Эта статья основана на докладе Ивана Глушкова (gli) на конференции DevOops 2017. Последние два места работы Ивана так или иначе были связаны с Kubernetes: и в Postmates, и в Machine Zone он работал в инфракомандах, и Kubernetes они затрагивают очень плотно. Плюс, Иван ведет подкаст DevZen. Дальнейшее изложение будет вестись от лица Ивана.

Сперва я пробегусь вкратце по области, почему это полезно и важно для многих, почему этот хайп возникает. Потом расскажу про наш опыт использования технологии. Ну и потом выводы.
В этой статье все слайды вставлены как картинки, но иногда хочется что-нибудь скопировать. Например, там будут примеры с конфигами. Слайды в PDF можно скачать по ссылке.
Я не буду строго всем говорить: обязательно используйте Kubernetes. Есть и плюсы, и минусы, поэтому, если вы пришли искать минусы, вы их найдете. Перед вами выбор, смотреть только на плюсы, только на минусы или в целом смотреть на все вместе. Плюсы мне будет помогать показывать Simon Cat, и черная кошка будет перебегать дорогу, когда есть минус.

Итак, почему вообще произошел этот хайп, почему технология Х лучше, чем Y. Kubernetes — это точно такая же система, и существует их гораздо больше, чем одна штука. Есть Puppet, Chef, Ansible, Bash+SSH, Terraform. Мой любимый SSH помогает мне сейчас, зачем мне переходить куда-то. Я считаю, что критериев много, но я выделил самые важные.
Время от коммита до релиза — очень хорошая оценка, и ребята из Express 42 — большие эксперты в этом. Автоматизация сборки, автоматизация всего pipeline — это очень хорошая вещь, нельзя её перехвалить, она на самом деле помогает. Continuous Integration, Continuous Deployment. И, конечно же, сколько усилий вы потратите на то, чтобы все сделать. Все можно написать на Ассемблере, как я говорю, систему деплоймента тоже, но удобства это не добавит.

Короткую вводную в Kubernetes я рассказывать не буду, вы знаете, что это такое. Я немного коснусь этих областей дальше.
Почему всё это так важно для разработчиков? Для них важна повторяемость, то есть если они написали какое-то приложение, запустили тест, оно будет работать и у вас, и у соседа, и в продакшне.
Второе — стандартизированное окружение: если вы изучили Kubernetes и пойдете соседнюю компанию, где есть Kubernetes, там будет всё то же самое. Упрощение процедуры тестирования и Continuous Integration — это не прямое следствие использования Kubernetes, но всё равно это упрощает задачу, поэтому всё становится удобнее.

Для релиз-разработчиков гораздо больше плюсов. Во-первых, это иммутабельная инфраструктура.
Во-вторых, инфраструктура как код, который где-то хранится. В-третьих, идемпотентность, возможность добавить релиз одной кнопкой. Откаты релизов происходят достаточно быстро, и интроспекция системы достаточно удобная. Конечно, все это можно сделать и в вашей системе, написанной на коленке, но вы не всегда можете это сделать правильно, а в Kubernetes это уже реализовано.
Чем Kubernetes не является, и что он не позволяет делать? Есть много заблуждений на этот счет. Начнем с контейнеров. Kubernetes работает поверх них. Контейнеры — не легковесные виртуальные машины, а совсем другая сущность. Их легко объяснить с помощью этого понятия, но на самом деле это неправильно. Концепция совершенно другая, её надо понять и принять.
Во-вторых, Kubernetes не делает приложение более защищенным. Он не делает его автоматически скалируемым.
Нужно сильно постараться, чтобы запустить Kubernetes, не будет так, что «нажал кнопку, и все автоматически заработало». Будет больно.

Наш опыт. Мы хотим, чтобы вы и все остальные ничего не ломали. Для этого нужно больше смотреть по сторонам — и вот наша сторона.

Во-первых, Kubernetes не ходит в одиночку. Когда вы строите структуру, которая будет полностью управлять релизами и деплоями, вы должны понимать, что Kubernetes — один кубик, а таких кубиков должно быть 100. Чтобы все это построить, нужно все это сильно изучить. Новички, которые будут приходить в вашу систему, тоже будут изучать этот стек, огромный объем информации.
Kubernetes — не единственный важный кубик, есть много других важных кубиков вокруг, без которых система работать не будет. То есть нужно очень сильно беспокоиться об отказоустойчивости.

Из-за этого Kubernetes'у минус. Система сложная, нужно много о чем заботиться.

Но есть и плюсы. Если человек изучил Kubernetes в одной компании, в другой у него не встанут волосы дыбом из-за системы релизов. С течением времени, когда Kubernetes захватит большее пространство, переход людей и обучение будет более простым. И за это — плюс.


Мы используем Helm. Это система, которая строится поверх Kubernetes, напоминает пакетный менеджер. Вы можете нажать кнопку, сказать, что хотите установить *Wine* в свою систему. Можно устанавливать и в Kubernetes. Оно работает, автоматически скачает, запустит, и все будет работать. Он позволяет работать с плагинами, клиент-серверная архитектура. Если вы будете с ним работать, рекомендуем запускать один Tiller на namespace. Это изолирует namespace друг от друга, и поломка одного не приведет к поломке другого.

На самом деле система очень сложная. Система, которая должна быть абстракцией более высокого уровня и более простой и понятной, на самом деле не делает понятнее нисколечко. За это минус.

Давайте сравним конфиги. Скорее всего, у вас тоже есть какие-то конфиги, если вы запускаете в продакшне вашу систему. У нас есть своя система, которая называется BOOMer. Я не знаю, почему мы ее так назвали. Она состоит из Puppet, Chef, Ansible, Terraform и всего остального, там большой флакон.

Давайте посмотрим, как оно работает. Вот пример реальной конфигурации, которая сейчас работает в продакшне. Что мы здесь видим?
Во-первых, мы видим, где запускать приложение, во-вторых, что надо запускать, и, в-третьих, как это надо подготовить к запуску. В одном флаконе уже смешаны концепции.

Если мы посмотрим дальше, из-за того, что мы добавили наследование, чтобы сделать более сложные конфиги, мы должны посмотреть на то, что находится в конфиге common, на который ссылаемся. Плюс, мы добавляем настройку сетей, прав доступа, планирование нагрузки. Все это в одном конфиге, который нам нужен для того, чтобы запустить реальное приложение в продакшне, мы смешиваем кучу концепций в одном месте.
Это очень сложно, это очень неправильно, и в этом огромный плюс Kubernetes, потому что в нем вы просто определяете, что запустить. Настройка сети была выполнена при установке Kubernetes, настройка всего provisioning решается с помощью докера — у вас произошла инкапсуляция, все проблемы каким-то образом разделились, и в данном случае в конфиге есть только ваше приложение, и за это плюс.

Давайте посмотрим внимательнее. Здесь у нас есть только одно приложение. Чтобы заработал деплоймент, нужно, чтобы работала еще куча всего. Во-первых, нужно определить сервисы. Каким образом к нам поступают секреты, ConfigMap, доступ к Load Balancer.

Не стоит забывать, что у вас есть несколько окружений. Есть Stage/Prod/Dev. Это все вместе составляет не маленький кусочек, который я показал, а огромный набор конфигов, что на самом деле сложно. За это минус.

Helm-шаблон для сравнения. Он полностью повторяет шаблоны Kubernetes, если есть какой-то файл в Kubernetes с определением деплоймента, то же самое будет в Helm. Вместо конкретных значений для окружения у вас есть шаблоны, которые подставляются из values.
У вас есть отдельно шаблон, отдельно значения, которые должны подставиться в этот шаблон.
Конечно, нужно дополнительно определить различную инфраструктуру самого Helm, притом что у вас в Kubernetes масса конфигурационных файлов, которые нужно перетащить в Helm. Это все очень непросто, за что минус.
Система, которая должна упрощать, на самом деле усложняет. Для меня это явный минус. Либо нужно надстраивать что-то еще, либо не использовать
Давайте пойдем поглубже, мы недостаточно глубоко.

Во-первых, как мы работаем с кластерами. Я прочитал статью Гугла «Borg, Omega и Kubernetes», в ней очень сильно защищают концепцию, что нужно иметь один большой кластер. Я тоже был за эту идею, но, в конце концов, мы от неё ушли. В результате наших споров, используем четыре разных кластера.
Первый кластер e2e, для тестирования самого Kubernetes и тестирования скриптов, разворачивающих окружение, плагины и так далее. Второй, конечно же, prod и stage. Это стандартные концепции. В-третьих, это admin, в котором сгрузилось все остальное — в частности, у нас там CI, и, похоже, из-за него этот кластер будет самым большим всегда.
Тестирований очень много: по коммиту, по merge, все делают кучу коммитов, поэтому кластеры просто громадные.

Мы пытались посмотреть на CoreOS, но не стали ее использовать. У них внутри TF или CloudFormation, и то и другое очень плохо позволяет понимать, что находится внутри state. Из-за этого возникают проблемы при обновлении. Когда вы хотите обновить настройки вашего Kubernetes, к примеру, его версию, можно столкнуться с тем, что обновление происходит не таким образом, не в той последовательности. Это большая проблема стабильности. Это минус.

Во-вторых, когда вы используете Kubernetes, нужно откуда-то скачивать образы. Это может быть внутренний источник, репозиторий, или внешний. Если внутренний, есть свои проблемы. Я рекомендую использовать Docker Distribution, потому что она стабильная, её сделал Docker. Но цена поддержки все равно высокая. Чтобы она работала, нужно сделать ее отказоустойчивой, потому что это единственное место, откуда ваши приложения получают данные для работы.

Представьте, что в самый ответственный момент, когда вы нашли баг на продакшне, у вас репозиторий упал — приложение обновить вы не сможете. Вы должны сделать его отказоустойчивым, причем от всех возможных проблем, которые только могут быть.
Во-вторых, если масса команд, у каждой свой образ, их накапливается очень много и очень быстро. Можно убить свой Docker Distribution. Нужно делать чистку, удалять образы, выносить информацию для пользователей, когда и что вы будете чистить.
В-третьих, при больших образах, скажем, если у вас есть монолит, размер образа будет очень большим. Представьте, что нужно зарелизить на 30 нод. 2 гигабайта на 30 нод — посчитайте, какой поток, как быстро он скачается на все ноды. Хотелось бы, чтобы нажал кнопку, и тут же зарелизилось. Но нет, нужно сначала дождаться, пока закачается. Надо как-то ускорять эту закачку, а все это работает с одной точки.

При внешних репозиториях есть те же проблемы с garbage collector, но чаще всего это делается автоматически. Мы используем Quay. В случае с внешними репозиториями — это сторонние сервисы, в которых большинство образов публичные. Чтобы не было публичных образов, нужно обеспечивать доступ. Нужны секреты, права доступа к образам, все это специально настраивать. Конечно, это можно автоматизировать, но в случае локального запуска Куба на своей системе вам все равно его придется настраивать.

Для установки Kubernetes мы используем kops. Это очень хорошая система, мы ранние пользователи с тех времен, когда они еще в блоге не писали. Она не до конца поддерживает CoreOS, хорошо работает с Debian, умеет автоматически конфигурировать мастер-ноды Kubernetes, работает с аддонами, есть способность делать нулевое время простоя во время обновления Kubernetes.
Все эти возможности из коробки, за что большой и жирный плюс. Отличная система!


По ссылкам можно найти много вариантов для настройки сети в Kubernetes. Их реально много, у всех свои достоинства и недостатки. Kops поддерживает только часть из этих вариантов. Можно, конечно, донастроить, чтобы работал через CNI, но лучше использовать самые популярные и стандартные. Они тестируются сообществом, и, скорее всего, стабильны.

Мы решили использовать Calico. Он заработал хорошо с нуля, без большого количества проблем, использует BGP, быстрее инкапсуляции, поддерживает IP-in-IP, позволяет работать с мультиклаудами, для нас это большой плюс.
Хорошая интеграция с Kubernetes, с помощью меток разграничивает трафик. За это — плюс.
Я не ожидал, что Calico дойдет до состояния, когда включил, и все работает без проблем.

High Availability, как я говорил, мы делаем через kops, можно использовать 5-7-9 нод, мы используем три. Сидим на etcd v2, из-за бага не обновлялись на v3. Теоретически, это позволит ускорить какие-то процессы. Я не знаю, сомневаюсь.

Хитрый момент, у нас есть специальный кластер для экспериментов со скриптами, автоматическая накатка через CI. Мы считаем, что у нас есть защита от совершенно неправильных действий, но для каких-то специальных и сложных релизов мы на всякий случаем делаем снапшоты всех дисков, мы не делаем бэкапов каждый день.


Авторизация — вечный вопрос. Мы в Kubernetes используем RBAC — доступ, основанный на ролях. Он намного лучше ABAC, и если вы его настраивали, то понимаете, о чем я. Посмотрите на конфиги — удивитесь.
Мы используем Dex, провайдер OpenID, который из какого-то источника данных выкачивает всю информацию.
А для того, чтобы залогиниться в Kubernetes, есть два пути. Нужно как-то прописать в .kube/config, куда идти и что он может делать. Нужно этот конфиг как-то получить. Либо пользователь идет в UI, где он логинится, получает конфиги, копипастит их в /config и работает. Это не очень удобно. Мы постепенно перешли к тому, что человек заходит в консоль, нажимает на кнопку, логинится, у него автоматически генерируются конфиги и складываются в нужное место. Так гораздо удобнее, мы решили действовать таким образом.

В качестве источника данных мы используем Active Directory. Kubernetes позволяет через всю структуру авторизации протащить информацию о группе, которая транслируется в namespace и роли. Таким образом сразу разграничиваем, куда человек может заходить, куда не имеет права заходить и что он может релизить.

Чаще всего людям нужен доступ к AWS. Если у вас нет Kubernetes, есть машина с запущенным приложением. Казалось бы, все что нужно — получать логи, смотри их и все. Это удобно, когда человек может зайти на свою машину и посмотреть, как работает приложение. С точки зрения Kubernetes все работает в контейнерах. Есть команда `kubectl exec` — залезть в контейнер в приложение и посмотреть, что там происходит. Поэтому на AWS-инстансы нет необходимости ходить. Мы запретили доступ для всех, кроме инфракоманды.
Более того, мы запретили долгоиграющие админские ключи, вход через роли. Если есть возможность использовать роль админа — я админ. Плюс мы добавили ротацию ключей. Это удобно конфигурировать через команду awsudo, это проект на гитхабе, очень рекомендую, позволяет работать, как с sudo-командой.



Квоты. Очень хорошая штука в Kubernetes, работает прямо из коробки. Вы ограничиваете какие-то namespace, скажем, по количеству объектов, памяти или CPU, которое можете потреблять. Я считаю, что это важно и полезно всем. Мы пока не дошли до памяти и CPU, используем только по количеству объектов, но это все добавим.
Большой и жирный плюс, позволяет сделать много хитрых вещей.


Масштабирование. Нельзя смешивать масштабирование внутри Kubernetes и снаружи Kubernetes. Внутри Kubernetes делает масштабирование сам. Он может увеличивать pod'ы автоматически, когда идет большая нагрузка.
Здесь я говорю про масштабирование самих инстансов Kubernetes. Это можно делать с помощью AWS Autoscaler, это проект на гитхабе. Когда вы добавляете новый pod и он не может стартовать, потому что ему не хватает ресурсов на всех инстансах, AWS Autoscaler автоматически может добавить ноды. Позволяет работать на Spot-инстансах, мы пока это не добавляли, но будем, позволяет сильно экономить.


Когда у вас очень много пользователей и приложений у пользователей, нужно как-то за ними следить. Обычно это телеметрия, логи, какие-то красивые графики.

У нас по историческим причинам был Sensu, он не очень подошел для Kubernetes. Нужен было более метрикоориентированный проект. Мы посмотрели на весь TICK стек, особенно InfluxDB. Хороший UI, SQL-подобный язык, но не хватило немножко фич. Мы перешли на Prometheus.
Он хорош. Хороший язык запросов, хорошие алерты, и все из коробки.

Чтобы посылать телеметрию, мы использовали Cernan. Это наш собственный проект, написанный на Rust. Это единственный проект на Rust, который уже год работает в нашем продакшне. У него есть несколько концепций: есть концепция источника данных, вы конфигурируете несколько источников. Вы конфигурируете, куда данные будете сливать. У нас есть конфигурация фильтров, то есть перетекающие данные можно каким-то образом перерабатывать. Вы можете преобразовывать логи в метрики, метрики в логи, все, что хотите.
При том, что у вас несколько входов, несколько выводов, и вы показываете, что куда идет, там что-то вроде большой системы графов, получается довольно удобно.

Мы сейчас плавно переходим с текущего стека Statsd/Cernan/Wavefront на Kubernetes. Теоретически, Prometheus хочет сам забирать данные из приложений, поэтому во все приложения нужно добавлять endpoint, из которого он будет забирать метрики. Cernan является передаточным звеном, должен работать везде. Тут две возможности: запускать на каждом инстансе Kubernetes, можно с помощью Sidecar-концепции, когда в вашем поле данных работает еще один контейнер, который посылает данные. Мы делаем и так, и так.

У нас прямо сейчас все логи шлются в stdout/stderr. Все приложения рассчитаны на это, поэтому одно из критических требований, чтобы мы не уходили от этой системы. Cernan посылает данные в ElasticSearch, события всей системы Kubernetes посылают туда же с помощью Heapster. Это очень хорошая система, рекомендую.
После этого все логи вы можете посмотреть в одном месте, к примеру, в консоли. Мы используем Kibana. Есть замечательный продукт Stern, как раз для логов. Он позволяет смотреть, раскрашивает в разные цвета разные поды, умеет видеть, когда один под умер, а другой рестартовал. Автоматически подхватывает все логи. Идеальный проект, очень его рекомендую, это жирный плюс Kubernetes, здесь все хорошо.


Секреты. Мы используем S3 и KMS. Думаем о переходе на Vault или секреты в самом Kubernetes. Они были в 1.7 в состоянии альфы, но что-то делать с этим надо.

Мы добрались до интересного. Разработка в Kubernetes вообще мало рассматривается. В основном говорится: «Kubernetes — идеальная система, в ней все хорошо, давайте, переходите».
Но на самом деле бесплатный сыр только в мышеловке, а для разработчиков в Kubernetes — ад.

Не с той точки зрения, что все плохо, а с той, что надо немножко по-другому взглянуть на вещи. Я разработку в Kubernetes сравниваю с функциональным программированием: пока ты его не коснулся, ты думаешь в своем императивном стиле, все хорошо. Для того, чтобы разрабатывать в функциональщине, надо немножко повернуть голову другим боком — здесь то же самое.
Разрабатывать можно, можно хорошо, но нужно смотреть на это иначе. Во-первых, разобраться с концепцией Docker Way. Это не то чтобы сложно, но до конца ее понять довольно проблематично. Большинство разработчиков привыкло, что они заходят на свою локальную, удаленную или виртуальную машину по SSH, говорят: «Давай я тут кое-что подправлю, подшаманю».
Ты говоришь ему, что в Kubernetes так не будет, потому что у тебя read only инфраструра. Когда ты хочешь обновить приложение, пожалуйста, сделай новый образ, который будет работать, а старый, пожалуйста, не трогай, он просто умрет. Я лично работал над внедрением Kubernetes в разные команды и вижу ужас в глазах людей, когда они понимают, что все старые привычки придется полностью отбросить, придумать новые, новую систему какую-то, а это очень сложно.
Плюс придется много делать выборов: скажем, когда делаешь какие-то изменения, если разработка локальная, нужно как-то коммитить в репозиторий, затем репозиторий по pipeline прогоняет тесты, а потом говорит: «Ой, тут опечатка в одном слове», нужно все делать локально. Монтировать каким-то образом папку, заходить туда, обновлять систему, хотя бы компилировать. Если тесты запускать локально неудобно, то может коммитить в CI хотя бы, чтобы проверять какие-то локальные действия, а затем уже отправлять их в CI на проверку. Эти выборы достаточно сложные.
Особенно сложно, когда у вас развесистое приложение, состоящее из ста сервисов, а чтобы работал один из них, нужно обеспечить работу всех остальных рядышком. Нужно либо эмулировать окружение, либо как-то запускать локально. Весь этот выбор нетривиальный, разработчику об этом нужно сильно думать. Из-за этого возникает негативное отношение к Kubernetes. Он, конечно, хорош — но он плох, потому что нужно много думать и изменять свои привычки.
Поэтому здесь три жирных кошки перебежали через дорогу.


Когда мы смотрели на Kubernetes, старались понять, может, есть какие-то удобные системы для разработки. В частности, есть такая вещь, как Deis, наверняка вы все про нее слышали. Она очень проста в использовании, и мы проверили, на самом деле, все простые проекты очень легко переходят на Deis. Но проблема в том, что более сложные проекты могут на Deis не перейти.
Как я уже рассказал, мы перешли на Helm Charts. Но единственная проблема, которую мы сейчас видим — нужно очень много хорошей документации. Нужны какие-то How-to, какие-то FAQ, чтобы человеку быстро стартовать, скопировать текущие конфиги, вставить свои, поменять названия для того, чтобы все было правильно. Это тоже важно понимать заранее, и нужно это все делать. У меня здесь перечислены общие наборы инструментов для разработки, всего этого не коснусь, кроме миникуба.

Minikube — очень хорошая система, в том смысле, что хорошо, что она есть, но плохо, что в таком виде. Она позволяет запускать Kubernetes локально, позволяет видеть все на вашем лэптопе, не надо никуда ходить по SSH и так далее.
Я работаю на MacOS, у меня Mac, соответственно, чтобы запускать локальный апп, мне нужно запускать локально докер. Это сделать никак нельзя. В итоге нужно либо запускать virtualbox, либо xhyve. Обе вещи, фактически, эмуляции поверх моей операционной системы. Мы используем xhyve, но рекомендуем использовать VirtualBox, поскольку очень много багов, их приходится обходить.
Но сама идея, что есть виртуализации, а внутри виртуализации запускается еще один уровень абстракции для виртуализации, какая-то нелепая, бредовая. В целом, хорошо, что он как-то работает, но лучше бы его еще доделали.


CI не относится напрямую к Kubernetes, но это очень важная система, особенно, если у вас есть Kubernetes, если ее интегрировать, можно получать очень хорошие результаты. Мы использовали Concourse для CI, очень богатая функциональность, можно строить страшные графы, что, откуда, как запускается, от чего зависит. Но разработчики Concourse очень странно относятся к своему продукту. Скажем, при переходе от одной версии на другую они поломали обратную совместимость и большинство плагинов не переписали. Более того, документацию не дописали, и, когда мы попытались что-то сделать, вообще ничего не заработало.
Документации мало вообще во всех CI, приходится читать код, и, в общем, мы отказались от Concourse. Перешли на Drone.io — он маленький, очень легкий, юркий, функциональности намного меньше, но чаще всего ее хватает. Да, большие и увесистые графы зависимости — было бы удобно иметь, но и на маленьких тоже можно работать. Тоже мало документации, читаем код, но это ок.
Каждая стадия pipeline работает в своем докер-контейнере, это позволяет сильно упростить переход на Kubernetes. Если есть приложение, которое работает на реальной машине, для того, чтобы добавить в CI, используете докер-контейнер, а после него перейти в Kubernetes проще простого.
У нас настроен автоматический релиз admin/stage-кластера, в продакшн-кластер пока боимся добавлять настройку. Плюс есть система плагинов.
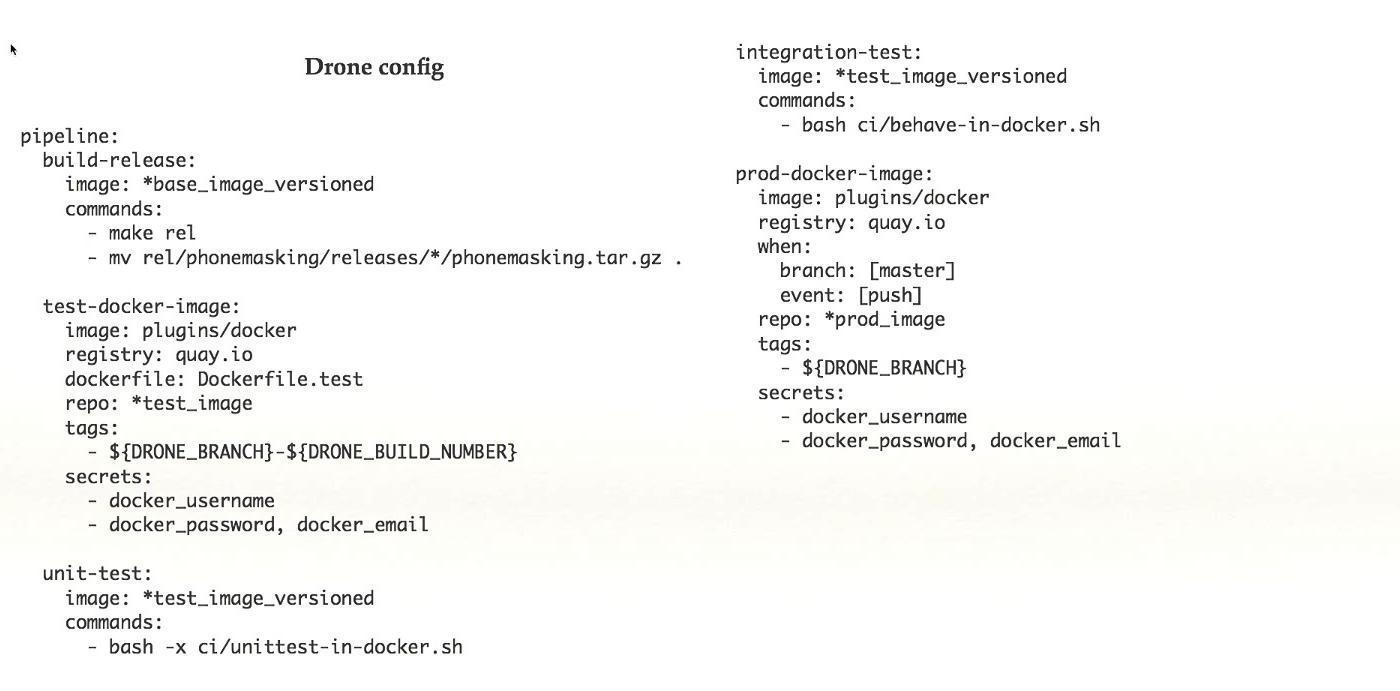
Это пример простого Drone-конфига. Взято из готовой рабочей системы, в данном случае есть пять шагов в pipeline, каждый шаг что-то делает: собирает, тестирует и так далее. При том наборе фич, что есть в Drone, я считаю, что это хорошая штука.

Мы много спорили о том, сколько иметь кластеров: один или несколько. Когда мы пришли к идее с несколькими кластерами, начали дальше работать в этом направлении, создали какие-то скрипты, понаставили кучу других кубиков к нашему Kubernetes. После этого пришли к Google и попросили консультации, все ли сделали так, может, нужно что-то исправить.
Google согласился, что идея одного кластера неприменима в Kubernetes. Есть много недоделок, в частности, работа с геолокациями. Получается, что идея верна, но говорить о ней пока рано. Возможно, попозже. Пока может помочь Service Mesh.

В целом, если хотите посмотреть, как работает наша система, обратите внимание на Geodesic. Это продукт, похожий на тот, что делаем мы. Он с открытыми исходниками, очень похожий выбор концепции дизайна. Мы думаем о том, чтобы объединиться и, возможно, использовать их.

Да, в нашей практике работы с Kubernetes тоже есть проблемы.
Есть боль с локальными именами, с сертификатами. Есть проблема с загрузками больших образов и их работой, возможно, связанная с файловой системой, мы туда еще не копали. Есть уже три разных способа устанавливать расширения Kubernetes. Мы меньше года работаем над этим проектом, и у нас уже три разных способа, годовые кольца растут.

Давайте подобьем все минусы.
Итак, я считаю, что один из главных минусов — большой объем информации на изучение, причем не только новых технологий, но и новых концепций и привычек. Это как новый язык выучить: в принципе, несложно, но сложно немного повернуть голову всем пользователям. Если раньше не работали с подобными концепциями — перейти на Kubernetes тяжело.
Kubernetes будет лишь небольшой частью вашей системы. Все думают, что установят Kubernetes, и всё сразу заработает. Нет, это маленький кубик, и таких кубиков будет много.
Некоторые приложения в принципе сложно запускать на Kubernetes — и лучше не запускать. Также очень тяжелые и большие конфигурационные файлы, и в концепциях поверх Kubernetes они ещё сложнее. Все текущие решения — сырые.
Все эти минусы, конечно, отвратительные.
Компромиссы и сложный переход создают негативный образ Kubernetes, и как с этим бороться — я не знаю. Мы не смогли сильно побороть, есть люди, которые ненавидят все это движение, не хотят и не понимают его плюсы.
Для того, чтобы запустить Minikube, вашу систему, чтобы все работало, придется сильно постараться. Как вы видите, минусов немало, и те, кто не хочет работать с Kubernetes имеют свои причины. Если не хотите слышать про плюсы — закройте глаза и уши, потому что дальше пойдут они.

Первый плюс — с течением времени придется все меньше учить новичков. Часто бывает так, что, придя в систему, новичок начинает вырывать все волосы, потому что первые 1-2 месяца он пытается разобраться, как это все зарелизить, если система большая и живет долго, наросло много годовых колец. В Kubernetes все будет проще.
Во-вторых, Kubernetes не сам делает, но позволяет сделать, короткий цикл релиза. Коммит создал CI, CI создал образ, автоматически подкачался, ты нажал кнопку, и все ушло в продакшн. Это сильно сокращает время релиза.
Следующее — разделение кода. Наша система и большинство ваших систем в одном месте собирают конфиги разных уровней, то есть у вас инфраструктурный код, бизнес код, все логики смешаны в одном месте. В Kubernetes такого не будет из коробки, выбор правильной концепции помогает этого избежать заранее.
Большое и очень активное сообщество, а значит, большое количество изменений. Большинство из того, о чем я упоминал, за последние два года стало настолько стабильным, что их можно выпускать в продакшн. Возможно, часть из них появилась пораньше, но была не очень стабильной.
Я считаю большим плюсом, что в одном месте можно видеть как логи приложения, так и логи работы Kubernetes с вашим приложением, что неоценимо. И нет доступа на ноды. Когда мы убрали у пользователей доступы на ноды, это сразу срезало большой класс проблем.

Вторая часть плюсов немного более концептуальна. Большая часть сообщества Kubernetes видят технологическую часть. Но мы увидели концептуальную менеджмент-часть. После того, как вы перейдете на Kubernetes, и если это все правильно настроить, инфракоманда (или бэкенд — я не знаю, как у вас это называется правильно) больше не нужна для того, чтобы релизить приложения.
Пользователь хочет зарелизить приложение, он не придет с просьбой об этом, а просто запустит новый pod, есть команда для этого. Инфракоманда не нужна для того, чтобы расследовать проблемы. Достаточно посмотреть логи, у нас набор конструкций не такой большой, есть список, по которому найти проблему очень легко. Да, иногда нужна поддержка, если проблема в Kubernetes, в инстансах, но чаще всего проблема с приложениями.
Мы добавили Error Budget. Это следующая концепция: у каждой команды есть статистика, сколько происходит проблем в продакшне. Если проблем происходит слишком много, команде режут релизы, пока не пройдет какое-то время. Это хорошо тем, что команда будет серьезно следить, чтобы их релизы были очень стабильными. Нужна новая функциональность — пожалуйста, релизьте. Хотите релизить в два часа ночи — пожалуйста. Если после релизов у вас в SLA одни «девятки» — делайте, что хотите, все стабильно, можете делать что угодно. Однако, если ситуация хуже, скорее всего, мы не разрешим релизить ничего, кроме фиксов.
Это удобная вещь как для стабильности системы, так и для настроя внутри команды. Мы перестаем быть «Полицией Нравов», не давая релизить поздно вечером. Делайте, что хотите, пока у вас хороший бюджет ошибок. Это сильно сокращает напряжение внутри компании.
Для связи со мной можно использовать почту или написать в Твиттере: @gliush.
И в конце для вас куча ссылок, можете сами всё скачать и посмотреть:
- Container-Native Networking — Comparison
- Continuous Delivery by Jez Humble, David Farley.
- Containers are not VMs
- Docker Distribution (image registry)
- Quay — Image Registry as a Service
- etcd-operator — Manager of etcd cluster atop Kubernetes
- Dex - OpenID Connect Identity (OIDC) and OAuth 2.0 Provider with Pluggable Connectors
- awsudo - sudo-like utility to manage AWS credentials
- Autoscaling-related components for Kubernetes
- Simon’s cat
- Helm: Kubernetes package manager
- Geodesic: framework to create your own cloud platform
- Calico: Configuring IP-in-IP
- Sensu: Open-core monitoring system
- InfluxDB: Scalable datastore for metrics, events, and real-time analytics
- Cernan: Telemetry and logging aggregation server
- Prometheus: Open Source monitoring solution
- Heapster: Compute Resource Usage Analysis and Monitoring of Container Clusters
- Stern: Multi pod and container log tailing for Kubernetes
- Minikube: tool to run Kubernetes locally
- Docker machine driver fox xhyve native OS X Hypervisor
- Drone: Continuous Delivery platform built on Docker, written in Go
- Borg, Omega and Kubernetes
- Container-Native Networking — Comparison
- Bug in minikube when working with xhyve driver.
Минутка рекламы. Если вам понравился этот доклад с конференции DevOops — обратите внимание, что 14 октября в Санкт-Петербурге пройдет новый DevOops 2018, в его программе тоже будет много интересного. На сайте уже есть первые спикеры и доклады.
Комментарии (43)

kvaps
05.07.2018 03:19+1Kubernetes — один кубик, а таких кубиков должно быть 100.
Kubernetes — это не кубик, он скорее каркас для кубиков или даже конструктор)
beduin01
05.07.2018 06:33-3Docker кстати тоже не нужен. Вот аргументы:
Разработчиков пишуших софт, работающий только на побитовых копиях их систем нужно бить плеткой.
— Docker полезен исключительно для воссоздания кривых окружений кривых программ (непременно stateless)
— В подавляющем большинстве случаев люди пытаются внедрением Docker компенсировать изначально кривую архитектуру своих приложенияй. Когда это не помогает начинаются разговоры о том, что Kubernetes поможет решить проблемы, но это приводит лишь к новым сложностям
— Docker вводит лишний уровень абстракции, зачастую там где она не нужна
— Содержимое Docker контейнера крайне плохо поддается аудиту
— Docker крайне не прост в настройке и поддержке. Большинство людей которые все же используют докер редко уходят дальше «Just use the docker image»
— Корректная настройка Docker требует найма дополнительного персонала с очень специфическими навыками. Уметь правильно настраивать сесть != уметь правильно настраивать сесть в Docker
— Docker никогда не бывает один и тянет за собой огромную экосистему. Этим он похож на NodeJS, когда очень скоро оказывается, что ваше Hello World приложение зависит от 300 разных библиотек и плагинов.
— Большинство проблем с масштабированием проще\надежнее решить без использования Docker
источник
Каждая новая абстракция это лишняя точка отказа. Уверен, скоро хайп около докера спадет и куча компаний ужаснется от того, что они наворотили. Перенимая «лучшие практики от Google» люди почему то забывают, что они не Google и даже не Amazon.gli
05.07.2018 09:38+2Всегда надо искать баланс, конечно же.
Да, у докера есть минусы, но большинство перечисленного — это просто перегретая параноя :)
VolCh
05.07.2018 10:37+1Одна из основных целей внедрения докера не перенос окружения разработчика на продакшн, а ровно наоборот. Девелопер или девопс описывают продакшн окружение, которое можно использовать и как девелоперское. И по сути докер не абстракция, а инструмент по типу bash скриптов провижинга и деплоя.
gre
05.07.2018 08:53+1А базы(postgres, elastic) вы держите в кубернетесе или выносите на физ.машины?
onlinehead
05.07.2018 10:31+1В случае облаков проще брать как сервис (если есть).
Если не облака или нет нужно базы — можно внутри, главное чтобы стораджи позволяли динамическое монтирование и имели достаточную скорость.
nlog
05.07.2018 12:15+1Присоединяюсь к вопросу. Хотелось бы узнать, как производится миграция изменений в реляционных БД. Обновление скриптами, дампами, использование утилит миграции типа Liquibase?
gli
05.07.2018 12:24+2Я бы вообще хотел узнать, хоть кто-нибудь запускает уже бд в k8s? Отзовитесь, если такие есть??
onlinehead
05.07.2018 12:59+2Да, запускает:)
Что интересно?gre
05.07.2018 14:35+1* Что используете в качестве файлового стораджа;
* насколько большие базы(ну и тип указать желательно);
* Нет ли проблем с latency / просадок по скорости;
* Насколько стабильно работаютonlinehead
05.07.2018 15:39+1В целом — ничего особенного.
1. EBS/Compute Engine PD в зависимости от облака. На своем — либо то, что предоставляет OpenStack, допустим, либо iSCSI/CephFS. Хотя последний я недолюбливаю, если честно:)
В целом по эксплуатационной части результат примерно один. Есть еще варианты с локальными стораджами.
2. Базы не очень большие, в пределах десятков ГБ. Postgres, Mongo, Elastic.
3. Проблемы есть ровно те же, как и просто с базами на виртуальных машинах. Исключение — сетевой сторадж, он дает задержки, хотя он и на виртуалках бывает. Но тут решается вариантом мультимастер + локальные стораджи с пересозданием при перезапуске. При условии достаточно стабильной инфраструктуры может быть не очень накладным выходом из ситуации.
4. Принципиальных отличий в стабильности от просто баз, развернутых на виртуалках, не находил.
В целом, Kubernetes позволяет повторить практичечески ту же самую конфигурацию БД, что была бы без него, так что каких-то ограничений (как и больших преимуществ) в переносе баз в него я привести не могу.
Fantyk
05.07.2018 10:39+1А можете поподробнее рассказать о Error Budget? Откуда берете приемлемое количество ошибок, как аргументируете бизнесу что «вот сейчас команде релизить нельзя», как пришли с этим к командам и объяснили почему так? И как возникла такая мысль)
onlinehead
05.07.2018 11:52+2За автора не отвечу, но могу рассказать из своего опыта.
Error Budget в целом высчитвывается статистически на основании требований бизнеса и текущей реальности.
Все ошибаются. Иногда что-то идет не так. Это факт. Допустим, мы волевым решением и на основании статистики принимаем решение что 3 релиза из 100 могут пойти не так. То есть для нас Error Budget — 3% (это достаточно высоко, в реальности бюджет не должен превышать 1, максимум 2 процентов).
После этого мы просто начинаем учитывать это в выкатке релизов, т.к. это является аггрегированным показателем качества.
Если ребята катят и не выходят за пределы бюджета, значит в целом качество кода хорошее и можно не боясь катиться практически в любое время.
Если команда начинает выходить за пределы бюджета, то процесс релизов приостанавливается до принятия мер, так как превышение бюджета явно свидетельствует о том, что что-то идет на так в команде, качество когда упало, возникла нестабильность и непонятно где оно стрельнет в следующий раз.
А обоснование для бизнеса простое — мы наблюдаем проблемы с качеством новых версий приложения. Или мы притормаживаем, разбираем инциденты, выясняем проблему и решаем ее, чтобы все было хорошо, или рано или поздно и скорее всего в ближайшее время у нас будут большие проблемы, которые дестабилизируют продукт с непредсказуемыми последствиями. Обычно такого объяснения для бизнеса достаточно, т.к. факты и статистика в наличии и однозначны в трактовке.gli
05.07.2018 12:28+2Все так!
Сперва, конечно, надо заручиться поддержкой бизнеса, но это достаточно легко аргументировать, потому что Error Budget вводится ради стабильности :)
Но мы считаем не проценты «хороших релизов», а просто считаем SLA в наших бизнес метриках (простейшее решение для API: кол-во 5xx / общее кол-во запросов). Все плохие релизы сильно снижают этот SLA.
Далее, мы выбираем, ниже какого SLA мы не разрешаем опускаться, и с помощью метода «пристального взгляда» вычисляем, на каких уровнях мы перестаем разрешать релизить новые фичи.
Лично у нас пока не сложилось до конца понимание, как сделать правильно, все до сих пор в стадии становления.onlinehead
05.07.2018 12:58+1Да, все так, конечно метрика «хороший\плохой» релиз она обобщенная и для понимания. У каждого свои метрики. Но, кстати, метрика "!302/301/200/403"/ «количество запросов» будет немного удачнее, чем «кол-во 5xx / общее кол-во запросов» мне кажется. Но я думаю с вашей стороны это тоже был пример.
А вот с 404 нужно быть аккуратнее, ее можно получить и без проблем в коде, лучше мониторить отдельно и эмперически добавлять к основной именно тогда, когда она вызвана именно продуктом.gli
05.07.2018 15:45+1Да, как пример, это в любом случае все очень сильно зависит от области и от соглашений интерфейса.

q2digger
05.07.2018 15:44+1Немного не понял в статье вот эту часть про minicube
Я работаю на MacOS, у меня Mac, соответственно, чтобы запускать локальный апп, мне нужно запускать локально докер. Это сделать никак нельзя
Вопрос — в чем тут проблема? Если у меня на макбуке стоит докер я не могу использовать minicube?
P.S. докер использую активно, до k8s никак руки не дойдут, хотел поставить minicube — поиграться.onlinehead
05.07.2018 15:48+1На счет поставить minikube, в Docker for Mac он уже есть — docs.docker.com/docker-for-mac/kubernetes, достаточно ткнуть галочку.
Ну и да, никаких проблем в этом нет.
gli
05.07.2018 15:51+11. Я рассказывал этот доклад еще до того момента, когда на MacOS был докер нормальный
2. Я сейчас не использую minikube совсем, мне он кажется не очень удобным. Поэтому я не большой знаток.
3. Если я не ошибаюсь, когда вы устанавливаете minikube, у вас используется один из гипервизоров, установленных на машине (VirtualBox, xhyve, VMWare Fusion), и не использует дефолтный докер. Т.е. у вас будет два разных докера на машине :)
Но я не эксперт в этом, могу и ошибатьсяq2digger
05.07.2018 16:06+1Спасибо. Действительно, после небольшого погружения в вопрос, увидел, что возможность использовать маковский hyperkit появился уже после этого доклада.
minikube start --vm-driver=hyperkit
minikube startgli
05.07.2018 17:31Выше в комментах ответили ссылкой, они уже в комплект докера добавили Kubernetes (Правда, пока только в Edge версию)

k0nst
05.07.2018 15:44+1На мой взгляд самый большой минус k8s — это то, что после весьма солидного времени, которое нужно потратить на порог вхождения в него, ты понимаешь, что впереди придется потратить еще большее количество времени на все то, что вокруг него. Kubernetes без ELK, Prometheus, Grafana, какой-нибуь CI сегодня — ничто. Важен именно интеграционный опыт вокруг Kubernetes, а не способность разбираться в нем самом
gli
05.07.2018 17:33Да, поэтому если команда маленькая — надо пользоваться готовыми инсталяциями: GKE, EKS,…
navion
05.07.2018 19:37Kubernetes без ELK, Prometheus, Grafana, какой-нибуь CI сегодня — ничто.
А для обычных серверов или ВМ это всё не нужно?k0nst
06.07.2018 07:29Нужно конечно. Просто в случае kubernetes, с ELK к примеру, вам понадобится: как минимум настроить провайдер PersistentVolume для самого elasticsearch (я настраивал для Vsphere, та ещё задачка, особенно когда документация безбожно устарела), discovery модуль для filebeat (который будет парсить k8s теги автоматом) В случае Prometheus — это как минимум kube-prometheus и оператор оттуда же. И вот куда не плюнь, везде понадобится нетривиальная настройка для kubernetes. А вот если все это хорошо заведется — профит огромный, все становится очень красиво.
VolCh
Вот почитал и опять пропало желание изучать k8s, которое появилось пару дней назад и было отложено на выходные. Опять подтвердилось впечатление, что для одной системы пускай из полусотни сервисов это из пушки по воробьям с одной стороны, а, с другой, что один человек с нулевыми знаниями по всяким BGB и IP-in-IP и год поднимать может эту систему до состояния «закоммитил-нажал кнопку-задеплоилось». И это уже в докеризированной и кластеризированной системе (docker swarm mode).
Или есть таки разработчики, которые это осилили в одиночку?
divanikus
Я пока на начальной стадии внедрения. Первые впечатления не очень. Ну т.е. для менеджера все выглядит круто, ты можешь ткнуть одну кнопку в «магазине приложений» и вот у тебя уже как-то само собой собрался кластер и даже отвечает на внешние запросы. Но внутри столько движущихся частей, что даже страшно представить что будет если там что-то упадет…
Сам кластер kubernetes очень легко и просто собирает Rancher, но вот дальше…
gli
Это один из самых частых вопросов, который мне задают.
У меня примерно следующее мнение:
— Если работаешь в одиночку, используй k8s, который кто-то другой поддерживает (GKE)
— Если нельзя иметь внешний k8s — обязательно нужно иметь команду, которая умеет его настраивать и отлаживать. Это необходимо, чтобы минимизировать время простоя когда что-то «пойдет не так».
— Если бизнес не требователен к SLA — можно и самому в одиночку настраивать и разбираться.
UPD: я — автор доклада.
onlinehead
Во, хороший шанс обратиться как к автору доклада:
1. Для ускорения получения контейнеров можно использовать Dragonfly. Это P2P система хранения с поддержкой Docker Registry протокола.
2. Kubernetes уже 1.11 вышел. Secret давно стабильны. Плюс еще много чего появилось, но думаю вы вкурсе.
3. Для локальной разработки можно (и возможно нужно) использовать Skaffold. Очень интересная утилитка, поддерживает Helm.
4. Для роутинга между подами и сервисами, ингресов, трейсов и еще кое-чего можно использовать Istio.
5. Споты в Kops тоже конечно же давно есть. Но это опять же, просто презентация старая.
6. На счет глобального роутинга — тут federation конечно поможет, но очень зависит от инфраструктуры под ногами.
7. На счет нескольких кластеров… тут важен объем. В ином случае Labels, Taints, NodeSelectors, Limits и Affinity решают вопросы разделения ресурсов и уплотнения. Но можно и несколько кластеров, конечно. Хотя без всех этих штук все равно сложно обойтись.
8. Автоскейлингом занимается Pod Autoscaler, он platform-agnostic. А вот Node Autoscaler в режиме AWS действительно скелит ноды.
9. У Helm, хоть я его не очень и люблю, есть свои dependency между чартами и hooks, что позволяет деплоить и обновлять продукт вместе со всеми зависимостями в правильном порядке, храня только 1 (ну или сколько удобно) конфигурационный файл для stage. Не очень понятно зачем нужны еще какие-то инструменты поверх него (или рядом).
gli
О, за Dragonfly отдельное спасибо! Мы делали подобную тулзу, но не довели ее до OpenSource, а тут уже готовое.
Да, докладу почти год уже, поэтому много что устарело (показатель активного развития k8s)
Про Helm и все окружение вокруг (Skaffold) я на РИТ++ делал доклад.
rootconf.ru/moscow-rit/2018/abstracts/3539
Видео пока нет, но слайды доступны.
Проблем у Helm много, когда проекты сильно взаимосвязаны, и есть транзитивные зависимости. Их сложно конфигурировать, тестировать (да и разрабатывать).
onlinehead
Посмотрел слайды, любопытно.
Может по слайдам просто непонятно, но я не очень согласен со «Сквозное конфигурирование? Нет». Оно там есть, при установке базового чарта можно передать конфигурацию зависимым. Но, возможно, оно не про это. Если не про это — скажите про что, интересно:)
На счет транзитивных зависимостей — да, их можно сказать что нет, точнее есть, но ломаются часто из-за кросс зависимостей.
В целом, я стараюсь вообще их избегать и деплоить в несколько шагов то, что можно деплоить в несколько шагов, но если очень надо — попробуйте Degasolv. Он универсальный, но тут тоже сгодится, заменяет requirement.yaml, но правда добавляет один шаг на собственно сборку зависимостей. Лечит дубликаты зависимостей и подобные штуки.
Но тут я согласен, да. Helm далеко не идеален.
gli
Под сквозным конфигурированием я имею ввиду именно возможность настраивать отдельные параметры в транзитивных зависимостях.
И да, мы пришли к такому же выводу — надо все устанавливать независимо, и самостоятельно проверять установленные зависимости.
Degasolv — посмотрю, спасибо!
VolCh
Я скорее про ситуацию, когда есть команда, работающая «по старинке» и хочется предоставить рабочее решение обычных задач типа оркестрации контейнеров, чтоб команда на него перешла или, хотя бы, пощупала его и аргументировано отвергла.
gli
Сложно дать «сферический ответ в вакууме», все сильно зависит от многих условий:
— где вы запускаетесь (железо/облака)
— подойдет ли вам попробовать GKE или аналоги
— что значит «пощупала»? Какие-то сервисы для staging попускала?
— какая цена ошибки? Возможен ли простой в несколько часов, пока инженеры пытаются восстановить сломанную во время «щупания» систему?
— насколько много инженеров понимают инфраструктуру k8s, чтобы сделать правильный выбор конфигурационных параметров?
— насколько много долгоживущих монолитов с внутренним стейтом, которые довольно сложно перетащить на k8s?
— если запускать часть сервисов в k8s рядом с работающей системой, насколько критично возрастание latency?
И таких вопросов еще много, я просто написал самое очевидное.
Если хочется потрогать, что это вообще такое — запустите где-нибудь k8s, это сейчас реально делается в пару кликов:
kubernetes.io/docs/setup/pick-right-solution
Самое сложное — что придется менять привычки разработчиков (пресловутый docker-way)
VolCh
Вот как раз с docker-way проблем нет, всё (кроме СУБД) в контейнерах по возможности в стиле лучших практик докера и 12 факторов, есть работающие кластеры (prod, stage и т. п.) на своём или условно своём (vmware облако) железе под оркестрацией docker в swarm mode, а так же локально у девов (аналог minicube). Но для нормальной работы они требуют сторонних тулзовин и баш скриптов, полноценное добавление нового сервиса в систему в лучшем случае копипастом получается только у некоторых, шаг влево-шаг вправо — паника.
Пока основная цель — чтобы команда захотела перейти (вернее первая — разобраться настолько чтобы самому захотеть), то есть основные ожидания от k8s — упростить работу без снижения скорости доставки и надежности. Как это «продать» бизнесу — это следующий этап.
onlinehead
Есть, я в свое время в одиночку вполне разобрался. Поначалу сложно, но после понимания концепции пойдет легче.
Преимущество, он же недостаток — гибкость. Очень широкий спект применения, отсюда очень много моментов, где можно споткнуться и сделать не так. Но решаемо.
BGP и IP-in-IP по началу не нужен совсем. Большинство CNI просто работают при условии соблюдения инструкции по установке.
В общем не все так страшно.
OnYourLips
Мне рассказывали про компанию, которая его внедрила за 5 человеколет.
Так что в одиночку вы навряд ли сделаете это: он и его экосистема будут развиваться быстрее, чем вы сможете их изучать.