При оценке эффективности перехода в облака Заказчики зачастую склонны сравнивать стоимость владения облаками и железом в лоб. Например, если покупаем 5 серверов с 40 процессорными ядрами и 256 ГБ RAM, то и у облачного провайдера запрашиваем аналогичные ресурсы (40*5=200 vCPU + 256*5=1280 ГБ vRAM), а потом сравниваем затраты за 3 года или даже 5 лет.
К сожалению, в большинстве случаев такой подход не будет объективным, поскольку не учитывает ряд важных нюансов, напрямую влияющих на стоимость владения.
1. Не учитываются ресурсы, требуемые для обеспечения отказоустойчивости
В облаке вопросы отказоустойчивости уже продуманы — хосты виртуализации кластеризованы, а в кластере зарезервированы ресурсы как минимум в размере одного хоста виртуализации, чтобы серверы клиентов в случае отказа хоста или его выключения на время регламентных работ могли быть перемещены на резервный хост. При этом дополнительной платы (сверх обозначенной стоимости ресурсов) за такой резерв сервис-провайдер не требует.
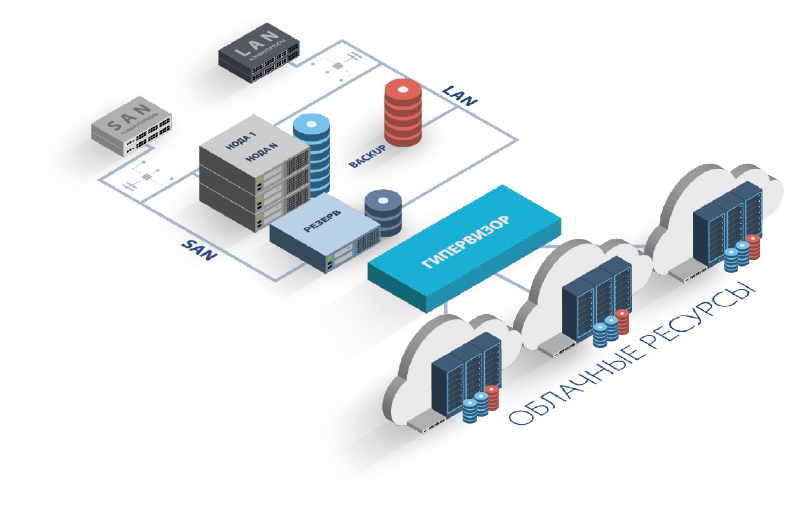
В случае своего железа потери на резервирование придётся вычесть из потенциально доступного на оборудовании пула ресурсов. В нашем примере с 5 серверами Заказчик при сохранении отказоустойчивости не сможет загрузить серверы по процессору и памяти более чем на 80%, иначе в случае отказа одного из хостов часть серверов физически не смогут быть перезапущены из-за нехватки ресурсов.
Конечно, можно рассчитывать, что в случае аварии вы сможете временно остановить ряд некритичных сервисов, но такой подход в реальных условиях как правило не работает.
То же самое справедливо и для облачного хранилища данных — в цену виртуального дискового пространства уже заложены устойчивые к множественным отказам типы рейдов и резервные диски горячей подмены, а в случае собственной СХД будут доступны для использования 45-65% от сырого дискового объема в зависимости от выбранного типа RAID-массива.
2. Не учитывается предел загрузки серверов и систем хранения данных
Практика показывает, что серверы архитектуры x86 не стоит постоянно нагружать более чем на 70-80% по процессору и 80-90% по памяти, иначе возможны просадки производительности, особенно заметные во время запуска обслуживающих задач (например, во время резервного копирования). При этом кратковременные всплески нагрузки железо, как правило, переживает нормально, а вот при долговременной работе в таком режиме деградация производительности размещённых на этом железе ИТ систем очень вероятна.
По этой причине многие сервисные провайдеры не только соблюдают правила допустимой предельной утилизации своего оборудования*, но и фиксируют такие обязательства в договоре с Заказчиком.
Выдержка из договора SLA для нашего облака VMware

На системе хранения данных утилизировать весь доступный объем, получившийся после сборки RAID-массивов, также не всегда получается, поскольку требуется резерв для работы различного функционала стораджа (например, аппаратных снапшотов или тиринга). Размер такого резерва может составлять 10% и более от доступного для адресации места.
При использовании СХД на механических дисках (HDD) размеченные луны не рекомендуется заполнять более чем на 70-80% при интенсивной дисковой нагрузке, чтобы избежать деградации производительности хранилища. SSD диски такой проблемы лишены, однако all-flash стораджи сегодня все еще достаточно дороги, и не для каждой компании их покупка рентабельна.
3. Не учитываются издержки, связанные с ограниченным масштабированием
Не секрет, что при планировании потребляемых ресурсов всегда закладывается определенный резерв на случай роста. Размер этого резерва индивидуален, однако влияющие на него факторы более-менее известны.
Можно отталкиваться от статистики роста потребления в предыдущие годы — если эти данные есть, то закладываем аналогичную динамику и немного сверху на непредусмотренные срочные инициативы бизнес-подразделений. Если такой статистики нет, то придётся делать предположение самостоятельно на основании плана будущих проектов и стратегии компании по росту и географической экспансии. Такой прогноз вряд ли окажется точным, но это все же лучше, чем оказаться без мощностей, нужных бизнесу «здесь и сейчас»
В период высокой конкуренции практически на всех b2c рынках, бизнес вынужден делать ставку на скорость запуска и вывода на рынок новых продуктов и услуг, потому как зачастую первый на рынке снимает сливки, а второй получает убытки.
В таких условиях поддерживать нужный темп, опираясь на собственную инфраструктуру, могут себе позволить только крупные игроки, способные инвестировать в собственную экспертизу, или даже ИТ платформу, и перераспределить ресурсы между проектами в случае необходимости.
Для менее крупных и средних компаний намного быстрее будет масштабироваться по мере необходимости на облачных мощностях, поскольку свое железо быстро нарастить не получится. Даже если в компании внедрены стандарты на оборудование и налажен процесс расчета конфигурации в выбранном вендоре, пройдет не менее 2-3 месяцев, прежде чем железо будет рассчитано, поставлено, смонтировано и настроено для возможной эксплуатации. Если же процедура приобретения основных средств достаточна сложна, как часто бывает, и корпоративные регламенты требуют каждый раз проводить тендер с участием нескольких конкурирующих производителей, то процесс расширения ресурсного пула легко может растянуться на полгода и более.
Конечно, в случае с облаком планировать и закладывать в бюджет резерв тоже нужно, однако при неверном планировании компания не понесёт заметных убытков — облачные мощности всегда можно масштабировать по реальному потреблению, и нет нужды оплачивать лишнее, пока оно реально не потребуется.
4. Не учитываются издержки на неточный сайзинг ключевых бизнес-систем
Точное планированием ресурсов для ключевых учётных информационные систем может быть сложной задачей, поскольку каждое внедрение индивидуально и часто сопряжено с большим объёмом доработок под конкретные бизнес-процессы. В этом случае при сайзинге остается надеяться на рекомендации разработчиков системы, которые обязательно заложат возможные риски — ведь им не хочется оправдываться перед Заказчиком за медленную работу системы после внедрения. Получив рекомендации производителя, собственные ИТ специалисты также заложат риски, потому что не хотят выслушивать упреки от пользователей. В итоге получается, что производитель перестраховался при предоставлении рекомендаций раза в полтора, и ИТ отдел перестраховался при заказе оборудования раза в полтора, а в результате приобретенное дорогостоящее железо простаивает больше чем на половину, и лишнее обратно в магазин уже не отнесешь.
Облако не только спасает от подобных ситуаций, но также может сильно облегчить жизнь тем, кто арендует мощности на время внедрения, выполняя таким образом сайзинг на реально развернутой системе. В этом случае, правда, появляются некоторые риски совместимости — после переезда на свое железо производительность системы может внезапно снизиться без видимых причин. Но такой подход все же лучше, чем покупка оборудования вслепую.
5. Не принимается в расчет стоимость обслуживания своей инфраструктуры
Любое железо, будь то сетевое оборудование, серверы или хранилища, нужно обслуживать. То же самое можно сказать в отношении систем виртуализации, мониторинга, безопасности, бекапирования и других сервисов, обеспечивающих стабильную и безопасную работу ключевых бизнес-систем компании. Персонал, способный поддерживать все это в рабочем состоянии и починить в случае аварии, стоит достаточно дорого. Зачастую — неоправданно дорого для не самого крупного бизнеса.

На основе статистических данных, в том числе HH.RU(https://stats.hh.ru).
При этом совокупная сложность используемого стека инфраструктурных технологий становится выше с каждым годом, и вместе с ней постоянно растут требования к квалификации обслуживающих специалистов.
Удерживать таких людей в штате даже при наличии пухлого бюджета становится все сложнее, поскольку стоящих специалистов помимо зарплаты необходимо также обеспечивать потоком задач с нарастающей сложностью и ответственностью. Конкурировать за них с профильными ИТ компаниями как правило попросту невыгодно.
Размещая инфраструктуру в облаке, Заказчик тем самым фактически получает доступ к разносторонней команде квалифицированных архитекторов и инженеров, опыт и компетенции которых постоянно растут. Чем плотнее компания взаимодействует с сервис-провайдером в своих проектах, тем в большей степени может рассматривать его не только как поставщика облачных услуг, но и как постоянно доступного ИТ партнера, готового делиться с клиентом опытом и комплексно решать его задачи.
Здесь важно отметить, что аренда мощностей и сервисов в облаке, конечно же, не освободит компанию от необходимости инвестировать в свою службу ИТ, однако позволит пересмотреть штат, выбирая специалистов с более узкими, профильными для ваших бизнес-систем компетенциями, перекладывая ответственность за инфраструктурные и пограничные сервисы на плечи провайдера.
6. Не всегда учитывается стоимость вендорской поддержки используемого ПО и оборудования
Каким бы именитым не был производитель, от производственного брака и ошибок в работе софта все равно не застрахован никто. Особенно бывает обидно, когда из-за этого не просто некорректно работает часть функционала, а невозможна эксплуатация приобретенных ИТ активов в целом, и оперативно решить вопрос с производителем не получается, даже если приобретена дорогая next business day поддержка.
Происходит такое по разным причинам: иногда у вендора ещё не выстроены процессы, и поддержка оказывается в ограниченном режиме, иногда нужных деталей нет в ЗИП, иногда требуются кастомные прошивки, на написание которых уходит не одна неделя, а то и не один месяц, — однако результат всегда один — потраченное время, нервы, сорванные сроки проекта и вызов на ковер к бизнесу. Думаю, многие согласятся, что переложить подобные риски на плечи провайдера намного приятнее.
7. Не учитывается стоимость постройки и содержания своей серверной
Облачные провайдеры обслуживают большое количество Заказчиков, и недоступность облака по любым причинам сильно бьет по деловой репутации поставщика услуг, даже если отказ произошел не по его вине. Клиентам все равно, какого размера дерево упало на датацентр, и какого цвета был экскаватор, повредивший оптику. Поэтому вопрос выбора и оснащения площадки как правило не стоит — арендуем Tier3 ЦОД и подключаем несколько Интернет-каналов с защитой от DDoS.
Чтобы обеспечить похожий уровень надежности и безопасности в локальной серверной, придется инвестировать в нее порядка 100 000 $ на стойку, но и в этом случае по ряду параметров коммерческий дата-центр будет выигрывать.
Даже если не ставить перед собой задачу построить серверную по мировым стандартам, а лишь обеспечить приемлемые условия эксплуатации для своего оборудования, то капитальные затраты все равно будут заметными — придется выделить помещение, проложить СКС, подключить пару внешних каналов связи, подвести качественные линии электропитания, способные выдержать десяток-другой киловатт, правильно организовать охлаждение и вентиляцию, позаботиться о ИБП, а в идеале задублировать основные инженерные системы и поставить промышленную систему пожаротушения и СКУД.
И конечно же все вышеперечисленное придется обслуживать, что вряд ли обойдётся дешевле четверти миллиона в год на каждую полную стойку.
Можно облегчить себе жизнь и разместить свое оборудование в коммерческом ЦОД. Однако преимущества аутсорсинга непрофильных ИТ операций достаточно быстро становятся очевидны, и от аренды стоек Заказчики переходят к гибриду своего железа и постепенно его заменяющих облачных сервисов.
Если при сравнении учесть описанные выше нюансы, то в большинстве случаев окажется, что облака позволяют бизнесу снизить издержки, даже если при выборе провайдера сделать акцент на качестве услуг и количестве доступных сервисов.
Быстро рассчитать стоимость ресурсов облака поможет калькулятор на сайте ActiveCloud — есть возможность сразу учесть в расчете резервное копирование, техническую поддержку, лицензии на операционную систему и другие опции. Если у вас есть потребность сравнить стоимость владения облачной и собственной инфраструктурой в деталях – напишите на dmitriy.yashin@activecloud.ru.
Комментарии (32)

alex_kag
28.06.2018 17:54+1А что вообще переносят в облака? Я имею в в виду какие сервисы? Вряд ли в облака отдают контроллеры домена и прочую инфраструктуру?
Gasaraki
28.06.2018 17:59Вполне можно и контроллеры домена. В принципе тебя никто не ограничивает. Например у тебя пара офисов — поднимаешь в облаке домен контроллер, поднимаешь до него туннели и все офисы у тебя оказываются в домене. Для резерва можешь поднять еще один домен контроллер в другом облаке и сделать перекрестные туннели.
navion
28.06.2018 20:25Будет неприятно, когда он свалится в DSRM. В Azure хоть сделали текстовую консоль через последовательный порт, а в AWS и того нет.
cyreex
29.06.2018 17:35Конкретно в облаках ActiveCloud такой проблемы нет — везде доступна консоль VM. Для VmWare и KVM — через браузер. Для Azure Pack — через RDP клиент.
Nimo_tsi
28.06.2018 20:50Видеонаблюдение, например, типа Ivideon, IPeye, Macrosop и т.п (VSaaS). Хранение архивов в облаке, плюс аналитика на облачных серверах. Не требуются ни локальные сервера, ни видеорегистраторы, ни мутки с VPN и т.п. Очень удобно иметь доступ ко всем камерам через один ЛК или мобильное приложение. Особенно для территориально распределенных организаций, торговых сетей и т.п. Очень динамично растет пока этот сегмент.
click0
29.06.2018 05:29Как только размер камеры превосходить 640 пикселей по одной стороне, так сразу маркетологи не гарантируют доставку видео до облака.
А камеры по-прежнему шлют потоки по udp и поэтому очень сильно все зависит от качества интерне-соединения между камерами и «облаками».
c1airvoyant Автор
29.06.2018 12:18На самом деле размещают практически все — как инфраструктурные системы, так и бизнес-приложения. Многие оставляют у себя на земле только небольшой базовый набор из дополнительного контроллера домена и принт-сервера, а то и просто VPN-шлюзом ограничиваются. У нас как-то был подобный проект — Заказчику нужно было переехать в новый офис, где не было места для серверов вообще — только небольшой шкаф для коммутаторов и пограничного шлюза.
Gasaraki
28.06.2018 17:56+1Практика показывает, что серверы архитектуры x86 не стоит постоянно нагружать более чем на 70-80% по процессору и 80-90% по памяти
Провайдеры очень любят делать оверселлинг на виртуалках т.к. это способ сэкономить на оборудовании. И vmware это очень даже хорошо позволяет делать. Заказчик это никак не отследит.
На тему капитальных затрат на оборудование — никто не мешает брать сервера в аренду, прямо в цодах. И это дешевле IaaS.
На тему дешевизны чужого облака — если ваши ресурсы укладываются в 1-2 железных сервера, то скорее всего у вас уже есть инженер на обслуживание этих ресурсов и переезд в чужое облако никуда этого инженера не денет. И с большой долей вероятности аренда резервного сервера будет стоить дешевле переезда в чужое облако. А в РФ возможно покупка серверов и установка в цоде отобьется уже через год.
Если у вас нету данных которые надо хранить на территории РФ, тогда вам прямой путь в европейские цоды. Они не стремятся окупить все железо за пол года и даже с учетом курса валюты, выделенные серверы там получается существенно дешевле.
Если у вас неравномерная нагрузка, тогда возможно вас спасут железные сервера на чуть выше минимальной нагрузки + для пиков нагрузки можно автоматически брать в аренду виртуалки.
Если у вас вобще неравномерная нагрузка, либо вам не хочется заниматься гибридной инфраструктурой, или не иметь геморроя с железом тогда облака ваш выход.
И не надо считать, что вам не придется периодически искать и решать нетривиальные проблемы — почему у вас так странно ведет себя приложение или трафик у облачного провайдера (у нас например диски от сервера с базой отваливались), кто виноват и что делать.Spline
29.06.2018 12:20CPU Steal time. Отслеживание оверселлинга. У меня на AWS до 80% доходило на американском сегменте в конфигурациях, доступных для free tier.
c1airvoyant Автор
29.06.2018 13:06По поводу оверселлинга:
Разные облака рассчитаны для разных задач, поэтому не могу назвать оверселлинг каким-то абсолютным злом. К примеру, если вам нужно разместить не особо нагруженный сайт, то вся мощь ядер вам не нужна, и оверселлинг у провайдера специализированного веб-хостинга позволит купить услугу дешевле.
С технической же точки зрения оверселлинг является неотъемлемой частью многих современных облачных платформ — процессорные ресурсы объединяются в ресурсный пул и раздаются в виде пула гигагерцев Заказчикам. Сопоставление физических и виртуальных ядер используется достаточно редко. Как правило это делается в частных инсталляциях специализированных бизнес-приложений, чтобы сохранить поддержку вендора.
«Честные» ядра нужны в облаках, рассчитанных на корпоративные приложения. В этом случае «честность» обеспечивается контролем предельной утилизации CPU на хосте, мониторингом доступность физического процессора для ВМ (CPU ready), а также, как верно написал Spline, периодическими замерами CPU steal time.
Заказчик вполне может контролировать оверселлинг — либо делая собственные замеры, либо запрашивая графики мониторинга у провайдера.
sizziff
28.06.2018 21:55+11. Не учитываются ресурсы, требуемые для обеспечения отказоустойчивости…
А в облаке как они учтены? В облаке что все машины сразу в фул толеранс? Или облако автоматом для каждой первой машины по две реплики на разных сайтах держит?
Опять взяли за основу кейс аномально быстрорастущего стартапа и пытаются натянуть его на все что движется…c1airvoyant Автор
29.06.2018 12:36Нет, машины не в фулл толеранс, к сожалению, т.к. эта технология пока слабо применима в облаках — такое делаем пока только в рамках частной инсталляции. С репликами на разных сайтах проще, но это все-таки уже катастрофоустойчивость, поэтому предлагается в виде платной опции.
Под ресурсами для отказоустойчивости понимаем гарантию наличия ресурсов для работы виртуальных машин при любой поломке. Это достигается резервными свободными хостами в кластерах виртуализации и регламентами по предельной загрузке продуктивного оборудования.Fortop
29.06.2018 17:34А можно узнать какой лимит резервных свободных хостов и какие нормативы по предельной загрузке в вашем облаке?
Yo1
28.06.2018 22:19+1Например, если покупаем 5 серверов с 40 процессорными ядрами и 256 ГБ RAM, то и у облачного провайдера запрашиваем аналогичные ресурсы (40*5=200 vCPU + 256*5=1280 ГБ vRAM)
это как у вас вышло 5*40 полновесных ядер = 200 vCPU !? vCPU у амазона и гугла это hardware thread, а не то что вы подумали.
arilou_camper
29.06.2018 00:23А трафик у вас, как в Амазоне, в 3-4 раза дороже?
c1airvoyant Автор
29.06.2018 12:26Нет, мы не берем дополнительную плату за траффик. Каких-то лимитов по объему месячного траффика также не устанавливаем. У нас, конечно, есть механизмы защиты от DDoS для внешних и внутренних атак, направленных на переполнение каналов, но если траффик валидный, то не лимитируем. И в целом избегаем каких-то скрытых платежей.
VolCh
29.06.2018 09:27+1Насчёт бюджетов в корпорациях: если покупка или аренда серверов требует тендеров и много месячных согласований, то и выбор облачного провайдера их потребует, причём тендер проводить каждый раз при увеличении ресурсов, а не так что один раз согласовал на 1000 в месяц, а потом молча оплачивают счёта на миллион.
c1airvoyant Автор
29.06.2018 17:05Сильно зависит от конкретной компании, но в целом да — тенденция ужесточения внутреннего контроля в корпорациях прослеживается, и тендер при выборе облачного провайдера как правило приходится играть. Другое дело, что компании в облако чаще заезжают сразу большим количеством ресурсов. Т.е. сначала берут, условно, на 200 тысяч, а потом по мере необходимости периодически расширяют по 20 уже без тендера.
Тендерную же процедуру просто повторяют периодически — кто-то раз в год, кто-то раз в 3 года, но при этом используют уже готовые тендерные документы с небольшими правками.
Pulso
29.06.2018 16:43Есть Azure Stack?
c1airvoyant Автор
29.06.2018 16:50Нет, Azure Stack пока опасаемся. Нужно понять динамику и вектор развития платформы — как быстро и в каком объеме сервисы большого Azure будут переноситься в Stack, не останутся ли через год-два обладатели Stack-инсталляций без полноценной поддержки с обновлением функционала и т.п.
cyreex
29.06.2018 17:27Да, мы еще помним про Azure Pack, последнее обновления для которого вышло года полтора назад, хотя обещали поддержку аж до 2027 года. Еще про Azure Stack надо помнить, что там довольно высокие CAPEX и OPEX. Ценник для конечного клиента, вероятно, будет просто огромный, дороже чем в Microsoft Azure. Вот тут можно посмотреть стоимость лицензий.
divaka
29.06.2018 17:50А как обстоят дела с ИБ. Любая служба корпоративной защиты завернет все облака на свои сервера.
vanxant
30.06.2018 00:451. Не любая.
2. Есть облака, сертифицированные по всяким разным стандартам типа PCI DSS, БиоПД, ФСТЭК и т.д. Причем свой ДЦ еще тоже надо сертифицировать, что непросто и небыстро.
3. Для параноид-режима, типа крупных банков, возможно физическое огораживание стоек в ДЦс автоматчиками по периметру. Хотя это уже не облака, а колок/аренда.
kt97679
30.06.2018 01:53Прямо сейчас я участвую в планировании миграции из собственного датацентра в aws. По самым оптимистичным прикидкам за aws придется платить минимум в 2.5 раза больше, чем за собственный датацентр. Опытные люди говорят, что финальная разница будет еще больше. При этом единственный весомый плюс от миграции будет мгновенная доступность новых машин когда они понадобятся.
Alliceinwonders
30.06.2018 11:20Вы не учли, что при переносе существующих решений в облако без коренной переработки архитектуры мы получаем самый обыкновенный хостинг у провайдера, и тут нет ничего от облаков. Выгода этого варианта сомнительна. Используется как раз при быстром наращивании мощностей стартапов или как временная мера при гибридном решении, пока не приехали сервера в свою серверную.
Для получения экономической выгоды от облаков необходимо часто в корень перерабатывать архитектуру всей инфраструктуры. Тут речь не о корпоративном портале или веб сайте компании, а о кейсах когда у компании 20+ различных решений используется. Переработка архитектуры будет стоить дороже чем выгода от экономии серверов или своей новой серверной. Окупится, может быть, через пять лет. Инвестиции на такой период с такими высокими рисками внедрения бизнес не любит.
Staff OpEx уже занимает серьезную долю бюджета и, не редко, даже людей быстро нанять сложнее чем купить сервера :)kt97679
30.06.2018 18:26Подпишусь под каждым словом. И добавлю, что надо менять менталитет разработчиков на тему экономии ресурсов. Нужно сделать эксперимент — поднял сервер, проверил, что надо, отдал сервер. Потому как я сейчас наблюдаю картину, когда на собственной инфраструктуре вирртуализации заброшенный тестовый сервер может крутиться годами. Ну и еще надо думать о vendor locking, хотя возможно это больше относится к провайдерам типа гугла и амазона.
Hardened
30.06.2018 20:08Давать Storage SLA по средней latency — дурной тон. На Хабре было значительное количество статей, почему.
paranoya_prod
Это всё хорошо, когда ничего нет. А когда всё уже есть — резервы, серверная и т.д.?
mickvav
Докупают ещё десяток серверов в свободные юниты и сами становятся «облачным провайдером»
c1airvoyant Автор
Сильно зависит от ситуации — как давно построена серверная, сколько лет оборудованию и пр. Если свое железо покупалось сравнительно недавно, то отказываться от него не нужно — лучше перевезти его в тот же датацентр, где находится облако выбранного провайдера, и организовать гибрид с облаком. В этом случае вы получите и гибкость облака, и ваше оборудование сможет отработать положенное, после чего также заменится на ресурсы провайдера.
С недавно построенной серверной несколько сложнее, но как вариант — использовать ее в качестве резервной площадки, либо арендовать оптику до облака и также организовать гибрид.
paranoya_prod
Перевести своё к провайдеру!? o_O
Я в Сочи, провайдер, к примеру, в Москве, какое ещё «перевезти»?
Недавняя серверная уже с резервом, зачем мне резерв резерва?