Какие возможности построения файлов Excel существуют в принципе?
- VBA-макросы. В наше время по соображениям безопасности идея использовать макросы чаще всего не подходит.
- Автоматизация Excel внешней программой через API. Требует наличия Excel на одной машине с программой, генерирующей Excel-отчёты. Во времена, когда клиенты были толстыми и писались в виде десктопных приложений Windows, такой способ годился (хотя не отличался скоростью и надёжностью), в нынешних реалиях это с трудом достижимый случай.
- Генерация XML-Excel-файла напрямую. Как известно, Excel поддерживает XML-формат сохранения документа, который потенциально можно сгенерировать/модифицировать с помощью любого средства работы с XML. Этот файл можно сохранить с расширением .xls, и хотя он, строго говоря, при этом не является xls-файлом, Excel его хорошо открывает. Такой подход довольно популярен, но к недостаткам следует отнести то, что всякое решение, основанное на прямом редактировании XML-Excel-формата, является одноразовым «хаком», лишенным общности.
- Наконец, возможна генерация Excel-файлов с использованием open source библиотек, из которых особо известна Apache POI. Разработчики Apache POI проделали титанический труд по reverse engineering бинарных форматов документов MS Office, и продолжают на протяжении многих лет поддерживать и развивать эту библиотеку. Результат этого reverse engineering-а, например, используется в Open Office для реализации сохранения документов в форматах, совместимых с MS Office.
На мой взгляд, именно последний из способов является сейчас предпочтительным для генерации MS Office-совместимых документов. С одной стороны, он не требует установки никакого проприетарного ПО на сервер, а с другой стороны, предоставляет богатый API, позволяющий использовать все функциональные возможности MS Office.
Но у прямого использования Apache POI есть и недостатки. Во-первых, это Java-библиотека, и если ваше приложение написано не на одном из JVM-языков, вы ей вряд ли сможете воспользоваться. Во-вторых, это низкоуровневая библиотека, работающая с такими понятиями, как «ячейка», «колонка», «шрифт». Поэтому «в лоб» написанная процедура генерации документа быстро превращается в обильную «лапшу» трудночитаемого кода, где отсутствует разделение на модель данных и представление, трудно вносить изменения и вообще — боль и стыд. И прекрасный повод делегировать задачу самому неопытному программисту – пусть ковыряется.
Но всё может быть совершенно иначе. Проект Xylophone под лицензией LGPL, построенный на базе Apache POI, основан на идее, которая имеет примерно 15-летнюю историю. В проектах, где я участвовал, он использовался в комбинации с самыми разными платформами и языками – а счёт разновидностей форм, сделанных с его помощью в самых разнообразных проектах, идёт, наверное, уже на тысячи. Это Java-проект, который может работать как в качестве утилиты командной строки, так и в качестве библиотеки (если у вас код на JVM-языке — вы можете подключить её как Maven-зависимость).
Xylophone реализует принцип отделения модели данных от их представления. В процедуре выгрузки необходимо сформировать данные в формате XML (не беспокоясь о ячейках, шрифтах и разделительных линиях), а Xylophone, при помощи Excel-шаблона и дескриптора, описывающего порядок обхода вашего XML-файла с данными, сформирует результат, как показано на диаграмме:

Шаблон документа (xls/xlsx template) выглядит примерно следующим образом:

Как правило, заготовку такого шаблона предоставляет сам заказчик. Вовлечённый заказчик с удовольствием принимает участие в создании шаблона: начиная с выбора нужной формы из «Консультанта» или придумывания собственной с нуля, и заканчивая размерами шрифтов и ширинами разделительных линий. Преимущество шаблона в том, что мелкие правки в него легко вносить уже тогда, когда отчёт полностью разработан.
Когда «оформительская» работа выполнена, разработчику остаётся
- Создать процедуру выгрузки необходимых данных в формате XML.
- Создать дескриптор, описывающий порядок обхода элементов XML-файла и копирования фрагментов шаблона в результирующий отчёт
- Обеспечить привязку ячеек шаблона к элементам XML-файла с помощью XPath-выражений.
С выгрузкой в XML всё более-менее понятно: достаточно выбрать адекватное XML-представление данных, необходимых для заполнения формы. Что такое дескриптор?
Если бы в форме, которую мы создаём, не было повторяющихся элементов с разным количеством (таких, как строки накладной, которых разное количество у разных накладных), то дескриптор выглядел бы следующим образом:
<element name="root">
<output range="A1:Z100"/>
</element>
Здесь root – название корневого элемента нашего XML-файла с данными, а диапазон A1:Z100 – это прямоугольный диапазон ячеек из шаблона, который будет скопирован в результат. При этом, как можно видеть из предыдущей иллюстрации, подстановочные поля, значения которых заменяются на данные из XML-файла, имеют формат
~{XPath-выражение} (тильда, фигурная скобка, XPath-выражение относительно текущего элемента XML, закрывающая фигурная скобка).Что делать, если в отчёте нам нужны повторяющиеся элементы? Естественным образом их можно представить в виде элементов XML-файла с данными, а помочь проитерировать по ним нужным образом помогает дескриптор. Повторение элементов в отчёте может иметь как вертикальное направление (когда мы вставляем строки накладной, например), так и горизонтальное (когда мы вставляем столбцы аналитического отчёта). При этом мы можем пользоваться вложенностью элементов XML, чтобы отразить сколь угодно глубокую вложенность повторяющихся элементов отчёта, как показано на диаграмме:

Красными квадратиками отмечены ячейки, которые будут являться левым верхним углом очередного прямоугольного фрагмента, который пристыковывает генератор отчёта.
Есть и ещё один возможный вариант повторяющихся элементов: листы в книге Excel. Возможность организовать такую итерацию тоже имеется.
Рассмотрим чуть более сложный пример. Допустим, нам надо получить сводный отчёт наподобие следующего:
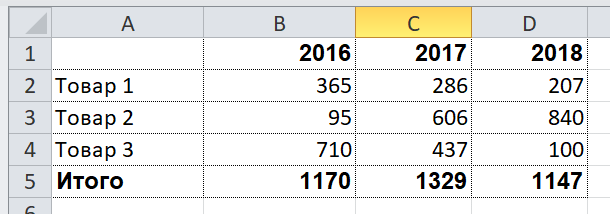
Пусть диапазон лет для выгрузки выбирает пользователь, поэтому в этом отчёте динамически создаваемыми являются как строки, так и столбцы. XML-представление данных для такого отчёта может выглядеть следующим образом:
<?xml version="1.0" encoding="UTF-8"?>
<report>
<column year="2016"/>
<column year="2017"/>
<column year="2018"/>
<item name="Товар 1">
<year amount="365"/>
<year amount="286"/>
<year amount="207"/>
</item>
<item name="Товар 2">
<year amount="95"/>
<year amount="606"/>
<year amount="840"/>
</item>
<item name="Товар 3">
<year amount="710"/>
<year amount="437"/>
<year amount="100"/>
</item>
<totals>
<year amount="1170"/>
<year amount="1329"/>
<year amount="1147"/>
</totals>
</report>
Мы вольны выбирать названия тэгов по своему вкусу, структура также может быть произвольной, но с оглядкой на простоту конвертации в отчёт. Например, выводимые на лист значения я обычно записываю в атрибуты, потому что это упрощает XPath-выражения (удобно, когда они имеют вид
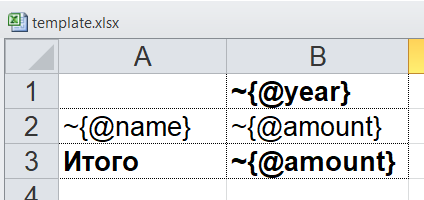
@имяатрибута).Шаблон такого отчёта будет выглядеть так (сравните XPath-выражения с именами атрибутов соответствующих тэгов):
Теперь наступает самая интересная часть: создание дескриптора. Т. к. это практически полностью динамически собираемый отчёт, дескриптор довольно сложен, на практике (когда у нас есть только «шапка» документа, его строки и «подвал») всё обычно гораздо проще. Вот какой в данном случае необходим дескриптор:
<?xml version="1.0" encoding="UTF-8"?>
<element name="report">
<!-- Создаём лист -->
<output worksheet="Отчет" sourcesheet="Лист1"/>
<!-- И за ним слева направо заголовки столбцов -->
<iteration mode="horizontal">
<element name="(before)">
<!-- Выводим пустую ячейку в ЛВУ сводной таблицы -->
<output range="A1"/>
</element>
<element name="column">
<output range="B1"/>
</element>
</iteration>
<!-- Выводим строки: итерация с режимом вывода умолчанию, сверху вниз -->
<iteration mode="vertical">
<element name="item">
<!-- И по строке - слева направо -->
<iteration mode="horizontal">
<element name="(before)">
<!-- Заголовок строки -->
<output range="A2"/>
</element>
<!-- И за ним слева направо строку с данными -->
<element name="year">
<output range="B2"/>
</element>
</iteration>
</element>
</iteration>
<iteration>
<element name="totals">
<iteration mode="horizontal">
<element name="(before)">
<!-- Заголовок строки -->
<output range="A3"/>
</element>
<!-- И за ним слева направо строку с данными -->
<element name="year">
<output range="B3"/>
</element>
</iteration>
</element>
</iteration>
</element>
Полностью элементы дескриптора описаны в документации. Вкратце, основные элементы дескриптора означают следующее:
- element — переход в режим чтения элемента XML-файла. Может или являться корневым элементом дескриптора, или находиться внутри
iteration. С помощью атрибутаnameмогут быть заданы разнообразные фильтры для элементов, напримерname="foo"— элементы с именем тэга fooname="*"— все элементыname="tagname[@attribute='value']"— элементы с определённым именем и значением атрибутаname="(before)",name="(after)"— «виртуальные» элементы, предшествующие итерации и закрывающие итерацию.
- iteration — переход в режим итерации. Может находиться только внутри
element. Могут быть выставлены различные параметры, напримерmode="horizontal"— режим вывода по горизонтали (по умолчанию — vertical)index=0— ограничить итерацию только самым первым встреченным элементом
- output — переход в режим вывода. Основные атрибуты следующие:
sourcesheet—лист книги шаблона, с которого берётся диапазон вывода. Если не указывать, то применяется текущий (последний использованный) лист.range– диапазон шаблона, копируемый в результирующий документ, например “A1:M10”, или “5:6”, или “C:C”. (Применение диапазонов строк типа “5:6” в режиме вывода horizontal и диапазонов столбцов типа “C:C” в режиме вывода vertical приведёт к ошибке).worksheet– если определён, то в файле вывода создаётся новый лист и позиция вывода смещается в ячейку A1 этого листа. Значение этого атрибута, равное константе или XPath-выражению, подставляется в имя нового листа.
В действительности всевозможных опций в дескрипторе гораздо больше, смотрите документацию.
Ну что же, настало время скачать Xylophone и запустить формирование отчёта.
Возьмите архив с bintray или Maven Central (NB: на момент прочтения этой статьи возможно наличие более свежих версий). В папке /bin находится shell-скрипт, при запуске которого без параметров вы увидите подсказку о параметрах командной строки. Для получения результата нам надо «скормить» ксилофону все приготовленные ранее ингредиенты:
xylophone -data testdata.xml -template template.xlsx -descr descriptor.xml -out report.xlsx
Открываем файл report.xlsx и убеждаемся, что получилось именно то, что нам нужно:
Так как библиотека ru.curs:xylophone доступна на Maven Central под лицензией LGPL, её можно без проблем использовать в программах на любом JVM-языке. Пожалуй, самый компактный полностью рабочий пример получается на языке Groovy, код в комментариях не нуждается:
@Grab('ru.curs:xylophone:6.1.3')
import ru.curs.xylophone.XML2Spreadsheet
baseDir = '.'
new File(baseDir, 'testdata.xml').withInputStream {
input ->
new File(baseDir, 'report.xlsx').withOutputStream {
output ->
XML2Spreadsheet.process(input,
new File(baseDir, 'descriptor.xml'),
new File(baseDir, 'template.xlsx'),
false, output)
}
}
println 'Done.'
У класса
XML2Spreadsheet есть несколько перегруженных вариантов статического метода process, но все они сводятся к передаче всё тех же «ингредиентов», необходимых для подготовки отчёта.Важная опция, о которой я до сих пор не упомянул — это возможность выбора между DOM и SAX парсерами на этапе разбора файла с XML-данными. Как известно, DOM-парсер загружает весь файл в память целиком, строит его объектное представление и даёт возможность обходить его содержимое произвольным образом (в том числе повторно возвращаясь в один и тот же элемент). SAX-парсер никогда не помещает файл с данными целиком в память, вместо этого обрабатывает его как «поток» элементов, не давая возможности вернуться к элементу повторно.
Использование SAX-режима в Xylophone (через параметр командной строки
-sax или установкой в true параметра useSax метода XML2Spreadsheet.process) бывает критически полезно в случаях, когда необходимо генерировать очень большие файлы. За счёт скорости и экономичности к ресурсам SAX-парсера скорость генерации файлов возрастает многократно. Это даётся ценой некоторых небольших ограничений на дескриптор (описано в документации), но в большинстве случаев отчёты удовлетворяют этим ограничениям, поэтому я бы рекомендовал использование SAX-режима везде, где это возможно.Надеюсь, что способ выгрузки в Excel через Xylophone вам понравился и сэкономит много времени и нервов — как сэкономил нам.
И напоследок ещё раз ссылки:
- исходники — здесь: github.com/CourseOrchestra/xylophone
- документация — здесь: corchestra.ru/wiki/index.php?title=Xylophone
- все примеры кода из этой статьи — здесь: github.com/inponomarev/xylophone-example.
Комментарии (25)

Mikluho
03.09.2018 06:44+2В мире .net самый популярный вариант — Open XML SDK.
Работаем с API документа, доступны все возможности (ну или почти все, хотя я не натыкался на ситуацию, чтобы чего-то не хватило). Для привязки значений к шаблону можно использовать именованные ячейки, диапазоны и таблицы. На основе этого не сложно сделать свою библиотеку, максимально упрощающую реализацию конкретных задач.DieSlogan
03.09.2018 08:10Она шибко мудреная. Для выгрузки данных лучше всего подойдёт EPPlus, она простая и многое может.
Кстати, Apache POI вешал Tomcat на том объёме данных, которые EPPlus обрабатывал не поперхнувшись.pankraty
03.09.2018 08:42+2Еще в мире .NET есть библиотека ClosedXML, которая предоставляет гораздо менее громоздкий (чем OpenXML) API для работы с книгами XLSX (сама библиотека использует OpenXML, т.е. по сути является "оберткой"). А конкретно для формирования отчетов по готовым шаблонам очень удобно использовать библиотеку ClosedXML.Report, явялющуюся надстройкой над ClosedXML. Вот тут есть примеры, как быстро создать отчет.
В шаблоне прописываются источники данных в виде наименований полей CLR-объектов (поддерживаются выражения, в т.ч. Linq):

И само формирование отчета производится в несколько строк:
const string outputFile = @".\Output\report.xlsx"; var template = new XLTemplate(@".\Templates\report.xlsx"); using (var db = new DbDemos()) { // You can get the value from anywhere, not only from the database var cust = db.customers.LoadWith(c => c.Orders).First(); template.AddVariable(cust); template.Generate(); } template.SaveAs(outputFile); //Show report Process.Start(new ProcessStartInfo(outputFile) { UseShellExecute = true });
Обе библиотеки распространяются под свободной лицензией и поддерживают .NET Core. Когда-нибудь, надеюсь, дойдут руки написать более подробную статью о них на Хабре.
Mikluho
03.09.2018 16:51Да, я в курсе про ClosedXML, но на нашем примере там всплыли баги, но у нас и задачи не тривиальные.
IvanPonomarev Автор
03.09.2018 16:57Решается ли проблема вставки повторяемых элементов как по вертикали, так и по горизонтали?
Просто во многих отчётных библиотеках элементы копируются по вертикали, что позволяет делать выгрузку документов. Но иногда бывает нужно динамически задавать не только строки, но и столбцы (как в примере, разобранном в статье).pankraty
03.09.2018 17:06Да, можно посмотреть тут https://closedxml.github.io/ClosedXML.Report/docs/ru/Flat-tables, раздел Горизонтальные области
IvanPonomarev Автор
03.09.2018 17:28Посмотрел на гитхабе — довольно интересно, спасибо! Да уж, миры .net и Java слабо пересекаются и зачастую эволюционируют параллельно)
nsmcan
03.09.2018 07:10+2Генерация XML-Excel-файла напрямую.… Такой подход довольно популярен, но к недостаткам следует отнести то, что всякое решение, основанное на прямом редактировании XML-Excel-формата, является одноразовым «хаком», лишенным общности.
Наконец, возможна генерация Excel-файлов с использованием open source библиотек, из которых особо известна Apache POI. Разработчики Apache POI проделали титанический труд по reverse engineering бинарных форматов документов MS Office, и продолжают на протяжении многих лет поддерживать и развивать эту библиотеку.
Хм, то есть Apache POI, редактирующий XML-Excel-формат напрямую (используя OOXML) — это все же не хак? А все остальные подобные решения — так сразу и хак?
Вся Ваша статья после данных высказываний — сплошной XML, правда через Apache POI и его надстройку. Так что это можно отнести к #3 в Вашем списке.
В остальном — интересные выкладки, спасибо! Учту принцип, если придется что-то подобное ваять на JS (с использованием какой-либо JS библиотеки, наверное)…
BDI
03.09.2018 09:06У варианта 3 есть ещё один недостаток — часто автоматически созданные «эксель» файлы отправляются в другую автоматизированную систему для последующей обработки(понятно что тут лучше JSON или XML с согласованной структурой, но я был на принимающей стороне, от меня формат не зависел). Вот только то что Excel может открыть файл с расширением xls даже когда в нём XML/HTML создаёт больше проблем, т.к. в отличии от честного XLS, который можно прочитать через то же ADO, кустарный XML/HTML возможно(мне пришлось, готовых компонент не нарыл) придётся парсить вручную. Ещё хуже когда сотрудник, так же получающий эти отчёты, открывает их в Excel, вносит корректировки, сохраняет(уже в настоящий XLS), и отправляет на автоматическую обработку, полагая что та всё съест(К счастью такое случалось редко, и я затягивал данные ручками через DTS).
Так что вариант 3 это крайне ограниченно годный вариант, лучше уж валидный XLSX или честный CSV, чем псевдо-XLS.nsmcan
03.09.2018 16:16Можно и текстовому файлу XLS раширение дать. И Excel его даже откроет и распарсит, ругнувшись предварительно. В статье есть ссылка на Apache POI. Там интересная инфа, я раньше не знал, как это официально называется:
various file formats based upon the Office Open XML standards (OOXML) and Microsoft's OLE 2 Compound Document format (OLE2)…
OLE2 files include most Microsoft Office files such as XLS, DOC, and PPT as well as MFC serialization API based file formats. The project provides APIs for the OLE2 Filesystem (POIFS) and OLE2 Document Properties (HPSF).
Раз есть официальные названия, то можно и поискать библиотеки, умеющие с ними работать. И использовать в своих проектах, где не подойдет Apache POIIvanPonomarev Автор
03.09.2018 17:00Лицензии этих библиотек тоже немаловажная вещь. Apache POI хорош своей пермиссивной Apache License. А детища Microsoft до последних пор не баловали совместимостью с опенсорсом.
hippohood
03.09.2018 11:44+1Как известно, Excel поддерживает XML-формат сохранения документа, который потенциально можно сгенерировать/модифицировать с помощью любого средства работы с XML. Этот файл можно сохранить с расширением .xls, и хотя он, строго говоря, при этом не является xls-файлом, Excel его хорошо открывает.
Ничего не понимаю. Это все на случай если кто-то пользуется офисом на Windows XP? XLSX format это ZIP file с обычным XML текстовыми файлами внутри. Если файл содержит только данные и немного форматирования, то его очень легко построить и редактировать. Я сам это делал в notepad.
turbanoff
03.09.2018 12:34Apache POI, например, используется в Libre Office для реализации сохранения документов в форматах, совместимых с MS Office
Откуда такая информация? Насколько я знаю, для работы LibreOffice уже давно не нужна java, а Apache POI написан на java.IvanPonomarev Автор
03.09.2018 17:29Точно использовался в OpenOffice, про OpenOffice у Apache POI информация на их сайте. С LibreOffice информация требует проверки, посмотрю.
turbanoff
03.09.2018 17:50А где именно на сайте? Не могу найти.
IvanPonomarev Автор
03.09.2018 18:11poi.apache.org/#Mission+Statement
«As a general policy we collaborate as much as possible with other projects [...] Examples include: [...] Open Office.org with whom we collaborate in documenting the XLS format [...] When practical, we donate components directly to those projects for POI-enabling them.»turbanoff
03.09.2018 18:13+1То есть, OpenOffice НЕ использует Apache POI. Они просто вместе занимались reverse engineering XLS формата.
High_Tower
05.09.2018 08:01Похожая идея реализована в yarg, которая распространяется под Apache 2.0, и поддерживается в рамках платформы Cuba. Не сравнивали Xylophone с ней?
IvanPonomarev Автор
05.09.2018 12:45Каждая бизнес-платформа должна иметь подобный инструмент. У Cuba свой, у CourseOrchestra — свой. Применительно к yarg (хабрапост, документация):
- нацелена как на Word, так и на Excel (Xylophone нацелен только на Excel),
- потому возможная структура генерируемых отчётов именно на Excel навскидку у Yarg проще, чем у Xylophone. Не вижу примеров с горизонтальной итерацией или итерацией по листам книги (хотя может быть просто плохо смотрю, и тут кубаводы может быть что-то могут сказать)
- заточено на использование совместно с кубой (в документации видим визуальные билдеры). Xylophone полностью самодостаточен (хотя опять же, может быть, я недооцениваю самодостаточность yarg)
BD9
Office Open XML
Лучше использовать OpenDocument, который для РФ является госстандартом.
Файлы МС Офиса (в т.ч. Экселя) есть XML файл, ужатый zip-ом (+ дополнения к этому XML файлу).
IvanPonomarev Автор
Насчёт ODF: в Xylophone разделены механизмы формирования отчёта (копирования кусков шаблона и подстановки выражений в ячейки) и формирования собственно выходного документа.
Поэтому добавить в Xylophone ODF-вывод является нетрудной задачей, и более того, есть уже даже класс ODFReportWriter, который, однако, в текущий момент — заглушка. За всё время реализовать поддержку ODF так и не потребовалось. Но мы принимаем пулл реквесты))