10Сложно сделать неправильно и невозможно правильно. У вас данные могут быть отсортированы только побайтово (ибо массив байт), а это освсем не помогает различным способам поиска (для разных типов данных нужны разные типы индексов, иначе с ускорением будет беда).
UltimaSol Автор
31.05.2018 21:15У вас данные могут быть отсортированы только побайтово (ибо массив байт), а это освсем не помогает различным способам поиска (для разных типов данных нужны разные типы индексов, иначе с ускорением будет беда).
Да, есть такая сложность, что числовые данные сложно привести в общем случае к формату, пригодному для индексирования в любом диапазоне. Сложность вполне решаемая.
Вне диапазона, по значению, проблемы нет.
Со строками и датами и тому, что к ним приводится, также проблем нет, в том числе с полнотекстовыми индексами.
roscomtheend
01.06.2018 14:19+1> Сложность вполне решаемая.
Нерешаема скорость выборки на различных типах данных. Индекс СУБД строит один, а на разных типах данных предпочтительны разные типы для разных операций, а в некоторых случаях не нужны (но вы тратите ресурсы на их поддержание).UltimaSol Автор
02.06.2018 19:04Данные можно преобразовать к тому виду, в котором они хранятся, чтобы использовать индекс.
Затруднение вызывает только применение индекса к диапазону чисел, потому что у них различается порядок — нельзя ранжировать по первым цифрам, нужно считать всё число.

lair
02.06.2018 19:31А напомните еще раз, как вы строите индексы по строковым значениям длиннее килобайта?
leotsarev
30.05.2018 11:37Сейчас вы будете писать, что мы типа не разобрались.
Ну давайте будем разбираться.
Ваша структура поддерживает SQL запросы?UltimaSol Автор
30.05.2018 19:45Есть построитель запросов, аналог SQL, там тот же принцип: перечисляете нужные вам поля данных из разных таблиц, ядро их связывает в запрос и выводит результат. Если связать можно разными способами (например, заказчик и подрядчик у договора хранятся в одной таблице юр.лиц), то вы можете указать, по каким полям нужна связь.
Статье есть пара ссылок на примеры, как это делается: вот и вот.leotsarev
01.06.2018 07:59А группировка там есть? Having?
Приведите пример, во что транслируется запрос «все авторы с двумя или более книгами» на вашей базе.UltimaSol Автор
01.06.2018 19:44Есть аналог HAVING.
Запрограммированный отчет в интерфейсе будет выглядеть примерно так:

В базу улетит примерно такой запрос:
SELECT a227.val v1_217,COUNT(a217.val) v2_217 FROM test a217 LEFT JOIN (test r227 JOIN test a227) ON r227.up=a217.id AND a227.id=r227.t AND a227.t=225 WHERE a217.up!=0 AND a217.t=217 GROUP BY v1_217 HAVING v2_217>=99999999 AND v2_217<=2
Как это делается можно также посмотреть на видео (полторы минуты).
DEbuger
30.05.2018 11:40В пред статьях было написано что интеграл построен на PHP + MySQL. Как оно может работать быстрее MySQL?
roscomtheend
31.05.2018 14:18Легко — делаете крайне неоптимальную структуру на MySSQL в сравнительном тесте и…
eugenero
30.05.2018 19:27+1Кажется, я понял. Автор изобрёл не EAV и не ORM, а дерево типов, а также способ уложить его в таблицу. Очень знакомо. Удивительно, что такую тривиальность можно запатентовать. UltimaSol, можно ссыль на патент или просто вложите сюда текст.
UltimaSol Автор
30.05.2018 21:14Спасибо, коллега! Вы первый комментатор, кто вдумался о чем речь.
На самом деле, запатентовать можно что угодно, и в ходе патентного поиска я насмотрелся всякого. Гораздо сложнее добиться практической работоспособности, и я начинал именно с неё.
Ссыльeugenero
30.05.2018 21:59Но ведь такая конструкция возникает во всякой более-менее развитой информационной системе: медицинской (сам видел), логистической (догадываюсь) и т.д. И тогда встаёт два вопроса: (а) если такое уже есть и используется, зачем это изобретать; (б) кто-то может оспорить патент по праву более раннего фактического использования всей этой хурмы.
UltimaSol Автор
30.05.2018 22:15Но ведь такая конструкция возникает во всякой более-менее развитой информационной системе
Кусками — возникает и используется.
В качестве самодостаточного работоспособного решения я такого нигде не видел и даже не слышал.lair
30.05.2018 22:33В качестве самодостаточного работоспособного решения я такого нигде не видел и даже не слышал.
Вы-то не видели, а я на рубеже века разработал систему со схожим механизмом хранения и успешно ее внедрил как минимум дважды.
UltimaSol Автор
30.05.2018 22:52Т.е. вы пробовали EAV и отчаялись еще на рубеже века, пару раз внедрив. Ваш негатив понятен.
Моё первое внедрение этой системы состоялось в 2006 году, и она там до сих пор работает.
stychos
31.05.2018 21:28Для одной логистической конторки такой же костыль лепил лет пятнадцать назад. И не подумал бы что изобретаю что-то выдающееся, и в упор не знал (да и не знаю) о буковках EAV =)
TischenkoSergey
01.06.2018 19:53>Спасибо, коллега! Вы первый комментатор, кто вдумался о чем речь.
Удивительно то, что читателям приходится гадать, что именно автор статьи имел ввиду. Тут естественно кто-то угадает, кто то нет…
Не умаляю Ваши заслуги в исследовании паттерна EAV (именно он и лежит в основе вашего патента), но такая болезненная реакция на совершенно адекватные вопросы читателей тоже немного удивляет.
lair
30.05.2018 22:32Автор изобрёл не EAV и не ORM, а дерево типов, а также способ уложить его в таблицу.
Может вы нам можете объяснить, чем показанная в комментариях выше структура хранения данных для конкретного объекта отличается от EAV?
UltimaSol Автор
30.05.2018 22:56Да бог с вами, назовите это EAV, если вам так лучше.
EAV и Интеграл ничем не отличается в плане хранения всех атрибутов в одной таблице.
В EAV, наверное, тоже есть встроенный редактор типов, там можно работать с миллионами записей, произвольно создавать структуры данных, писать запросы, которые реализуют любые конструкции SQL и всё такое.
Да EAV, чё…lair
30.05.2018 23:00там [в EAV] можно работать с миллионами записей, произвольно создавать структуры данных, писать запросы, которые реализуют любые конструкции SQL и всё такое.
Можно, конечно.
Ну а встроенный редактор типов — это, извините, как ваша "экосистема": "учитывая простоту архитектуры, адаптация этих средств под конкретный проект сопоставима с написанием их с нуля". В том смысле, что если кто-то построил (как я в свое время) фреймворк на базе EAV, то редактор типов там был второй реализованной задачей (и она тривиальна).
Да EAV, чё…
Да я же не против, я искренне спрашиваю "в чем отличия", только пока что-то никто не рассказывает.
eugenero
30.05.2018 23:04Более высокий уровень абстракции — как множества vs категории. Это красиво и, время от времени, идеологически необходимо.
lair
30.05.2018 23:11+1А более конкретно? Я выше уже приводил пример:
Parent | Type | Value 220 | 218 | 1923 220 | 223 | 670
(это реальная структура хранения от автора статьи)
Каким образом это более высокий уровень абстракции, чем EAV? Тем, что названия поменяли? Ну так с точки зрения имплементации ничего не поменялось. Тем, что можно хранить произвольной глубины иерархию для объекта? Так там нет оптимизации для выборки объектов произвольной глубины.
eugenero
30.05.2018 23:34Так я тоже удивлён этим, так сказать, нахальством. Теперь автор может тролльнуть на поле патентного права лично вас, например, раз вы уже признались в нелицензированном использовании запатентованной технологии. Дважды.
lair
30.05.2018 23:36Лично меня вряд ли может, потому что в этом клубе джентельменам на слово не верят.
roscomtheend
31.05.2018 14:24И лишиться патентов, которые получены минимум на 20 лет позже разработанного? Новизны-то в них не окажется.
AlexTest
31.05.2018 06:09там нет оптимизации для выборки объектов произвольной глубины
Уверен что UltimaSol даже не представляет как это его «изобретение» будет жрать как не в себя ресурсы и жутко тормозить на т.н. рекурсивных запросах к этой единственной таблице если таких объектов произвольной глубины будет в ней достаточно много. Думаю уже ста тысяч хватит чтобы все просто умерло даже на самом крутом железе.UltimaSol Автор
31.05.2018 13:09Вполне представляю и могу вам показать — см. комментарий выше.
Статистика взята из сервиса, где одновременно работают от 15 до 30 человек, в работе у них больше 50 тысяч кандидатов.
Сервер самый простой: стоимость менее 25$ в год, 1 ядро @2.5MHz, RAM 1Gb.AlexTest
31.05.2018 14:43Вы хоть понимаете о чем речь?
Где в этом сервисе объекты произвольной глубины?
Как вы их ищете по атрибуту, который может быть на ЛЮБОМ уровне в ЛЮБОЙ ветке дерева данных такого объекта?
Как вы в конце концов извлекаете и собираете такие объекты, где чтения данных КАЖДОГО уровня КАЖДОЙ ветки требуется ОТДЕЛЬНЫЙ запрос к БД?UltimaSol Автор
31.05.2018 20:38Вы хоть понимаете о чем речь?
Где в этом сервисе объекты произвольной глубины?
Немного понимаю. Вот, ниже структура таблиц, как она видна программисту в этом сервисе:

Это фрагмент того, что относится к основным моментам бизнеса в приложении, для которого я привел здесь статистику.
Глубина структуры может быть какой угодно, это ограничено только объемом, предоставленным железом, и на быстродействие не влияет сколько-нибудь существенно.
Как вы их ищете по атрибуту, который может быть на ЛЮБОМ уровне в ЛЮБОЙ ветке дерева данных такого объекта?
Как вы в конце концов извлекаете и собираете такие объекты, где чтения данных КАЖДОГО уровня КАЖДОЙ ветки требуется ОТДЕЛЬНЫЙ запрос к БД?
Так и ищу, по коду типа. Индекс выводит меня прямо к нужному листу нужной ветки, не пробегаясь по всему дереву. Без отдельных запросов, одним единственным.
lair
31.05.2018 22:04Вот, ниже структура таблиц, как она видна программисту в этом сервисе:
Я что-то в этой структуре глубины больше двух-то и не вижу.
Так и ищу, по коду типа. Индекс выводит меня прямо к нужному листу нужной ветки, не пробегаясь по всему дереву.
Дадада, вот только теперь как от этого листа в один запрос попасть к соответствующему началу дерева?
Грубо говоря, представьте себе, что у вас есть "авторы", у них есть вложенные сущности "книги" (да, в рамках этой задачи у каждой книги есть только один автор, и книги без авторов не бывает; "вложенная" — это когда parent этой сущности — это другая сущность), у "книги" есть вложенная сущность "глава", у "главы" — "страница", у "страницы" — "абзац", а вот в "абзацах" бывают "термины". Вот получили в в один запрос нужный "термин" — а теперь можете ли вы в один запрос сказать, у какого автора он встретился? А если задачу немного — совсем немного — усложнить, и сказать, что под "книгой" бывают "разделы", а под "разделами" — другие "разделы", и так до бесконечности, а вот уже в "разделах" — "термины"?
UltimaSol Автор
31.05.2018 22:11В любой СУБД вам придется сделать столько JOIN, сколько уровней от автора до нужной вам сущности. Точно такой же запрос с тем же количеством JOIN'ов будет выполнен и в этой архитектуре — один запрос.
lair
31.05.2018 22:13В любой СУБД вам придется сделать столько JOIN, сколько уровней от автора до нужной вам сущности.
Эээ, конечно же, нет. Если система заточена под иерархии (как видно из вашего ответа, ваша — не заточена), то будет не больше одного JOIN.
Точно такой же запрос с тем же количеством JOIN'ов будет выполнен и в этой архитектуре — один запрос.
… так что же делать, если количество уровней неизвестно?
UltimaSol Автор
31.05.2018 22:16Вы о чем сейчас? Приведите пример, пожалуйста.
Это решение эмулирует РСУБД и её возможности.lair
31.05.2018 22:18Я сейчас о способах хранения древовидных структур в БД — которых даже для РСУБД не меньше трех (а еще ведь есть нереляционные БД).
Собственно, все, что я хотел увидеть — это то, что на хранение именно древовидных структур ваша система тоже не заточена.
UltimaSol Автор
31.05.2018 22:40В данном случае нет цели хранения древовидных структур, хотя это тоже можно эмулировать, если будет задача.
Повторюсь в очередной раз, система решает задачу РСУБД в общем, без экзотики и спецнаправлений.lair
31.05.2018 22:42В данном случае нет цели хранения древовидных структур
Вот, собственно, и ответ на "автор изобрёл [...] дерево типов". Что и требовалось доказать.
Повторюсь в очередной раз, система решает задачу РСУБД в общем
Эм, зачем решать задачу РСУБД, если есть РСУБД?
без экзотики и спецнаправлений.
Древовидные структуры — это нифига не экзотика.
michael_vostrikov
01.06.2018 06:04Вот, ниже структура таблиц, как она видна программисту в этом сервисе
Подскажите, какой запрос (на SQL) летит в базу, если мы хотим найти все вакансии, на которые откликнулись кандидаты с фамилией "Иванов", и вывести город, зарплату от/до, и работодателя вакансий. С разделением по страницам, естественно.
UltimaSol Автор
01.06.2018 21:05Примерно такой запрос, как ниже.
Количество записей на странице определяется параметром отчета, номер страницы передается также параметром.
SELECT a330.val v1837447_321,a208.val v1837452_0,a236.val v1837453_208,a260.val v1837454_208,a261.val v1837455_208,a210.val v1837456_0 FROM hr4hr a209 LEFT JOIN (hr4hr r321 JOIN hr4hr a321 ) ON r321.up=a209.id AND a321.id=r321.t AND a321.t=321 LEFT JOIN hr4hr a330 ON a330.up=a321.id AND a330.t=330 LEFT JOIN hr4hr a208 ON a208.t=208 AND a209.up=a208.id LEFT JOIN (hr4hr r236 JOIN hr4hr a236 USE INDEX (PRIMARY)) ON r236.up=a208.id AND a236.id=r236.t AND a236.t=234 LEFT JOIN hr4hr a260 ON a260.up=a208.id AND a260.t=260 LEFT JOIN hr4hr a261 ON a261.up=a208.id AND a261.t=261 LEFT JOIN hr4hr a210 ON a210.t=210 AND a208.up=a210.id WHERE a209.up!=0 AND a209.val!='' AND a209.t=209 AND a330.val ='Иванов' LIMIT 10,20
kahi4
31.05.2018 18:12При всем уважении, даже банальный grep по файлу на 50 тысяч строк для 15, 30, да хоть сотни пользователей, спокойно справится на
самой простоймаломощной машине. Правильно понимаю, что в задаче никаких JOIN хотя бы нет? Вы же понимаете, что с таким объемом у вас раскладные расходы на сеть и подключение к БД выше, чем расходы этой самой базы?UltimaSol Автор
31.05.2018 20:44Правильно понимаю, что в задаче никаких JOIN хотя бы нет? Вы же понимаете, что с таким объемом у вас раскладные расходы на сеть и подключение к БД выше, чем расходы этой самой базы?
JOIN есть для каждого атрибута, поэтому в базу летит один сравнительно короткий запрос на весь набор данных.
UltimaSol Автор
31.05.2018 13:17-1(это реальная структура хранения от автора статьи)
Нет, это обрезанная версия, зачем передергиваете, «джентльмен»?lair
31.05.2018 13:23Я, вроде, нигде и не говорил, что она полная.
А, главное, если опущенные мной фрагменты влияют на классификацию — то вы покажите, как именно.
UltimaSol Автор
02.06.2018 18:45-1Фатально
lair
02.06.2018 18:47Докажите.
UltimaSol Автор
02.06.2018 19:09-1На выкинутые вами поля построены индесы. Они принципиально меняют план запроса к базе.
lair
02.06.2018 19:15(1) у вас есть индекс на поле Order, который "принципиально меняет план запроса к базе"?
(2) выкинутое мное поле ID влияет на план запроса к БД (на самом деле — не всегда), но не на классификацию. Но вообще, конечно, да, для запроса конкретного свойства это поле очень нужно — чтобы добавить в план запроса key lookup и джойн… вы же покрывающие индексы строить отказываетесь, хотя они бы избавили вас от лишней ветки.lair
02.06.2018 19:29вы же покрывающие индексы строить отказываетесь, хотя они бы избавили вас от лишней ветки.
… ну да, так и есть, добавление в индексы
INCLUDEрезко улучшило план запросов (пять index seek, ни одного скана, ни одного key lookup).
lair
01.06.2018 23:47Администратор работает с предельно простой базой данных, в которой задачи кластеризации, зеркалирования, шардирования и подобные решаются также значительно проще
О, кстати, о "решаются проще". Есть, значит, простая задачка: у меня есть книги и есть их содержимое (текст + источник + еще несколько полей). Я хочу, чтобы данные по книгам лежали на SSD, а их содержимое (очевидно, этих данных больше на несколько порядков, но зато они намного реже используются) лежали на HDD. Как это сделать в MS SQL с традиционной схемой, я хорошо знаю и представляю. А как это сделать в вашем решении мечты?
lair
01.06.2018 23:54Все данные физически хранятся в одной таблице из 5 полей: ID, родитель (ID), тип (тоже ID), порядок среди равных (число), значение (набор байтов). У неё есть 3 индекса: ID, тип-значение, родитель-тип.
И еще раз кстати. А как вы решаете ту проблему, что далеко не все значения вообще можно проиндексировать (например, в MS SQL в индекс нельзя включить поля длинее 900 байт, в InnoDB есть аналогичные ограничения)?
lair
02.06.2018 01:32+1… я, значит, не поленился и создал маленькую тестовую БД. Схема тривиальна: авторы-книги, у автора только имя, у книги — автор, название, год и число страниц. 100 тысяч авторов, для каждого автора от 1 до 25 книг. Таблицу из поста воспроизвел как понял на основании описания в посте, комментах и патенте.
Сначала просто статистика по объему: в таблице с авторами — 100k строк, с книгами — ~1.25m строк, в плоской таблице — ~6.5m. По объему, соответственно, 8, 141 и 536 Мб. Если кто-то думает, что место нынче бесплатно, то нет.
Ну а теперь запросы. Начнем с авторов, у которых в имени есть
5300:select Name from Authors where Name like '%5300%'. 20 записей, никаких чудес, index scan (индекс по имени автора, конечно же, есть, но толку от него здесь пренебрежимо мало). CPU time = 234 ms, elapsed time = 242 ms. Добавим идентификатор:`select Id, Name...: время не изменилось, план выполнения не изменился. Пока все предсказуемо.
Теперь все то же самое на плоской таблице:
select Value from Flat where Value like '%5300%' and Type = 705712. В плане выполнения — index seek с критерием по типу, число прочтенных строк (как и выше) — 100k. Время выполнения тоже не отличается. Добавим идентификатор:select ParentId, Value.... Время выполнения подросло: CPU time = 219 ms, elapsed time = 314 ms, в плане выполнения появился key lookup и join (еще бы, никто же не озаботился покрывающим индексом на ParentId), но пока еще терпимо — неудивительно, все на SSD, памяти много, ресурсов хватает всем и на всё.
Ладно, давайте посмотрим на книги этих авторов.
select Authors.Id, Authors.Name, Books.Id, Books.Name, Books.Pages, Books.Year from Authors inner join Books on Authors.Id = Books.AuthorId where Authors.Name like '%5300%'
308 строк, CPU time = 218 ms, elapsed time = 765 ms, в плане выполнения — index scan (авторы), index seek (книги по авторам) и key lookup (сами книги). Все предсказуемо, как топор.
А теперь...
select AuthorName.ParentId, AuthorName.Value, BookAuthorId.ParentId, BookName.Value, BookYear.Value, BookPages.Value from Flat AuthorName inner join Flat BookAuthorId on BookAuthorId.Type = 705715 and BookAuthorId.Value = AuthorName.ParentId inner join Flat BookName on BookName.Type = 705717 and BookName.ParentId = BookAuthorId.ParentId inner join Flat BookYear on BookYear.Type = 705719 and BookYear.ParentId = BookAuthorId.ParentId inner join Flat BookPages on BookPages.Type = 705721 and BookPages.ParentId = BookAuthorId.ParentId where AuthorName.Type = 705712 and AuthorName.Value like '%5300%'
308 строк на выходе. CPU time = 1641 ms, elapsed time = 2117 ms. В плане выполнения — два полных скана таблицы и три пары index seek/key lookup (ну и соответствующее количество джойнов). И это у нас всего шесть полей в выводе.
Снижение риска деградации производительности, говорили они...
UltimaSol Автор
02.06.2018 18:40И здесь вы всё переврали, не повторив таблицу из 5 полей с 3 индексами. Но в этот раз ваш косяк виден как на ладони.
Главная вещь, которую стоит уяснить: в при приведенном здесь подходе полный скан таблицы не случится никогда.
Я тоже сделал табличку с 1048552 книгами (сколько влезло на лист экселя) и 142654 авторами.
Книги:

Авторы:

Также я сделал отчет, но не писал SQL, а набрал нужные поля и сразу вписал условие (перебрал их несколько, пока не получил не менее 300 и не более 1000 результатов):

Последнее условие вернуло такой результат — 465 строк с авторами по маске, к которой неприменим индекс:

Все запросы при построении отчета, а их было 6 штук (проверка токена пользователя, поиск отчета, сбор метаданных, выполнение отчета), выполнились за 124.3 мс, из которых 121.3 мс заняло выполнение собственно запроса для отчета.
Сам запрос получился такой:
SELECT a225.val v1_225,a217.val v2_217,a223.val v3_217,a219.val v4_217 FROM test a225 LEFT JOIN (test r217 JOIN test a217 USE INDEX (PRIMARY)) ON r217.up=a217.id AND a225.id=r217.t AND a217.t=217 LEFT JOIN test a223 ON a223.up=a217.id AND a223.t=223 LEFT JOIN test a219 ON a219.up=a217.id AND a219.t=219 WHERE a225.up!=0 AND length(a225.val) AND a225.t=225 AND a225.val LIKE '%aro%'
План его выполнения:

lair
02.06.2018 18:46Но в этот раз ваш косяк виден как на ладони.
Да? И в чем же он конкретно?
Главная вещь, которую стоит уяснить: в при приведенном здесь подходе полный скан таблицы не случится никогда.
Докажите.
michael_vostrikov
02.06.2018 19:31Вы бы лучше дамп базы скинули. Чтобы все могли повторить тесты на тех же данных.

gasizdat
Стесняюсь спросить, так чего в итоге изобрели-то? (Следующий вопрос будет — зачем?)
AlexTest
Человек заново «изобрел» adjacency list model (очевидно не подозревая о ее существовании) прикрутив к ней зачем то еще дополнительное поле типа. Более того он утверждает, что
при этом не объясняя как ему удается сохранять консистентность хранимых данных и не терять ресурсы и производительность на рекурсивных запросах.Я думаю это просто следствие того, что он не знает про limitations of the adjacency list model.
UltimaSol пожалуйста, прежде чем патентовать что-то — прочтите для общего развития хотя бы вот эту простую статью из топа гуглопоиска по данной теме.
Если не можете читать на английском — хабр вам в помощь.
Вон например люди еще в 2012 году в статье и обсуждении размышляли как можно улучшить Adjacency List (что-то вроде ваших типов в отдельной таблице), но им даже в голову не пришло патентовать очевидные вещи!
UltimaSol Автор
Как вы можете рассуждать, не понимая о чем речь?
По одной из ссылок вообще информация из одного из ближайших патентов 1994 года, вы это знали?
Только там кусок решения для частного случая, у меня же — целое, законченное решение.
AlexTest
Последний вопрос к UltimaSol:
Правильно ли я понимаю что вы запатентовали структуру данных?
UltimaSol Автор
Неправильно.
Систему хранения и способ обработки.
lair
А ознакомиться с патентом где-нибудь можно?
UltimaSol Автор
Я же дал здесь ссылку. Вы просто пишете, не читая. Пишите дальше.
lair
Ссылку на патент? В посте я ее не нашел. Вас не затруднит повторить, я надеюсь.
michael_vostrikov
То есть если кто-то сделает аналогичную структуру, только будет хранить значения типов по разным таблицам (отдельно целые числа, отдельно строки, ...), это будет другая система, и он не нарушит патент?
А если кто-то уже сделал структуру данных с аналогичными столбцами, только в разных таблицах, или с дополнительными столбцами, это другая система или ваш патент недействительный?
UltimaSol Автор
С точки зрения патентного права, оба случая закрыты этим патентом.
Хотя это всё вообще не важно.
michael_vostrikov
В таком случае, с точки зрения патентного права ваш патент недействительный. Так как подобные структуры базы данных существовали и до него.

Magento EAV
Обратите внимание на названия полей.
Я правда не разбираюсь в патентах, но в обратном случае в существовании патентов не было бы смысла.
UltimaSol Автор
Дело не в незнании вами патентных тонкостей, а в небрежном отношении к материалу. Вы приводите часть некоей структуры, которую никак нельзя трансформировать в мою обратимыми преобразованиями (перестановка полей, транспонирование таблиц, декомпозиция и объединение и т.д.).
То есть, то, что вы привели, вообще никакого отношения не имеет к обсуждаемой здесь статье.
michael_vostrikov
То есть вы, как разработчик программы, защищенной патентом, согласны, что никакие функционально эквивалентные вариации указанной на рисунке схемы не являются нарушением вашего патента?
Я спрашиваю серьезно, потому что это патент, и я не хотел бы, чтобы из-за вашей некомпетентности или некомпетентности сотрудника патентной организации в области информационных технологий у меня появились проблемы в работе.
lair
Насколько я понимаю, достаточно не хранить "корневой элемент" и "строки, отображающие тип данных" — и формула изобретения будет другой. Впрочем, я ничего не понимаю в патентном праве.
Другое дело, что если кто-то на основании этого патента попробует опротестовать новосозданные EAV, немедленно случится встречный иск на более раннее изобретение.
Вообще, конечно, этот патент — это прекрасная иллюстрация к тезису "запатентовать можно что угодно". Особенно жгут "фиг. 8" и следующее к ней обоснование: