Содержание
- Мнемоника БМВ
- Общие примеры
- Мои примеры из практики
Большой мышонок
- Linux, Lucene, Mmap
- Redhat 6 ? Redhat 7
- Java и garbage collection
- Wildfly
- Логирование
- Транслитерация
- Oracle RAC
Маленький мышонок
- Итого
Мнемоника — слово или фраза, которая помогает нам что-то запомнить. Самая известная мнемоника — «каждый охотник желает знать, где сидит фазан». Кого не спроси, все с ней знакомы.
А вот в профессиональной сфере все немного грустнее. Спросите товарищей, знают ли они, что такое SPDFOT или RCRCRC. Далеко не факт… А ведь мнемоники помогают нам прогнать тесты, не забыв проверить самое важное. Чек-лист, схлопнутый в одну фразу!
Англоязычные коллеги-тестировщики активно используют мнемоники. Знакомая, читающая иностранные блоги, говорит, что американцы придумывают их чуть ли не на каждый чих.
И я думаю, что это здорово. Чужая мнемоника может не подойти именно под вашу систему или ваши процессы. А свое, родное, напомнит «не продолбать проверить вот это и это» и ограничит количество багов в продакшене.
Сегодня я хочу поделиться с вами своей мнемоникой БМВ для исследования граничных значений. Ее можно:
- дать джуниору для общего развития в тест-дизайне;
- использовать на собеседовании — задачу «найди границу в числе» кандидат обычно решает, а вот найдет ли он границу в строке или для загрузки файла?
Мнемоника БМВ
Б — большой
М — маленький
В — в самый раз

Ее легко запомнить. Просто вспоминаешь эту классную машинку и сразу расшифровка готова! Но что она значит и как поможет на собеседованиях?
В самый раз

В принципе, «в самый раз» вы тестируете и без всяких мнемоник. Мы всегда начинаем с позитивного тестирования, чтобы проверить, что система в принципе работает.
Если поле числовое, вводим распространенное значение. Скажем, у нас розничный интернет-магазин. В количестве товара можем проверить 1 или 2.
Позитивный тест — это и есть «в самый раз». Я мнемонику показала в виде мышонка. Тут он стандартного размера.
Большой
Потом мы говорим, что мышонка надо раздуть до невероятных размеров, вот чтобы прям на картинку не влезал. И посмотреть, как система будет с ним работать.

В данном случае мы как раз уходим «далеко вперед». ОЧЕНЬ ДАЛЕКО! Большой мышонок олицетворяет собой поиск технологической границы где-то там, за пределами произвольной.
Для ввода количества товаров это будет «9999999999999999999999999999999999999999999999999999999999...». Не просто какое-то большое значение (9999), а ОЧЕНЬ большое. Вспомните мышонка — его так раздуло, что даже на картинку не влез.
Разница важна, большое значение поможет найти произвольную границу, а огромное — технологическую. Тест на «большое» проводят часто, на «огромное» — нет. Мнемонику напоминает именно о нем.
Маленький
Протыкаем мышонка, и он сдувается до микроскопического размера.

Маленький мышонок — это поиск значений около нуля. Самое минимальное позитивное значение.
Как насчет теста на «0,00000001»? На ноль проверили, но не забудьте копнуть рядышком.
И что тут такого?
Вроде бы очевидные вещи говорю. Вроде бы это и так все знают. Только даешь на собеседовании задачку на числа, тот же треугольник (задачка из Майерса), и понимаешь, что это не так… Очень мало кто пойдет искать технологическую границу или попробует ввести дробное значение около нуля. Максимум ноль и предложат проверить.
А если предложить протестировать НЕ число, то это еще больший ступор. С числом то ладно, проверили ноль и границу по ТЗ, уже неплохо. А в строке что тестировать? А в файле?
Об этом я и хочу рассказать в статье. Как можно применять мнемонику в реальной жизни и при этом ловить баги. Начнем с общих примеров — которые встречаются на каждом проекте. И которые можно дать на собеседовании в виде небольшой задачки.
А потом расскажу примеры из моей работы. Да, они специфичные. Да, они про конкретные технологии. Ну и что? Зато показывают, как можно применить мнемонику в более сложных местах.
Смысл все тот же: границы есть практически везде. Просто найдите число и поэкспериментируйте с ним. И не забудьте про мнемонику БМВ, потому что именно на Б и М мы часто можем встретить баги.
Общие примеры
Примеры, которые есть в любом проекте: числовое поле, строка, дата… Рассматривать будем в таком порядке:
- В самый раз
- Большой
- Маленький
Число
- 10
- 0,00000001
- 999999999999999999999999....
Скажем, поле с количеством книг, платьев или пакетов сока. В качестве позитивного теста выбираем какое-то адекватное количество: 3, 5, 10.
В качестве маленького значения выбираем максимально приближенное к нулю. Помните, что мышонок должен быть совсем небольшим. Это не просто единица, а N-ный знак после запятой. Вдруг он округлится до нуля и где-то в формулах произойдет сбой? При этом на числе «1» все будет работать хорошо.
Ну а максимум достигается за счет ввода 10 млн девяток. Сгенерируйте такую строку с помощью инструментов типа Perlclip, и вперед, тестировать ОЧЕНЬ много!
См также:
Классы эквивалентности для строки, которая обозначает число — еще больше идей для тестов числовой строки
Как сгенерить большую строку, инструменты — помощники в генерации большого значения
Дата
- 26.05.2017
- 01.01.1900
- 21.12.3003
Позитивная дата — это или «сегодня», если мы грузим отчет на какую-то дату. Или своя дата рождения, если речь о ДР, или какая-то еще, которая подходит под ваш бизнес-процесс.
В качестве маленькой даты берем магическую дату «01.01.1900», на которой приложения часто разваливаются. С этой даты начинается отсчет времени в Excel. Она же пролезает и в приложения. Выставишь это магическое число — и отчет разваливается, даже если есть защита от дурака на нули. Так что настоятельно рекомендую ее к проверке.
Если говорить про совсем мелкого мышонка, то можно еще проверить «00.00.0000». Это будет проверкой на ноль, что тоже важно. Но от такого дурака разработчики защищаются чаще, чем от 01.01.1900.
«Далеко впереди» тоже может быть разным. Можно уйти в негатив и проверить такое число или месяц, которого реально не существует: 40.05.2018. Или поискать технологическую границу с помощью даты 99.99.9999. А можно взять чуть более реальное значение, которое просто наступит нескоро: 2400 или 3000 год.
См также:
Классы эквивалентности для строки, которая обозначает дату — еще больше идей для тестирования даты

Строка
- Вася
- (один пробел)
- (Тут было много текста)
Скажем, при регистрации есть поле с именем. Позитивный тест — обычное имя: Ольга, Вася, Петр…
При поиске маленького мышонка мы берем пустую строку или лайфхак: один или два пробела. При этом строка остается пустой (символов там нету), но при этом вроде как заполненной.
На чем акцент при поиске большого мышонка? Когда мы тестируем большую строку, надо протестировать БОЛЬШУЮ строку! Вспомнить, что мышонок должен быть БОЛЬШИМ. Потому что я обычно объясняю студентам, как это все работает, как искать технологическую границу итд. А потом они мне сдают ДЗ и пишут «я проверил 1000 символов — технологической границы нет».
21 век на дворе, ну какие 1000 символов? Берем любой инструмент, который позволяет сгенерировать 10 млн, и вставляем 10 млн. Вот это уже будет поиск технологической границы. И на этом уже бывают баги, на этом система может обломаться. Но 1000 символов? Нет.
См также:
Как сгенерить большую строку, инструменты — помощники в генерации большого значения
Но ок, здесь тоже все понятно. А что будет, если мы тестируем файл?
Файл
Где можно поискать число в файле?
Во-первых, у файла есть его размер:
- 5 мб
- 1 кб
- 10 гб
Когда тестируют большой файл, обычно пробуют что-то типа 30Мб, на этом и успокаиваются. А потом грузишь 1гб — и все, сервер завис.
Конечно, если вы новичок и тестируете для опыта какой-то реальный сайт, не стоит его нагружать без ведома владельца. А вот когда будете тестировать на работе, обязательно проверьте большого мышонка.
Во-вторых, у файла есть название > а это длина строки, которую мы только что обсудили.
Но у файла есть еще его наполнение! Есть количество столбцов (колонок) и строк. Тесты по строкам:
- 5 строк
- 1 строка
- 10000000000 строк
И тут уже начинается интересное. Потому что даже в том же экселе в разных версиях есть разные ограничения по количеству строк, которые он поддерживает:
- Excel ниже 97 – 16 384
- Excel 97-2003 – 65 536
- Excel 2007 – 1 048 576
Но все равно числа довольно большие, это неинтересно. А вот по колонкам старый эксель не открывал больше 256, и вот это уже серьезное ограничение:
- Excel 2003 – 256
- Excel 2007 – 16 385
Его бесплатный собрат LibreOffice не умеет открывать больше 1024 колонок.

История из жизни
Мы пишем некоторые автотесты в CSV-формате. На входе таблица, на выходе таблица. Открываем и редактируем в LibreOffice, чтобы видеть, где какая колонка. Все здорово, все работает. Пока количество колонок не вылезает за 1024.
Тут начинается #жизньболь. LibreOffice тест уже не откроет, в формате CSV неудобно, потому что сложно понять, где же тут 555 колонка. Открываешь тест в Excel, редактируешь, сохраняешь, запускаешь тест… Он падает в 10 новых местах: ИНН испортился. Он ведь длинный, например 7710152113. Эксель его радостно переводит в формат 1,2Е+5.
Другие длинные числа тоже теряются.
Если значение было в кавычках, оно оборачивается в дополнительные кавычки, которые тест не ожидает.
И эти мелочи исправляешь уже в формате CSV, мысленно ругая Excel про себя… Так что ограничение есть, о нем следует помнить! Хотя оно не отображается на работе самой системы, просто может усложнить жизнь тестировщику.
Таблица в Oracle (база данных)
И раз уж мы заговорили про 1024 столбца, то вспомним про Oracle (популярная база данных). Там такое же ограничение: в одной таблице может быть максимум 1024 колонки.
Об этом лучше помнить заранее! У нас была таблица, в которой было порядка 1000 колонок, но половина зарезервирована на будущее: «когда-нибудь пригодится, нам этого надолго хватит». Хватило, но ненадолго…
Расширять таблицу некуда — уперлись в ограничение. Так что или разделять таблицу на две, или упаковывать содержимое в BLOB: это что-то zip-архива с данными получается, занимает одну колонку, а внутри содержит сколько угодно.
Но в любом случае это миграция данных. А миграция данных это всегда жизньболь. На большой базе идет долго, приносит новые проблемы, которые могут выстрелить лишь через полгода… Бррр! Если можно обойтись без миграции, то лучше обойтись.
Если у вас есть таблица, в которой МНОГО данных, задумайтесь о будущем. Будете ли вы всегда влезать в 1024 колонки? Не придется ли потом мигрировать? Ведь чем дольше система живет, тем сложнее будет перенос. И «хватит лет на 5» — значит мигрировать надо будет пятилетний объем.
Как это тестировать? Да по коду, оцените ваши таблицы с данными, присмотритесь, что где лежит. Обратите внимание на большого мышонка: те таблицы, в которых уже сейчас много колонок. Не возникнет ли с ними проблем в будущем?
Отчет в системе
А зачем вообще мы грузим файлы в систему или выкачиваем данные из оракла? Скорее всего для того, чтобы построить какой-нибудь отчет. И здесь тоже можно применить эту мнемонику.
Данные могут быть как на входе (много, мало, в самый раз), так и на выходе! И это тоже важно, так как это разные классы эквивалентности.
В итоге тестируем количество:
- столбцов отчета;
- строк;
- данных на входе;
- данных на выходе (в самом отчете).
Структура (столбцы и строки)
Можем ли мы влиять на количество строк или столбцов? Иногда да, можем. На второй работе я тестировала конструктор отчетов: слева у тебя кубики с названиями параметров, которые ты можешь накидывать в сам отчет по горизонтали или вертикали. То есть сам решаешь, сколько будет строк, а сколько колонок.
Применяем мнемонику. После типового отчета (позитивный тест, «в самый раз» мышонок) пробуем сделать мало:
- 1 столбец, 0 строк;
- 0 столбцов, 1 строка;
- 1 столбец, 1 строка.
Потом много:
- максимум столбцов, 1 строка (все кубики в столбцы перекинули);
- максимум строк, 1 столбец;
- если кубики можно дублировать, то и там и там по максимуму, но это сомнительно;
- максимум вложенных уровней (это когда внутри одной колонки-агрегатора находятся две других).
Далее тестируем данные на входе и выходе. Вот на них мы можем влиять в любом отчете, даже если нет конструктора и количество строк и столбцов всегда одинаково.
Данные на входе
Выясняем, как формируется отчет. Допустим, каждый день заполняются некие данные, скажем, количество проданных платьев, сарафанов, маечек. А в отчете мы видим группировку данных по категориям, цветам, размерам. Сколько продано в день / месяц / час.
Строим отчет, а сами влияем на данные на входе:
- Обычное число (5 платьев в день, хотя на огромных площадках это число может быть и 2000, и больше, тут надо уточнять, что будет более позитивно под вашу систему).
- Пусто, ничего не продали / продали 1 вещь за месяц.
- Объем нереально большой, по максимуму каждого товара, каждого цвета, каждого размера. Ставим максимум «лежит на складе» и все продаем: в течение месяца или даже одного дня. Что на это скажет отчетность?
Данные на выходе
По идее, данные на выходе коррелируют с данными на входе. На входе мало > на выходе будет мало. На входе много — на выходе много.
Но так работает не всегда. Иногда данные на входе могут отсеиваться, или, наоборот, умножаться. И тогда мы можем как-то с этим играть.
Вот, например, система Дадата. Загружаешь файл с одной колонкой ФИО, на выходе получаешь сразу несколько:
- Исходное ФИО, что было в файле;
- Разобранное ФИО (если смогли разобрать);
- Род. падеж;
- Дат. падеж;
- Твор. падеж;
- Фамилия;
- Имя;
- Отчество;
- Статус разбора — уверенное распознавание механизмом или выверить человеком;

Из одной ячейки получили 9. И это только по ФИО так, а еще система умеет разбирать адреса. Там из одной ячейки получается чуть ли не 50: помимо гранулярных компонентов еще всякие коды КЛАДР, ФИАС, ОКАТО…
И тут уже интересно. Получается, у нас может быть мало данных на входе, но много на выходе. И если мы исследуем максимум по колонкам, то у нас есть два варианта:
- 500 колонок на выходе (что около 10 адресов на входе);
- 500 колонок на входе (и целая куча на выходе).
Принцип работает и в обратную сторону. Что, если на входе целая куча данных, а на выходе — пшик? Если вместо ФИО там какая-то бредятина типа «ор34е8н8пе»? Тогда получится, что все дополнительные колонки пустые, только статус разбора «ты мне фигню прислал». Так мы получаем минимум на выходе (маленький мышонок), что тоже стоит проверить.
А уж если колонки можно исключать! Можно и класс эквивалентности «ноль» проверить, когда ноль на выходе, исходный файл непустой. Можно и минимум проверить, когда оставили 1 колонку из сотни.
Тут главное — помнить, что помимо данных на входе у нас есть данные на выходе. И иногда в них можно проверить границы, которые не будут зависеть от данных на входе. И тогда это обязательно нужно сделать.
Мобильные приложения
Связь
Есть разные варианты связи:
- Нормальная;
- Совсем фиговая (мелкий мышонок);
- Супер-быстрая (крупный).
Причем плохая связь может быть частично: если ты в зоне с нормальным вайфаем и плохой сотовой сетью. Хорошо работает интернет, но плохо смс.
Количество памяти
Важно еще, сколько памяти есть у приложения:
- Нормальное количество;
- Очень мало;
- Очень много.
И если в данном случае первый и третий тесты в данном случае можно совместить, то маленький мышонок очень интересен. И тут есть разные варианты:
— запускаем приложение на телефоне, у которого УЖЕ мало памяти;
— запускаем, когда памяти нормально, сворачиваем, разворачиваем что-то крупное, пытаемся вернуться в первое приложение.
Вот если приложение не умеет нормально резервировать память, то во втором случае оно просто упадет, память то уже отжали.
Диагональ устройства
- Стандартная (изучаем рынок, смотрим, что популярнее у наших пользователей).
- Минимум (телефон).
- Максимум (большой планшет).
Разрешение экрана
- Стандартное;
- Самое мелкое;
- Самое большое;
Не путайте разрешение и диагональ, это разные вещи. У вас может быть старое устройство с большим дисплеем, а у меня новый модный смартфон, где разрешение в 5 раз лучше. А уж что будет лет через 20, страшно представить.
GPX пути
GPX пути — это XML-файлы с последовательными координатами. Их можно загружать в эмуляторы мобильных, чтобы телефон думал, что он перемещается в пространстве с какой-то скоростью.
Полезно, если приложение считывает GPS-координаты для каких-то своих целей. Так оно само определяет, идешь ты, бежишь или едешь. А можно не бегать, просто скормить приложению координаты, выставить коэффициент их прохождения и тестировать, сидя в офисе.
Какие коэффициенты стоит проверить? Все согласно мнемонике:
- 1 — обычный коэффициент, простую ходьбу заменяет;
- 0,01 — словно ты меееееееедленно плетешься;
- 200 — даже не бежишь, а летишь!
Зачем это все надо проверять? Какие можно встретить баги?
Например, приложение может крашиться в самолете — запустил, а оно тут же развалилось. Так как считывает координаты и пытается определить твою скорость. Но кто же знал, что скорость будет выше 130?
На медленной скорости приложение может вылетать. Настроит себе миллион промежуточных точек и не осилит удержать их в памяти. И все, тю тю…
См также:
Что такое GPX пути и зачем они тестировщику? — подробнее о gpx-путях и пример такого файла
Резюме по общим примерам
Я хочу здесь показать, что, казалось бы, «большой, маленький» — числовое поле и все!
А на самом деле мнемонику можно применять везде, будь то файлы, игрушки, отчеты… И она реально помогает нам найти баги. Вот некоторые примеры из моей практики:
Маленький мышонок (нижняя граница)
— Дата 01.01.1900
Когда я работала на фрилансе, эта дата мне разваливала все отчеты. Потому что даже если разработчик ставил защиту от дурака, он ставил защиту от 0000. А защиту от 1900 не ставил.
— Одинокий символ конца строки
Этот тест мне подсказал более опытный коллега, когда мы обсуждали примеры применения мнемоники. Если система проверяет файл на пустоту, надо проверить не совсем пустой.
Рекомендую такой тест: добавить в файл символ конца строки. Даже не пробел, а спецсимвол. И посмотреть, как система отреагирует. А реагирует она не всегда хорошо =)
Большой мышонок (верхняя граница)
Если говорить про большого мышонка, то там вообще бесконечное множество багов:
— Война и мир;
— Много данных;
— 2 Гб.
Можно загрузить войну и мир в текстовое поле, загрузить огромный файл в систему, получить много данных на входе или на выходе. Это все типовые ошибки, которые я встречала в своей практике. Да и не только я, верхнюю границу вообще часто проверяют как раз потому, что знают: там могут быть баги. Это скорее про мелкого мышонка забывают.
Другой пример большого мышонка — нагрузочное тестирование. О! Такие примеры есть у меня, поэтому мы переходим в хардкор.
Если вы знаете контекст, если вы знаете, как работает ваше приложение внутри, на каком оно языке программирования написано, какую базу данных использует, вы тоже можете применять эту мнемонику. И я хочу показать это на конкретных примерах.
Мои примеры из практики
Большой мышонок
Linux, Lucene, Mmap
В операционной системе Linux есть настройка максимального количества открытых файловых дескрипторов:
- redhat-6 — /etc/security/limits.conf
- redhat-7 — /etc/systemd/system/[name of service].service.d/limits.conf (для каждого сервиса свой)
Файловый дескриптор открывается на любое действие с файлами:
- создать соединение с базой данных;
- читать файл;
- записывать в файл.
- ...
Если ваша система активно работает с файлами и проводит много операций — настройку нужно увеличивать. Иначе малейшая нагрузка вас положит.
В нашей системе используется поисковый индекс Lucene. Это когда мы некоторые данные из БД берем и выгружаем на диск, чтобы потом по ним быстрее искать. И если мы строим индекс с помощью технологии mmap, то она во время построения индекса открывает много файлов на запись.
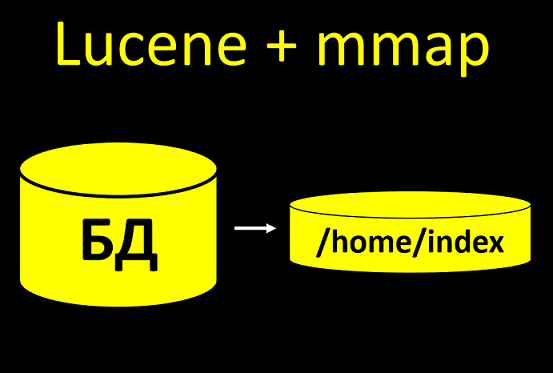
В тестовой базе обычно 100 клиентов, ну 1000. Не так уж и много. Перестроение проходит без проблем, даже если не настраивать дескрипторы.
А в реальной системе будет 10+ млн клиентов. И вот если там не настроить количество файловых дескрипторов, то при запуске построения индексов все просто рухнет.
Об этом нужно знать и сразу написать инструкцию: настройте операционную систему на сервере, иначе будут такие то и такие последствия. А на своей стороне важно проводить не только функциональные тесты, но и нагрузочные, на реальным количестве данных.
Redhat 6 ? Redhat 7
Когда тестируете большого мышонка (нагрузку), не забывайте о том, что в разных конфигурациях приложение будет работать по-разному. Если взять инструкцию из прошлого пункта, то ее надо не просто написать, но и проверить. Причем проверить в окружении заказчика.
Потому что разные операционные системы работают по-разному. И у нас была такая ситуация, что вроде как все настроено, но система падает и говорит «мне не хватает открытых файловых дескрипторов». Мы говорим:
— Проверьте параметр.
— Он настроен, все по вашей инструкции!
Как так? Оказывается, что у нас инструкция для Redhat 6, а у них Redhat 7, где настройка совершенно в другом месте! В итоге сделали по нерабочей инструкции и словно не делали вообще.
Так что если работаете с разными версиями linux-дистрибутивов, их надо проверить все. И не просто сервисы развернуть на машине, но и нагрузочное тестирование провести хотя бы один раз: убедиться, что все работает. Ведь лучше поймать баг в тестовой среде, чем потом разбираться в продакшене.
Java и garbage collection
У нас используется язык java, который имеет встроенный сборщик мусора… Иногда кажется, что если приложение использует много памяти и на какой-то сложной операции находится на грани ООМ (Out of Memory), то можно решить эту проблему легко, просто увеличив количество доступной памяти! Зачем тестировать?
На самом деле нет. Дашь много Xmx — приложение будет зависать на сборщике мусора…

Причем проявляется это очень внезапно для пользователя. Вот ночью подали большую нагрузку, загрузили много данных — специально в нерабочее время, чтобы никому не мешать. Утром приходит пользователь, он пока единственный работает с системой, нагрузки почти никакой, а у него все подвисает. И он даже не понимает, почему.
А на самом деле нагрузка прошла, нагрузка ушла, и гарбиджколлектор вышел все подчищать, из-за этого фризы. И хотя сейчас нагрузки нет и работает одинокий пользователь, ему грустно.
Поэтому просто выделить много памяти приложению «и можно не тестировать» — так не работает. Лучше проверить.
Wildfly
Сервер java-приложений WildFly не позволит загружать большие файлы, если его не настроить соответствующим образом.

У нас используется сервер приложения Jboss, он же Wildfly. И оказывается, что в него по умолчанию нельзя загружать большие файлы. Причем мы помним, что мышка должна быть БОЛЬШАЯ. Если мы тестируем 5мб или 50, все работает, все хорошо.
Но если попробовать загрузить 2гб, система выдает 404 ошибку, а вы по логам ничего понять не сможете: в логах приложения пусто. Потому что это не приложение не может загрузить файл, его сам Wildfly режет.
Если не проводить тестирование на своей стороне — с этим может столкнуться заказчик. И будет очень неприятно, он придет с вопросом «Почему не грузится?», а без разработчика ты ничего сказать не можешь. Поэтому лучше не забывать тестировать границы, в том числе и большие файлы в систему запихивать. Как минимум вы будете знать результат таких действий.
И тут либо исправляем, увеличивая параметр max-post-size, либо даем информацию про ограничение и прописываем его в ТЗ.
Логирование
Еще пример на тестирование «большой» мышки. Да, на нее как-то побольше примеров вспоминается… Чаще баги ловит!
Допустим, мы проверяем логирование ошибок. Что ошибка записывается в стектрейс в лог. Вот мы проверили, мы молодцы: да, все круто, все записывается! И я все понял из стека по тексту ошибки. Если у Заказчика упадет, я сразу пойму почему.

А что будет, если у нас не одна ошибка, а несколько? Тоже все хорошо, все логируется, все прекрасно! Но мы помним, что мышка должна быть БОЛЬШАЯ:

Что будет, если у нас будет МНОГО ошибок? У нас как раз была такая ситуация. Исходная система выгружает данные в буферную таблицу в БД. Наша система эти данные оттуда забирает и как-то потом с ними работает.
В исходной системе произошел сбой и она выгрузила некорректный инкремент, где все данные были ошибочными. Наша система забрала инкремент, а там 13600 ошибок. И когда Java попыталась сгенерировать стек-трейс на 13к ошибок, она выжрала всю память, которую ей выделили, а потом сказала «Ой, java heap space».
Как исправили? Добавили параметр maxStoredErrors (default 100) в задачу загрузки— максимальное кол-во хранимых в памяти ошибок для одного потока. По достижению этого количества ошибки выводятся в лог и список очищается.
Также убрали дублирование сообщений об ошибке выполнения задачи нашим Task и quarz'овским RunShell, повысив уровень логирования последнего до warn (сообщение выводится им в info). Из-за дублирования стек увеличивался еще в два раза…
А какой вывод из этой истории? Недостаточно проверить «в самый раз». Это важный и полезный тест, да, никто не спорит. Смотрим, логируется ли ошибка в принципе, в каким тестом и т.д. Но потом очень важно проверить БОЛЬШУЮ мышку. Что случится, если ошибок будет много?
Причем нужно понимать, что «много» — это значит МНОГО. Если загрузить инкремент на 10 ошибок и сказать «10 ошибок тоже норм, система выводит все стек-трейсы», то тестирование вроде как провели, а проблему не выявили. Если мы видим, что система выводит все сообщения, нужно заранее подумать: а что будет, если их будет МНОГО? И проверить.
Транслитерация
Если у вас есть какой-то принцип транслитерации, можно пойти и попробовать узнать, а как он вообще внутри работает? Если он две буквы транслитерирует как одну, то что будет, если мы введем три буковки или четыре одинаковых?
ОО = У
ООО =?

А что будет, если мы введет их много? Вполне возможно, что система начнет перебирает варианты и уйдет в бесконечную рекурсию, а потом просто зависнет. Так что проверяем длинную строку:
ОоооОООоооОООооООООооООооОООоооооОООоооо
Она вешает приложение намертво, если разработчики не учли бесконечный цикл вариантов «оо»

Oracle RAC
Oracle — популярная база данных. Oracle RAC — это когда у вас несколько инстансов базы данных. Нужно для обеспечения бесперебойной работы бизнес-критичных систем: даже если один инстанс сломался, остальные продолжают работать, пользователь об этом даже не узнает.
Если вы используете Oracle RAC — ОБЯЗАТЕЛЬНО надо провести на нем нагрузочное тестирование. Если у вас его нет, то надо просить заказчика, у которого он стоит, проводить нагрузку на своей стороне.
Тут может возникнуть вопрос — почему тогда его нет у вас? Все просто, железо под тестирование обычно всегда дают похуже. И если система ориентирована просто на Oracle и RAC использует один клиент из двадцати, то покупать его ради тестирования будет невыгодно, так как RAC стоит очень дорого. Проще договориться с клиентом и помочь ему провести тесты.
Что будет, если нагрузочное тестирование не проводить? Вот пример из жизни.
В базе есть возможность создать колонку и сказать, что это — автоинкрементальное поле. Это значит, что вы поле не заполняете вообще, его генерирует база данных. Появилась новая строка? Записала значение «1». Еще новая строка? У нее будет значение «2». И каждое новое значение будет все больше и больше.
Так, например, очень удобно генерировать идентификаторы. Ты всегда знаешь, что твой id — уникален. И для каждой новой строки он больше, чем для предыдущей. По идее…
У нас в системе есть два идентификатора сущности:
- id — идентификатор конкретной версии, автоинкрементальное поле;
- hid — исторический идентификатор, он для одной сущности всегда постоянный и не меняется.
В итоге можно сделать выборку по конкретной версии, а можно сделать выборку по hid-у сущности и увидеть всю ее историю.
Когда сущность создается, id = hid. А потом id возрастает, он у новых версий всегда больше, чем hid. Поэтому формула определения версии:
version = (id – hid) + 1
Отрицательной она быть не может, так как id создает сама база.
Но вот к нам приходят с вопросом по сущности и показывают записи из базы. Я уже не помню, о чем был тот вопрос, да это и не важно. Я смотрю на записи и глазам своим не верю: там у версии есть отрицательные значения. Как так?? Это же невозможно. Оказалось, возможно.
В RAC у каждой ноды есть свой кеш. И может получиться так, что ноды не успевают друг друга оповестить, и одно и то же число у вас встречается в табличке дважды:
- Создается сущность. Нода смотрит в кеш, какое последнее значение автоинкрементальноо поля? Ага, 10. Значит, я дам идентификатор 11.
- Тут же приходит новая сущность на вторую ноду (запросы пришли одновременно и балансировщик один кинул на ноду 1, а второй на ноду 2).
- Вторая нода смотрит в свой кеш, какое последнее значение поля? Ага, 10 (первая нода еще не успела сообщить второй, что заняла это число). Значит, я дам идентификатор 11.
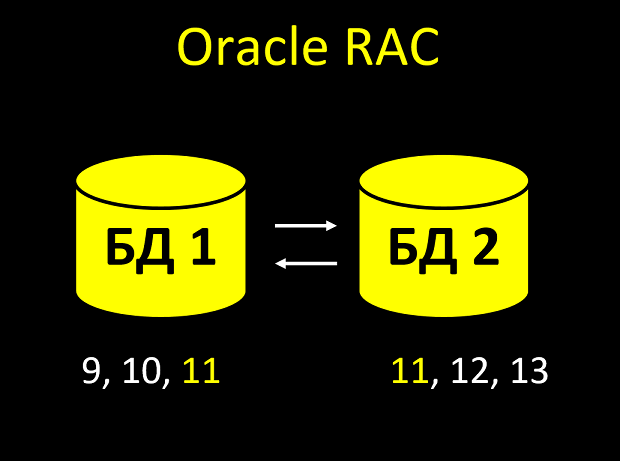
Итого получаем не уникальное значение уникального поля. И ведь при большой нагрузке таких пересечений идентификаторов будет не один и даже не два… Если у вас вся бизнес-логика завязана на то, что id всегда уникален и всегда возрастает, будет ОЙ.
В нашем случае ничего катастрофического не произошло, да и помогло проведение нагрузочного тестирования на тестовом стенде заказчика. Нашли проблему рано, как выяснилось, отрицательные версии системе жить не мешают. Но мы добавили в скрипты создания БД упорядочивание сиквенсов, как раз на такие случаи.
Мораль сей басни такова — ОЧЕНЬ важно проводить нагрузочное тестирование на таком же железе, которое будет в PROD. Все может повлиять на результат: настройки самой OS, настройки базы, да что угодно. То, о чем вы даже не подозревали.
Проводите тесты заранее. И помните, что далеко не все проблемы можно найти функциональными тестами. В этом примере простое тестировали не нашло бы багов. Ведь если создавать сущности вручную, то есть медленно, все ноды базы данных будут успевать оповестить соседние, так что неконсистентности мы не получим.
Маленький мышонок
Пустой JSON
Если вы используете открытую библиотеку Axis, попробуйте послать в приложение пустой JSON. Он вполне может повесить все напрочь.
И самое главное — вы ничего не можете с этим сделать на своей стороне! Это баг в сторонней библиотеке. Так что тут или ждать официального исправления, или менять библиотеку, что может быть очень сложно.
На самом деле этот баг уже исправлен в новой версии Axis. Казалось бы, просто обновись, и все! Но… В системе редко используется одна сторонняя библиотека. Обычно их несколько, они завязаны одна на другую. Чтобы их обновить, надо обновлять все сразу. Надо проводить рефакторинг, потому что они теперь по другому работают. Надо выделять ресурсы разработчиков.
В общем, просто обновление версии библиотеки порой занимает целый релиз крутого разработчика. Так, например, когда мы переезжали на новую версию Lucene, мы потратили на задачу 56 часов, это 7 человеко-дней, неделя фулл-тайм разработчика и плюс тестирование. Сама задача выглядит примерно так, ставит ее архитектор:
Lucene. Перейти на использование PointValues вместо Long/IntegerFieldИ это просто обновление библиотеки! А уж отказаться от одной библиотеки из-за бага в ней вообще страшно представить, сколько времени займет…
В Lucene Migration 5 -> 6 доке есть пункт об отказе от Long(Integer/Double)Field в пользу PointValues.
При переходе на Lucene 6.3.1 я оставил старые поля (все классы были переименованы с добавлением Legacy- префикса), потому что перевод тянет на отдельную задачу.
Нужно отказаться от старых полей и заиспользовать Long(Integer/Double)Point классы, которые по тестам быстрее и меньше весят в индексе. Придется переписать достаточно много кода.
Обязательно! Переход должен быть с обратной совместимостью, чтобы поиск (по крайней мере ключевые функции) не отломался с обновлением версии. Он должен работать на старом индексе (до перестроения), а после перестроения (в удобное заказчику время) должны подхватиться новые поля.
Так что вполне возможно, что вы какое-то время просто будете жить с багом. Знать о нем, но ничего не менять. В конце концов, «нечего глупые запросы слать».
Но в любом случае о наличии бага нужно хотя бы знать. Потому что если к вам придет пользователь и скажет: «У вас все зависло», вы должны понять почему. При том, что в логах пусто. Потому что это не ваше приложение зависает, все виснет на этапе преобразования JSON-а.
Казалось бы — пустой запрос! А вот он к чему может привести… То есть даже если вы не знаете, что в Axis есть такой баг, вы можете просто проверить пустой JSON, пустой SOAP-запрос. В конце концов, это отличный пример теста на ноль в разрезе JSON-запроса.
Не забывайте тестировать ноль. И наименьшее значение — маленького мышонка, потому что он тоже приносит баги, причем иногда вот настолько страшные.
См также:
Класс эквивалентности «Ноль-не ноль» — подробнее о тестировании нуля
«Москва» в поле адреса
Сервис Дадата умеет стандартизировать адреса — раскладывать адрес одной строкой на гранулярные компненты + определять площадь квартиры, если она есть в справочнике.
Во время тестирования нашелся забавный баг — если ввести в адрес слово «Москва», то система определяет площадь квартиры. Хотя, казалось бы, где в этом «адресе» квартира?

Я считаю, это отличный пример «маленькой мышки». Потому что что обычно проверяют? Обычный адрес, адрес до улицы, до дома… Пустое поле. Один любой символ — это считается проверкой на единицу.
Но если ввести одну букву — система определит ввод как полный треш и очистит адрес. Она ведет себя корректно, но это негативный кейс на единицу. Это проверка исключительно длины поля.
А тут стоит еще задуматься — есть ли позитивная единица? Есть. Одно слово, такое система определит. И тут уже тоже разные классы эквивалентности: это может быть слово из начала адреса (город), а может быть из середины (улица). Попробовать стоит и то, и другое. А вот если ограничитесь только «единица в текстовом поле = один символ», то этот баг никогда не найдете.
Итого
Мнемоник существует великое множество. И их использование может вам помочь. Потому что вы уже смотрите на свое приложение 10-ый, 100-ый раз… У вас уже замылился взгляд, вы можете пропустить очевидную ошибку. И если вы возьмете любую существующую мнемонику, то посмотрите на приложение по новому. Что поможет обнаружить новые баги.
И даже такая простая мнемоника, как БМВ, очень сильно помогает. А ведь, казалось бы… Большое, маленькое, подумаешь! Простые граничные значения. Но о них всегда нужно помнить и всегда проверять! Это приносит плоды и самые разные баги.
На своих примерах я хотела показать, что искать границы можно не только в текстовом или числовом поле. Мнемоника работает везде: в Oracle RAC, Java, Wildfly, да где угодно! Учитесь смотреть на границы шире обычного понимания «ввели «Войну и мир» в текстовое поле».
Конечно, основной упор мы делаем именно на «большую мышку», именно она приносит большинство багов. Именно такие случаи вспоминаются, когда думаешь, что встречал на своем проекте.
Но и про «маленького мышонка» не стоит забывать. Да, я смогла вспомнить всего пару примеров, специфичных для моей работы. Но это не значит, что я не нахожу баги на мелком мышонке. Нахожу! Те, которые есть в разделе общих примеров: дата 01.01.1900, файл размером 1 кб, пустой отчет при заполненных данных…
Границы — это очень важно. Не забывайте тестировать их. Надеюсь, мои примеры вас вдохновят, а мнемоника БМВ всегда будет всплывать в голове при выделении классов эквивалентности.
А может быть, вы придумаете свою мнемонику. Которая будет под вас, под вашу команду, под ваши особенности, под ваши процессы. И это тоже здорово, это тоже успех. Главное, чтобы оно помогало!
PS — это выдержка из моей книги для начинающих тестировщиков. Также про мнемонику я рассказывала в докладе на SQA Days, видео тут.
Комментарии (4)

brnovk
26.07.2018 07:58+1Небольшое пояснение по поводу дат — не всегда точка начала времён это 1900.01.01.
1899.12.30, такое ещё можно встретить в легаси, процитирую ответ с русскоязычного форума:
Вообще, 0 предполагалось в качестве даты-времени старта нового века.
Однако, когда Микрософт приобрел Эксел, нужно было обеспечить совместимость с Лотус 1-2-3. А в Лотус 1-2-3 был баг в отношении 1900 года — оно думало что это високосный год, в то время как 1900 — не високосный. Для обеспечения совместимости команда Экселя решила ввести этот баг в Эксель.
Таким образом, чтобы дата не уехала, 0 на самом деле представляет собой 01.01.1900 минус 1 день. Вот так.
VDitsL
годно
Molechka Автор
Спасибо))