Предисловие
Описанная здесь реализация trie на PHP делает пока слишком жирный словарь, который соответственно довольно долго загружается в память, что нивелирует довольно неплохую скорость её работы. Скорость поиска составляет ~80 тыс. слов в секунду. Словарь сделан из списка лемм словаря opencorpora.org и включает в себя 389844 слова. В несжатом виде словарь весит ~150мб, а сжатый gzip ~6мб. Однако довольно неплохие результаты быстродействия доказывают, что на чистом PHP можно сделать вполне работоспособное префиксное дерево trie.
Заранее прошу программистов с задатками литературных критиков не писать злобных комментариев. Эта статья должна быть интересна новичкам, как и я сам. Кому лень читать можно сразу посмотреть код на github.
Как все началось
Уже довольно давно я вынашиваю идею написания морфологического анализатора для своих PHP проектов, который сможет быстро проводить морфологический разбор заданных слов, а также трансформацию слов в нужную морфологическую форму.
На PHP уже есть подобная библиотека, которая называется phpmorhy. Работает довольно быстро и я бы использовал её и ничего бы не выдумывал, но компилятор словаря в ней сделан в виде отдельного не PHP приложения, что для меня делает невозможным использование этой библиотеки. Сама библиотека построена на базе уже давно не обновляемого словаря AOT, что еще больше снижает её полезность.
Шли недели и месяцы, я прочитал статью хабровчанина, потом статью И. Сегаловича о быстром морфологическом алгоритме для поисковика, потом еще кучу разных статей.
Мало-помалу я созрел для написания собственного
Взял словарь opencorpora.org, положил в mysql и получил скорость поиска 2 тыс. слов в секунду. Надо загружать словарь в память, думаю я. И тут оказывается, что для того чтобы доступными в PHP штатными структурами данных вроде массива или объекта, хранить словарь на 3 млн. нужно примерно 2Гб оперативной памяти. Все реализации trie на php, которые мне попадались, годились только как учебное пособие демонстрации логики работы, поскольку сами строились на нативных PHP структурах по хранению данных.
Устройство хранения словаря и принцип работы
Везде, где мне удалось почитать, послушать или посмотреть про префиксное дерево trie не объясняется как именно данных будут хранится в памяти. Вот у нас узел, а вот его наследники, а вот флаг окончания слова, что под капотом не показывают. Поэтому способ хранения мне пришлось выдумывать самому.
Как известно префиксное дерево trie состоит из узлов. Узел хранит в себе префикс, ссылки на последующие узлы (потомков) и указатель на то, что этот префикс является последним в цепочке. Довольно доходчиво про trie рассказывает индус вот тут.
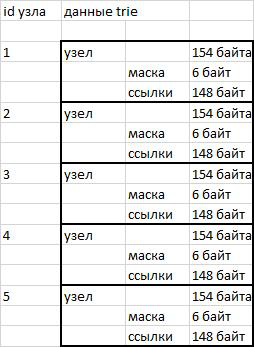
Узлы в моей реализации trie представляют собой блоки данных фиксированной длины 154 байта. Первые 6 байт (48 бит) содержат в себе битовую маску наследников. 46 первых бит — русский алфавит, цифры, кавычка, дефис и апостроф. Апостроф добавлен потому что в словаре opencorpora.org есть слово «кот-д’ивуар», в котором используется именно знак апостроф. 47-й бит служит для хранения флага окончания слова. Следующие после битовой маски 148 байт используются для хранения ссылок на наследников узла. По 3 байта на каждый знак (46 * 3 = 148).
Узлы хранятся в виде двоичных данных в строке. Доступ к нужному участку осуществляется с помощью функции substr() и последующей распаковкой unpack().
Использование узлов фиксированной длины позволяет упростить процесс адресации. Для переключения на нужный узел достаточно знать его порядковый номер (id) и длину узла. Умножаем порядковый номер на длину и узнаем смещение относительно начала строки — все очень просто.
рис. 1 Схема хранения
Недостатки
Используемая схема хранения упрощает адресацию, но прямо-таки пожирает место. Для хранения 380 тыс. слов требуется чуть более миллиона узлов. 154 байта * 1 000 000 узлов = 146.86 мегабайт. Т.е. примерно 400 байт на 1 слово. Если записывать слова в простой текстовый файл в кодировке utf8, то эти же 380 тыс. слов можно уместить в 16 мегабайт.
Планы
Чтобы использовать память более рационально я хочу перейти к переменной длине узлов, тогда в качестве ссылки придется записывать не id узла, а его местоположение в байтах. Определение места хранения ссылки на нужный узел будет происходить следующим образом. На примере слова «абв».
Буква «а» первая в алфавите поэтому узел у неё тоже первый, соответственно смещение 0. Читаем 6 байт, начиная от 0.
$str = substr($dic, 0, 6);Распаковываем строку:
$mask = (ord($str[5]) << 40) + (ord($str[4]) << 32) + (ord($str[3]) << 24) + (ord($str[2]) << 16) + (ord($str[1]) << 8) + ord($str[0]);Смотрим в маске 2-й бит (буква «б»)
bit_get($mask, 2);Бит установлен, теперь считаем кол-во поднятых бит в маске до 2. Допустим у нашего узла бит буквы «а» тоже поднят, значит наш бит буквы «б» будет вторым поднятым битом. Считаем смещение, чтобы прочитать ссылку
$offset = 6 + 3;6 байт маска + 3 байта, которые занимает первая ссылка, получается 9 байт. Читаем нужный кусок строки.
$str = substr($dic, $offset, 3);Распаковываем ссылку:
$ref = (ord($str[2]) << 16) + (ord($str[1]) << 8) + ord($str[0]);Переходим к следующему узлу и все повторяем снова. В последней букве проверяем наличие 47 бита в маске, если он установлен — в нашем trie есть искомое слово.
Надеюсь, что удастся сохранить скорость не ниже 50 тыс. слов в секунду.
Благодарности
Хочу поблагодарить участников форума nulled.cc и php.ru за помощь с побитовыми функциями.
Комментарии (19)

babylon
04.07.2018 20:42Что значит не будет бинарного файла? Бинарный файл и будет. К тому же RAW. Десерилизуйте так же как и серилизовали.
154 байта на узел это зашквар. Какая новая структура вам нужна? В MsgPack тоже биты используются для кодирования типов.johovich Автор
04.07.2018 22:49Мы о разных вещах говорим видимо. В каком качестве ты предлагаешь использовать msgpack? Насколько я знаком с msgpack, он позволяет сериализовывать примитивные типы и массивы. Проще говоря, этакий json или serialize только быстрее. Главная проблема в PHP не в хранении, с хранением вполне успешно справляется serialize/unserialize json encode/decode или var_export/eval, есть из чего выбрать. Главная проблема в отсутствии структур для эффективной работы с большими данными. Как тут msgpack поможет?
babylon
04.07.2018 23:15+1Надо понять что ты понимаешь под эффективностью, структурой и объемом. MP поддерживает достаточные объемы. Для твоих задач хватит с избытком. Читай спеки. Мапы он тоже серилизует и десерилизует. Причем сохраняя битовую типизацию и для полей объекта в том числе. Тебе же это надо. Наверное разработчики тарантула ошиблись выбрав MP для хранения данных:)
johovich Автор
05.07.2018 01:54+1Я совсем не против msgpack и даже использую его для хранения файлового кеша. Если его можно использовать и в каком-то другом качестве — отлично. Но я так и не понял, что он будет делать в trie. У меня сейчас словарь записан в виде строки бинарных данных, если получится сделать компактнее, чем 154 байт на узел — это все равно будет строка бинарных данных, которая в ходе работы программы не становится массивом или объектом. Вот есть сущность словаря — узел, который состоит из маски и ссылок, которые просты куски по 3 байта. Что может msgpack? Сохранить на диск? Ок. А дальше? msgpack_unpack() даёт мне массив на 2гб? Или он может какой-то свой объект для хранения предложить? Эффективность — когда для хранения 10 байт я трачу 15. У меня сейчас неэффективно, потому что 400байт на 1 слово, весь словарь 150мб, но если я беру массив, то там ещё хуже с эффективностью.
babylon
05.07.2018 04:49Гораздо интереснее вопрос: Как найти и прочитать значение узла в упакованном массиве? Учитывая, что типы записываются последовательно с данными узла наверное, что-то сделать можно.
Deosis
05.07.2018 08:38+1Можно вместо 46 указателей хранить 1 указатель и все дочерние записи располагать подряд.
Выигрыш будет тем больше, чем полнее дерево.
ПС. Посчитал, выигрыш по памяти будет, даже если у родителя только 2 ребенка.johovich Автор
05.07.2018 12:25Да, отличная идея. Но места резервировать под всех возможных детей? Как бы этого не делать?
babylon
05.07.2018 13:33+1Зачем резервировать? Можно реплицировать узел и добавлять к нему новых детей в конец буфера. При инициализации сливать детей с общими узлами.
johovich Автор
05.07.2018 13:51Реплицировать, добавлять новых детей и писать в конец? А как же быть с теми узлами, которые на него ссылаются? Сейчас связь односторонняя. Родители знают своих детей, но не наоборот. Что бы с этим придумать.
Yeah
04.07.2018 22:57+1А теперь переписать это все на zephir и скомпилить в виде расширения. Интересно, на сколько выростет скорость?
acdee
05.07.2018 00:03По битовое смещение не должно «вау» как прибавить в скорости, но так или иначе ускорение ожидаемо. Хотя по мне так и не велико.
johovich Автор
05.07.2018 02:01Вау или не вау, но побайтовая распаковка со смещением и последующим сложением делает на 10% быстрее, чем unpack('P'). А вот substr(pack('P'),0,6) на полпроцента, но быстрее связки chr($int). chr($int >> 8) ....

mcferden
05.07.2018 06:33Не силен в PHP, хотелось бы прояснить 2 момента:
1) Правильно ли я понимаю, что узлы хранятся в одном непрерывном блоке памяти? Тогда получается, что при вставке нового узла из-за добавления ссылки придется двигать какую-то часть этого блока?
2) Не совсем понятно, как работают ссылки через смещения. Опять же, узлы же должны двигаться?johovich Автор
05.07.2018 12:35Все верно, все в непрерывном блоке. Двигать ничего не приходится, потому что каждый узел имеет место для ссылок на всех возможных детей. Узел.маска.ссылки.Узел.маска.ссылки
Но вот сейчас начал пробовать по схеме с переменной длиной узла, когда свободного места не будет на всех детей. Сразу застрял. Как раз проблема с тем, что придётся менять адреса у других узлов, мало того, что это долго, так ещё непонятно как узнать кто является родителем узла.
johovich Автор
05.07.2018 12:49Ссылки сейчас даже без смещения. Само смещение вычисляется из ссылки. Вот к примеру нужен узел с индексом 121. Считаем его смещение: offset = 121 * 154
johovich Автор
05.07.2018 14:23Люди, кто в Си шарит, можете посмотреть как хранится узел и ссылки в этой сишной реализации? github.com/Ethiraric/libTrie
babylon
Чего бы MessagePack не использовать? Бинарный формат JSON как нельзя лучше подходит под это.
johovich Автор
А какой смысл? Короче просто бинарного файла все равно не будет. Насколько я знаю, messagePack даёт возможность сериализации, но никакой новой структуры данных не даёт.
johovich Автор
Если что-то готовое брать. Наверное лучше всего будет взять что-то типа структуры vector из проекта php-ds. Недавно натолкнулся, очень перспективно выглядит, там через php расширение, поэтому скорость, как у ракеты.