
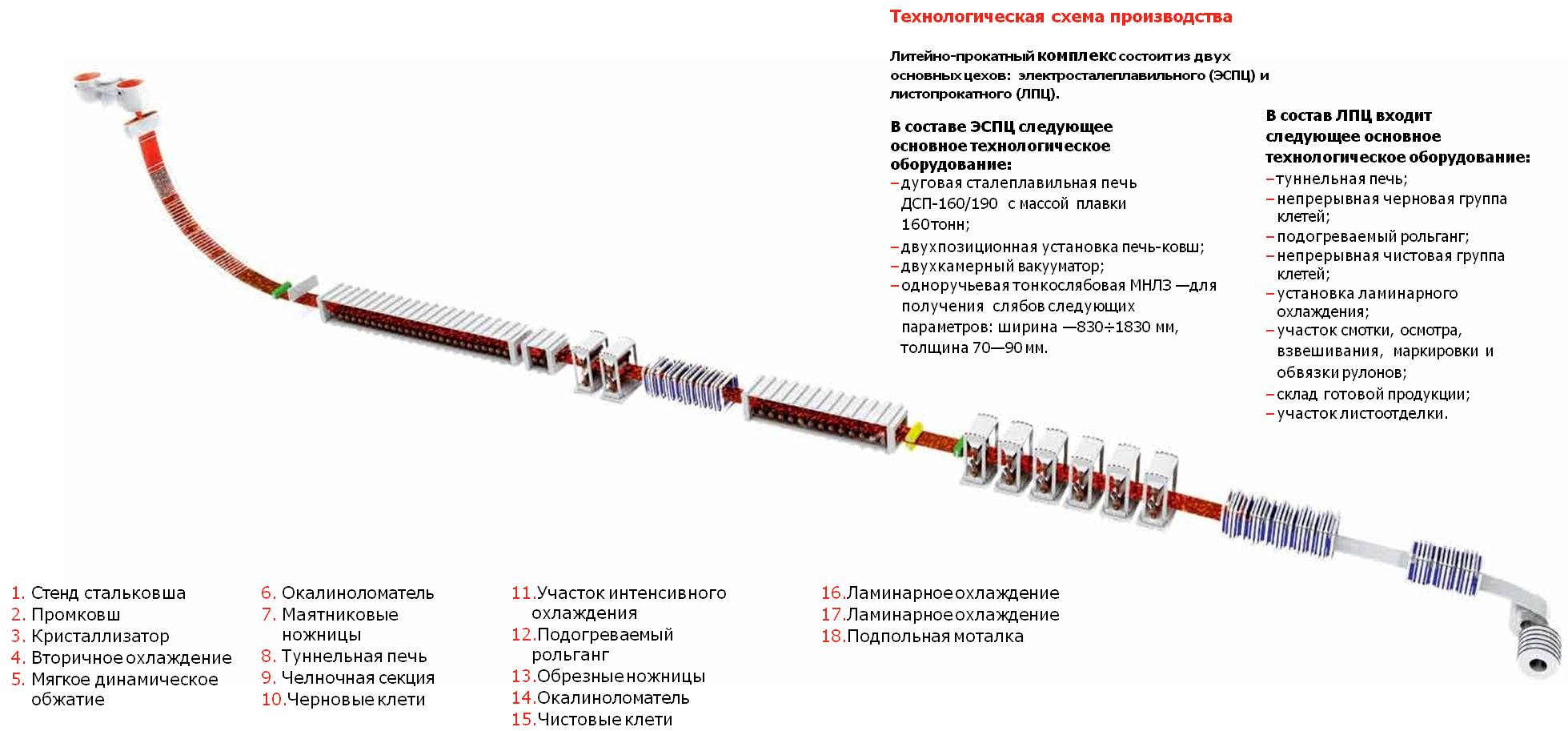
Производственная линия
Одна огромная российская производственная компания куёт сталь, которой знаменита наша страна. Эта сталь идёт на строительство судов и на менее романтичные вещи в промышленности вроде труб. У них установлена современная линия — прокатный стан, комплекс для производства крупнолистового проката.
Линия управляется вендорской коробкой типа «чёрный ящик», которая знает усреднённые значения параметров для в среднем оптимального получения результата. Но все заготовки разные, и некоторые результаты выходят с линии бракованными. Их пытаются править с помощью мужика с болгаркой или отправляют назад в переплавку в зависимости от типа брака.
Самая больная точка — устройство контролируемого охлаждения (один из 14 этапов линии). Мы пришли туда со своей математикой для двух задач:
- Поиска заготовок, которые надо снимать с линии, — с ними при охлаждении в любом случае получится брак.
- Подбора индивидуальных параметров охлаждения под каждую заготовку.
Результат — из тех нескольких процентов брака мы умеем «спасать» 42% заготовок и знаем про заведомый брак (до окончания обработки на линии) на ещё примерно 35% заготовок. Это 10 миллионов рублей на партию.
Что происходит на линии
Первоначально заготовка (обрезанный сляб) загружается в нагревательную печь, где разогревается до температуры порядка 1300 °C. Греется сляб примерно 6 часов. Затем он очищается от окалины гидравлическим сбивом, проходит через клеть с усилием 12 тысяч тонн и установку предварительной правки. Получается лист. Затем в установке контролируемого охлаждения за счёт сверхточных режимов термомеханической обработки раскат приобретает равномерные свойства и микроструктуру по всей длине и ширине листа. После механической правки и участка замедленного охлаждения листы поступают на инспекцию геометрии и в устройство ультразвукового контроля внутренних дефектов. После чего признанные качественными листы подвергаются окончательной резке и сортировке.
Постановка задачи
Лист может быть бракован в следующих случаях:
- Неверные геометрические параметры (что-то пошло не так, и его перекосило).
- Плены (расслоения металла), трещины, пузыри, раковины и прочие дефекты, вызванные газами в нагретом состоянии металла.
Именно минимизация повреждений из-за действия газов в раскалённой заготовке позволяет больше всего повлиять на снижение брака. Редко когда заготовка приходит сразу бракованной — обычно лист повреждается при охлаждении.
На входе у нас есть набор датчиков, который позволяет всесторонне оценить заготовку. На выходе есть данные контроля качества, которые также дают хорошую картину результата.
Гипотеза в том, что, анализируя первое, второе и режимы работы агрегатов, можно выявить закономерности в том, что именно происходит не так. Напомню, линия уже хороша в состоянии от вендора, но автоматика просто использует некую эвристику «так лучше всем листам» без учёта их индивидуального состояния.
Поскольку интеграция всего этого — процесс длительный, специалисты предприятия сказали следующее: если мы сможем предсказывать брак заранее без ложноположительных срабатываний, то этого будет достаточно для того, чтобы доказать им, что дата-майнинг может быть использован на производстве. Честно говоря, они нам не очень-то доверяли поначалу: это абсолютно нормально, что на тяжёлых производствах металлурги считают тех, кто не видел всего этого вживую несколько лет, немного клоунами.
Результаты первого этапа:
— Модель прогноза аномалий (брака).
— Оценка степени влияния отдельных признаков (параметров) на нарушение температурного режима.
— Оценка степени влияния различных комбинаций признаков на нарушение температурного режима.
— Абсолютную величину влияния изменений каждого единичного признака на температуру (коэффициенты модели линейной регрессии).
Что дал завод
Завод предоставил нам огромный массив данных.
- Полные исторические данные АСУ ТП первого уровня о параметрах и сигналах для 1000 произведённых листов (в т. ч. показания 2000 датчиков SCADA, используемой заводом).
- Усреднённые и нормализованные данные второго уровня АСУ ТП, сформированные в базу данных Oracle.
- Примеры данных термосканера.
- Отчёты третьего уровня АСУ ТП.
Задача попала в нашу команду R&D. Мы вооружились очень быстро, развернули свой движок машинного обучения в своём же облаке (быстрое прототипирование за 2 недели для доказательства коммерческих гипотез — это наш конёк).
Утром мы получили массив, вечером над ним уже работали скрипты, отлаженные в нашей же среде для разработчиков облака.
Для выполнения задачи первого этапа пилота опробованы различные методы машинного обучения для проведения анализа важности признаков. В результате была выбрана модель линейной регрессии, показавшая наилучший предсказательный эффект:
— достоверность классификации (Precision) — 90%;
— точность попаданий (Recall) — 60%.
Выяснилось, что очень многое зависит от того, с какой температурой лист покидает установку контролируемого охлаждения (УКО). Если он чуть более холодный, чем требуется, почти гарантированно будет брак. Выявили ещё ряд параметров, с которыми корреляция была больше 0,7.
Второй вопрос был такой: а почему некоторые листы выходят из УКО чуть более холодными? Изученная выборка состояла из данных первого уровня IBA, данных второго уровня АСУТП, данных логов управляющей модели SMS-Siemag и данных третьего уровня. Потом мы обсудили свои гипотезы с экспертами завода, которые интуитивно знают, где будет брак, а где нет. Их интуитивные эмпирические модели оказались достаточно точными. В итоговой обучающей выборке осталось 197 различных параметров после удаления малозначимых (отсеянных на первом этапе) и редких.
На предыдущем этапе анализа данных большее внимание было уделено моделированию процесса охлаждения и построению регрессионных моделей. На втором этапе задача решалась как классификация (прогноз возникновения брака) по различным сценариям:
— Классы +25°, -25°, +40°, -40° без объединения и удачные охлаждения.
— Классы +25°, -25° и удачные охлаждения.
— Классы +40°, -40° и удачные охлаждения.
Наилучшим методом, опробованным нами для классификации, показал себя метод XGBoost:
— достоверность классификации (Precision) — 98,8%;
— точность попаданий (Recall) — 42,1%.
Эти параметры в дальнейшем могут быть улучшены благодаря обучению модели на новых данных в процессе использования.
Получилось!
Когда по конвейеру едет заготовка, которая в конце окажется браком (50 листов на тысячу), мы детектируем её заранее в 42% случаев (21 лист из тысячи). Ложноположительных срабатываний пока нет.
Практический результат — экономия более 10 миллионов рублей с одной партии металлических листов.
Результат — готовое ядро промышленной системы, способной в случае высокой вероятности брака самостоятельно выставлять нужные параметры охлаждения. Следующая задача — законченное комплексное решение, которое можно будет тиражировать на предприятиях данного типа. То есть интеграция с узлами линии.
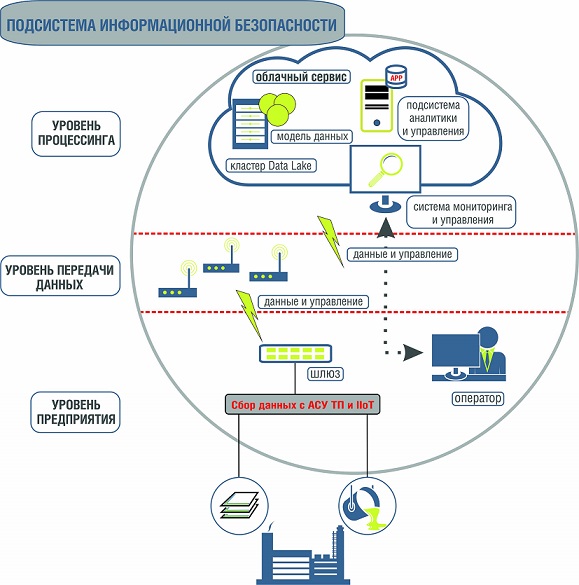
Логическая схема целевой комплексной системы предиктивного анализа
Хочется отметить, что мы сознательно проектировали решение таким образом, чтобы сделать его максимально гибким и независимым от информационной инфраструктуры предприятия. Для этого сетевой уровень может быть представлен любой глобальной сетью внешнего оператора связи, а уровень процессинга — облачным сервисом. Хотя весь комплекс можно реализовать на самом предприятии.
Итак, на уровне процессинга в безопасном и отказоустойчивом облаке размещается кластер «озера данных» (Data Lake), куда стекаются все собранные с объекта управления необходимые нам данные. То есть никаких чёрных ящиков с хардкодом — всё можно менять «на лету», в том числе чистить данные.
Итого: 3 недели на доказательство и первые коммерческие результаты.
Где ещё это применимо
Такие же проекты мы можем быстро сделать для снижения уровня брака на основе анализа входных параметров изделий для аграрных предприятий, производства автомобилей, производителей двигателей и турбин, самолётостроения, судостроительной сферы, станкостроения. Лучше всего дата-майнинг подходит для оценки обработки деталей, обточки, выплавки, закалки, сборки двигателей, сборки деталей. Везде можно существенно снизить брак, оценивая параметры с помощью датчиков на входе и имея обучающую выборку.
И да, мы можем за пару дней оценить возможный коммерческий эффект (это бесплатно) и собрать ядро по типу, как описано выше (это платно, но довольно быстро и доступно в сравнении с интеграцией). Если интересно получить оценку по вашему производству, пишите на GShatirov@technoserv.com.
И да, мы как разработчики очень любим такие проекты. Потому что они быстрые, результативные и удивительно хорошие для нашей личной кармы — видно, как математика экономит огромные деньги.
Комментарии (39)

JC_IIB
26.06.2018 12:16Их пытаются править с помощью мужика с болгаркой или отправляют назад в переплавку в зависимости от типа брака.
Напомнило: ithappens.me/story/590UnrealQW
26.06.2018 13:08Вот только не нужно думать, что листы металла реально будут пилить вручную. Есть отрубные станки и прочие ленточнопильные станки. На заводе заводские масштабы — там отгружают сталь тысячами тонн!
TimsTims
26.06.2018 15:32+7Кому лень переходить на ithappens.me/story/590 , либо корпоративный firewall блочитЗа всю мою 16-летнюю практику в отрасли, ничто не доставляло столько удивительных вещей, как реалии постсоветского производства. Попадались, конечно, странные технические решения и в банках, и в добыче ископаемых, но с заводами не сравнится ничто.
Итак. Некий машиностроительный заводик отхватил подряд у буржуйского автомобильного производства, которое требовалось максимально локализовать. Подряд состоял в производстве некой железки. Буржуи, надо сказать, прекрасно знакомы с реалиями нашего машиностроения, поэтому конвейер подрядчика снабдили на выходе лазерным объемным сканнером, который не давал отгружать брак. Наша задача заключалась в том, чтобы чутка подкрутить софтину на базе Websphere MQ, которая обрабатывала данные от сканнера и складывала их по Интернету в буржуйский SAP. Явившись в цех и прицепившись к сканнеру, мы узрели неких мужчин, одетых в спецовку, и совершавших судорожные челночные перебежки от сканнера к конвейеру и обратно. Это были «слесари по наебалову» системы контроля качества. У них было некоторое количество эталонных деталей, которые заведомо проскакивали через сканнер. И, чтобы обмануть счетчик, через сканнер пропускались, раз за разом, именно эти детали, а в отгрузку шло то, что получилось.
Более того, как выяснилось, на складе имелся недельный объем эталонной готовой продукции, который руками подкладывался на конвейер, когда приезжал контроль качества от заказчика. Долго враги не могли понять, где же скрылась проблема, и сканнер меняли трижды. В очередной наш приезд на настройку нового сканнера, мы обнаружили, что буржуи снабдили конвейер дополнительной железкой — приклеивалкой RFID меток. Не прошло и месяца, как команда «слесарей по наебалову» была доукомплектована взводом переклеивальщиков с парогенераторами.
В общем, никогда в этой стране не было и не будет качественного поточного производства, пока в головах вот такая разруха. И никогда тоёта, собранная из вот так вот «локализованных» запчастей, нормально ездить не будет. Здесь поможет только немец с железной палкой, приставленный к оператору станка. Как, собственно, и происходило в момент становления российской индустрии.striver
26.06.2018 15:51Это еще со школы… когда одни учат, а другие даже не пытаются и сразу готовят шпоры, ибо на «3» со шпорами да получится, а с головы — даже на «2» не получится. Как итог, те кто готовил шпоры в школе, сейчас успешные бизнесмены. Правда это применимо только к «нашим» краям.
BalinTomsk
26.06.2018 15:53+6Напомнило историю.
После того, как Л. В. Канторовичем был предложен оптимальный метод распила фанерного листа, этот метод в том числе попытались применить к разрезанию стальных листов. После внедрения методов оптимизации на производстве одной из фабрик инженерам удалось улучшить показатели, что привело, однако, к негативным последствиям: система социалистического планирования требовала, чтобы в следующем году план был перевыполнен, что было принципиально невозможно при имеющихся ресурсах, поскольку найденное решение было абсолютным максимумом; фабрика не выполнила план по металлолому, львиная доля которого складывалась из обрезков стальных листов. Руководство фабрики получило выговор и больше с математиками не связывалось
ru.wikipedia.org/wiki/%D0%9A%D0%B0%D0%BD%D1%82%D0%BE%D1%80%D0%BE%D0%B2%D0%B8%D1%87,_%D0%9B%D0%B5%D0%BE%D0%BD%D0%B8%D0%B4_%D0%92%D0%B8%D1%82%D0%B0%D0%BB%D1%8C%D0%B5%D0%B2%D0%B8%D1%87
solariserj
26.06.2018 19:04Нам учителя еще в школе похожую байку рассказывали, правда там было про газировку и что работники сломали линию, так как та не давала разбавлять на больше воды чем нужно.
striver
26.06.2018 19:45-1Есть пример моего одного знакомого. Написал дипломную по развитию колхоза, даже на компьютере посчитал, а злостная машина выдала эффект 300%… на защиту нужно было скинуть немного… кратно. Так глава комиссии сказал, что если это и вправду даст эффект 30%, то студенту нужно выдать орден Ленина. Студент согласился, а у проффесора очки чуть не лопнули, типа ты что там щенок рассказываешь. Как итог что мы имеем сейчас? 1 условный Джон Дир работает за 5-10 Нив/Колосов. Спросил я когда-то своего дядю-комбайнера, с какой же скорость собирает урожай этот новый комбайн Массей Фергюсон, в ответ было сказано — он собирает урожай с такой скорость, с которой Нива не едет по асфальту… Я уже неоднократно сталкивался с этим «совком» не на одной работе… как обычно говорилось — всегда так было, есть и будет. Но что-то меняется в ту сторону, в которую ты давишь, но очень медленно и с шишками на лбу (даже комиссию раз создали на предмет моей компетенции — вообще уникальный случай, даже для организации :)). А когда люди поувольнялись и никого не берут, но работать как-то нужно… то для «совковых норм» нужно 2-3 человека, а есть 1. Так даже обычный эксель может упростить работу… не говоря уже о БД и простых программах учета. У меня были предложения по компьютеризации и автоматизации… вплоть до уровня полной ликвидации отдела на 5 человек… всего-то нужно… 2-3 месяца и пару тройку программистов, к сожалению сам я не потяну, ибо работа после работы уже немного надоела. При этом при всём не проводился глубокий анализ… по моим прикидкам, то даже частично можно было заменять работу 2х бухгалтеров в обычном рабочем режиме, а не авральном… но, я так полагаю, в дальнейшем это будет после меня, ибо есть барьеры, которые я не могу преодолеть, ибо разработки, на которые ушли месяцы работы, и не только мои — один ответ — так здесь работать не будет…
UnrealQW
27.06.2018 07:28Наверное такое тоже бывает. Но по случаю топикстартера листовые заготовки — это все-же намного проще, чем готовые детали для авто. Заготовки можно и нужно делать довольно грубо, но поточно.
Denxc
26.06.2018 12:58+2Отличная работа. Но, боюсь, что для тиражирования нужно будет проводить обучение всегда заново, так как промышленные показатели от завода к заводу могут отличаться существенно. Датчики могут быть откалиброваны по-разному — как минимум.
rakoshuk
26.06.2018 14:22+6Их пытаются править с помощью мужика с болгаркой или отправляют назад в переплавку в зависимости от типа брака.
Когда по конвейеру едет заготовка, которая в конце окажется браком (50 листов на тысячу), мы детектируем её заранее в 42% случаев
Практический результат — экономия более 10 миллионов рублей
Простите, но не совсем уловил как вы получили 10 миллионов? Мужик с болгаркой вышел заранее?
Контроль на УКО происходит на выходе установки. То, что вы знаете на этом этапе, что будет брак не экономит деньги. А если понятна граница, зачем автоматизированная система, если это корректируется уставками? Понятно, что есть доп. признаки, которые вы не описали. Но если они все описываются как температура выхода из УКО, то автоматизированная система опять же, не нужна.
мы детектируем её заранее
Заранее это на выходе из УКО, когда уже понятно, что будет брак, что бы не произошло на холодном прокате? На входе в установку?
Поймите правильно, сама по себе задача прогнозирования брака не может принести экономию. Если вы решали задачу поиска оптимальных режимов охлаждения для уменьшения выхода дефекта плена, то это другое. Если прогнозирование выхода брака, тогда непонятна экономия.
Опять же, эти цифры подтверждены ВМК, что они действительно вашей моделью могут экономит до 10мл на партию или это ваши эмпирические вычисления?vanraven Автор
27.06.2018 10:5310 млн руб. экономия по 42% листов, которые благодаря превентивной оптимизации режимов не превратились в брак, на устранение которого производитель затратил бы собственные ресурсы.
Мы уточнили у технологов стоимость утилизации брака и стоимость возврата на переработку бракованного листа, помножили на количество листов в партии и на количество партий, проходящих в год. Технологи такой подход к оценке экономии нам подтвердили.
Действительно, задача не в прогнозировании брака, а в автоматизированном поиске оптимальных режимов.
Разработанная система предсказывает возможность брака на входе в установку, и в тот же момент предлагает оптимальные режимы.uSasha
27.06.2018 11:12Вы детектируете брак и экономите на более ранней его отсортировке или вы полностью устраняете 42% брака перенастройкой оборудования в реальном времени?
10М это в год а не за партию?
Если делаете перенастройку, то:
— как вы на xgboost решаете задачу оптимизации?
— как интегрируете свое решение в АСУ ТП?
lipkij
26.06.2018 14:38«Наилучшим методом, опробованным нами для классификации, показал себя метод XGBoost:»?
Это метод или библиотека? Я не очень ориентируюсь, но очень интересно.
Как принимается решение, что следует использовать именно линейную регрессию, а не более сложные модели?
Спасибо.AmberSP
27.06.2018 10:35Если заказчику надо ехать, а не шашечки («хочу нейронку, как у пацанов»), то первыми проверяются линейные модели, следом бустинги. Потому что просто, быстро и интрепретируемо: можно понять, какие признаки какое влияние на результат оказывают. И если результат устраивает, то нет смысла в глубинное обучение лезть.
vanraven Автор
27.06.2018 15:01XGBoost — это библиотека, а метод — это градиентный бустинг.
Природа решаемой нами задачи была регрессионная. Но итог измерения температуры переводится в результат брак/не брак.
Регрессия давала лучшие из опробованных методов результаты.
Брак бывает двух видов: выше или ниже нормы. Для классификации нужно было 3 класса. Алгоритм классификации работал хуже, так как разница в несколько градусов могла означать изменение в результате с «не брак» на «брак» — разделить такую выборку классификации сложно.
Сложные модели на основе нейронных сетей использовать не было смысла: недостаточно было данных, чтобы заметить прирост в качестве от их использования. Тут была важна скорость работы алгоритма, а простые модели работают быстрее. Да и интерпретировать результаты регрессии проще.
lingvo
26.06.2018 18:08Очень интересная статья. А можете решить более простую, но тем не менее ценную задачу с помощью дата-майнинга?
Суть в том, что есть жилое здание на N-этажей и несколько лифтов. Есть полная информация о том, когда и с какого этажа приходили вызовы и куда ехали люди хоть за месяцы наблюдений. То есть известны зависимости и от времени суток и от того, какой сегодня день недели. Можно ли с помощью дата-майнинга определить наиболее оптимальную стратегию управления лифтами в таком здании для уменьшения времен ожидания жильцов и на ее основе построить предикативную систему, управляющую размещением лифтов и назначением им текущих вызовов в реальном времени?
Желательно, чтобы это все требовало вычислительных ресурсов не более, чем у Raspberry Pi.
Эта задача вообще из вашей области?bougakov
26.06.2018 19:41+1www.wsj.com/articles/SB10001424127887324469304578143200385871618
Here is a typical problem: A passenger on the sixth floor wants to descend. The closest car is on the seventh floor, but it already has three riders and has made two stops. Is it the right choice to make that car stop again? That would be the best result for the sixth-floor passenger, but it would make the other people's rides longer.
For Ms. Christy, these are mathematical problems with no one optimum solution. In the real world, there are so many parameters and combinations that everything changes as soon as the next rider presses a button. In a building with six elevators and 10 people trying to move between floors, there are over 60 million possible combinations—too many, she says, for the elevator's computer to process in split seconds.
«We are constantly seeking the magic balance,» says the Wellesley math major. «Sometimes what is good for the individual person isn't good for the rest.»lingvo
26.06.2018 21:35+1Вот именно, что это утверждение "over 60 million possible combinations—too many, she says, for the elevator's computer to process in split seconds." — постоянно устаревает. Сейчас мощности компьютеров намного превосходят те, что были ранее. Ну и вот про тот же дата майнинг — я представляю себе это так: данная ситуация "In a building with six elevators and 10 people trying to move between floors" уже должна быть заранее "проведена" через дата-майнинг с получением оптимального решения для каждого из вариантов развития событий, и лифтовому компьютеру в реальном времени нужно просто выбрать из таблицы нужный вариант, подходящий под текущие условия.
selenite
26.06.2018 21:29Паттерн очевиден без датамайнинга (9-11 утра в жилом доме — держать лифты на высоте 70-80% здания, 9-11 вечера — первые этажи), но по моим попыткам задавать вопросы и не получать ответа — электричество, шум, нежелание оставлять лифты unattended и нехватка гибкости логики ПЛК. Буду рад, если всё не так глупо, конечно.
P.S. Проще решать это на уровне жильцов — привычка отправлять лифт в одиночную поездку после себя уже решит проблему)
fivehouse
26.06.2018 21:32-1Когда дата майнинг пихают во все щели, даже там где он был совсем не нужен, я уже давно молчу. Если не нормальным методом, так пусть хоть дата майнингом решают стандартную задачу. Для решения задач описанных автором статьи вполне подошла бы стандартная и давно известная дисциплина «Управление качеством статистическими методами.» Этой дисциплине лет уж 25 и более. И никакого дата майнинга, никаких облаков, никакой биг даты и никакой «движухи». Но дата майнинг моден, под него выделяют деньги, им можно эффективно пока проехать по ушам.
Ваша же задача это классическая задача оптимизации систем массового обслуживания со всеми стандартными ограничениями. Но вам нужно не просто задать параметры системы массового обслуживания, а сгенерировать стратегию. Это, конечно, совсем задача не для дата майнинга. Но вполне решается перебором системой моделирования. Предполагаю, что при современных вычислителных мощностях статистически оценить 1000 стратегий (выбранных эмпирически и с параметрами) на некотором ядре написанном на С вполне можно и за считанные минуты машинного времени. И выбрать подходящую под имеющиеся требования.lingvo
26.06.2018 21:41+2Дык я так понимаю, что вся прелесть дата майнинга в применении к этой задаче в том, что они решили ее максимум за пару человекомесяцев обычного программирования, и сэкономили владельцу 10 миллионов, а при классическом подходе на это надо было бы создавать целый отдел с узкопрофильными специалистами, который неизвестно когда достиг бы такой отдачи.
Для собственника завода это очевидный плюс.fivehouse
27.06.2018 00:07В статье я так и не нашел какие конкретно рекомендации были сделаны заводу и что именно было изменено в технологической схеме. Одна трескотня. Для завода это был контракт со сторонней организацией и сколько это стоило заводу не известно. И было ли это выгодно тоже не известно. Вне зависимости от 3 недель не первые результаты. Оцениваю стоимость описанных работ в 10 млн руб как минимум. Это 4-6 годовых зарплаты специалиста высшей категории по проблеме «Управление качеством статистическими методами.» в Москве. За это время он мог бы 10-20 похожих проблем решить стандартными методами.
ToSHiC
26.06.2018 22:34+2Так они это и сделали. Построили из готовых кубиков модельку, которая выделяет важные параметры из всего гигантского набора, и ещё одну модельку, которая прогнозирует брак на основе того среза этих важных данных, которые уже есть до начала охлаждения листа. Т.к. кубики готовые, а люди умели ими пользоваться, на всё это и ушло всего 2 недели реального времени. И никакого маркетинга в статье нету, автор молодец.
sved
27.06.2018 02:03+1О! это моя бакалаврская дипломная работа 2004 года. Только там надо было оценить качество листового стекла. Тренировались множества нейронных сетей разных видов и выбирались наилучшие (радиальные победили)
sved
27.06.2018 02:10… Ещё присутствовал на защите кандидатской. Где аспирант оценивала разные методы прогнозирования для той же самой задачи. У неё вышло что самый лучший инструмент это нейронные сети которые дали точность в 10E-10. То что она тестировала сеть на тренирующих данных нисколько её не смутило. В итоге всё равно сдала! Такие у нас кандидаты в ВУЗе были :D
Tomasina
27.06.2018 04:15Перебор статистических данных для максимального сближения с конечеой целью — я всегда считал что для этого используют нейросети. Ныне это называют дата-майнингом?
KiloLeo
27.06.2018 10:08Тоже удивил термин Дата майнинг в данном контексте. Скорее речь идёт о машинном обучении. Нейросети не единственный инструмент машинного обучения, есть много других подходов.
lingvo
27.06.2018 10:22А я наоборот, не вижу тут никакого машинного обучения или нейросетей, а тот самый дата-майнинг. Грубо говоря поиск и анализ закономерностей и связей в огромной базе данных разных наблюдений. В данном случае анализ, похоже, был сделан простым "брутфорсом" — перебирали все комбинации, пока не попали.
KiloLeo
27.06.2018 11:25Вроде как классическая задача классификации. Такие решаются как раз методами МО.
«Наилучшим методом, опробованным нами для классификации, показал себя метод XGBoost»
" it was the algorithm of choice for many winning teams of a number of machine learning competitions" en.wikipedia.org/wiki/Xgboost
Именно что МО, но не нейросети.
Gansterito
27.06.2018 10:01+1Если честно, то был уверен, что уже везде внедрены подобные системы. Я проходил практику на НЛМК в 2003 году, там аналогичная система (французского происхождения) успешно работала на «Стан 2000».
Спасибо за интересную статью!
uSasha
27.06.2018 10:21+1Статья откровенно рекламного содержания, этому не место на хабре.
По опыту DS в тяжелой промышленности могу сказать, что никакими 2 неделями там не пахнет, это сказки для заказчиков, которыми их кормят подобные менеджеры.
Львиная доля работы это правильно поставить задачу, т.к. precision/recall денег не дает, а важно как изменить бизнес процесс, когда алгоритм сигналит о браке.
Заказчик часто не понимает что на самом деле нужно. Был такой пример: просили построить аналогичную модель, но при этом хотели увеличения количество выхода годных катушек. Если вдуматься становится понятно, что это бред и если что-то отбраковывать, то количество выхода годных катушек всегда уменьшится, может увеличиться только процент (но он был не нужен заказчику).
Вторая боль проектов в тяжелой промышленности это чистка данных. В системах могут твориться чудеса (например слябов приехало 100 тонн, а полосы получилось уже 110 тонн), многое вносится вручную, у работников свои KPI и тд.
Если выделить техническую часть статьи то ее можно свести к:
— получили датасет
— запустили линейку и xgboost
— профит
Ни деталей по валидации, ни предобработки дынных и формированию фичей, ничего.
Очень интересно было бы почитать детали по внедрению, там есть много неочевидных моментов:
— получения данных в реальном времени с АСУТП
— интерфейс к производству (это прост экран оператору или какое-то подключение к АСУ)
— потоковая предобработка данныхKiloLeo
27.06.2018 15:07— На Хабре в блогах компаний все статьи рекламного содержания, это вроде как приветствуется. Почему Техносерву нельзя?
— Проекты за 2 недели реально есть. Не могу сказать конкретно об этом, но это не исключено.
— Проблемы с качеством данных часто решаются довольно быстро выкидыванием откровенно нелепых комбинаций.
— Деталей в статье действительно нет, что грустно.uSasha
27.06.2018 16:24Рекламные статьи с полезной технической информацией — норм. Статьи «приходите к нам, мы делаем быстро и качественно» — говно.
А есть опыт то с DS проектами в тяжелой индустрии с внедрением за 2-3 недели?
Или хотя бы где угодно, но чтобы от запроса до внедрения 2 недели?
Срок выглядит не то что нереально, а просто смешно.
Ну да, фит-предикт на грязном датасете сделать легко, но чтобы нормально поставить задачу (чтобы она решалась и решение приносило пользу большую чем расходы на внедрение) и внедрить — это минимум месяцы.
Если есть реальный проект, ты было бы интересно услышать описание того, что было сделано и за сколько, вариант «мы за неделю сделали ноутбучек с норм AUC_ROC и полгода его внедряли не катит».
Если бы 3-4 человека за 3 недели генирили 10М с _партии_, т.е. несколько раз в день. Это было бы выгоднее продажи наркотиков.KiloLeo
27.06.2018 17:00Ну да, 2 недели — это скорее «проверка концепции» — убедиться, что в принципе работает и можно начинать проект. А так, конечно, одно только тестирование больше займёт.
А по последнему тезису — внедрять ИТ — очень часто выгоднее продажи наркотиков. Гугл, Яндекс, Амазон, САП наваривают погуще наркокартелей.selenite
27.06.2018 23:37Значимость наркокартелей завышается тем, что это острая тема, которую любят обсуждать. А по факту ни бюджетов, ни оборотов, ни технологий-инноваций.
Hardcoin
Как вы определяете, что ложно-положительных пока нет? Precision в 98.8% говорит, что 11-12 ложноположительных на тысячу должно быть. Может просто не определяют ложноположительные? Система сказала брак, значит брак?
И на каком объеме заготовок потом проверялось ядро в реальной эксплуатации?
vanraven Автор
Некорректно фразу построил.
Конечно, ложноположительные у нас были. Мы пытались их снижать при поддержании требуемого recall.
Мы не можем утверждать, что ложноположительных не будет в 100% случаев: у модели есть и true positive, и false positive rate.
В эксплуатации система будет тестироваться во втором полугодии, после проведения всех необходимых интеграций с АСУТП.
Hardcoin
Это понятно. Потому и интересно, как планируете отличать ложноположительную в реальном тестировании (если планируете).
vanraven Автор
В реальном тестировании будет сложно отличить.
Ошибки можно интерпретировать как неверную корректировку, проанализировать характеристики листов и поправок параметров с ошибками.
Если будут выявлены проблемы — скорректировать модель.
Но если корректировки внесены, а на выходе все равно брак, то корректировки были неверные. Сказать были ли они нужные нельзя.