
Сейчас все очень много говорят про искусственный интеллект и его применение во всех сферах работы компании. Однако есть некоторые области, где еще с давних времён главенствует один вид модели, так называемый «белый ящик» — логистическая регрессия. Одна из таких областей – банковский кредитный скоринг.
Для этого есть несколько причин:
- Коэффициенты регрессии можно легко объяснить в отличие от «черных ящиков» вроде бустинга, куда может входить более 500 переменных
- Машинное обучение всё еще не вызывает доверия у менеджмента из-за сложности в интерпретации моделей
- Существуют неписанные требования регулятора к интепретируемости моделей: в любой момент, например, Центробанк может попросить объяснения — почему было отказано в кредите заемщику
- Компании используют внешние data mining программы (например, rapid miner, SAS Enterprise Miner, STATISTICA или любой другой пакет), которые позволяют быстро научиться строить модели, даже не имея навыков программирования
Эти причины делают практически невозможным использование сложных моделей машинного обучения в некоторых сферах, поэтому важно уметь «выжимать максимум» из простой логистической регрессии, которую легко объяснить и интерпретировать.
В этом посте мы расскажем о том, как при построении скоринга мы отказались от внешних data mining пакетов в пользу open source решения в виде Python, увеличили скорость разработки в несколько раз, а также улучшили качество всех моделей.
Процесс построения скоринга
Классический процесс построения скоринговых моделей на регрессии выглядит так:
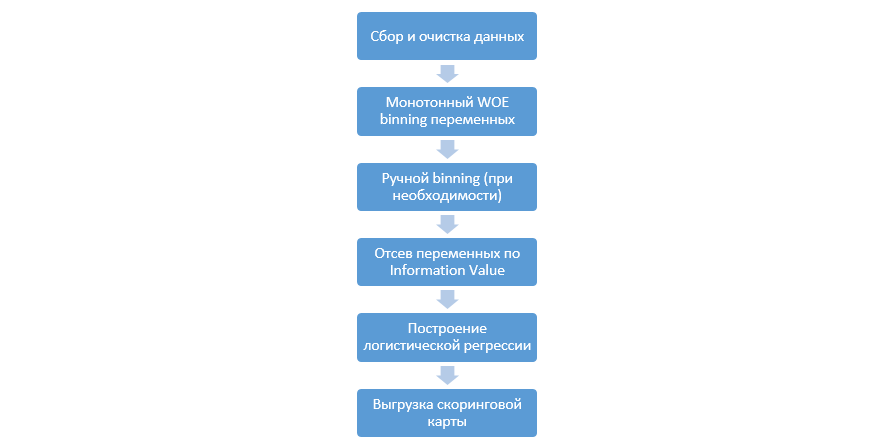
Он может меняться от компании к компании, но главные этапы остаются постоянными. Нам всегда необходимо производить биннинг переменных (в отличие от парадигмы машинного обучения, где в большинстве случаев нужно лишь категориальное кодирование), их отсев по Information Value (IV), и ручную выгрузку всех коэффициентов и бинов для последующей интеграции в DSL.
Такой подход к построению скоринговых карт отлично работал в 90-е, однако технологии классических data mining пакетов сильно устарели и не позволяют использовать новые методики, такие как, например, L2-регуляризация в регрессии, которые позволяют значительно улучшить качество моделей.
В один момент в качестве исследования мы решили воспроизвести все этапы, которые аналитики делают при построении скоринга, дополнить их знаниями Data Scientist’ов, а также максимально автоматизировать весь процесс.
Улучшение в Python
В качестве инструмента для разработки мы выбрали Python за его простоту и хорошие библиотеки, и начали воспроизводить все этапы по порядку.
Первым делом необходим сбор данных и генерация переменных – этот этап составляет значительную часть работы аналитиков.
В Python загрузить из базы собранные данные можно с помощью pymysql.
def con():
conn = pymysql.connect(
host='10.100.10.100',
port=3306,
user='******* ',
password='*****',
db='mysql')
return conn;
df = pd.read_sql('''
SELECT *
FROM idf_ru.data_for_scoring
''', con=con())Далее мы заменяем редкие и пропущенные значения отдельной категорией для предотвращения ovefitting’а, выбираем целевую, удаляем лишние колонки, а также делим на трейн и тест.
def filling(df):
cat_vars = df.select_dtypes(include=[object]).columns
num_vars = df.select_dtypes(include=[np.number]).columns
df[cat_vars] = df[cat_vars].fillna('_MISSING_')
df[num_vars] = df[num_vars].fillna(np.nan)
return df
def replace_not_frequent(df, cols, perc_min=5, value_to_replace = "_ELSE_"):
else_df = pd.DataFrame(columns=['var', 'list'])
for i in cols:
if i != 'date_requested' and i != 'credit_id':
t = df[i].value_counts(normalize=True)
q = list(t[t.values < perc_min/100].index)
if q:
else_df = else_df.append(pd.DataFrame([[i, q]], columns=['var', 'list']))
df.loc[df[i].value_counts(normalize=True)[df[i]].values < perc_min/100, i] =value_to_replace
else_df = else_df.set_index('var')
return df, else_df
cat_vars = df.select_dtypes(include=[object]).columns
df = filling(df)
df, else_df = replace_not_frequent_2(df, cat_vars)
df.drop(['credit_id', 'target_value', 'bor_credit_id', 'bchg_credit_id', 'last_credit_id', 'bcacr_credit_id', 'bor_bonuses_got' ], axis=1, inplace=True)
df_train, df_test, y_train, y_test = train_test_split(df, y, test_size=0.33, stratify=df.y, random_state=42)Теперь начинается самой важный этап в скоринге для регресии – необходимо написать WOE-binning для числовых и категориальных переменных. В открытом доступе мы не нашли хороших и подходящих для нас вариантов и решили написать сами. За основу числового биннинга взяли эту статью 2017 года, а также эту, категориальный написали сами с нуля. Результаты получились впечатляющими (Gini на тесте поднимался на 3-5 по сравнению с алгоритмами биннинга внешних data mining программ).
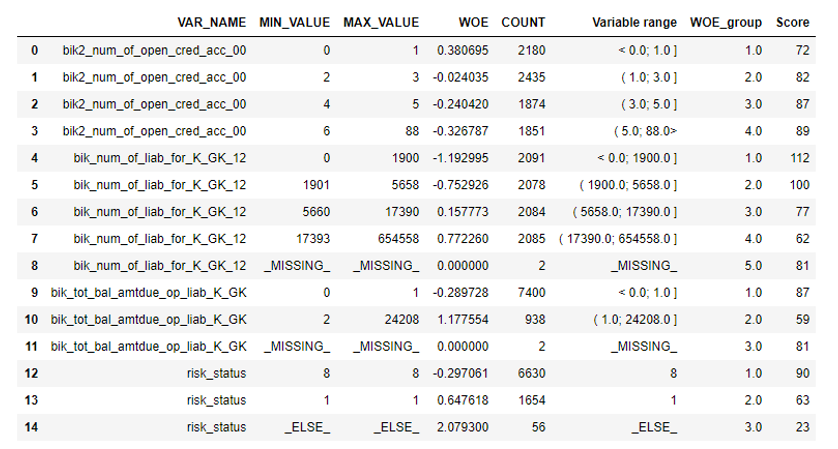
После этого можно посмотреть на графиках или таблицах (которые мы потом запишем в excel), как переменные разбились по группам и проверить монотонность:
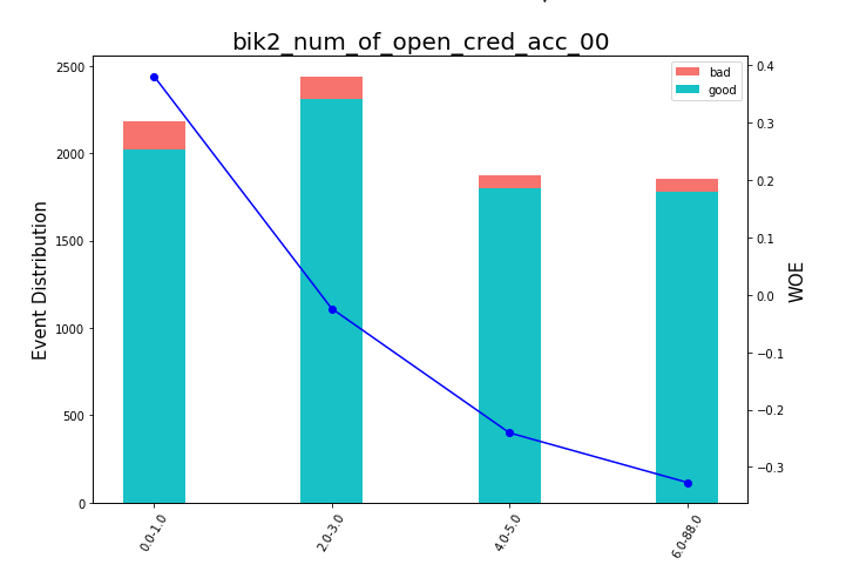
def plot_bin(ev, for_excel=False):
ind = np.arange(len(ev.index))
width = 0.35
fig, ax1 = plt.subplots(figsize=(10, 7))
ax2 = ax1.twinx()
p1 = ax1.bar(ind, ev['NONEVENT'], width, color=(24/254, 192/254, 196/254))
p2 = ax1.bar(ind, ev['EVENT'], width, bottom=ev['NONEVENT'], color=(246/254, 115/254, 109/254))
ax1.set_ylabel('Event Distribution', fontsize=15)
ax2.set_ylabel('WOE', fontsize=15)
plt.title(list(ev.VAR_NAME)[0], fontsize=20)
ax2.plot(ind, ev['WOE'], marker='o', color='blue')
# Legend
plt.legend((p2[0], p1[0]), ('bad', 'good'), loc='best', fontsize=10)
#Set xticklabels
q = list()
for i in range(len(ev)):
try:
mn = str(round(ev.MIN_VALUE[i], 2))
mx = str(round(ev.MAX_VALUE[i], 2))
except:
mn = str((ev.MIN_VALUE[i]))
mx = str((ev.MAX_VALUE[i]))
q.append(mn + '-' + mx)
plt.xticks(ind, q, rotation='vertical')
for tick in ax1.get_xticklabels():
tick.set_rotation(60)
plt.savefig('{}.png'.format(ev.VAR_NAME[0]), dpi=500, bbox_inches = 'tight')
plt.show()
def plot_all_bins(iv_df):
for i in [x.replace('WOE_','') for x in X_train.columns]:
ev = iv_df[iv_df.VAR_NAME==i]
ev.reset_index(inplace=True)
plot_bin(ev) Отдельно была написана функция для ручного биннинга, которая полезна, например, в случае с переменной «версия ОС», где все телефоны на Android и iOS были сгруппированы вручную.
def adjust_binning(df, bins_dict):
for i in range(len(bins_dict)):
key = list(bins_dict.keys())[i]
if type(list(bins_dict.values())[i])==dict:
df[key] = df[key].map(list(bins_dict.values())[i])
else:
#Categories labels
categories = list()
for j in range(len(list(bins_dict.values())[i])):
if j == 0:
categories.append('<'+ str(list(bins_dict.values())[i][j]))
try:
categories.append('(' + str(list(bins_dict.values())[i][j]) +'; '+ str(list(bins_dict.values())[i][j+1]) + ']')
except:
categories.append('(' + str(list(bins_dict.values())[i][j]))
elif j==len(list(bins_dict.values())[i])-1:
categories.append(str(list(bins_dict.values())[i][j]) +'>')
else:
categories.append('(' + str(list(bins_dict.values())[i][j]) +'; '+ str(list(bins_dict.values())[i][j+1]) + ']')
values = [df[key].min()] + list(bins_dict.values())[i] + [df[key].max()]
df[key + '_bins'] = pd.cut(df[key], values, include_lowest=True, labels=categories).astype(object).fillna('_MISSING_').astype(str)
df[key] = df[key + '_bins']#.map(df.groupby(key + '_bins')[key].agg('median'))
df.drop([key + '_bins'], axis=1, inplace=True)
return df
bins_dict = {
'equi_delinquencyDays': [ 200,400,600]
'loan_purpose': {'medicine':'1_group',
'repair':'1_group',
'helpFriend':'2_group'}
}
df = adjust_binning(df, bins_dict)Следующим этапом идёт отбор переменных по Information Value. Стандартным значением является кат офф 0.1 (все переменные ниже не имеют хорошей предсказательной силы).
После осуществлялась проверка на корреляцию. Из двух коррелирующих переменных нужно удалить ту, у которой IV меньше. Кат офф по удалению был взят 0.75.
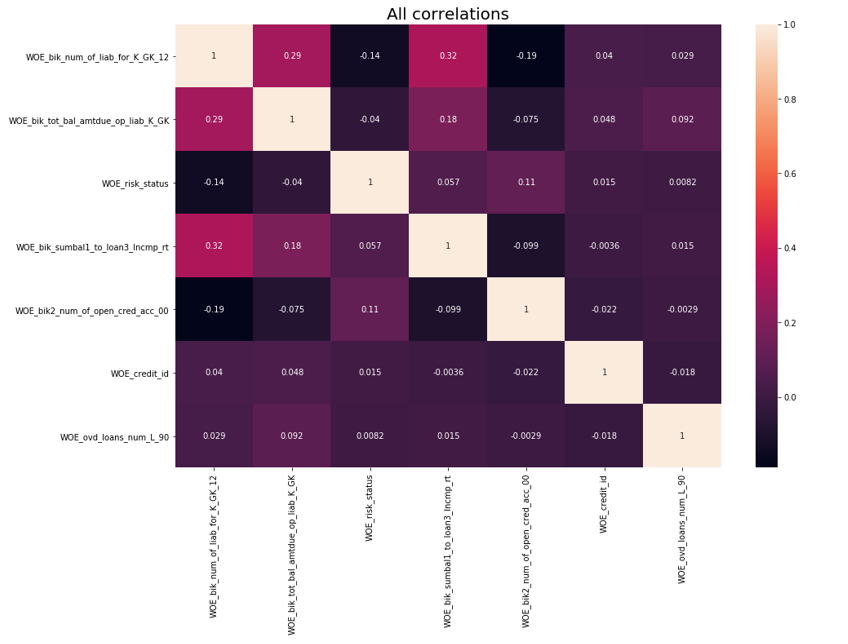
def delete_correlated_features(df, cut_off=0.75, exclude = []):
# Create correlation matrix
corr_matrix = df.corr().abs()
# Select upper triangle of correlation matrix
upper = corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k=1).astype(np.bool))
# Plotting All correlations
f, ax = plt.subplots(figsize=(15, 10))
plt.title('All correlations', fontsize=20)
sns.heatmap(X_train.corr(), annot=True)
# Plotting highly correlated
try:
f, ax = plt.subplots(figsize=(15, 10))
plt.title('High correlated', fontsize=20)
sns.heatmap(corr_matrix[(corr_matrix>cut_off) & (corr_matrix!=1)].dropna(axis=0, how='all').dropna(axis=1, how='all'), annot=True, linewidths=.5)
except:
print ('No highly correlated features found')
# Find index of feature columns with correlation greater than cut_off
to_drop = [column for column in upper.columns if any(upper[column] > cut_off)]
to_drop = [column for column in to_drop if column not in exclude]
print ('Dropped columns:', to_drop, '\n')
df2 = df.drop(to_drop, axis=1)
print ('Features left after correlation check: {}'.format(len(df.columns)-len(to_drop)), '\n')
print ('Not dropped columns:', list(df2.columns), '\n')
# Plotting final correlations
f, ax = plt.subplots(figsize=(15, 10))
plt.title('Final correlations', fontsize=20)
sns.heatmap(df2.corr(), annot=True)
plt.show()
return df2 Помимо отбора по IV мы добавили рекурсивный поиск оптимального количества переменных методом RFE из sklearn.
Как мы видим на графике – после 13 переменных качество не изменяется, а значит лишние можно удалить. Для регрессии более 15 переменных в скоринге считается плохим тоном, что в большинстве случаев исправляется с помощью RFE.
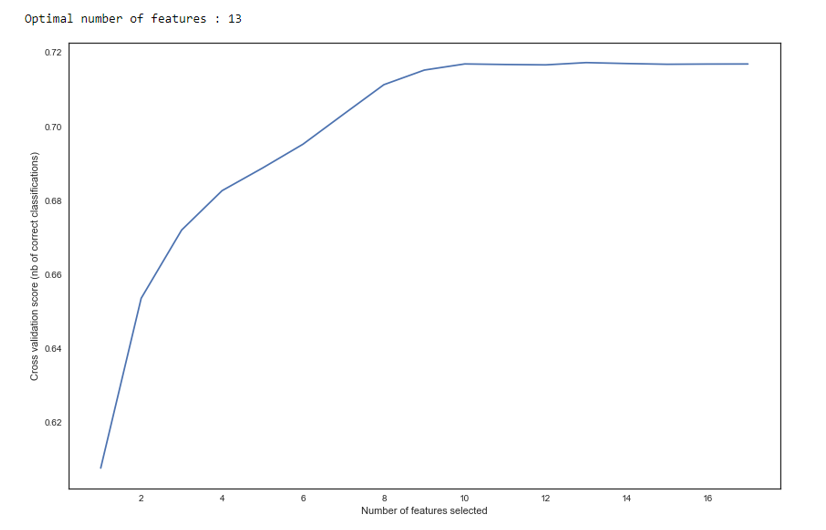
def RFE_feature_selection(clf_lr, X, y):
rfecv = RFECV(estimator=clf_lr, step=1, cv=StratifiedKFold(5), verbose=0, scoring='roc_auc')
rfecv.fit(X, y)
print("Optimal number of features : %d" % rfecv.n_features_)
# Plot number of features VS. cross-validation scores
f, ax = plt.subplots(figsize=(14, 9))
plt.xlabel("Number of features selected")
plt.ylabel("Cross validation score (nb of correct classifications)")
plt.plot(range(1, len(rfecv.grid_scores_) + 1), rfecv.grid_scores_)
plt.show()
mask = rfecv.get_support()
X = X.ix[:, mask]
return XДалее строилась регрессия и оценивались её метрики на кросс-валидации и тестовой выборке. Обычно все смотрят на коэффициент Gini (хорошая статья про него тут).
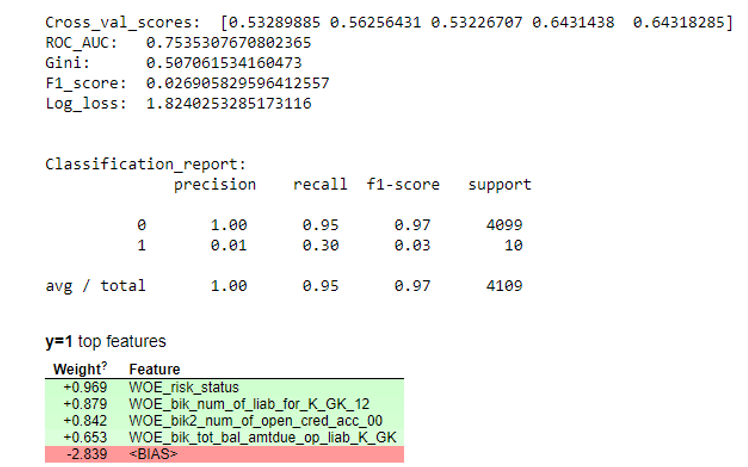
def plot_score(clf, X_test, y_test, feat_to_show=30, is_normalize=False, cut_off=0.5):
#cm = confusion_matrix(pd.Series(clf.predict_proba(X_test)[:,1]).apply(lambda x: 1 if x>cut_off else 0), y_test)
print ('ROC_AUC: ', round(roc_auc_score(y_test, clf.predict_proba(X_test)[:,1]), 3))
print ('Gini: ', round(2*roc_auc_score(y_test, clf.predict_proba(X_test)[:,1]) - 1, 3))
print ('F1_score: ', round(f1_score(y_test, clf.predict(X_test)), 3))
print ('Log_loss: ', round(log_loss(y_test, clf.predict(X_test)), 3))
print ('\n')
print ('Classification_report: \n', classification_report(pd.Series(clf.predict_proba(X_test)[:,1]).apply(lambda x: 1 if x>cut_off else 0), y_test))
skplt.metrics.plot_confusion_matrix(y_test, pd.Series(clf.predict_proba(X_test)[:,1]).apply(lambda x: 1 if x>cut_off else 0), title="Confusion Matrix",
normalize=is_normalize,figsize=(8,8),text_fontsize='large')
display(eli5.show_weights(clf, top=20, feature_names = list(X_test.columns)))
clf_lr = LogisticRegressionCV(random_state=1, cv=7)
clf_lr.fit(X_train, y_train)
plot_score(clf_lr, X_test, y_test, cut_off=0.5)Когда мы удостоверились в том, что качество модели нас устраивает, необходимо записать все результаты (коэффициенты регрессии, группы бинов, графики стабильности Gini и переменных и т.д.) в excel. Для этого удобно использовать xlsxwriter, который может работать как с данными, так и с картинками.
Примеры листов экселя:
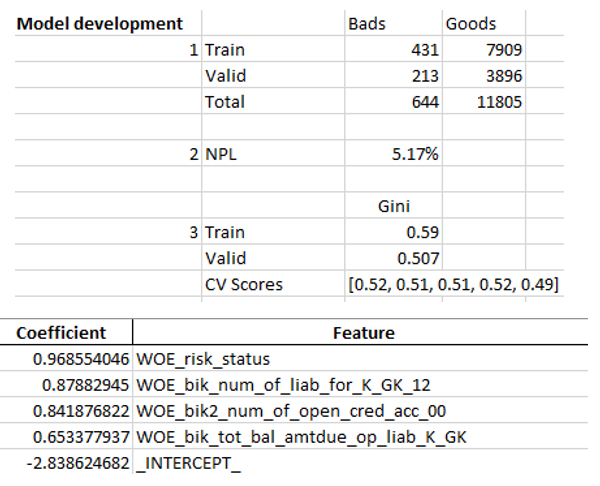
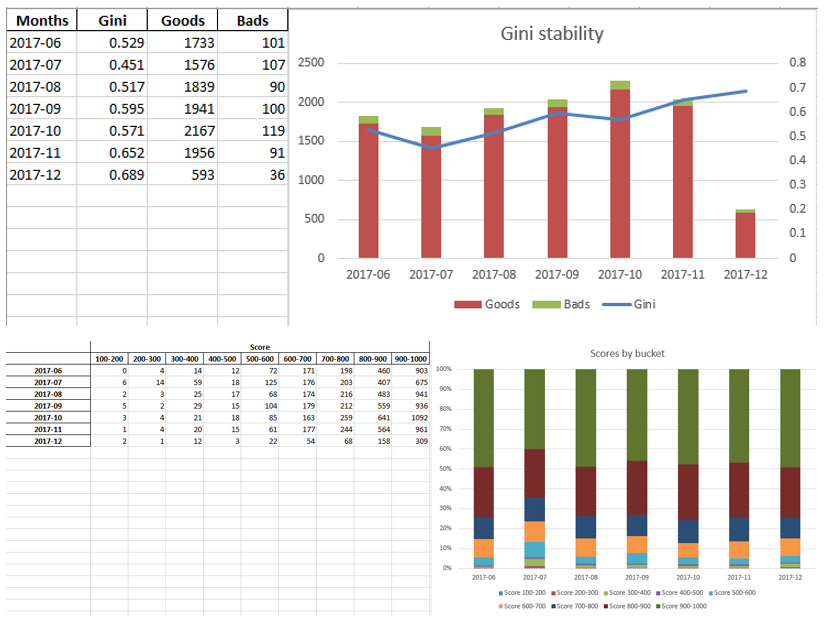
#WRITING
writer = pd.ExcelWriter('PDL_Score_20180815-3.xlsx', engine='xlsxwriter')
workbook = writer.book
worksheet = workbook.add_worksheet('Sample information')
bold = workbook.add_format({'bold': True})
percent_fmt = workbook.add_format({'num_format': '0.00%'})
worksheet.set_column('A:A', 20)
worksheet.set_column('B:B', 15)
worksheet.set_column('C:C', 10)
# Sample
worksheet.write('A2', 'Sample conditions', bold)
worksheet.write('A3', 1)
worksheet.write('A4', 2)
worksheet.write('A5', 3)
worksheet.write('A6', 4)
# Model
worksheet.write('A8', 'Model development', bold)
worksheet.write('A9', 1)
#labels
worksheet.write('C8', 'Bads')
worksheet.write('D8', 'Goods')
worksheet.write('B9', 'Train')
worksheet.write('B10', 'Valid')
worksheet.write('B11', 'Total')
# goods and bads
worksheet.write('C9', y_train.value_counts()[1])
worksheet.write('C10', y_test.value_counts()[1])
worksheet.write('D9', y_train.value_counts()[0])
worksheet.write('D10', y_test.value_counts()[0])
worksheet.write('C11', y.value_counts()[1])
worksheet.write('D11', y.value_counts()[0])
# NPL
worksheet.write('A13', 2)
worksheet.write('B13', 'NPL')
worksheet.write('C13', (y.value_counts()[1]/(y.value_counts()[1]+y.value_counts()[0])), percent_fmt)
worksheet.write('A16', 3)
worksheet.write('C15', 'Gini')
worksheet.write('B16', 'Train')
worksheet.write('B17', 'Valid')
worksheet.write('B18', 'CV Scores')
worksheet.write('C18', str([round(sc, 2) for sc in scores]))
worksheet.write('C16', round(2*roc_auc_score(y_train, clf_lr.predict_proba(X_train)[:,1]) - 1, 3))
worksheet.write('C17', round(2*roc_auc_score(y_test, clf_lr.predict_proba(X_test)[:,1]) - 1, 3))
# Regreesion coefs
feat.to_excel(writer, sheet_name='Regression coefficients', index=False)
worksheet2 = writer.sheets['Regression coefficients']
worksheet2.set_column('A:A', 15)
worksheet2.set_column('B:B', 50)
#WOE
ivs[['VAR_NAME', 'Variable range', 'WOE', 'COUNT', 'WOE_group']].to_excel(writer, sheet_name='WOE', index=False)
worksheet3 = writer.sheets['WOE']
worksheet3.set_column('A:A', 50)
worksheet3.set_column('B:B', 60)
worksheet3.set_column('C:C', 30)
worksheet3.set_column('D:D', 20)
worksheet3.set_column('E:E', 12)
for num, i in enumerate([x.replace('WOE_','') for x in X_train.columns]):
ev = iv_df[iv_df.VAR_NAME==i]
ev.reset_index(inplace=True)
worksheet3.insert_image('G{}'.format(num*34+1), '{}.png'.format(i))
df3.to_excel(writer, sheet_name='Data', index=False)
table.to_excel(writer, sheet_name='Scores by buckets', header = True, index = True)
worksheet4 = writer.sheets['Scores by buckets']
worksheet4.set_column('A:A', 20)
worksheet4.insert_image('J1', 'score_distribution.png')
Ginis.to_excel(writer, sheet_name='Gini distribution', header = True, index = True)
worksheet5 = writer.sheets['Gini distribution']
worksheet5.insert_image('E1', 'gini_stability.png')
writer.save()Итоговый excel в конце еще раз смотрится менеджментом, после чего отдаётся в IT для встраивания модели в продакшен.
Итог
Как мы увидели, почти все этапы скоринга можно автоматизировать так, чтобы аналитикам не нужны были навыки программирования для построения моделей. В нашем случае, после создания данного фреймворка от аналитика требуется лишь собрать данные и указать несколько параметров (указать целевую переменную, какие колонки удалить, минимальное количество бинов, коэффициент отсечения для корреляции переменных и т.д), после чего можно запустить скрипт на python, который построит модель и выдаст excel с нужными результатами.
Конечно же, иногда приходится исправлять код под нужды конкретного проекта, и одной кнопкой запуска скрипта при моделировании не обойдешься, однако даже сейчас мы видим качество лучше, чем у применяемых на рынке data mining пакетов благодаря таким техникам как оптимальный и монотонный биннинг, проверка на корреляцию, RFE, регуляризированная версия регрессии и т.д.
Таким образом, благодаря использованию Python мы значительно сократили время разработки скоринговых карт, а также уменьшили затраты труда аналитиков.
Комментарии (19)

lornemalvo
24.08.2018 13:08Знакома проблема черного/белого ящика, когда нужно строить объяснимую для бизнеса модель, хоть и работаю с другой отраслью (ритейл).
Для увеличения точности может помочь стакинг, когда результаты одного или нескольких «белых ящиков» подаются на вход другого «белого ящика». Если модель можно разложить на понятные компоненты. Например, в спросе на товары можно выделить сезонность, веса дней недель, эластичность по цене и т. д.
Voila2000
24.08.2018 13:30Вы пишите «а также улучшили качество всех моделей».
А по какому критерию вы оцениваете качество скоринговых моделей?
Такой подход работает с любыми типами заемщиков?Distem Автор
24.08.2018 13:31Качество оцениваем с помощью коэффициента Gini на тестовой выборке. И как раз благодаря методикам, описанным в статье он возрастает.
Второй вопрос не совсем понял.Kordamon
24.08.2018 20:03А вы пробовали оценивать эффективность в рублях? Типа «Средний доход от хорошего клиента — Цена привлечения — Потери от плохого — Упущенная выгода»

Andriljo
24.08.2018 16:15Вы используете Базель в качестве методологии расчета скоринг моделей? Но вы так же писали об том, что порой ML эффективнее в плане работы с категориями, но не продемонстрировали это. Так же вы используете бининг и WoE для отбора, причем понимаю это и для категорий и для чисел. Почему б не посмотреть в сторону методов ML для кодирования категорий и отбора признаков?
Distem Автор
24.08.2018 18:53В этой статье мы рассказываем только про логистическую регрессию и все процессы классического кредитного скоринга — то есть без применения машинного обучения. WoE
Биннинг не лучше кодирования для ML моделей, однако именно он даёт регрессии такую стабильность и интерпретируемость, за которые её любят в банках.
Kordamon
24.08.2018 18:35Спасибо, очень интересно!
Скажите:
1) Самый важный вопрос: насколько тако вариант регресии с самописным бинингом проигрывает ML моделям по Gini?
2) Как вы эту модель деплоите потом? У вас там на Проде Питон стоит или надо весь набор препроцесинга и модель заново кодить в Java?
3) Если для деплоя используется PMML, то как вы туда добавляете бины?Distem Автор
24.08.2018 19:131. В среднем ML модели выигрывают около 10-15 gini, однако они используют 100+ переменных вместо 10 в регрессии и чуть менее стабильны при изменении, например, потока клиентов.
2. В excel выгружаются бины и коэффициенты регрессии. В нашем случае (это не всегда так и зависит от компании) дальше создается DSL-скрипт — при попадание клиента в такой-то бин ему присвается такое-то WOE. После чего скрипт используется в Java.
Kordamon
24.08.2018 19:56На вашем потоке 10п Gini это некислые деньги! И руководство даже не использует ML модели параллельно?
А предобработка? Ну там, кросс-переменные, нормализация, вот эта логика для заполнения пропусков — как она попадает на Продакшн?
upd: не туда ответил, это коммент к комменту habr.com/company/idfinance/blog/421091/#comment_19030713Distem Автор
27.08.2018 10:27ML модели используются как раз в большинстве случаев. Для них используется Docker, в котором находится скрипт на питоне.
А в случае описанном в статье нормализация и замена пропусков как раз решается WOE биннингом.Kordamon
27.08.2018 12:28То есть у вас Продакшн скоринг в части ML работает на Питоне? Вот это и правда редкий случай, уважаю! :)
И какой поток входящих запросов держит один инстанс Докера, если не секрет?
Gewissta
25.08.2018 16:09в общем, бегло пробежал, какие замечания
Биннинг может помочь улучшить качество модели, потому что помогает лучше описать взаимосвязь между предиктором и зависимой переменной, но этого же можно добиться за счет преобразований (квадратный корень, кубический корень, свернутый корень, арксинусное простое или удвоенное, сплайны, ну или Бокс-Кокс для ленивых). Про недостатки биннинга хорошо написано у Харрелла biostat.mc.vanderbilt.edu/wiki/Main/CatContinuous Повысить стабильность позволяет не биннинг, а соблюдение трех предпосылок – нормальность (отсюда делаем преобразования, максимизирующие нормальность, хоть это и не так критично, как для линейной регрессии, но решение будет более стабильным), приведение переменных к единому масштабу (стандартизация) и регуляризация. Эластичная сеть есть в классе H2OGeneralizedLinearEstimator библиотеки h2o. Там логрег – частный случай GLM. Глянуть, как работает, можно здесь
github.com/Gewissta/Learning_Pandas_russian_translation/blob/master/Notebooks/%D0%9F%D1%80%D0%B8%D0%BB%D0%BE%D0%B6%D0%B5%D0%BD%D0%B8%D0%B5%204_%D0%9F%D1%80%D0%B8%D0%BC%D0%B5%D1%80%20%D0%BF%D1%80%D0%B5%D0%B4%D0%B2%D0%B0%D1%80%D0%B8%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D0%BE%D0%B9%20%D0%BF%D0%BE%D0%B4%D0%B3%D0%BE%D1%82%D0%BE%D0%B2%D0%BA%D0%B8%20%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85%20%D0%B2%20pandas.ipynb
Дополнительное удобство – можно задавать парные взаимодействия.
Выкидывать ручками коррелирующие переменные – тоже сомнительная затея, лучше сделать агрегаты по возможности или отдать это на откуп регуляризации, как это делает в H2O lambda_search — поиск оптимального значения штрафного коэффициента при переборе alpha, задающего соотношение l1 и l2-штрафов, ну и там гранулярность настраиваем с помощью nlambdas и lambda_min_ratio.
RFE и BorutaPy действительно помогают, но тут надо помнить, что помимо логрега надо тюнить еще и лес, с помощью которого отбираем фичи. Общее правило – брать не сильно глубокие деревья или спарсивать признаки на самых верхних уровнях, поскольку наиболее важные у нас будут в наиболее верхних уровнях.
По поводу машинного обучения. И опять-таки оно помогает нашей старушке логистической регрессии. Можно строить ансамбли CHAID и логистической регрессии. Можно построить лес, извлечь наиболее полезные правила (наиболее часто встречающиеся, дающие наименьшую ошибку) и подать на вход логрегу. Делается в пакетах R inTrees и RandomForestExplainer. Это называют моделью «мастер-ассистент», мастером выступает логистическая регрессия, ассистент, ищущий полезные фичи, — лес или бустинг. Разумеется, делаем это, когда основной feature engineering, обогащение внешними данными выполнены.Kordamon
25.08.2018 19:29Биннинг может помочь улучшить качество модели, потому что помогает лучше описать взаимосвязь между предиктором и зависимой переменной, но этого же можно добиться за счет преобразований (квадратный корень, кубический корень, свернутый корень, арксинусное простое или удвоенное, сплайны, ну или Бокс-Кокс для ленивых).
Самое интересное в бининге для таких задач, как банковский скоринг, это не стабильность (тут альтернатив и правда много), а то, что эксперт может добавить в модель свои знания. Возраст — классический случай. 99% что пик WOE по возрасту это косяк в данных или непредставительная выборка. Тогда аналитик накладывает ограничение неубывания WOE на бины — Gini падает на тренинговом множестве, но растет на тесте (а даже если и не растет на тесте, то стабильность модели все равно повышается).
ИМХО другого такого способа прямо выразить знания эксперта в модель в DS просто нет.
lornemalvo
Не пробовали использовать elastic net регуляризацию для выбора переменных? См. ссылки 1 и 2 ниже.
Я использую не Python, а R, но вроде в scikit-learn должна быть встроена elastic net регуляризация для логистической регрессии.
В любом случае, есть библиотека glmnet (см. ссылку 3), где реализована логистическая регрессия с кросс-валидацией и elastic net регуляризацией. По утверждению авторов, это еще и одна из самых быстрых реализаций (ссылка 4).
Ссылки:
1. en.wikipedia.org/wiki/Elastic_net_regularization
2. web.stanford.edu/~hastie/Papers/B67.2%20(2005)%20301-320%20Zou%20&%20Hastie.pdf
3. glmnet-python.readthedocs.io/en/latest/glmnet_vignette.html
4. web.stanford.edu/~hastie/Papers/glmnet.pdf
Distem Автор
Привет! Elastic Net пробовали использовать, она не встроена в обычную регрессию, но доступна в sklearn.linear_model.ElasticNet. В последней версии мы прогоняем разные версии регрессии, и выбирается наилучшая из них. Но у версии в sklearn есть минус — она не выдает вероятности (нет метода predict_proba)
Arseny_Info
Неудивительно, что в
sklearn.linear_model.ElasticNetнет методаpredict_proba, ведь это регрессор, а не классификатор в отличие от стандартного логрега. Впрочем, написать ElasticNet с нуля совсем не сложно — нужно только добавить кусок к лоссу в обычной логистической регрессии.lornemalvo
Написать elastic net или lasso (L1) с нуля сложнее, чем ridge (L2), потому что там есть часть с коэффициентами по модулю, который не дифференцируется в нуле. Да и незачем писать с нуля, если уже есть glmnet, в которой реализована логистическая и другие регрессии с elastic net, lasso и ridge регуляризацией и k-fold кросс-валидацией.