
Приходится искать альтернативу в хадупах. Я попробовал сравнить некоторые запросы на витрину данных построенную на parquet файлах в хадупе, против оракла Oracle standard на 8 xeon ядрах, 196 гб рам, некий энтерпрайз сторидж с HDD и SSD кешем, который шариться еще с несколькими системами. Первый запрос затрагивает 4 таблицы, в оракле они занимали 62, 12, 6.5 и 3.5 гб. В табличке, что покрупней порядка 880 млн строк. В оракле план запроса был такой:
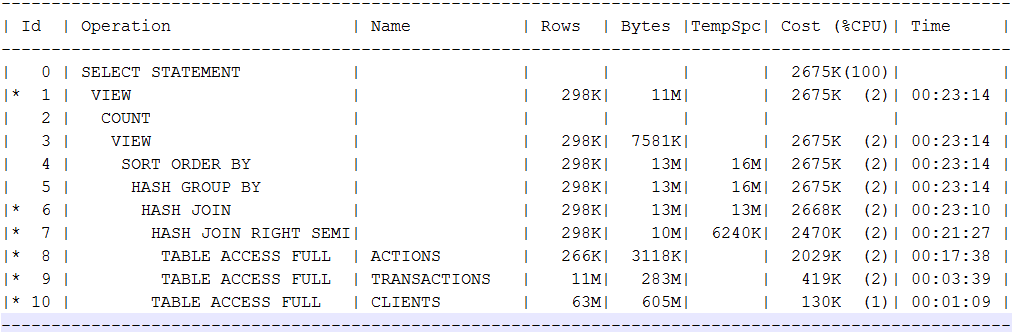
В плане я специально хотел увидеть фулсканы и хешджоины, типичные в моих аналитических запросах. В реальности запрос на standard редакции Oracle занимает порядка 7 минут. Spark 2.3 запущенный через spark2-submit на 14 executors по 4 ядра/16 гб рам выдает ответ на практически такой же запрос с 10k HDD дисков в пределах минуты. Cloudera Impala толкающаяся с yarn и spark на том же кластере (impalad на 8 нодах, ресурсов сравнимо с 14 executers по 4 ядра) стабильно выдает ответ за 11-12 секунд. При этом у Impala постоянно параллельно нагрузка идет, которая должна бы вымывать закешированные данные.
Игры с размером блока, переезд на Oracle EE редакцию с ее параллельностью и взрослым partitioning наверняка дали бы сокращение времени исполнения в несколько раз, но я слегка сомневаюсь, что время бы было сравнимо даже с тем, что я получил в Spark. С другой стороны всего 3-4 ноды практически бесплатного Cloudera Hadoop по сути позволяют в привычном SQL получить, скорости за которые пришлось бы ораклу несопоставимо большие деньги.
Ораклу стоит серьезно задуматься о лицензионной политике, если уже большие фанаты, типа меня, не находят смысла платить за Enterprise edition.
Комментарии (37)

fediq
28.06.2018 00:29+1"Что-то Lamborghini дороговата… Сравнил её с комбайном Ростсельмаш Дон без переднего колеса, так вот он больше картошки за раз везёт. Правда, в лесу борона за сосны цепляется, могли бы предусмотреть… Да, надо Lamborghini подумать о ценовой политике!"
Несопоставимые вычислительные мощности, use case заведомо проигрышный для Oracle, неоптимальный способ запуска Spark (spark-submit для SQL, серьёзно?), однобокий запрос — методология абсолютно кустарна.
Если хотите сравнивать производительность аналитических запросов — сравнивайте Spark SQL, Teradata, Vertica, GreenPlum, HANA, ClickHouse и т.п. Причем у каждого из этих решений есть своя оптимальная ниша и свои условия работы. Зачем сравнивать с Oracle, который играет в совсем другие игры?
Yo1 Автор
28.06.2018 01:12я сравниваю то что стоит сравнивать. в DWH и аналитике хадупы заменяют оракл, конкретно в моем проекте и миллионе соседних.
говоришь несопоставимые мощности. а что бы дали 56 ядер Standard edition? Standard ничерта в параллель делать не умеет, сколько ему не выдели 1,5-2 ядра от силы будет занято. даже если был EE пришлось бы нарезать туеву кучу партиций, что бы загрузить хотя бы треть от тех 56 ядер. но никто на такие объемы не стал бы лицензировать 56 ядер, потому что цена.
и да, spark-submit для sql это не просто серьезно, это в принципе единсвенный для спарка вариант. все остальное лишь обвязка вокруг spark-submit, причем в случае с клоудерой единственный вариант. там ни hive на spark2 не переключить, ни утилиты spark-sql.fediq
28.06.2018 02:00Vertica оставила бы и Spark, и Impala глотать пыль на сопоставимых мощностях в структурированной задаче на таких крошечных размерах. Oracle сравнивать с ними совсем не стоит, это решение под транзакционные нагрузки, его используют под DWH либо как легаси, либо по неграмотности.
Аналитические ad-hoc запросы на Spark нужно запускать в уже проинициализированном контексте, опционально, с динамическим аллоцированием. Из коробки в CDH это умеет Hive-on-Spark через CLI или Hue. Не из коробки после небольшой магии можно поднять Spark SQL Thrift Server или Hive LLAP + Spark. Самый кастомный вариант — можно держать контекст в отдельном приложении и сделать свой собственный интерфейс.
Yo1 Автор
28.06.2018 10:01Vertica мне не интересна. совсем. платить за каждый ТБ в эпоху 16Тб дисков глупо.
Hive-on-Spark в CDH не поддерживает spark 2.х в принципе, с коробкой или без там лишь spark 1.6, со всеми вытекающими, т.е. все ваши фантазии мимо. Thrift клоудера тоже не поддерживает и очень не рекомендует ставить. но это все не важно, как бы ты не запускал, это лишь обвязки вокруг spark-submit. я тоже запускал через свою rest обвязку.
SergeyUstinov
28.06.2018 10:06По поводу небольших компаний — не соглашусь.
Небольшие компании — это десятки — сотни миллионов записей (не миллиарды — десятки — сотни миллиардов). И под такие объемы тот же Microsoft SQL Server Standard хорошо справляется (кубы и база в качестве DWH). Партицирования не хватает (в стандарте только 4 партиции разрешено), но жить можно.
А по цене — если арендовать сервер с сиквелом в том же Azure, то по цене вполне нормально. И для таких объемов данных — хватает.Yo1 Автор
28.06.2018 12:17разве mssql standard умеет что-то читать в параллель?
SergeyUstinov
28.06.2018 13:54Насколько я знаю, разные секции могут читаться параллельно. И стандарт едитион это поддерживает.
Вот немного на эту тему: Partitioned Tables and Indexes
Если честно, я не настолько глубоко погружался в этот вопрос (что именно параллелит ms sql). На практике, если нормально спроектировать структуру куба, всё работает с приемлемой скоростью (если мы говорим об объемах данных небольших и средних компаний — десятки / сотни миллионов записей).Yo1 Автор
28.06.2018 14:32Partitioned Table Parallelism только EE yes
docs.microsoft.com/en-us/sql/sql-server/editions-and-components-of-sql-server-2016?view=sql-server-2017
т.е. абсолютно та же ситуация — банальный хеш джоин будет в один поток 60 гб читать долгими минутами, а лицензировать на EE нет никакого смысла из-за цены.SergeyUstinov
28.06.2018 15:21Наверно, параллельное чтение только у ентерпрайза — я в такие нюансы не вникал.
Но, как я уже говорил, для относительно небольших объемов данных стандарт едитион (плюс быстрые ссд диски) вполне хватает.
И совокупная стоимость получается существенно ниже альтернативных вариантов (если включать зарплату специалистов).
Поэтому я и говорю, что для небольших компаний есть весомые резоны делать аналитику на стандартной субд, той же мс скл. Совокупная стоимость достаточно низкая и при этом альтернативы получаются дороже.Yo1 Автор
28.06.2018 21:33+1параллелить standard ничего не умеет, но лицензировать требует каждое ядрышко. один сокет и 22 ядра вытянут на $80+ тысяч за лицензии. и за эти деньги будет тошнить в одном потоке в сотни раз уступая импале. в чем смысл?
я не вижу смысла вкладывать в технологии, которые не способны и десятой доли ресурсов односокетного сервера воспользоватьсяmzinal
28.06.2018 23:35-1Oracle DB под "чистую" аналитику — пустая трата денег (imho, разумеется). Есть более годные продукты.
Hadoop и его друг Spark могут быть полезны, но пока скорее делают первые шаги, когда индустрия ушла гораздо дальше.
SergeyUstinov
29.06.2018 10:28Не требует Standard Edition лицензировать каждое ядро. Можно, разумеется, и такую модель лицензирования выбрать — но тогда сам себе злобный буратино. :)
Мы купили лицензию на сервер (виртуальную машину). И стоила эта лицензия примерно одну тысячу долларов. Посмотри сам на Цены на SQL Server именно на Standard Edition. Правда, под аналитику у нас выделено не 22, а 14 ядер, но нам этого хватает.
А так как у нас ERP (навижин) и так крутилась на ms sql, и юзеры уже пользовались экселем (через него смотрим кубы), никаких дополнительных затрат на софт для аналитики нести не пришлось.
В том то и дело, что для небольших компаний ms sql standard (про оракл не знаю) во многих случаях очень даже приемлемый вариант как по цене, так и по скорости.Yo1 Автор
29.06.2018 10:34открыл, посмотрел. вижу standard edition $3,717 за ядро. то о чем я и толкую. лицензия на ваши 14 ядер тянут на $52 тысячи
SergeyUstinov
29.06.2018 15:28Я ведь уже написал, что лицензировать на ядро для небольших компаний — сам себе злобный буратино. :)
Читаем буквально в следующей строке:«Сервер + клиентская лицензия CAL $931»
931 доллар ЗА СЕРВЕР без учета количества ядер!
Учитывая, что CALы у нас уже были куплены для других целей, стоимость MS SQL Standard Edition для целей аналитики составила эти самые 931 доллар и всё. Больше нам ничего платить не пришлось.
И даже если надо покупать CALы. Стоят они 200 баксов за юзера. Скольким юзерам в небольшой фирме нужен доступ к аналитике? 30-40, максимум 50. 50 * 200 = 10000 долларов на CALы. Приплюсовываем 1000 на серверную лицензию — 11000 долларов за софт для аналитики, что тоже отнюдь не заоблачная цена.
dim2r
28.06.2018 10:44Не совсем понял название. Что значит «выталкивает аналитику»?
Oracle — воротилы бизнеса надо признать. Прибрали к рукам MySQL и Java. Никто не застрахован, что и Hadoop приберут.fediq
28.06.2018 16:54Есть Oracle Big Data Appliance с CDH Enterprise под капотом — ребята идут в ногу со временем, никто их ниоткуда не выдавливает.
Yo1 Автор
28.06.2018 21:52ну да, клеить лейблы на чужие технологии это путь к успеху. главное, что бы клиент понимал, на кой ему платить за CDH ораклу, а не получить все что там под капотом мимо оракла.
dim2r
29.06.2018 12:05-1Охота посмотреть. Дистрибутив откуда можно скачать?
fediq
29.06.2018 12:47Appliance — это по-русски ПАК, т.е. железо вместе с софтом. Дистрибутив поставляется вместе с железным кластером и сразу готов к работе. Full Rack стоит около $680k (плюс поддержка, плюс интеграции, плюс ...), и он прекрасен.
https://www.oracle.com/engineered-systems/big-data-appliance/index.html
mzinal
28.06.2018 23:28Коллега, я таки извиняюсь, но вы бредите.
Разговор про partitioning ещё худо-бедно в тему, но rac под аналитику — полнейшая бессмыслица.
Под серьезную аналитику нужна mpp-система, которую на Oracle DB сделать нельзя.
Из бесплатного тут скорее можно посмотреть на Yandex Clickhouse и Greenplum, при всех их недостатках. Коммерческие продукты есть более серьезные — Vertica, Teradata, SAP HANA, IBM Db2.
Tetriz
29.06.2018 09:07Помимо всяких hadoop решений не забывайте, что задачи DWH сегодня элегантно решаются и облачными сервисами типа AWS Redshift. Вообще, я считаю, что мы уже в post hadoop эре (в плане хранения данных). Намного интереснее хранить данные на чем-то вроде S3, трансформировать их при помощи spark и выплевывать опять-таки либо в S3 или в любое количество нужных DWH на Redshift. При этом данные могут читаться по SQL и напрямую с S3 (Athena, Spektrum). И никакой головной боли с администрирлванием собственных hadoop кластеров. Про лицензии Оракл/SAP я вообще молчу…
Yo1 Автор
29.06.2018 10:18-1имхо облачные базы очень дорого и могут окупиться лишь в штатах и совсем западной европе, где персонал стоит по $200к в год. я больше про гугло-клауд знаю, у гугла bigtable. неадекватно дорого. про редшифт почти ничего не знаю, но пошел в их калькулятор, ткнул 3 ноды ds2.8xlarge/16Tb (т.е. hdd и примерно столько же ядер, как у у меня в спарке было). ценник $20,000 в месяц. за деньги какие эти три ноды за три года скушают в наших широтах можно десятки нод хадупа держать и кормить двух админов, которые 24 часа будут вокруг кластера скакать.
у гугла можно просто хадуп арендовать, свалив на него администрирование. но на мой вкус тоже сильно дороже выходит. у accenture есть документ со сравнением vs bare metal
www.accenture.com/t00010101T000000__w__/jp-ja/_acnmedia/Accenture/Conversion-Assets/DotCom/Documents/Local/ja-jp/PDF_2/Accenture-Cloud-Based-Hadoop-Deployments-Benefits-and-Considerations.pdf
они подогнали равенство с bare metal за счет расхода на персонал, тогда как расходы на железо в 5 раз дороже, сторидж в двое. у нас к примеру кластер на порядок крупней, а обслуживающий персонал 1.5 человека с далеко не американскими зарплатами. это имеет смысл в штатах, где спец непомерно дорого стоит.Tetriz
29.06.2018 11:22про редшифт почти ничего не знаю, но пошел в их калькулятор, ткнул 3 ноды ds2.8xlarge/16Tb (т.е. hdd и примерно столько же ядер, как у у меня в спарке было). ценник $20,000 в месяц.
Это самая распространенная ошибка взять конфигурацию on-premise и попытаться повторить ее на облачных сервисах и потом удивиться ценнику. Фишка облачных сервисов в возможности использования их on demand.
В конкретно этом случае, я бы действовал так:
- Данные поступают в S3 в виде orc / csv
- Если их надо трансформировать (аггрегации, etc) — запускаете регулярно Glue jobs и результат сохраняете в S3 опять. Платите только за время работы Glue (там Spark jobs).
- Теперь вы можете сразу же запрашивать данные по SQL напрямую использую Athena по цене "$5 per TB of data scanned" — уже неплохо, да? Нет запросов — нет затрат. А еще, если вы их сожмете в gzip, то цена уменьшится пропорционально степени сжатия.
- Если вам нужны очень специфические модели данных, возможно, с очень специальными требованиями к производительности — тогда вы можете уже выплевывать данные в один или несколько Reshift инстансов/кластеров, убивать их при необходимости и т.д.
Как-то так.Yo1 Автор
30.06.2018 11:11ну это речь про батч-процессинг, в то время как современная аналитика движется к риалтайм, сейчас модно доставлять в dwh горячие данные через какую-нибудь kafka. сколько будет стоить spark streaming job? подозреваю мого дороже.
по кластерам редшифт не понятно, что значит убивать? а данные куда? если на S3 устроить datalake, а в redshift держать витрины для BI, убивать не получиться и снова возвращаемся к цене.Tetriz
30.06.2018 13:00Давайте по порядку. Сначала с batch.
по кластерам редшифт не понятно, что значит убивать? а данные куда? если на S3 устроить datalake, а в redshift держать витрины для BI, убивать не получиться и снова возвращаемся к цене.
Да я ж написал, вам в большинстве случаев Redshift и ненужен — вы сырые данные трансформируете в витрины (например с помощью Glue) и держите в том же S3, запрашивая данные по SQL через Athena. Redshift вам нужен только при специфических требованиях по производительности. А убивать — значит, что если Redshift-витрина вам не нужна больше, то можно грохнуть (данные-то в S3) и потом создать при необходимости опять в пару кликов.
в то время как современная аналитика движется к риалтайм, сейчас модно доставлять в dwh горячие данные через какую-нибудь kafka. сколько будет стоить spark streaming job? подозреваю мого дороже.
Ооо. Это моя любимая тема. Вы слышали о лябда-архитектурах? Так вот, на AWS они реализуются очень элегантно: входящие данные (например вы получаете их как поток через Kinesis) разделяются на 2 потока (причем это деляется очень легко):
- Один поток (обычно — все данные) идет на S3 в надежное хранилище и далее в поток «none real time» процессинга — например куча всяких аггрегаций и т.д. Ну и вообще тут применимо все то, что мы описали выше для Batch
- Второй поток идет уже в тот же Spark кластер (а иногда и этого ненадо — данные важные для realtime часто намного меньше основной массы). А вот тут опять — я бы никому не посоветовал бы сегодня поднимать свой кластер, а вместо этого взял бы AWS EMR (если нагрузка более менее постоянная во времени) или подключил бы сервис Qubole (это подороже, но если надо чтобы кластер динамически масштабировался вверх и вниз — отличное решение. там еще экономия на использовании spot instances).
PS: я понимаю, что чисто по operational costs есть ситуации когда все на своем железе дешевле (с учетом мизерных з/п). Но вы не забывайте что у ентерпрайза не только деньги, но еще и другие требования к решениям (например availability, resilience, etc.) Разместите-ка свой on-premise Hadoop кластер и прочие компоненты в 3х регионах… И посчитаем. Вдруг окажется что клауд дешевле и надежней. Да даже в одном регионе, если уметь готовить клауд, а не лепить «как у меня в DC было», то все очень хорошо можно сделать.
Geckelberryfinn
29.06.2018 20:48+1Мне кажется, что немного смешиваете область применения различных продуктов. Мне кажется (зависит, конечно от конкретных требований), что лучше всего комбинировать hadoop и реляционные или аналитические базы (лучше колоночные, конечно, вроде DB2 Blu или Vectorwise). Hadoop для холодного архива и batch-обработки, RDBMS — для горячих данных и аналитики. При этом, можно использовать гибридные моторы, типа IBM BigSql для бесшовной интеграции с этими двумя мирами.
wildraid
30.06.2018 11:33Не пробовали Exasol? Если используете много сложных JOIN'ов (десятки-сотни в одном запросе), то рискну утверждать, что по производительности это наилучшее решение на текущий момент.
Их SQL очень близок к Oracle, изменения будут минимальными. До 1Tb raw данных бесплатно, далее очень дёшево (в моём понятии). Особенно учитывая большую экономию на железе, потому что его нужно меньше на ту же нагрузку.
Единственное, нет «настоящей» реалтайм-аналитики, потому что есть ACID, и нужно всё же делать батчи и commit'ы. Но никто не мешает делать импорт раз в 5-10 минут.
skymal4ik
Спасибо, статья интересная вышла.
Но, вы уж простите, расскажите людям не сведующим в области, кто вы, что в конце статьи так прямо говорите что ораклу надо менять их политику цен чтобы вы не перестали пользоваться их продуктами?
Ну и было бы интересно узнать что за данные или какой бизнес-кейс рассматривается. Цифры это хорошо, но как-то… Искусственно что ли…
sshikov
Ну, на самом деле ничего искусственного. Заметьте, тут написано «аналитику» — так что речь например (или даже как правило) идет о данных например Т-1, нам не нужны транзакции, потому что данные эти write once, ну и так далее. И при этом запросы на оракле выполняются минутами (т.е. речь в целом об отчетах).
И именно в таких условиях хадуп реально рулит, ибо это как раз его ниша. На хадупе сложно (пока, во всяком случае) получать ответы на запросы реально быстро, потому что map reduce задачи стартуют достаточно медленно, и с этим мало что можно сделать, на хадупе как минимум сложнее обеспечивать транзакционность, потому что в основе значительной части «таблиц» в Hive лежит просто текстовый файл в CSV, который о транзакциях ни сном ни духом, а поддерживаются транзакции пожалуй только в формате ORC, с которым (вот сюрприз) есть некоторые проблемы у Impala. В общем, хадуп — это не серебряная пуля.
Но вот гибко переваривать заранее денормализованные (чтобы не делать лишние join-ы) данные тера- или петабайтами, на базе подхода schema on read — это у хадупа получается хорошо. И инструменты его, начиная с Hive и не заканчивая спарком, по большей части значительно более гибкие, чем может предложить тот же оракл (и да, MS SQL и остальных это тоже касается).
Yo1 Автор
хм, надо будет почитать про ORC, думал это концептуально тот же паркет, просто от hortonworks.
по поводу транзакций, на мой вкус в DWH и аналитике снепшоты hdfs даже удобней транзакций. у нас когда приходит батч, на hdfs создается снепшот и перестраивается витрина построенная на parquet файликах. те кто стартанули расчет/запрос работают со старым снепшотом, те кто стартанули позже, работают с новым. а в оракле все равно транзакции на таких задачах бесполезны, ты вынужден коммитить каждые 100500 строк при закачке батча. а раз комитишь, соответсвенно и консистентность идет мимо. плюс если что-то поло не так, у тебя пол батча в базе.
Geckelberryfinn
У orc еще в заголовке каждого страйпа есть статистическая информация о данных в нем. Сильно может помочь при аналитических запросах. На моих тестах orc показывает себя лучше чем паркет
Yo1 Автор
Я тот, кто с грустью наблюдает закат технологии, вызванный одной лишь жадностью. Оракловые кластера по адекватным ценам могли бы безраздельно править хоть в DWH, хоть в OLTP. Oracle rac это индексы, транзакции, консистетность, при этом масштабируемость на десяток узлов, ну где такое еще дают? но цена… что толку от всего этого если 24 ядра экзадаты с железом тысяч на $40 уже тянет на миллион с лицензиями?
Бизнес кейс не суть важно, это хадуп, который читает файлы данных таблиц целиком. т.е. совершенно не важно, что у вас там за структуры и насколько сложные связи. все равно хадуп будет читать все, поэтому была бы это схема зведа с 60 гб фактов и гиганскими измерениями или что-то другое, как у меня, все равно ответ будет примерно в то же время
mzinal
Oracle в серьезном dwh — дань инерции разработчиков и администраторов.
Потому как очень ограничен в возможностях горизонтального масштабирования.
Hardened
Эти ограничения больше экономические, чем технологические. Сходился бы кейс по финансам технические недочёты бы быстро подтянули. Oracle проморгал сегмент…