Cоавтор статьи: Mike Cheng
Google Cloud Platform теперь в своем портфолио имеет образы виртуальных машин, разработанные специально для тех, кто занимается Deep Learning. Сегодня мы поговорим о том что эти образы из себя представляют, какие преимущества они дают разработчикам и исследователям, ну и само собой о том, как создать виртуальную машину на их базе.
Лирическое отступление: на момент написания статьи продукт все еще находился в Beta, соответственно, на него не распространяются никакие SLA.
Что это за зверь такой, образы виртуальных машин для Deep Learning от Google?
Образы виртуальных машин для Deep Learning от Google это образы Debian 9, которые прямо из коробки имеют все, что необходимо для Deep Learning. На текущий момент существуют версии образов с TensorFlow, PyTorch и образы общего назначения. Каждая версия существует в редакции для только-CPU и GPU инстансов. Для того, чтобы немного лучше понять какой образ Вам нужен, я нарисовал небольшую шпаргалку:
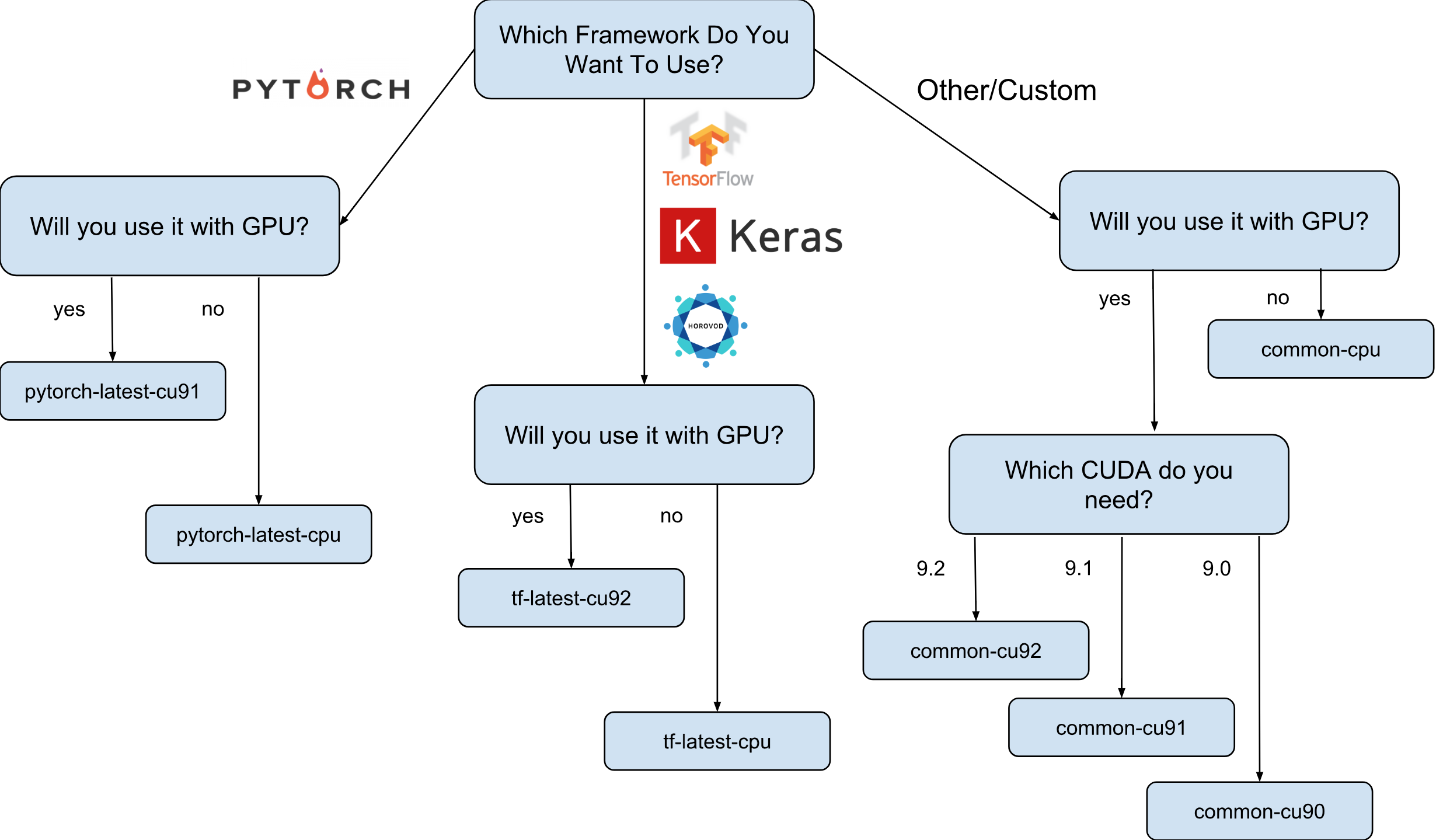
Как показано на шпаргалке, существует 8 различных семейств образов. Как уже говорилось, все они базируются на Debian 9.
Что же именно предустановлено на образы?
Все образы имеют Python 2.7/3.5 со следующими предустановленными пакетами:
- numpy
- sklearn
- scipy
- pandas
- nltk
- pillow
- Jupyter environments (Lab и Notebook)
- и многое другое.
Сконфигурированный стек от Nvidia (только в GPU образах):
- CUDA 9.*
- CuDNN 7.1
- NCCL 2.*
- последний Nvidia Driver
Список постоянно пополняется, так что следите за обновлениями на официальной странице.
А зачем собственно эти образы нужны?
Давайте предположим, что Вам нужно обучить модель нейронной сети при помощи Keras (с TensorFlow). Вам важна скорость обучения и Вы решаете использовать GPU. Для использования GPU Вам понадобится установить и настроить стек Nvidia (Nvidia driver + CUDA + CuDNN + NCCL). Мало того, что этот процесс достаточно сложный сам по себе (особенно, если Вы не системный инженер, а исследователь), так все осложняет еще и тот факт, что Вам нужно учитывать бинарные зависимости Вашей версии библиотеки TensorFlow. Например, официальный дистрибутив TensorFlow 1.9 скомпилирован с CUDA 9.0 и он не будет работать, если у Вас стек, в котором установлена CUDA 9.1 или 9.2. Настройка этого стека может быть "веселым" процессом, я думаю, с этим не поспорит никто (особенно те, кто это проделал).
Теперь предположим, что после нескольких бессонных ночей все настроено и работает. Вопрос: эта конфигурация, которую Вы смогли настроить, является ли она наиболее оптимальной для Вашего железа? Например, правда ли, что установленная CUDA 9.0 и официальный бинарный пакет TensorFlow 1.9 показывает самую быструю скорость на инстансе с процессором SkyLake и одним Volta V100 GPU?
Ответить практически нереально без выполнения тестирования с другими версиями CUDA. Чтобы ответить наверняка, нужно руками пересобрать TensorFlow в разных конфигурациях и прогнать Ваши тесты. Все это нужно проводить на том дорогом железе, на котором планируется впоследствии тренировать модель. Ну и самое последнее, все эти измерения можно выкинуть, как только новая версия TensorFlow или стека от Nvidia выйдет в свет. Можно смело утверждать, что большинство исследователей просто не будут этим заниматься и будут просто использовать стандартную сборку TensorFlow, имея не оптимальную скорость работы.
Вот тут и появляются на сцене образы Deep Learning от Google. Например, образы с TensorFlow имеют свою собственною сборку TensorFlow, которая оптимизирована под железо, которое есть на Google Cloud Engine. Они протестированы с различной конфигурацией стека Nvidia и основаны на той, которая показала самую большую производительность (спойлер: это не всегда самое новое). Ну и самое главное — почти все, что нужно для проведения исследований уже предустановленно!
Как можно создать инстанс на базе одного из образов?
Существует два варианта создать новый инстанс на базе этих образов:
- При помощи Google Cloud Marketplace Web UI
- При помощи gcloud
Так, как я большой фанат терминала и CLI утилит, то в этой статье я расскажу именно об этом варианте. Тем более, если Вы любите UI, есть довольно неплохая документация, описывающая как создать инстанс при помощи Web UI.
Перед тем, как продолжить, установите (если еще не установили) тулзу gcloud. Опционально Вы можете использовать Google Cloud Shell, однако учтите, что функция WebPreview в Google Cloud Shell в настоящий момент не поддерживается и посему Вы не сможете там использовать Jupyter Lab или Notebook.
Следующим этапом будет выбор семейства изображений. Я позволю себе еще раз привести шпаргалку с выбором семейства изображений.
Для примера, мы предположим, что Ваш выбор пал на tf-latest-cu92, его мы и будем использовать далее по тексту.
Погодите, но что если мне нужна конкретная версия TensorFlow, а не “последняя”?
Предположим, что у нас есть проект, который требует TensorFlow 1.8, но в тоже время 1.9 уже вышел в свет и образы в семействе tf-latest уже имеют 1.9. Для такого случая у нас есть семейство изображений, которое всегда имеет определенную версию фреймворка (в нашем случае, tf-1-8-cpu и tf-1-8-cu92). Эти семейства изображений будут обновляться, но версия TensorFlow в них меняться не будет.
Так как это только Beta релиз, то сейчас мы поддерживаем только TensorFlow 1.8/1.9 и PyTorch 0.4. Мы планируем поддерживать последующее релизы, но мы не можем на текущем этапе четко ответить на вопрос как долго будут поддерживатся старые версии.
Что, если я хочу создать кластер или использовать один и тот же образ?
Действительно, может быть много случаев, когда необходимо переиспользовать один и тот же образ вновь и вновь (а не семью образов). Строго говоря, использование образов напрямую это почти всегда предпочтительный вариант. Ну, например, если Вы запускаете кластер с несколькими инстансами, не рекомендуется в таком случае указывать в Ваших скриптах напрямую семейства образов, так как если семейство будет обновлено в момент, когда скрипт работает, есть вероятность, что разные инстансы кластера будут созданы из разных образов (и могут иметь разные версии библиотек!). В таких случая предпочтительно вначале получить конкретное имя образа их семейства, а уже потом использовать конкретное имя.
Если интересует эта тема, можете посмотреть на мою статью “Как правильно использовать семейства изображений”.
Посмотреть имя последнего образа в семействе можно простой командой:
gcloud compute images describe-from-family tf-latest-cu92 --project deeplearning-platform-releaseДопустим что имя конкретного образа tf-latest-cu92–1529452792, его то уже и можно использовать где угодно:
Время создать наш первый инстанс!
Чтобы создать инстанс из семейства образов, достаточно выполнить одну простую команду:
export IMAGE_FAMILY="tf-latest-cu92" # подставьте нужное семейство образов
export ZONE="us-west1-b"
export INSTANCE_NAME="my-instance"
gcloud compute instances create $INSTANCE_NAME --zone=$ZONE --image-family=$IMAGE_FAMILY --image-project=deeplearning-platform-release --maintenance-policy=TERMINATE --accelerator='type=nvidia-tesla-v100,count=8' --metadata='install-nvidia-driver=True'Если Вы используете имя образа, а не семейство образов, нужно заменить “?--?image-family=$IMAGE_FAMILY” на “?--?image=$IMAGE-NAME”.
Если Вы используете инстанс с GPU, то необходимо обратить внимание на такие обстоятельства:
Вам нужно выбрать правильную зону. Если Вы создаете инстанс с определенным GPU, Вам нужно убедится, что этот тип GPU доступен в зоне, в которой Вы создаете инстанс. Вот тут можно найти соответсвие зон типам GPU. Как можно увидеть, us-west1-b единственная зона, в которой есть все 3 возможных типа GPU (K80/P100/V100).
Убедитесь, что у Вас есть достаточно квоты, чтобы создать инстанс с GPU. Даже, если Вы выбрали верный регион, это еще не значит, что у Вас есть квота на создание инстанса с GPU в этом регионе. По умолчанию квота на GPU установлена в ноль во всех регионах, так что все попытки создать инстанс с GPU провалятся. Хорошее объяснение того, как увеличить квоту можно найти вот тут.
Убедитесь, что в зоне есть достаточно GPU, чтобы удовлетворить Ваш запрос. Даже, если Вы выбрали верный регион и у Вас есть квота на GPU в этом регионе, это еще не означает, что в этой зоне есть в наличии интересующее Вас GPU. К сожалению, я не в курсе как еще можно проверить наличие GPU, кроме как попыткой создать инстанс и посмотреть что будет =)
Выберете корректное количество GPU (в зависимости от типа GPU). Дело в том, что флаг “accelerator” в нашей команде отвечает за тип и за количество GPU, которое будет доступно инстансу: т.е. “-- accelerator=’type=nvidia-tesla-v100,count=8'” создаст инстанс с восемью доступными GPU Nvidia Tesla V100 (Volta). Каждый тип GPU имеет допустимый список значений числа count. Вот этот самый список для каждого типа GPU :
- nvidia-tesla-k80, can have counts: 1, 2, 4, 8
- nvidia-tesla-p100, can have counts: 1, 2, 4
- nvidia-tesla-v100, can have counts: 1, 8
Дайте разрешение Google Cloud установить драйвер Nvidia от Вашего имени в момент запуска инстанса. Драйвер от Nvidia является обязательной составляющей. По причинам выходящим за рамки этой статьи, в образах нету предустановленного драйвера Nvidia. Однако, можно дать право Google Cloud установить его от Вашего имени при первом запуске инстанса. Это сделано путем добавления флага “?--?metadata=’install-nvidia-driver=True’”. Если Вы не укажите этот флаг, то при первом подключении по SSH Вам будет предложено установить драйвер.
К сожалению, процесс установки драйвера занимает время при первой загрузки, так как ему нужно этот самый драйвер загрузить и установить (а это влечет за собой еще и перезагрузку инстанса). В общей сложности это не должно занять более 5 минут. Мы еще поговорим немного позже о том, как можно уменьшить время первой загрузки.
Подключение к инстансу по SSH
Это проще паренной репы и может быть сделано одной командой:
gcloud compute ssh $INSTANCE_NAMEgcloud создаст пару ключей и автоматически загрузит их на новосозданный инстанс, а также создаст на нем Вашего пользователя. Если хочется сделать этот процесс еще более простым, то можете воспользоваться функцией которая упрощает и это:
function gssh() {
gcloud compute ssh $@
}
gssh $INSTANCE_NAMEКстати, Вы можете найти все мои gcloud bash функции вот тут. Ну а перед тем, как мы перейдем к вопросу того, насколько эти образы быстрые, ну или что с ними можно сделать, позвольте мне уточнить о проблеме со скоростью запуска инстансов.
Как можно уменьшить время первого запуска?
Технически время самого первого запуска — никак. Но можно:
- создать самый дешевый n1-standard-1 инстанс с одним K80;
- подождать пока первая загрузка закончится;
- проверить, что Nvidia драйвер установлен (это можно сделать запустив “nvidia-smi”);
- остановить инстанс;
- создать собственный образ из остановленного инстанса;
- Profit ?—? все инстансы, созданные из Вашего производного образа, будут иметь легендарное 15 секундное время запуска.
Итак, из этого списка нам уже известно, как создать новый инстанс и подключится к нему, также мы знаем, как проверить драйвера на работоспособность. Осталось лишь рассказать о том, как останавливать инстанс и создавать из него образ.
Для остановки инстанса выполните следующую команду:
function ginstance_stop() {
gcloud compute instances stop?-?quiet $@
}
ginstance_stop $INSTANCE_NAMEА вот команда для создания образа:
export IMAGE_NAME="my-awesome-image"
export IMAGE_FAMILY="family1"
gcloud compute images create $IMAGE_NAME? --source-disk $INSTANCE_NAME? --source-disk-zone $ZONE? --family $IMAGE_FAMILYПоздравляю, теперь у Вас есть свой образ с установленными Nvidia драйверами.
Как насчет Jupyter Lab?
Как только Ваш инстанс работает, следующим логичным шагом будет запустить Jupyter Lab, чтобы заняться непосредственно делом :) С новыми образами это очень просто. Jupyter Lab уже запущен с момента, как был запущен инстанс. Все, что нужно сделать — это подключится к инстансу с пробрасыванием порта, на котором слушает Jupyter Lab. А это порт 8080. Это делается следующей командой:
gssh $INSTANCE_NAME -- -L 8080:localhost:8080Все готово, теперь можно просто открыть Ваш любимый браузер и зайти на http://localhost:8080
Насколько быстрее TensorFlow из образов?
Очень Важный вопрос, так как скорость тренинга модели — реальные деньги. Однако, полный ответ на этот вопрос будет длиннее всего, что уже написано в этой статье. Так что Вам придется подождать следующей статьи:)
Ну а пока я Вас побалую некоторыми числами полученными на моем маленьком личном эксперименте. Итак, скорость тренинга на ImageNet составила 6100 изображений в секунду (сеть ResNet-50). Мой личный бюджет не позволил мне закончить тренировку модели полностью, однако, при такой скорости, я предполагаю, что можно достичь 75% точности за 5 часов с небольшим.
Где получить помощь?
Если Вам нужна любая информация относительно новых образов Вы можете:
- задать вопрос на stackoverflow, с тегом google-dl-platform;
- написать в открытую Google Group;
- можете написать мне на почту или в твиттер.
Ваша обратная связь очень важна, если Вам есть что сказать относительно образов, пожалуйста, не стесняйтесь и связывайтесь со мной любым удобным для Вас способом или оставляйте комментарий под этой статьей.