Каждый из нас делает рутинную работу. Каждый пишет boilerplate код. Зачем? Не лучше ли автоматизировать данный процесс и работать только над интересными задачами? Читай эту статью, если хочешь, чтобы такую работу за тебя делал комп.

Данная статья написана на основе расшифровки доклада Зака Свирса (Zack Sweers), разработчика мобильных приложений Uber, с которым он выступил на конференции MBLT DEV в 2017 году.
В Uber около 300 разработчиков мобильных приложений. Я работаю в команде, которая называется «mobile platform». Работа моей команды заключается в том, чтобы максимально упростить и улучшить процесс разработки мобильных приложений. В основном мы работаем над внутренними фреймворками, библиотеками, архитектурами и так далее. Из-за большого штата нам приходится делать масштабные проекты, которые понадобятся нашим инженерам в будущем. Это может быть завтра, а может быть в следующем месяце или даже году.
Мне хотелось бы продемонстрировать ценность процесса кодогенерации, а также рассмотреть несколько практических примеров. Сам процесс выглядит примерно так:
Это пример использования Kotlin Poet. Kotlin Poet — библиотека с хорошим API, которая генерирует Kotlin-код. Итак, что же мы здесь видим?
После кодогенерации получается следующее:
Результат кодогенерации — файл с названием, комментарием, аннотацией и именем автора. Сразу возникает вопрос: «Зачем мне нужно генерировать этот код, если я могу сделать это в пару простых действий?» Да, вы правы, но что, если мне нужна тысяча таких файлов с различными вариантами конфигураций? Что произойдёт, если мы начнём изменять значения в этом коде? Что, если у нас есть множество презентаций? Что, если нам предстоит множество конференций?
В итоге мы придём к тому, что поддерживать такое количество файлов вручную станет просто невозможно — необходимо автоматизировать. Поэтому первое преимущество кодогенерации — избавление от рутинной работы.
Второе важное преимущество автоматизации — безошибочность. Все люди допускают ошибки. Особенно часто это происходит, когда мы делаем одно и то же. Компьютеры же, наоборот, такую работу выполняют прекрасно.
Рассмотрим простой пример. Есть класс Person:
Допустим, мы хотим добавить к нему сериализацию в JSON. Делать это будем с помощью библиотеки Moshi, так как она достаточно проста и отлично подходит для демонстрации. Создаём PersonJsonAdapter и наследуемся от JsonAdapter с параметром типа Person:
Далее реализуем метод fromJson. Он предоставляет reader для считывания информации, которая в конце будет возвращена в Person. Затем заполняем поля с именем и фамилией и получаем новое значение Person:
Далее смотрим данные в формате JSON, проверяем их и заносим в нужные поля:
Это сработает? Да, но есть нюанс: внутри JSON должны содержаться объекты, которые мы считываем. Для того, чтобы фильтровать лишние данные, которые могут прийти от сервера, добавим ещё одну строчку кода:
На этом моменте мы успешно обходим область рутинного кода. В этом примере только два поля значения. Однако, в этом коде есть куча различных участков, на которых у вас внезапно может возникнуть сбой. Вдруг мы допустили ошибку в коде?
Рассмотрим другой пример:
Если у вас возникает хотя бы одна проблема через каждые 10 моделей или около того, то это значит, что на этом участке у вас обязательно возникнут сложности. И это тот случай, когда кодогенерация действительно может прийти вам на помощь. Если классов много, без автоматизации работать не получится, потому что опечатки допускают все люди. С помощью кодогенерации все задачи будут выполнены автоматически и без ошибок.
У кодогенерации есть и другие преимущества. Например, она выдаёт информацию о коде или подсказывает, если что-то идёт не так. Кодогенерация будет полезна на стадии тестирования. Если вы используете генерируемый код, то сможете увидеть, как действительно будет выглядеть рабочий код. Вы даже можете запускать кодогенерацию во время тестов, чтобы упростить себе работу.
Вывод: стоит рассмотреть кодогенерацию в качестве возможного решения для избавления от ошибок.
Теперь рассмотрим программные инструменты, которые помогают с кодогенерацией.
Для сборки кода есть два основных инструмента:
Теперь рассмотрим несколько примеров.
Butter Knife – это библиотека, которую разработал Jake Wharton. Он является достаточно известной фигурой в сообществе разработчиков. Библиотека очень популярна среди Android-разработчиков, потому что она помогает избежать большого количества рутинной работы, с которой сталкивается практически каждый.
Обычно мы инициализируем view таким образом:
С помощью Butterknife это будет выглядеть так:
И мы легко сможем добавлять любое количество view, при этом метод onCreate не будет обрастать boilerplate кодом:
Вместо того, чтобы каждый раз вручную делать эту привязку, вы попросту добавляете в эти поля аннотации @BindView, а также идентификаторы (ID), за которыми они закреплены.
В Butter Knife классно то, что она проанализирует код и сгенерирует вам все его аналогичные участки. Она также имеет прекрасную масштабируемость для новых данных. Поэтому если появляются новые данные, нет необходимости снова применять onCreate или отслеживать что-либо вручную. Эта библиотека также отлично подходит для удаления данных.
Итак, как же выглядит эта система изнутри? Поиск view происходит путём распознавания кода, и этот процесс выполняется на стадии обработки аннотаций.
У нас есть вот такое поле:
Судя по этим данным, они применяются в некой FooActivity:
У неё имеется свое значение (R.id.title), которое выступает в роли целевого объекта. Обратите внимание, что во время обработки данных этот объект становится постоянным значением внутри системы:
Это нормально. Это то, к чему Butter Knife должна иметь доступ в любом случае. В качестве типа имеется компонент TextView. Само поле называется title. Если мы, например, сделаем из этих данных класс-контейнер, то получится что-то вроде этого:
Итак, все эти данные можно без труда получить во время их обработки. Это также очень похоже на то, чем занимается Butter Knife внутри системы.
В результате у нас генерируется вот такой класс:
Здесь мы видим, что все эти кусочки данных собираются воедино. В итоге, мы имеем целевой класс ViewBinding из java-библиотеки Underscore. Внутри, эта система устроена таким образом, что каждый раз при создании экземпляра класса, она тут же выполняет всю эту привязку к той информации (коду), который вы сгенерировали. И всё это предварительно статически генерируется во время обработки аннотаций, а значит, это технически правильно.
Вернёмся к нашему программному конвейеру:
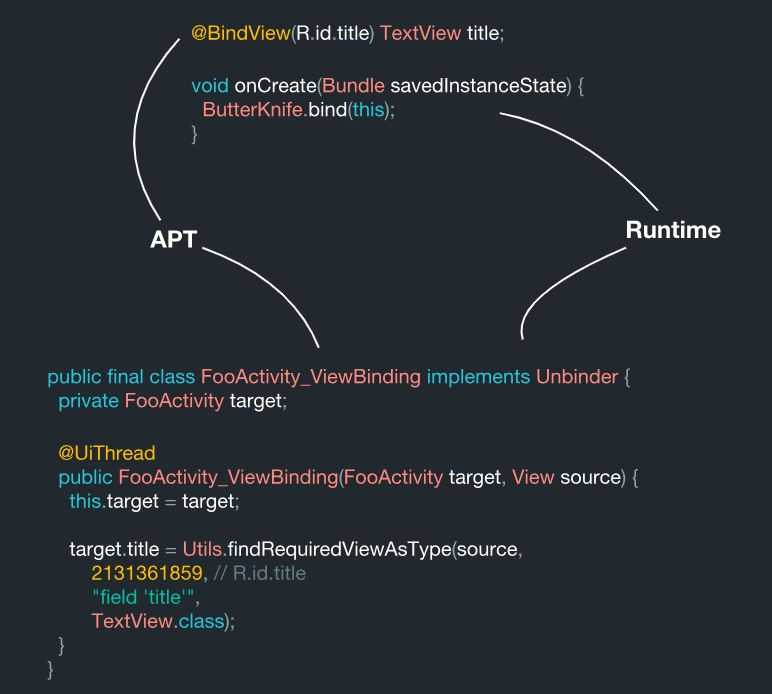
Во время обработки аннотации система считывает эти аннотации и генерируется класс ViewBinding. А затем во время выполнения метода bind мы производим идентичный поиск одного и того же класса простым способом: мы берём его название и дописываем ViewBinding в конце. Сам по себе участок с ViewBinding в процессе обработки переписывается в указанную область при помощи JavaPoet.
Сама по себе RxBindings не отвечает за кодогенерацию. Она не занимается обработкой аннотаций и не является плагином Gradle. Это обычная библиотека. Она предоставляет статические фабрики, основанные на принципе реактивного программирования для Android API. Это значит, что, например, если у вас есть setOnClickListener, то появится метод для клика, который будет возвращать поток(Observable) событий. Он выступает в роли моста (шаблон проектирования).
Но на самом деле в RxBinding есть кодогенерация:
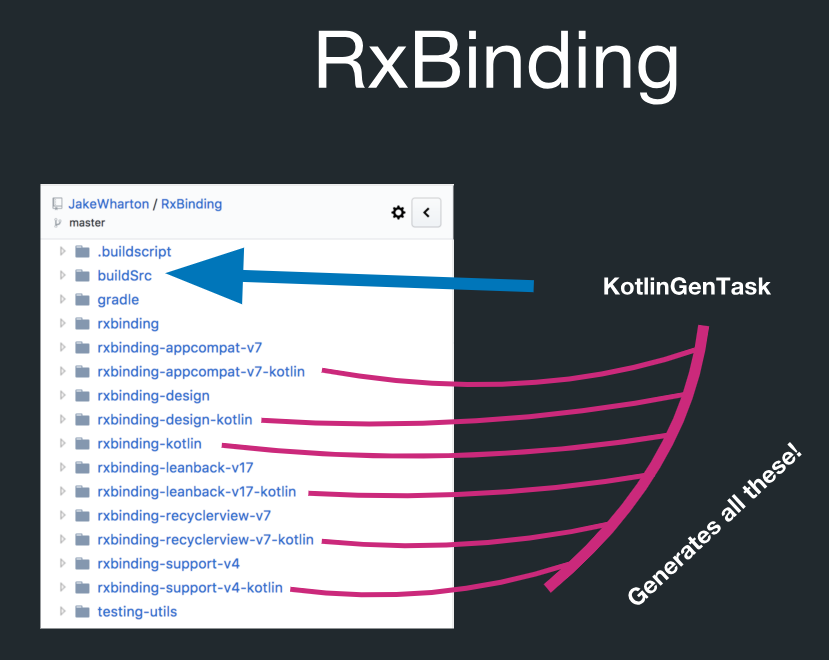
В этой директории под названием buildSrc есть задача Gradle, которая называется KotlinGenTask. Это означает, что всё это на самом деле создается путём кодогенерации. RxBinding имеет реализации на Java. У неё также есть артефакты Kotlin, которые содержат функции-расширения для всех целевых типов. И всё это очень жёстко подчиняется правилам. Например, вы можете сгенерировать все функции-расширения Kotlin, и вам не придётся контролировать их по отдельности.
Как это выглядит на самом деле?
Перед вами вполне классический метод RxBinding. Здесь возвращаются Observable объектов. Метод называется clicks. Работа с click-событиями происходит «под капотом». Опустим лишние фрагменты кода для сохранения читабельности примера. В Kotlin это выглядит следующим образом:
Эта extension-функция возвращает Observable объектов. Во внутренней структуре программы она напрямую вызывает привычный для нас Java-интерфейс. В Kotlin придётся поменять это на тип Unit:
То есть в Java это выглядит так:
А так — Kotlin-код:
У нас есть класс RxView, в котором содержится данный метод. Мы можем подставить соответствующие фрагменты данных в атрибут target, в атрибут name с названием метода и в тип, который мы расширяем, а также в тип возвращаемого значения. Всей этой информации будет достаточно, чтобы приступить к написанию этих методов:
Теперь мы сможем напрямую подставить эти фрагменты в сгенерированный код на Kotlin внутри программы. Вот что получится в итоге:
Над Service Gen мы работаем в Uber. Если вы работаете в компании и имеете дело с общими характеристиками и общим программным интерфейсом как для бэкенда, так и для и клиентской стороны, то вне зависимости от того, разрабатываете ли вы Android, iOS или веб-приложения, нет смысла вручную создавать модели и сервисы для работы команды.
Мы используем библиотеку AutoValue от Google для моделей объектов. Она обрабатывает аннотации, анализирует данные и генерирует хеш-код из двух строк, метод equals() и другие реализации. Она также отвечает за поддержку расширений.
У нас имеется объект типа Rider:
У нас есть строки с ID, firstname, lastname и address. Для работы с сетью мы используем библиотеки Retrofit и OkHttp и в качестве формата данных — JSON. Также мы используем RxJava для реактивного программирования. Так выглядит наш сгенерированный API сервис:
Мы можем написать всё это вручную, если нам так захочется. И в течение длительного периода времени мы так и делали. Но на это уходит очень много времени. В итоге — это дорого обходится в плане затрат времени и денег.
Последняя задача моей команды — создать текстовый редактор с нуля. Мы решили больше не писать вручную код, который впоследствии попадает в сеть, поэтому мы используем Thrift. Это что-то вроде языка программирования и протокола одновременно. Uber использует Thrift как язык для технических характеристик.
В Thrift мы определяем API-контракты между бэкендом и клиентской стороной, а затем просто генерируем соответствующий код. Чтобы парсить данные пользуемся библиотекой Thrifty, а для кодогенерации — JavaPoet. В конце генерируем реализации с помощью AutoValue:
Всю работу мы выполняем в JSON. Существует расширение под названием AutoValue Moshi, которое можно добавить в AutoValue-классы при помощи статического jsonAdapter метода:
Thrift помогает и в разработке сервисов:
Нам также приходится вносить сюда некоторые метаданные, чтобы сообщить, какой конечный результат мы хотим достичь:
После кодогенерации мы получим наш сервис:
Но это лишь один из возможных результатов. Одна модель. Как мы знаем из опыта, никто никогда не пользовался только одной моделью. У нас есть множество моделей, которые генерируют код для наших сервисов:
На данный момент у нас есть около 5-6 приложений. И в них множество сервисов. И все проходят через один и тот же программный конвейер. Писать всё это вручную было бы безумием.
В сериализации в JSON “adapter” не нужно регистрировать в Moshi, а если используете JSON — то не нужно регистрировать в JSON. Предлагать сотрудникам проводить десериализацию через переписывание кода через DI-граф — тоже сомнительно.
Но мы работаем с Java, поэтому можем воспользоваться паттерном Factory, который генерируем через библиотеку Fractory. Мы можем это сгенерировать, так как знаем об этих типах, до того, как произошла компиляция. Fractory генерирует адаптер вроде этого:
Сгенерированный код выглядит не очень. Если режет глаз, его можно переписать вручную.
Здесь видны уже упомянутые ранее типы с названиями сервисов. Система автоматически определит, какие адаптеры нужно выбрать, и вызовет их. Но здесь мы сталкиваемся с ещё одной проблемой. У нас есть 6000 таких адаптеров. Даже если разделить их между собой в рамках одного шаблона, модель “Eats” или “Driver” попадёт в модель “Rider” или окажется в его приложении. Код растянется. После определ`нного момента, он не сможет даже поместиться в .dex файл. Поэтому нужно каким-то образом разделить адаптеры:

В конечном итоге, мы проанализируем код заранее и создадим для него рабочий подпроект, как в Gradle:

Во внутренней структуре эти зависимости становятся зависимостями Gradle. Элементы, использующие приложение Rider, теперь зависят от него. С его помощью они будут формировать нужные им модели. В итоге наша задача будет решена, и всё это будет регулироваться системой сборки кода внутри программы.
Но здесь мы сталкиваемся с ещё одной проблемой: теперь у нас n-количество моделей фабрик. Все они компилируются в различные объекты:
В процессе обработки аннотаций не получится считывать только аннотации к внешним зависимостям и делать дополнительную кодогенерацию только по ним.
Решение: у нас есть некоторая поддержка в библиотеке Fractory, которая помогает нам одним хитрым приёмом. Он содержится в процессе связывания данных. Вводим метаданные при помощи параметра classpath в Java-архив для их дальнейшего хранения:
Теперь каждый раз, когда нужно задействовать их в приложении, заходим в фильтр директории classpath с этими файлами, а затем извлекаем их оттуда в формате JSON, чтобы узнать, какие из зависимостей доступны.
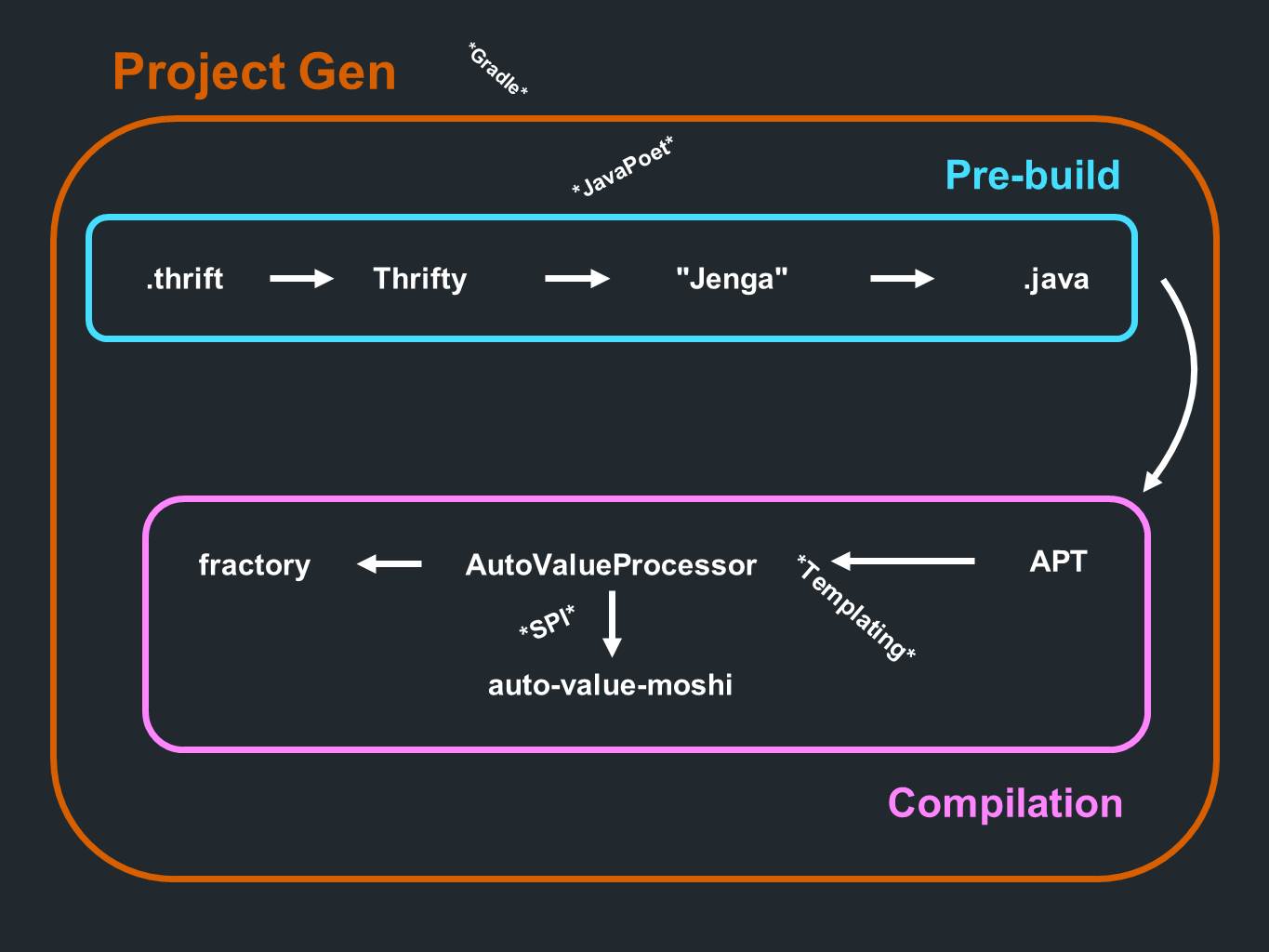
У нас есть Thrift. Данные оттуда поступают в Thrifty и проходят парсинг. Далее они проходят через программу для кодогенерации, которую мы называем Jenga. Она выдаёт файлы в формате Java. Всё это происходит ещё до предварительной стадии обработки или до компиляции. А во время процесса компиляции происходит обработка аннотаций. Наступает очередь AutoValue генерировать реализацию. Он также вызывает AutoValue Moshi для обеспечения JSON-поддержки. В этом участвует и Fractory. Всё происходит во время процесса компиляции. Процессу предшествует компонент создания самого проекта, который, в первую очередь, генерирует подпроекты Gradle.
Теперь, когда вы видите полную картину, вы начинаете замечать инструменты, которые упоминались ранее. Так, например, здесь есть Gradle, создание шаблонов, AutoValue, JavaPoet для кодогенерации. Все инструменты не только полезны сами по себе, но и в сочетании друг с другом.
Нужно рассказать и о подводных камнях. Самый очевидный минус — раздувание кода и потеря контроля над ним. Например, Dagger занимает примерно 10% от всего кода в приложении. Модели занимают значительно большую долю — около 25%.
В Uber мы пытаемся решить проблему, выбрасывая ненужный код. Нам предстоит провести некий статистический анализ кода и понять, какие участки действительно задействованы в работе. Когда выясним это, сможем произвести некие преобразования и посмотреть, что из этого выйдет.
Мы рассчитываем сократить количество генерируемых моделей примерно на 40%. Это поможет ускорить установку и работу приложений, а также сэкономить нам деньги.
Кодогенерация, безусловно, ускоряет разработку, но сроки зависят и от инструментов, которые использует команда. Например, если вы работаете в Gradle, скорее всего, вы это делаете в размеренном темпе. Дело в том, что Gradle генерирует модели один раз в день, а не тогда, когда хочет разработчик.
28 сентября в Москве стартует 5-я Международная конференция мобильных разработчиков MBLT DEV. 800 участников, топовые спикеры, квизы и задачки для тех, кому интересная разработка для Android и iOS.
Организаторы конференции — e-Legion и РАЭК. Стать участником или партнёром MBLT DEV 2018 можно на сайте конференции.
Данная статья написана на основе расшифровки доклада Зака Свирса (Zack Sweers), разработчика мобильных приложений Uber, с которым он выступил на конференции MBLT DEV в 2017 году.
В Uber около 300 разработчиков мобильных приложений. Я работаю в команде, которая называется «mobile platform». Работа моей команды заключается в том, чтобы максимально упростить и улучшить процесс разработки мобильных приложений. В основном мы работаем над внутренними фреймворками, библиотеками, архитектурами и так далее. Из-за большого штата нам приходится делать масштабные проекты, которые понадобятся нашим инженерам в будущем. Это может быть завтра, а может быть в следующем месяце или даже году.
Кодогенерация для автоматизации
Мне хотелось бы продемонстрировать ценность процесса кодогенерации, а также рассмотреть несколько практических примеров. Сам процесс выглядит примерно так:
FileSpec.builder("", "Presentation")
.addComment("Code generating your way to happiness.")
.addAnnotation(AnnotationSpec.builder(Author::class)
.addMember("name", "%S", "Zac Sweers")
.useSiteTarget(FILE)
.build())
.build()
Это пример использования Kotlin Poet. Kotlin Poet — библиотека с хорошим API, которая генерирует Kotlin-код. Итак, что же мы здесь видим?
- FileSpec.builder создаёт файл с именем “Presentation”.
- .addComment() — добавляет комментарий в сгенерированный код.
- .addAnnotation() — добавляет аннотацию с типом Author.
- .addMember() — добавляет переменную “name” с параметром, в нашем случае это “Zac Sweers”. %S — тип параметра.
- .useSiteTarget() — устанавливает SiteTarget.
- .build() — завершает описание кода, который будет генерироваться.
После кодогенерации получается следующее:
Presentation.kt
// Code generating your way to happiness.
@file:Author(name = "Zac Sweers")Результат кодогенерации — файл с названием, комментарием, аннотацией и именем автора. Сразу возникает вопрос: «Зачем мне нужно генерировать этот код, если я могу сделать это в пару простых действий?» Да, вы правы, но что, если мне нужна тысяча таких файлов с различными вариантами конфигураций? Что произойдёт, если мы начнём изменять значения в этом коде? Что, если у нас есть множество презентаций? Что, если нам предстоит множество конференций?
conferences
.flatMap { it.presentations }
.onEach { (presentationName, comment, author) ->
FileSpec.builder("", presentationName)
.addComment(comment)
.addAnnotation(AnnotationSpec.builder(Author::class)
.addMember("name", "%S", author)
.useSiteTarget(FILE)
.build())
.build()
}
В итоге мы придём к тому, что поддерживать такое количество файлов вручную станет просто невозможно — необходимо автоматизировать. Поэтому первое преимущество кодогенерации — избавление от рутинной работы.
Кодогенерация без ошибок
Второе важное преимущество автоматизации — безошибочность. Все люди допускают ошибки. Особенно часто это происходит, когда мы делаем одно и то же. Компьютеры же, наоборот, такую работу выполняют прекрасно.
Рассмотрим простой пример. Есть класс Person:
class Person(val firstName: String, val lastName: String)
Допустим, мы хотим добавить к нему сериализацию в JSON. Делать это будем с помощью библиотеки Moshi, так как она достаточно проста и отлично подходит для демонстрации. Создаём PersonJsonAdapter и наследуемся от JsonAdapter с параметром типа Person:
class Person(val firstName: String, val lastName: String)
class PersonJsonAdapter : JsonAdapter<Person>() {
}
Далее реализуем метод fromJson. Он предоставляет reader для считывания информации, которая в конце будет возвращена в Person. Затем заполняем поля с именем и фамилией и получаем новое значение Person:
class Person(val firstName: String, val lastName: String)
class PersonJsonAdapter : JsonAdapter<Person>() {
override fun fromJson(reader: JsonReader): Person? {
lateinit var firstName: String
lateinit var lastName: String
return Person(firstName, lastName)
}
}
Далее смотрим данные в формате JSON, проверяем их и заносим в нужные поля:
class Person(val firstName: String, val lastName: String)
class PersonJsonAdapter : JsonAdapter<Person>() {
override fun fromJson(reader: JsonReader): Person? {
lateinit var firstName: String
lateinit var lastName: String
while (reader.hasNext()) {
when (reader.nextName()) {
"firstName" -> firstName = reader.nextString()
"lastName" -> lastName = reader.nextString()
}
}
return Person(firstName, lastName)
}
}
Это сработает? Да, но есть нюанс: внутри JSON должны содержаться объекты, которые мы считываем. Для того, чтобы фильтровать лишние данные, которые могут прийти от сервера, добавим ещё одну строчку кода:
class Person(val firstName: String, val lastName: String)
class PersonJsonAdapter : JsonAdapter<Person>() {
override fun fromJson(reader: JsonReader): Person? {
lateinit var firstName: String
lateinit var lastName: String
while (reader.hasNext()) {
when (reader.nextName()) {
"firstName" -> firstName = reader.nextString()
"lastName" -> lastName = reader.nextString()
else -> reader.skipValue()
}
}
return Person(firstName, lastName)
}
}
На этом моменте мы успешно обходим область рутинного кода. В этом примере только два поля значения. Однако, в этом коде есть куча различных участков, на которых у вас внезапно может возникнуть сбой. Вдруг мы допустили ошибку в коде?
Рассмотрим другой пример:
class Person(val firstName: String, val lastName: String)
class City(val name: String, val country: String)
class Vehicle(val licensePlate: String)
class Restaurant(val type: String, val address: Address)
class Payment(val cardNumber: String, val type: String)
class TipAmount(val value: Double)
class Rating(val numStars: Int)
class Correctness(val confidence: Double)
Если у вас возникает хотя бы одна проблема через каждые 10 моделей или около того, то это значит, что на этом участке у вас обязательно возникнут сложности. И это тот случай, когда кодогенерация действительно может прийти вам на помощь. Если классов много, без автоматизации работать не получится, потому что опечатки допускают все люди. С помощью кодогенерации все задачи будут выполнены автоматически и без ошибок.
У кодогенерации есть и другие преимущества. Например, она выдаёт информацию о коде или подсказывает, если что-то идёт не так. Кодогенерация будет полезна на стадии тестирования. Если вы используете генерируемый код, то сможете увидеть, как действительно будет выглядеть рабочий код. Вы даже можете запускать кодогенерацию во время тестов, чтобы упростить себе работу.
Вывод: стоит рассмотреть кодогенерацию в качестве возможного решения для избавления от ошибок.
Теперь рассмотрим программные инструменты, которые помогают с кодогенерацией.
Инструменты
- Библиотеки JavaPoet и KotlinPoet для Java и Kotlin соответственно. Это эталоны кодогенерации.
- Шаблонизация. Популярный пример шаблонизации для Java — Apache Velocity, а для iOS — Handlebars.
- SPI — Service Processor Interface. Он встроен в Java и позволяет создать и применить интерфейс, а затем объявить его в JAR. Когда программа выполняется, вы можете получить все готовые реализации интерфейса.
- Compile Testing — библиотека от Google, которая помогает проводить тестирование компиляции. В рамках кодогенерации это означает: «Вот то, что я ожидал, а вот то, что я в итоге получил». Запустится компиляция в памяти, а затем система сообщит вам, был ли завершён этот процесс или какие ошибки возникли. Если компиляция была завершена, вам будет предложено сравнить результат с вашими ожиданиями. Сравнение проводится на основе скомпилированного кода, поэтому не стоит беспокоиться о таких вещах, как форматирование кода или о чем-то ещё.
Инструменты для сборки кода
Для сборки кода есть два основных инструмента:
- Annotation Processing (Обработка аннотаций) — вы можете написать аннотации в коде и запросить у программы дополнительную информацию о них. Компилятор выдаст информацию ещё до того, как закончит работать с исходным кодом.
- Gradle — система сборки приложений со множеством хуков (хук — перехват вызова функций) в её жизненном цикле сборки кода. Она широко применяется при разработке на Android. Также она позволяет применить кодогенерацию к исходному коду, который не зависит от текущих исходников.
Теперь рассмотрим несколько примеров.
Butter Knife
Butter Knife – это библиотека, которую разработал Jake Wharton. Он является достаточно известной фигурой в сообществе разработчиков. Библиотека очень популярна среди Android-разработчиков, потому что она помогает избежать большого количества рутинной работы, с которой сталкивается практически каждый.
Обычно мы инициализируем view таким образом:
TextView title;
ImageView icon;
void onCreate(Bundle savedInstanceState) {
title = findViewById(R.id.title);
icon = findViewById(R.id.icon);
}
С помощью Butterknife это будет выглядеть так:
@BindView(R.id.title) TextView title;
@BindView(R.id.icon) ImageView icon;
void onCreate(Bundle savedInstanceState) {
ButterKnife.bind(this);
}
И мы легко сможем добавлять любое количество view, при этом метод onCreate не будет обрастать boilerplate кодом:
@BindView(R.id.title) TextView title;
@BindView(R.id.text) TextView text;
@BindView(R.id.icon) ImageView icon;
@BindView(R.id.button) Button button;
@BindView(R.id.next) Button next;
@BindView(R.id.back) Button back;
@BindView(R.id.open) Button open;
void onCreate(Bundle savedInstanceState) {
ButterKnife.bind(this);
}
Вместо того, чтобы каждый раз вручную делать эту привязку, вы попросту добавляете в эти поля аннотации @BindView, а также идентификаторы (ID), за которыми они закреплены.
В Butter Knife классно то, что она проанализирует код и сгенерирует вам все его аналогичные участки. Она также имеет прекрасную масштабируемость для новых данных. Поэтому если появляются новые данные, нет необходимости снова применять onCreate или отслеживать что-либо вручную. Эта библиотека также отлично подходит для удаления данных.
Итак, как же выглядит эта система изнутри? Поиск view происходит путём распознавания кода, и этот процесс выполняется на стадии обработки аннотаций.
У нас есть вот такое поле:
@BindView(R.id.title) TextView title;
Судя по этим данным, они применяются в некой FooActivity:
// FooActivity
@BindView(R.id.title) TextView title;
У неё имеется свое значение (R.id.title), которое выступает в роли целевого объекта. Обратите внимание, что во время обработки данных этот объект становится постоянным значением внутри системы:
// FooActivity
@BindView(2131361859) TextView title;
Это нормально. Это то, к чему Butter Knife должна иметь доступ в любом случае. В качестве типа имеется компонент TextView. Само поле называется title. Если мы, например, сделаем из этих данных класс-контейнер, то получится что-то вроде этого:
ViewBinding(
target = "FooActivity",
id = 2131361859,
name = "title",
type = "field",
viewType = TextView.class
)
Итак, все эти данные можно без труда получить во время их обработки. Это также очень похоже на то, чем занимается Butter Knife внутри системы.
В результате у нас генерируется вот такой класс:
public final class FooActivity_ViewBinding implements Unbinder {
private FooActivity target;
@UiThread
public FooActivity_ViewBinding(FooActivity target, View source) {
this.target = target;
target.title = Utils.findRequiredViewAsType(source,
2131361859, // R.id.title
"field 'title'",
TextView.class);
}
}
Здесь мы видим, что все эти кусочки данных собираются воедино. В итоге, мы имеем целевой класс ViewBinding из java-библиотеки Underscore. Внутри, эта система устроена таким образом, что каждый раз при создании экземпляра класса, она тут же выполняет всю эту привязку к той информации (коду), который вы сгенерировали. И всё это предварительно статически генерируется во время обработки аннотаций, а значит, это технически правильно.
Вернёмся к нашему программному конвейеру:
Во время обработки аннотации система считывает эти аннотации и генерируется класс ViewBinding. А затем во время выполнения метода bind мы производим идентичный поиск одного и того же класса простым способом: мы берём его название и дописываем ViewBinding в конце. Сам по себе участок с ViewBinding в процессе обработки переписывается в указанную область при помощи JavaPoet.
RxBindings
Сама по себе RxBindings не отвечает за кодогенерацию. Она не занимается обработкой аннотаций и не является плагином Gradle. Это обычная библиотека. Она предоставляет статические фабрики, основанные на принципе реактивного программирования для Android API. Это значит, что, например, если у вас есть setOnClickListener, то появится метод для клика, который будет возвращать поток(Observable) событий. Он выступает в роли моста (шаблон проектирования).
Но на самом деле в RxBinding есть кодогенерация:
В этой директории под названием buildSrc есть задача Gradle, которая называется KotlinGenTask. Это означает, что всё это на самом деле создается путём кодогенерации. RxBinding имеет реализации на Java. У неё также есть артефакты Kotlin, которые содержат функции-расширения для всех целевых типов. И всё это очень жёстко подчиняется правилам. Например, вы можете сгенерировать все функции-расширения Kotlin, и вам не придётся контролировать их по отдельности.
Как это выглядит на самом деле?
public static Observable<Object> clicks(View view) {
return new ViewClickObservable(view);
}
Перед вами вполне классический метод RxBinding. Здесь возвращаются Observable объектов. Метод называется clicks. Работа с click-событиями происходит «под капотом». Опустим лишние фрагменты кода для сохранения читабельности примера. В Kotlin это выглядит следующим образом:
fun View.clicks(): Observable<Object> = RxView.clicks(this)
Эта extension-функция возвращает Observable объектов. Во внутренней структуре программы она напрямую вызывает привычный для нас Java-интерфейс. В Kotlin придётся поменять это на тип Unit:
fun View.clicks(): Observable<Unit> = RxView.clicks(this)
То есть в Java это выглядит так:
public static Observable<Object> clicks(View view) {
return new ViewClickObservable(view);
}
А так — Kotlin-код:
fun View.clicks(): Observable<Unit> = RxView.clicks(this)
У нас есть класс RxView, в котором содержится данный метод. Мы можем подставить соответствующие фрагменты данных в атрибут target, в атрибут name с названием метода и в тип, который мы расширяем, а также в тип возвращаемого значения. Всей этой информации будет достаточно, чтобы приступить к написанию этих методов:
BindingMethod(
target = "RxView",
name = "clicks",
type = View.class,
returnType = "Observable<Unit>"
)
Теперь мы сможем напрямую подставить эти фрагменты в сгенерированный код на Kotlin внутри программы. Вот что получится в итоге:
fun View.clicks(): Observable<Unit> = RxView.clicks(this)
Service Gen
Над Service Gen мы работаем в Uber. Если вы работаете в компании и имеете дело с общими характеристиками и общим программным интерфейсом как для бэкенда, так и для и клиентской стороны, то вне зависимости от того, разрабатываете ли вы Android, iOS или веб-приложения, нет смысла вручную создавать модели и сервисы для работы команды.
Мы используем библиотеку AutoValue от Google для моделей объектов. Она обрабатывает аннотации, анализирует данные и генерирует хеш-код из двух строк, метод equals() и другие реализации. Она также отвечает за поддержку расширений.
У нас имеется объект типа Rider:
@AutoValue
abstract class Rider {
abstract String uuid();
abstract String firstName();
abstract String lastName();
abstract Address address();
}
У нас есть строки с ID, firstname, lastname и address. Для работы с сетью мы используем библиотеки Retrofit и OkHttp и в качестве формата данных — JSON. Также мы используем RxJava для реактивного программирования. Так выглядит наш сгенерированный API сервис:
interface UberService {
@GET("/rider")
Rider getRider()
}
Мы можем написать всё это вручную, если нам так захочется. И в течение длительного периода времени мы так и делали. Но на это уходит очень много времени. В итоге — это дорого обходится в плане затрат времени и денег.
Что и как Uber делает сегодня
Последняя задача моей команды — создать текстовый редактор с нуля. Мы решили больше не писать вручную код, который впоследствии попадает в сеть, поэтому мы используем Thrift. Это что-то вроде языка программирования и протокола одновременно. Uber использует Thrift как язык для технических характеристик.
struct Rider {
1: required string uuid;
2: required string firstName;
3: required string lastName;
4: optional Address address;
}
В Thrift мы определяем API-контракты между бэкендом и клиентской стороной, а затем просто генерируем соответствующий код. Чтобы парсить данные пользуемся библиотекой Thrifty, а для кодогенерации — JavaPoet. В конце генерируем реализации с помощью AutoValue:
@AutoValue
abstract class Rider {
abstract String uuid();
abstract String firstName();
abstract String lastName();
abstract Address address();
}
Всю работу мы выполняем в JSON. Существует расширение под названием AutoValue Moshi, которое можно добавить в AutoValue-классы при помощи статического jsonAdapter метода:
@AutoValue
abstract class Rider {
abstract String uuid();
abstract String firstName();
abstract String lastName();
abstract Address address();
static JsonAdapter<Rider> jsonAdapter(Moshi moshi) {
return new AutoValue_Rider.JsonAdapter(moshi);
}
}Thrift помогает и в разработке сервисов:
service UberService {
Rider getRider()
}
Нам также приходится вносить сюда некоторые метаданные, чтобы сообщить, какой конечный результат мы хотим достичь:
service UberService {
Rider getRider() (path="/rider")
}
После кодогенерации мы получим наш сервис:
interface UberService {
@GET("/rider")
Single<Rider> getRider();
}
Но это лишь один из возможных результатов. Одна модель. Как мы знаем из опыта, никто никогда не пользовался только одной моделью. У нас есть множество моделей, которые генерируют код для наших сервисов:
struct Rider
struct City
struct Vehicle
struct Restaurant
struct Payment
struct TipAmount
struct Rating
// And 6000 more
На данный момент у нас есть около 5-6 приложений. И в них множество сервисов. И все проходят через один и тот же программный конвейер. Писать всё это вручную было бы безумием.
В сериализации в JSON “adapter” не нужно регистрировать в Moshi, а если используете JSON — то не нужно регистрировать в JSON. Предлагать сотрудникам проводить десериализацию через переписывание кода через DI-граф — тоже сомнительно.
Но мы работаем с Java, поэтому можем воспользоваться паттерном Factory, который генерируем через библиотеку Fractory. Мы можем это сгенерировать, так как знаем об этих типах, до того, как произошла компиляция. Fractory генерирует адаптер вроде этого:
class ModelsAdapterFactory implements JsonAdapter.Factory {
@Override
public JsonAdapter<?> create(Type type, Set<? extends Annotation> annotations, Moshi moshi) {
Class<?> rawType = Types.getRawType(type);
if (rawType.isAssignableFrom(Rider.class)) {
return Rider.adapter(moshi);
} else if (rawType.isAssignableFrom(City.class)) {
return City.adapter(moshi);
} else if (rawType.isAssignableFrom(Vehicle.class)) {
return Vehicle.adapter(moshi);
}
// Etc etc
return null;
}
}
Сгенерированный код выглядит не очень. Если режет глаз, его можно переписать вручную.
Здесь видны уже упомянутые ранее типы с названиями сервисов. Система автоматически определит, какие адаптеры нужно выбрать, и вызовет их. Но здесь мы сталкиваемся с ещё одной проблемой. У нас есть 6000 таких адаптеров. Даже если разделить их между собой в рамках одного шаблона, модель “Eats” или “Driver” попадёт в модель “Rider” или окажется в его приложении. Код растянется. После определ`нного момента, он не сможет даже поместиться в .dex файл. Поэтому нужно каким-то образом разделить адаптеры:
В конечном итоге, мы проанализируем код заранее и создадим для него рабочий подпроект, как в Gradle:
Во внутренней структуре эти зависимости становятся зависимостями Gradle. Элементы, использующие приложение Rider, теперь зависят от него. С его помощью они будут формировать нужные им модели. В итоге наша задача будет решена, и всё это будет регулироваться системой сборки кода внутри программы.
Но здесь мы сталкиваемся с ещё одной проблемой: теперь у нас n-количество моделей фабрик. Все они компилируются в различные объекты:
class RiderModelFactory
class GiftCardModelFactory
class PricingModelFactory
class DriverModelFactory
class EATSModelFactory
class PaymentsModelFactory
В процессе обработки аннотаций не получится считывать только аннотации к внешним зависимостям и делать дополнительную кодогенерацию только по ним.
Решение: у нас есть некоторая поддержка в библиотеке Fractory, которая помогает нам одним хитрым приёмом. Он содержится в процессе связывания данных. Вводим метаданные при помощи параметра classpath в Java-архив для их дальнейшего хранения:
class RiderModelFactory
// -> json
// -> ridermodelfactory-fractory.bin
class MyAppGlobalFactory
// Delegates to all discovered fractories
Теперь каждый раз, когда нужно задействовать их в приложении, заходим в фильтр директории classpath с этими файлами, а затем извлекаем их оттуда в формате JSON, чтобы узнать, какие из зависимостей доступны.
Как все сочетается друг с другом
У нас есть Thrift. Данные оттуда поступают в Thrifty и проходят парсинг. Далее они проходят через программу для кодогенерации, которую мы называем Jenga. Она выдаёт файлы в формате Java. Всё это происходит ещё до предварительной стадии обработки или до компиляции. А во время процесса компиляции происходит обработка аннотаций. Наступает очередь AutoValue генерировать реализацию. Он также вызывает AutoValue Moshi для обеспечения JSON-поддержки. В этом участвует и Fractory. Всё происходит во время процесса компиляции. Процессу предшествует компонент создания самого проекта, который, в первую очередь, генерирует подпроекты Gradle.
Теперь, когда вы видите полную картину, вы начинаете замечать инструменты, которые упоминались ранее. Так, например, здесь есть Gradle, создание шаблонов, AutoValue, JavaPoet для кодогенерации. Все инструменты не только полезны сами по себе, но и в сочетании друг с другом.
Минусы кодогенерации
Нужно рассказать и о подводных камнях. Самый очевидный минус — раздувание кода и потеря контроля над ним. Например, Dagger занимает примерно 10% от всего кода в приложении. Модели занимают значительно большую долю — около 25%.
В Uber мы пытаемся решить проблему, выбрасывая ненужный код. Нам предстоит провести некий статистический анализ кода и понять, какие участки действительно задействованы в работе. Когда выясним это, сможем произвести некие преобразования и посмотреть, что из этого выйдет.
Мы рассчитываем сократить количество генерируемых моделей примерно на 40%. Это поможет ускорить установку и работу приложений, а также сэкономить нам деньги.
Как кодогенерация влияет на сроки разработки проекта
Кодогенерация, безусловно, ускоряет разработку, но сроки зависят и от инструментов, которые использует команда. Например, если вы работаете в Gradle, скорее всего, вы это делаете в размеренном темпе. Дело в том, что Gradle генерирует модели один раз в день, а не тогда, когда хочет разработчик.
Узнать больше о разработке в Uber и других топовых компаниях
28 сентября в Москве стартует 5-я Международная конференция мобильных разработчиков MBLT DEV. 800 участников, топовые спикеры, квизы и задачки для тех, кому интересная разработка для Android и iOS.
Организаторы конференции — e-Legion и РАЭК. Стать участником или партнёром MBLT DEV 2018 можно на сайте конференции.
Видеозапись доклада
Комментарии (3)

geisha
09.06.2018 14:12Мы рассчитываем сократить количество генерируемых моделей примерно на 40%. Это поможет ускорить установку и работу приложений, а также сэкономить нам деньги.
Да судя по обилию лагов, сокращать там нужно процентов на 400. Типичный случай когда с помощью велосипедов испоганивают приложение уровня курсовой.
AlexTheLost
Удивляюсь все время, люди не готовы использовать новые/другие языки, где данные проблемы или решены или минимизированы до безобразия, на уровне самого языка. Но готовы использовать странные библиотеки которые помимо минимизации типового кода, несут доп. сложности в отладке и др.)
У кого нибудь есть идеи как это объяснить, кроме консерватизма и других искажений восприятия?
rraderio