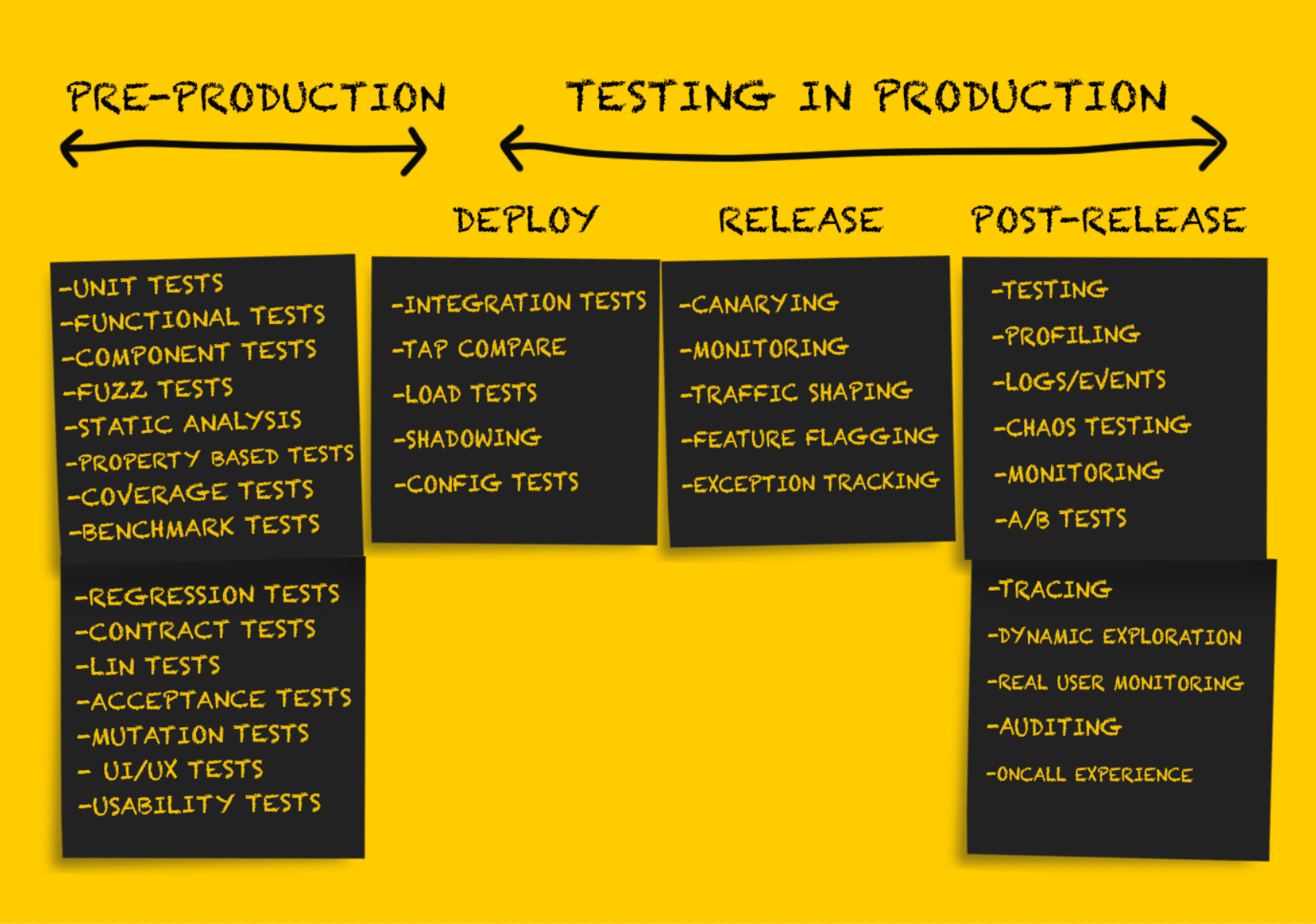
В этой части статьи мы продолжим рассматривать различные виды тестирования в продакшене. Те, кто пропустил первую часть, могут прочитать её здесь. Остальным — добро пожаловать под кат.
Тестирование на продакшене: релиз
Протестировав сервис после развёртывания, его необходимо подготовить к релизу.
Важно отметить, что на этом этапе откат изменений возможен только в ситуациях устойчивого отказа, например:
- зацикливание сбоя сервиса;
- превышение времени ожидания для значительного числа соединений в восходящем потоке, вызывающее сильное увеличение частоты возникновения ошибок;
- недопустимое изменение конфигурации, например, отсутствие секретного ключа в переменной среды, которое вызывает сбой в работе сервиса (переменных среды вообще лучше избегать, но это тема для отдельной дискуссии).
Тщательное тестирование на этапе развёртывания позволяет в идеале минимизировать или вовсе избежать неприятных неожиданностей на этапе выпуска. Тем не менее, существует ряд рекомендаций по безопасному выпуску нового кода.
Канареечное развёртывание
Канареечное развёртывание – это частичный выпуск сервиса в продакшен. По мере прохождения базовой проверки работоспособности в выпущенные части направляются небольшие объёмы текущего трафика продакшен-среды. Результаты работы частей сервиса отслеживаются по мере обработки трафика, показатели сопоставляются с эталонными (не относящимися к канареечным), и если они выходят за пределы допустимых пороговых значений, то выполняется откат к предыдущему состоянию. Хотя этот подход, как правило, применяется при выпуске серверного программного обеспечения, всё более распространённым становится также канареечное тестирование клиентского программного обеспечения.
Различные факторы влияют на то, какой трафик будет использован для канареечного развёртывания. В ряде компаний выпущенные части сервиса сначала получают только внутренний пользовательский трафик (т.н. dogfooding). Если ошибок не наблюдается, то добавляется небольшая часть трафика продакшен-среды, после чего выполняется полноценное развёртывание. Откат к предыдущему состоянию в случае недопустимых результатов канареечного развёртывания рекомендуется выполнять автоматически, и в таких инструментах, как Spinnaker, предусмотрена встроенная поддержка автоматизированного анализа и функции отката.
С канареечным тестированием связаны некоторые проблемы, и в этой статье представлен достаточно полный их обзор.
Мониторинг
Мониторинг является совершенно необходимой процедурой на каждом этапе развёртывания продукта в продакшене, однако особенно важной эта функция будет на этапе релиза. Мониторинг хорошо подходит для получения сведений об общем уровне работоспособности систем. А вот мониторинг всего на свете может быть не самым лучшим решением. Эффективный мониторинг выполняется точечно, что позволяет выявить небольшой набор режимов устойчивого отказа системы или базового набора показателей. Примерами таких режимов отказа могут быть:
- увеличение частоты возникновения ошибок;
- снижение общей скорости обработки запросов во всём сервисе, на конкретной конечной точке или, что ещё хуже, полное прекращение работы;
- увеличение задержки.
Наблюдение любого из таких режимов устойчивого отказа является основанием для немедленного отката к предыдущему состоянию или наката новых выпущенных версий программного обеспечения. Важно помнить, что мониторинг на этом этапе вряд ли будет полноценным и показательным. Многие полагают, что идеальное количество отслеживаемых во время мониторинга сигналов — от 3 до 5, но однозначно не более 7–10. Технический документ Facebook по Kraken предлагает следующий вариант решения:
«Задача решается при помощи легконастраиваемого компонента для мониторинга, которому сообщается два базовых показателя (99-й перцентиль времени отклика веб-сервера и частота возникновения неустранимых ошибок HTTP), объективно описывающих качество взаимодействия с пользователями».
Набор показателей системы и приложения, в отношении которых выполняется мониторинг на этапе релиза, лучше всего определять во время проектирования системы.
Отслеживание исключений
Речь идёт об отслеживании исключений на этапе релиза, хотя может показаться, что на этапах развёртывания и после релиза это было бы не менее полезным. Средства отслеживания исключений зачастую не гарантируют такой же тщательности, точности и массовости охвата, как некоторые другие инструменты контроля системы, однако они всё равно могут быть очень полезны.
Инструменты с открытым исходным кодом (например, Sentry) отображают расширенные сведения о поступающих запросах и создают стеки данных о трассировке и локальных переменных, что существенно упрощает процесс отладки, обычно заключающийся в просмотре логов событий. Отслеживание исключений также полезно при сортировке и приоритизации проблем, которые не требуют полного отката к предыдущему состоянию (например, пограничный случай, вызывающий исключение).
Шейпинг трафика
Шейпинг трафика (перераспределение трафика) – это не столько самостоятельная форма тестирования, сколько инструмент для поддержки канареечного подхода и поэтапного выпуска нового кода. По сути, шейпинг трафика обеспечивается за счёт обновления конфигурации балансировщика нагрузки, что позволяет постепенно перенаправлять всё больше трафика в новую выпущенную версию.
Этот метод также полезно использовать при поэтапном развёртывании нового программного обеспечения (отдельно от обычного развёртывания). Рассмотрим пример. Компании imgix в июне 2016 года требовалось развернуть принципиально новую архитектуру инфраструктуры. После первого тестирования новой инфраструктуры с помощью некоторого объёма тёмного трафика они приступили к развёртыванию в продакшене, изначально перенаправив примерно 1% трафика продакшен-среды в новый стек. Затем в течение нескольких недель наращивали объёмы данных, поступающих в новый стек (решая попутно возникающие проблемы), пока он не стал обрабатывать 100% трафика.
Популярность архитектуры service mesh обусловила новый всплеск интереса к прокси-серверам. В результате как в старые (nginx, HAProxy), так и в новые (Envoy, Conduit) прокси-серверы добавили поддержку новых функций в попытке обогнать конкурентов. Мне кажется, что будущее, в котором перераспределение трафика от 0 до 100% на этапе релиза продукта выполняется автоматически, уже не за горами.
Тестирование в продакшене: после релиза
Тестирование после релиза осуществляется в виде проверки, выполняемой после успешного релиза кода. На этом этапе можно быть уверенными в том, что код в целом является верным, он успешно выпущен в продакшен и обрабатывает трафик надлежащим образом. Развёрнутый код непосредственно или косвенно используется в реальных условиях, обслуживая реальных клиентов или выполняя задачи, которые оказывают существенное влияние на бизнес.
Цель любого тестирования на этом этапе сводится в основном к проверке работоспособности системы с учётом возможных различных нагрузок и схем трафика. Лучший способ это сделать – собрать документальные свидетельства обо всём, что происходит в продакшене, и использовать их как для отладки, так и для получения полного представления о системе.
Feature Flagging, или Тёмный запуск
Самая старая публикация об успешном применении feature flags (флагов функций), которую мне удалось найти, опубликована почти десять лет назад. На веб-сайте featureflags.io представлено самое полное руководство по этому вопросу.
«Feature flagging представляет собой метод, используемый разработчиками для маркировки новой функции с помощью операторов if-then, что позволяет более тщательно контролировать её релиз. Пометив функцию флагом и изолировав её таким образом, разработчик получает возможность включать и выключать эту функцию независимо от статуса развёртывания. Это позволяет эффективно отделить выпуск функции от развёртывания кода».
Пометив новый код флагом, можно тестировать его производительность и работоспособность в продакшене по мере необходимости. Feature flagging – один из общепринятых типов тестирования в продакшене, он хорошо известен и часто описывается в различных источниках. Гораздо менее известен тот факт, что этот метод можно использовать и в процессе тестирования переноса баз данных или программного обеспечения для персональных систем.
О чём редко пишут авторы статей, так это о лучших методах разработки и применения флагов функций. Неконтролируемое использование флагов может стать серьёзной проблемой. Отсутствие дисциплины в плане удаления неиспользуемых флагов по истечении заданного периода иногда приводит к тому, что приходится проводить полную ревизию и удалять устаревшие флаги, накопленные за месяцы (если не за годы) работы.
A/B-тестирование
A/B-тестирование зачастую выполняется в рамках экспериментального анализа и не рассматривается как тестирование в продакшене. По этой причине A/B-тесты не только широко (иногда даже сомнительным образом) используют, но и активно изучают и описывают (включая статьи о том, что определяет эффективную систему показателей для онлайн-экспериментов). Гораздо реже A/B-тесты используются для тестирования различных конфигураций оборудования или виртуальных машин. Их часто называют «тюнингом» (например, тюнинг JVM), но не относят к типичным A/B-тестам (хотя тюнинг вполне можно рассматривать как тип A/B-теста, выполняемого с тем же уровнем строгости, когда речь идёт об измерениях).
Логи, события, показатели и трассировка
О так называемых «трёх китах наблюдаемости» – логах, показателях и распределённой трассировке можно почитать здесь.
Профилирование
В отдельных случаях для диагностики проблем производительности необходимо использовать профилирование приложений в продакшене. В зависимости от поддерживаемых языков и сред выполнения профилирование может быть довольно простой процедурой, предполагающей добавление всего одной строки кода в приложение (
import _ "net/http/pprof" в случае с Go). С другой стороны, оно может потребовать применения множества инструментов либо тестирования выполняемого процесса методом чёрного ящика и проверки результатов с помощью таких инструментов, как flamegraphs.Tee-тест
Многие считают такое тестирование чем-то вроде теневого дублирования данных, поскольку в обоих случаях трафик продакшен-среды отправляется в непроизводственные кластеры или процессы. На мой взгляд, разница заключается в том, что использование трафика в целях тестирования несколько отличается от его использования в целях отладки.
Компания Etsy писала в своём блоге об использовании tee-тестов в качестве инструмента верификации (этот пример действительно напоминает теневое дублирование данных).
«Здесь tee можно воспринимать как команду tee в командной строке. Мы написали правило iRule на основе существующего балансировщика нагрузки F5, чтобы клонировать трафик HTTP, направленный в один из пулов, и переадресовать его в другой пул. Таким образом, мы смогли использовать трафик продакшен-среды, направленный в наш API-кластер, и отправить его копию в экспериментальный кластер HHVM, а также в изолированный PHP-кластер для сравнения.
Этот приём оказался очень эффективным. Он позволил нам сравнить производительность двух конфигураций, используя для этого идентичные профили трафика».
Тем не менее, иногда выполнение tee-теста на основе трафика продакшен-среды в автономной системе требуется для проведения отладки. В таких случаях автономную систему можно изменить, чтобы настроить вывод дополнительной диагностической информации или другую процедуру компиляции (например, с помощью инструмента очистки потока), что существенно упрощает процесс устранения неполадок. В таких случаях tee-тесты следует считать, скорее, инструментами отладки, а не проверки.
Раньше в imgix такие типы отладки встречались сравнительно редко, но всё же применялись, особенно если речь шла о проблемах с отладкой приложений, чувствительных к задержке.
Например, ниже приведено аналитическое описание одного из таких инцидентов, произошедших в 2015 году. Ошибка 400 возникала настолько редко, что её почти не видели, когда пытались воспроизвести проблему. Она появлялась буквально в нескольких случаях из миллиарда. За день их было совсем немного. В итоге оказалось, что надёжно воспроизвести проблему просто невозможно, поэтому потребовалось выполнить отладку с использованием рабочего трафика, чтобы появился шанс отследить возникновение этой ошибки. Вот что написал об этом мой бывший коллега:
«Я выбрал библиотеку, которая должна была быть внутренней, но в конечном счёте пришлось создать собственную на основе библиотеки, предоставленной системой. В версии, предоставленной системой, периодически возникала ошибка, которая никак не проявлялась, пока объём трафика был небольшим. Однако истинной проблемой стало усечённое имя в заголовке.
За следующие два дня я подробно изучил проблему, связанную с повышенной частотой возникновения ложных ошибок 400. Ошибка проявлялась в весьма незначительном количестве запросов, а проблемы такого типа достаточно сложно поддаются диагностике. Всё это было похоже на пресловутую иголку в стоге сена: проблема встречалась в одном случае на миллиард.
Первым шагом в обнаружении источника ошибок было получение всех необработанных исходных данных HTTP-запросов, которые приводили к некорректному отклику. Чтобы выполнить tee-тест входящего трафика при подключении к сокету, я добавил конечную точку сокета домена Unix на сервер визуализации. Идея заключалась в том, чтобы позволить нам быстро и без особых затрат включать и отключать поток тёмного трафика и проводить тестирование непосредственно на компьютере разработчика. Чтобы избежать проблем в продакшене, требовалось разрывать соединение, если возникала проблема back-pressure. Т.е. если дубликат не справлялся с задачей, он отключался. Этот сокет был весьма полезным в ряде случаев во время разработки. На этот раз, однако, мы использовали его для сбора входящего трафика на выбранных серверах, надеясь получить достаточное количество запросов, чтобы выявить закономерность, которая привела к возникновению ложных ошибок 400. С помощью dsh и netcat мне удалось сравнительно легко вывести входящий трафик в локальный файл.
Большая часть среды была потрачена на сбор этих данных. Как только у нас накопилось достаточно данных, я смог использовать netcat, чтобы воспроизвести их в локальной системе, конфигурация которой была изменена для вывода большого объёма информации об отладке. И всё прошло отлично. Следующий шаг – воспроизведение данных на максимально высокой скорости. В этом случае цикл с проверкой условия отправлял необработанные запросы поочерёдно. Примерно через два часа мне удалось достигнуть желаемого результата. Данные в логах демонстрировали отсутствие заголовка!
Для передачи заголовков я использую красно-чёрное дерево. Такие структуры рассматривают сравнимость как идентичность, что само по себе очень полезно при наличии специальных требований к ключам: в нашем случае заголовки HTTP не учитывали регистр. Сначала мы думали, что проблема была в листовом узле используемой библиотеки. Порядок добавления действительно влияет на порядок построения базового дерева, а балансировка красно-чёрного дерева — довольно сложный процесс. И хотя эта ситуация была маловероятной, она не была невозможной. Я переключился на другую реализацию красно-чёрного дерева. Оно было исправлено несколько лет назад, так что я решил встроить его непосредственно в исходник, чтобы точно получить ту версию, которая была необходима. Тем не менее, сборка выбрала иную версию, и поскольку я рассчитывал на более новую, то получил в итоге некорректное поведение.
Из-за этого система визуализации выдавала ошибки 500, что приводило к прерыванию цикла. Вот почему ошибка возникала только с течением времени. После циклической обработки нескольких сборок трафик из них был перенаправлен по другому маршруту, что увеличивало масштаб проблемы на данном сервере. Моё предположение, что проблема заключалась в библиотеке, оказалось неверным, и обратное переключение позволило устранить ошибки 500.
Я вернулся к ошибкам 400: всё ещё оставалась проблема, связанная с ошибкой, для обнаружения которой понадобилось примерно два часа. Смена библиотеки, очевидно, не решала проблему, но я был уверен в том, что выбранная библиотека достаточно надёжна. Не осознавая ошибочность выбора, я ничего не менял. Изучив ситуацию более подробно, я понял, что верное значение хранилось в односимвольном заголовке (например, «h: 12345»). До меня наконец дошло, что h — концевой символ заголовка Content-Length. Вновь просмотрев данные, я понял, что заголовок Content-Length был пустым.
В итоге всё дело было в ошибке смещения на единицу при считывании заголовков. Анализатор HTTP nginx/joyent создаёт частичные данные, и каждый раз, когда поле частичного заголовка оказывалось на один символ короче, чем нужно, я отправлял заголовок без значения и впоследствии получал поле односимвольного заголовка, содержащее верное значение. Это довольно редкая комбинация, поэтому её срабатывание занимает такое продолжительное время. Так что я увеличил объёмы сбора данных при каждом появлении односимвольного заголовка, применил предложенное исправление и успешно выполнял сценарий в течение нескольких часов.
Конечно, могли обнаружиться ещё какие-нибудь подводные камни с упомянутой неисправностью библиотеки, но обе ошибки были устранены».
Инженерам, занимающимся разработкой чувствительных к задержке приложений, нужна возможность отладки с использованием захваченного динамического трафика, поскольку зачастую возникают ошибки, которые невозможно воспроизвести при юнит-тестировании или обнаружить с помощью инструмента мониторинга (особенно если при логировании есть серьёзная задержка).
Подход Chaos Engineering
Chaos Engineering – это подход, основанный на проведении экспериментов над распределённой системой с целью подтвердить её способность противостоять хаотичным условиям продакшен-среды.
Метод Chaos Engineering, впервые ставший известным благодаря инструменту Chaos Monkey от компании Netflix, теперь превратился в самостоятельную дисциплину. Термин Chaos Engineering появился совсем недавно, однако тестирование методом внесения неисправностей — давно существующая практика.
Термином «хаотическое тестирование» обозначаются следующие приемы:
- отключение произвольных узлов, чтобы определить, насколько система устойчива к их отказу;
- внесение ошибок (например, увеличение задержки) с целью подтвердить, что система правильно их обрабатывает;
- принудительное нарушение работы сети в целях определения реакции сервиса.
Большинство компаний использует недостаточно сложную и многоуровневую операционную среду, чтобы эффективно проводить хаотическое тестирование. Важно подчеркнуть, что внесение неисправностей в систему лучше всего выполнять после настройки базовых функций отказоустойчивости. Этот технический документ компании Gremlin содержит достаточно полное описание принципов хаотического тестирования, а также инструкции по подготовке к этой процедуре.
«Особенно важен тот факт, что Chaos Engineering считается научной дисциплиной. В рамках этой дисциплины применяются высокоточные инженерные процессы.
Задача Chaos Engineering — сообщить пользователям что-то новое об уязвимостях системы путём проведения экспериментов над ней. Необходимо выявить все скрытые проблемы, которые могли возникнуть в продакшене, ещё до того, как они вызовут масштабный сбой. Только после этого вы сможете эффективно устранить все слабые места в системе и сделать её действительно отказоустойчивой».
Заключение
Целью тестирования в продакшене не является полное устранение всех возможных сбоев в системе. Джон Оллспоу (John Allspaw) говорит:
«Мы видим, что системы становятся всё более отказоустойчивыми — и это прекрасно. Но надо признать: «всё более» не равно «абсолютно». В любой сложной системе сбой может произойти (и произойдёт) самым непредсказуемым образом».
Тестирование в продакшене на первый взгляд может казаться довольно сложной задачей, выходящей далеко за пределы компетенции большинства инженерно-технических компаний. И хотя такое тестирование является непростым делом, связанным с некоторыми рисками, если выполнить его по всем правилам, оно поможет добиться надёжности сложных распределённых систем, которые сегодня встречаются повсеместно.